注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 在大家都在等待 DeepSeek 时,智谱给了大家一个26年春节的惊喜
- 在很多指标上(特别是编程指标上),基本上到了第一梯队
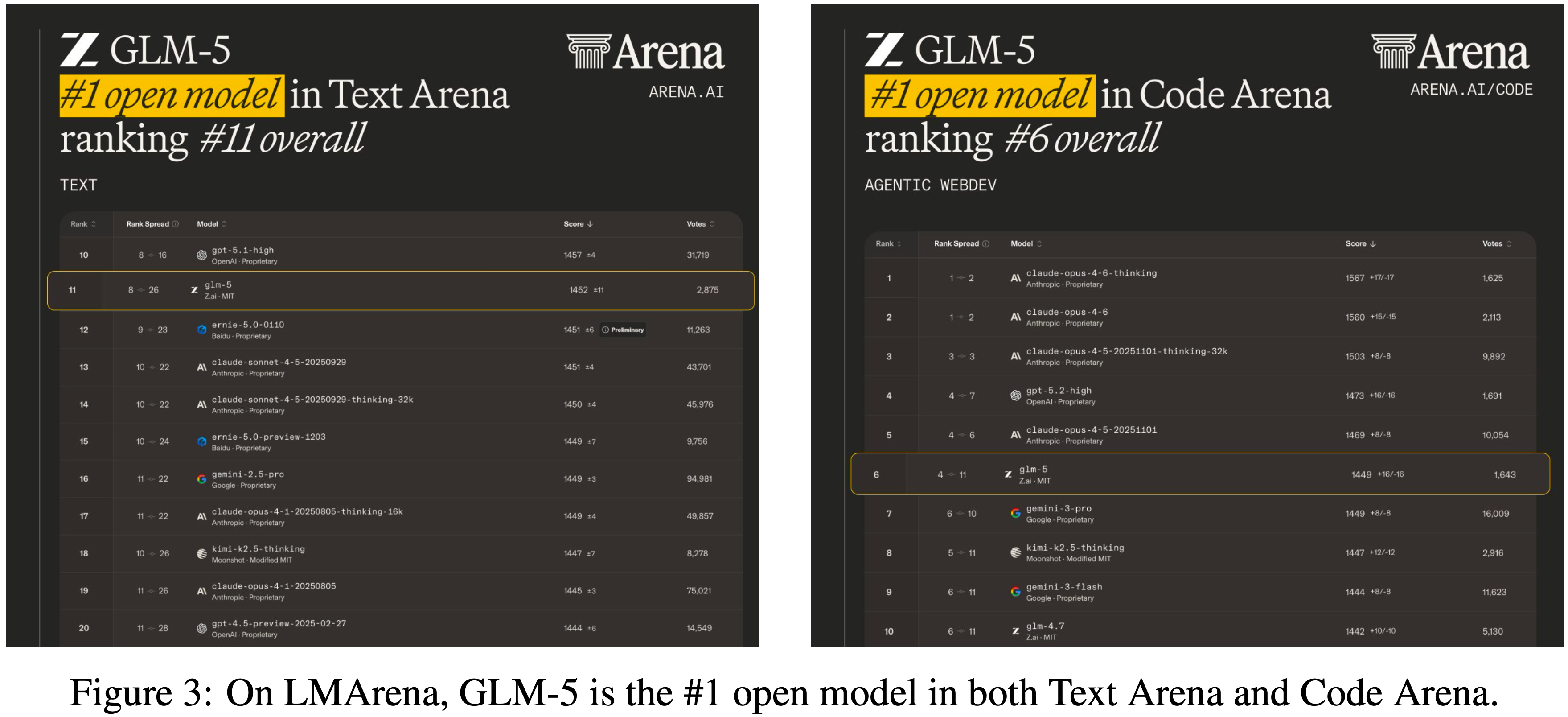
- LMArena 上超过了百度的 ERNIE-5.0,是新的开源 SOTA
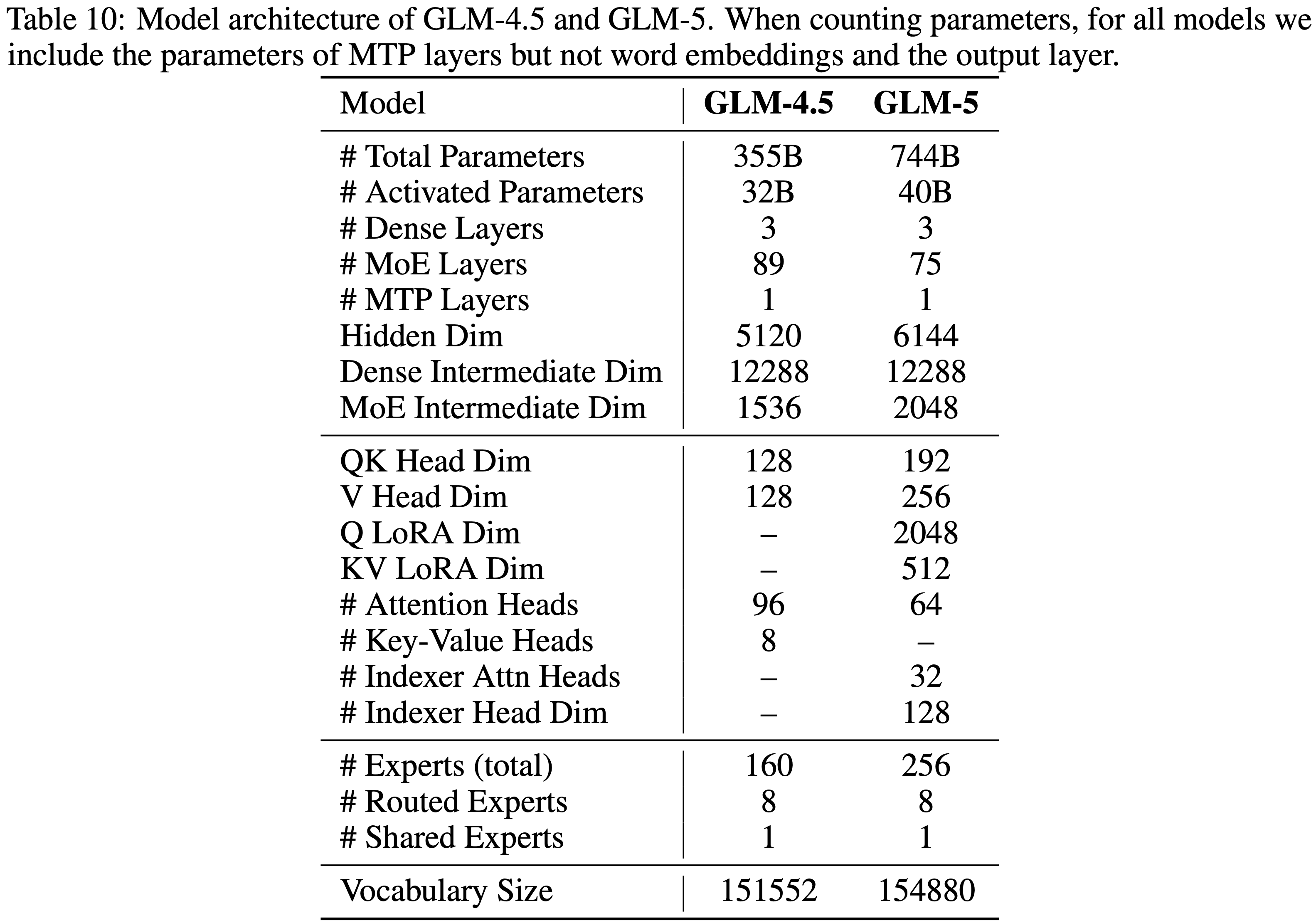
- GLM-5 参数量: 744B-A40B,总参数量相对上一代模型翻倍,但激活参数量只增加了25% (注:上一代的 GLM-4.5 是 355B-A32B 参数)
- 主要卖点:from Vibe Coding to Agentic Engineering
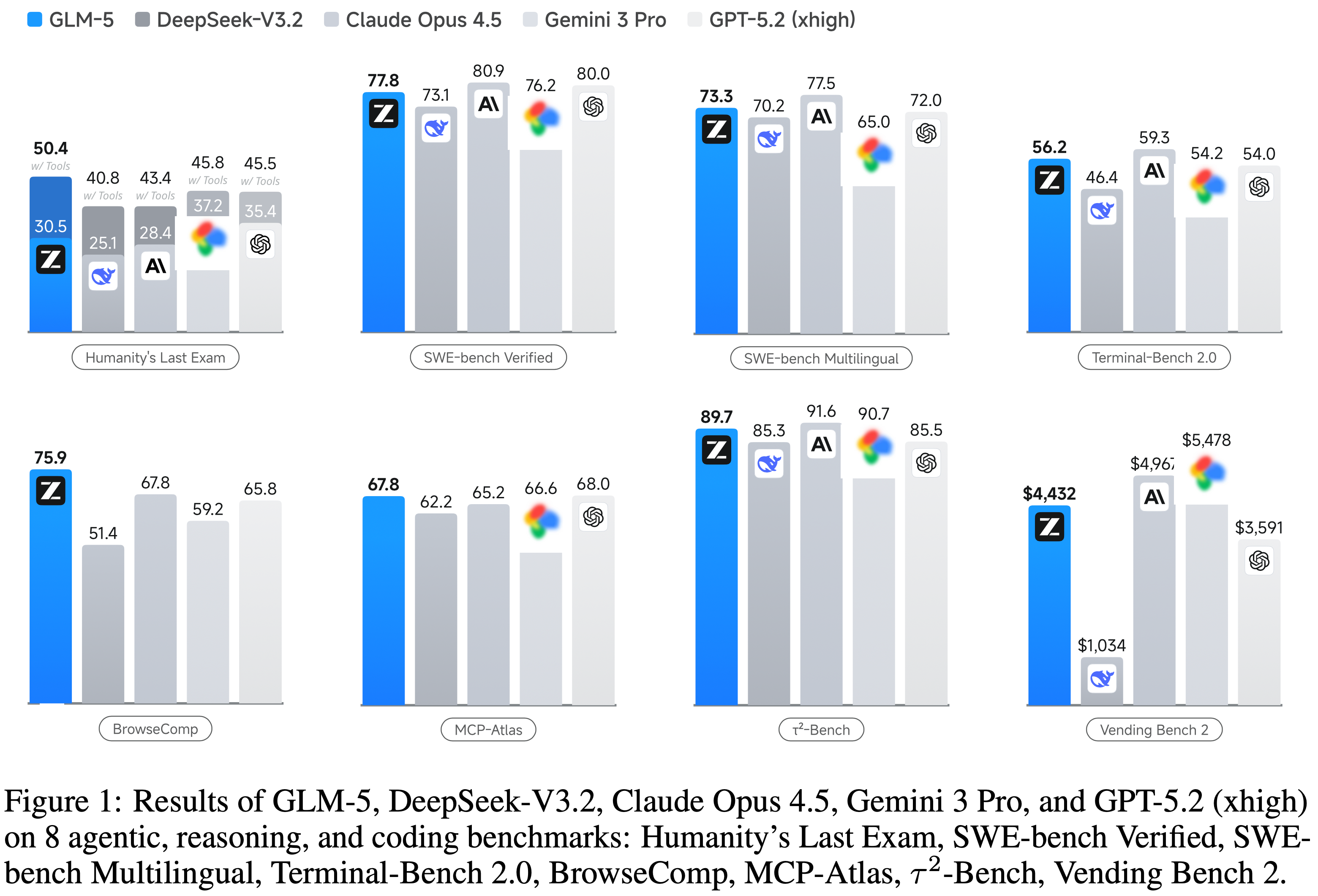
- 对比模型是 DeepSeek-V3.2, Claude Opus 4.5, Gemini 3 pro 和 GPT-5.2(xhigh),都是当前处于第一梯队的模型
- PS:智谱似乎没有考虑跟 20260131 发布的开源 SOTA Kimi-K2.5 比较一下?其实 Kimi-K2.5 在 HLE, BrowseComp, SWE-Bench Verified 和 SWE-Bench Multilingual 等指标上都只差 GLM-5 一点点
- 唯一的遗憾:GLM-5 仍然不是多模态模型
- 对训练流程的总结:
- GLM-5 的后训练流程分为 Pre-Training -> Mid-Training -> SFT -> Reasoning RL -> Agentic RL -> General RL -> On-Policy Cross-Stage Distillation (OPD)
- 关于 OPD阶段 (其实本质四 MOPD)
- 学生模型 :OPD 阶段的学生模型起点 = General RL 阶段完成后的最终模型权重
- 教师模型 :教师模型是前一阶段训练完成后的最终 checkpoint,包括 Reasoning RL 和 General RL 阶段的模型输出
- 这个设计的核心是让学生把遗忘的 Reasoning RL 能力和 General RL 能力找回来
- GLM-5 的目标是将 vibe coding 范式过渡到 agentic engineering
- 使用了 DSA:基于之前模型的 Agentic 、Reasoning 和 Coding 能力(三者在 GLM-4.5 中简称 ARC),采用 DSA 显著降低训练和推理成本,同时保持长上下文的保真度
- 异步 RL 框架:将生成与训练解耦,大幅提高了后训练效率
- 异步 Agent RL 算法:进一步提升了 RL 质量,使模型能够更有效地从复杂的、长视野的交互中学习
Introduction and Discussion
- LLM 逐步从被动的知识库转变为主动的问题求解,计算成本和现实世界适应性的双重挑战已成为主要的瓶颈(GLM-5 旨在客服这些障碍)
- 尤其是在复杂的软件工程领域
- GLM-5 在性能和效率上都代表了一种范式转变,在主要的公开排行榜(包括 ArtificialAnalysis.ai、LMArena Text 和 LMArena Code)等上都取得了 SOTA 成绩
- GLM-5 重新定义了现实世界编码的标准,展示了处理复杂的、端到端的软件开发任务的空前能力,这些任务远远超出了像 SWE-bench 这类传统静态基准的范围
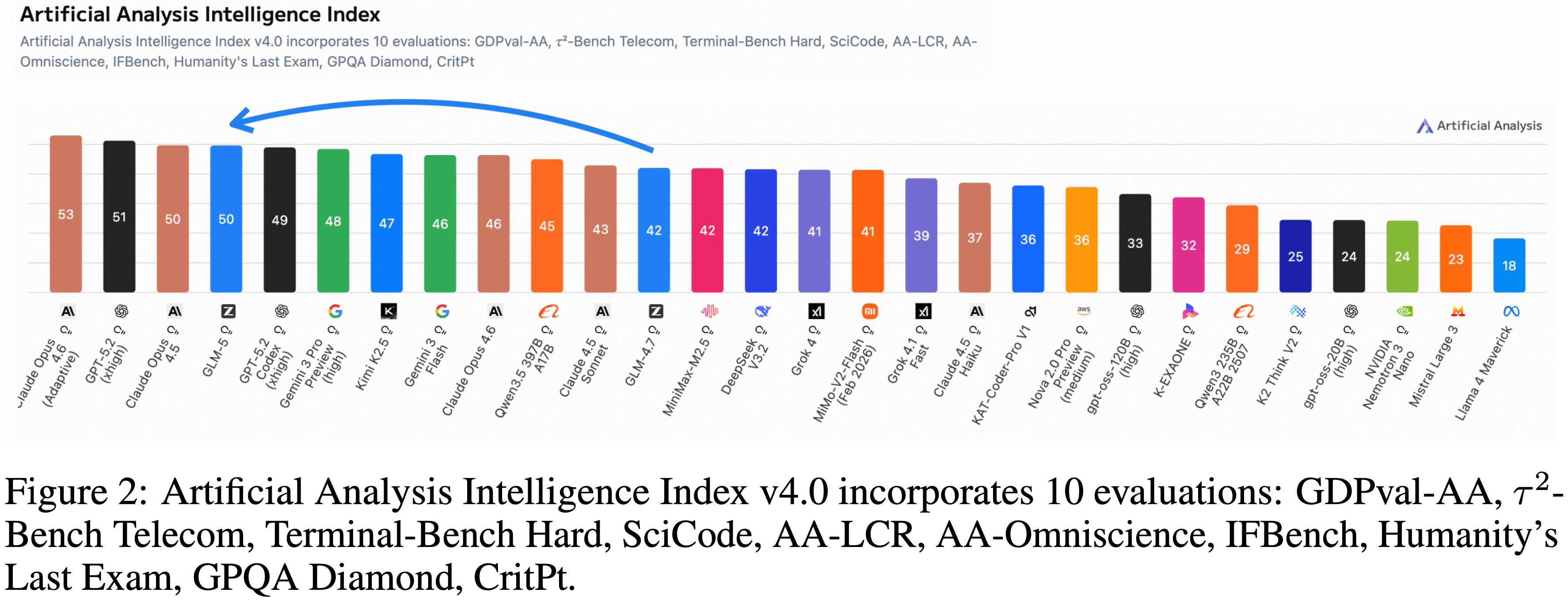
- GLM-5 在 Intelligence Index v4.0 上得分为 50(注:比 GLM-4.7 的 42 分提升了 8 分)
- 这一跃升得益于 agentic 性能以及知识/幻觉方面的改进
- 这是开源权重模型首次在 Artificial Analysis Intelligence Index v4.0 上取得 50 分
- 图3显示 GLM-5 在 Text Arena 和 Code Arena 中再次成为排名第一的开源模型,并且总体上与 Claude-Opus-4.5 和 Gemini-3-pro 持平
- GLM-5 完成长视野任务的能力:
- Vending-Bench 2 是一个衡量 AI 模型在长时间范围内经营企业性能的基准。模型的任务是在一年内经营一个模拟的自动售货机业务,并根据其年末的银行账户余额进行评分
- 图4(左)显示 GLM-5 在所有开源模型中排名第一,最终账户余额为 $4,432(接近 Claude Opus 4.5,展示了强大的长期规划和资源管理能力
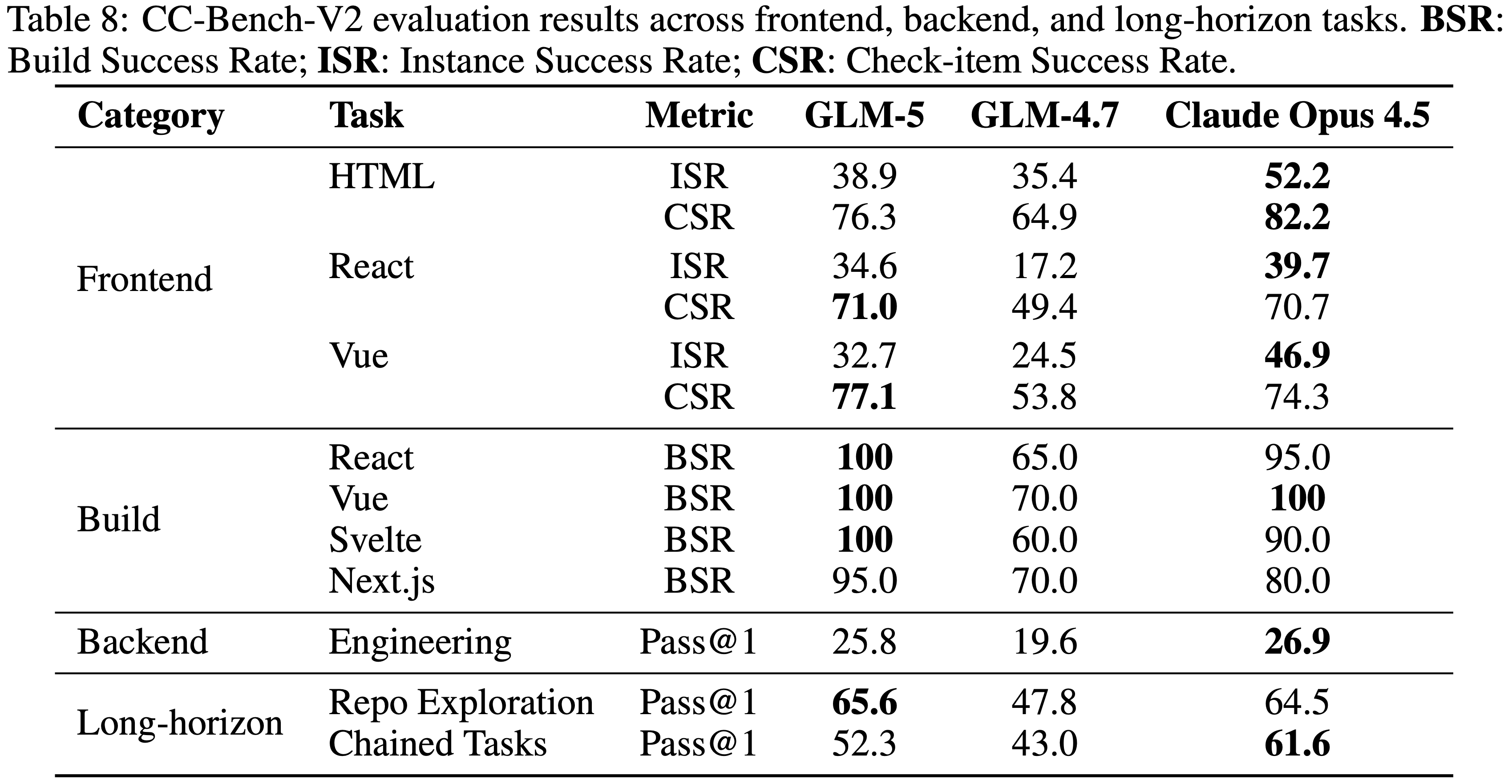
- 图4(右)进一步展示了作者在内部评估套件 CC-Bench-V2 上的结果
- GLM-5 在前端、后端和长视野任务上显著优于 GLM-4.7,缩小了与 Claude Opus 4.5 的差距
- Vending-Bench 2 是一个衡量 AI 模型在长时间范围内经营企业性能的基准。模型的任务是在一年内经营一个模拟的自动售货机业务,并根据其年末的银行账户余额进行评分
- 图5 展示了 GLM-5 的整体训练流程
- Pre-training:27T Token 的语料库
- 优先考虑代码和推理
- Mid-training:将上下文长度从 4K 逐步扩展到 200K
- 特别关注长上下文的 agentic 数据,以确保在复杂工作流程中的稳定性
- Post-training:使用顺序强化学习流程,Reasoning RL -> Agentic RL -> General RL
- 在整个过程中利用了 On-Policy Cross-Stage Distillation 来防止灾难性遗忘,确保模型在成为强大的通才(generalist)的同时,保持其敏锐的推理能力
- Pre-training:27T Token 的语料库
- GLM-5 技术贡献总结
- 使用了 DSA(DeepSeek Sparse Attention)(2025),显著降低了训练和推理成本
- 注:GLM-4.5 是标准的 MoE
- DSA 允许 GLM-5 基于 token 重要性动态分配注意力资源,在不影响长上下文理解或推理深度的情况下,大幅降低计算开销
- 借助 DSA,作者将模型参数扩展到 744B ,并将训练 token 预算扩展到 28.5T Token
- 新的异步强化学习基础框架:
- 基于在 GLM-4.5 中初始化的 “slime” 框架和解耦的 rollout 引擎,进一步将生成与训练解耦,以最大化 GPU 利用率
- 该系统允许对 agent 轨迹进行大规模探索,而无需之前阻碍迭代速度的同步瓶颈,显著提高了作者 RL 后训练流程的效率
- 新颖的异步 Agent RL 算法,目标是提高自主决策的质量
- 注:在 GLM-4.5 中,作者利用迭代自蒸馏和结果监督来训练智能体
- GLM-5 中,作者开发了异步算法,允许模型持续地从多样化的、长视野的交互中学习
- 这些算法专门针对提高模型在动态环境中的规划和自我纠正能力进行了优化,促成了作者在现实世界编码场景中的主导地位
- 从第一天起,GLM-5 就全面适配了中国芯片生态系统
- 作者已在七个主流国产芯片平台上成功完成了深度优化——涵盖从底层 kernel 到上层推理框架
- 包括华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、MetaX 和燧原科技(Huawei Ascend, Moore Threads, Hygon, Cambricon, Kunlunxin, MetaX, and Enflame)
- 作者已在七个主流国产芯片平台上成功完成了深度优化——涵盖从底层 kernel 到上层推理框架
- 使用了 DSA(DeepSeek Sparse Attention)(2025),显著降低了训练和推理成本
Pre-Training
- 基础模型的训练包含两个阶段(GLM-4.5 也一样):
- Pre-Training:通用语言和编码能力
- Mid-training:agentic 和长上下文能力
- 基础模型总计达到 28.5T Token
Architecture
- Model size scaling
- 对比:GLM-4.5 参数量为 355B-A32B
- GLM-5 参数量为 744B-A40B,256 个专家,层数 80 层(这里刻意减少层数以最小化专家并行通信开销)
- Multi-latent Attention(MLA)
