注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 注:Kimi-K2.5 是一个统一的模型,但提供了两种不同的模式:Thinking Mode(思考模式)和 Instant Mode(即时模式)
- 所以在 LMArena 上排名会是有两个名字:
kimi-k2.5-thinking和kimi-k2.5-instant; - 两者表示同一个模型的两种不同模式
- 所以在 LMArena 上排名会是有两个名字:
- 总体评价:
- 与 Kimi-K1.5 间隔差不多刚好一年,Kimi-K2.5 终于出山,Kimi 的发挥依然稳定,Kimi-K2.5 让人看到了一些惊喜
- 亮点1:原生多模态(K2.5 让文本与视觉两种模态融合,并实现了互相增强)
- 联合文本-视觉预训练 (joint text-vision pre-training)
- zero-vision SFT(Text-only SFT)
- 联合文本-视觉强化学习 (joint text-vision reinforcement learning)
- 亮点2:Agent Swarm
- Agent Swarm 是一个自导向的并行智能体编排框架,能够动态地将复杂任务分解为异构子问题并并发执行
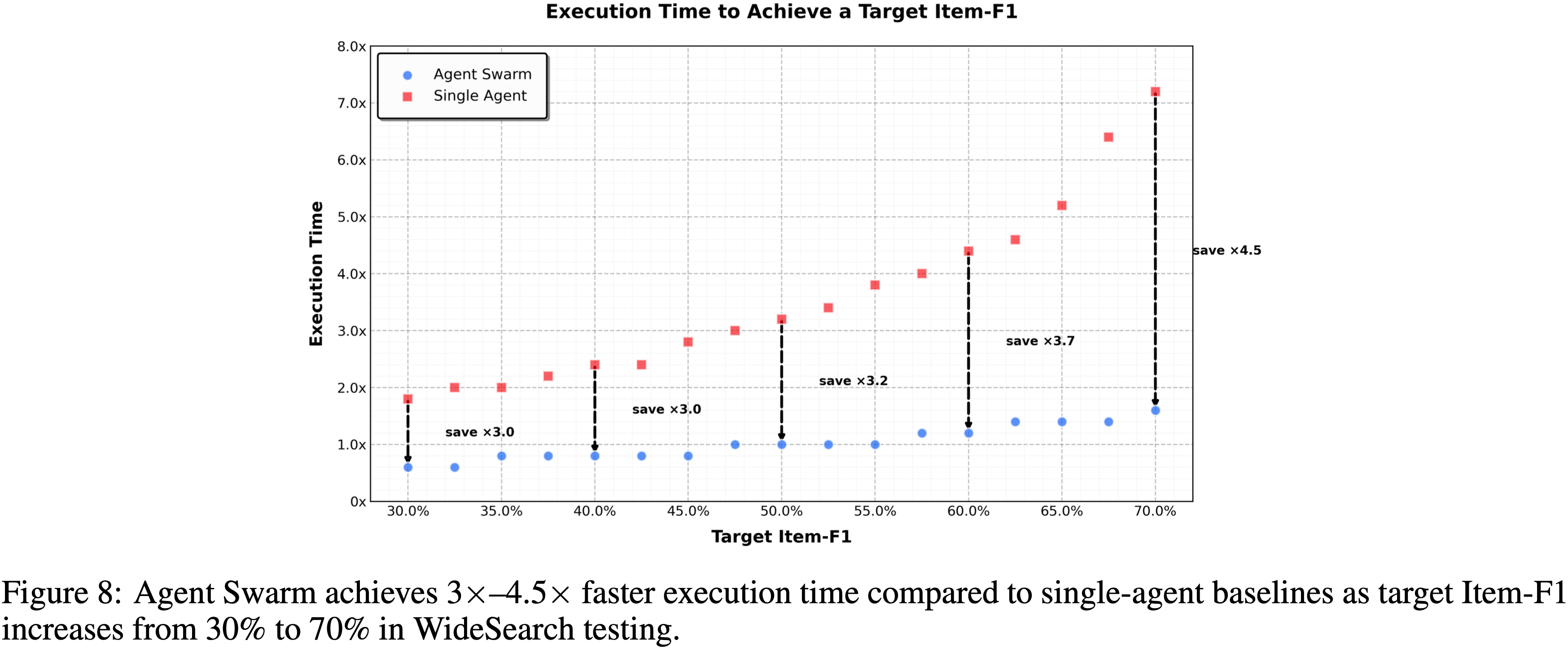
- Agent Swarm 的异构子任务并发执行,减少推理延迟的同时,提升了工作性能(注:延迟相比单 Agent 最多可降低达 \(4.5\times\))
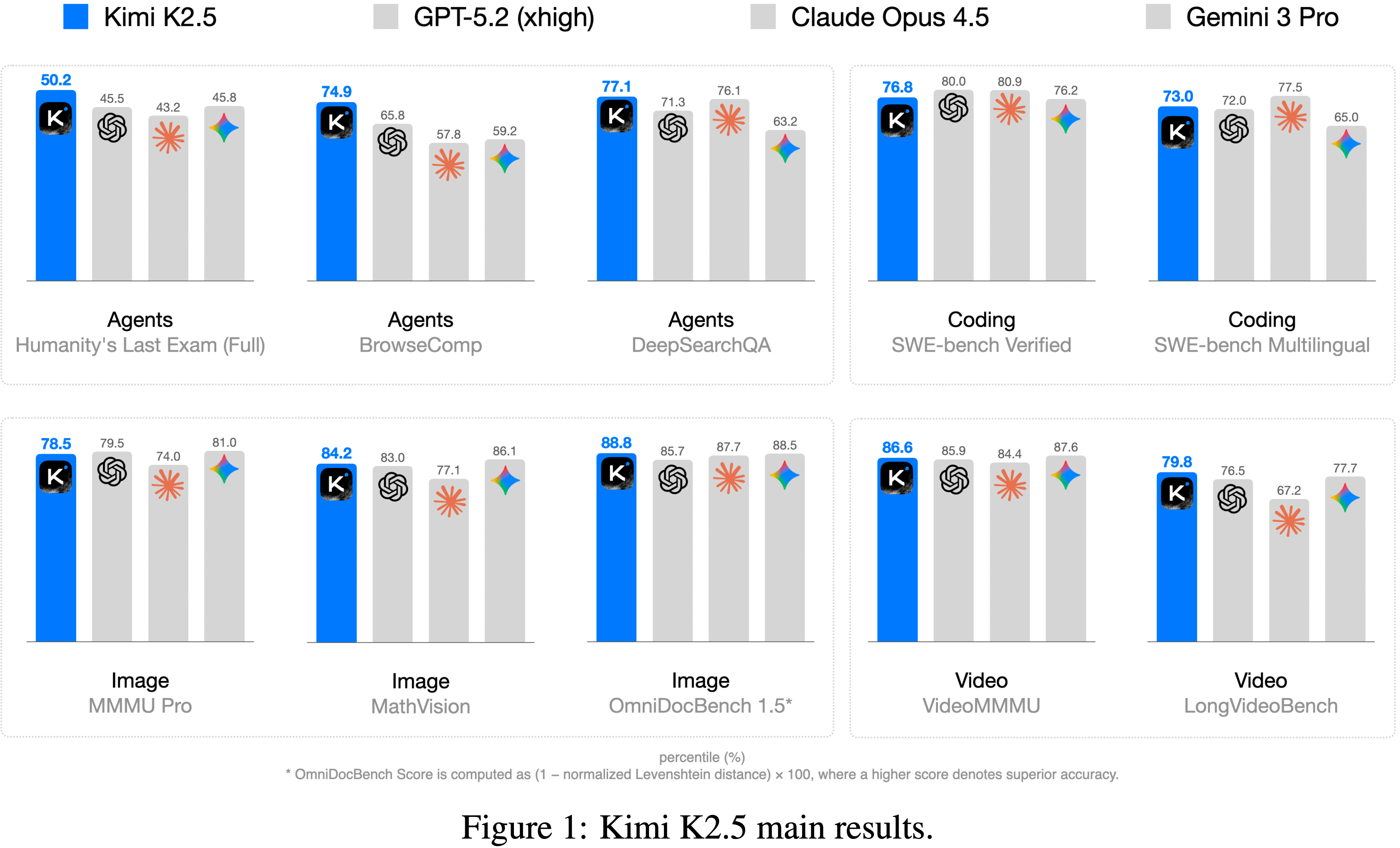
- Kimi K2.5 在包括编码、视觉、推理和智能体任务在内的各个领域均取得了当前开源 SOTA(甚至跟闭源模型硬刚)
- 在各种指标上,对比的 Baseline 都是闭源模型
- 整体训练流程:
- Pre-Training -> Mid-Training -> SFT (含 Zero-Vision SFT) -> Joint Multimodal RL (含 PARL)
- 指标对比图:
Introduction and Discussion
- 智能体智能(Agentic Intelligence)模型逐渐表现出一些智能:可以将复杂问题分解为多步骤计划,并执行交错的推理和动作长序列
- 论文核心创新1:Joint Optimization of Text and Vision
- K2.5 实践中的一个关键 Insight 是:文本与视觉的联合优化能同时增强两种模态并避免冲突
- 预训练阶段:
- 作者发现,预训练期间,在给定的视觉-文本 Token 总数下,早期融合且视觉占比较低往往能产生更好的结果
- 注:这不同于在后期向文本主干添加视觉 Token 的传统方法 (2023, 2025)
- K2.5 在 整个训练过程中以恒定比例混合文本和视觉 Token
- 在架构上,Kimi K2.5 采用了 MoonViT-3D
- MoonViT-3D 是一个原生分辨率的视觉 Encoder,结合了 NaViT 打包策略 (2023),支持可变分辨率的图像输入
- For 视频理解(Video Understanding),作者引入了一种轻量级的 3D ViT 压缩机制:
- 连续的帧以四帧为一组,通过共享的 MoonViT Encoder 处理,并在图像块层面进行时间平均
- 这种设计使得 Kimi K2.5 能够在相同的上下文窗口中处理长达 \(4\times\) 的视频,同时保持图像和视频 Encoder 之间的完全权重共享
- 作者发现,预训练期间,在给定的视觉-文本 Token 总数下,早期融合且视觉占比较低往往能产生更好的结果
- 后训练阶段
- 作者引入了 Zero-vision SFT,即仅使用文本的 SFT 就能激活视觉推理和工具使用
- 作者发现,在此阶段添加人工设计的视觉轨迹会损害泛化能力;相反,仅文本的 SFT 表现更好(作者推测可能是因为联合预训练已经建立了强大的视觉-文本对齐,使得能力能够自然地跨模态泛化)
- SFT 后,作者在文本和视觉任务上应用联合 RL
- 作者发现视觉 RL 增强了文本性能 ,在 MMLU-Pro 和 GPQA-Diamond 上有所提升
- 这种双向增强 :即文本引导视觉,视觉精炼文本,代表了联合训练中优越的跨模态对齐
- 论文核心创新2:Agent Swarm: Parallel Agent Orchestration
- 大多数现有的智能体模型依赖于工具调用的顺序执行
- 即使是能够执行数百个推理步骤的系统,例如 Kimi K2-Thinking (2025),也面临推理时间线性缩放的问题,导致不可接受的延迟并限制了任务复杂性
- 随着智能体工作负载在范围和异构性上增长(例如,构建涉及大规模研究、设计和开发的复杂项目),顺序范式变得越来越低效
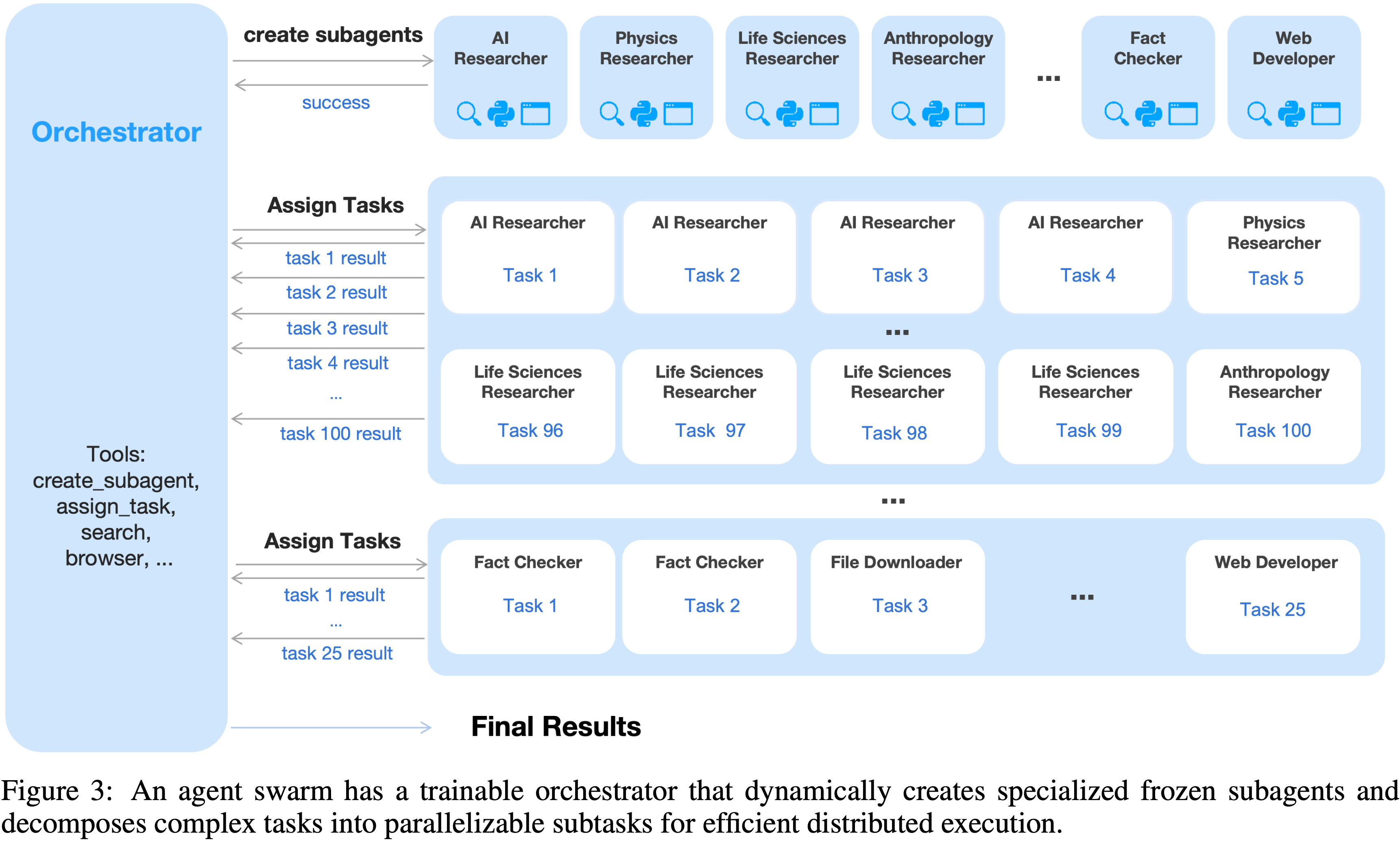
- 为了克服顺序智能体执行的延迟和可扩展性限制,Kimi K2.5 引入了 Agent Swarm(并行智能体编排的动态框架)
- 作者提出了一个并行智能体强化学习 (Parallel-Agent Reinforcement Learning, PARL) 范式(不同于传统的智能体 RL)
- 除了通过可验证的奖励来优化工具执行 外,模型还配备了创建子智能体(Sub-agent)和任务委派的接口
- 在训练期间,子智能体被冻结,其执行轨迹从优化目标中排除;只有编排器通过强化学习进行更新
- 这种解耦规避了端到端协同优化的两个挑战:信用分配模糊性 和训练不稳定性
- Agent Swarm 使得复杂任务能够被分解为由领域专业化智能体并发执行的异构子问题,将任务复杂性从线性缩放转变为并行处理
- 在广泛搜索场景中,与单智能体基线相比,Agent Swarm 将推理延迟降低了多达 \(4.5\times\),同时将项目级 F1 从 \(72.8%\) 提高到 \(79.0%\)
- 大多数现有的智能体模型依赖于工具调用的顺序执行
- Kimi K2.5 代表了通用智能体智能的统一架构,集成了视觉与语言、思考与即时模式、聊天与智能体
- 在作者内部评估中取得视觉到代码生成(图像/视频到代码)和现实世界软件工程方面的 SOTA 结果
Joint Optimization of Text and Vision
- Kimi K2.5 是基于 Kimi K2 的原生多模态模型(大约 15T 混合视觉和文本 Token 联合预训练)
- 不同于在语言或视觉能力上有所妥协的视觉适应模型,Kimi K2.5 的联合预训练范式同时增强了两种模态
Native Multimodal Pre-Training(原生多模态)
- 多模态预训练的一个关键设计问题是:在给定的视觉-文本 Token 预算下,什么是优化的视觉-文本联合训练策略
- 传统观点 (2023, 2025) 认为,主要在 LLM 训练的后期阶段以高比例(例如,\(50%\) 或更高)引入视觉 Token 应能加速多模态能力获取
- 理解:这种方式本质将多模态能力视为语言能力的事后附加功能
- 传统观点 (2023, 2025) 认为,主要在 LLM 训练的后期阶段以高比例(例如,\(50%\) 或更高)引入视觉 Token 应能加速多模态能力获取
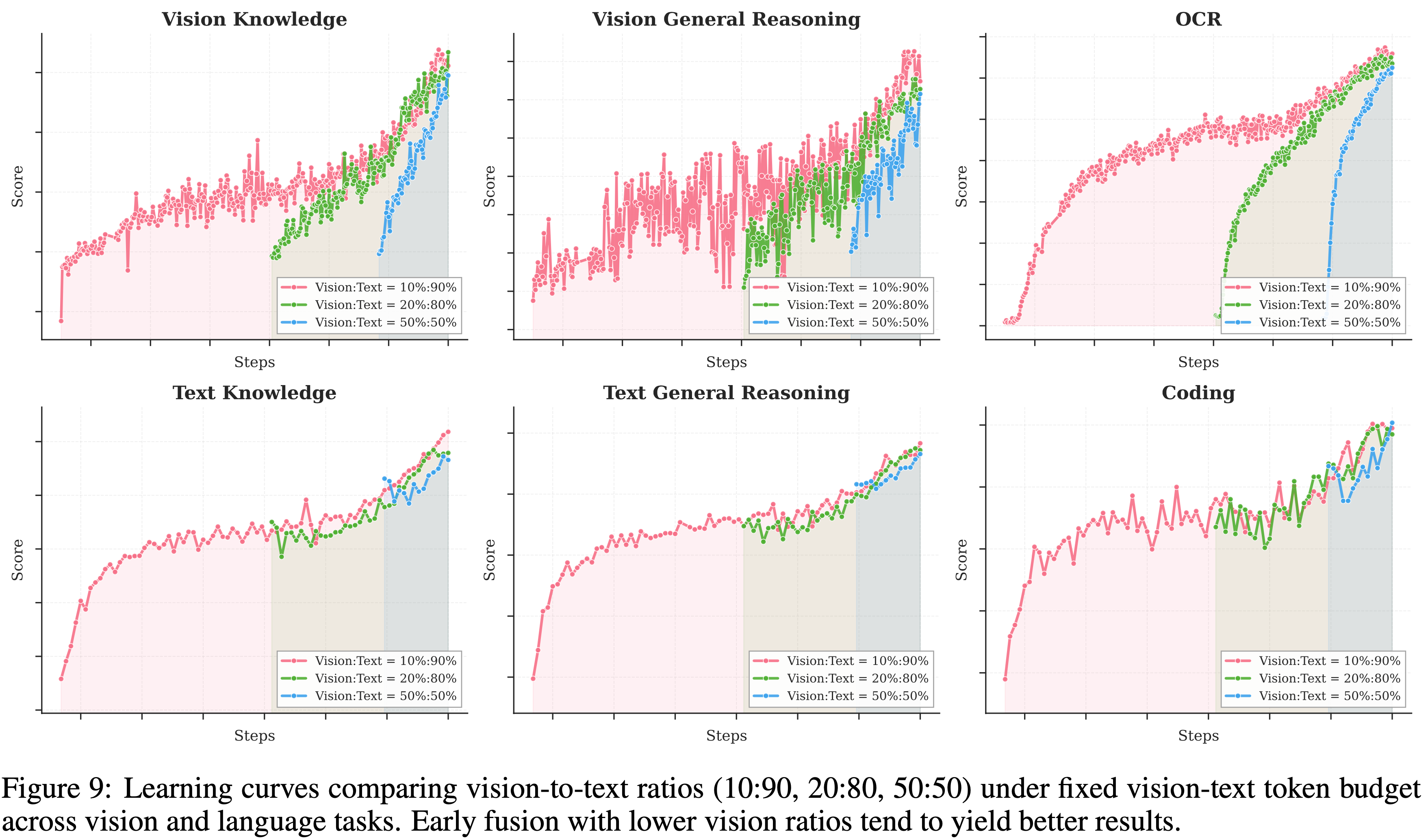
- 但 Kimi 团队的实验(如表 1/图 9 所示)揭示了一个不同的情况
- 作者在保持视觉和文本 Token 总预算固定的情况下,进行了不同视觉比例和视觉注入时机的消融研究
- 为了严格满足不同比例的目标,作者在引入视觉数据之前,先用纯文本 Token 对模型进行了特定计算出的 Token 数量的预训练
- 令人惊讶的是,作者发现视觉比例对最终的多模态性能影响微乎其微
- 事实上,在固定的视觉-文本总 Token 预算下,早期融合且视觉占比较低会产生更好的结果
- 这启发了作者的原生多模态预训练策略:不是将密集的视觉训练集中在训练末期,而是采用中等视觉比例,在训练过程的早期就进行整合,使得模型能够在扩展的双模态协同优化中自然发展出平衡的多模态表征

Zero-Vision SFT
- 经过预训练的 VLM 不会自然地执行基于视觉的工具调用,所以作者需要对多模态 RL 做冷启动
- 传统方法通过手动标注或提示工程设计的 CoT 数据 (2023) 来解决这个问题
- 但此类方法多样性有限 ,通常将视觉推理限制在简单图表和原始工具操作(裁剪、旋转、翻转)
- 一个观察是:高质量的文本 SFT 数据相对丰富且多样
- 作者提出了 zero-vision SFT(其他文章没有使用过的方法),在后训练期间仅使用文本 SFT 数据 来激活视觉和智能体能力
- 在这种方法中,所有图像操作都通过 **IPython 中的程序化操作来代理** ,有效地作为传统视觉工具使用的泛化
- 问题:如何理解这里的方法?
- 这种“零视觉”激活能够实现多样化的推理行为,包括通过二值化和计数进行物体尺寸估计等像素级操作,并泛化到基于视觉的任务,如物体定位、计数和 OCR
- 在这种方法中,所有图像操作都通过 **IPython 中的程序化操作来代理** ,有效地作为传统视觉工具使用的泛化
- 图 2 展示了 RL 训练曲线,其起点来自零视觉 SFT
