注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:Seed1.5-Thinking: Advancing Superb Reasoning Models with Reinforcement Learning, arXiv 20250429, ByteDance Seed
- 模型试用链接:火山方舟
- 文章中常常提到 Doubao-1.5-pro,未找到技术文档,仅官方发布模型时有介绍: Doubao-1.5-pro
Paper Summary
- 整体内容总结:
- 论文是字节的第一次开源,本论文介绍了推理模型 Seed1.5-Thinking
- 利用先进的 RL 技术,稳定可靠地提高了思维能力,在 AIME24 上达到 86.7%,在 AIME25 上达到 74.0%,在 Codeforces 上达到 55.0%
- Seed1.5-Thinking 模型能够在 response 前进行思考推理,在广泛的基准测试中实现了性能提升
- Seed1.5-Thinking 是一个 MoE(200B-A20B)
- Seed1.5-Thinking 展现了在 STEM 和编程领域卓越的推理能力
- 在 AIME 2024 上达到 86.7 分,在 Codeforces 上达到 55.0 分,在 GPQA 上达到 77.3 分
- 在非推理任务上,其胜率比 DeepSeek R1 高出 8%
- 作为论文评估广义推理能力工作的一部分,论文开发了两个内部基准测试 BeyondAIME 和 Codeforces(两者都开源)
Introduction and Discussion
- 在 LLM 上进行大规模强化学习,使得推理模型取得了显著进展
- OpenAI 的 o1 系列 (2024)、DeepSeek 的 R1 (2025)、Google 的 Gemini 2.5 (2025) 以及 Anthropic 的 Claude 3.7 (2025) 已成为 SOTA 模型,各自在逻辑推理、数学问题解决和代码生成方面取得了实质性进展
- 这些进展强调了向更结构化、更高效和可扩展的推理模型的转变,当前的研究重点集中在训练效率、长思维链(long chain-of-thought)和大规模强化学习上
- 在这项工作中,论文提出了一个新的推理模型,称为 Seed1.5-Thinking。该模型在推理和非推理任务上都取得了强大的性能
- 数学推理 (Mathematical Reasoning) :
- 对于数学竞赛,Seed1.5-Thinking 在 AIME 2024 上达到 86.7 分,与 o3-mini-high 的性能相当,并显著优于 o1 和 DeepSeek R1,展现了竞争优势
- 由于 AIME 2024 不再提供足够的区分度,论文构建了一个更具挑战性的评估集,命名为 BeyondAIME
- BeyondAIME 中的所有问题都是由人类专家新策划的,旨在最大限度地减少通过记忆或猜测解决的可能性
- 虽然 Seed1.5-Thinking 超越了 o1 和 R1,但与 o3 和 Gemini pro 2.5 相比仍存在性能差距
- 这也进一步证明了新评估集的区分能力
- 竞技编程 (Competitive Programming) :
- 对于竞技编程的评估,论文采用 Codeforces 作为论文的基准
- 与一些依赖 Elo 分数(包含估计且无法直接比较)的先前工作不同,论文采用了一个基于最近 12 场 Codeforces 比赛的具体评估协议
- 具体来说,论文报告 pass@1 和 pass@8 指标,其中 pass@k 表示模型是否在 k 次尝试内解决问题,即从 k 次生成的提交中选择最佳结果
- 论文选择报告 pass@8,因为它提供了更稳定的结果,并且更贴近实际的用户提交模式
- Seed1.5-Thinking 在这两个指标上都优于 DeepSeek R1,尽管与 o3 相比仍存在性能差距
- 评估集将在未来的版本中公开发布
- 科学 (Science) :
- Seed1.5-Thinking 在 GPQA 上达到了 77.3 分,接近 o3 级别的性能
- 特别地,这一提升主要归功于数学训练带来的泛化能力改进,而不是领域特定科学数据的增加
- 非推理任务 (Non-reasoning Tasks) :
- 对于非推理任务,Seed1.5-Thinking 使用一个旨在复现真实世界用户需求的测试集进行评估
- 通过在多样化场景下与 DeepSeek R1 进行的人工评估,Seed1.5-Thinking 展示了显著进步:用户的正面反馈总体提升了 8.0%,从而凸显了其处理复杂用户场景能力的增强
- 数学推理 (Mathematical Reasoning) :
- 高质量推理模型的开发有三个关键点 :训练数据、RL 算法和 RL 基础设施。论文在这三个方面投入了大量精力,并将详细讨论它们
- 数据 (Data) :
- 对于 SFT 训练 ,与传统的后训练数据不同,推理模型依赖于 CoT 数据 ,这些数据明确勾勒出逐步推理过程
- 论文的初步实验表明,过多的非 CoT SFT 数据会显著降低模型的探索能力
- 对于 RL 训练 ,论文整合了四类数据 :STEM 问题、代码相关任务、逻辑推理以及非推理数据(如创意写作和对话)
- 经验1:逻辑推理数据对 ARC-AGI 基准测试的性能提升贡献显著
- 经验2:数学数据展现出强大的泛化能力 ,并能带来跨任务的广泛性能提升
- RL 算法 (RL Algorithm) :
- 推理模型的 RL 训练非常不稳定且经常崩溃 ,特别是对于没有经过 SFT 的模型
- 有时,两次运行之间的分数差异可能高达 10 分
- RL 系统的稳定训练对于推理模型的成功至关重要
- 为了解决这些长期存在的问题,论文开创了 VAPO (2025) 和 DAPO (2025),两个分别针对 Actor-Critic 和策略梯度(policy-gradient)RL 范式的独特框架
- VAPO 现已成为 Actor-Critic 方法中 SOTA 解决方案,而 DAPO 则为无评论员模型的策略梯度方法确立了新的 SOTA 结果
- 推理模型的 RL 训练非常不稳定且经常崩溃 ,特别是对于没有经过 SFT 的模型
- 数据 (Data) :
Data
RL Training Data
- 论文的 RL 训练数据主要包括两个部分:
- 具有明确答案的可验证问题(verifiable problems)
- 没有明确答案的不可验证问题(non-verifiable problems)
- 模型的推理能力主要来自第一部分(可验证问题),并可以泛化到第二部分(不可验证问题)
Verifiable Problems
- 可验证问题主要包括配有答案的 STEM 问题、配备单元测试的编程问题以及适合自动验证的逻辑推理问题
STEM Data
- 论文的数据集包含数十万个高质量的竞赛级别问题,涵盖数学、物理和化学,其中数学占大多数(超过 80%)
- 这些问题来源于开源数据集、公共竞赛(国内和国际)以及专有集合的混合
- 对于数据清理,论文做以下流程:
- 首先剔除问题陈述不完整、符号不一致或要求不明确的问题
