注:本文包含 AI 辅助创作
- 参考链接:
- 技术报告链接:LongCat-Flash-Thinking Technical Report, 20250922, Meituan LongCat
- Huggingface:huggingface.co/meituan-longcat/LongCat-Flash-Thinking
- GitHub:github.com/meituan-longcat/LongCat-Flash-Thinking
- LongCat Chat 在线体验: https://longcat.ai
- 部署链接:LongCat-Flash-Thinking Deployment Guide
- SGlang PR:[Model] Support Meituan LongCat-Flash && LongCat-Flash-MTP #9824
- vLLM PR:[Model] Add LongCat-Flash #23991
- 注:本次不需要新增代码,仅使用 LongCat-Flash-Chat 的代码即可
Paper Summary
- 论文介绍了 LongCat-Flash-Thinking(560B MoE 推理模型)
- LongCat-Flash-Thinking 的核心创新如下:
- 1)一个精心设计的冷启动训练策略
- 2)一个领域并行训练方案
- 3)一个高效且可扩展的强化学习框架,在数万个加速器上实现了工业规模的异步训练
- 整体来说,LongCat-Flash-Thinking 的流程包括:长 CoT 数据冷启动和大规模 RL
- 1)采用一种精心设计的冷启动训练策略,显著增强了模型的推理潜力,并使其具备了形式化推理(formal reasoning)和智能体推理(agentic reasoning)方面的专业技能
- 2)一个核心创新是论文的领域并行训练方案(domain-parallel training scheme) ,该方案解耦了不同领域(例如 STEM、代码、智能体)的优化过程,并将得到的专家模型融合为一个近乎帕累托最优(Pareto-optimal)的单一模型
- 整个流程由论文的动态异步 rollout 编排(Dynamic ORchestration for Asynchronous rollout, DORA)系统驱动,这是一个大规模 RL 框架,在数万个加速器上相比同步方法实现了超过三倍的训练加速
- 3)LongCat-Flash-Thinking 在一系列复杂推理任务上实现了开源模型中 SOTA 性能
- 该模型在智能体推理方面表现出卓越的效率,在 AIME-25 基准测试上将平均 token 消耗降低了 \(64.5%\)(从 \(19,653\) 降至 \(6,965\)),且未降低任务准确率
Introduction and Discussion
- 近年来, LLM 的前沿已明确转向增强其推理能力,不断推动通用人工智能(Artificial General Intelligence, AGI)的边界
- SOTA 模型展示了这一趋势,在复杂逻辑、数学、代码生成和智能体任务方面展现出卓越的能力
- 如 OpenAI 的 o1 (2024)、OpenAI 的 o3 (2025a)、Gemini 2.5 (2025)、DeepSeek-R1 (2025)、Qwen3 (2025) 和 GLM-4.5 (2025a),
- 这一进步主要由一个新范式驱动:利用大规模 RL (1998) 不仅来精炼模型,还能在推理时实现更深入、更广泛的推理
- 通过动态分配更多计算 FLOPs 来扩展 CoT (2022),像 OpenAI 的 o1 和 Gemini 2.5 Pro 这样的专业模型在包括奥林匹克级数学、竞争性编程和复杂智能体场景在内的艰巨挑战上取得了突破性性能
- 论文介绍了 LongCat-Flash-Thinking,一个高效的开源 MoE 推理模型,它为开源推理模型树立了新的最先进水平
- 基于基础的 LongCat-Flash-Base 模型 (2025) 构建,LongCat-Flash-Thinking(总参数量 560B:平均激活 27B)在复杂逻辑、数学、编码和智能体任务上表现出色
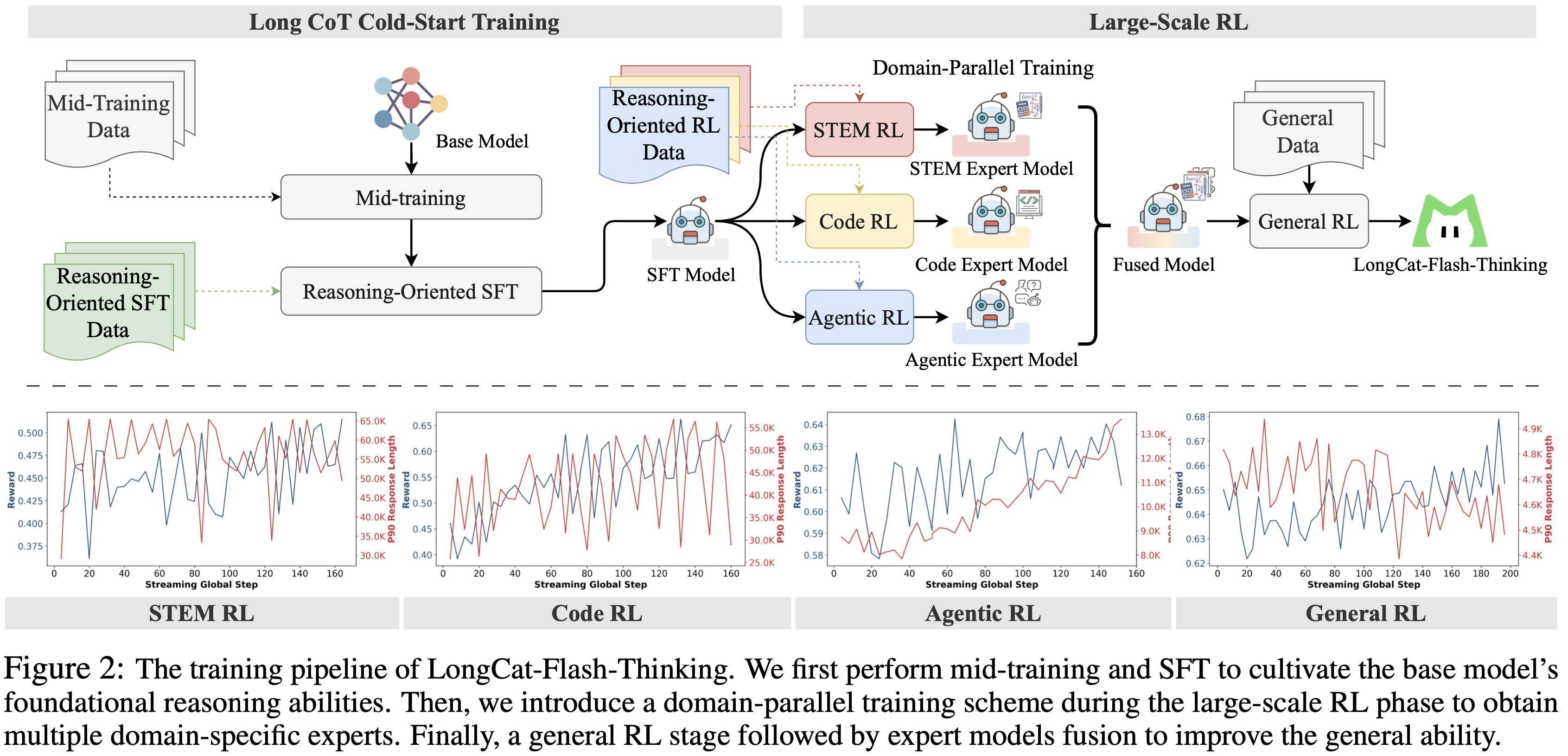
- LongCat-Flash-Thinking 的开发遵循一个精心设计的两阶段流程:长 CoT 冷启动训练(Long CoT Cold-Start Training)和大规模 RL(Large-Scale RL)
- 第一阶段,目标是构建模型的基础推理能力
- 这始于中段训练(mid-training)期间的课程学习(curriculum learning)策略,以增强其内在能力;
- 随后是一个针对推理密集型和智能体数据的有 SFT 阶段,为模型的高级学习做好准备
- 第二阶段,通过一个高效的 RL 框架来扩展这一潜力,该框架建立在论文提出的用于工业级异步训练的动态异步 rollout 编排(Dynamic ORchestration for Asynchronous rollout, DORA)系统之上
- 为了解决异步 RL 训练中的稳定性挑战,论文采用并扩展了 GRPO (2024) 算法,以实现稳健的探索-利用平衡
- 该阶段的一个关键创新是论文的领域并行训练方案(domain-parallel training scheme) ,它同时在不同领域优化模型,随后将得到的领域专家模型合并为一个融合模型 (2024a)
- 最后一个通用 RL 阶段进一步精炼融合模型,提高其在实际应用中的鲁棒性、安全性和人类对齐性
- 第一阶段,目标是构建模型的基础推理能力
- 训练流程概述如图 2 所示
- 首先,进行中段训练(mid-training)和 SFT 以培养基础模型的基础推理能力
- 然后,在大规模 RL 阶段引入领域并行训练方案以获得多个领域特定的专家
- 最后,通过一个通用 RL 阶段和随后的专家模型融合来提高通用能力
- 论文的工作提出了三个核心贡献:
- 领域并行 RL 训练与融合方法(Domain-Parallel RL Training and Fusion Methodology) :
- 为了克服传统混合领域 RL 训练的不稳定性,论文设计了一个领域并行方案,解耦了 STEM、编码和智能体任务的优化
- 这种方法不仅稳定了训练,还允许论文将得到的领域专家模型融合成一个近乎帕累托最优的最终模型,该模型在所有专业领域都表现出色
- 开创性的工业级 RL 基础设施(Pioneering Industrial-Scale RL Infrastructure) :
- 论文的 DORA 系统为训练提供了强大的骨干支持
- 其异步架构相比同步框架实现了超过三倍的加速,使得在数万个加速器上的稳定训练成为可能
- 这个工业级系统支持了接近预训练计算量 20% 的大规模 RL 投入,使得论文的先进方法能够大规模可行
- 论文还重点介绍了其新颖特性,包括弹性共置(elastic colocation)和高效的 KV 缓存(KV-cache)重用,这些将在第 3.1 节详述
- 论文的 DORA 系统为训练提供了强大的骨干支持
- 广泛且高效的高级推理(Broad and Efficient Advanced Reasoning) :
- 论文显著扩展了模型在挑战性领域的能力,实现了卓越的性能和效率
- 为了改进智能体能力,论文提出了一种双路径推理方法(dual-path reasoning approach)来选择最能从工具集成中受益的高价值训练查询
- 论文辅以一个自动化流程来构建高质量的、工具增强的推理轨迹用于训练
- 对于智能体工具使用,LongCat-Flash-Thinking 在 AIME-25 基准测试上实现了 token 消耗降低 64.5%,同时保持准确性
- 对于形式化推理,论文开发了一个与 Lean4 服务器集成的专家迭代(expert-iteration)流程,以合成生成经过验证的证明,系统地灌输了大多数大语言模型所缺乏的能力
- 领域并行 RL 训练与融合方法(Domain-Parallel RL Training and Fusion Methodology) :
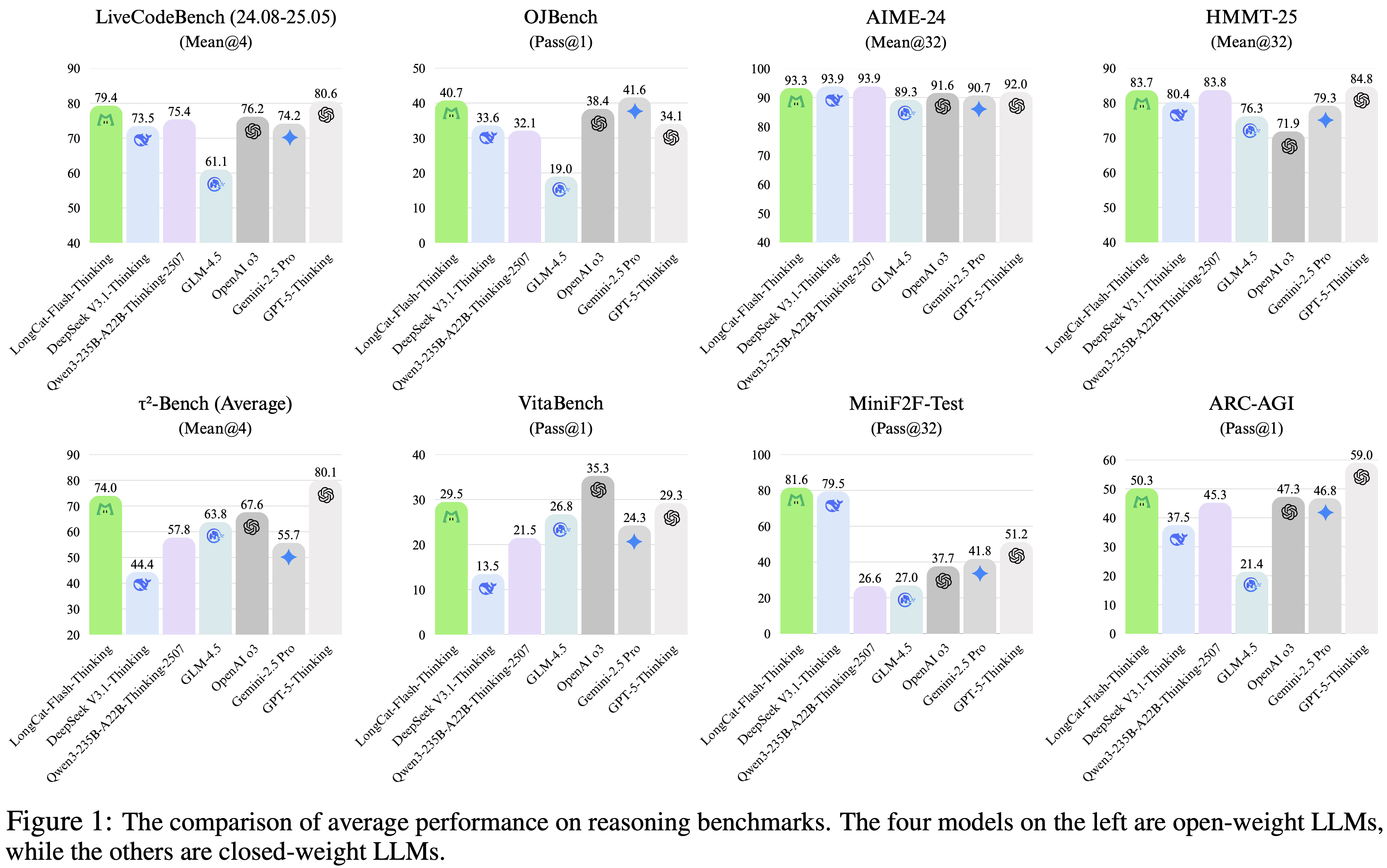
- 这些贡献最终形成了一个模型,它不仅在一系列多样化的基准测试上(图 1)实现了 SOTA 性能,而且在其开源同行中,在形式化证明和智能体推理这两个关键领域确立了明显优势
Long CoT Cold-Start Training
- LongCat-Flash-Thinking 是一个强大而高效的 LLM ,构建于论文的 LongCat-Flash-Base 模型 (Meituan, 2025) 之上
- 论文基于 LongCat-Flash-Base 进行了长思维链(Long Chain-of-Thought, Long CoT)冷启动训练和大规模 RL,为其赋予了先进的推理能力
- 得益于零计算专家 (2024) 和 shortcut-connected 的 MoE 结构 (2024),LongCat-Flash-Thinking 在达到相当性能的同时,相比其他模型具有显著的效率优势
- 在本节中,论文专注于通过多阶段课程学习方法来增强论文基础模型的长思维链推理能力 (2025)
- 首先,引入一个 mid-training阶段,在此阶段,基础模型从多样化的推理数据中学习,以增强其基础推理能力和强化学习潜力
- 随后,加入一个紧凑的有 SFT 阶段
- 除了高质量的通用推理数据外,论文特别让模型接触形式化推理(formal reasoning) 和智能体推理(agentic reasoning) 的能力,这两者都旨在有效提升推理性能
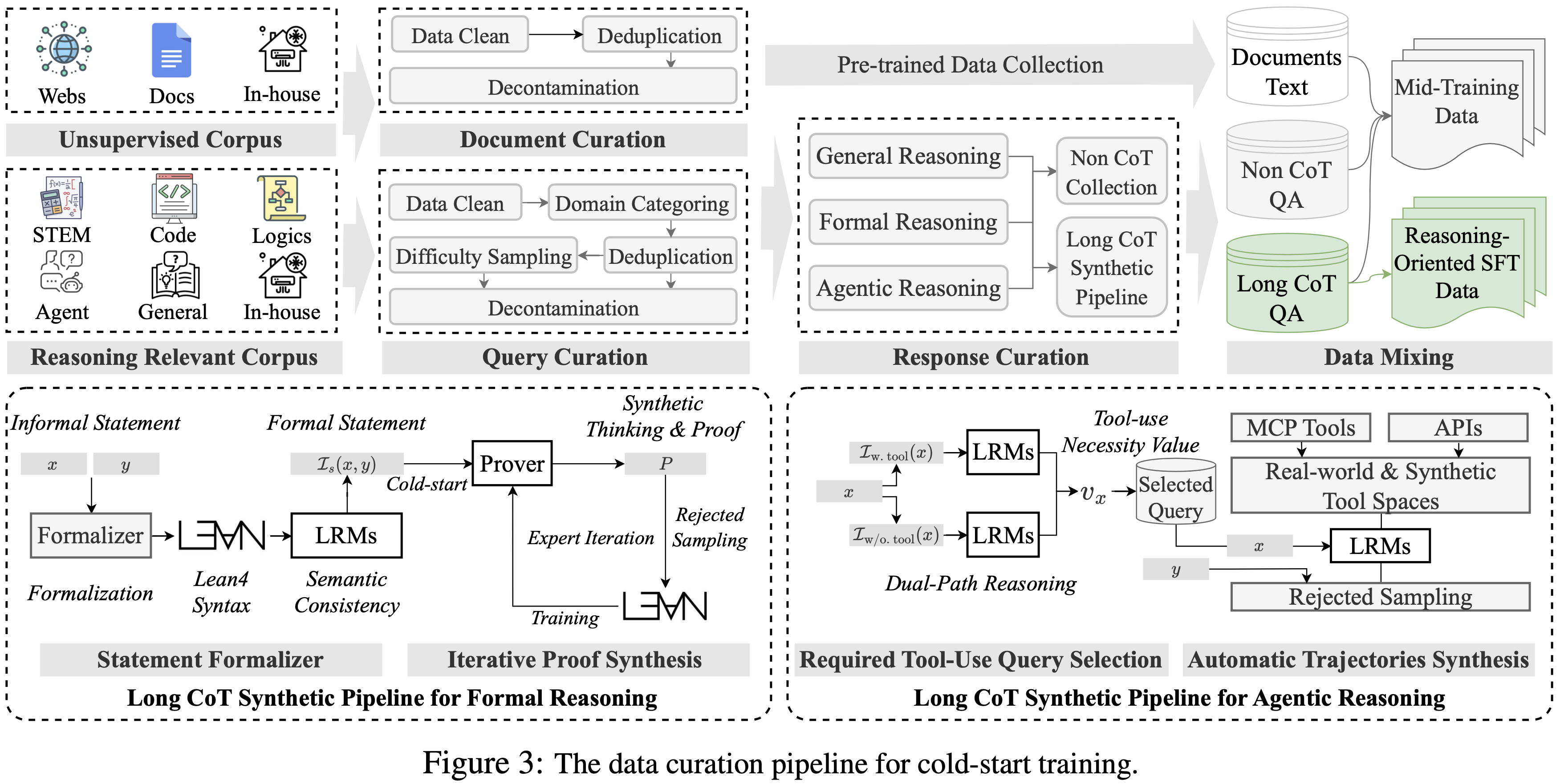
- 冷启动数据构建流程的概览如图 3 所示
Mid-training: Reasoning Capability Enhancement
- 虽然论文的基础预训练产生了一个具有强大通用能力的模型 (Meituan, 2025),但论文发现其在处理复杂推理任务方面存在一个关键局限
- 尽管对基础模型进行微调后再进行 RL 训练已显著提高了推理性能,但论文观察到这些模型通常会产生同质化的推理模式,这阻碍了它们进行深度反思并为具有挑战性的问题获得正确解决方案的能力
- 这种缺陷是双重的,源于通用预训练语料库的构成
- 首先,虽然语料库规模庞大,但其严重偏向于通用文本,导致来自 STEM(科学、技术、工程和数学)和编程等推理密集型领域的数据比例不足
- 其次,(更关键的是),明确的长思维链模式,构成了方法论推理的结构,即使在这些专业数据中也自然稀缺
- 这种双方面的数据差距阻碍了模型内在的推理潜力,为后续的微调阶段创造了显著的瓶颈
- 为了克服这一点,并受到大型推理模型(Large Reasoning Models, LRMs)中推理边界分析 (2025 Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?) 的启发,论文的方法将标准的 mid-training 阶段 (Meituan, 2025) 转变为一个精心平衡的课程