- 零视觉 SFT 足以激活视觉能力,同时确保跨模态的泛化
- 这种现象可能是由于第 2.1 节所述的文本和视觉数据的联合预训练所致
- 与零视觉 SFT 相比,作者的初步实验表明,文本-视觉 SFT 在视觉智能体任务上表现要差得多,可能是因为缺乏高质量的视觉数据

Joint Multimodal Reinforcement Learning (RL)
Outcome-Based Visual RL
- 零视觉 SFT 之后,模型需要进一步精炼以可靠地将视觉输入纳入推理
- 仅文本启动的激活表现出明显的失败模式:有时会忽略视觉输入,并且必要时可能不会关注图像
- 作者在明确需要视觉理解才能获得正确答案的任务上采用基于结果的 RL
- 作者将这些任务分为三个领域:
- 视觉定位与计数 (Visual grounding and counting):精确地定位和枚举图像内的物体;
- 图表与文档理解 (Chart and document understanding):解释结构化的视觉信息和文本提取;
- 视觉关键 STEM 问题 (Vision-critical STEM problems):筛选出需要视觉输入的数学和科学问题
- 在这些任务上的基于结果的 RL 提高了基本的视觉能力和更复杂的智能体行为
- 提取这些轨迹用于拒绝采样微调 RFT 能够建立一个自我改进的数据管道,使得后续的联合 RL 阶段能够利用更丰富的多模态推理轨迹
Visual RL Improves Text Performance
- 为了研究视觉和文本性能之间潜在的权衡,作者在视觉 RL 前后评估了纯文本基准测试
- 惊喜是,基于结果的视觉 RL 在文本任务中 产生了可衡量的改进
- MMLU-Pro \((84.7% \rightarrow 86.4%)\)
- GPQA-Diamond \((84.3% \rightarrow 86.4%)\)
- LongBench v2 \((56.7% \rightarrow 58.9%)\)(表 2)
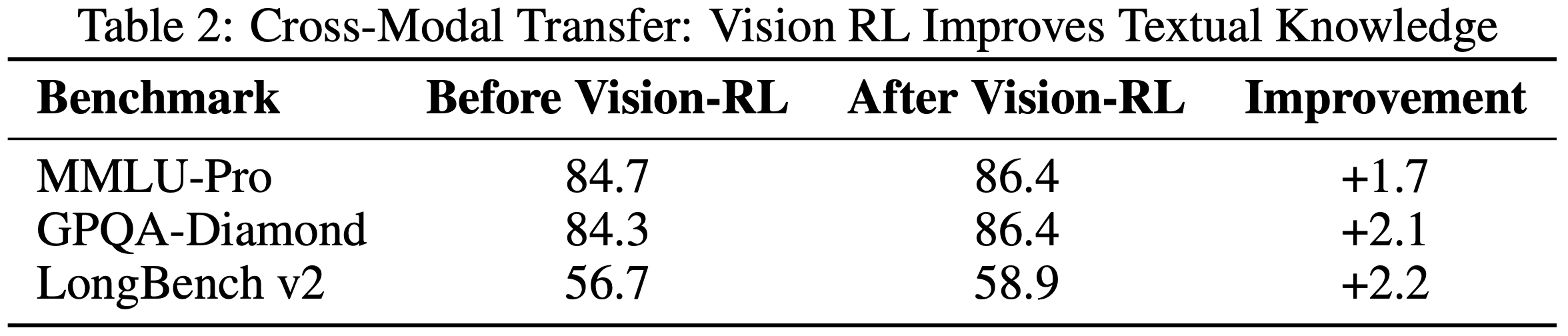
- 分析表明,视觉 RL 增强了在需要结构化信息提取的领域的校准能力,减少了类似基于视觉的推理(例如,计数、OCR)查询的不确定性
- 这些发现表明,视觉 RL 可以促进跨模态泛化,改善文本推理,同时没有观察到语言能力的退化
Joint Multimodal RL
- 作者在 Kimi K2.5 的后训练期间采用了联合多模态 RL 范式
- 作者在论文中声称这是:受到视觉能力可以从零视觉 SFT 配合视觉 RL 中涌现这一发现的启发
- 与传统的特定模态专家划分不同,作者不是按输入模态,而是按能力(知识、推理、编码、智能体等)来组织 RL 领域
- 这些领域专家共同从纯文本和多模态查询中学习,而生成式奖励模型(GRM)同样在没有模态障碍的情况下优化异构轨迹
- 这种范式确保了通过文本或视觉输入获得的能力提升能够固有地泛化,以增强相关跨模态能力,从而最大化跨模态能力迁移
Agent Swarm
- 现有基于智能体的系统的主要挑战在于它们依赖于推理和工具调用步骤的顺序执行
- 这种结构对于较简单的、短视距的任务可能有效,但无法处理任务复杂性高和累积上下文长的场景
- 一个单智能体按顺序执行每一步的有限容量可能导致实际推理深度和工具调用预算的耗尽,最终阻碍系统处理更复杂场景的能力
- 作者引入了 Agent Swarm 和 PARL (Parallel Agent Reinforcement Learning)
- K2.5 不是将任务作为推理链执行或依赖预定义的并行化启发式方法,而是通过动态任务分解、子智能体实例化和并行子任务调度来启动一个 Agent Swarm
- 重要的是,并行性并非被假定为固有优势;关于是否、何时以及如何并行化的决策是通过环境反馈和 RL 驱动的探索来明确学习的
- 如图 4 所示,性能的进展展示了这种自适应能力,随着编排器在整个训练过程中优化其并行化策略,累积奖励平稳增长
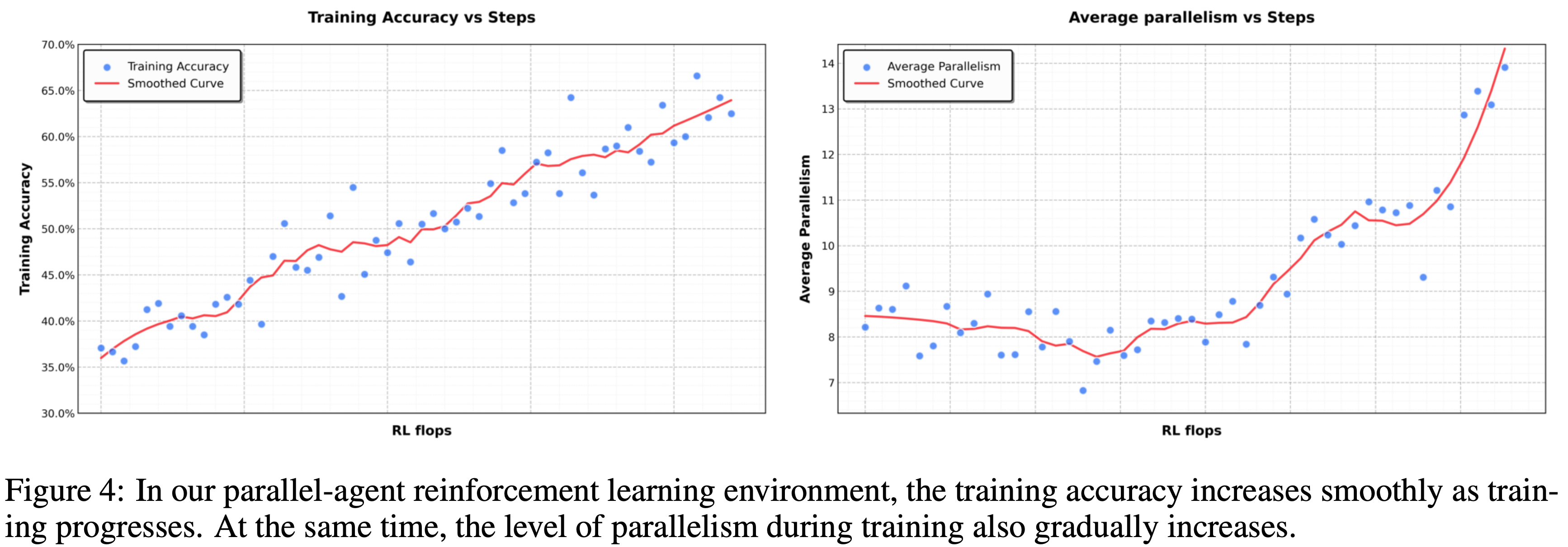
Architecture and Learning Setup
- PARL 框架采用了一种解耦架构,包含一个可训练的编排器和从固定中间策略检查点实例化的冻结子智能体
- 这种设计有意避免端到端的协同优化,以规避两个基本挑战:信用分配模糊性和训练不稳定性
- 在这种多智能体设置中,基于结果的奖励本质上是稀疏且有噪声的;
- 一个正确的最终答案并不保证子智能体执行的完美无缺,正如一个失败并不暗示所有子智能体都有错误
- 作者通过冻结子智能体并将其输出视为环境观察而非可微分的决策点 ,将高层协调逻辑与低层执行能力分离开来,从而实现更稳健的收敛
- 为了提高效率,作者首先使用小型子智能体训练编排器,然后过渡到更大的模型
- 作者的 RL 框架 还 支持动态调整子智能体和编排器之间的推理实例比例,最大化集群内的资源使用率
- 在这种多智能体设置中,基于结果的奖励本质上是稀疏且有噪声的;
PARL Reward
- 由于独立子智能体执行固有的延迟、稀疏和非平稳反馈,训练一个可靠的并行编排器具有挑战性
- 为了解决这个问题,作者将 PARL 奖励定义为:
$$r_{\mathrm{PARL} }(x,y) = \lambda_{1}\cdot \underbrace{r_{\mathrm{parallel} } }_{\mathrm{instantiation reward} } + \lambda_{2}\cdot \underbrace{r_{\mathrm{finish} } }_{\mathrm{sub-agent finish rate} } + \underbrace{r_{\mathrm{perf} }(x,y)}_{\mathrm{task-level outcome} }.$$ - 解读:
- 性能奖励 \(r_{\mathrm{perf} }(x, y)\) 评估给定任务 \(x\) 的解决方案 \(y\) 的整体成功和质量
- 另外两个辅助奖励用于增强 \(r_{\mathrm{perf} }(x, y)\),每个辅助奖励都解决了学习并行编排中的一个独特挑战
- 引入奖励 \(r_{\mathrm{parallel} }\) 是为了缓解串行崩溃(一种编排器默认使用单智能体执行的局部最优)
- 通过激励子智能体实例化,该项鼓励探索并发调度空间
- 理解:多智能体训练时模型也会倾向于使用单智能体完成任务,从而陷入局部最优
- 奖励 \(r_{\mathrm{finish} }\) 专注于已分配子任务的成功完成
- 它用于防止虚假并行性,即一种 Reward Hacking 行为,其中编排器通过生成许多没有有意义的任务分解的子智能体来急剧增加并行指标
- 通过奖励完成的子任务,\(r_{\mathrm{finish} }\) 强制执行可行性,并引导策略走向有效且有效的分解
- 引入奖励 \(r_{\mathrm{parallel} }\) 是为了缓解串行崩溃(一种编排器默认使用单智能体执行的局部最优)
- 为了确保最终策略优化主要目标,超参数 \(\lambda_{1}\) 和 \(\lambda_{2}\) 在训练过程中逐渐退火至零
- 理解:这两个辅助奖励本身类似于手脚架的作用,初期用于防止陷入局部最优,或 Reward Hacking,后期可以逐步丢弃
Critical Steps as Resource Constraint(将关键步骤作为资源约束)
- 为了在并行智能体设置中衡量计算时间成本,作者类比计算图中的关键路径(Critical Path)来定义 Critical Steps
- 理解:这里的 Critical Steps 就是指步数最大的那个路径(这里应该是用步数来表示资源约束,类似时间或者 Token 量、请求数等)
- 作者将一个回合建模为一系列执行阶段,索引为 \(t = 1,\ldots ,T\)
- 在每个阶段,主智能体执行一个动作,该动作对应于直接工具调用或一组并行运行的子智能体的实例化
- 令 \(S_{\mathrm{main} }^{(t)}\) 表示主智能体在阶段 \(t\) 中采取的步数(通常 \(S_{\mathrm{main} }^{(t)} = 1\)),\(S_{\mathrm{sub},i}^{(t)}\) 表示该并行组中第 \(i\) 个子智能体采取的步数
- 阶段 \(t\) 的持续时间由该组中运行时间最长的子智能体决定
- 一个回合的总 Critical Steps 定义为:
$$\mathrm{CriticalSteps} = \sum_{t = 1}^{T}\left(S_{\mathrm{main} }^{(t)} + \max_{i}S_{\mathrm{sub},i}^{(t)}\right).$$ - 通过使用 Critical Steps而非总步骤来约束训练和评估 ,该框架明确激励有效的并行化
- 过多的子任务创建如果不能减少并行组的最大执行时间,在此指标下几乎没有好处,而平衡良好的任务分解缩短了最长的并行分支,直接减少了 Critical Steps
- 因此,鼓励编排器以最小化端到端延迟,而非仅仅最大化并发性或总工作量的方式在子智能体之间分配工作
Prompt Construction for Parallel-agent Capability Induction