- MLA 采用缩减的键值向量,达到了与 GQA 相当的效果,为长上下文序列提供了卓越的 GPU 内存节省和更快的处理速度
- 在使用 Muon 优化器的实验中,作者发现 576 维 latent KV 缓存的 MLA 无法匹配 8 个查询组的 GQA(denoted as GQA-8,2048-维度 KV-Cache)的性能
- For 克服性能差距,作者对 GLM-4.5 中的 Muon 优化器配方提出了一项调整:
- 在原始配方中:对多头查询、键和值的升投影矩阵 \(W^{UQ},W^{UK},W^{UV}\) 应用矩阵正交化
- 本文配方:将这些矩阵拆分成不同头的更小矩阵,并对这些独立的矩阵应用矩阵正交化
- 这种方法称为 Muon Split ,使得不同注意力头的投影权重能够以不同的尺度更新
- For 克服性能差距,作者对 GLM-4.5 中的 Muon 优化器配方提出了一项调整:
- 如表1所示,该方法有效地提高了 MLA 的性能,使其与 GQA-8 相匹配
- 在实践中,作者还发现,使用 Muon Split,GLM-5 的注意力 logits 尺度在预训练期间保持稳定,无需任何裁剪策略
- MLA 的另一个缺点是其解码期间的高计算成本
- 在解码中,MLA 执行 576 维的点积,高于 GQA 的 128 维计算
- 虽然 DeepSeek-V3 中注意力头的数量是根据 H800 的 roofline 模型选择的 (2025),但它不适用于其他硬件
- 鉴于 MLA 在训练和预填充期间的 MHA 风格,作者将头维度从 192 增加到 256,并将注意力头数量减少 1/3
- 这在保持训练计算量和参数数量不变的同时,减少了解码计算量
- 表 1 中记为 MLA-256 的变体,其性能与 Muon Split 下的 MLA 相当

- Multi-token Prediction with Parameter Sharing
- MTP 提高了基础模型的性能,并可作为推测解码的 Draft Model (2023)
- 在训练期间,为了预测接下来的 \(n\) 个 token,需要 \(n\) 个 MTP 层
- MTP 参数和 KV 缓存的内存使用量与推测步骤的数量成线性增长
- DeepSeek-V3 使用单个 MTP 层进行训练 ,在推理期间预测接下来的 2 个 token
- 这种训练-推理差异降低了第二个 token 的接受率
- 作者提出在训练期间共享 3 个 MTP 层的参数,使得 Draft Model 的内存成本与 DeepSeek-V3 保持一致,同时提高了接受率
- 表 2 中 作者展示了在私有 Prompt 集上,给定相同数量的推测步骤(4),GLM-5 的接受长度比 DeepSeek-V3.2 更长

Continued Pre-Training with DeepSeek Sparse Attention (DSA)
- DSA 的核心思想是用一种动态的、细粒度的选择机制取代传统的 Dense \(O(L^{2})\) 注意力
- 传统 Dense 注意力在 128K 上下文中变得极其昂贵
- 与固定模式(如滑动窗口)不同,DSA 会“查看”内容以决定哪些 token 是重要的
- 从研究人员的角度来看,DSA 特别有趣之处在于它是如何通过对 Dense 基础模型进行继续预训练而引入的
- 这避免了从头开始训练的“天文数字”成本
- 这种转变遵循一个两阶段的“Dense 预热和稀疏训练适应”策略
- DeepSeek-V3.2-Exp 保持与其 Dense 前身相同的基准性能,证明了长上下文中 \(90%\) 的注意力条目确实是冗余的
- DSA 将长序列的注意力计算减少了大约 \(1.5 - 2x\),这对于本文正在构建的推理密集型智能体来说非常重要,能够以一半的 GPU 成本处理 128K 上下文
- DSA 训练从 Mid-training 结束时的基础模型开始
- 预热阶段进行 1000 步,每一步在 14 个长度为 202,752 token 的序列上进行训练,最大学习率为 5e-3
- 稀疏适应阶段遵循 Mid-training 的训练数据和超参数,处理 20B token
- 尽管训练预算远小于 DeepSeek-V3.2(943.7B token),但作者发现这足以使 DSA 模型的性能与原始 MLA 模型相匹配
- 如表 3 所示,DSA 模型的长上下文性能接近 MLA 模型
- 为了进一步验证 DSA 训练的有效性,作者分别使用相同的 SFT 数据对 DSA 和 MLA 模型进行微调 ,发现两个模型在训练损失和评估基准上表现相当

- 为了进一步验证 DSA 训练的有效性,作者分别使用相同的 SFT 数据对 DSA 和 MLA 模型进行微调 ,发现两个模型在训练损失和评估基准上表现相当
Ablation Study of Efficient Attention Variants
- 除了 DSA (2025) 之外,作者基于 GLM-9B 探索了几种替代的高效注意力机制
- Baseline 模型在所有 40 层中采用分组查询注意力,并已使用 128K token 上下文窗口进行微调
- 作者评估了以下方法:
- 滑动窗口注意力交错:一种固定的交替模式,在全注意力和窗口注意力层之间交替,均匀地应用于整个网络
- Gated DeltaNet(GDN)(2024):一种线性注意力变体,用门控线性循环取代了二次的 softmax 注意力计算,将注意力的计算成本从序列长度的二次方降低到线性
- 在这些基线的基础上,作者提出了两项改进:
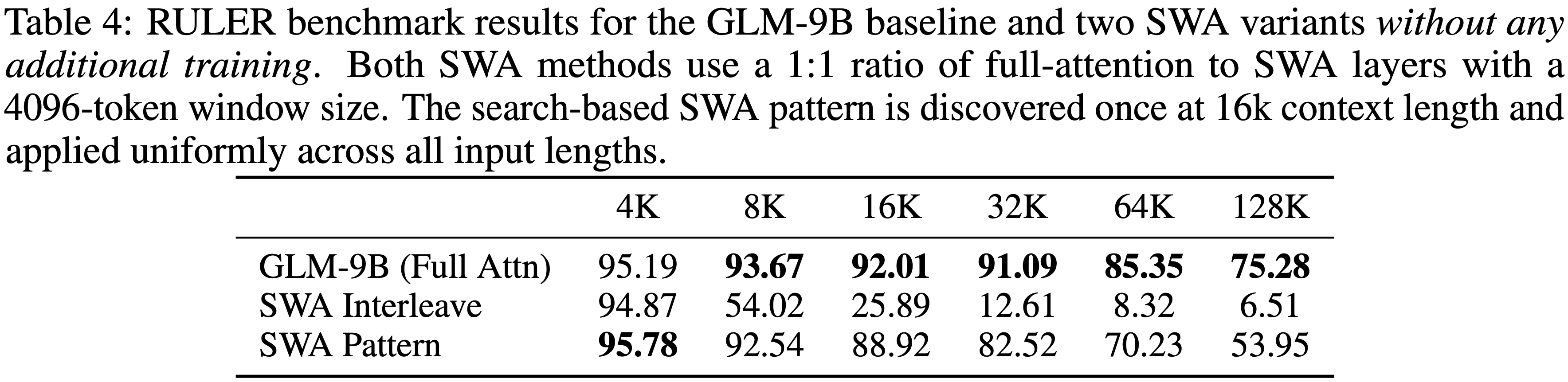
- 改进1:SWA 模式(基于搜索):受 PostNAS (2025) 启发,作者引入了一种基于搜索的适应方法,该方法识别出适合转换为 SWA 的最佳层子集,同时在其余层中保留全注意力
- 作者采用 Beam Search 策略来确定配置,以最大化长上下文下游任务的性能
- 为了减轻计算成本,作者仅在 16K 上下文长度下进行搜索,并将结果模式推广到所有其他输入长度
- 具体来说,作者使用 Beam 大小为 8,每步优化两层;对于 GLM-9B(40 层),该过程大约在 10 步内收敛
- 在每一步,候选模式都在 RULER 基准测试 (2024) 上以 16K 上下文长度进行评估,并保留前 8 个候选模式用于下一步
- 最终得出的模式是 SFSFFSSSFFFFSSSFFFFFFSFSFSFSFSFSFSFSFSFS,其中 S 和 F 分别表示 SWA 和全注意力层
- 如表 4 所示,这种基于搜索的配置显著优于固定的交错方法。值得注意的是,尽管仅在 16K 下优化,该模式表现出强大的长度泛化能力,在所有测试的上下文长度下都保持有效
- 改进2:SimpleGDN:一种极简的线性化策略,旨在最大程度地重用预训练权重,改进了 GDN 以适应继续训练
- 作者完全移除了 Conv1d 和显式门控模块,而是直接将预训练的 Query、Key 和 Value 投影权重映射到线性循环公式中
- 这种简化消除了对额外参数的需求,同时保留了线性注意力的效率优势
- 作者在四个长上下文基准上评估所有方法:RULER (2024)、MRCR2、HELMET-ICL (2024) 和 RepoQA (2024)
- 结果汇总在表 5 中
- 作者对每种方法在 190B token 上以 64K 上下文长度进行持续训练,保持高效注意力层与全注意力层之间 1:1 的比例
- 对于 GDN 和 SimpleGDN 方法,作者遵循 Jet-Nemotron (2025) 流程
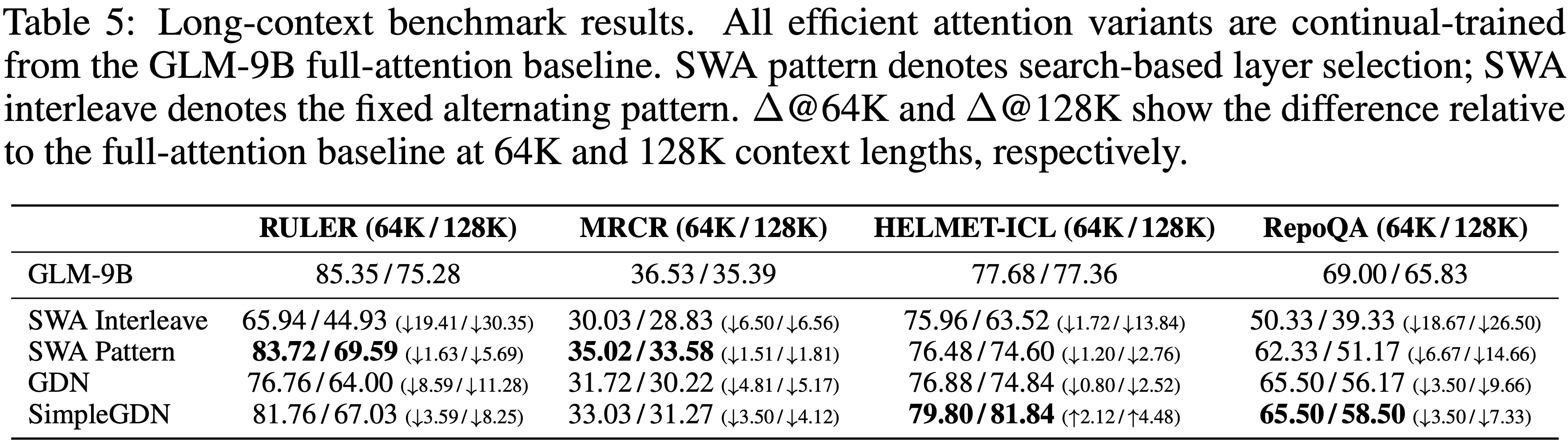
- 表 5 中的结果揭示了高效注意力方法之间清晰的权衡层次结构
- 简单交错的滑动窗口注意力(SWA)会导致长上下文任务的灾难性退化(例如,在 RULER@128K 上下降 30.35 分)
- 基于搜索的层选择通过在最关键的地方保留全注意力,显著缩小了这一差距
- 像 GDN 这样的线性注意力变体进一步提高了质量,但代价是增加了额外参数;
- SimpleGDN 通过最大限度地重用预训练权重,达到了最佳的平衡
- 注:所有这些方法在细粒度检索任务上都存在固有的准确性差距(在 RULER@128K 上高达 5.69 分,在 RepoQA@128K 上高达 7.33 分)
- 这是由于在持续训练适应过程中,即使一半的层保留全注意力,高效注意力机制也不可避免地引入信息丢失
- 简单交错的滑动窗口注意力(SWA)会导致长上下文任务的灾难性退化(例如,在 RULER@128K 上下降 30.35 分)