- 目标是培养模型的潜在推理能力(有效地对其进行“冷启动”),同时不降低其基础的通才知识,从而为后续的长思维链 SFT 设定一个更强的起点
Training Recipe
- 论文的课程建立在一个精心策划的数据集之上,该数据集包含跨 STEM 和编程领域的推理密集型问题
- STEM 集合:
- 包含了来自学术档案、教科书和专有数据的多样化数学、物理和化学问题,并特别强调竞赛级别的挑战以确保深度
- 论文的筛选过程优先选择需要多步逻辑推理的问题,而不是那些可以通过简单事实检索解决的问题
- 算法编程推理
- 论文汇总了来自各种开源代码竞赛数据集的问题
- 然后,这些经过筛选的数据被策略性地注入训练语料库中
- 论文采用严格的质量控制流程,使用启发式规则和 LLM-as-a-Judge 方法的混合来进行过滤、去重和去污
- 关键的是,论文仔细管理数据混合比例,平衡推理密集型数据与原始的 mid-training 数据
- 这确保了模型发展基础推理技能的同时,不降低其通才能力
- 详细的数据筛选和混合过程在附录 A.1 中提供
Evaluation
- 在正式对 LongCat-Flash-Base (Meituan, 2025) 进行训练之前,论文首先进行了一项初步实验,以验证论文推理增强 mid-training 的有效性
- 这项试点研究是在一个小规模的、内部共享相同架构的 MoE 模型上进行的
- 论文采用重复采样策略,使用 pass@k (2025, 2024) 指标来评估模型的推理能力
- 为确保该指标的无偏估计,论文遵循 Chen 等人 (2021) 提出的方法
- 形式上,给定来自查询集 \(\mathcal{D}\) 的一个查询 \(x\),令模型为 \(\pi_{\theta}\),其中 \(\theta\) 表示参数,论文生成 \(N\) (\(N>0\)) 个响应作为 \(\{y_{i}\}_{i=1}^{N}\),其中 \(y_{i}=\pi_{\theta}(x)\) 代表一个响应。因此,pass@k 定义为:
$$pass@k:=\mathbb{E}_{x_{i}\sim\mathcal{D} }\bigg{[}1-\frac{\binom{N-C_{i} }{k} }{\binom {N}{k} }\bigg{]},$$ - 其中 \(C_{i}\) (\(C_{i}\leq N\)) 表示正确答案的数量
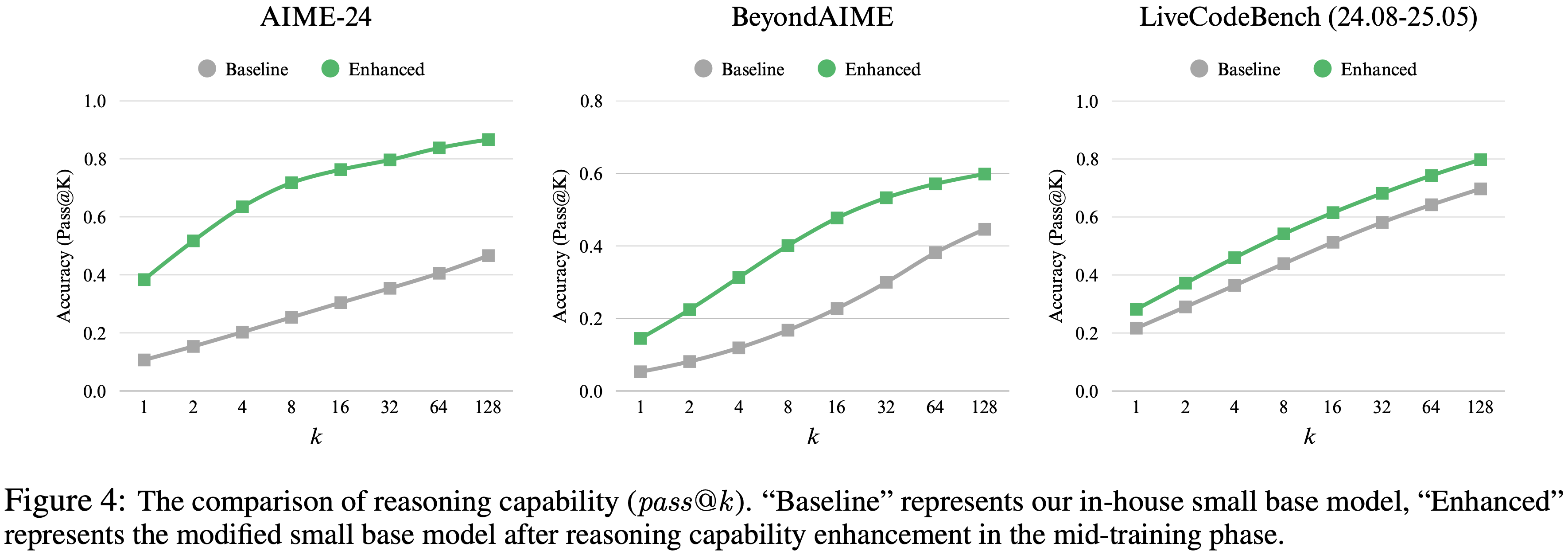
- 图 4 展示了论文在三个基准测试上的评估结果:AIME-24、BeyondAIME 和 LiveCodeBench (LCB) (24.08-25.05)
- 结果揭示了一个清晰的趋势:在 mid-training 中 ,更高比例的推理密集型数据持续提升了模型在所有指标上的推理性能 ,从 pass@1 到 pass@128
- 这种效应在所有采样复杂度上都很显著, pass@1 分数在 AIME-24 上提高了 27.7%,在 BeyondAIME 上提高了 9.3%,在 LCB 上提高了 6.5%
- 特别地,对于更高的 k 值(如 pass@64 和 pass@128 ),改进更为显著,表明这种方法有效地拓宽了模型的推理边界
- 这些令人信服的发现促使论文将此策略整合到 LongCat-Flash-Thinking 的 mid-training 过程中
Reasoning-oriented SFT
- 在 mid-training 课程(curriculum)之后,论文引入了一个面向推理的 SFT 阶段,以使模型与高质量的指令遵循模式对齐,并增强其专业推理能力,从而为后续的大规模 RL 奠定坚实的基础
- 除了通用推理,论文还专注于推进 LongCat-Flash-Thinking 在形式化推理和智能体推理方面的能力,这可以分别培养模型使用形式化语言和现实世界工具进行推理的能力
General Reasoning
- 为了增强通用推理能力,论文从多个领域策划了一个多样化、高质量的训练数据集:STEM、代码、逻辑和通用问答(QA)
- 构建过程涉及一个严格的 Prompt 筛选和响应生成流程,如下所述
- (每个领域数据处理的更多细节在附录 A.2 中提供)
- 首先,对于 Prompt 筛选,论文实施了一个多阶段过滤过程
- 1)初步筛选(Initial Screening) :论文使用 LLM-as-Judge (2025) 方法来消除低质量或无法回答的查询 ,例如不完整的陈述
- 对于代码相关数据,论文选择那些具有清晰描述、至少包含五个单元测试的健壮测试集以及可执行评判脚本的问题
- 2)真实答案验证(Ground-Truth Validation) :为了验证正确性 ,采用了基于模型的投票机制
- 这涉及自动生成多样化的响应,以识别并过滤掉那些具有不一致或可能错误的标准答案(ground truth)的 Prompt
- 3)难度过滤(Difficulty Filtering) :除了通用 QA ,论文通过专家模型的通过率(pass rate)来估计问题难度
- 通过率超过特定阈值的 Prompt 被视为过于简单而被丢弃
- 最终的 Prompt 集根据难度分布从过滤后的池中采样
- 1)初步筛选(Initial Screening) :论文使用 LLM-as-Judge (2025) 方法来消除低质量或无法回答的查询 ,例如不完整的陈述
- 其次,对于响应生成,论文采用了拒绝采样(rejection sampling)方法
- 为每个 Prompt 合成候选响应,其中 LongCat-Flash-Chat (Meituan, 2025) 作为主要的生成器
- 然后,这些候选响应通过基于规则和基于模型的判断相结合的方式进行评估,以选择最高质量的响应作为论文最终的训练数据
Formal Reasoning
- 最近像 Qwen2.5-Math (2024)、Kimina-Prover (2025a) 和 DeepSeek-Prover (2025;) 这样的模型的成功,突显了 LRMs 在加速自动定理证明(Automatic Theorem Proving, ATP)等形式化推理任务研究方面的巨大潜力
- 为了帮助实现这一潜力并赋能研究人员,论文显著增强了论文模型的形式化推理能力
- 论文的工作旨在提供一个健壮且多功能的基础,供社区在其上构建和探索新的科学前沿
- 为此,论文专注于 ATP,这是形式化推理中一个具有代表性且具有挑战性的任务
- 论文引入了一种新颖的方法来系统地增强论文模型在这一领域的能力
- 该流程如图 3 左下角所示(为方便查看,补充到下面):
Task Definition
- 形式上,ATP 的任务是:给定的形式化陈述,生成一个有效的证明 \(\mathcal{P}\)
- 该过程从一个非正式问题开始,包括一个自然语言问题 \(x\) 及其答案 \(y\)
- 这首先通过一个自动形式化器(autoformalizer)\(\mathcal{I}_{s}\) 转换为一个形式化陈述 \(s=\mathcal{I}_{s}(x,y)\)
- 然后模型 \(\pi_{\theta}\) 生成一个证明候选 \(\mathcal{P}=\pi_{\theta}(s)\)
- 验证器 \(\mathcal{V}\) 检查该证明,产生一个二元结果
$$\mathcal{V}(\mathcal{P},s)\in\{\text{PASS},\text{FAIL}\}$$ - 论文的工作专注于全证明生成(whole-proof generation) ,即从形式化陈述开始,在单轮中生成整个证明
Statement Formalization
- 论文收集了多个竞赛级别的数学问题,并进行了数据去重和去污
- 由于原始数据仅包含自然语言问题,论文训练了一个基于 8B 参数的自动形式化器(autoformalizer)模型,将每个非正式陈述(包含原始问题和答案)翻译成形式化陈述
- 然后论文执行一个两阶段过滤过程以确保其正确性:
- 1)语法过滤 :论文遵循 Wang 等人 (2025a) 的工作,开发了 Leand Server 1 (v4.15)
- 每个生成的形式化陈述都与占位符 “\(=\) by sorry” 连接,并通过 Leand Server 进行编译。因此,具有语法错误的陈述被移除
- 2)语义过滤 :论文发现自动形式化有时会改变原始问题的含义
- 为了解决这个问题,论文采用了一个基于模型的语义过滤器,以识别并丢弃与其非正式对应物不一致的形式化陈述
- 1)语法过滤 :论文遵循 Wang 等人 (2025a) 的工作,开发了 Leand Server 1 (v4.15)
Iterative Proof Synthesis
- 论文的证明合成遵循迭代数据增强策略,从一个冷启动过程开始,并通过专家迭代(expert iteration)逐步完善
- 为此,论文利用论文经过推理增强的 LongCat-Flash-Base 模型作为 Prover(证明器)的基础,该 Prover 在整个过程中得到系统性改进
- 迭代流程如下:
- 冷启动 Prover 训练 (Cold-start Prover Training) :此阶段的目标是构建一个初始数据集来训练基线 Prover
- 验证成功问题收集 :为了识别一组可解决的问题,论文利用现有的定理证明工具来过滤论文的形式化陈述
- 验证成功的陈述(statement)被保留,形成论文初始的(陈述(statement),证明(proof))对集合
- 思考过程合成 :为了用推理步骤丰富这些数据,论文采用基于模型的合成方法为每对生成一个自然语言的“思考过程(thinking process)”
- 新的三元组 :这就创建了最终的(陈述,思考过程,证明)三元组训练数据,然后用于对论文的 LongCat-Flash-Base 模型进行初始 SFT
- 验证成功问题收集 :为了识别一组可解决的问题,论文利用现有的定理证明工具来过滤论文的形式化陈述
- 专家迭代 (Expert Iteration) :此阶段迭代地扩展数据集并增强 Prover。在每次迭代中:
- 1)当前的 Prover 尝试为所有仍未解决的形式化陈述生成证明
- 2)新生成的证明经过验证,成功的(陈述,证明)对被添加到论文的数据集中
- 3)这些新的对随后使用相同的基于模型的方法,合成为一个思考过程来丰富数据
- 4)最后,论文汇总所有筛选过的训练三元组,并从头开始重新训练 Prover
- 这个自我改进的循环重复固定的迭代次数
- 冷启动 Prover 训练 (Cold-start Prover Training) :此阶段的目标是构建一个初始数据集来训练基线 Prover
- 通过这个迭代过程,论文策划了一个包含大量高质量训练实例的语料库,每个实例包含一个形式化陈述、一个合成的思考过程和一个经过验证的证明
- 该数据集随后被用来全面增强论文 LongCat-Flash-Thinking 的形式化定理证明能力
Agentic Reasoning