- 为了激励编排器利用并行化的优势,作者构建了一套合成提示,旨在测试顺序智能体执行的极限
- 这些提示要么强调广泛搜索,需要同时探索许多独立的信息源,要么强调深度搜索,需要多个延迟聚合的推理分支
- 作者还加入了受现实世界工作负载启发的任务,例如长上下文文档分析和大规模文件下载
- 当顺序执行时,这些任务很难在固定的推理步骤和工具调用预算内完成
- 通过构造,它们鼓励编排器并行分配子任务,使得完成所需的 Critical Steps 比单个顺序智能体要少
- 重要的是,提示词没有明确指示模型进行并行化。相反,它们塑造了任务分布(Task Distribution),使得并行分解和调度策略自然地被青睐
Method Overview
Foundation: Kimi K2 Base Model
- Kimi K2.5 的基础是 Kimi K2 (2025)
- Kimi K2 是在 15 万亿高质量文本 token 上进行预训练的万亿参数 MoE Transformer
- Kimi K2 采用 token 高效的 MuonClip 优化器 (2024, 2025) 和 QK-Clip 来确保训练稳定性
- 模型参数 1.04T-A32B ,使用 384 个专家,每个 token 激活 8 个 (稀疏度为 48)
- 关于 MuonClip、架构设计和训练基础设施的详细描述,请参阅 Kimi K2 技术报告 (2025)
Model Architecture
- Kimi K2.5 的多模态架构由三个组件组成:
- 一个三维原生分辨率视觉 Encoder (MoonViT-3D)
- 一个 MLP 投影器
- Kimi K2 MoE 语言模型,遵循 Kimi-VL (2025) 建立的设计原则
MoonViT-3D: Shared Embedding Space for Images and Videos
- 在 Kimi-VL 中,作者使用 MoonViT 以原生分辨率处理图像,无需复杂的子图像分割和拼接操作
- MoonViT 由 SigLIP-SO-400M (2023) 初始化,并融合了 NaViT (2023) 的 patch 打包策略,即将单个图像划分为 patch,展平后按顺序拼接成一维序列,从而实现不同分辨率图像的高效同步训练
- 为了最大化将图像理解能力迁移到视频,作者引入了具有统一架构、完全共享参数和一致嵌入空间的 MoonViT-3D
- 通过将“patch n’ pack”理念推广到时间维度,最多四个连续帧被视为一个时空体:
- 来自这些帧的 2D patch 被联合展平并打包成一个单一的一维序列,使得相同的注意力机制可以无缝地在空间和时间上运行
- 虽然额外的时序注意力有助于理解高速运动和视觉效果,但参数的共享最大化了从静态图像到动态视频的知识泛化,无需专门的视频模块或架构分叉即可实现强大的视频理解性能(见表 4)
- 在 MLP 投影器之前,轻量级时序池化聚合每个时序块内的 patch,实现 \(4 \times\) 的时序压缩,从而显著延长可行的视频长度
- 最终形成了一个统一的流程,通过一个共享的参数空间和特征表示,将从图像预训练中获得的知识和能力整体迁移到视频中
Pre-training Pipeline
- 如表 3 所示,Kimi K2.5 的预训练基于 Kimi K2 语言模型检查点进行,分三个阶段处理大约 15T token:首先,独立的 ViT 训练以建立强大的原生分辨率视觉 Encoder ;其次,联合预训练以同时增强语言和多模态能力;第三,中期训练使用高质量数据和长上下文激活来精炼能力并扩展上下文窗口
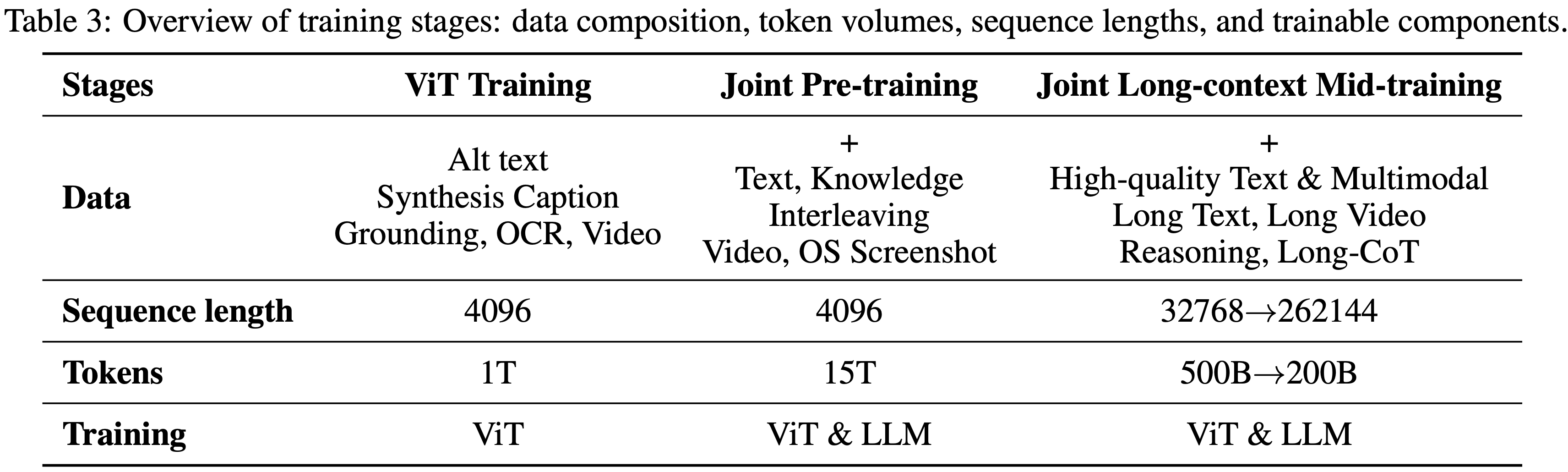
ViT Training Stage
- MoonViT-3D 在图像-文本和视频-文本对上进行训练
- 其中文本组件包含多种目标:图像替代文本(image alt texts)、图像和视频的合成描述(synthetic captions of images and videos)、定位框(grounding bboxes)和 OCR 文本(OCR texts)
- 训练遵循 CoCa (2022) 包含两个目标:SigLIP 损失 \(L_{\text{signip} }\)(对比损失的一种变体)和用于生成以输入图像为条件的描述的交叉熵损失 \(L_{\text{caption} }\)
- 作者采用两阶段对齐策略
- 第一阶段 ,作者仅优化描述生成损失 \(L_{\text{caption} }\),以使 MoonViT-3D 与 Moonlight-16B-A3B (2025) 对齐,消耗 1T token,此阶段 ViT 权重将被更新
- 第二阶段 (非常短的),仅更新 MLP 投影器以将 ViT 与 1T 的 LLM 桥接,以实现更平滑的联合预训练
Joint Training Stages
- 联合预训练阶段从接近尾声的 Kimi K2 检查点继续,在 4K 序列长度下额外处理 15T 视觉-文本 token
- 数据配方通过引入独特 token、调整数据比例(增加编码相关内容的权重)以及控制每个数据源的最大训练轮数,扩展了 Kimi K2 的预训练分布
- 第三阶段 通过集成的更高质量中期数据进行长上下文激活,通过 YaRN (2023) 插值依次扩展上下文长度
- 这在长上下文文本理解和长视频理解方面带来了显著提升
Post-Training
Supervised Fine-Tuning
- 遵循 Kimi K2 (2025) 建立的 SFT 流程,作者通过综合来自 K2、K2 Thinking 以及一系列内部专有专家模型的高质量候选响应来开发 K2.5
- 数据生成策略采用了针对特定领域量身定制的专用流程,将人工标注与先进的提示工程和多阶段验证相结合
- 这种方法产生了一个大规模的指令调优数据集,包含多样化的提示和复杂的推理轨迹,最终训练模型优先考虑交互式推理和精确的工具调用,以应对复杂的现实世界应用
Reinforcement Learning
- 为了促进跨文本和视觉模态的联合优化,以及实现用于智能体集群的 PARL,作者开发了一个统一的智能体强化学习环境(附录 D)并优化了 RL 算法
- 文本-视觉联合 RL 和 PARL 都建立在本节描述的算法之上
Policy Optimization
- 对于从数据集 \(\mathcal{D}\) 中采样的每个问题 \(x\),使用先前的策略 \(\pi_{\mathrm{old} }\) 生成 \(K\) 个响应 \(\{y_{1},\ldots ,y_{K}\}\)
- 作者针对以下目标优化模型 \(\pi_{\theta}\):
$$L_{\mathrm{RL} }(\pmb {\theta}) = \mathbb{E}_{x\sim \mathcal{D} }\left[\frac{1}{N}\sum_{j = 1}^{K}\sum_{i = 1}^{|y_j|}\mathrm{Clip}\left(\frac{\pi_{\theta}(y_j^i|x,y_j^{0;i})}{\pi_{\mathrm{old} }(y_j^i|x,y_j^{0;i})},\alpha ,\beta\right)(r(x,y_j) - \bar{r} (x)) - \tau \left(\log \frac{\pi_{\theta}(y_j^i|x,y_j^{0;i})}{\pi_{\mathrm{old} }(y_j^i|x,y_j^{0;i})}\right)^2\right]. \quad (1)$$- \(\alpha ,\beta ,\tau >0\) 是超参数
- \(y_{ij}^{0}\) 是第 \(j\) 个响应到第 \(i\) 个 token 的前缀
- \(N = \sum_{i = 1}^{K}|y_{i}|\) 是一个批次中生成 token 的总数
- \(\begin{array}{r}\bar{r} (x) = \frac{1}{K}\sum_{j = 1}^{K}r(x,y_{j}) \end{array}\) 是所有生成响应的平均奖励
- 该损失函数与 K1.5 (2025) 中使用的策略优化算法不同,它引入了 token-level 的裁剪机制,旨在减轻由训练和推理框架之间的差异放大的离策略偏差
- 该机制作为一个简单的梯度掩码方案:对于对数比在区间 \([\alpha ,\beta ]\) 内的 token,正常计算策略梯度,而对于超出此范围的 token,梯度设为零
- 与标准 PPO 裁剪的一个关键区别在于,作者的方法严格依赖于对数比来明确限制离策略漂移,而不考虑优势 (advantage) 的符号
- 这种方法与最近提出的稳定大规模 RL 训练的策略 (2025, 2025) 相一致
- 经验上,作者发现这种机制对于在需要长视野、多步骤工具使用推理的复杂领域中保持训练稳定性至关重要
- 作者使用 MuonClip 优化器 (2024, 2025) 来最小化这个目标
Reward Function
- 对于具有可验证解决方案的任务(例如推理和智能体任务),应用基于规则的结果奖励
- 为了优化资源消耗,作者还纳入了一个旨在提高 token 效率的预算控制奖励
- 对于通用任务 ,作者采用生成式奖励模型 ,它提供与 Kimi 内部价值标准一致的细粒度评估
- 问题:这里是说只使用 GRM 没有使用 BT RM 吗?