- 对于剩余的问题,论文使用论文的模型(Doubao-Pro 1.5)生成多个回答
- 模型在该问题上获得 woN 分数(worst of N)为 1 的问题被认为过于简单并被移除
- 最后,有些问题的参考答案可能不准确
- 论文使用 SOTA 推理模型为每个问题生成多个候选回答
- 作者认为参考答案是错误的判断依据:
- 如果模型的答案与参考答案不一致 ,但模型的输出显示出高度的内部一致性(或者仅涉及极少量的推理标记(reasoning tokens)不一致)
- 随后,人类专家对这些问题进行手动验证,以确保参考答案是正确的
- 论文还应用数据增强(data augmentation)使数据更适合学习和评估
- 论文将选择题转换为填空题或简答题格式,以消除猜测的可能性,并更好地评估推理能力
- 而且论文修改某些数学问题 ,以确保答案尽可能为整数
- 经过数据清理和增强后,论文最终获得了一个包含 10 万个 STEM 问题的训练集用于 RL 训练
- 在训练期间,论文使用基于模型的 Seed-Verifier 来评估回答的正确性 ,这将在 3.1 节介绍
Code Data
- 对于编程问题,论文优先选择高质量且具有挑战性的算法任务来源 ,主要来自著名的竞技编程竞赛
- 论文对数据进行过滤,以确保每个问题都包含全面的规范:清晰的问题描述、一组单元测试和一个检查器脚本(checker script)
- 单元测试 :验证解决方案的功能正确性
- 检查器脚本 :强制执行额外的约束,如输出格式和边缘情况
- 论文还进行了难度过滤 ,确保问题具有适当的复杂度和对现实世界算法推理的适用性
- 对于模型生成代码的评估:
- 最准确的形式是将生成的代码提交到官方平台,但在强化学习过程中,实时提交是不可行的
- 论文开发了一个离线评估集以进行高效的本地验证(论文的观察表明,离线评估结果与官方判定之间存在很强的相关性)
- 所有的训练和评估问题都被集成到一个内部的代码沙箱环境中,从而能够直接执行和评估模型生成的代码
- 论文确保沙箱的稳定性和高吞吐量,以便在 RL 训练过程中提供一致且准确的反馈
Logical Puzzle Data
- 对于逻辑推理数据,论文收集了 22 个常被研究的任务,例如 24 点、迷宫、数独等
- 对于每个任务,论文构建了一个数据生成器和一个答案验证器
- 数据生成器可以自动生成大量的训练和评估数据
- 此外,对于许多任务,我们可以配置生成问题的难度
- 在训练过程中 ,论文根据模型在某些任务上的表现逐步调整训练数据的难度(人工盯盘)
- 答案验证器严格评估生成的正确性,并可以作为奖励函数无缝集成到 RL 流程中
- 论文生成了大约 1 万个谜题问题用于 RL 训练
- 数据生成器可以自动生成大量的训练和评估数据
Non-verifiable Problems
- 不可验证问题主要包括需要基于人类偏好进行质量评估的非推理任务,涉及创意写作、翻译、知识问答(knowledge QA)、角色扮演等任务
- 提示词(prompts)来源于 Doubao-1.5 Pro (2025) 的 RL 训练数据
- 该数据集在不同领域具有足够的覆盖度
- 论文丢弃了样本分数方差低和难度低的数据
- 论文使用 SFT 模型为每个 Prompt 生成多个候选,然后使用奖励模型(reward model)对它们进行评分
- 分数方差低的 Prompt 被移除,因为它们表现出有限的采样多样性和最小的改进潜力
- 在 Doubao 1.5 Pro RL 训练过程 (2025) 中,奖励分数提升超过某个阈值的提示也会被移除
- 这是因为此类数据可能过于简单或已在数据集中大量存在
- 离线实验表明,对此类样本进行过度优化会导致模型的探索空间过早崩溃并降低性能
- 问题:如何理解这里的 奖励分数提升超过某个阈值(reward score improvement surpasses a certain threshold) 移除?原文如下:
Prompts are also removed where the reward score improvement surpasses a certain threshold during the Doubao 1.5 Pro RL training process [8]. This is because such data may be overly simplistic or already abundantly represented in the dataset. Offline experiments show that overoptimizing such samples leads to premature collapse of the model’s exploration space and diminish the performance.
- 对于这些不可验证的数据,论文采用成对奖励方法(pairwise rewarding method)进行评分和 RL 训练
- 通过比较两个样本(samples)的相对质量 ,这种方法有助于模型更好地理解用户偏好,提高生成结果的质量和多样性
- 理解:即同一个 Prompt 生成多个候选,然后两两比较优劣?
- 奖励模型的细节在 3.2 节介绍
- 通过比较两个样本(samples)的相对质量 ,这种方法有助于模型更好地理解用户偏好,提高生成结果的质量和多样性
Advanced Math Benchmark
- 当前的推理模型通常使用 AIME 作为评估数学推理能力的首选基准
- 但由于其每年仅发布 30 个问题,有限的规模可能导致高方差的评估结果,使得有效区分 SOTA 推理模型具有挑战性
- 为了更好地评估模型的数学推理能力,论文构建了一个新的基准数据集:BeyondAIME
- 论文与数学专家合作,基于既有的竞赛形式开发原创问题
- 论文通过结构修改和场景重构系统地改编现有的竞赛题目,确保没有直接重复
- 此外,论文确保答案绝不是 trivial 的值(never trivial values,例如问题陈述中明确提到的数字),以减少模型在没有适当推理的情况下猜测正确答案的机会
- 通过这种严格的过滤和策划过程,论文最终汇编了 100 个问题集,每个问题的难度水平等于或大于 AIME 中最难的问题
- 与 AIME 类似 ,所有答案都保证是整数(不限于特定的数值范围),这简化并稳定了评估过程
Reward Modeling
- 作为 RL 中的关键组成部分,奖励建模定义了策略试图实现的目标或目的
- 一个精心设计的奖励机制对于在训练阶段为模型响应提供精确可靠的奖励信号至关重要
- 对于可验证和不可验证的问题,论文采用不同的奖励建模方法
Reward Modeling for Verifiable Problems
- 借助正确的原则和思维轨迹,论文利用 LLM 来评判不同场景下的各种可验证问题
- 这种方法产生了一种更通用的解决方案,超越了基于规则的奖励系统的局限性
- 论文设计了两种渐进的奖励建模解决方案,Seed-Verifier 和 Seed-Thinking-Verifier :
- Seed-Verifier 基于一套由人工精心编写的原则(问题:非 thinking 模式?)