- 智能体推理可以体现在工具使用、解释和复杂问题解决中 (2025b, OpenAI, 2024)
- 现有的数据集常常受到一些实例的困扰,即模型可以在不实际调用工具的情况下产生令人满意的答案
- 这类数据对于现实世界的智能体行为提供的效用有限,因为它们缺乏利用外部工具解决问题的挑战
- 为了缓解这个问题,论文专注于识别和保留那些真正需要工具辅助的高质量查询 ,从而促进健壮的智能体能力的发展
Required Tool-Use Query Selection
- 为了策划一个真正需要工具使用的查询数据集,论文使用以下步骤:
- 首先,从各种来源聚合候选查询,包括开源数据集(例如 ToolBench (2023), ToolLLM (2023))和内部数据,并执行标准的去重和去污
- 然后,论文引入了一种新颖的双路径评估流程来评估每个查询的“工具必要性(tool necessity)”
- 对于给定的查询 \(x\in\mathcal{D}\),论文 Prompt 一个基线模型在两种不同的设置下生成 \(N\) 个解决方案轨迹(trajectory):
- 一种可以访问工具 \((\mathcal{I}_{\text{wt, tool} })\)
- 另一种不能 \((\mathcal{I}_{\text{w/o, tool} })\)
- 这产生了两组响应:
$$\mathcal{Y}_{\text{wt, tool} }=\{y_{i}|y_{i}=\pi_{\theta}(\mathcal{I}_{\text{wt, tool} }(x))\}_{i=1}^{N},\text{ 和 }\mathcal{Y}_{\text{w/o, tool} }=\{y_{i}|y_{i}=\pi_{\theta}(\mathcal{I}_{\text{w/o, tool} }(x))\}_{i=1}^{N}.$$
- 对于给定的查询 \(x\in\mathcal{D}\),论文 Prompt 一个基线模型在两种不同的设置下生成 \(N\) 个解决方案轨迹(trajectory):
- 接下来,这些响应由 LLM-as-a-Judge 进行评估,以分别计算 \(\mathcal{Y}_{\text{wt, tool} }\) 和 \(\mathcal{Y}_{\text{w/o, tool} }\) 的通过率 \(s_{\text{wt, tool} }(x)\) 和 \(s_{\text{w/o, tool} }(x)\)
- 工具必要性值 \(v_{x}\) 则定义为使用工具带来的性能增益:
$$ v_{x}=s_{\text{wt, tool} }(x)-s_{\text{w/o, tool} }(x) $$- 更高的 \(v_{x}\) 意味着一个查询仅凭内部知识难以解决,但在工具辅助下变得可管理(manageable)
- 假设 \(\tau_{1}\), \(\tau_{2}\), \(\tau_{3}\) 是预定义的阈值,论文根据一组阈值选择查询:
$$ \{x|v_{x}>\tau_{1}\wedge s_{\text{wt, tool} }(x)>\tau_{2}\wedge s_{\text{w/o, tool } }(x)<\tau_{3},x\in\mathcal{D}\}$$- 上述公式可以确保,最终数据集由工具有用(helpful)且必不可少(indispensable)的问题组成
- 理解:要求不使用工具时成功率低于某一水位,使用工具后成功率高于某一水位,同时增益高于一定阈值
Automatic Trajectories Synthesis
- 选择高价值查询后,论文合成相应的高质量解决方案轨迹
- 为了支持广泛的任务,论文首先构建了一个包含多样化工具 API 的多功能环境,包括 MCP 服务器以及用于单轮和多轮交互的模拟工具
- 对于每个选定的查询,论文进行以下步骤:
- 候选轨迹生成 :使用一个强大的生成模型来产生多个候选轨迹,范围从简单的工具调用到复杂的多步骤工作流
- 候选轨迹评估 :这些候选轨迹由一个基于模型的评判小组根据正确性、逻辑一致性和工具使用的完整性等标准进行严格评估
- 只有通过此评估的轨迹才会被保留
- 经过验证的轨迹随后被标准化为一致的格式,确保逻辑完整性和推理步骤的清晰性
- 轨迹分层 :论文根据复杂度对这些轨迹进行分层
- 基于诸如工具调用次数(单轮 vs 多轮)、依赖结构(顺序 vs 并行)和推理深度(例如,查找、多跳、规划)等因素,以促进基于课程的学习和有针对性的模型增强
Training Recipe
- 对于 SFT 阶段,论文采用复杂的数据筛选策略来平衡来自论文三个面向推理的数据集的多样化和复杂场景
- 该策略包括严格的数据去污协议 ,以确保在训练期间对测试数据的零暴露
- 为了进一步增强通用推理 ,论文对来自 STEM 和编程领域的数据进行了上采样(up-sampled)
- 此外,根据论文定义的几个响应行为特征(例如平均响应长度、反思密度和查询聚类)来筛选最终的训练实例
- 这种方法的目标是显著提高在广泛推理任务上的性能,同时保持在智能体工具使用和形式化证明生成等专业领域的熟练度
- 最终的数据混合比例如图 10 所示:
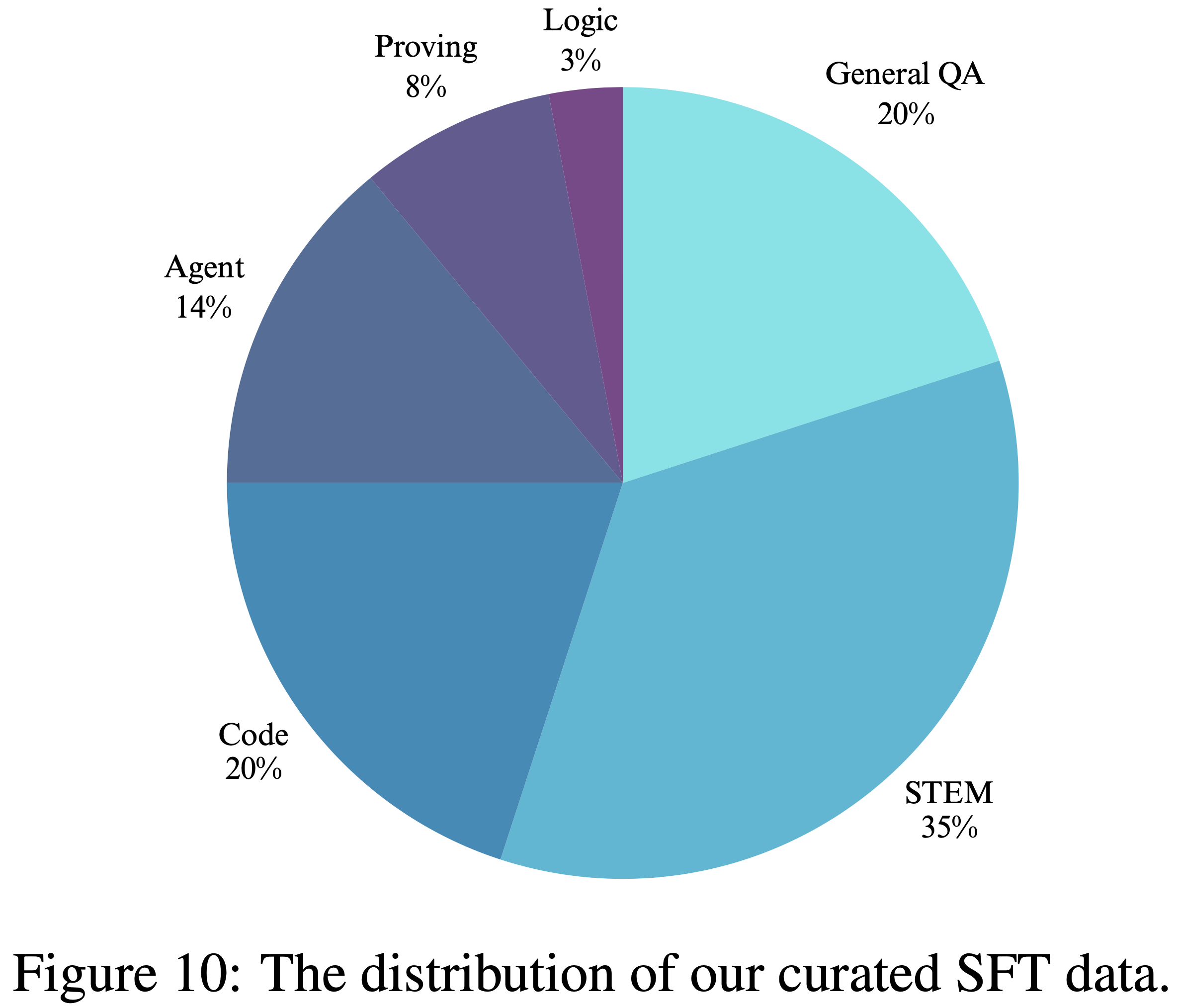
- SFT 是在论文经过 mid-training 阶段推理增强的基础模型上进行的
- 论文使用 AdamW 优化器,学习率为 \(3e-5\),并将模型训练 \(2\) 个 Epochs
- 为了适应复杂和扩展的推理链,论文将上下文长度(context length)设置为 48K 个 Tokens
Large-Scale Reinforcement Learning
- RL 是提升 LLM 推理能力的关键阶段,与 SFT 相比,它具有更高的 token 效率和更好的泛化能力
- 但将 RL 应用于 LLM 是众所周知的挑战:
- 训练过程通常不稳定,对超参数高度敏感,并且会产生巨大的系统开销,这使得工业级部署变得复杂
- 为了克服这些障碍,论文开发了一个全面的、三管齐下的解决方案:
- 1)在系统层面,论文构建了 DORA,一个支持异步训练和灵活加速器使用的鲁棒分布式 RL 框架,以确保稳定性和效率
- 2)在算法层面,论文引入了若干修改以稳定训练并增强适应性
- 3)在奖励层面,论文设计了一个能够处理可验证和不可验证任务的通用奖励系统,确保广泛的领域适用性
- 以下小节将详细介绍论文的 RL 基础设施、算法增强和奖励设计
RL Infrastructure
- RL 训练的效率受到两个主要问题的阻碍:RL 调度问题 (RL scheduling) (2023; 2024; 2025) 和偏斜生成问题 (skewed generation problem) (2025; 2025; 2025)【TODO:skewed generation 的翻译】
- 在调度问题方面:
- 分离式架构 (disaggregated architecture) 由于不同阶段之间的依赖性导致设备闲置
- 共置式架构 (colocated architecture) 通过让所有角色共享相同的设备来避免这种情况,但这种效率是有代价的
- 对于异构工作负载(其中生成是内存瓶颈,而训练是计算瓶颈),硬件的紧密耦合可能导致次优性能
- 偏斜生成问题方面:
- 问题出现:偏斜生成问题出现在同步训练中,整个批次会被单个最长的输出阻塞
- 这个问题在长上下文场景(如推理或智能体工具使用)中会加剧
- 一些异步训练方法 (2025; 2025) 已被提出来优化长尾生成问题
- 如部分 rollout (partial rollout),将长响应分解成多个片段,并利用最新的 Actor 模型在不同迭代中生成每个片段
- 然而,论文在实践中观察到中断样本的重新预填充 (re-prefilling) 效率相当低下
- 使用最新更新的 Actor 模型需要在将中断样本与之前不完整的 rollout 响应连接后进行所有中断样本的重新预填充
- 此外,对单个响应的不同片段使用不一致的策略版本在理论上可能损害模型收敛
- 如部分 rollout (partial rollout),将长响应分解成多个片段,并利用最新的 Actor 模型在不同迭代中生成每个片段
- 问题出现:偏斜生成问题出现在同步训练中,整个批次会被单个最长的输出阻塞
- 在调度问题方面:
DORA:Dynamic ORchestration for Asynchronous rollout
- 为了解决上述挑战,论文引入了论文的 DORA 系统
- DORA 系统的核心思想是通过流式 rollout (streaming rollout) 利用多个旧版本的 Actor 模型来优化长尾生成,同时保持采样一致性
- 为了进一步提高调度效率并在没有设备闲置的情况下并行化生成和训练阶段,论文引入了 RL 角色的弹性共置 (elastic colocation)
- 如图 5 所示,DORA 采用分离式架构,将加速器集群划分为两个不同的组:
- 独立生成器组 (Standalone Generator Group) :一个专门用于生成器 (Generator) 角色的设备池,确保优化的 rollout
- 生成器是专门用于推理的 Actor 模型的副本
- 弹性角色组 (Elastic Role Group) :一个角色可以弹性共置的设备池,以确保灵活性和效率
- 这些设备可以动态地在充当生成器和执行各种训练相关角色(例如, Reference & Actor , Reward & Critic )之间切换
- 图 5 :DORA 系统演示时间线中的陈旧性 (staleness) 设置为 2,允许最多三个策略权重 \(\theta_{j}\)(注意:这里有多个策略版本在内存中,之前用旧策略生成的样本,接下来也继续用旧策略 rollout,保证了生成的样本是同一个策略产生的)
- 在第 \(n\) 步, Prompt 5, 8, 3, 1, 6, 和 2 被依次完成
- Prompt 2 的完成填充了批次,然后用于训练
- Prompt 10 和 12 被丢弃并安排重新生成(理解:这两个 Prompt 大于一定轮次了)
- 剩余的 Prompt 使用 KV 缓存重用或转移继续 rollout
- 注:图 5 中 KV-Cache Transfer 是指复用之前的 KV-Cache(对于上一轮没有生成完成的 Prompt),而且这里看起来应该是不丢弃之前轮次生成的模型的情况
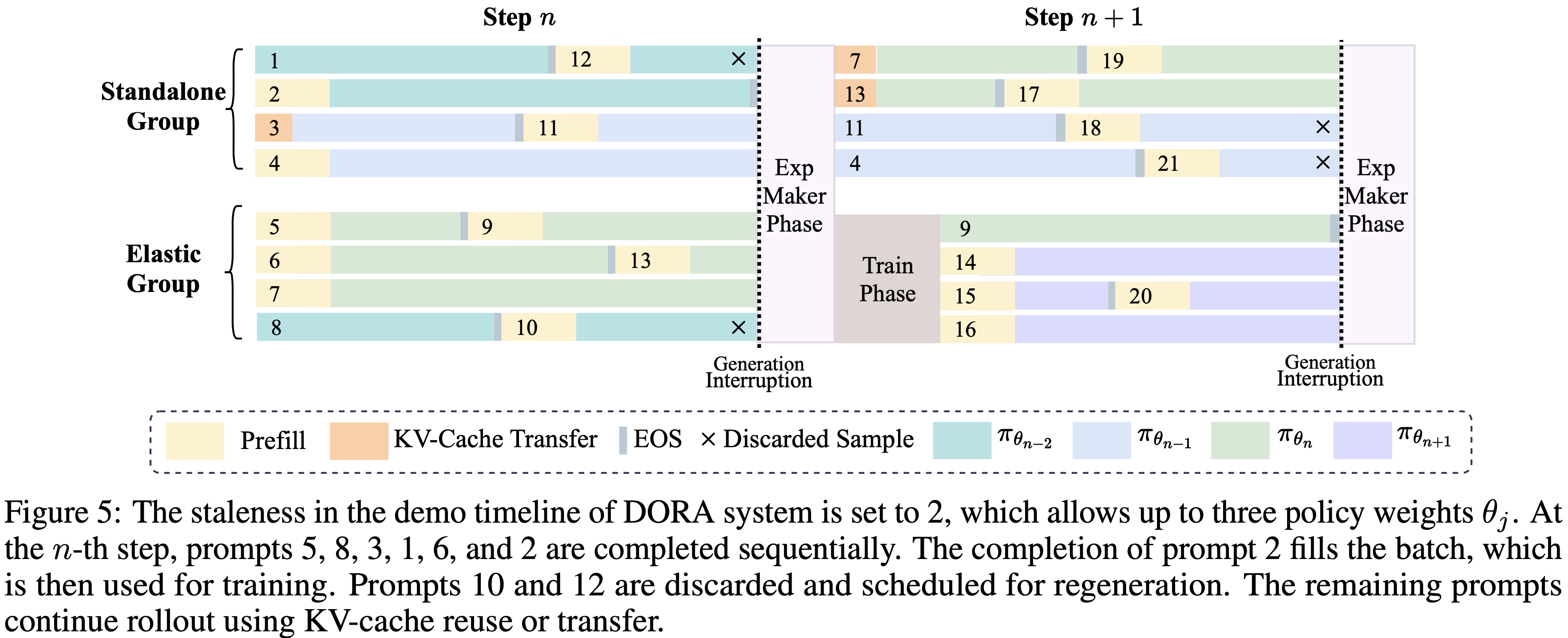
- 独立生成器组 (Standalone Generator Group) :一个专门用于生成器 (Generator) 角色的设备池,确保优化的 rollout
- 基于论文为异步 rollout 设计的资源调度,论文介绍 DORA 系统的工作流程如下:
- 生成阶段 (Generation Phase)
- 为了提高 rollout 吞吐量,论文扩展生成器设备,独立组和弹性组都激活推理引擎进行 rollout
- 推理实例维护最多预定义陈旧性数量的策略权重版本
- 注意:这里有多个策略版本在内存中,保证了生成的样本是同一个策略产生的