- 对于视觉任务,作者设计特定于任务的奖励函数以提供细粒度的监督
- 对于视觉定位和点定位任务,作者采用基于 F1 的软匹配奖励:定位任务从交并比 (Intersection over Union, IoU) 推导软匹配,点任务从最优匹配下的高斯加权距离推导软匹配
- 对于多边形分割任务,作者将预测的多边形栅格化为二进制掩码,并根据与真实掩码的分割 IoU 来计算奖励
- 对于 OCR 任务,作者采用归一化编辑距离来量化预测与真实值之间的字符级对齐
- 对于计数任务,根据预测与真实值的绝对差异分配奖励
- 此外,作者合成了复杂的视觉谜题问题,并利用 LLM 验证器 (Kimi K2) 来提供反馈
- 对于通用任务 ,作者采用生成式奖励模型 ,它提供与 Kimi 内部价值标准一致的细粒度评估
Generative Reward Models
- Kimi K2 利用自评标准奖励 (self-critique rubric reward) 进行开放式生成 (2025),K2.5 通过系统性地在广泛的智能体行为和多模态轨迹上部署 GRMs 来扩展这项工作
- 作者不仅将奖励建模局限于对话输出,还在多样化环境中的已验证奖励信号之上应用 GRMs,包括聊天助手、编码智能体、搜索智能体和工件生成智能体
- 值得注意的是,GRMs 的功能不是二元判定者,而是与 Kimi 价值观一致的细粒度评估器 ,这些价值观对用户体验至关重要 ,例如有帮助性、响应就绪度、上下文相关性、细节的适当程度、生成工件的审美质量以及严格遵守指令
- 这种设计使得奖励信号能够捕捉细微的偏好梯度,这些梯度很难用纯粹的基于规则或特定任务的验证器编码
- 为了减轻奖励黑客攻击和对单一偏好信号的过拟合,作者采用了多个针对不同任务上下文量身定制的替代 GRM 标准
- 理解:这里是在说更多地使用 GRM 来作为奖励信号
Token Efficient Reinforcement Learning
- Token 效率对于具有测试时缩放 (test-time scaling) 的 LLM 至关重要
- 虽然测试时缩放本质上是计算与推理质量的权衡,但实际增益需要算法创新来积极驾驭这种权衡
- 作者之前的发现表明:
- 施加依赖于问题的预算 (problem-dependent budget) 可以有效限制推理时计算,激励模型生成更简洁的思维链推理模式,避免不必要的 token 扩展 (2025, 2025)
- 但作者也观察到长度过拟合现象:
- 在严格预算约束下训练的模型往往无法泛化到更高的计算规模
- 因此,它们无法有效利用额外的推理时 token 来解决复杂问题,而是退回到截断的推理模式
- 为此,作者提出 Toggle
- Taggle 是一种在推理时缩放和预算约束优化之间交替的训练启发式方法:对于学习迭代 \(t\),奖励函数定义为
$$
\begin{align}
\tilde{r}(x, y) =
\begin{cases}
r(x, y) \cdot \mathbb{I} \{ \frac{1}{K}\sum_{i=1}^{K} r(x, y_i) < \lambda \text{ or } |y_i| \leq \text{budget}(\mathrm{x}) \} & \text{if } \lfloor t/m \rfloor (\text{mod}2) = 0 \ (\text{Phase0}) \\
r(x, y) & \text{if } \lfloor t/m \rfloor (\text{mod}2) = 1 \ (\text{Phase1})
\end{cases}
\end{align}
$$- 其中 \(\lambda\) 和 \(m\) 是算法的超参数,\(K\) 是每个问题的 Rollout 数量
- 具体来说,算法每 \(m\) 次迭代在两个优化阶段之间交替:
- Phase0 (budget limited phase) : 模型被训练在依赖于任务的 token 预算内解决问题
- 为了防止过早地牺牲质量换取效率 ,该约束是条件性应用的:仅当模型对给定问题的平均准确率超过阈值 \(\lambda\) 时才强制执行
- Phase1 (standard scaling phase) : 模型生成响应直到最大 token 限制,鼓励模型利用计算实现更好的推理时缩放
- Phase0 (budget limited phase) : 模型被训练在依赖于任务的 token 预算内解决问题
- 依赖于问题的预算从正确响应子集中的 token 长度的 \(\rho\) 分位数估计得出:
$$\mathrm{budget}(x) = \mathrm{Percentile}(\{|y_j| |r(x,y_i) = 1,i = 1,\ldots ,K\} ,\rho). \quad (2)$$- 该预算在训练开始时估计一次,之后保持固定
- Toggle 作为一个针对双目标问题的随机交替优化函数:它专门设计用于协调推理能力与计算效率
- Taggle 是一种在推理时缩放和预算约束优化之间交替的训练启发式方法:对于学习迭代 \(t\),奖励函数定义为
- 作者在 K2 Thinking (2025) 上评估了 Toggle 的有效性
- 如图 5 所示,作者观察到在几乎所有基准测试中输出长度持续减少
- 平均而言,Toggle 将输出 token 减少了 \(25\sim 30%\),对性能的影响可忽略不计
- 作者还观察到,思维链中的冗余模式,例如重复验证和机械计算,显著减少
- 此外,Toggle 显示出强大的领域泛化能力
- 例如,仅在数学和编程任务上训练时,模型在 GPQA 和 MMLU-Pro 上仍然实现了一致的 token 减少,而性能仅有轻微下降(图 5)
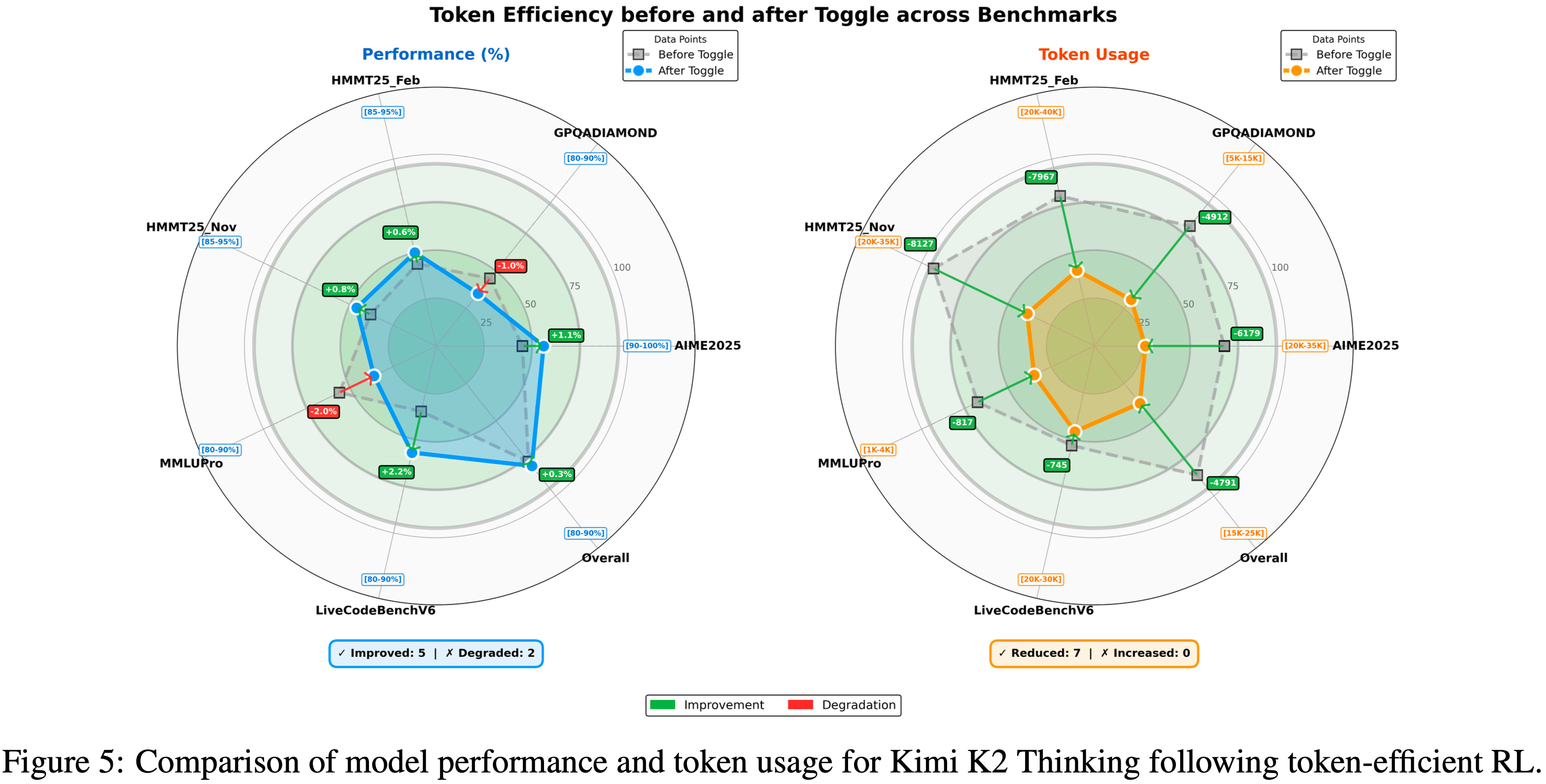
- 例如,仅在数学和编程任务上训练时,模型在 GPQA 和 MMLU-Pro 上仍然实现了一致的 token 减少,而性能仅有轻微下降(图 5)
Training Infrastructure
- Kimi K2.5 继承了 Kimi K2 (2025) 的训练基础设施
- 对于多模态训练,作者提出了解耦 Encoder 进程 (Decoupled Encoder Process, DEP),其中视觉 Encoder 以可忽略的额外开销纳入现有流程
Decoupled Encoder Process, DEP
- 在使用流水线并行 (PP) 的典型多模态训练范式中,视觉 Encoder 和文本嵌入共同位于流水线的第一阶段 (Stage-0)
- 但由于多模态输入大小(例如图像数量和分辨率)的固有变化,Stage-0 的计算负载和内存使用都存在剧烈波动
- 这迫使现有解决方案为视觉-语言模型采用定制的 PP 配置
- 例如,(2025) 手动调整 Stage-0 中的文本解码器层数以预留内存
- 虽然这种折衷缓解了内存压力,但并没有从根本上解决由多模态输入大小引起的负载不平衡问题
- 更重要的是,它排除了直接复用已为纯文本训练高度优化的并行策略
- 利用视觉 Encoder 在计算图中的独特拓扑位置,特别是它作为前向传播的开始和后向传播的终点,作者的训练使用解耦 Encoder 进程 (DEP) ,每个训练步骤由三个阶段组成:
- 1)平衡视觉前向 (Balanced Vision Forward) : 作者首先执行全局批次中所有视觉数据的前向传播。由于视觉 Encoder 较小,作者无论其他并行策略如何,都将其复制到所有 GPU 上。在此阶段,前向计算工作负载根据负载指标(例如图像或 patch 数量)均匀分布在所有 GPU 上。这消除了由 PP 和视觉 token 计数引起的负载不平衡。为了最小化峰值内存使用,作者丢弃所有中间激活,仅保留最终输出激活。结果被收集回 PP 的 Stage-0
- 2)主干训练 (Backbone Training) : 此阶段执行主 Transformer 主干的前向和后向传播。通过丢弃前一阶段的中间激活,作者现在可以完全利用在纯文本训练中验证过的任何高效并行策略。在此阶段之后,梯度在视觉 Encoder 输出处累积
- 3)视觉重计算与后向 (Vision Recomputation & Backward) : 作者重新计算视觉 Encoder 的前向传播,然后执行后向传播以计算视觉 Encoder 参数的梯度
- DEP 不仅实现了负载平衡,还解耦了视觉 Encoder 和主主干的优化策略
- K2.5 无缝继承了 K2 的并行策略,相对于纯文本训练,实现了 \(90%\) 的多模态训练效率
- 作者注意到一个同期工作,LongCat-Flash-Omni (2025),分享了类似的设计理念
Evaluations
Main Results
Evaluation Settings
Benchmark
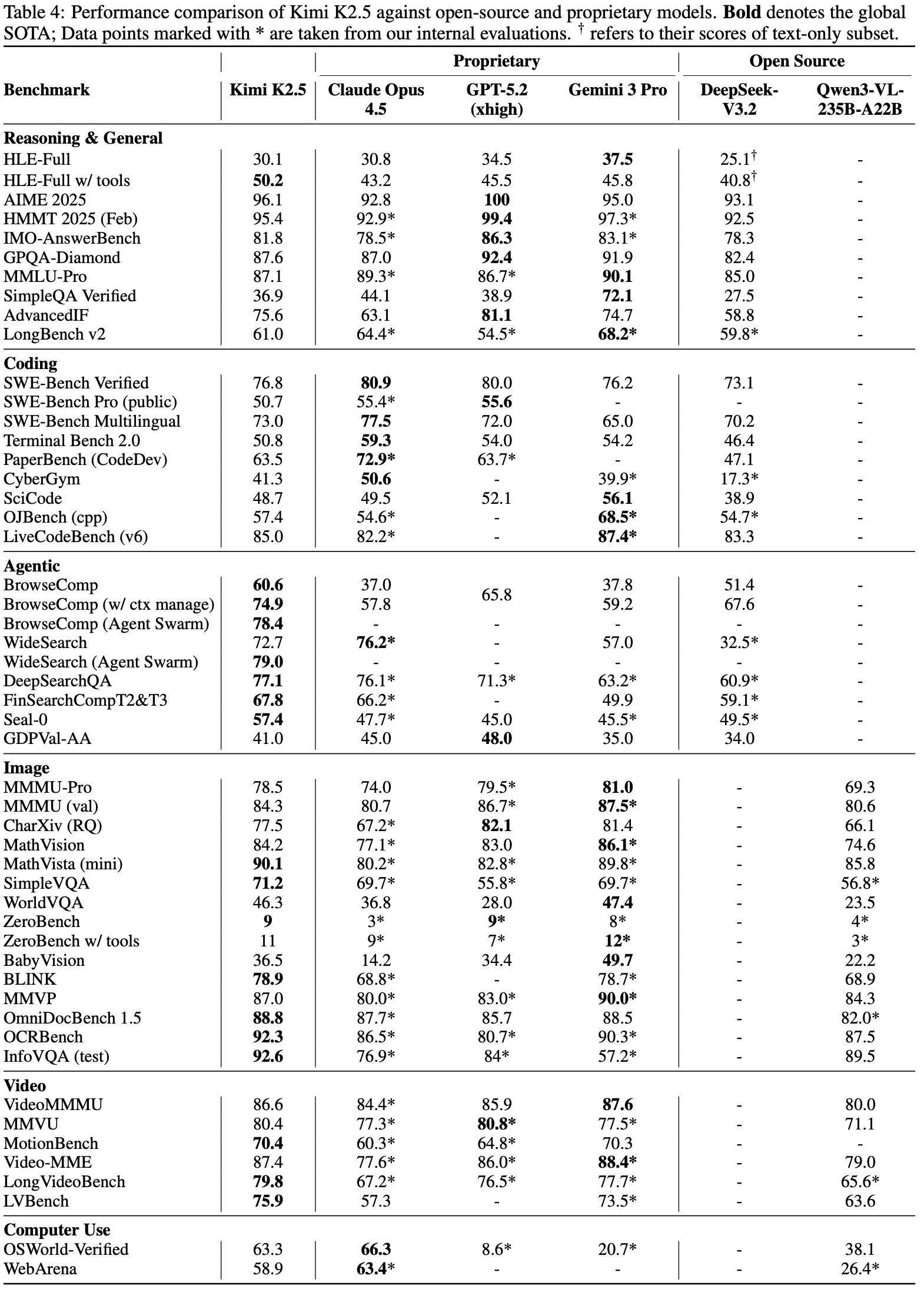
- 作者在一个全面的基准测试套件上评估 Kimi K2.5,涵盖基于文本的推理、竞争性和智能体编码、多模态理解(图像和视频)、自主智能体执行和计算机使用
- 作者的基准分类法按以下能力轴组织:
- Reasoning & General:人类的最后考试 (HLE) (2025)、2025年美国数学邀请赛 (AIME 2025) (2025)、哈佛-麻省理工数学锦标赛 (HMMT 2025) (2025)、IMO-AnswerBench (2025)、GPQA-Diamond (2024)、MMLU-Pro (2024)、SimpleQA Verified (2025)、AdvancedIF (2025) 和 LongBench v2 (2025)
- Coding:SWE-Bench Verified (2023)、SWE-Bench Pro (public) (2025)、SWE-Bench Multilingual (2023)、Terminal Bench 2.0 (2026)、PaperBench (CodeDev) (2025)、CyberGym (2025)、SciCode (2024)、OJBench (cpp) (2025) 和 LiveCodeBench (v6) (2024)
- Agentic Capabilities:BrowseComp (2025)、WideSearch (2025)、DeepSearchQA (2025)、FinSearchComp (T2&T3) (2025)、Seal-0 (2025)、GDPVal (2025)
- Image Understanding:(数学与推理)MMMU-Pro (2025)、MMMU (val) (2024)、CharXiv (RQ) (2024)、Math-Vision (2024) 和 MathVista (mini) (2024);(视觉知识)SimpleVQA (2025) 和 WorldVQA 2;(感知)ZeroBench(带/不带工具)(2025)、BabyVision (2026)、BLINK (2024) 和 MMVP (2024);(OCR 和文档)OCR-Bench (2024)、OmniDocBench 1.5 (2025) 和 InfoVQA (2021)
- Video Understanding:VideoMMMU (2025)、MMVU (2025)、MotionBench (2025)、Video-MME (2025)(带字幕)、LongVideoBench (2024) 和 LVBench (2025)
- Computer Use:OSWorld-Verified (2025, 2024) 和 WebArena (2023)
Baselines
- 作者以 SOTA 闭源和开源模型作为基准
- 闭源模型:Claude Opus 4.5(带扩展思考)(2025)、GPT-5.2(带 xhigh 推理力度)(2025) 和 Gemini 3 Pro(带高推理级别)
- 开源模型:
- 文本基准测试:包括 DeepSeek-V3.2(启用思考模式)(2025)
- 视觉基准测试:报告 Qwen3-VL-235B-A22B-Thinking (2025)
Evaluation Configurations
- 除非另有说明,所有 Kimi K2.5 评估都使用
temperature = 1.0,top-p = 0.95,上下文长度为 256k tokens - 对于没有公开分数的基准测试,在相同条件下重新评估,并标有星号 (*)