- 利用 LLM 强大的基础能力来评估一个包含问题、参考答案和模型生成答案的三元组
- 如果参考答案和模型生成的答案本质上是等价的,则返回“YES”;否则返回“NO”
- 这里的等价性不是字面上的完全匹配,而是基于计算规则和数学原则的更深入评估,证明两个答案传达了相同的数学含义
- 这种方法确保奖励信号能准确反映模型的响应在本质上是否正确,即使措辞有所不同
- Seed-Thinking-Verifier 的灵感来源于人类的判断过程,即通过细致的思考和深入的分析来生成结论性的判断
- 为了实现这一点,论文训练了一个验证器(问题:Seed-Thinking-Verifier?),为其评估提供详细的推理路径
- 具体来说,论文将此视为一个可验证的任务,并与其他数学推理任务一起进行优化
- 该验证器可以剖析参考答案和模型生成答案之间的异同,提供精确而细致的判断结果
- 问题:Seed-Verifier 与 Seed-Thinking-Verifier 的区别是什么?
- 回答(待确认):Seed-Verifier 更简单也更快,Seed-Thinking-Verifier 则更复杂,但更详细,更精确
- Seed-Verifier 基于一套由人工精心编写的原则(问题:非 thinking 模式?)
- Seed-Thinking-Verifier 显著缓解了与 Seed-Verifier 相关的三个主要问题:
- 奖励黑客攻击 (Reward Hacking) :非思考模型可能利用漏洞获得奖励,而没有真正理解问题
- Seed-Thinking-Verifier 中详细的推理过程使得此类黑客攻击更加困难
- 预测的不确定性 (Uncertainty in Predictions) :在参考答案和模型生成答案本质上等价但格式可能不同的情况下
- 例如 \(2^{19}\) 与 524288,Seed-Verifier 有时可能返回“YES”,有时返回“NO”
- 问题:Seed-Verifier 会评估答案的本质是否等价,不会这都判断不了吧
- Seed-Thinking-Verifier 通过彻底分析答案背后的推理,提供一致的结果
- 例如 \(2^{19}\) 与 524288,Seed-Verifier 有时可能返回“YES”,有时返回“NO”
- 在极端案例上的失败 (Failure on Corner Cases) :存在某些边缘案例是 Seed-Verifier 难以有效处理的
- Seed-Thinking-Verifier 提供详细推理的能力使其能够更好地处理这些复杂场景
- 奖励黑客攻击 (Reward Hacking) :非思考模型可能利用漏洞获得奖励,而没有真正理解问题
- 表 1 展示了上述两种验证器的性能
- 结果表明,Seed-Verifier 难以有效处理某些特定情况,而 Seed-Thinking-Verifier 则展现出提供准确判断的卓越能力
- 尽管后者的思考过程确实消耗了大量的 GPU 资源,但作者相信其产生的精确且稳健的奖励结果对于赋予策略强大的推理能力至关重要
- 表 1:两种验证器类型的准确率,具体来说,训练集上的准确率来自训练统计数据,此外,论文手动标注了 456 个样本来形成测试集,这些样本是专门从 Seed-Verifier 无法稳定处理的案例中挑选出来的

Reward Modeling for Non-verifiable Problems
- 对于不可验证的问题,论文训练一个奖励模型用于 RL 训练
- 奖励模型的训练数据与 Doubao 1.5 Pro (2025) 中使用的人类偏好数据一致,主要涵盖创意写作和摘要等类别
- 为了增强奖励模型的有效性:论文采用了 (2025) 中提到的成对生成奖励模型(pairwise generative reward model)
- 论文链接:Exploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback, arXiv 20250402, ByteDance Seed
- 具体方式:该模型评估两个响应的优劣,并使用“YES”或“NO”的概率作为最终的奖励分数
- 这种方法使模型能够在评分时直接比较响应之间的差异 ,从而避免过度关注不相关的细节
- 实验结果表明,这种奖励建模方法提高了 RL 训练的稳定性 ,特别是在涉及不可验证和可验证问题的混合训练场景中 ,通过最小化两种不同类型奖励建模范式之间的冲突来实现
- 这种改进可能归因于成对生成奖励模型在缓解异常值分数生成方面相比传统奖励模型具有固有优势,因此避免了与验证器在分数分布上的显著差异
- 问题:在训练时岂不是要两两对照进入奖励模型?奖励生成的成本会很高吧?
Approach
Supervised Fine-Tuning
- 论文的训练过程从 SFT 开始,SFT 阶段为后续的强化学习阶段奠定了坚实的基础
- 与从基础模型开始 RL 相比,SFT 模型产生更具可读性的输出,表现出更少的幻觉实例,并显示出更低的危害性
- 论文策划(curate)了一个包含 40 万个训练实例的 SFT 数据,其中包括 30 万个可验证问题和 10 万个不可验证问题
- 可验证的提示词是从 RL 训练集中随机采样的
- 不可验证数据来源于用于 Doubao-Pro 1.5 (2025) 的 SFT 数据,涵盖创意写作、基于知识的问答、安全性和函数调用等领域
- 为了生成具有长思维链(long CoT)的高质量响应,论文采用了一个集成模型合成(integrates model synthesis)、人工标注(human annotation)和拒绝采样(rejection sampling)的迭代工作流程
- 最初,人类专家应用提示工程(prompt engineering)技术或与内部模型进行交互式对话,以产生具有各种推理模式的响应
- 在积累了数十个(tens)高质量的冷启动样本后,我们可以训练一个具有长 CoT 的推理模型作为更有能力的助手
- 问题:只是数十个吗?如何理解 SFT 这里的整个迭代工作流程?