- 在 rollout 阶段,论文的负载均衡控制器 (Load Balancing Controller) 重新平衡不同策略版本之间的资源分配,并在推理引擎内重用 KV 缓存,如图 6 所示
- 关键的是,已完成的样本会立即流式传输到下一阶段,而不会阻塞后续阶段
- 经验制作阶段 (Experience-Maker Phase)
- 一旦生成的样本满足训练条件,弹性组会缩减其生成器角色,并激活其他 RL 角色
- 在部分共置(partial colocation)设置中:
- Reference & Actor 以及 Reward & Critic 角色并行执行推理阶段
- 同时独立生成器(Standalone Generators)暂时切换到训练引擎以重新计算对数概率
- 问题:独立生成器也能切换训练引擎计算对数概率?那为什么还叫做独立生成器?
- 这是最小化推理和训练引擎之间系统级不匹配的关键步骤
- 完成后,独立组重新激活推理引擎,并使用先前的策略版本继续生成
- 模型训练阶段 (Model Training Phase) 最后,Actor 和 Critic 模型在收集的经验上进行训练。同时,独立组继续无阻塞地生成,同时重新平衡工作负载和重新分配资源。值得注意的是,特定的策略版本一旦满足用户定义的驱逐策略就会被删除。训练完成后,最新的策略权重使用分层点对点 (layer-wise Point-to-Point) 通信有效地同步回生成器角色,为下一轮 RL 训练做准备
- 生成阶段 (Generation Phase)
- 图 6 :负载均衡的工作流程。负载均衡控制器监控每个设备上的负载,当达到预定义阈值时,它启动资源重新分配,包括权重转移和 KV 缓存转移
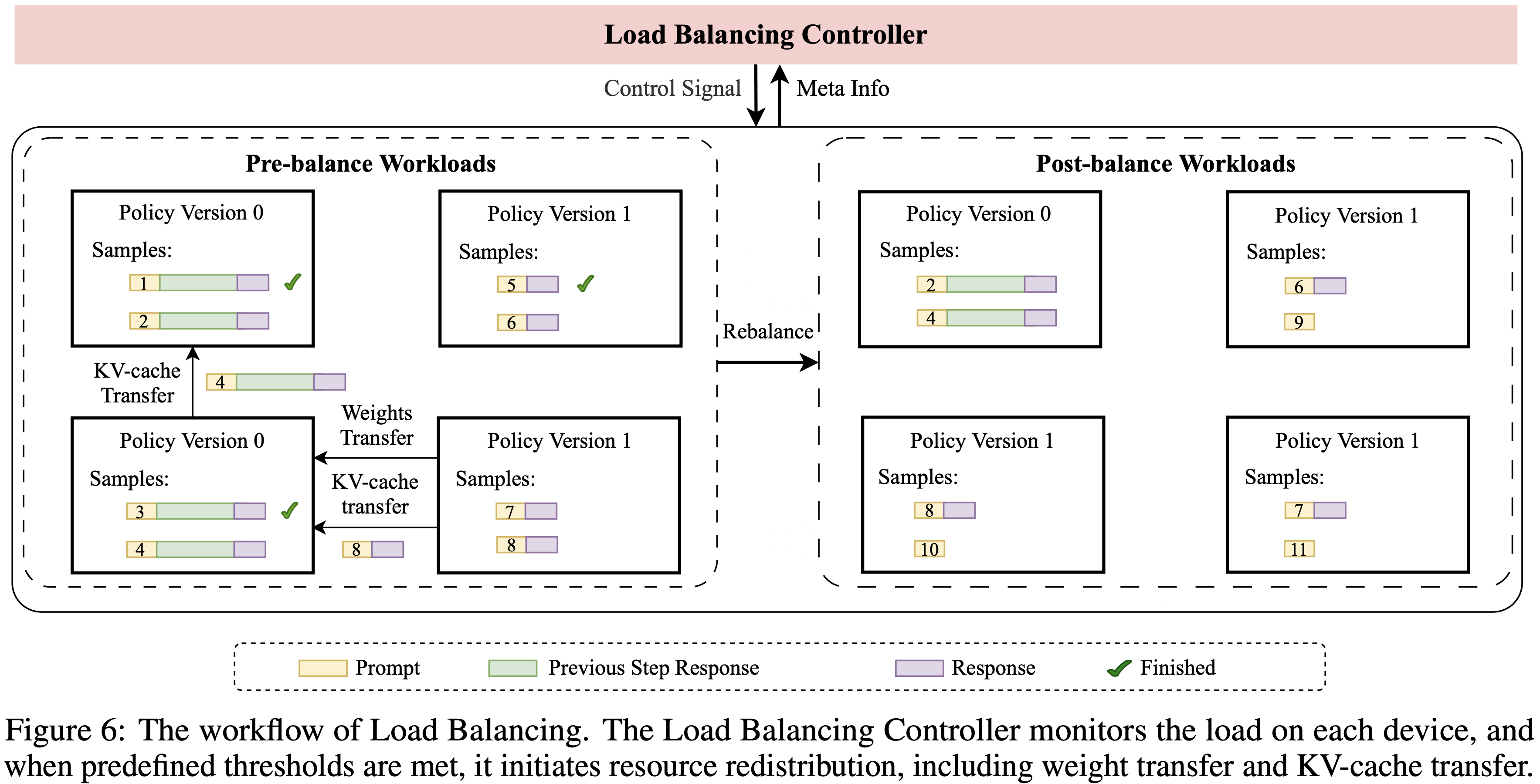
- DORA 的主要优势总结如下:
- 1)流式架构确保首先完成的响应可以立即在后续阶段处理,而不会被最长的响应阻塞
- 2)多版本设计保证每个响应完全由同一个 Actor 模型生成直至完成 ,消除了片段之间的不一致性
- 这也使得可以轻松地重用中断样本的 KV 缓存,以显著减少开销,尤其是在预填充 (prefill) 繁重的场景中
- 3)论文的弹性共置策略通过进程内上下文切换和卸载,实现了近乎零的设备闲置气泡 (bubbles)
- 它还通过允许灵活地将加速器的数量和类型分配给不同的工作负载,保留了分离式架构的优势
Optimization for Large-Scale Training
- 为了在论文的 DORA 系统上实现跨数万个加速器的工业级 RL 训练,论文引入了几个关键的工程优化
- 大规模流式 RPC (Massive Streaming RPC)
- 论文系统的控制平面建立在 PyTorch RPC (2023) 之上,它提供了为张量优化的远程过程调用
- 它减少了张量的大量序列化和反序列化成本,并允许对计算集群进行专用和灵活的控制
- 为了实现大规模 RPC 能力,论文在 RPC 初始化期间通过额外的组键原语 (group-key primitives) 和数据压缩增强了 TCPStore 实现,将通信复杂度从 \(O(N^{2})\) 降低到 \(O(N)\)
- 在运行时,论文引入了双向流式 RPC(与 PyTorch 中的一元 RPC 不同),这使得推理引擎在异步训练期间能够进行高性能流式 rollout
- 大规模高效 MoE 并行 (Efficient MoE Parallelism at Scale)
- 为了在论文的加速器上部署 LongCat-Flash,论文在生成时采用了高度专家并行 (expert parallelism)
- 该策略不仅分布了计算负载,还增加了每个加速器的可用内存,这对于容纳长上下文任务所需的大 KV 缓存至关重要
- 但随着专家并行规模的增加,跨分布式加速器保持同步通常受限于主机端内核启动开销,这可能导致执行不同步
- 为了解决这个问题,论文采用图级编译 (graph-level compilation) 方法来减少内核分发频率 (2024),从而能够应用图级优化并有效地重叠通信与计算
- 与标准的即时执行 (eager execution) 相比,该策略实现了 \(1.5\times\) 的 rollout 加速
- 最终,DORA 架构和大规模优化的结合展现了卓越的性能和工业级能力
- 与同步训练相比,为论文的 560B LongCat-Flash 模型在数万个加速器上实现了超过三倍的加速
RL Algorithm
Training Objective
- 论文的 RL 算法是基于 DORA 系统开发的
- 论文将 \(\pi\) 表示为由 \(\theta\) 参数化的自回归语言模型
- 给定来自训练集 \(\mathcal{D}\) 的查询 \(x\),响应 \(y\) 的似然表示为
$$ \pi_{\theta}(y|x)=\prod_{t=1}^{|y|}\pi_{\theta}(y_{t}|x,y_{ < t})$$- 其中 \(|y|\) 表示响应 \(y\) 的长度
- 使用从行为策略 \(\pi_{\mu}\) 生成的样本,GRPO (2024) 通过以下目标在具有组级优势 (group-level advantages) 的信任区域内优化策略模型:
$$
\mathcal{J}_{\text{GRPO} }(\theta)=\mathbb{E}\underset{\begin{subarray}{c}\{y_{i} \}_{i=1}^{G}\sim\pi_{\mu}(\cdot|x)\end{subarray} }{\overset{x\sim\mathcal{D} }{\pi_{\theta}(y_{i,t}|x,y_{i,<t})} }\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|y_{i}|}\sum_{t=1}^{|y_{t}|}\left(\min\left(r_{i,t}(\theta)\hat{A}_{i,t},\text{clip }_{\varepsilon}\left(r_{i,t}(\theta)\right)\hat{A}_{i,t}\right)-\beta\mathbb {D}_{\text{KL} }[\pi_{\theta}||\pi_{\text{ref} }]\right)\right], \tag{3}
$$- 其中:
- \(r_{i,t}(\theta)=\frac{\pi_{\theta}(y_{i,t}|x,y_{i,< t})}{\pi_{\mu}(y_{i,t}|x,y_{i,< t})}\) 是重要性权重
- clip\({}_{\varepsilon}\) 是将值裁剪到 \([1-\varepsilon,1+\varepsilon]\) 的函数
- \(\epsilon\) 定义了裁剪范围
- \(\hat{A}_{i,t}\) 是估计的优势 (advantage)
- \(G\) 表示来自同一查询的样本组
- \(\pi_{\text{ref} }\) 是 SFT 模型
- 其中:
- 但当这个目标应用于复杂推理场景中的异步训练时,由于分布漂移 (distribution drift),它面临着显著的挑战,这可能会破坏模型的收敛并导致其迅速崩溃。这种现象可以分为两个不同的来源:
- 引擎数值差距 (Engine Numerical Gap) :
- 为了实现高吞吐量和数据效率,作者使用高度优化的推理引擎(例如 vLLM (2023))生成样本
- 但这些引擎使用了如内核融合 (kernel fusion) 等优化,这些优化不能保证比特级一致性 (bitwise consistency)
- 当推理和后端训练(例如 Megatron 引擎 (2019))不匹配时,这种不一致性尤其关键
- 问题:为什么 内核融合 不能保证比特级一致性
- 回答:Kernel Fusion 会改变计算的 “实现细节”,但不改变 “数学逻辑”,而浮点计算的特性决定了 “实现细节差异” 会导致二进制结果不同
- 虽然可以在策略优化期间使用推理引擎的采样概率作为 \(\pi_{\mu}\),但由此后端不匹配累积的数值误差可能导致不稳定性
- 策略陈旧性 (Policy Staleness) :
- 在异步训练中,每个生成的样本可能源自多个先前的策略版本,这些版本随着当前策略 \(\pi_{\theta}\) 的持续更新而变得过时
- 生成数据的行为策略与正在优化的目标策略之间的这种差异给训练过程带来了不稳定性,阻碍了收敛,并在极端情况下可能导致模型崩溃
- 像公式 3 这样的标准目标假设高度的策略对齐,对这些偏差并不鲁棒,陈旧性的影响会损害其有效性
- 引擎数值差距 (Engine Numerical Gap) :
- 为了缓解上述问题,论文通过以下改进修订了 GRPO 目标:
- 原始的 GRPO 损失包含一个 KL 散度损失项,以防止策略偏离 Reference Model 太远
- 但使用默认的 \(k_{3}\) 估计器,尽管其期望是无偏的,但该项的相应梯度在优化过程中是有偏的 (Zang, 2025)
- 因此,论文移除了 GRPO 损失中的 KL 损失项 ,这有助于进行大幅度的策略更新
- 论文采用 Token-level 损失,而不是 Sample-level 损失,以增强训练的稳定性和模型的最终性能
- 同时,遵循 Liu 等 (2025, Dr.GRPO) 的方法,论文在训练期间使用全局常数最大生成长度作为损失函数的分母(虽然损失函数公式上没有写,但 Dr.GRPO 4.2 节中的实现细节是这样做的)
- 这种调整减轻了可能对训练鲁棒性构成挑战的长度偏差 (length bias)
- 理解:这里指的 Token-level 的损失就是 Dr.GRPO 对应的损失,而 Sample-level 的损失就是原始 GRPO 对应的损失
- 设置裁剪范围对于有效的策略优化至关重要,因为它影响探索和模型稳定性
- 此外,由于专家路由策略可能在不同版本的策略之间发生变化,陈旧性问题在稀疏 MoE 模型中可能更加明显,其中负的 Token-level 优势可能导致过大的重要性采样比率和无界的方差
- 遵循 Yu 等 (2025) 和 Ye 等 (2020),论文采用三重裁剪方案 (triplet clipping scheme):
- \(\epsilon_{\text{neg}_{\text{low} } }\) 和 \(\epsilon_{\text{neg}_{\text{high} } }\) 限制负优势的重要性比率
- \(\epsilon_{\text{pos}_{\text{high} } }\) 为正优势提供上限
- 该策略防止模型崩溃并保持足够的熵以进行有效探索
- 问题:这里的 triplet clipping scheme 可以再思考一下,负优势给上下界,正优势只有上界
- 理解:
- 相当于当优势为正时,无论概率比例多小,都允许其增大(符合预期,可以理解);
- 但当优势为负时,不允许比值过小的继续下降,能理解;比值过大为什么不允许继续下降?是因为此时多是异常比值吗?