- 完整的评估设置可以在附录 E 中找到
Evaluation Results
- 表 4 展示了将 Kimi K2.5 与专有和开源基线模型进行比较的综合结果
Reasoning and General
- Kimi K2.5 在严格的 STEM 基准测试上与顶级专有模型相比具有竞争力
- 数学任务:
- AIME 2025,K2.5 得分 \(96.1%\),接近 GPT-5.2 的满分,同时优于 Claude Opus 4.5 (92.8%) 和 Gemini 3 Pro (95.0%)
- HMMT 2025 (95.4%) 和 IMO-AnswerBench (81.8%),展示了 K2.5 卓越的推理深度
- 知识和科学推理能力
- SimpleQA Verified 上得分 36.9%;MMLU-Pro 上得分 87.1%;在 GPQA 上得分 87.6%
- 在不使用工具的情况下,K2.5 在 HLE 上获得了 30.1% 的 HLE-Full 分数,其中文本子集得分 31.5%,图像子集得分 21.3%
- 当启用工具使用时,K2.5 的 HLE-Full 分数上升到 50.2%,其中文本 51.8%,图像 39.8%,显著优于 Gemini 3 Pro (45.8%) 和 GPT-5.2 (45.5%)
- 除了推理和知识外,K2.5 在指令遵循(AdvancedIF 上 75.6%)和长上下文能力(LongBench v2 上 61.0%)方面也表现出色,与专有和开源模型相比都很有竞争力
- 数学任务:
Complex Coding and Software Engineering
- Kimi K2.5 表现出强大的软件工程能力,尤其是在现实世界的编码和维护任务上
- 在 SWE-Bench Verified 上取得 76.8% 的成绩,在 SWE-Bench Multilingual 上取得 73.0%,优于 Gemini 3 Pro,同时与 Claude Opus 4.5 和 GPT-5.2 保持竞争力
- 在 LiveCodeBench v6 上,Kimi K2.5 达到 85.0%,超过了 DeepSeek-V3.2 (83.3%) 和 Claude Opus 4.5 (82.2%),突显了其在实时、持续更新的编码挑战上的稳健性
- 在 TerminalBench 2.0、PaperBench 和 SciCode 上,它分别得分 50.8%、63.5% 和 48.7%,展示了在不同领域的自动化软件工程和问题解决中稳定的竞争水平性能
- 此外,K2.5 在 CyberGym 上获得 41.3 分,该任务是在仅给定弱点高级描述的情况下,在真实开源软件项目中查找先前发现的漏洞,进一步强调了其在面向安全的软件分析中的有效性
Agentic Capabilities
- Kimi K2.5 在复杂的智能体搜索和浏览任务上确立了新的最先进性能
- 在 BrowseComp 上,K2.5 在不使用上下文管理技术的情况下达到 60.6%,在使用 Discard-all 上下文管理 (2025) 的情况下达到 74.9%,显著优于 GPT-5.2 报告的 65.8%、Claude Opus 4.5 (37.0%) 和 Gemini 3 Pro (37.8%)
- WideSearch 在 item-F1 上达到 72.7%
- 在 DeepSearchQA (77.1%)、FinSearchComp T2&T3 (67.8%) 和 Seal-0 (57.4%) 上,K2.5 在所有评估模型中领先,展示了其在智能体深度研究、信息综合和多步骤工具编排方面的卓越能力
Vision Reasoning, Knowledge and Perception
- Kimi K2.5 展示了强大的视觉推理和世界知识能力
- 在 MMMU-Pro 上得分 \(78.5%\),涵盖多学科多模态任务
- 对于世界知识问答:
- K2.5 在 SimpleVQA 上取得 \(71.2%\),在 WorldVQA 上取得 \(46.3%\)
- 对于视觉推理
- K2.5 在 MathVision 上取得 \(84.2%\),在 MathVista (mini) 上取得 \(90.1%\),在 BabyVision 上取得 \(36.5%\)
- 对于 OCR 和文档理解
K2.5 在 CharXiv (RQ) 上为 \(77.5%\),在 OCRBench 上为 \(92.3%\),在 OmniDocBench 1.5 上为 \(88.8%\),在 InfoVQA (test) 上为 \(92.6%\) - 在具有挑战性的 ZeroBench 上,Kimi K2.5 在使用工具增强的情况下达到 \(9%\) 和 \(11%\),大幅领先于竞争模型
- 在基础视觉感知基准测试 BLINK (\(78.9%\)) 和 MMVP (\(87.0%\)) 上,Kimi K2.5 具有竞争力的性能,展示了其稳健的现实世界视觉感知能力
Video Understanding
- Kimi K2.5 在不同的视频理解任务上取得了 SOTA 性能
- 在 VideoMMMU 上达到 \(86.6%\),在 MMU 上达到 \(80.4%\),与前沿模型对齐
- 借助 MoonViT-3D 的上下文压缩和密集时间理解能力,Kimi K2.5 还通过在长视频理解(LVBench 上 \(75.9%\) 和 LongVideoBench 上 \(79.8%\),输入超过 2000 帧)上创造了新的全球 SOTA 记录,同时在高度维度的 MotionBench 上展示了稳健的密集运动理解能力 (\(70.4%\))
Computer-Use Capability
- Kimi K2.5 在现实世界任务上展示了 SOTA 计算机使用能力
- 在计算机使用基准测试 OSWorld-Verified (2025, 2024) 上,仅依靠 GUI 操作而不使用外部工具,实现了 \(63.3%\) 的成功率
- 这显著优于开源模型,如 Qwen3-VL-235B-A22B (\(38.1%\)) 和 OpenAI 的计算机使用智能体框架 Operator (基于 o3) (\(42.9%\)),同时与当前领先的 CUA 模型 Claude Opus 4.5 (\(66.3%\)) 保持竞争力
- 在 WebArena (2023) 上(一个基于 GUI 的网页浏览的成熟基准测试),Kimi K2.5 实现了 \(58.9%\) 的成功率,超过了 OpenAI 的 Operator (\(58.1%\)),并接近 Claude Opus 4.5 的性能 (\(63.4%\))
- 在计算机使用基准测试 OSWorld-Verified (2025, 2024) 上,仅依靠 GUI 操作而不使用外部工具,实现了 \(63.3%\) 的成功率
Agent Swarm Results
Benchmarks
- 为了严格评估智能体群框架的有效性,作者选择了三个代表性基准测试,共同覆盖深度推理、大规模检索和现实世界复杂性:
- BrowseComp :一个具有挑战性的深度研究基准测试,需要多步骤推理和复杂的信息综合
- WideSearch :一个旨在评估跨多样来源进行广泛、多步骤信息搜索和推理能力的基准测试
- 内部群基准测试 (In-house Swarm Bench) :一个内部开发的群基准测试,旨在评估智能体群在现实世界、高复杂性条件下的性能;涵盖四个领域:
- WildSearch(在开放网络上的无约束、现实世界信息检索)
- Batch Download(大规模获取多样资源)
- WideRead(涉及超过 100 个输入文档的大规模文档理解)
- Long-Form Writing(连贯生成超过 10 万字的广泛内容)
- 该基准测试包含极端规模的场景,对基于智能体的系统的编排、可扩展性和协调能力进行压力测试
Performance
- 表 6 展示了 Kimi K2.5 Agent Swarm 相对于单智能体配置和专有基线的性能:结果表明,多智能体编排带来了显著的性能提升
- 在 BrowseComp 上,Agent Swarm 达到 \(78.4%\),相比单智能体 K2.5 (60.6%) 提高了 \(17.8%\) 的绝对增益,甚至超过了 GPT-5.2 Pro (\(77.9%\))
- 类似地,WideSearch 在 Item-F1 上提升了 \(6.3%\) (\(72.7% \rightarrow\) \(79.0%\)),使 K2.5 Agent Swarm 优于 Claude Opus 4.5 (\(76.2%\)),并确立了新的 SOTA
- 提升在内部群基准测试 (\(16.7%\)) 上最为显著,那里的任务明确设计为奖励并行分解
- 这些在基准测试上的一致性改进验证了 Agent Swarm 有效地将计算并行性转化为定性能力提升,特别是对于需要广泛探索、多源验证或同时处理独立子任务的问题

Execution Time Savings via Parallelism
- 除了改善任务性能外,Agent Swarm 通过并行执行子智能体实现了显著的挂钟时间减少
- 在 WideSearch 基准测试上,与单智能体基线相比,它将达到目标性能所需的执行时间减少了 \(3\times \sim 4.5\times\)
- 如图 8 所示
- 这种效率增益随任务复杂性而缩放:随着目标 Item-F1 从 \(30%\) 增加到 \(70%\),单智能体的执行时间从大约基线的 \(1.8\times\) 增长到超过 \(7.0\times\),而 Agent Swarm 则保持接近恒定的低延迟,范围在 \(0.6\times \sim 1.6\times\)
- 这些结果表明,Agent Swarm 有效地将顺序工具调用转换为并行操作,防止了通常随着任务难度增加而观察到的完成时间线性增长
Dynamic Subagent Creation and Scheduling
- 在智能体群中,子智能体是动态实例化的,而非预先定义的
- 通过 PARL,编排器学习自适应策略,以根据演化的任务结构和问题状态来创建和调度自托管的子智能体
- 与静态分解方法不同,这种学习到的策略使 Orchestrator 能够根据查询来推理所需的子智能体数量、时机和专业化程度
- 异构的智能体组从这种自适应分配策略中自然出现(图 6)

- 异构的智能体组从这种自适应分配策略中自然出现(图 6)
Agent Swarm as Proactive Context Management
- 除了更好的性能和运行时加速外,智能体群是一种由多智能体架构 (2026) 实现的主动且智能的上下文管理方法
- 这种方法不同于测试时上下文截断策略,如 Hide-Tool-Result (2025)、Summary (2025) 或 Discard-all (2025),这些策略通过压缩或丢弃累积的历史记录来应对上下文溢出
- 虽然这些方法在减少 token 使用方面有效,但它们本质上是反应性的,并且常常牺牲结构信息或中间推理
- Agent Swarm 通过显式的编排实现主动的上下文控制
- 长视距任务被分解为并行、语义上隔离的子任务,每个子任务由一个具有有限本地上下文的专用子智能体执行
- 这些子智能体保持独立的工作记忆并进行本地推理,而不会直接改变或污染中央编排器的全局上下文
- 只有任务相关的输出,而不是完整的交互轨迹,被有选择地路由回编排器
- Agent Swarm 的这种设计得到的是上下文分片,而不是上下文截断 ,使系统能够沿额外的架构维度扩展有效上下文长度,同时保持模块化、信息局部性和推理完整性
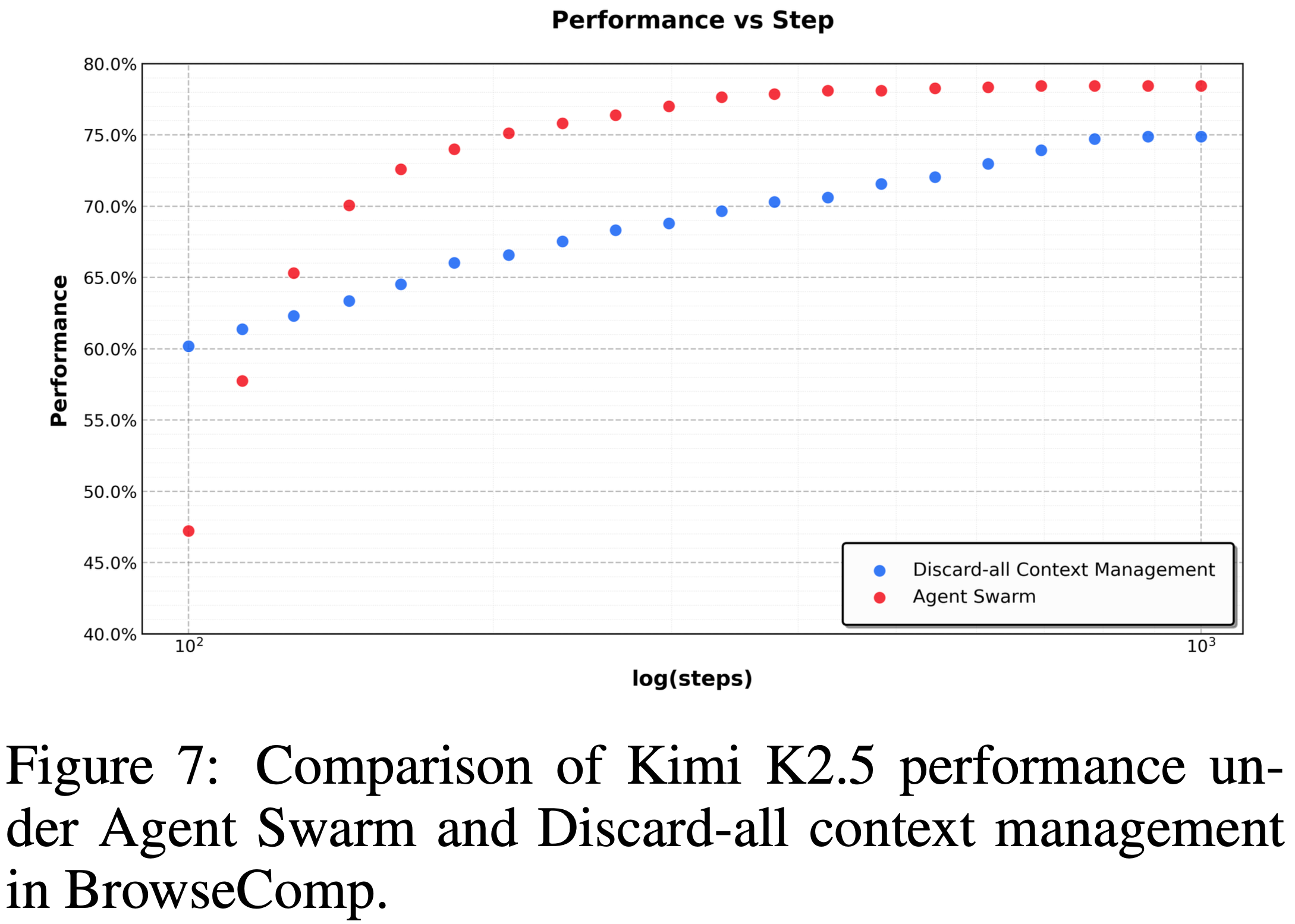
- 如图 7 所示,这种主动策略在 BrowseComp 上的效率和准确性都优于 Discard-all
- 通过在编排器级别保持任务级连贯性,同时保持子智能体上下文严格受限,Agent Swarm 实现了具有选择性上下文持久性的并行执行,仅保留高级协调信号或必要的中间结果
- Agent Swarm 作为一个主动的、结构化的上下文管理器运行,以比均匀上下文截断少得多的 Critical Steps 实现更高的准确性
附录 B:Pre-training
Joint-Training
- 作者在图 9 中进一步提供了所有配置的完整训练曲线
- 在 mid-fusion 和 late-fusion 阶段,文本性能出现“下降-恢复”的模式:当首次引入视觉数据时,文本能力最初会下降,然后逐渐恢复