- 相比之下,DSA 本质上是无损的:其 lightning indexer 实现了 Token-level 稀疏性,而不会丢弃任何长距离依赖关系,使其能够应用于所有层且无质量下降
- 为了验证这一点,作者在配备 MLA 的 GLM-4.7-Flash 上进行了小规模的 DSA 实验
- 遵循标准的 DSA 流程,训练分两个阶段进行:
- (i) 一个预热阶段,仅训练 indexer 1000 步(批量大小 16),同时保持所有基础模型权重冻结
- (ii) 一个联合训练阶段,模型和 indexer 在 150B token 上共同训练
- 表6总结了在上下文长度从 4K 到 128K 的 RULER 上的结果
- 仅预热的变体(GLM-4.7-Flash + DSA warmup)就已经能保留基线性能的绝大部分
- 性能下降幅度较小且集中在最长的上下文窗口(128K:79.21 -> 71.35),较短的上下文几乎不受影响
- 经过完整的 150B token 联合训练阶段后,GLM-4.7-Flash + DSA 几乎弥合了所有剩余的差距:
- 在 16K \((+0.86)\)、32K \((+0.49)\) 和 64K \((+1.72)\) 上超过了基线,仅在 128K 上存在 0.35 分的 deficit
- 仅预热的变体(GLM-4.7-Flash + DSA warmup)就已经能保留基线性能的绝大部分
Pre-training Data
Web
- 基于 GLM-4.5 的数据流程
- 改进了对海量网络数据集的选择标准
- 引入了另一个基于句子 Embedding 的 DCLM (2025) 分类器,以识别和聚合超出标准分类器的额外高质量数据
- 为了解决长尾知识的挑战,利用一个世界知识分类器(通过维基百科条目和 LLM 标记的数据进行优化)从中低质量数据中提炼有价值的信息
Code
- 用来自主要代码托管平台的刷新快照和更大规模的包含代码的网页集合来扩展代码预训练语料库,使得模糊去重后的唯一 token 数量增加了 \(28%\)
- 为了提高语料库的完整性和减少噪声,作者修复了 Software Heritage 代码文件中的元数据对齐问题,并采用了更准确的语言分类流程
- 遵循 GLM-4.5 针对源代码和代码相关网页文档的质量感知采样策略
- 为更广泛的低资源编程语言(例如 Scala、Swift、Lua 等)训练了专门的分类器,以提高这些语言的采样质量
Math & Science
- 作者从网页、书籍和论文中收集高质量的数学和科学数据,以进一步增强推理能力
- 作者改进了网页的内容提取流程以及书籍和论文的 PDF 解析机制,以提高数据质量
- 采用 LLM 对候选文档进行评分,并只保留最具教育意义的内容
- 对于长上下文文档,作者开发了一种分块聚合评分算法,以提高评分准确性
- 执行过滤流程,严格避免使用合成、AI 生成或基于模板的数据
Mid-Training
- 基于 GLM-4.5 中引入的 Mid-training 框架,并在 GLM-5 中扩展了训练量和最大上下文长度,以进一步加强模型的推理、长上下文和 agentic 能力
Extended context and training scale
- 分三个阶段逐步扩展上下文窗口:
- 32K(1T token)、128K(500B token)和 200K(50B token)
- 与 GLM-4.5 中 128K 的最大长度相比,额外的 200K 阶段显著提高了模型处理超长文档和复杂多文件代码库的能力
- 长文档和合成 agent 轨迹在后期阶段相应地进行了上采样
Software engineering data
- 作者保留了将 Repo-level 代码文件、Commit Diffs、GitHub Issues、Pull Requests 和相关源文件连接成统一训练序列的范式
- 在 GLM-5 中,作者放宽了 Repo-level 过滤标准,以扩大合格仓库的范围,产生了大约 10M 个 issue-PR 对,同时加强了个别 issue 级别的质量过滤以减少噪音
- 作者还为每个 issue-PR 对检索了更大规模的相关文件集合,从而产生更丰富的开发上下文和更广泛的现实世界软件工程场景覆盖
- 经过过滤,数据集的 issue-PR 部分包含大约 160B 唯一 token
Long-context data
- 长上下文训练集包括自然数据和合成数据
- 自然数据来源于书籍、学术论文和来自通用预训练语料库的文档,采用多阶段过滤(PPL、去重、长度),并对知识密集型领域进行上采样
- 在合成数据构建中,受 NextLong (2025) 和 EntropyLong (2025) 的启发,作者采用了多种技术来构建长程依赖关系
- 通过交错打包将高度相似的文本聚合以产生序列,旨在缓解“中间丢失”现象,并提高在各种长上下文任务上的性能
- 在 200K 阶段,作者还加入了一小部分类似 MRCR 的数据,设计了多种变体以扩展 OpenAI 的原始范式,以增强在扩展的多轮对话中的召回能力
- 根据经验,作者发现增加数据多样性可逐步提高模型的长上下文性能
- 特别说明:在最初的 128K 阶段之后,再进行一个 200K 的 Mid-training 阶段,即使在 128K 上下文窗口内也进一步增强了模型的性能
Training Infrastructure
Memory Efficiency
Flexible MTP placement
- 在交错流水线并行 (2021) 下,模型组件被灵活地分配到各个 Stage
- 问题:
- MTP 模块跨越 Embedding 、transformer 和输出组件
- MTP 其他模块消耗明显更高的内存,导致 Stage-level 不平衡
- 解法:作者将 MTP 输出层与主输出层共同放置在最后一个 Stage 以实现参数共享,同时将其 Embedding 和 transformer 组件放置在前一个阶段
- 这减少了最后一个 Stage 的内存压力,并改善了流水线 ranks 之间的平衡
Pipeline ZeRO2 gradient sharding
- 每个流水线 rank 维护多个 Stages (2021),并且原生的每个 Stage 都需要一个完整的梯度缓冲区用于累积和优化器更新
- 受 ZeRO2 (2020) 启发,作者在数据并行 ranks 之间对梯度进行分片,这样每个 Stage 只存储完整梯度的 \(1/dp\) 部分
- 此外,仅保留两个 Stage 的完整累积缓冲区,并通过双缓冲重用它们
- 当一个 Stage 缓冲区在连续微批次上累积梯度时,前一个 Stage 缓冲区的梯度同步并行执行
- 这将持久性梯度内存减少到每 Stage 的分片缓冲区加上仅用于滚动累积的两个完整缓冲区,而实践中没有额外的同步开销
Zero-redundant communication for the Muon distributed optimizer
- 朴素的 Muon 实现在每个数据并行 rank 上 All-gather 完整模型参数
- 这导致了瞬时内存峰值和冗余通信
- 作者将 All-gather 限制在每个 rank 拥有的参数分片上,并将本地计算与分片通信重叠
- 这消除了冗余通信,并显著降低了与优化器相关的峰值内存开销
Pipeline activation offloading
- 在流水线预热期间,前向执行先于反向传播,延长了中间激活的生命周期
- 作者在前向执行后将激活卸载到主机内存,并在反向执行前重新加载它们 (2024)
- 卸载以层粒度应用,以进一步减少峰值内存使用
- 结合细粒度的重计算,在很大程度上消除了将激活常驻在 GPU 内存中的需要
- 卸载和重新加载的调度与计算重叠,同时避免与点对点通信和 MoE token 路由(分发和组合)争用
- 这显著减少了激活内存占用,且开销几乎为零
Sequence-chunked output projection for peak memory reduction
- 输出投影和交叉熵损失会产生瞬态内存开销,这是由于存储用于反向传播的激活以及在损失计算期间将它们提升到更高精度
- 为了减少这种开销,作者将输入序列划分为更小的块,并在每个块上独立计算投影和损失,完成前向和反向传播后立即释放激活
- 因此,峰值内存使用随着块数量的增加而减少
- 通过设置适当的块数量,这种方法减轻了输出层的内存压力,同时保持与未分块执行相当的性能
Parallelism Efficiency
Efficient deferred weight gradient computation
- To Reduce Pipeline Bubbles,作者将一些权重梯度计算移出关键路径 (2023)
- 通过优化存储和通信重叠的细粒度延迟,提高了吞吐量,同时保持内存开销可控