- 理解:
- 引擎数值差距会在 RL 训练过程中累积,从而使整个训练过程不稳定
- 论文应用截断重要性采样 (truncated importance sampling) (2025; Ionides, 2008) 来减轻推理引擎和训练引擎之间的分布不匹配
- 问题:这里的 truncated importance sampling 是指什么?博客地址:Your efficient rl framework secretly brings you off-policy rl training, August 2025
- 回答:这里 truncated importance sampling 主要是用 重要性采样的思想,对齐 推理(vLLM) 和 训练(FSDP)之间的 分布差异:
$$ \mathbb{E}_{a \sim \color{red}{\pi_{\text{vllm}}}(\theta)} \Bigl[\underbrace{\min\Bigl(\frac{\color{blue}{\pi_{\text{fsdp}}}(a, \theta)}{\color{red}{\pi_{\text{vllm}}}(a, \theta)}, C\Bigr)}_{\text{truncated importance ratio}} \cdot R(a) \cdot \nabla_\theta \log \color{blue}{\pi_{\text{fsdp}}}(a, \theta)\Bigr] $$ - 问题:为什么取 min 而不是 clip ?
- 回答:这里 truncated importance sampling 主要是用 重要性采样的思想,对齐 推理(vLLM) 和 训练(FSDP)之间的 分布差异:
- 原始的 GRPO 损失包含一个 KL 散度损失项,以防止策略偏离 Reference Model 太远
- 最终目标可以表述如下:
$$
\mathcal{J}(\theta)=\mathbb{E}_{\begin{subarray}{c}x\sim\mathcal{D}, \{y_{i}\}_{i=1}^{G}\sim\pi_{\mu}(\cdot|x)\end{subarray} } \left[\frac{1}{G\cdot T_{\max} }\sum_{i=1}^{G}\sum_{t=1}^{\lvert y_{i}\rvert}\min\left(r_{i,t}(\mu),C \right)\right. \max\left(\min\left(r_{i,t}(\theta)\hat{A}_{i,t}, \operatorname{clip}\left(r_{i,t}(\theta), 1-\varepsilon_{\text{neg}_{\text{ low} } },1+\varepsilon_{\text{pos}_{\text{high} } })\hat{A}_{i,t}\right),\varepsilon_{\text{neg}_{\text{high} } }\hat{A}_{i,t}\right)\right],
$$- 其中:
- \(T_{\max}\) 是最大生成长度
- \(r_{i,t}(\mu)=\frac{\pi^{\text{train} } }{\pi^{\text{inference} }_{\mu} }\) 是在采样策略 \(\mu\) 下训练引擎和推理引擎之间的重要性比率
- \(C\) 是一个常数值
- 其中:
Efficient Training Strategies
- 为了更好地平衡有效性和效率,同时保持稳定性并避免 Reward Hacking,论文还利用了其他技术:
- 带替换的在线过滤 (With-replacement Online Filtering)
- 论文在流式生成阶段采用在线过滤来移除准确率分数等于 \(1\)(完全正确)或 \(0\)(完全错误)的 Prompt
- 保留那些具有持续挑战性难度、能提供有效梯度信号以防止大幅梯度波动的样本
- 为了 确保数据至少被消费一次 (consumed-at-least-once) 和完整性 (integrity) (2024),论文为训练开发了一种带替换采样 (sampling-with-replacement) 策略
- 不同于动态采样 (dynamic sampling) 中使用的无替换采样 (sampling-without-replacement) (2025)
- 在同步训练场景中,该机制使得过采样(over-sampling)的 Prompt 可以在每个训练步骤重新生成
- 理解:允许故意的数据重复(过采样),每个样本至少使用一次
- 在异步训练场景中,如果 Prompt 的陈旧性未超过最大陈旧性阈值,则重用它们;否则,重新生成它们
- 问题:这里的确保数据至少被消费一次,不是训练一次吧,是否跟准确性无关?
- 论文在流式生成阶段采用在线过滤来移除准确率分数等于 \(1\)(完全正确)或 \(0\)(完全错误)的 Prompt
- 陈旧性控制 (Staleness Control)
- 在流式 Pipeline 中,论文应用最大陈旧性作为中断策略的一部分,以保持生成样本的可控新鲜度
- 为了提高样本效率,论文应用数据重用策略(data reuse strategy) ,其中在线过滤器(online filter)的过采样(oversampled data)数据存储在回放缓冲区 (replay buffer) 中,并在后续训练迭代中根据预定义的重用比率 (reuse-ratio) 重新采样
- 问题:为什么 online filter 会有 过采样数据?
- 该机制将这些陈旧样本(stale samples)缓存在回放缓冲区(replay buffer)中,允许它们在后续训练迭代中按比例与新样本混合
- 同时,需要对这个混合训练批次进行 shuffle,以稳定缓冲区(buffer)内的训练陈旧性
- 尽管该策略不可避免地增加了平均陈旧性,但样本效率的提升证明这是一种有效的权衡
- 不完整信号掩码 (Incomplete-Signal Masking)
- 论文对存在评分问题的样本应用掩码策略 ,例如代码评估期间的沙箱执行错误
- 这确保了奖励信号的可靠性,产生了略有偏差但低方差的梯度
- 问题:偏差来源于哪里?来源于这部分样本不参与训练,相当于有选择的丢弃了一些样本,导致训练梯度有偏
- 理解:即将这部分评估存在问题的样本的损失 mask 掉,不参与模型更新(问题:与 K2 策略是相似的吗?)
- 这确保了奖励信号的可靠性,产生了略有偏差但低方差的梯度
- 论文还对那些达到生成 token 长度但未被识别为重复的样本进行掩码
- 这有助于防止损失受到因长度限制而被截断的输出影响,进一步提高了训练信号的稳定性
- 问题:目前是如何识别重复的?
- 论文对存在评分问题的样本应用掩码策略 ,例如代码评估期间的沙箱执行错误
- 带替换的在线过滤 (With-replacement Online Filtering)
Reward System
- 为了训练 LongCat-Flash-Thinking,论文开发了一个精心设计的奖励系统(奖励系统对于在训练过程中提供优化方向至关重要),使用不同的 Reward Model 为不同的任务提供准确的奖励信号
Non-Verifiable Tasks
- 对于不可验证的任务,如创意写作、知识问答等,采用判别式 Reward Model (discriminative reward model) 来提供奖励信号
- Reward Model 训练:基于 LongCat-Flash SFT 检查点对其进行初始化(模型 size 大小相同?),随后在一个全面的人工和模型联合标注的偏好数据集上对其进行训练
- 这种方法使判别式 Reward Model 能够准确捕捉不同响应之间的偏好
- 对于长思维链 (long CoT) 响应,论文不将推理过程作为输入;
- 即 Reward Model 仅评估答案部分
Verifiable Tasks
- 对于 STEM 领域 ,论文开发了一个带有推理过程的生成式 Reward Model (Generative Reward Model, GenRM),而不是使用基于规则的奖励系统,在训练过程中提供奖励信号 (2025)
- 给定问题,GenRM 将参考答案与 LLM 的响应进行比较,并确定响应是否正确(理解:这里是通过 Prompt 来问询模型的,这是 生成式 RM 与 判别式 RM 的区别)
- 使用带有推理过程的 GenRM 有几个优点
- 首先,GenRM 适应具有相同含义的各种答案表达方式,例如 \(a^{2}-b^{2}\) 和 \((a+b)(a-b)\)
- 同时,GenRM 能够处理复杂的表达式
- 此外,带有推理过程的 GenRM 不仅提供预测,还揭示了预测背后的原因
- 推理过程使论文能够持续改进 GenRM
- 论文在一个人工标注的测试集上比较了不同 Reward Model 的有效性:
- 一个基于规则的奖励方法
- 一个直接输出 True 或 False 的非推理 GenRM
- 一个包含推理过程的 GenRM
- 表 1 展示了这些模型的预测准确率,证明了论文 GenRM 方法的有效性
基于规则的 Reward Model 非推理 GenRM 推理 GenRM (Ours) 80.9% 94.0% 98.8%
- 论文在一个人工标注的测试集上比较了不同 Reward Model 的有效性:
- 对于编码任务 ,开发了一个分布式代码沙箱集群 ,以高效管理超过 20 种编程语言的数百万并发代码执行
- 为了处理来自异步 RL 的可变工作负载,论文设计了一个异步接口来处理大批量代码,通过消除恒定轮询(constant polling)显著提高了吞吐量
- 论文还通过一次编译多运行执行 (once-compilation for multi-run executions) 来优化效率以减少开销,并通过压缩和缓存分片 (cache sharding) 确保快速可靠的数据传输和存储
Training Recipe
- 论文的 RL 训练方案遵循一个结构化的三阶段方法,旨在培养高级推理能力,包括:
- 1)领域并行训练 (Domain-Parallel Training) :专家模型在针对不同领域(例如 STEM、代码、智能体)精心策划的数据集上独立训练;
- 2)模型融合 (Model Fusion) :一种将这些专家整合成一个单一的、连贯的智能体并巩固其技能的新技术;
- 3)通用 RL 微调 (General RL Fine-Tuning) :一个最终阶段,用于协调模型的能力并确保在各种应用中的鲁棒性能
Reasoning-oriented RL: A Domain-Parallel Approach
- 在大规模 RL 中,论文观察到领域混合训练 Pipeline 通常会在异步训练中导致负迁移 (negative transfer),从而导致效率低下和次优性能
- 论文将此归因于训练批次之间显著的分布偏移 ,这是由跨领域的响应特征变化引起的(如图 7 所示)
- 虽然顺序训练(即一次优化一个领域)可以部分缓解这个问题,但它本质上是低效且不灵活的
- 一旦后期训练阶段开始,就很难重新访问或改进早期领域的能力
- 因此,论文引入了一个领域并行训练框架
- 这种方法:1)首先为不同的推理领域训练单独的“专家”模型;2)然后将它们合并成一个单一的、强大的模型,该模型在所有专业领域实现近乎帕累托最优 (Pareto-optimal) 的性能;3)最后通过一个通用 RL 阶段,以确保广泛的能力和对齐
- 这个整体流程如图 2 所示
- 图 7:
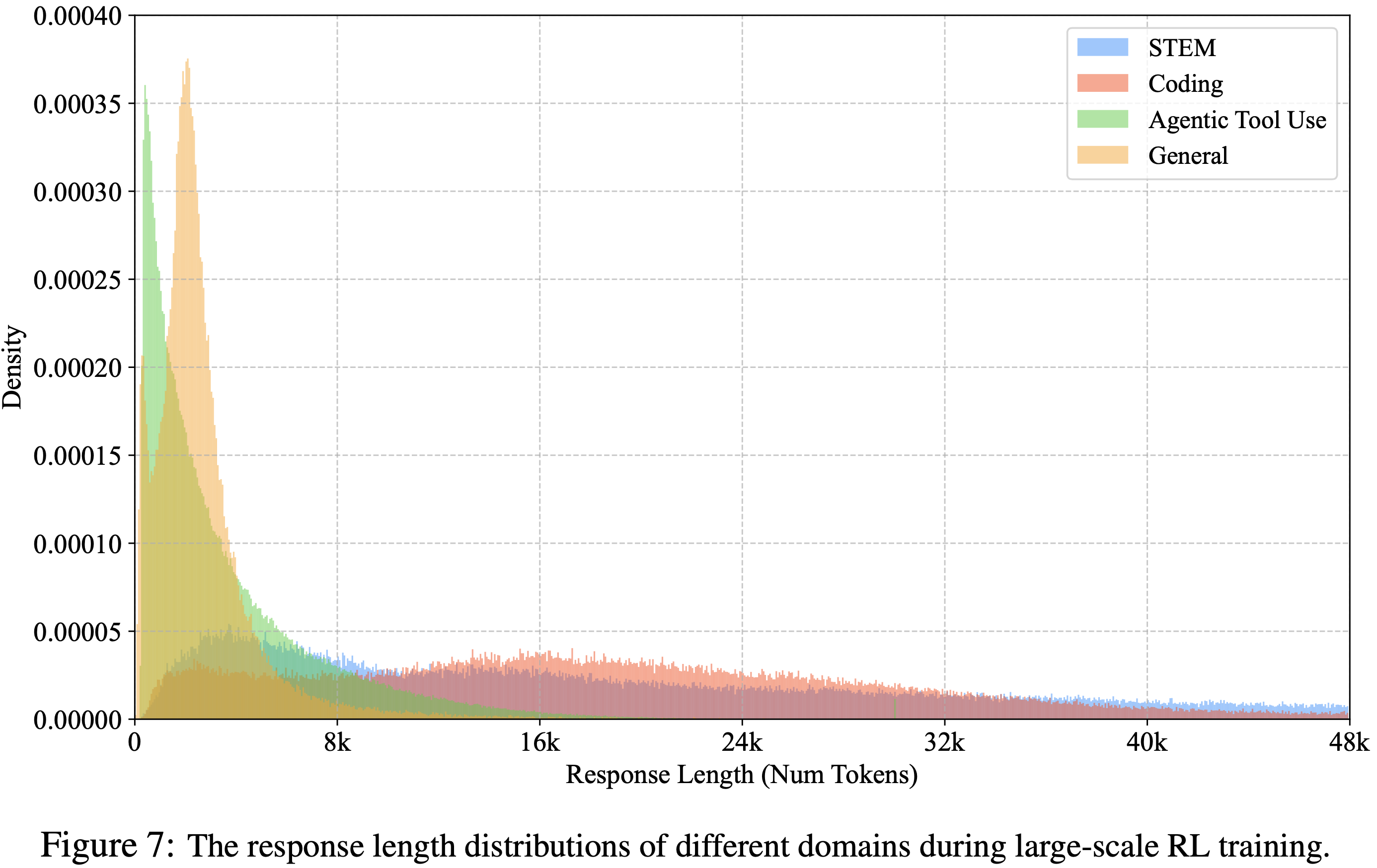