- 作者将此归因于模态领域的转变(视觉 token 的突然引入扰乱了已建立的语言表示空间,迫使模型暂时牺牲文本特定能力以换取跨模态对齐)
- early fusion 在整个训练过程中保持了更健康、更稳定的文本性能曲线
- 通过从一开始就共同优化视觉和语言,模型自然地演化出统一的多模态表示,而无需经历后期领域迁移的冲击
- 这表明早期暴露不仅防止了在 late fusion 中观察到的表示崩溃,还为两种模态提供了更平滑的梯度景观
- 在 mid-fusion 和 late-fusion 阶段,文本性能出现“下降-恢复”的模式:当首次引入视觉数据时,文本能力最初会下降,然后逐渐恢复
- 总的来说,这些发现强化了作者关于原生多模态预训练 (native multimodal pre-training) 的提议:适度的视觉比例与早期融合相结合,在固定的 token 预算下能产生更优越的收敛特性和更稳健的双模态能力
Text data
- Kimi K2.5 预训练文本语料库包含精选的高质量数据,涵盖四个主要领域:网络文本 (Web Text)、代码 (Code)、数学 (Mathematics) 和知识 (Knowledge)
- 大多数数据处理流程遵循 Kimi K2 (2025) 中概述的方法
- 对于每个领域,作者执行了严格的正确性和质量验证,并设计了有针对性的数据实验,以确保精选数据集同时实现高多样性和有效性
增强的代码智能
- 作者提升了以代码为中心的数据权重,显著扩展了以下内容:
- (1) 支持跨文件推理和架构理解的仓库级代码 (repository-level code)
- (2) 来自互联网的 issues、代码审查和提交历史,捕获了真实的开发模式
- (3) 从 PDF 和网页文本语料库中检索到的与代码相关的文档
- 这些努力增强了针对复杂编码任务的仓库级理解能力,提高了在代理式编码子任务(如补丁生成和单元测试编写)上的表现,并增强了与代码相关的知识能力
Vision data
- 作者的多模态预训练语料库包括七个类别:字幕 (caption)、交错数据 (interleaving)、OCR、知识 (knowledge)、感知 (perception)、视频 (video) 和代理数据 (agent data)
- 字幕数据 (caption data) (2022, 2024) 提供了基础的模态对齐,并对合成字幕施加了严格的限制以减轻幻觉
- 来自书籍、网页和教程的图像-文本交错数据 (image-text interleaving data) (2024, 2024) 使得多图像理解和长上下文学习成为可能
- OCR 数据涵盖多语言文本、密集布局和多页文档。知识数据 (knowledge data) 包含通过布局解析器处理的学术材料,以发展视觉推理能力
- 作者精选了一个专门的多模态问题解决语料库,以加强科学、技术、工程和数学领域的推理能力
- 这些数据通过有针对性的检索和网络爬虫进行聚合;对于缺乏明确查询格式的信息内容,作者采用上下文学习 (in-context learning) (2020) 自动将原始材料重新格式化为涵盖 K-12 到大学级别的结构化学术问题
- 为了弥合视觉布局与代码数据之间的模态差距,作者纳入了大量的图像-代码配对数据
- 包括多种代码格式,如 HTML、React 和 SVG 等,以及它们对应的渲染截图,使得模型能够将抽象的结构逻辑与具体的视觉几何形状对齐
- 对于代理和时间理解,作者收集了跨桌面、移动和网络环境的 GUI 截图和操作轨迹,包括人工标注的演示
- 来自不同来源的视频数据实现了长达数小时的视频理解和细粒度的时空感知
- 此外,作者加入了 grounding 数据以增强细粒度视觉定位能力,包括感知标注(边界框)、基于点的参考
- 作者还引入了一个新的轮廓级分割任务 (contour-level segmentation task) (2026) 用于像素级感知学习
- 所有数据都经过严格的过滤、去重和质量控制,以确保高度的多样性和有效性
附录 C:Infra
- Kim K2.5 在 NVIDIA H800 GPU 集群上进行训练,节点间使用 \(8\times 400\) Gbps RoCE 互连
- 作者采用了灵活的并行策略,结合了 16 路 PP 与 virtual stages (2019, 2021),16 路专家并行 (EP) (2020),以及 ZeRO-1 数据并行 (DP),使得可以在任意为 32 倍数的节点数上进行训练
- 在交错的 1F1B 调度下,EP 的 all-to-all 通信与计算重叠
- 为了将激活值容纳在 GPU 内存限制内,作者对 LayerNorm、SwiGLU 和 MLA up-projections 应用了选择性重计算 (selective recomputation),将不敏感的激活值压缩到 FP8-E4M3,并将剩余的激活值以重叠流式方式卸载到 CPU
Data Storage and Loading
- 作者使用云服务商的 S3 (2023) 兼容对象存储解决方案来存放作者的 VLM 数据集
- 为了弥合数据准备和模型训练之间的差距,作者将视觉数据以其原生格式保留,并设计了一个高效且适应性强的基础设施
- 该基础设施提供了几个关键优势:
- 灵活性:在整个训练过程中支持动态数据打乱、混合、 Token 化、损失掩码和序列打包,能够根据需求变化调整数据比例;
- 增强:允许对视觉和文本模态进行随机增强,同时在几何变换过程中保持 2D 空间坐标和方向元数据的完整性;
- 确定性:通过精细管理随机种子和工作进程状态,保证完全确定的训练,确保任何训练中断都可以无缝恢复——恢复后的数据序列与不间断运行的序列保持一致;
- 可扩展性:通过分级缓存机制实现卓越的数据加载吞吐量,能够稳健地扩展到大型分布式集群,同时将对象存储的请求频率控制在可接受的范围内
- 此外,为了维护统一的数据集质量标准,作者构建了一个统一平台,负责数据注册、可视化、统计分析、跨云同步和生命周期治理
附录 D:Unified Agentic Reinforcement Learning Environment
Environment
- 为了支持统一的代理式强化学习,作者的强化学习框架采用了一个标准化的 Gym-like (2016) 接口 来简化不同环境的实现
- 这种设计使用户能够以最小的开销实现和定制环境。作者的设计优先考虑组合模块化,集成了一套可插拔的组件,例如用于支持带有沙盒的各种工具的 Toolset 模块、用于多方面奖励信号的 Judge 模块 ,以及用于提示多样化和指令遵循增强的专用模块
- 这些组件可以与核心代理循环动态组合,提供高度灵活性并增强模型泛化能力
- 在执行层面,作者的强化学习框架将每个代理任务视为一个独立的异步协程
- 每个任务可以递归地触发子任务 rollouts,简化了复杂多智能体范式(如并行代理强化学习 (Parallel-Agent RL) 和“代理即裁判 (Agent-as-Judge)”)的实现
- 如图 10 所示,一个专用的 Rollout Manager 在强化学习过程中协调多达 100,000 个并发代理任务,提供细粒度控制以实现诸如部分 rollout (2025) 等功能
- 激活后,每个任务从受管理的池中获取一个环境实例,该实例配备了一个沙盒和专用工具
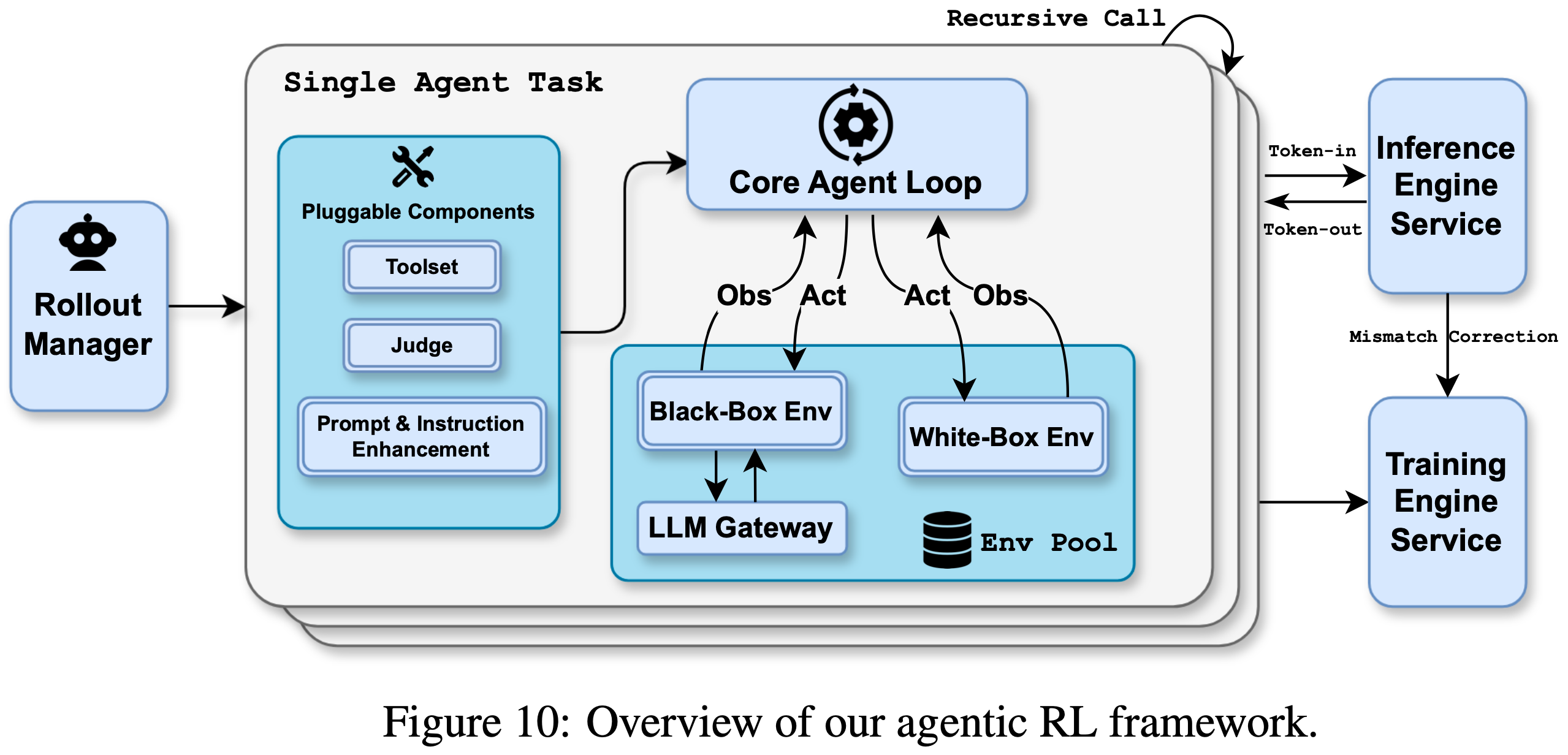
- 激活后,每个任务从受管理的池中获取一个环境实例,该实例配备了一个沙盒和专用工具
Inference Engine Co-design
- 作者的框架严格遵循 Token-in-Token-out 范式
- 理解:即模型的输入和输出都是 Token
- 作者还记录了所有推理引擎输出的对数概率,以执行训练-推理不匹配校正,确保强化学习训练的稳定性
- 针对强化学习需求的推理引擎协同设计让我们能够通过为强化学习定制的推理 API 来支持这些功能
- 除了全套内置的白盒环境外,还有只能在标准 LLM API 协议下运行的黑盒环境,它们无法利用作者自定义 API 协议提供的高级功能
- 为了在黑盒环境下促进模型优化,作者开发了 LLM Gateway,这是一个代理服务,用于在作者的自定义协议下详细记录 rollout 请求和响应
Monitoring and debugging
- 在确保正确性的同时,优化高度并行的异步执行系统的性能是一项具有挑战性的任务
- 作者开发了一系列用于性能监控、性能剖析、数据可视化和数据验证的工具。作者发现这些工具对于调试以及确保作者代理式强化学习的效率和正确性至关重要
附录 E:Evaluation Settings
- 本节为表 4 中报告的所有基准测试提供了全面的配置细节和测试协议
General Evaluation Protocol
- 除非另有明确说明,否则所有 Kimi-K2.5 的实验均遵循以下超参数配置:
- Temperature: 1.0
- Top-p: 0.95
- Context Length: 256k tokens
Baselines
- 对于基线模型,作者在它们各自的高性能推理配置下报告结果:
Claude Opus 4.5: 扩展思维模式 (Extended thinking mode)
GPT-5.2: 最大推理努力 (Maximum reasoning effort (xhigh))
Gemini 3 Pro: 高思维等级 (High thinking level)
DeepSeek-V3.2: 启用思维模式 (Thinking mode enabled)(仅用于纯文本基准测试)
Qwen3-VL-235B-A22B: 思维模式 (Thinking mode)(仅用于视觉基准测试) - 对于视觉和多模态基准测试,GPT-5.2-xhigh 在视觉评估中表现出大约 \(10%\) 的失败率(即,尽管有三次重试尝试,但没有生成输出)
- 这些失败被视为错误预测,这意味着报告的分值可能是模型真实能力的保守下界
- 此外,由于作者无法持续访问稳定的 GPT-5.2 API ,作者跳过了一些评估成本较高的基准测试,例如 WideSearch
Text Benchmarks
Reasoning Benchmarks
- 对于高复杂度推理基准测试,包括 HLE-Full、AIME 2025、HMMT 2025、GPQA-Diamond 和 IMO-AnswerBench,作者强制执行最大 96k token 的完成预算,以确保足够的推理深度
- 为了减少由随机推理路径引起的方差,AIME 2025 和 HMMT 2025 (Feb) 的结果是 64 次独立运行的平均值 (Avg@64),而 GPQA-Diamond 是 8 次运行的平均值 (Avg@8)
LongBench v2
- 为了公平比较,作者使用与 (2025) 中相同的截断策略将所有输入上下文标准化为大约 128k token
- 作者观察到 GPT5.2-xhigh 经常产生自由形式的问答风格响应,而不是所需的多选格式
- 因此,作者报告使用 GPT5.2-high 的结果,它能始终遵循预期的输出格式
Image and Video Benchmarks
- 所有图像和视频理解评估均使用以下配置:
- Maximum Tokens: 64k
- Sampling: 3 次独立运行的平均值 (Avg@3)
ZeroBench(w/ tools)
- 多步推理评估使用约束的逐步生成:
- Max Tokens per Step: 24k
- Maximum Steps: 30
MMMU-Pro
- 作者严格遵循官方评估协议:保留所有模态的输入顺序,按照基准指南的规定将图像预置到文本序列之前
Sampling Strategies for Video Benchmarks
- 对于短视频基准测试(VideoMMMU、MMVU & MotionBench),作者采样 128 个均匀输入帧,最大空间分辨率为 896;
- 对于长视频基准测试(Video-MME、LongVideoBench & LVBench),采样 2048 个均匀帧,空间分辨率为 448
pecialized Metrics
- OmniDocBench 1.5: 分值计算为 \((1 - 标准化的莱文斯坦距离 (normalized Levenshtein distance)) \times 100\),数值越高表示 OCR 和文档理解准确率越高