Efficient long-sequence training
- 更长的序列加剧了数据并行和流水线并行组之间的负载不平衡
- 作者通过工作负载感知的序列重排序、注意力计算的动态重新分配以及将数据并行 ranks 灵活划分为不同大小的上下文并行组来解决这个问题 (2025; 2025)
- 一种分层 all-to-all 方式重叠 QKV 张量的节点内和节点间通信以减少延迟
INT4 Quantization-aware training
- 为了在低精度下提供更好的准确性,作者在 SFT 阶段应用了 INT4 QAT
- 为了进一步减轻训练时间开销,作者开发了一个适用于训练和离线权重量化的量化 kernel,确保训练和推理之间的行为按位一致(ensures bitwise-identical behavior between training and inference)
Post-Training
- GLM-5 的后训练阶段旨在将基础模型转变为具有强大推理、编码和 agentic 能力的高性能助手
- 如图5所示,作者的流程遵循一种渐进的对齐策略:
- 从引入复杂交错思考模式的多任务监督微调开始
- 然后是针对推理和 agentic 任务的专门强化学习阶段
- 最后以通用 RL 阶段结束,以实现类似人类的对齐
- GLM-5 利用 on-policy cross-stage distillation 作为最终的精炼步骤,在利用每个训练阶段带来的性能提升的同时,有效地缓解了能力退化
Supervised Fine-Tuning
- 与 GLM-4.5 相比,GLM-5 在 SFT 阶段显著扩展了 Agent 和编码数据的规模,GLM-5 的 SFT 语料库涵盖三大类别:
- 通用聊天:问答、写作、角色扮演、翻译、多轮对话和长上下文交互
- 推理:数学、编程和科学推理
- 编码与智能体:前端和后端工程代码、工具调用、编码智能体、搜索智能体和通用智能体
- GLM-5 在 SFT 期间将最大上下文长度扩展到 202,752 个 token
- 结合更新的聊天模板,该模型支持三种不同的思考特性(参见图7),包括:
- Interleaved Thinking:模型在每次响应和工具调用前进行思考,提高了指令跟随能力和生成质量
- Preserved Thinking:在编码智能体场景中,模型自动在多轮对话中保留所有思考块,重用现有推理而不是从头开始重新推导
- 这减少了信息丢失和不一致性,非常适合长视野、复杂的任务
- Turn-level Thinking:模型支持在会话中按轮次控制推理,为轻量级请求禁用思考以减少延迟/成本,为复杂任务启用思考以提高准确性和稳定性
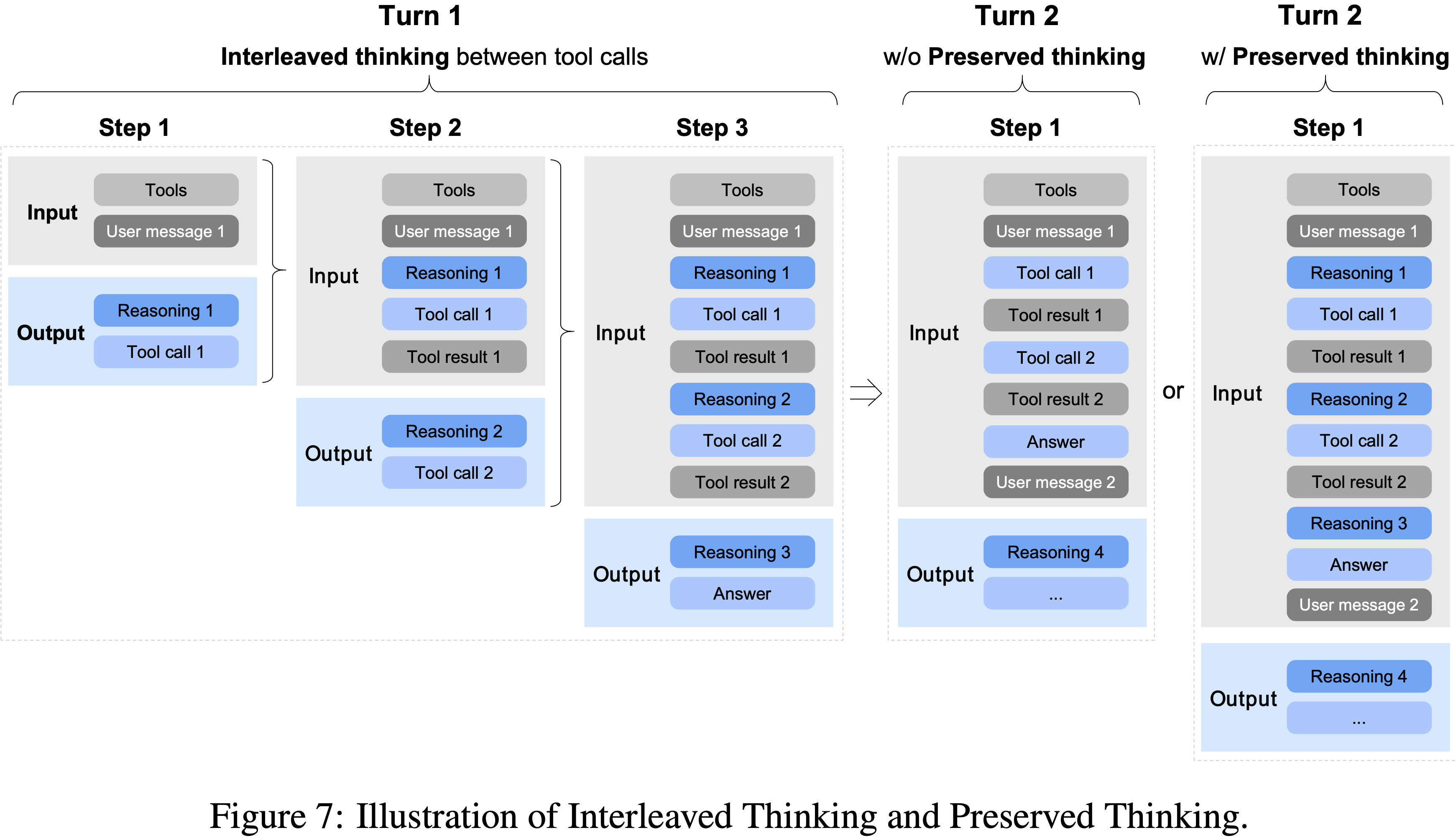
- GLM-5 在动作之间进行思考并保持跨轮次的一致性,在复杂任务上实现了更稳定和可控的行为
- 对于通用聊天
- 与 GLM-4.5 相比,优化了响应风格,使其更具逻辑性和简洁性
- 对于角色扮演任务,收集和构建了一个更广泛、更多样化的数据集,涵盖多种语言和角色配置
- 特别是,作者定义了几个评估维度(包括指令跟随、语言表现力、创造力、逻辑连贯性和长对话一致性),并应用自动和人工过滤来筛选和精炼数据
- 对于推理任务
- 进一步增强模型推理的深度
- 对于逻辑推理,作者构建了可验证的问题,并使用拒绝采样合成高质量数据
- 对于数学和科学问题,应用了基于难度的过滤流程,只保留那些对 GLM-4.7 模型具有挑战性的问题
- 对于编码和智能体任务
- 与 GLM-4.5 相比,GLM-5 构建了大量的执行环境以获得高质量的轨迹,特别强调现实世界场景和长视野任务
- 使用专家强化学习和拒绝采样进一步改进 SFT 数据
- 轨迹中的错误片段被保留,但在损失函数中被掩盖 ,允许模型学习纠错行为,而不会强化错误动作
Reasoning RL
RL algorithm backbone
- 本文的 RL 算法建立在 GRPO 之上
- 注:结合了 IcePop 技术 (2025) 以缓解训练-推理不匹配问题,即 RL 优化期间推理分布与训练分布之间的差异
- 明确区分了用于梯度更新的训练策略 \(\pi^{\mathrm{train} }\) 和用于轨迹采样的推理策略 \(\pi^{\mathrm{infer} }\)
- 与原始的 IcePop 公式相比,作者去除了 KL 正则化项以加速 RL 改进。最终的优化损失为:
$$\begin{array}{rl}\mathcal{L}(\theta) = -\mathbb{E}_{x\sim \mathcal{D},\{y_i\}_{i = 1}^G\sim \pi_{\theta_{\mathrm{old} } }^{\mathrm{infer} }(\cdot |x)}\left[\frac{1}{G}\sum_{i = 1}^G\frac{1}{|y_i|}\sum_{t = 1}^{|y_i|}\mathrm{pop}(\rho_{i,t},1 / \beta ,\beta) \cdot \min \left(r_{i,t}\hat{A}_{i,t},\mathrm{clip}(r_{i,t},1 - \epsilon_{\mathrm{low} },1 + \epsilon_{\mathrm{high} })\hat{A}_{i,t}\right)\right] \end{array} \tag {1}$$ - 其中训练-推理不匹配比率定义为
$$\rho_{i,t} = \frac{\pi_{\theta_{\mathrm{old} } }^{\mathrm{train} }(y_{i,t}\mid x,y_{i,< t})}{\pi_{\theta_{\mathrm{old} } }^{\mathrm{infer} }(y_{i,t}\mid x,y_{i,< t})} $$ - 操作符 \(\mathrm{pop}(\cdot)\) 抑制那些不匹配比率过度偏离的样本:
$$ \mathrm{pop}(\rho, l, h) = \begin{cases} 0 & \text{if } \rho < l \text{ or } \rho > h \\ 1 & \text{otherwise} \end{cases} $$ - PPO 风格的重要性比率和组归一化优势遵循原始的 GRPO 定义:
$$r_{i,t} = \frac{\pi_{i}^{\mathrm{train} }(y_{i,t}\mid x,y_{i,< t})}{\pi_{i_{\mathrm{old} } }^{\mathrm{train} }(y_{i,t}\mid x,y_{i,< t})},\quad \hat{A}_{i,t} = \frac{R_{i} - \mathrm{mean}(R_{1},\ldots,R_{G})}{\mathrm{std}(R_{1},\ldots,R_{G})}.$$ - 在训练期间,作者设置超参数 \(\beta = 2\),\(\epsilon_{\mathrm{low} } = 0.2\),\(\epsilon_{\mathrm{high} } = 0.28\)
- 训练完全在 on-policy 下进行,组大小为 32,批量大小为 32
DSA RL insights
- 作者在基于 DSA 架构的模型上进行了非常大规模的 RL 训练
- 问题:
- 与 MLA 相比,DSA 引入了一个额外的 indexer,它检索最相关的 top-k 键值条目,并在检索到的子集上稀疏地计算注意力
- 检索到的 top-k 结果对于 RL 稳定性至关重要
- 这类似于 MoE 模型如何使用路由重放 (2025) 来保留激活的 top-k 专家,以确保训练-推理一致性
- 但在每个 token 位置存储 indexer 的 top-k 索引显然是不切实际的
- 因为 indexer 使用的 \(k = 2048\) 远大于 MoE 中通常使用的 \(k\),并且存储所有这些索引将带来巨大的存储成本以及训练引擎和推理引擎之间的显著通信开销
- 与 MLA 相比,DSA 引入了一个额外的 indexer,它检索最相关的 top-k 键值条目,并在检索到的子集上稀疏地计算注意力
- 解法:
- 作者发现采用确定性的 top-k 操作符可以有效解决这个问题
- 与 SGLang 的 DSA Indexer 中使用的非确定性 CUDA 基础 top-k 实现相比,直接使用朴素的
torch.topk稍慢但具有确定性torch.topk产生更一致的输出,并带来显著的 RL 收益