Query Curation for RL
- 为了为 RL 阶段提供高质量数据,论文为每个推理领域实施了一个严格的、多方面的策划协议(multi-faceted curation protocol)
- 对于 STEM 和代码 Query ,该协议首先针对已知基准进行标准去污和去重
- 论文通过排除不合适的格式(例如多部分、多项选择或真/假问题)进一步优化 STEM 数据集
- 对于代码 Query ,测试用例被系统地重新格式化为标准化的输入-输出结构以确保兼容性
- 随后对两个领域应用一个关键的过滤步骤以防止奖励信号偏差:
- 使用一个 SFT 模型,论文为每个 Query 生成多个响应 ,并仅保留那些表现出正确和错误解决方案平衡分布的实例
- 这避免了过于简单(全部正确)或不可能困难(全部错误)的问题,从而提高了训练效果
- 特别是对于代码,论文还利用沙箱执行反馈来识别和删除可能导致假阴性 (false negatives) 的模糊问题或不匹配的测试用例
- 随后对两个领域应用一个关键的过滤步骤以防止奖励信号偏差:
- 对于智能体 RL ,论文策划了一个专注于需要复杂推理和工具应用的数学问题的专门数据集
- 每个训练实例被构造为一个三元组,包含问题描述、参考答案和附带的评分标准 (grading rubric)
- 这种详细的结构旨在有效地指导模型学习解决复杂任务的适当工具使用轨迹
- 问题:这里仅仅是 数学问题吗?为什么工具使用的 agentic RL 训练要限制在数据问题上
Domain-Parallel Training
- 论文领域并行方法的一个关键优势是能够根据每个推理领域的独特特征定制训练方法
- 论文为 STEM、代码和智能体 RL 应用了不同的配置以最大化它们各自的优势:
- STEM RL:
- 训练过程使用固定的 64K 上下文长度
- 通过逐渐增加数据难度(通过降低包含的通过率阈值)来实施课程学习策略
- 动态地调整 PPO 裁剪边界 \(\varepsilon_{\text{pos}_{\text{high} } }\) 以保持训练稳定性
- 这些方法保证了模型的学习以高效的方式进行,同时无缝适应训练数据日益增长的复杂性
- 代码 RL:
- 对上下文长度采用多阶段课程,从 48K token 开始,然后逐步扩展到 56K,最终达到 64K
- 一旦生成输出长度的 \(TP-90\) 分位数接近当前限制,就扩展上下文窗口,确保平滑适应
- 理解:有 10% 超过当前限制长度则开始扩展
- 智能体 RL:
- 训练过程使用固定的 48K 上下文长度
- 通过两种技术强制执行结构化推理和工具使用:
- 1)使用 <longcat_think> 和 <longcat_tool_call> 标签的结构化对话模板
- 2)激励语法正确工具使用的工具调用格式奖励,确保稳定和可解释的多轮轨迹
- STEM RL:
Model Fusion
- 为了巩固论文领域专家模型的能力,论文将它们的参数合并成一个单一的、统一的智能体
- 这种方法得到了先前工作 (2023, 2025) 的支持,这些工作表明合并领域特定模型可以产生一个具有卓越整体性能的单一模型
- 模型融合的主要挑战是减轻专家之间的参数干扰 (parameter interference)
- 为了解决这个问题,论文采用了受最新进展启发的三管齐下策略:
- 1)归一化 (Normalization) :论文对任务向量 (\(\tau_{i}=\theta^{i}_{RL}-\theta_{SFT}\)) 的幅度进行归一化,以平衡来自不同领域的贡献
- 2)Dropout :类似于 DARE (2024a),论文应用 Dropout 来修剪冗余的 delta 参数
- 3)擦除 (Erase) :受 SCE (2024) 的启发,论文擦除具有少数方向更新的参数元素
- 这种融合策略构建了一个在数学推理、编码和智能体能力方面表现出色的单一模型,如图 8 所示
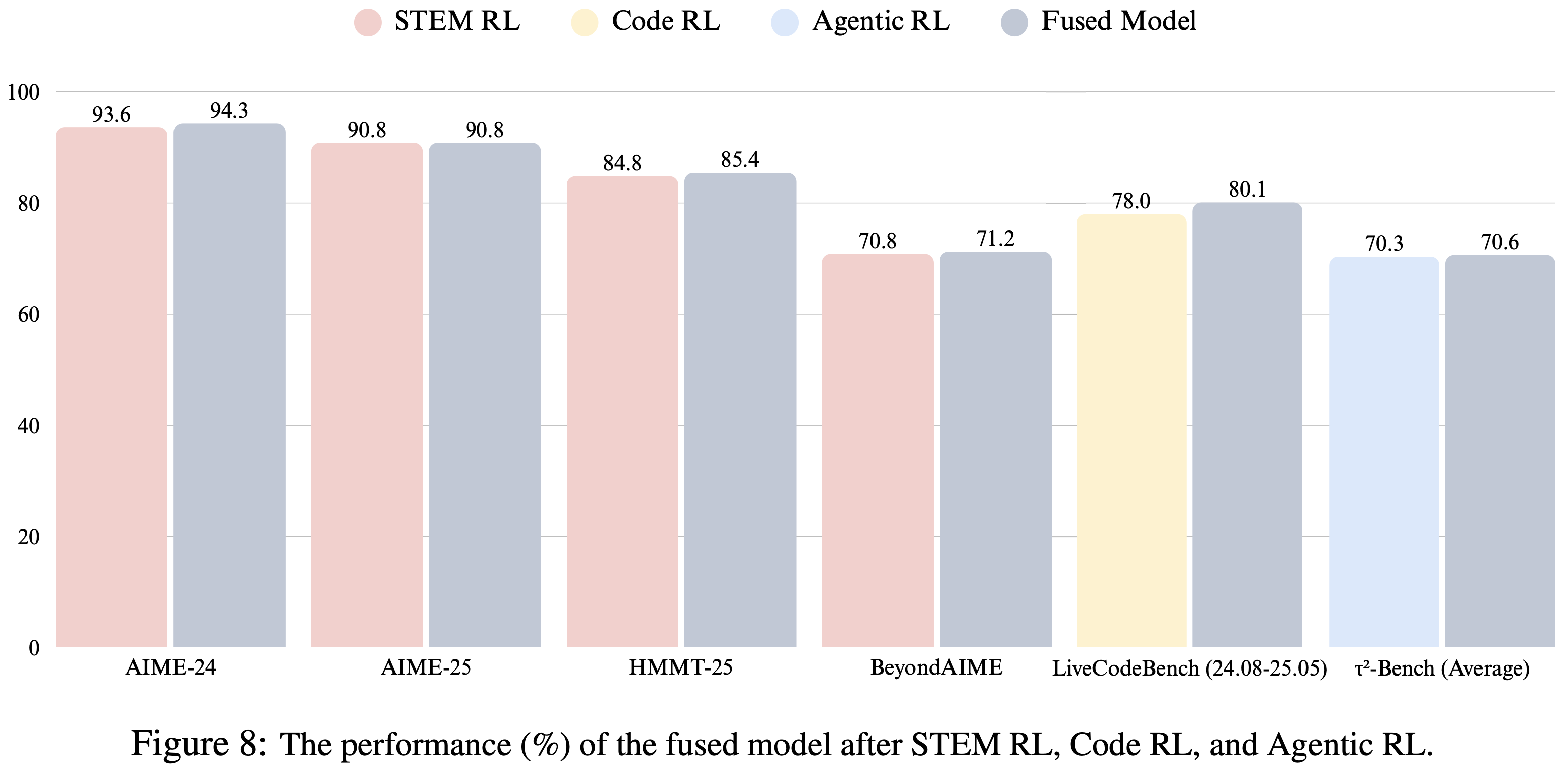
- 问题:模型融合相关的知识有时间需要回来再看
Final Alignment with General RL
- 论文 Pipeline 的最后阶段是一个通用 RL 阶段,旨在增强模型在广泛场景(例如创意写作、指令遵循)中的能力,并防止融合后核心能力(如安全性)的任何回归(regression)
- 论文首先从开源和合成查询中编译(compile)一个多样化的数据集,然后应用聚类算法进行去重和过滤,以获得高质量、具有挑战性的数据
- 这个精心策划的数据集随后用于最后一轮(final round)的 PPO 训练,确保模型为实际应用做好了对齐、鲁棒和适应性的准备
- 问题:这里说的 final round 是指这里的 通用 RL 阶段,还是通用 RL 中的最后一轮?
Evaluations
- LongCat-Flash-Thinking 模型在自动化基准测试上进行了评估
- 这些基准测试分为多个维度,包括通用问答(General QA)、对齐(Alignment)、数学、通用推理(General Reasoning)、编程(Coding)、智能体工具使用(Agentic Tool Use)、形式化定理证明(Formal Theorem Proving)以及安全性(Safety)
Benchmarks and Configurations
- 评估采用了以下基准测试:
- 通用问答(General QA):
- MMLU-Pro (2024),一个经过严格重新评估的 MMLU (2021) 版本,修正了错误并减少了数据污染
- MMLU-Redux (2025),MMLU 基准测试的另一个高质量变体
- 对齐(Alignment):
- IFEval (2023),一个指令遵循基准测试,包含一组具有可编程验证约束的 Prompt ,可对模型遵循复杂指令的忠实度提供客观评分
- Arena-Hard (2024),一个源自 Chatbot Arena 平台的基准测试 ,用于评估模型在困难、开放式用户查询上的帮助性和对话质量
- Mathematical Reasoning:
- 奥林匹克级别的数学基准测试,包括 MATH-500 (2023)、HMMT-25 (HMMT, 2025)(哈佛-麻省理工学院数学锦标赛)、AIME-24 (MAA, 2024) 和 AIME-25 (MAA, 2025)(美国数学邀请赛),以及 BeyondAIME (ByteDance-Seed, 2025)
- 通用推理(General Reasoning):
- GPQA-Diamond (2024),一个评估多个科学领域研究生水平问题深度推理能力的基准测试
- ZebraLogic (2025),由经典的逻辑网格谜题组成,需要多步演绎推理和约束满足
- Sudoku-Bench (2025),通过要求模型解决数独谜题来评估符号化和结构化推理能力(论文在具有挑战性的 nikoli_100 数据集上评估模型)
- ARC-AGI (Chollet, 2019),一个旨在衡量流体智能的基准测试
- 编程(Coding):
- LiveCodeBench (LCB) (2025),一个动态基准测试,论文评估了 2408 至 2505 期间的问题
- OJBench (2025b),ACM-ICPC 级别的代码推理基准测试
- 智能体工具使用(Agentic Tool Using):
- SWE-Bench (2024),源自真实的 GitHub issues,用于评估模型解决软件工程问题的能力
- BFCL (2025) 和 \(\tau^{2}\)-Bench (2025) 是工具增强推理基准测试
- VitaBench (Meituan, 2025),论文自行设计的综合性现实世界基准测试,用于系统评估模型解决复杂现实世界任务的能力
- 形式化定理证明(Formal Theorem Proving):
- MiniF2F (2021) 是一个形式化理论证明的基准测试,包含跨多个形式化系统翻译的问题陈述(注:目前涵盖 Metamath、Lean、Isabelle(部分)和 HOL Light(部分)四种证明系统)
- 问题来源于高中数学和本科数学练习题,以及来自 AMC、AIME 和 IMO 等著名竞赛的具有挑战性的题目
- 论文在包含 244 个问题的测试集上进行评估
- 安全性(Safety):
- 遵循 LongCat-Flash-Chat (Meituan, 2025),论文在四个主要风险类别上评估 LongCat-Flash-Thinking 的安全性表现:
- 有害内容(Harmful)(例如,暴力、仇恨言论、侮辱、骚扰、自残和成人内容)
- 犯罪活动(Criminal)(例如,非法活动、恐怖主义和未成年人违规)
- 虚假信息(Misinformation)(例如,错误信息、虚假信息和不安全实践)
- 隐私(Privacy)(例如,隐私侵犯和侵权)
- 对于每个类别,论文策划了大量的私有测试查询,并进行了严格的人工审查以验证其分类并确保质量
- 遵循 LongCat-Flash-Chat (Meituan, 2025),论文在四个主要风险类别上评估 LongCat-Flash-Thinking 的安全性表现:
- 通用问答(General QA):
- 对于每个基准测试类别,论文采用以下专门的指标和配置:
- 通用问答(General QA):
- 论文使用准确率(accuracy)作为主要评估指标
- 遵循 (Meituan, 2025),论文采用一个评分模型来评估模型响应与参考答案之间的语义对齐程度
- 由于这种方法能识别语义正确但文本不完全相同的响应,论文报告的准确率分数可能略高于原始记录的分数
- 对齐(Alignment):
- 为了评估指令遵循情况,论文设计了针对每个任务特定规则的正则表达式
- 此验证过程还得到了基于规则和基于模型的答案片段提取工具的支持
- Mathematical Reasoning:
- 对于 AIME 和 HMMT 基准测试,论文报告 32 个样本的平均准确率(Mean@32)
- 对于 MATH-500 和 BeyondAIME,论文分别报告 Mean@1 和 Mean@10
- 通用推理(General Reasoning):
- 对 GPQA-diamond 应用 LLM-as-a-Judge 方法
- 对 ZebraLogic 应用基于规则的匹配
- 对于 GPQA-diamond 基准测试,论文报告 16 个样本的平均准确率(Mean@16)
- 对于 ZebraLogic、Sudoku-Bench 和 ARC-AGI,报告 Mean@1 准确率
- 编程(Coding):
- 论文使用接受率(acceptance rate, AC rate)来评估编程性能,模型在一个问题上只有在其代码通过所有测试用例时才得 1 分 ,否则得 0 分
- 问题:通过部分测试用例为啥不给一些分?是担心 Reward Hacking 吗?
- 对于 LCB,论文按照论文建议使用 Python 3.11
- 对于每个基准测试,论文利用官方基准测试框架以确保公平性和可复现性
- 论文使用接受率(acceptance rate, AC rate)来评估编程性能,模型在一个问题上只有在其代码通过所有测试用例时才得 1 分 ,否则得 0 分
- 智能体工具使用(Agentic Tool Using):
- 与编程任务类似,论文也利用官方基准测试框架以确保公平性和可复现性
- 形式化定理证明(Formal Theorem Proving):
- 论文报告 MiniF2F-Test 的 pass@k 指标(\(k\in\{1,8,32\}\))
- 如果证明通过 Lean4 服务器的语法检查(syntax check),则被接受
- 问题:通过语法检查就接受?不应该是推理成功才接受吗?