- WorldVQA: 访问地址:https://github.com/MoonshotAI/WorldVQA。该基准测试评估需要细粒度视觉识别和地理理解的原子化、视觉中心的世界知识
Coding and Software Engineering
Terminal Bench 2.0
- 所有分值均使用默认的 Terminus-2 agent 框架和提供的 JSON 解析器获得
- 作者在非思维模式下进行评估,因为目前针对思维模式的上下文管理实现在技术上与 Terminus-2 的对话状态处理不兼容
- 问题:这个是不能改的吗?
SWE-Bench 系列
- 作者使用一个内部开发的评估框架,其包含最小工具集:bash, create_file, insert, view, str_replace, 和 submit
- System prompts 专门针对仓库级代码操作而定制
- 在所有 SWE-Bench 变体(Verified、Multilingual 和 Pro)中,非思维模式下达到峰值性能
CyberGym
- 根据其技术文档中的规定,Claude Opus 4.5 在此基准测试下的结果是在非思维设置下报告的
- 作者报告难度等级 1(主要设置)下的分值
PaperBench
- 作者报告 CodeDev 设置下的分值
Sampling
- 所有编码任务结果均为 5 次独立运行的平均值 (Avg@5),以确保跨环境初始化和非确定性测试用例排序的稳定性
Agentic Evaluation
Tool Setting
- Kimi-K2.5 为所有代理式评估配备了网络搜索工具、代码解释器(Python 执行环境)和网络浏览工具,包括使用工具的 HLE 和代理式搜索基准测试(BrowseComp、WideSearch、DeepSearchQA、FinSearchComp T2&T3 和 Seal-0)
Context Management Strategies
- 为了处理复杂代理式任务中固有的超长轨迹长度,作者实现了特定领域的上下文管理协议
- 除非以下另有说明,否则代理式评估不应用任何上下文管理;超出模型支持的上下文窗口的任务直接计为失败,而不是被截断
- Humanity’s Last Exam (HLE)
- 对于 HLE 工具增强设置,作者采用“隐藏工具结果”上下文管理策略 (Hide-Tool-Result Context Management strategy):
- 当上下文长度超过预定阈值时,仅保留最近一轮的工具消息(观察和返回值),而来自之前所有步骤的推理链和思维过程则完全保留
- 对于 HLE 工具增强设置,作者采用“隐藏工具结果”上下文管理策略 (Hide-Tool-Result Context Management strategy):
- BrowseComp
- 对于 BrowseComp 评估,作者的评估包含有和没有上下文管理设置的两种。在上下文管理设置下,作者采用 DeepSeek 提出的相同的丢弃所有策略 (discard-all strategy),即一旦 token 阈值超过,所有历史记录都会被截断
System Prompt
- 所有代理式搜索和 HLE 评估均使用以下统一的系统提示,其中 DATE 被动态设置为当前时间戳:
1
2
3
4
5
6
7
8
9
10You are Kimi, today’s date: DATE.
Your task is to help the user with their questions by using various tools, thinking deeply, and ultimately answering the user’s questions.
Please follow the following principles strictly during the deep research:
1. Always focus on the user’s original question during the research process, avoiding deviating from the topic.
2. When facing uncertain information, use search tools to confirm.
3. When searching, filter high-trust sources (such as authoritative websites, academic databases, and professional media) and maintain a critical mindset towards low-trust sources.
4. When performing numerical calculations, prioritize using programming tools to ensure accuracy.
5. Please use the format [^index^] to cite any information you use.
6. This is a **Very Difficult** problem——do not underestimate it. You must use tools to help your reasoning and then solve the problem.
7. Before you finally give your answer, please recall what the question is asking for.
Sampling Protocol
- 考虑到搜索引擎结果排名和动态网络内容可用性固有的随机性,Seal-0 和 WideSearch 的结果是 4 次独立运行的平均值 (Avg@4)
- 所有其他代理式基准测试均在单次运行协议下进行评估,除非另有明确说明
Computer-Use Evaluation
Hyperparameter Settings
- 作者为所有实验设置
max_steps_per_episode = 100 - OSWorld-Verified
temperature = 0,WebArena 的temperature = 0.1 - 由于资源限制,所有模型都在 one-shot setting 下进行评估
- 遵循 OpenCUA 配置 (2025),代理上下文包括最后 3 张历史图像、完整的思维历史记录和任务指令
- 对于 WebArena,作者手动更正了评估脚本中的错误,并使用 GPT-4o 作为 fuzzy_match 函数的评判模型
- 为确保公平比较,Claude Opus 4.5 仅使用计算机使用工具(排除浏览器工具)进行评估,这与 System Card 配置 (2025) 不同
System Prompt
作者为所有计算机使用任务使用统一的系统提示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39You are a GUI agent. You are given an instruction, a screenshot of the screen and your previous interactions with the computer.
You need to perform a series of actions to complete the task. The password of the computer is {password}.
For each step, provide your response in this format:
{thought}
## Action:
{action}
## Code:
{code}
In the code section, the code should be either pyautogui code or one of the following functions wrapped in the code block:
- {
"name": "computer.wait",
"description": "Make the computer wait for 20 seconds for installation, running code, etc.",
"parameters": {
"type": "object",
"properties":{},
"required": []
}
}
- {
"name": "computer.terminate",
"description": "Terminate the current task and report its completion status",
"parameters": {
"type": "object",
"properties": {
"status": {
"type": "string",
"enum": ["success", "failure"],
"description": "The status of the task"
},
"answer": {
"type": "string",
"description": "The answer of the task"
}
},
"required": ["status"]
}
}- 注:”pyautogui”(”PyAutoGUI”) 是一个 Python 库的名称,通常有以下译法或解释方式,常用 PyAutoGUI 实现自动化操作
Agent Swarm Configuration
Tool Setting
- 除了附录 E.6 中描述的核心工具集(网络搜索、代码解释器和网络浏览)之外,协调器 (orchestrator) 还配备了两种用于创建和调度子代理的专用工具:
- create_subagent:实例化一个具有自定义系统提示和标识符的专用子代理,以便在跨任务中重用
- assign_task:将任务分派给创建的子代理
- The tool schemas are provided below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36{
"name": "create_subagent",
"description": "使用特定的系统提示和名称创建自定义子代理以便重用。",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "此代理配置的唯一名称"
},
"system_prompt": {
"type": "string",
"description": "定义代理角色、能力和边界的系统提示"
}
},
"required": ["name", "system_prompt"]
}
}
{
"name": "assign_task",
"description": "启动一个新代理。\n使用说明:\n 1. 只要可能,你可以同时启动多个代理,以最大化性能;\n 2. 当代理完成时,它会向你返回一条消息。",
"parameters": {
"type": "object",
"properties": {
"agent": {
"type": "string",
"description": "指定要使用哪个已创建的代理。"
},
"prompt": {
"type": "string",
"description": "代理要执行的任务"
}
},
"required": ["agent", "prompt"]
}
}
Step Limits
- 在 Agent Swarm 模式下运行时,作者为协调器 (orchestrator) 和子代理设置计算预算,步骤限制适用于工具调用和环境交互的总计数
- BrowseComp:协调器被限制为最多 15 步。每个生成的子代理在最多 100 步的限制下运行(即每个子代理最多 100 次工具调用)
- WideSearch:协调器和每个子代理都被分配了最多 100 步的预算
- 内部基准测试 (In-house Bench):协调器被限制为最多 100 步。每个生成的子代理在最多 50 步的限制下运行
System Prompt
- 原文内容如下
1
2
3
4
5
6
7
8
9
10
11
12You are Kimi, a professional and meticulous expert in information collection and organization.