- 相比之下,其他非确定性的 top-k 操作符(例如 CUDA 或 TileLang 实现)在仅仅几步 RL 后就导致了剧烈的性能下降,并伴随着熵的急剧下降
- 因此,在作者的整个 RL 阶段,作者在训练引擎的 DSA Indexer 中使用
torch.topk作为默认的 top-k 操作符 - 作者在 RL 期间默认冻结 indexer 参数,以加速训练并防止 indexer 中的学习不稳定
Mixed domain reasoning RL
- 在推理 RL 阶段,作者在四个领域进行混合 RL 训练:数学、科学、代码和工具集成推理(Tool-integrated Reasoning ,TIR)
- 对于数学和科学,作者从开源数据集 (2025) 和与外部标注供应商共同开发的集合中筛选数据
- 作者进一步应用难度过滤,将训练重点放在 GLM-4.7 很少或始终无法正确解决,但更强的教师模型(例如 GPT-5.2 xhigh 和 Gemini 3 Pro Preview)能够解决的问题上
- 对于代码,作者涵盖竞争性编程风格的任务和科学编码任务
- 前者主要来源于 Codeforces 和代表性数据集,如 TACO (2023) 和 SYNTHETIC-2-RL (2025),而后者则通过将问题分解为正确解决方案所需的最小代码实现,从内部问题库中构建
- 对于 TIR,作者复用了数学和科学 RL 数据中更具挑战性的子集,并另外与标注供应商共同构建了 STEM 问题,这些问题明确设计为使用外部工具来回答
- 在 RL 训练期间,作者分配领域和来源特定的 judge 模型或评估系统来产生二元结果奖励
- 作者保持四个领域之间的整体混合大致平衡,并始终观察到在混合 RL 设置下,每个领域都取得了稳定且显著的收益
Agentic RL
- 朴素的同步 RL 在长视野智能体 rollout 期间存在严重的 GPU 空闲时间
- 为了促进 GLM-5 的 agentic 性能,作者开发了一个完全异步和解耦的 RL 框架,并在编码和搜索智能体任务上优化 GLM-5
- 通过中央多任务 Rollout 协调器将推理引擎和训练引擎解耦,作者在不同的 agentic 工作负载上实现了高吞吐量的联合训练
- 为了在异步 off-policy 条件下保持训练稳定性,GLM-5 引入了两个关键机制
- 机制1:Token-in-Token-out(TITO)网关通过保留精确的动作级对应关系,消除了重新 tokenization 的不匹配
- 机制2:直接双面重要性采样,对 rollout log-probabilities 应用 Token-level 裁剪机制 \((1 - \epsilon_{t},1 + \epsilon_{h})\),同时有效控制 off-policy 偏差,而无需跟踪历史策略检查点
- 为了加速,作者还采用了 DP-aware 路由,以在长上下文推理期间最大化大型 MoE 模型的 KV 缓存重用
- 为了扩展 agentic 环境,作者在三个领域扩展了可验证的训练环境:
- 超过 10,000 个现实世界的软件工程任务
- 终端任务
- 高难度多跳搜索任务
- 注:关于 agentic RL 的更多细节可以在后面的第 4 节中找到
General RL
Multi-dimensional optimization objectives
- 作者将通用 RL 的优化目标分解为三个互补的维度:
- 基础正确性,foundational correctness
- 情感智能,emotional intelligence
- 任务特定质量,task-specific quality
- 三个维度的详细解释如下:
- 基础正确性 维度作为响应质量的基石
- 针对一系列削弱模型输出可用性的错误类型,包括指令跟随失败、逻辑不一致、事实不准确、知识幻觉和语言不流畅
- 目标是最大限度地降低错误率,使响应达到可用的基线水平
- 作者认为这是所有后续优化的先决条件:包含事实错误或误解用户意图的响应,无论其外观多么精致,都可能误导用户
- 情感智能 维度优化核心正确性之外的用户体验
- 目标是产生富有同理心、有洞察力且风格接近自然人类交流的响应,使与模型的交互感觉更自然、更吸引人
- 任务特定质量 维度针对各种特定任务进行细粒度优化
- 建立在基础正确性建立的可用性之上,它旨在将响应从仅仅是正确的提升到在每个任务类别内真正高质量的级别
- 该维度涵盖广泛的任务,包括写作、文本处理、主观和客观问答、角色扮演和翻译。每个任务领域都要求不同的奖励信号,需要混合奖励系统
- 基础正确性 维度作为响应质量的基石
Hybrid reward system
- 为了监督上述多样化的目标,作者构建了一个混合奖励系统,它集成了三种互补类型的奖励信号:
- 基于规则的奖励函数,rule-based reward functions
- 结果奖励模型,outcome reward models (ORMs)
- 生成式奖励模型,generative reward models (GRMs)
- 每种方法都有其独特的优缺点,它们的结合是稳定、高效和可扩展的通用 RL 训练过程的关键
- 基于规则的奖励 提供精确且可解释的信号,但仅限于可表达为确定性规则的方面
- ORM 提供低方差信号和高训练效率,但更容易受到 Reward Hacking 行为的影响
- 即策略利用表面模式而不是真正提高核心能力
- GRM 利用语言模型产生标量或结构化评估,并且更能抵抗这种利用,但往往表现出更高的方差
- 通过混合这三种信号类型,作者获得了一个平衡了精度、效率和鲁棒性的奖励系统,减轻了任何单一组件的弱点
Human-in-the-loop style alignment
- 通用 RL 流程的一个独特之处在于明确纳入了高质量的人类编写的响应
- 作者不只依赖模型生成的响应,而是引入专家人类响应作为风格和质量的锚点
- 以上是基于观察得到的:纯模型生成的优化倾向于收敛到可识别的“类似模型”模式,通常是冗长的、公式化的,或者缺乏熟练人类写作的细微差别
- 通过让模型接触人类编写的范例,作者鼓励它采用更自然、更符合人类习惯的响应模式
On-Policy Cross-Stage Distillation
- 在多阶段 RL 流程中,为不同目标进行顺序优化可能导致先前获得的能力累积退化
- 为了缓解这个问题,作者执行 on-policy cross-stage distillation 作为最终阶段,采用 on-policy 蒸馏算法 (2025) 快速恢复早期 SFT 和 RL 阶段(Reasoning RL 和 General RL)获得的技能
- 具体方法:
- 先前训练阶段的最终检查点作为教师模型,其中训练 Prompt 从相应教师的 RL 训练集中采样,并以适当比例混合
- 训练损失可以通过用以下公式替换公式1中的优势项来获得(’sg’ 代表 stop gradient 操作,例如
.detach()):
$$\hat{A}_{i,t} = \mathrm{sg}\left[\log \frac{\pi_{i,\mathrm{base} }^{\mathrm{infer} }(\boldsymbol{y}_{i,t}\mid\boldsymbol{x},\boldsymbol{y}_{i,< t})}{\pi_{i,\mathrm{in} }^{\mathrm{infer} }(\boldsymbol{y}_{i,t}\mid\boldsymbol{x},\boldsymbol{y}_{i,< t})}\right]. \tag {2}$$
- 目前,作者利用推理引擎获取教师的 logits
- 将来,作者计划将推理后端迁移到训练引擎,并统一采用 MLA 的多查询注意力模式进行推理
$$ (\pi_{i,\mathrm{base} }^{\mathrm{infer} }\rightarrow \pi_{i,\mathrm{base} }^{\mathrm{train} })$$ - 在训练期间,GRPO 算法中的组大小配置为 1 以增加数据吞吐量,批量大小设置为 1024
- 在这个阶段这样做是可行的,因为不再需要为每个 Prompt 维持一大组样本来估计优势;优势直接根据与教师模型的差距计算得出
RL Training Infrastructure: The slime Framework
- GLM-5 继续使用 slime 作为统一后训练基础设施,实现大规模的端到端强化学习
- GLM-5 没有引入新的系统组件,而是充分利用了 slime 的能力:
- (1) 通过自由形式的 rollout 定制和基于服务器的执行模型来拓宽任务覆盖范围
- (2) 通过混合精度训练/rollouts 结合 MTP 和 Prefill-Decode 分离,特别是对于多轮 RL 工作负载,来显著提高吞吐量