- 安全性(Safety):
- 论文直接选择准确率作为主要指标
- 通用问答(General QA):
Evaluation Results
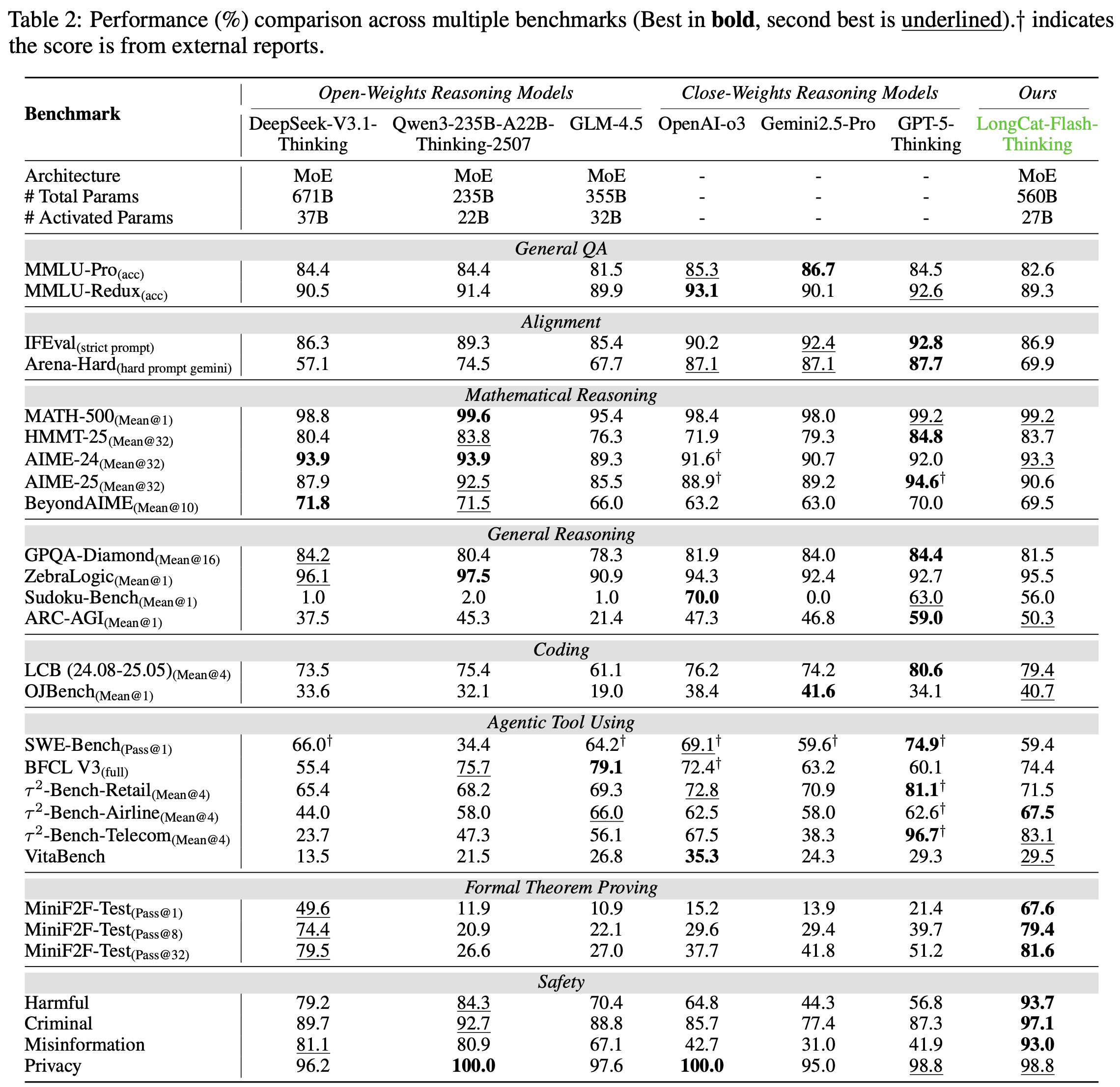
- 如表 2 所示,论文将 LongCat-Flash-Thinking 与几个先进的推理模型进行了比较
- 包括 DeepSeek-V3.1-Thinking (DeepSeek-2025)、Qwen3-235B-A22B-Thinking (Qwen, 2025)、GLM-4.5 (2025a)、OpenAI-o3 (OpenAI, 2025a)、Gemini2.5-Pro (2025) 和 GPT-5-Thinking (OpenAI, 2025b)
- 包括 DeepSeek-V3.1-Thinking (DeepSeek-2025)、Qwen3-235B-A22B-Thinking (Qwen, 2025)、GLM-4.5 (2025a)、OpenAI-o3 (OpenAI, 2025a)、Gemini2.5-Pro (2025) 和 GPT-5-Thinking (OpenAI, 2025b)
- 论文全面评估的结果表明,LongCat-Flash-Thinking 是一个能力强大且多才多艺的模型
- 在广泛的推理任务中 consistently 表现出卓越的性能,超越了那些需要更多激活参数的同类模型(后续分析提供了这些能力的详细分解)
- 论文的 LongCat-Flash-Thinking 的推理参数设置为
temperature=1.0, topk=1, topp=0.95
- 通用能力(General Abilities):
- 在通用知识领域,结果表明 LongCat-Flash-Thinking 具有强大的基础理解能力,尤其是在综合多任务基准测试上
- 在 MMLU-Redux 上达到了 89.3% 的准确率,与 SOTA 开源模型 Qwen3-235B-A22B 相媲美,并在 MMLU-Pro 上保持了强大的竞争力,得分为 82.6%
- 考虑到 LongCat-Flash-Thinking 的高效性,这些结果尤其引人注目
- 对齐能力(Alignment Abilities):
- 在对齐任务中,LongCat-Flash-Thinking 表现出强大且具有竞争力的性能(注:高于所有基线模型)
- 在 IFEval 基准测试(Strict Prompt)上取得了 86.9% 的 impressive 分数
- 在 Arena-Hard(困难 Prompt gemini)上取得了 69.9% 的分数,展示了其在遵循复杂指令方面的强大能力,并超越了包括 DeepSeek V3.1 在内的几个关键基线模型
- 数学能力(Mathematical Abilities):
- LongCat-Flash-Thinking 在数学推理方面表现出卓越的熟练度,使其成为当前可用的顶级性能模型之一
- 特别是,它在 MATH500 基准测试上取得了 99.2% 的高度竞争力分数,而其真正实力在更具挑战性的基准测试上变得更加明显
- 该模型在 HMMT 和 AIME 相关基准测试上提供了令人印象深刻的结果,优于 OpenAI-o3 等强大基线,并与 Qwen3-235B-A22B 和 GPT-5 等领先的专有模型相媲美
- 这些发现凸显了其解决复杂、多步问题的高级能力
- 通用推理能力(General Reasoning Abilities):
- LongCat-Flash-Thinking 展示了卓越的通用推理能力,尤其是在需要结构化逻辑的任务中
- 在 ARC-AGI 上取得了 exceptional 性能,达到了 50.3% 的分数,并超越了 OpenAI-o3 和 Gemini2.5-Pro 等领先的专有模型
- 在谜题推理方面表现出显著的天赋,在 Sudoku-Bench 上得分为 56.0%,在 ZebraLogic 上得分为 95.5%,突显了其解决复杂、非语言谜题的高级能力
- 编程能力(Coding Abilities):
- 在编程领域,LongCat-Flash-Thinking 展示了 SOTA 性能和强大的整体能力
- 在 LiveCodeBench 上,取得了 79.4% 的分数,显著优于所有列出的开源模型,并与顶级专有模型 GPT-5 (80.6%) 表现相当
- 这展示了其在解决新颖的竞争性编程问题方面的出色熟练度
- 在 OJBench 上得分为 40.7%,超过了大多数专有模型,并几乎与 Gemini2.5-Pro 的领先分数 (41.6%) 持平
- 智能体能力(Agentic Abilities):
- 对智能体能力的评估表明,LongCat-Flash-Thinking 在复杂的、工具增强的推理方面表现出色,展示了在智能体工具使用方面的强大能力
- 在 \(\tau^{2}\)-Bench-Airline 上取得了 SOTA 结果,得分为 67.5%,并在包括 SWE-Bench、BFCL V3 和 VitaBench 在内的一系列其他基准测试中提供了高度竞争力的性能
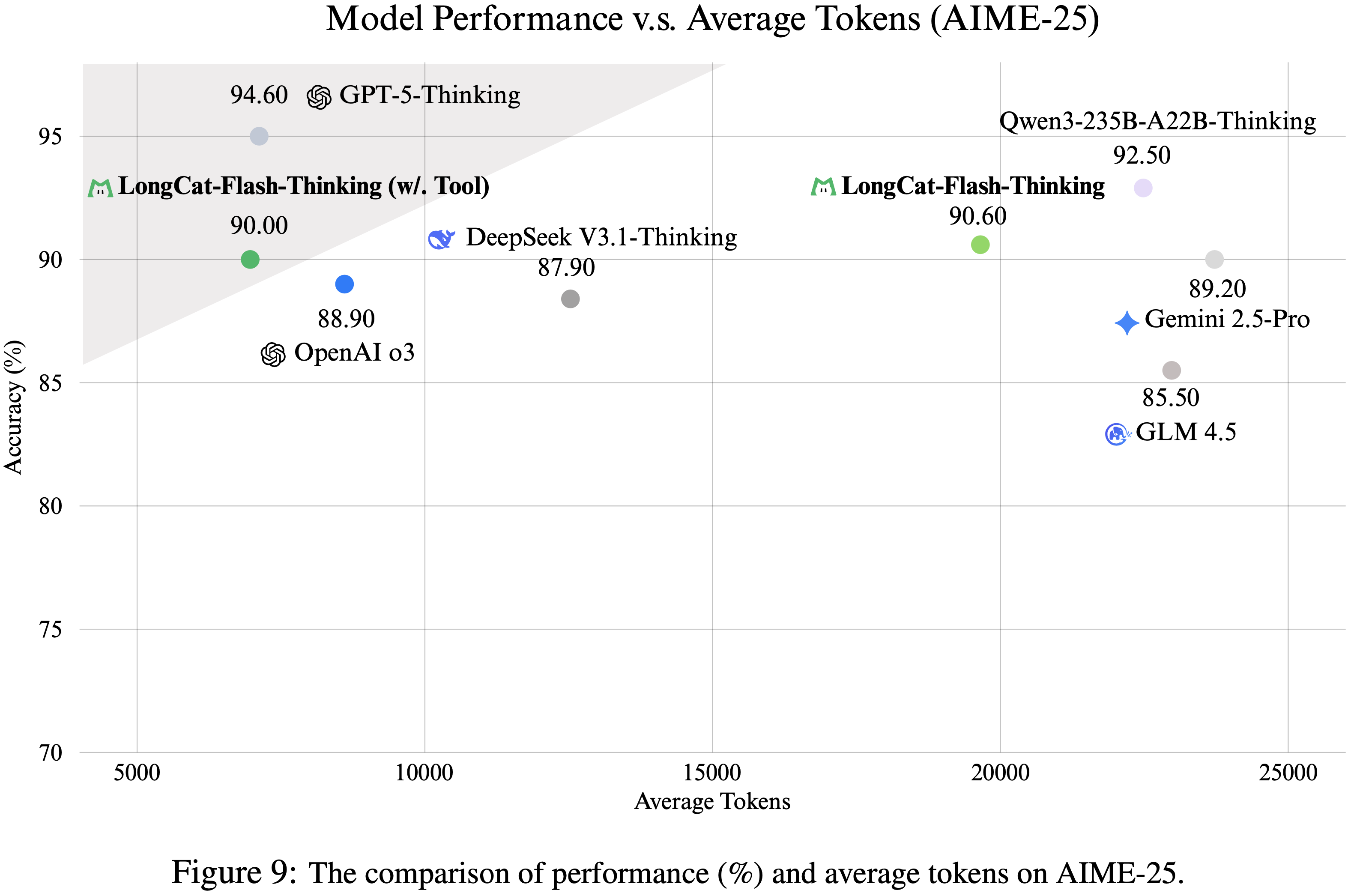
- 特别是,启用定向工具使用(enabling targeted tool use)显著改善了性能与 token 预算之间的权衡
- 问题:这里说的定向工具使用是什么?如何理解启动定向工具使用,有什么特殊的含义吗?
- 在论文的实验中,使用工具的 LongCat-Flash-Thinking 将平均 token 消耗从 \(19,653\) 减少到 \(9,653\)(约减少 64.5%),同时保持了 AIME-25 的准确率,如图 9 所示
- 这表明智能体系统不仅可以通过扩展纯模型推理来实现近乎 SOTA 性能,还可以通过将选定的推理步骤卸载到外部工具来高效实现
- ATP 形式化推理(Formal Reasoning for ATP):
- 在证明(proving)领域,LongCat-Flash-Thinking 展示了 SOTA 能力
- 在 MiniF2F-Test 基准测试上,它取得了 pass@1 分数 67.6%,以 18% 的显著优势超越了第二好的模型 DeepSeek V3.1(这一领先优势在 pass@8 和 pass@32 上得以保持)
- 突显了其在生成结构化证明和形式化数学推理方面的卓越能力
- 安全能力(Safety Abilities):
- 在安全性基准测试上,LongCat-Flash-Thinking 在拒绝回答有害或不道德查询方面展示了 SOTA 性能
- 取得了 overall 最佳性能!显著优于所有其他评估的开源和专有模型
- 其优势在所有子类别中保持一致,在有害内容(93.7%)、犯罪活动(97.1%)和虚假信息(93.0%)方面均取得 top 分数
- 这一稳健的性能 underscore 了论文模型安全对齐的有效性及其遵守安全协议的可靠性
- 图 9:
附录 A: 论文附录内容
A.1 mid-training 的细节 (Details of Mid-training)
- 对于 mid-training 阶段,数据质量和多样性对于增强模型的推理能力至关重要 (2025)
- 在过滤阶段,论文结合使用启发式规则和 LLM-as-a-Judge 方法来确保 Query 的可解性和难度分布,以及答案的质量和正确性
- 为保证 Query 的可解性
- 应用了基于规则的方法,如 URL 过滤、多表过滤和 HTML/XML 标签过滤,以消除依赖外部信息或本质上无法回答的推理问题
- 对于合成答案:
- 首先应用规则去除那些存在重复生成、截断、语言混合或不符合理期望推理格式等问题的答案
- 为了验证答案的正确性,论文结合了基于模型和基于规则的方法,将合成回答与标准答案进行比较,以评估其在各种形式和风格变体下的等价性
- 对于剩余的数据,强调难度分布和多样性的重要性(这显著影响模型的长链思维(long CoT)推理能力)
- 论文标注了一个小规模的分类训练数据集,以构建一个神经评分器,为每个文档分配一个难度分数
- 考虑到多样性,论文并未完全移除低难度样本,而是应用了适当比例的降采样
- 对于有多个答案的 Query ,论文努力平衡答案来源或合成方法 ,并在答案数量过多时施加限制
- 问题:具体如何平衡?
- 最终,论文遵循 LongCat-Flash-Chat 的做法,通过结合基于规则和基于神经模型的方法,执行基于语义相似性的数据净化和去重
A.2 Details of SFT
A.2.1 通用推理数据的细节 (Details of General Reasoning Data)
- STEM:
- STEM 的训练数据包含数十万个带有可验证答案的实例,涵盖数学、物理、化学、生物学及其他相关科学领域
- 大部分问题来自开源数据集、公开竞赛以及从预训练语料库中检索到的少量指令数据
- 为确保数据质量和正确性,论文实施了一个多阶段过滤流程
- 在初始阶段,论文利用 LLM-as-a-Judge 方法自动识别并排除不适合回答的问题,例如不完整的陈述和概念性 Query
- 随后,对于每个剩余的问题,论文使用多个先进的大型推理模型(Large Reasoning Models, LRMs)生成候选回答
- 基于投票结果来过滤那些真实答案(ground truth)与投票结果不一致的数据
- Code:
- 代码数据主要从开源竞赛数据中收集
- 论文筛选出那些具有清晰问题描述、包含至少 5 个测试用例的单元测试集、以及带有启动代码或函数体的评判脚本的 Query
- 问题描述必须包含问题、运行成本约束以及一些输入输出对
- 单元测试被视为生成代码的参数 ,并可通过评判脚本来验证其正确性
- 问题:如何理解 单元测试被视为生成代码的参数 ?