- 然后,论文使用 Seed-Verifier 对该推理模型执行拒绝采样
- 虽然此工作流程主要应用于数学数据,但论文观察到它可以很好地推广到其他领域,例如编码、逻辑谜题甚至创意写作
- 因此,对于其他领域,论文也进行冷启动过程,然后进行拒绝采样,以产生详细的推理轨迹
- 最初,人类专家应用提示工程(prompt engineering)技术或与内部模型进行交互式对话,以产生具有各种推理模式的响应
- 一些训练细节:
- 在训练期间,每个实例被截断至 32,000 个 tokens
- 论文使用上述数据对基础模型进行两个周期(epochs)的微调
- 论文使用余弦衰减学习率调度(cosine decay learning rate scheduling)
- 峰值学习率 \(\mathrm{lr}\) 为 \(2\times 10^{-5}\),
- 逐渐衰减至 \(2\times 10^{-6}\)
Reinforcement Learning
- 论文开发了一个统一的强化学习框架,可以无缝融合来自广泛领域的数据。这种集成包含三种数据类别:
- 可验证数据 (Verifiable data) ,从验证器获取反馈
- 这类数据允许根据已知标准直接验证(verification)模型的输出
- 通用数据 (General data) ,由奖励模型评分
- 奖励模型根据模型的响应与人类偏好的匹配程度来分配分数
- 一类特定数据(A specific class of data) ,结合了验证器和奖励模型的分数
- 这种混合数据类型利用了基于验证(verification)和基于奖励(reward)的评估的优势
- 可验证数据 (Verifiable data) ,从验证器获取反馈
- 在长思维链 RLHF(long-CoT RLHF)的背景下,论文遇到了几个挑战,例如价值模型偏差(value model bias)和奖励信号的稀疏性
- 为了以上解决这些问题,论文借鉴了先前工作 (2025, 2025, 2025) 中的关键技术:
- 价值预训练 (Value-Pretraining) :
- 论文从固定策略(例如 \(\pi_{\text{sft} }\))中采样响应,并使用蒙特卡洛回报(Monte-Carlo return)更新价值模型
- 这个过程确保初始化的价值模型与论文的策略 \(\pi_{\text{sft} }\) 完全对齐
- 保持这种对齐已被证明对于保持模型的 CoT 模式至关重要,使模型能够生成连贯且合乎逻辑的 CoT
- 解耦广义优势估计 (Decoupled-GAE) :
- 采用不同的广义优势估计(Generalized Advantage Estimation, GAE)参数,
- 例如 \(\lambda_{\text{value} }=1.0\) 和 \(\lambda_{\text{policy} }=0.95\),
- 允许价值模型以无偏的方式更新 ,同时,策略可以独立地平衡自身的偏差和方差
- 这种解耦使得模型的训练更加高效和稳定
- 采用不同的广义优势估计(Generalized Advantage Estimation, GAE)参数,
- 长度自适应的 GAE (Length-adaptive GAE) :
- 论文设定 \(\lambda_{\text{policy} }=1-\frac{1}{\alpha l}\),其中 \(\alpha\) 是一个超参数,\(l\) 是响应长度
- 这种方法确保时间差分(Temporal Difference, TD)误差在短序列和长序列上分布更均匀
- 因此,模型在训练期间可以更有效地处理不同长度的序列
- 问题:理解一下这里的方法
- 动态采样 (Dynamic Sampling) :