- (3) 通过心跳驱动的 rollout 容错和路由器级服务器生命周期管理,来提高鲁棒性
Scaling Out: Flexible Training via Highly Customizable Rollouts
- GLM-5 的后训练涵盖多样化的目标谱系
- 为了支持这种多样性而无需特定于任务的分支,GLM-5 利用了 slime 高度可定制的 rollout 接口及其基于服务器的 rollout 执行
Highly customizable rollouts
- slime 提供了一个灵活的接口,用于实现特定于任务的 rollout 逻辑(包括多轮交互循环、工具调用、环境反馈处理和验证器引导的分支)而无需修改底层基础设施
- GLM-5 利用此功能支持广泛的领域和训练范式,包括但不限于推理 RL、通用 RL、agentic RL 和 on-policy 蒸馏,所有这些都在统一的训练栈中完成
Server-based rollouts via HTTP APIs
- slime 通过标准 HTTP API 暴露其 rollout 服务器和推理路由器,允许用户以与传统推理引擎相同的方式与 slime 的服务层交互
- 这将 rollout 逻辑与训练进程边界解耦:
- 外部智能体框架和环境可以直接调用服务器/路由器端点
- 短视野的单轮训练和长视野的多轮轨迹,优化后端保持不变
Scaling Up: Tail-Latency Optimization for RL Rollouts
- 对于 RL rollouts,优化目标不是总吞吐量,而是端到端延迟,由每一步中最慢的样本主导
- 在实践中,单个拖尾轨迹可能会阻塞同步点(例如,批次完成、缓冲区就绪、训练器更新),并直接决定挂钟进度
- 因此,GLM-5 充分利用 slime 的延迟导向服务和调度机制,以最小化中位数延迟,更重要的是,尾部延迟
No-queue serving via multi-node inference with DP-attention for MLA
- 通过具有 MLA 的 DP 注意力实现多节点推理的无队列服务
- 为了避免排队延迟,即使在突发流量下也必须及时服务 rollout 请求,这需要大量的 KV 缓存容量
- GLM-5 采用多节点推理部署(例如,在 8 个节点上使用 EP64 和 DP64)来提供充足的分布式 KV 缓存
- 引入 DP 注意力主要是为了防止在不同 ranks 之间复制 KV
Tail-latency reduction with FP8 rollouts and MTP
- 使用 FP8 rollouts 和 MTP 减少尾部延迟
- GLM-5 使用 FP8 进行 rollout 推理,以减少每 token 延迟并缩短长轨迹的完成时间
- 此外,GLM-5 利用 slime 对多 token 预测的支持,这在 RL rollouts 典型的小批量解码 regime 下特别有效。由于尾部延迟通常由小批量
Tail-latency reduction with FP8 rollouts and MTP
- 1)GLM-5 使用 FP8 进行 Rollout 推理,以减少每 Token 延迟并缩短长轨迹的完成时间
- 2)GLM-5 利用了 slime 对 MTP 的支持
- 这在 RL Rollout 典型的小批量解码场景下尤其有效
- 由于尾延迟通常由小批量中的掉队者(stragglers)引起(例如,罕见的长上下文、复杂的多轮推理、密集使用工具的执行轨迹)
- MTP 在长尾部分提供了不成比例的巨大收益,改善了最慢样本的完成时间,从而减少了步骤级的停滞时间
PD disaggregation to prevent prefill-decode interference in multi-turn RL
- 在多轮设置中,长前缀的预填(prefill)操作非常频繁(对话历史、工具执行痕迹、代码上下文)
- 在 DP-Attention 下,将预填和解码混合在同一个服务资源上会产生严重的干扰:一个繁重的预填操作可能会抢占或中断服务器上正在进行的解码,阻碍其他样本持续取得进展,并急剧恶化尾延迟
- GLM-5 利用了 slime 的预填-解码 (PD) 分离功能
- 通过在专用资源上运行预填和解码,解码过程保持稳定且不受中断,使得长时程样本能够持续进行,从而显著改善了多轮智能体 RL 中的尾延迟表现
Rollout Robustness: Heartbeat-Driven Fault Tolerance
- 在大规模下,瞬时故障(例如,单个服务器崩溃、网络问题或性能下降)是不可避免的
- GLM-5 利用 slime 的心跳驱动容错来确保在此类事件下的训练连续性:
- rollout 服务器定期发出由编排层监控的心跳,不健康的服务器会被主动终止并从推理路由器注销
- 重试会自动从故障或降级服务器路由到健康服务器,防止单个服务器事件中断 rollouts,并保持不间断的端到端 RL 训练
Agentic Engineering
- 作者描述了从氛围编程(vibe coding,即通过人类 Prompt 编程)到智能体工程(agentic engineering)的转变
- 在氛围编程中,人类 Prompt AI 模型编写代码
- 在智能体工程中,AI 智能体自己编写代码
- 它们进行规划、实现和迭代
- 为了支持这些 Long-horizon 任务,GLM-5 利用了一个完全异步和解耦的 RL 框架,通过减少智能体 Rollout 过程中的空闲时间,显著提升了 GPU 利用率
- 为了扩展智能体环境,作者开发了环境构建流水线
- 对于编码任务,作者通过创建超过 10,000 个可验证的训练场景,设置了真实的软件工程问题和终端任务
- 对于搜索智能体,作者开发了一个自动且可扩展的复杂多步推理数据合成流水线,用于构建智能体训练数据
Asynchronous RL for Agentic Tasks
- 为智能体任务 RL 训练设计了一个完全异步和解耦的 RL 基础设施
- 能高效处理 Long-horizon 智能体 Rollout,并支持跨不同智能体框架的灵活多任务 RL 训练
- 采用基于组的策略优化算法进行 RL 训练
- 对于每个问题 \(x\) ,作者从旧策略 \(\pi_{\mathrm{old} }\) 中采样 \(K\) 条智能体轨迹 \(\{y_{1},\ldots ,y_{K}\}\) ,并根据以下目标优化模型 \(\pi_{\theta}\) :
$$L(\theta) = \mathbb{E}_{x\sim \mathcal{D} }\left[\frac{1}{K}\sum_{i = 1}^{K}(r(x,y_i) - \bar{r} (x))\right],$$- 其中 \(\begin{array}{r}\bar{r} (x) = \frac{1}{K}\sum_{i = 1}^{K}r(x,y_i) \end{array}\) 是采样响应的平均奖励
- 注:只有模型生成的 Token 用于优化,环境反馈在损失计算中被忽略
- 对于每个问题 \(x\) ,作者从旧策略 \(\pi_{\mathrm{old} }\) 中采样 \(K\) 条智能体轨迹 \(\{y_{1},\ldots ,y_{K}\}\) ,并根据以下目标优化模型 \(\pi_{\theta}\) :
Asynchronous RL Design for Agentic Training
- 由于 Rollout 过程的长尾特性,同步 RL 训练在 Rollout 阶段会引入大量气泡,这是因为智能体任务生成的严重不平衡,可能导致 GPU 长时间空闲
- 为了提高训练吞吐量,作者对 Agentic RL 采用完全异步的训练范式,以提升 GPU 利用率和训练效率
- 具体方法:
- 将训练引擎和推理引擎解耦到不同的 GPU 设备上
- 推理引擎持续生成轨迹,生成的轨迹数量达到预定义的阈值后,该批次就会被发送到训练引擎以更新模型
- 为了减少策略滞后并保持训练近似 On-policy,Rollout 引擎使用的模型权重会定期与训练引擎的权重同步
- 训练引擎每进行 \(K\) 次梯度更新,就会更新模型参数并将新权重推回推理引擎
- 虽然异步可以显著提高整体训练效率,但这也意味着不同的轨迹可能由不同版本的模型生成,从而引入了严重的 Off-policy 问题
- 由于推理策略的变化使得权重更新面临不同的优化问题,在每次更新推理引擎的权重后需要重置优化器
- 理解:混合策略下的优化目标不再是“当前策略下的期望回报”,而是一个混合策略分布下的期望回报,这本质上是一个不同的优化问题(different optimization problem),因为:
- 数据分布变了
- 策略的梯度方向可能不一致
- 训练不再是对当前策略的稳定改进
- 理解:为什么“重置优化器”能缓解这个问题?
- 在标准的优化器(如 Adam)会维护动量(momentum) 和方差(variance) 等状态
- 这些状态是累积历史梯度信息的,假设优化目标是平滑变化的
- 但在异步 RL 中:
- 每次推理引擎更新后,优化目标(采样数据分布决定了优化目标)发生了突变
- 如果保留旧的优化器状态,可能会:
- 引入错误的梯度方向
- 导致训练不稳定
- 延缓收敛
- 因此,作者选择在每次推理引擎权重更新后重置优化器,相当于:
- 清空历史梯度信息
- 重新开始优化当前策略下的新目标
- 在标准的优化器(如 Adam)会维护动量(momentum) 和方差(variance) 等状态
- 理解:混合策略下的优化目标不再是“当前策略下的期望回报”,而是一个混合策略分布下的期望回报,这本质上是一个不同的优化问题(different optimization problem),因为:
Server-based multi-task training design
- 为了解决多任务 RL 中轨迹生成的异质性(不同任务通常依赖不同的工具集和特定于任务的 Rollout 逻辑),作者引入了一个基于服务器的多任务 Rollout Orchestrator 用于多任务 RL 训练
- 该组件旨在通过一个中心 Orchestrator 协调多个注册的任务服务,确保 slime RL 训练框架与下游任务之间的无缝兼容
- 具体方法:
- 每个任务将其自己的 Rollout 和奖励逻辑实现为一个独立的微服务,并在中心 Orchestrator 上注册以进行管理和调度
- 在 Rollout 阶段,中心 Orchestrator 控制每个任务的 Rollout 比例和生成速度,以实现跨任务的数据收集平衡
- 这里的关键在于:将所有智能体任务的轨迹标准化为统一的消息列表表示形式
- 这使得能够对复杂的智能体框架(例如软件工程任务)进行联合训练,同时也支持对异构工作负载进行集中的后处理和日志记录
- 这种设计将任务特定的逻辑与核心训练循环清晰地隔离开来,实现了与多任务 RL 训练的无缝集成
- 作为 GLM-5 训练基础设施的骨干,该 Orchestrator 支持超过 1000 个并发的 Rollout,并能够自动动态调整任务采样比例,以及对任务进度进行细粒度监控
Optimizing Asynchronous Training Stability
Token-in-Token-out vs. Text-in-Text-out
- 在 RL Rollout 设置中:
- Token-in-Token-out (TITO) 意味着训练流水线消费由推理引擎产生的确切 Tokenization 和解码后的 Token 流,并直接使用它来构建用于学习的轨迹
- Text-in-Text-out 将 Rollout 引擎视为一个黑盒,返回最终确定的文本;然后训练器通过对该文本进行重新 Tokenization (通常还要重新推导边界和截断)来重建轨迹,然后再计算损失
- 以上这个看似微小的选择却至关重要:
- 重新 Tokenization 可能会在 Token 边界、空格/标准化处理、截断或特殊 Token 放置方面引入细微的不匹配,这进而可能破坏动作和奖励/优势之间的步骤对齐
- 尤其是在 Rollout 被流式传输、截断或跨多个执行器交错时
- 作者发现 Token-in-Token-out 对于异步 RL 训练至关重要,因为它保留了采样内容与优化内容之间精确的动作级对应关系,同时使执行器能够立即发出轨迹片段(Token ID + 元数据),而无需经过有损的文本往返过程,也无需在学习器端等待事后的重新 Tokenization
- 重新 Tokenization 可能会在 Token 边界、空格/标准化处理、截断或特殊 Token 放置方面引入细微的不匹配,这进而可能破坏动作和奖励/优势之间的步骤对齐
- 在实践中,作者实现了一个 TITO Gateway,拦截来自 Rollout 任务的所有生成请求,并记录每条轨迹的 Token ID 和元数据
- 这种设计将繁琐的 Token ID 处理与下游智能体 Rollout 逻辑隔离开 来,同时避免了 RL 训练期间因重新 Tokenization 导致的不匹配
Direct double-sided importance sampling for token clipping
- 与第 3 节中的同步 RL 训练设置不同,在异步设置中,Rollout 引擎可能在单条轨迹生成过程中经历多次更新 ,这使得追踪确切的行为概率 \(\pi_{\theta_{\mathrm{old} } }\) 在计算上变得不可行
- 在这种情况下,我们可能将不得不维护一个庞大的模型检查点历史 \(\{\pi_{\theta_{\mathrm{old} }^{(1)} },\ldots ,\pi_{\theta_{\mathrm{old} }^{(N)} }\}\) ,这在实际实现中是行不通的
- 解决方案:
- 1)采用一种简化的 Token-level 重要性采样机制,该机制重用 Rollout 期间生成的 Log-probabilities 作为直接的行为代理
- 通过将重要性采样比率计算为 \(r_t(\theta) = \frac{\pi_{\theta} }{\pi_{\mathrm{rollout} } }\) ,并丢弃传统的 \(\pi_{\theta_{\mathrm{old} } }\) ,作者消除了单独进行旧策略推理的计算开销
- 2)采用一种双面校准的 Token-level 掩码策略
- 注:这不是使用标准 PPO 中使用的非对称裁剪,而是将信任区域限制在 \([1 - \epsilon_t, 1 + \epsilon_h]\) ,其中 \(\epsilon_t\) 和 \(\epsilon_h\) 是裁剪超参数
- 落在此区间之外的 Token 将完全从梯度计算中掩盖,以防止因策略极端分歧而导致的不稳定性
- 这与 IcePop 机制 (2025) 有相似之处,但 GLM-5 作者的策略更简单,因为它进一步移除了 \(\pi_{\theta_{\mathrm{old} } }\) 并实现了更稳定的训练
- 1)采用一种简化的 Token-level 重要性采样机制,该机制重用 Rollout 期间生成的 Log-probabilities 作为直接的行为代理
- 形式上,带有 Token-level 裁剪的优化目标可以写成:
$$
\mathcal{L}(\theta) = \mathbb{E}_t \left[ f(r_t(\theta), \epsilon_l, \epsilon_h) A_t \log \pi_{\theta}(a_t|s_t) \right] \tag {3}
$$- 在这个公式中,重要性采样比率 \(r_t(\theta)\) 计算如下:
$$
r_t(\theta) = \exp \left( \log \pi_{\theta}(a_t|s_t) - \log \pi_{\text{rollout} }(a_t|s_t) \right) \tag {4}
$$ - 稳定性进一步通过校准函数 \(f(x; \epsilon_l, \epsilon_h)\) 来加强:
$$
f(x; \epsilon_l, \epsilon_h) =
\begin{cases}
x, & \text{If } 1 - \epsilon_l < x < 1 + \epsilon_h \\
0, & \text{Otherwise }
\end{cases} \tag {5}
$$
- 在这个公式中,重要性采样比率 \(r_t(\theta)\) 计算如下:
- 在实验中,作者发现重用 Rollout Log-probabilities 允许一定程度的可控 off-policy 偏差,以避免追踪历史策略的需求,同时提升训练稳定性
Dropping off-policy and noisy samples
- 问题1:在异步 RL 中,过长的轨迹可能会变得高度 off-policy,这可能会 destabilize 训练
- 解法1:为了过滤掉这些严重 off-policy 的样本,作者在生成时记录了 Rollout 引擎使用的策略权重版本
- 解法1 具体方法(维护陈旧性指标并丢弃过于陈旧的轨迹):
- 对于每个 Response,作者记录了所涉及的模型版本序列 \((w_0, \ldots, w_k)\),其中 \(w_0 < \cdots < w_k\)
- 令 \(w’\) 表示当前的策略版本