You fully understand user needs, skillfully use various tools, and complete tasks with the highest efficiency.
# Task Description
After receiving users’ questions, you need to fully understand their needs and think about and plan how to complete the tasks efficiently and quickly.
# Available Tools
To help you complete tasks better and faster, I have provided you with the following tools:
1. Search tool: You can use the search engine to retrieve information, supporting multiple queries in parallel.
2. Browser tools: You can visit web links (web pages, PDFs, etc.), get page content, and perform interactions such as clicking, inputting, finding, and scrolling.
3. Sub Agent tools:
- ‘create_subagent‘: Create a new sub-agent with a unique name and clear, specific system prompt.
- ‘assign_task‘: Delegate tasks to created sub-agents. Sub-agents can also use search and browser tools.
4. Other tools: Including code execution (IPython, Shell).
GDPVal
- 作者引用了 Artificial Analysis 的 GDPVal-AA 评估,表 4 中报告的分值反映了截至 2026 年 1 月 28 日的官方排行榜指标
附录 F:Visualization
- 图 11 展示了作者的 Agent Swarm 处理一个具有挑战性的长形式视频理解任务:分析《黑神话:悟空》的完整通关流程(24 小时连续游戏过程,跨越 32 个视频,总计 40GB)
- 该系统采用分层多代理架构,其中主代理 (Main Agent) 协调并行子代理 (Sub Agents) 独立处理各个视频片段
- 每个子代理执行帧提取、时间事件分析和关键时刻识别(如 BOSS 战、升级)
- 随后,主代理聚合这些分布式分析,合成一个包含时间线、嵌入视频剪辑和交互式可视化的综合性 HTML 展示
- 此示例展示了系统通过并行化处理大规模多模态内容的能力,同时保持了连贯的长上下文理解

- 图 12 展示了 Kimi K2.5 通过工具增强推理解决多样化视觉推理任务的定性示例;该模型展示了:
- (1) 迷宫求解——处理二值图像分割并实现寻路算法(广度优先搜索)来导航复杂迷宫;
- (2) 饼图分析——执行像素级颜色分割和几何计算以确定精确的面积比例;
- (3) 找不同——采用计算机视觉技术检测图像对之间的像素级差异
- 这些示例突出了该模型将复杂视觉问题分解为可执行代码、根据中间结果迭代优化策略以及通过定量视觉分析综合精确答案的能力

附录:Kimi-K2.5 博客内容(部分解读
- 原始博客链接:Kimi K2.5: Visual Agentic Intelligence, 20260127
- 注:博客先于技术报告发出
- 博客中很多炫酷的图,强烈建议看原始博客
- 博客自信的写道: Kimi K2.5 是迄今为止最强大的开源模型
- Kimi K2.5 在 Kimi K2 的基础上,继续使用大约 15T 的混合视觉与文本 Token 进行预训练
- 作为一个原生的多模态模型,K2.5 提供了 SOTA 编程和视觉能力,以及一个自我导向的智能体集群范式
- 对于复杂任务,Kimi K2.5 能够自我导向地组织一个最多包含 100 个子智能体的集群,在最多 1500 次工具调用中执行并行工作流
- 与单智能体设置相比,这可将执行时间缩短多达 4.5 倍
- 该智能体集群由 Kimi K2.5 自动创建和编排,无需任何预定义的子智能体或工作流
- Kimi K2.5 可通过 Kimi.com 网站、Kimi App、API 以及 Kimi Code 获得
- Kimi.com 网站和 Kimi App 目前支持 4 种模式:K2.5 即时模式、K2.5 思考模式、K2.5 智能体模式和 K2.5 智能体集群模式(Beta)
- 智能体集群功能目前在 Kimi.com 上处于测试阶段,高级付费用户可获得免费额度
- 测评指标包括:
- Agents:HLE-Full,BrowseComp,DeepSearchQA
- Coding:SWE-Bench Verified,SWE-Bench Multilingual
- Image:MMMU Pro:MathVision ,OmniDocBench 1.5
- Video:VideoMMMU,LongVideoBench
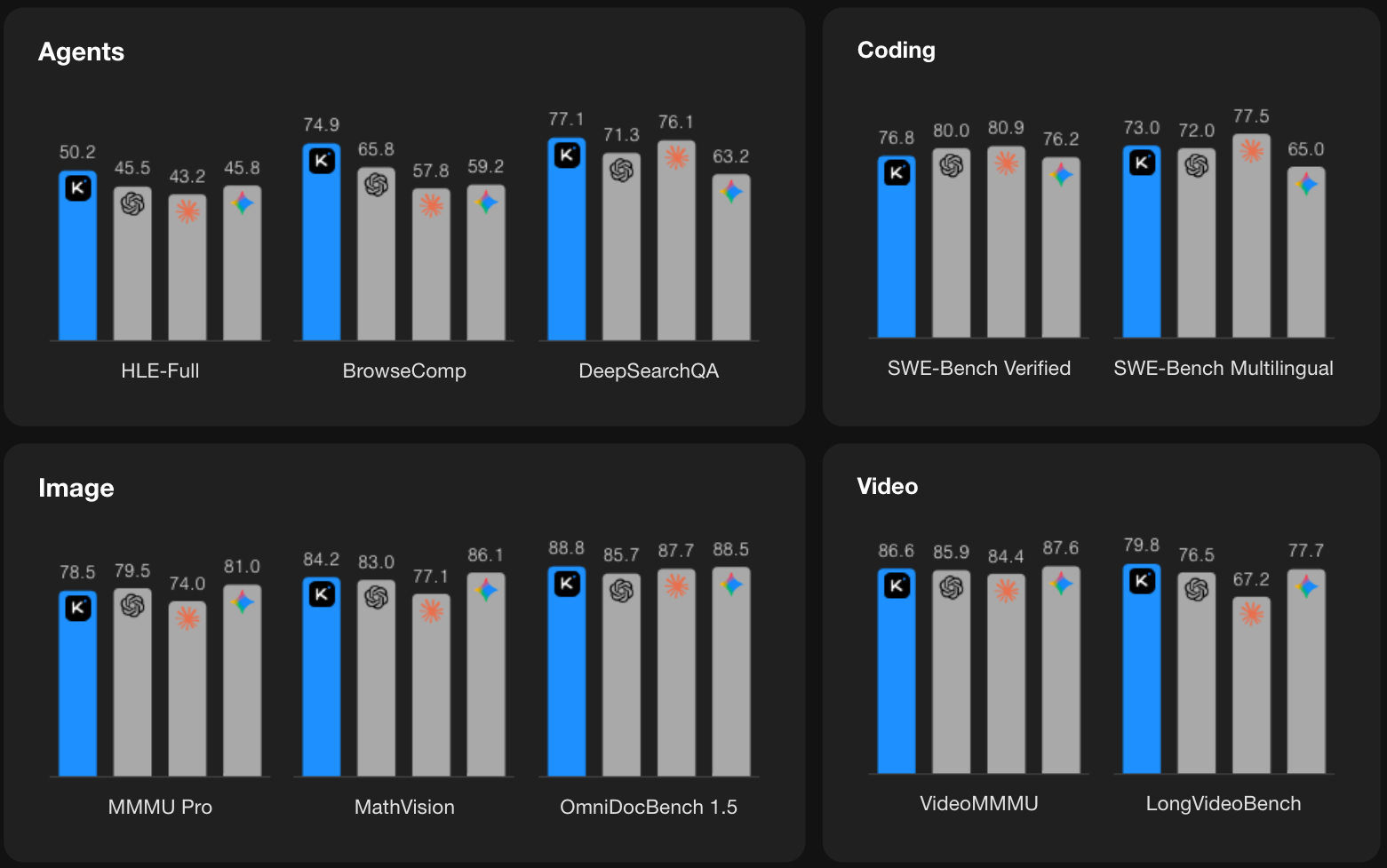
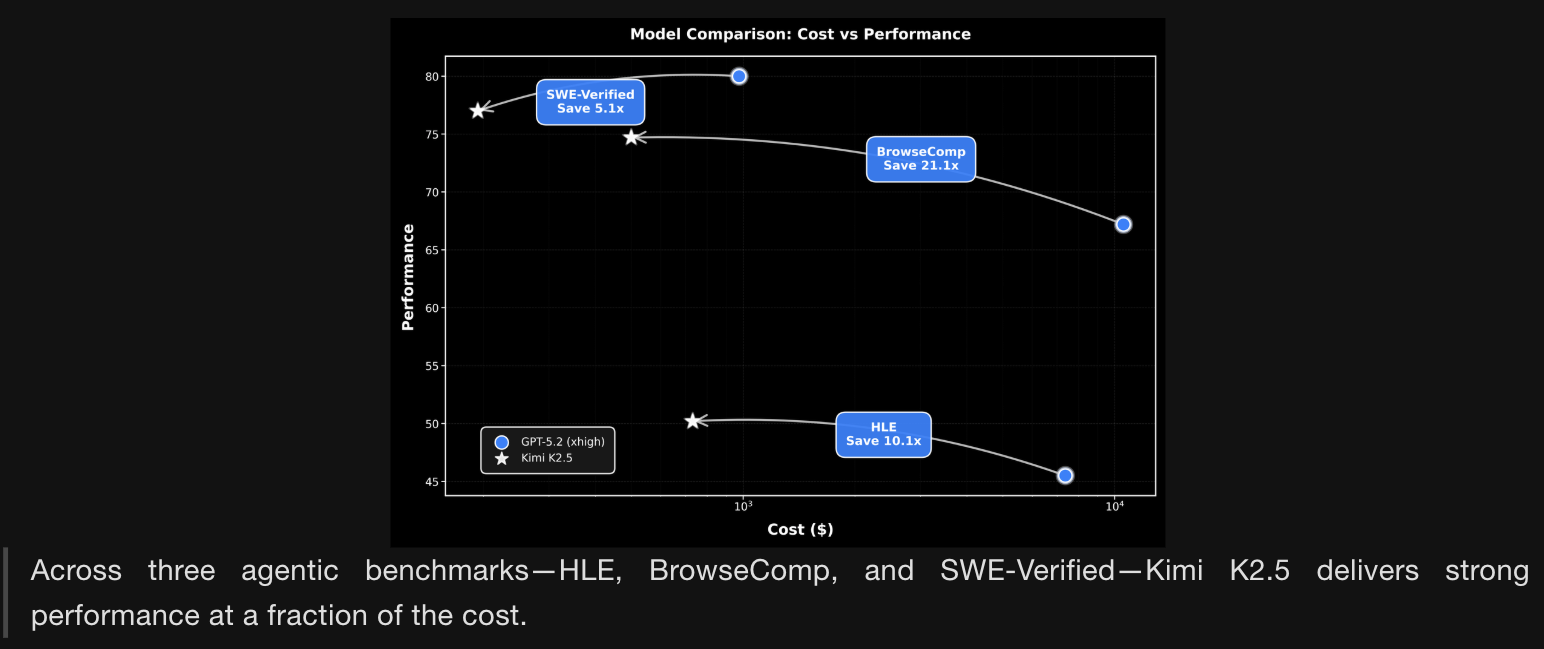
- 在三个智能体基准测试(HLE、BrowseComp 和 SWE-Verified) 中,Kimi K2.5 以极低的成本提供了强大的性能
Coding with Vision
- Kimi K2.5 是迄今为止最强大的开源编程模型 ,在前端开发方面能力尤为突出
- K2.5 可以将简单的对话转化为完整的前端界面,实现交互式布局和丰富的动画效果,例如滚动触发的特效
- 以下是 K2.5 根据一个包含图像生成工具的提示词生成的示例:
- 除了文本提示,K2.5 在视觉编程方面表现出色
- 通过对图像和视频进行推理,K2.5 改进了图像/视频到代码的生成以及视觉调试,降低了用户通过视觉表达意图的门槛
- 以下是 K2.5 根据视频重建网站的一个示例:

- 这种能力源于大规模的视觉-文本联合预训练。在足够大的规模下,视觉能力和文本能力之间的权衡消失了——它们同步提升
- 以下是 K2.5 对一个谜题进行推理并用代码 Token 最短路径的示例:
- 示例详情见博客原文
- K2.5 在现实世界的软件工程任务中表现出色。论文使用 Kimi Code Bench(论文内部的编程基准测试)对其进行评估,该测试涵盖了多样化的端到端任务,即从构建到调试、重构、测试和脚本编写,跨越多种编程语言
- 在此基准测试中,K2.5 在不同任务类型上相比 K2 都显示出持续且有意义的改进

- 在此基准测试中,K2.5 在不同任务类型上相比 K2 都显示出持续且有意义的改进
- 要尝试 K2.5 的智能体编程能力,K2.5 智能体模式提供了一组预配置的工具,可进行即时、动手体验。对于软件工程用例,论文建议将 Kimi K2.5 与论文的新产品 Kimi Code 配合使用
- Kimi Code 可在您的终端中运行,并可集成到各种 IDE 中,包括 VSCode、Cursor、Zed 等
- Kimi Code 是开源的,支持图像和视频作为输入。它还能自动发现并迁移现有的技能和 MCP 到您在 Kimi Code 中的工作环境
- 这是一个使用 Kimi Code 将马蒂斯的《舞蹈》的美学风格转化到 Kimi App 的示例
- 这个演示突出了自主视觉调试方面的一个突破
- 利用视觉输入和文档查阅,K2.5 能够视觉检查自己的输出并自主进行迭代
- 它创建了一个从端到端完成的艺术灵感网页:
- 详情见原博客
Agent Swarm,智能体集群
- 横向扩展,而不仅仅是向上扩展 (Scaling Out, Not Just Up.)
- 论文发布了 K2.5 智能体集群作为研究预览,标志着从单智能体扩展向自我导向、协调的集群式执行的转变
- 通过并行智能体强化学习(Parallel-Agent Reinforcement Learning, PARL)训练,K2.5 学会了自我导向地组织一个最多包含 100 个子智能体的集群,在最多 1500 个协调步骤中执行并行工作流,而无需预定义角色或手工制作的工作流
- PARL 使用一个可训练的组织器智能体将任务分解为可并行执行的子任务,每个子任务由动态实例化的、冻结的子智能体执行
- 与顺序的智能体执行相比,并行运行这些子任务能显著降低端到端延迟
- 训练一个可靠的并行组织器具有挑战性,因为来自独立运行的子智能体的反馈是延迟的、稀疏的且非平稳的
- 一个常见的失败模式是序列崩溃 ,即组织器尽管具备并行能力,却退回到单智能体执行
- 为了解决这个问题,PARL 采用了分阶段奖励塑造 ,在训练早期鼓励并行性,并逐渐将重点转向任务成功
- To Be Continue …