- 论文采用动态采样,并过滤掉准确率分数等于 1 或 0 的提示词,仅保留批次中表现出有效梯度的那些
- 这个过程有助于防止模型训练期间梯度信号的衰减
- Clip-Higher :
- 在近端策略优化(Proximal Policy Optimization, PPO)算法中,论文将上下裁剪边界解耦如下:
$$\mathcal{L}^{CLIP}(\theta)=\hat{\mathbb{E} }_{t}\left[\min\left(r_{t}(\theta)\hat {A}_{t},\operatorname{clip}(r_{t}(\theta),1-\epsilon_{\text{low} },1+\epsilon_{ \text{high} })\hat{A}_{t}\right)\right] \tag{1}$$ - 通过增加 \(\epsilon_{\text{high} }\) 的值,论文为低概率词元的增加创造了更多空间
- 这鼓励模型探索更广泛的可能响应,增强其发现新颖有效解决方案的能力
- 在近端策略优化(Proximal Policy Optimization, PPO)算法中,论文将上下裁剪边界解耦如下:
- 词元级损失 (Token-level Loss) :
- 论文不是在整个响应上定义策略损失,而是在所有词元上定义它
- 这种方法解决了词元对最终损失贡献不平衡的问题,确保每个词元对训练过程的影响得到适当考虑
- 正样本语言模型损失 (Positive Example LM Loss) :
- 该损失函数旨在提高 RL 训练过程中正样本的利用效率。论文为正样本添加一个系数为 \(\mu\) 的语言模型损失:
$$\mathcal{L}(\theta)=\mathcal{L}_{\text{PPO} }(\theta)+\mu*\mathcal{L}_{\text{NLL } }(\theta) \tag{2}$$ - 这个额外的损失项有助于模型更好地从正样本中学习,提高其整体性能(理解:相当于对正样本做 SFT)
- 该损失函数旨在提高 RL 训练过程中正样本的利用效率。论文为正样本添加一个系数为 \(\mu\) 的语言模型损失:
- 价值预训练 (Value-Pretraining) :
- 当合并来自不同领域的数据并整合不同的评分机制时,论文面临着不同数据领域之间相互干扰的挑战
- 这种干扰可能源于难度水平的差异、奖励黑客攻击的风险以及其他潜在因素
- 这些问题使得在模型的所有能力上实现统一且同步的改进变得极其困难
- 为了抵消这一点,论文引入了在线数据分布自适应 (Online Data Distribution Adaptation)
- 该方法将强化学习期间的静态提示分布转换为自适应分布,更好地满足模型在训练期间的需求
- 通过这样做,论文最大限度地减少了数据干扰的负面影响,并确保不同能力之间更平衡的改进
- 因此,模型可以在广泛的任务中更一致地提高其性能
Infrastructures
Framework
- 训练框架使用 HybridFlow (2024) 编程抽象构建
- 整个训练工作负载运行在 Ray (2017) 集群之上
- 数据加载器(databader)和 RL 算法在单个进程的 Ray Actor(单一控制器)中实现
- 模型训练和响应生成(rollout)在 Ray Worker Group 中实现
- Ray Worker Group 暴露一组 API(例如,generate_response / train_batch 等),通过 Worker Group 内部的 SPMD(单程序多数据)运行繁重的训练/生成工作负载
- 单一控制器调用 Ray Worker Group 暴露的各种 API 来构建训练流程
- HybridFlow 编程抽象使得能够快速原型化 RL 算法思想,而无需处理复杂的分布式系统