- 为避免诸如标题描述不清、单元测试错误和评判脚本错误等问题
- 首先,实施了一个过滤流程,以消除包含乱码内容、缺失信息或逻辑错误的 Query
- 然后,论文构建了一个内部的代码沙盒环境,并利用多个先进的 LRM 生成候选代码
- 如果所有 LRM 生成的代码都无法在论文的沙盒中通过所有单元测试 ,则这部分数据将被过滤掉
- 为了平衡多样性,论文训练了一个小型分类器来为每个 Query 标记特定的知识点和难度,并执行难度过滤,确保问题具有适当的复杂度和对现实世界算法推理的适用性
- 逻辑 (Logic)
- 逻辑推理是必不可少的通用推理任务之一,在类人的探索、回溯和深度思考中扮演着重要角色 (2024b; 2025)
- 论文收集了一系列广泛考虑的演绎、归纳和溯因逻辑任务
- 对于每项任务,论文设计了一个专门的生成器 ,以自动合成具有精确可控难度的 Query
- 据此,我们可以将 Query 难度分为三个不同的级别:简单、中等和困难
- 为了合成高质量的回答:
- 首先,通过在这些逻辑任务上应用 RLVR (2024) 来训练一个小型模型
- 然后,通过从训练好的模型中蒸馏,为每个 Query 生成多个长链思维(long CoT)轨迹
- 具有正确答案的可靠回答将被用于训练实例
- 通用问答 (General QA)
- 论文还考虑了一些通用任务,例如指令遵循、常识知识和安全等
- 对于指令遵循,论文策划了包含单轮和多轮的指令遵循数据集,其约束复杂度和数量各不相同
- 过滤掉语义质量低的 Query,并采用逆向 Prompt 生成策略 (2024) 来确保回答满足所有约束
- 对于常识知识,论文开发了三种类型的通用问答数据集:阅读理解、基于表格的问答和自定义设计的任务
- 这些特定领域可以显著增强论文模型的多轮对话、推理和长上下文能力
- 对于安全性
- 制定一个内容安全策略,将 Query 分为超过 40 个不同的安全类别,涵盖五种响应类型:
- 遵从(comply)
- 遵从并带 guideline(comply with guideline)
- 软拒绝(soft refuse)
- 软拒绝并带 guideline(soft refuse with guideline)
- 硬拒绝(hard refuse)
- 该标准指导论文训练一个小型模型,将每个 Query 划分到特定的安全类别,并根据不同的安全类别通过人工标注来优化回答
- 因为过度拒绝会显著影响模型的有用性(helpfulness),论文还通过仔细处理通用 Query 来优化拒绝能力
- 制定一个内容安全策略,将 Query 分为超过 40 个不同的安全类别,涵盖五种响应类型:
- 除了通用问答之外,论文还通过高级 LRM 估计的通过率(pass rate)来评估 Query 的难度
- 通过率超过预定义阈值的 Query 被认为过于简单并被移除,从而将重点集中在需要实质性推理的问题上
- 最终的训练集是根据通过率分布从过滤后的池中采样得到的,从而产生了一个适用于训练推理模型的高质量数据集
- Figure 10: The distribution of our curated SFT data
附录:LongCat-Flash-Thinking-2601
- HuggingFace: huggingface.co/meituan-longcat/LongCat-Flash-Thinking-2601
- LongCat-Flash-Thinking-2601 是 LongCat-Flash-Thinking 的升级版
- 该版本不仅继承了上一版本的领域并行训练方案,在传统推理基准测试中保持了极具竞争力的性能,还通过精心设计的训练流程系统强化了智能体思维能力
- 该流程融合了环境扩展、后续任务合成,以及可靠高效的大规模多环境强化学习
- 为了更好地适应现实世界智能体任务中固有的噪声和不确定性,作者对多种类型和级别的环境噪声进行了系统分析和课程式训练,使模型在非理想条件下仍能实现稳定性能
- LongCat-Flash-Thinking-2601 不仅在智能体工具使用、智能体搜索和工具集成推理等基准测试中取得了顶尖成绩,还在任意分布外的现实世界智能体场景中显著提升了泛化能力
- 作者还设计了专门的评估协议,用于考核模型的稳健性和泛化能力
- 此外,LongCat-Flash-Thinking-2601 引入了 “深度思考模式”(Heavy Thinking Mode) ,通过密集并行思考进一步提升模型在极富挑战性任务上的表现
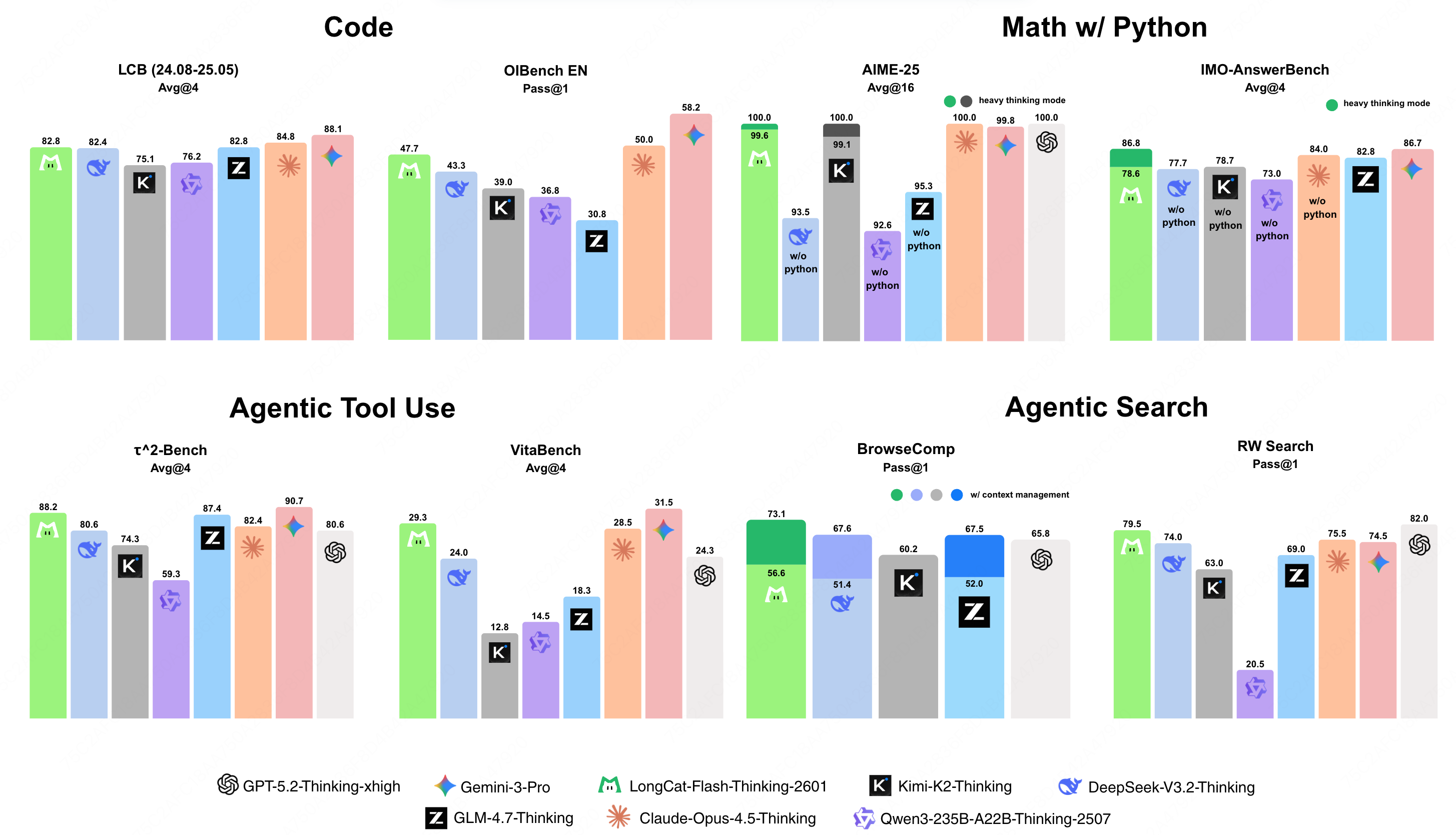
- 该版本不仅继承了上一版本的领域并行训练方案,在传统推理基准测试中保持了极具竞争力的性能,还通过精心设计的训练流程系统强化了智能体思维能力
Environment Scaling and Multi-Environment Reinforcement Learning
- 作者构建了多样化的高质量环境集合,作为强化学习的训练场景,使模型能够习得高级、可泛化的智能体技能
- 每个环境包含 60 余种工具,这些工具以密集依赖图的形式组织,为多样化任务构建和大规模探索提供了充足的复杂性
- 随着训练环境数量的增加,作者观察到模型在分布外评估中的性能持续提升,这表明其泛化能力得到了强化
- 高质量任务构建(High Quality Task Construction):为确保训练任务集的质量,作者明确控制了任务的复杂性和多样性
- 每个任务基于从高质量环境中采样的连通子图定义,通过要求在采样子图内协调使用尽可能多的工具来控制任务复杂性
- 同时,逐步降低已选工具的采样概率,以提升任务多样性
- 作者构建了相应的数据库以确保任务的可执行性,每个任务均经过验证,至少存在一种可执行解决方案
- 然而,当环境包含大量工具时,维持数据库间的一致性会面临挑战,可能导致不可验证的任务,为此作者设计了专门的策略来解决这一问题
- 多环境强化学习(Multi-Environment Reinforcement Learning):在保留高效异步训练和流式推演特性的基础上,作者进一步扩展了强化学习基础设施(DORA),以支持环境扩展方案所需的大规模多环境智能体训练
- 每个训练批次中,来自多个环境的任务会以平衡的方式联合组织,并根据任务复杂性和当前训练状态分配不同的 Rollout Budget
Robust Training against Noisy Environment
- 由于现实世界的智能体环境本质上存在噪声且并不完美,仅在理想化环境中训练模型是不够的,往往会导致模型稳健性有限
- 为解决这一问题,作者将环境缺陷明确纳入模型训练过程,以增强其稳健性
- 具体而言,作者系统分析了智能体场景中现实世界噪声的主要来源,然后设计了自动流程将此类噪声注入训练环境
- 在强化学习过程中,作者采用课程式训练策略,随着训练推进逐步增加噪声的类型和强度
- 得益于这种稳健训练,LongCat-Flash-Thinking-2601 具备了强大的环境不确定性适应能力,在非理想条件下始终能实现性能提升
Heavy Thinking Mode
- 为突破当前推理能力的边界,作者推出了“深度思考模式”
- 具体而言,作者将复杂问题求解分解为两个互补阶段:并行思考和总结归纳
- 从而同时提升推理的深度和广度
- 在推理广度扩展方面,深度思考模式下会以并行方式独立生成多条推理轨迹,实现推理路径的广泛探索,并通过设置合理的高推理温度确保路径多样性
- 在推理深度扩展方面,总结阶段的优化轨迹可递归反馈至总结模型,形成迭代推理循环,支持逐步深化的推理过程
- 作者还专门设计了额外的强化学习阶段来训练总结能力,进一步释放该模式的潜力
Benchmark DeepSeek-V3.2-Thinking Kimi-K2-Thinking Qwen3-235B-A22B-Thinking-2507 GLM-4.7-Thinking Claude-Opus-4.5-Thinking Gemini-3-Pro GPT-5.2-Thinking-xhigh LongCat-Flash-Thinking-2601 Architecture MoE MoE MoE MoE - - - MoE # Total Params 671B 1T 235B 355B - - - 560B # Activated Params 37B 32B 22B 32B - - - 27B Mathematical Reasoning w/ Tools AIME-25 (Avg@16) 93.5* 99.1† 92.6* 95.3* 100.0 99.8 100.0 99.6 / 100.0 ‡ HMMT-25 (Avg@16) 93.5* 95.1† 83.9* 98.1* 98.6 99.8 99.6 93.4 / 97.5‡ IMO-AnswerBench (Avg@4) 77.7* 78.7* 73.0* 84.0* 82.8 86.7 - 78.6 / 86.8‡ AMO-Bench EN (Avg@16) 51.9* 56.0* 47.8* 62.4* 66.0 72.5 - 61.6 / 66.0 ‡ AMO-Bench CH (Avg@16) 52.0* 51.8* 28.8* 35.1* 67.7 74.9 - 56.8 / 67.5 ‡ Agentic Search BrowseComp (Pass@1) 51.4 / 67.6† - / 60.2† - 52.0 / 67.5† - - 65.8 / - 56.6 / 73.1 BrowseComp-zh (Pass@1) 65.0 / - - / 62.3† - 66.6 / - - - - 69.0 / 77.7 RW Search (Pass@1) 74.0 63.0 20.5 69.0 75.5 74.5 82.0 79.5 Agentic Tool Using τ²-Retail (Avg@4) 81.8† - 71.9† - 88.9† - 82.0† 88.6 τ²-Airline (Avg@4) 63.8† - 58.6† - - - - 76.5 τ²-Telecom (Avg@4) 96.2† - 47.3 - 98.2† - 98.7† 99.3 τ²-Avg (Avg@4) 80.6 74.3† 59.3 87.4† 82.4 90.7† 80.6 88.2 τ²-Noise (Avg@4) 64.1 63.1 44.3 66.0 59.4 57.3 65.0 67.1 VitaBench (Avg@4) 24.0 12.8 14.5 18.3 28.5 31.5 24.3 29.3 VitaBench-Noise (Avg@4) 14.0 9.2 6.5 10.8 20.3 20.8 19.0 20.5 Random Complex Tasks (Avg@4) 32.5 29.7 32.7 25.3 32.6 32.5 17.2 35.8 General QA HLE text-only (w/o tools) 24.1 24.4 17.8 26.9 32.0 40.3 34.5† 25.2 GPQA-Diamond (Avg@16) 86.9 85.4 80.5 84.9 86.9 91.9 92.9 80.5 / 85.2‡ Coding LCB (24.08–25.05) (Avg@4) 82.4 75.1 76.2 84.8 82.8 88.1 - 82.8 OJBench (Pass@1) 41.8 42.3 35.6 44.6 46.7 61.2 - 42.2 OIBench EN (Pass@1) 43.3 39.0 36.8 30.8 50.0 58.2 - 47.7 SWE-bench Verified (Avg@5) 73.1 71.3 - 73.8 80.9 76.2 80.0 70.0 - Note
- Values marked with † are sourced from other public reports.
- ‡ indicates the score obtained using our Heavy Thinking mode.
- * indicates that the result with tools is unavailable, and thus the corresponding result without tools is reported instead.
- For BrowseComp-zh, due to a high error rate in the original annotations, we manually revised the answers for 24 cases.
- For the τ²-Airline domain, we adopt the fixes to the environment as proposed in the Claude Opus 4.5 release report.
- For BrowseComp, performance is reported both without and with the context management technique.
- The Noise benchmarks are constructed by injecting environmental noise into existing benchmarks to better approximate real-world agentic environments, and are used to evaluate the model’s robustness.
- Random Complex Tasks refers to randomly constructed environments, and are used to evaluate the model’s generalization capability, which we detail below.
Evaluation in Random Complex Tasks
- 作者提出了一种评估智能体模型泛化能力的新方法
- 具体而言,作者构建了一个自动合成流程,用户可通过输入一组关键词,为任意场景随机生成复杂任务
- 每个生成的任务都配备了相应的工具集和可执行环境
- 由于这些环境中的工具具有高度随机性,作者通过评估模型在这类环境中的表现来衡量其泛化能力
- LongCat 在该设置下持续取得优异性能,展现出在智能体场景中强大的泛化能力
- 作者还提供了视频演示供参考