- Seed1.5-Thinking 通过混合引擎架构 (2023) 进行训练,其中所有模型都位于同一位置(all the models are co-located)
- 这防止了在训练和生成之间切换时 GPU 的空闲时间
- 在长链思维(Long-CoT)生成过程中,论文观察到由于不同提示词(prompts)的响应长度差异巨大而导致的严重掉队现象(severe straggler phenomenon)
- 这导致生成过程中大量的 GPU 空闲时间
- 为了缓解长尾响应生成的掉队问题,论文提出了 SRS(流式 Rollout 系统,Streaming Rollout System) ,这是一个资源感知的调度框架(resource-aware scheduling framework),它策略性地部署独立的流式计算单元 ,将系统约束从 内存受限(memory-bound) 转变为 计算受限(compute-bound)
Streaming Rollout System
- SRS 架构引入了 流式 rollout(streaming rollout) 来将模型演化与运行时执行解耦,通过参数 \(\alpha\) 动态调整在策略(on-policy)与离策略(off-policy)样本的比例:
- 定义完成率 (\(\alpha \in [0,1]\)) 为使用最新模型版本生成的 on-policy 样本比例
- 将剩余未完成部分 (\(1-\alpha\)) 分配给来自版本化模型快照的 off-policy rollout,通过在独立资源上异步继续部分生成来实现无缝集成(seamlessly integrated through asynchronous continuation of partial generations on the standalone resources)
- 此外,论文还在环境交互阶段实现了动态精度调度 ,通过训练后量化和误差补偿范围缩放来部署 FP8 策略网络(deploys FP8 policy networks via post-training quantization with error-compensated range scaling)
- 为了解决 MoE 系统中的 Token 不平衡问题,论文实现了一个三层并行架构,结合了用于逐层计算的 TP(张量并行,tensor parallelism)、带有动态专家分配的 EP(专家并行,expert parallelism)以及用于上下文分块的 SP(序列并行,sequence parallelism)
- 论文的内核自动调优器(kernel auto-tuner)根据实时负载监控动态选择最优的 CUDA 内核配置
Training System
- 为了高效地大规模训练 Seed1.5-Thinking 模型,论文设计了一个混合分布式训练框架,该框架集成了先进的并行策略、动态工作负载平衡和内存优化
- 下面论文详细介绍驱动系统效率和可扩展性的核心技术创新
- 并行机制(Parallelism mechanisms)
- 论文将 TP(张量并行)/ EP(专家并行)/ CP(上下文并行,context parallelism)与完全分片数据并行(Fully Sharded Data Parallelism, FSDP)相结合来训练 Seed1.5-Thinking
- 具体来说,论文对注意力层应用 TP/CP ,对 MoE 层应用 EP
- 序列长度平衡(Sequence length balancing)
- 现有挑战:有效序列长度在 DP ranks 之间可能不平衡,导致计算工作量不平衡和训练效率低下
- 注:DP ranks 即数据并行数量
- 为了应对这一挑战,论文利用 KARP (1982) 算法,该算法在一个小批量(mini-batch)内重新排列输入序列,使它们在微批次(micro-batches)之间达到平衡
- 问题:待补充 KARP 算法
- 回答:KARP 是一种用于解决组合优化领域的 NP 难问题的算法,核心思想是通过动态规划(Dynamic Programming, DP) 降低 NP 难问题的时间复杂度
- 现有挑战:有效序列长度在 DP ranks 之间可能不平衡,导致计算工作量不平衡和训练效率低下
- 内存优化(Memory optimization)
- 论文采用逐层重计算 (2016)、激活卸载(activation offload)和优化器卸载(optimizer offload)来支持更大微批次的训练,以重叠由 FSDP 引起的通信开销
- 自动并行(Auto parallelism)
- 为了实现最佳系统性能,论文开发了一个自动调优系统,称为 AutoTuner
- 具体来说:
- AutoTuner 采用基于性能分析 (2022) 的方案对内存使用进行建模
- 然后,它估计各种配置的性能和内存使用情况,以获得最优配置
- 检查点(Checkpoint)
- 论文采用 ByteCheckpoint (2025) 来支持以最小开销从不同分布式配置中恢复检查点
- 这使得用户能够弹性地训练任务以提高集群效率
- 并行机制(Parallelism mechanisms)
Experiment Results
Auto Evaluation Results
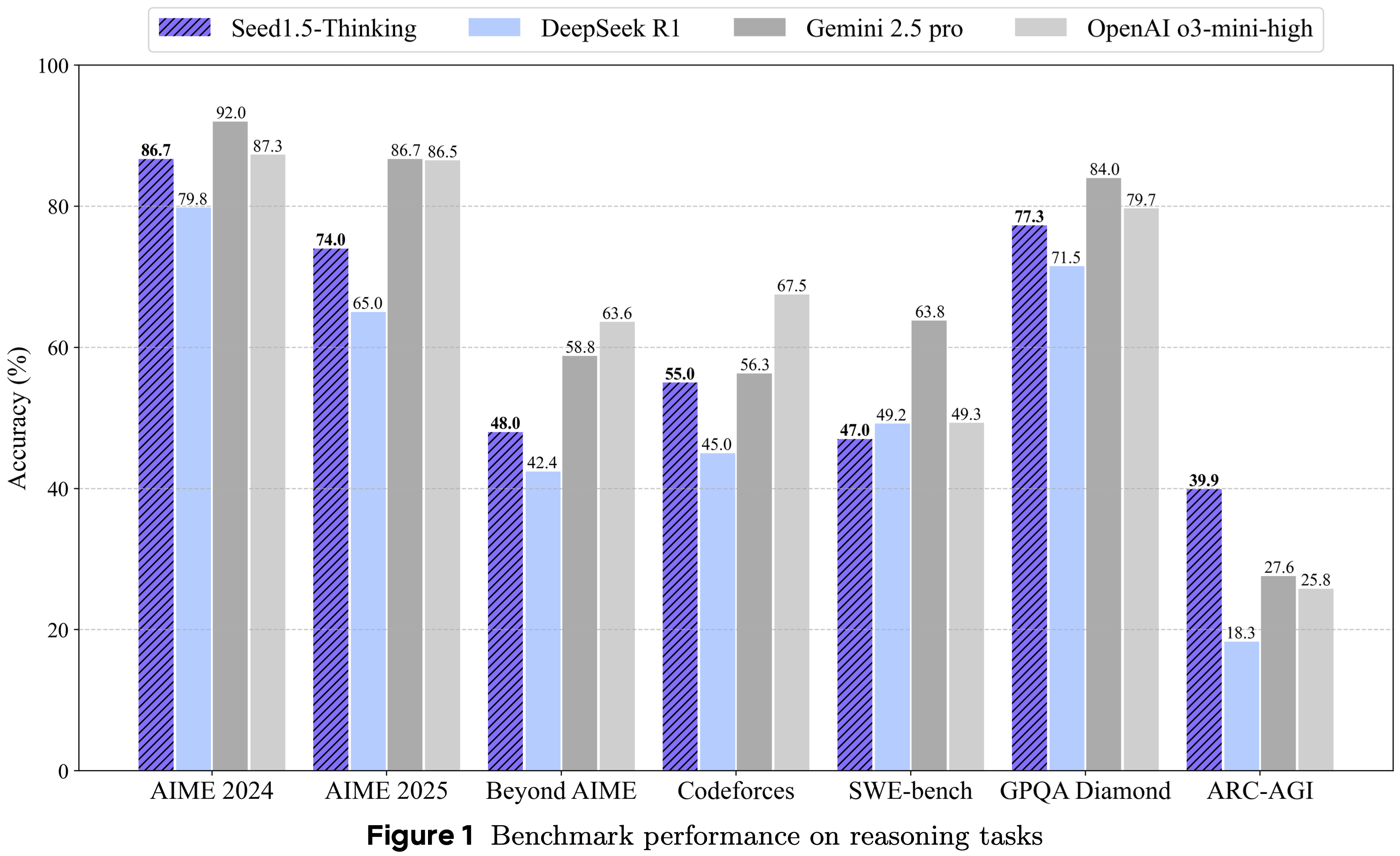
- 表 2 展示了在数学、编码、科学和常识领域等各种任务上的评估结果
- 对于数学基准任务,结果是 32 个模型响应的平均值,而 GPQA 任务的结果是 8 个响应的平均值
- 对于 Codeforces,论文同时报告 avg@8 和 pass@8,因为 pass@8 更符合人类提交习惯
- 所有其他任务的结果均为 1 个响应的平均值
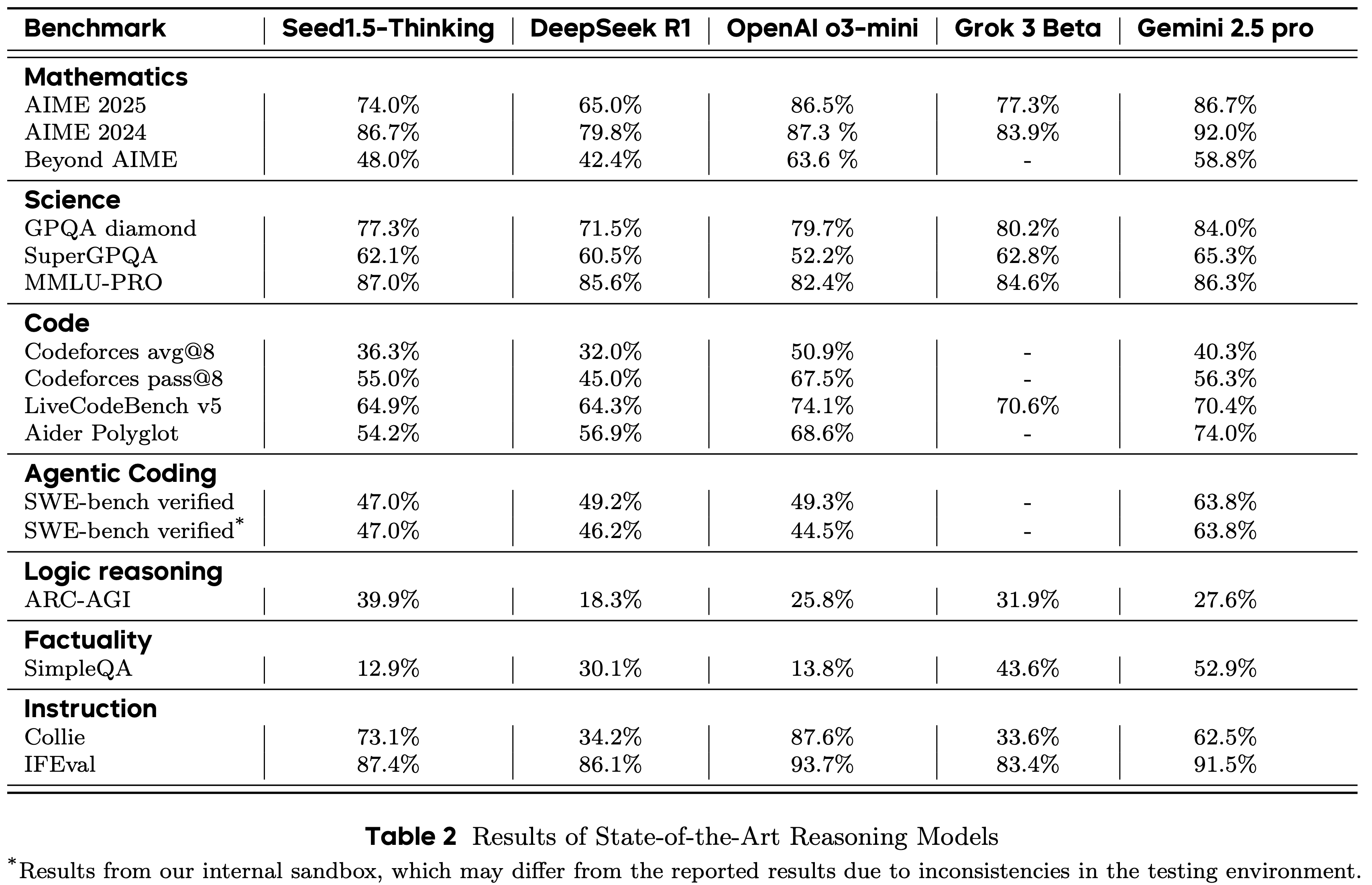
- 在数学推理方面
- Seed1.5-Thinking 在 AIME 2024 基准上达到了顶级性能,得分为 86.7,与 OpenAI 的 o3-mini-high 模型的性能相当
- 在更新的 AIME 2025 和更高级的 BeyondAIME 挑战上,Seed1.5-Thinking 仍然落后于 o3 级别的性能
- 对于 GPQA 任务,Seed1.5-Thinking 达到了 77.3% 的准确率,接近 o3-mini-high 的性能
- 在代码生成场景(如 Codeforces)中,
- Seed1.5-Thinking 几乎与 Gemini 2.5 Pro 的性能相当,但仍然落后于 o3-mini-high
- 值得注意的是,Seed1.5-Thinking 在 SimpleQA 上的结果不太令人印象深刻
- 值得强调的是,该基准主要作为一个面向记忆的指标,其性能与预训练模型规模的相关性更强,而不是与真正的推理能力相关
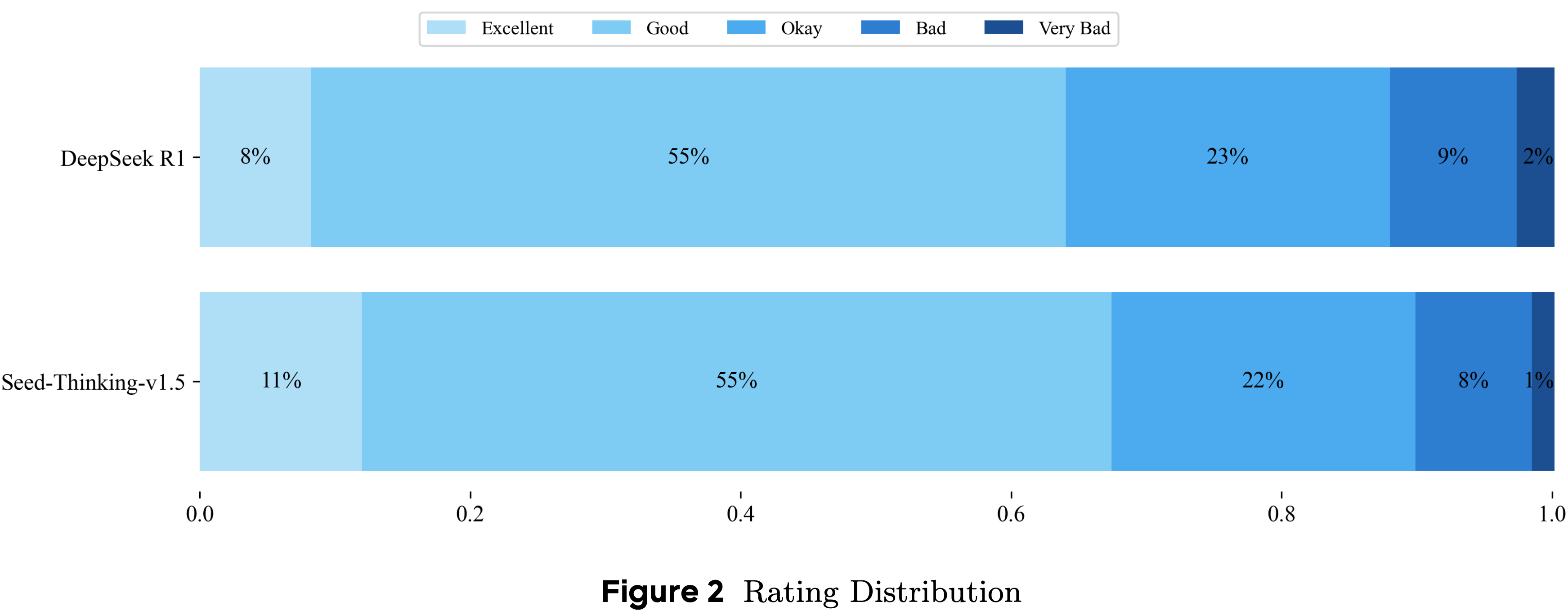
Human Evaluation Results
- 为了评估模型在主观任务上的性能(在这些任务中,自动化指标不足以捕捉细微的人类偏好),论文在各种非推理场景中进行了人工评估
- 论文的评估旨在衡量质量的关键维度,如连贯性、相关性、创造性和对人类中心偏好的遵守程度,由一个领域专家评估小组根据预定义的评分标准对模型输出与 Deepseek R1 进行评分
- 论文使用 5 点序数量表,范围从 0(非常差)到 4(优秀),并在具有多轮的会话提示词上评估两个模型
- 每个完整会话都用一个二元胜/负结果进行注释以捕捉整体用户体验,并且每轮分配一个 0-4 的分数
- 问题:二元比较又如何分配 0-4 的分数
- Seed1.5-Thinking 在评估的会话中实现了 8.0% 的总胜率,表明其在符合人类中心偏好方面具有优势
- 此外,这种胜率在不同场景中是一致的,从创意写作到人文知识阐述
- 图 2 显示了每轮级别的分数分布
Effects of pre-train models
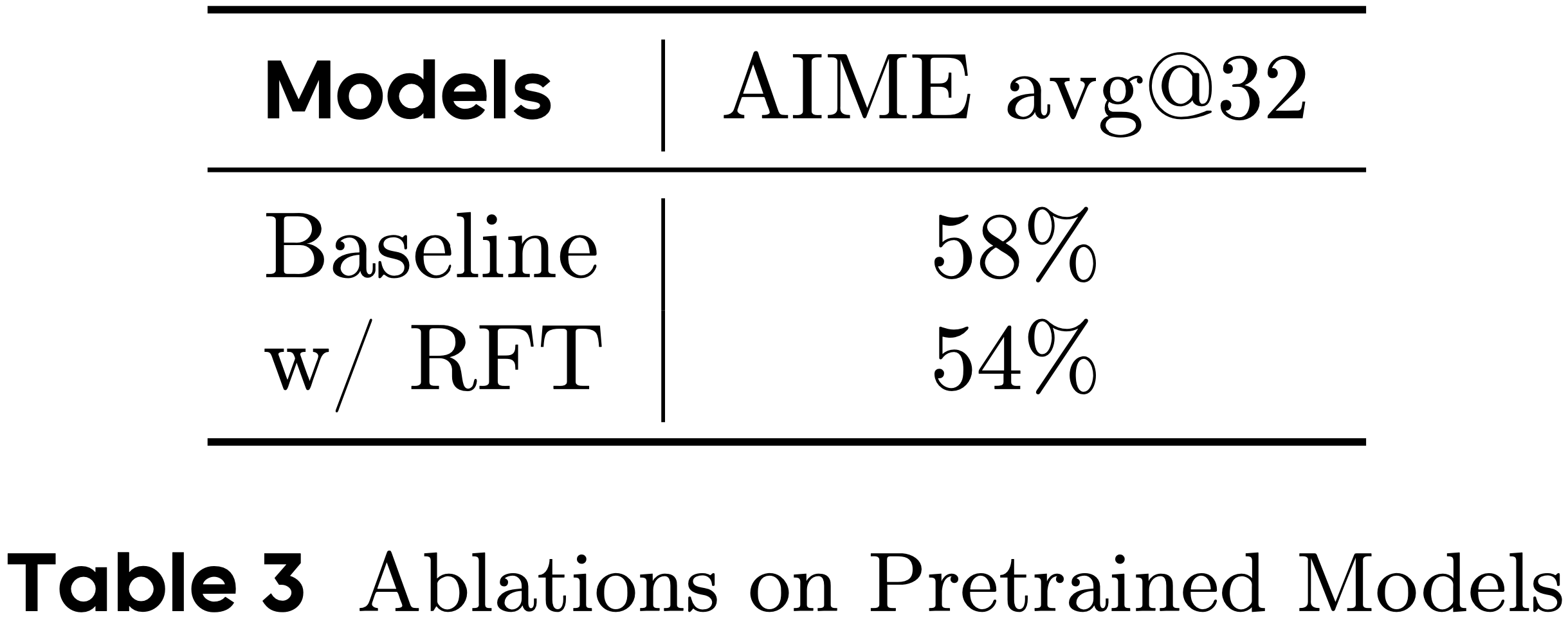
- 拒绝采样(Rejection Sampling)
& 拒绝采样已被认为是一种提高模型性能的有价值的技术 (2024)- 论文进行了一项消融实验,以检查使用拒绝微调(Rejection Fine-Tuning, RFT)模型初始化 RL 是否会影响结果
- 论文的结果表明,使用 RFT 初始化的预训练模型在训练过程中饱和得更快,但最终达到的性能低于没有使用 RFT 训练的模型 ,如表 3 所示
- 跨模型尺寸的一致性算法排名(Consistent algorithm rankings across model size)
- 论文观察到 RL 算法在不同尺寸和架构的不同模型中表现出一致的排名行为
- 如表 4 所示,Seed-150B-MoE(一个在架构(MoE vs. Dense)和尺寸上都与 Qwen-32B 不同的模型)表现出了一致的排名
- 值得注意的是,这种一致性表明 Qwen-32B 可以有效地作为研究 RL 算法的代理模型
- 理解:Qwen-32B与其他超大模型在强化算法上的效果表现比较一致,可以用于验证不同方法的效果
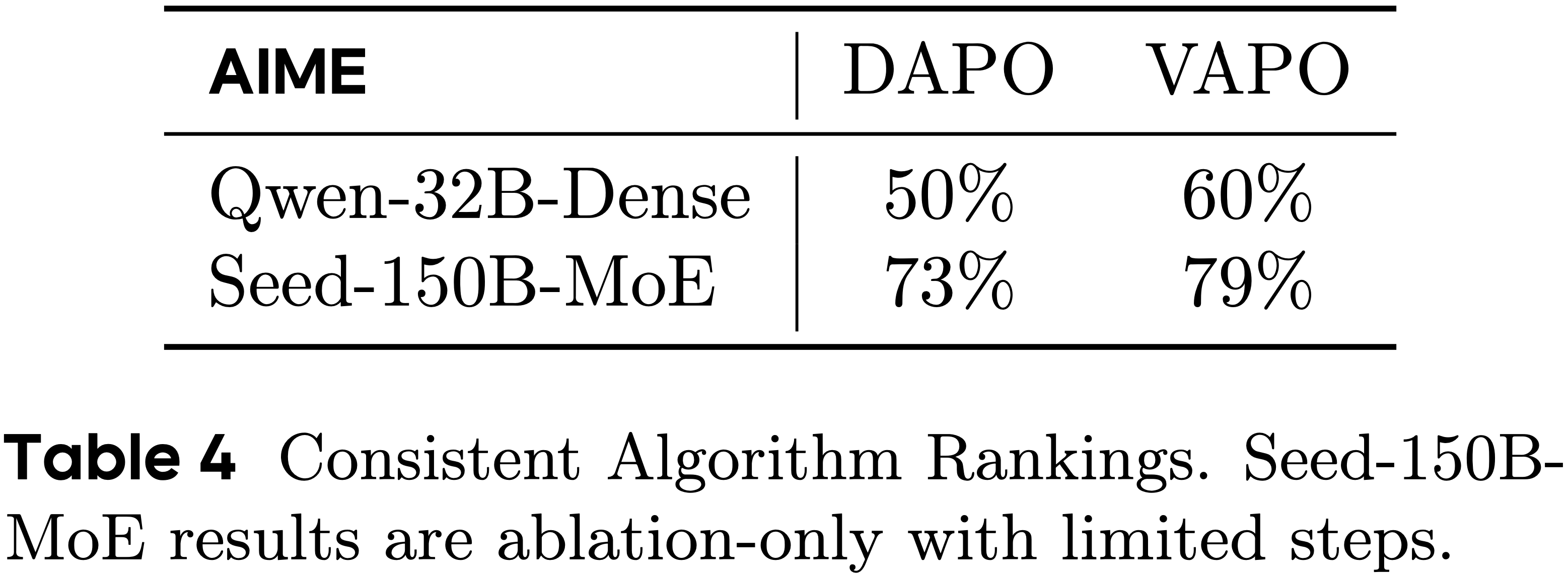
- 理解:Qwen-32B与其他超大模型在强化算法上的效果表现比较一致,可以用于验证不同方法的效果
Related Work
- 测试时缩放(Test-time scaling)(2024, 2025, 2025, 2025),已经催化了 LLM (2020, 2023) 的深刻范式转变
- 例如 OpenAI 的 o1 (2024) 和 DeepSeek 的 R1 (2025)
- 测试时缩放(Test-time scaling)通过启用扩展的思维链(CoT)推理 (2022) 并激发复杂的推理能力
- 这些方法使 LLM 能够在复杂的数学和编码任务中表现出色,包括来自 AIME 和 Codeforces 等竞赛的任务
- 这一转变的核心是大规模强化学习,它促进了复杂推理行为的出现——例如自我验证和迭代优化
- 但支持可扩展 RL 训练的关键方法和算法在很大程度上仍然不为人知,通常被现有推理模型 (2023, 2025, 2023, 2022, 2024) 的技术文档所忽略
- 在论文中,论文介绍了一个 SOTA 级别的模型 Seed1.5-Thinking,并从数据、RL 算法和 RL 基础设施三个方面介绍了实现该性能的细节
附录 A:Case Study on Verifier
- 表5展示了种子验证器(Seed-Verifier)与种子思维验证器(Seed-Thinking-Verifier)的对比案例研究
- 可以明显看出
- Seed-Verifier 在处理具有复杂答案的样本时存在显著困难
- Seed-Thinking-Verifier 能够通过逐步分析提供准确的判断结果
- 得益于其详细的思维过程,Seed-Thinking-Verifier 展现出卓越的灵活性,并能有效泛化至几乎任何领域

- 可以明显看出
附录 B:Case Study on Creative Writing
- 在表6、7、8中,论文通过中英文示例展示了模型在创意写作方面的能力
- 每个示例均包含三个独立部分:用户原始提示、模型的思维链以及模型的最终响应