- 如果某个样本的最旧 Rollout 版本过时,即如果 \(w’ - w_0 > \tau\)(其中 \(\tau\) 是一个预定义阈值),就丢弃该样本
- 这移除了那些落后于当前策略太多的轨迹
- 问题2:Coding-agent 沙箱可能 inherently 不稳定,并且可能因与模型无关的原因(例如,环境崩溃)而失败
- 此类失败会引入有噪声的训练信号,因为它们反映的是环境的不稳定性,而非模型的能力
- 解法2:记录每个样本的失败原因,并排除了因环境崩溃而失败的样本
- 对于像 GRPO 这样基于组的采样方法,移除失败的样本可能会导致组不完整,在这种情况下:
- 如果有效样本的数量超过组大小的一半,通过重复有效样本的方式来填充该组
- 否则,丢弃整个组
- 这个过程减少了虚假的奖励噪声,并提高了训练稳定性
- 对于像 GRPO 这样基于组的采样方法,移除失败的样本可能会导致组不完整,在这种情况下:
DP-aware routing for acceleration
- 作者提出了一种 DP 感知的路由机制,以便在为大规模 MoE 推理进行数据并行时,保留 KV 缓存的局部性
- 在多轮 Agent 工作负载中,来自同一个 Rollout 的连续请求共享相同的前缀
- 为了最大化 KV 重用,作者强制执行 Rollout 级的亲和性:
- 属于给定 Agent 实例的所有请求都被路由到同一个 DP rank
- 具体方法:
- 引入一个有状态的路由层,它使用一致性哈希将每个 Rollout ID 映射到一个固定的 DP rank
- 这种映射在多轮之间保持稳定,消除了跨 rank 的缓存缺失
- 为了防止长期的不平衡,将哈希与哈希空间上的轻量级动态负载均衡结合起来
- 这种设计避免了冗余的 Prefill 计算,而无需在 DP rank 之间同步 KV
- 随着 Rollout 长度的增加,Prefill 成本仍然与增量 token 成正比,而不是与总上下文长度成正比
- 改善了端到端的延迟,并为长上下文 Agentic 推理带来了更高的有效吞吐量
- 引入一个有状态的路由层,它使用一致性哈希将每个 Rollout ID 映射到一个固定的 DP rank
Asynchronous Attention-aware Load Balancing for Agentic Inference
- 问题:Rollout 过程中时间线的延长和环境的异构性,大规模智能体训练的推理工作负载可能存在显著差异,导致在 MoE 模型中将请求路由到不同专家时出现负载不平衡
- 这种不平衡会导致推理延迟出现不可接受的峰值
- 解法:在 MoE 模型的 Attention 和 FFN 部分都采用了负载均衡感知的路由策略
- 在训练有素的 MoE 模型中
- FFN 路由已经相对稳定,其负载不平衡可以通过专家并行和数据并行策略的组合来缓解
- 但 Attention 路由的动态性要高得多:
- 在不同 Agentic 任务中,指令和中间生成的 Token 的内容变化多样,导致 Attention 路由(即 DSA 中的 Lightning Indexer)选择的 Top-k KV 条目出现显著的负载波动
- 这会导致 KV 检索延迟出现长尾分布,严重拖慢 Rollout 速度,并在异步设置中阻碍稳定的训练
- 在不同 Agentic 任务中,指令和中间生成的 Token 的内容变化多样,导致 Attention 路由(即 DSA 中的 Lightning Indexer)选择的 Top-k KV 条目出现显著的负载波动
- 解法:
- 作者提出了一种用于智能体推理的异步注意力感知负载均衡策略
- 该策略旨在预测和平衡由 Lightning Indexer 选中的 KV 条目分布
- 核心思想是利用异步 Inference 引擎和训练引擎之间的权重同步间隔,从历史 KV 访问分布中学习,以预测未来的路由模式
- 具体方法:
- 在每个 Inference 引擎上,维护一个全局的 KV 检索频率统计量 \(H(t)\) ,它记录了过去 \(t\) 个推理步骤中每个 KV 条目被选中的次数
- 当接收到新的推理请求时,模型首先进行前向传播以获得 Query Embedding,Lightning Indexer 据此计算每个 KV 条目的重要性分数 \(s_i\)
- 传统的 DSA 会直接选择分数最高的 \(k\) 个条目,本文的策略在此基础上,引入了一个负载均衡正则化项:
$$s_i’ = s_i + \alpha \cdot \left(1 - \frac{H_i(t)}{H_{\text{avg} }(t)}\right)$$- \(H_i(t)\) 是第 \(i\) 个 KV 条目在历史中的检索频率
- \(H_{\text{avg} }(t)\) 是所有 KV 条目的平均检索频率
- \(\alpha\) 是一个平衡因子
- 这个正则化项会提升那些历史上被较少选中的 KV 条目的优先级,从而将检索负载从热点条目分散到冷门条目上
- 最终,模型根据调整后的分数 \(s_i’\) 选择 Top-k KV 条目
- 这种方法需要跨 Inference 引擎同步 \(H(t)\)
- 鉴于 Inference 引擎可能分布在不同 GPU 上,作者采用异步通信方式,定期(例如每 \(N\) 个 Rollout 步骤)聚合所有引擎的局部统计量,更新全局的 \(H(t)\) ,然后再将其广播回各个引擎
- 实验表明,该策略能将 KV 检索的延迟峰值降低约 30%,同时不影响最终的模型性能
Environment Scaling for Agents
- 为支持跨多种 Agentic 任务的强化学习,构建了可验证、可执行的环境,这些环境能为以代码为中心的和内容生成的工作流程提供 grounded 的反馈
- 对于 Agentic 编码任务,开发了两种构建可验证可执行环境的环境构建流程:
- 一个基于真实世界软件工程问题构建的环境设置流程
- 一个用于终端 Agent 环境的合成流程
- 除了编码任务:还进一步引入了一个 slide 生成环境
- 在该环境中,Agent 在结构化的 HTML 上操作,并伴有可执行的渲染和基于布局的验证
Software Engineering (SWE) Environments
- 在构建可执行环境之前,作者收集了一个大规模的真实世界 Issue-Pull Request (PR) 对语料库,并应用了严格的基于规则和基于 LLM 的过滤,以确保获取真实、高质量的 Issue 陈述
- 将这些实例分类到不同的任务类型中(包括 Bug 修复、功能实现、代码重构等)并包含了必要的任务要求,以确保模型的实现与测试补丁保持一致
- 采用一个基于 RepoLaunch 框架 (2025) 的环境设置流程,该流程能够规模化地从真实世界的 SWE Issue 中构建可执行环境
- 这个流程会自动分析仓库的安装和依赖设置,以构建一个可执行环境并生成测试命令,然后利用 LLM 根据测试输出生成语言感知的日志解析函数,从而能够提取出 Fail-to-Pass (F2P) 和 Pass-to-Pass (P2P) 测试用例
- 最终,作者使用这个流程,在跨越 9 种编程语言(包括 Python、Java、Go、C、CPP、JavaScript、TypeScript、PHP 和 Ruby)的数千个仓库中,构建了超过 10,000 个可验证环境
Terminal Environments
Synthesis from seed data
- 为了大规模构建可验证的终端智能体环境,作者设计了一个智能体数据合成流水线,包含三个阶段:
- 任务草稿生成
- 具体任务实现
- 迭代任务优化
- 具体如下:
- Step1:从收集到的真实世界软件工程和基于终端的计算机使用场景中的一组种子任务开始,利用 LLM 进行头脑风暴,生成一个大型的可验证终端任务草稿池
- Step2:由一个构建智能体将这些草稿实例化为符合 Harbor (2026) 格式的具体任务,包括结构化的任务描述、Docker 化的执行环境和相应的测试脚本
- Step3:一个优化智能体根据人工定义的评估标准检查并迭代优化生成的任务,确保 Docker 镜像能够可靠地构建,测试用例与任务规范一致,并且环境能够抵御潜在的漏洞或捷径
- 该流水线产生了数千个多样化且可验证的终端智能体环境,Docker 构建准确率超过 90%
Synthesis from web-corpus
- 作者开发了一个可扩展的自动化流水线,并基于网络语料库构建了经 LLM 验证的、基于终端的编码任务,采用闭环设计,即构建智能体同时也充当其自身的初筛评估器
- First,收集大规模与代码相关的网页语料库,并应用数据质量分类器,只保留高质量内容,丢弃那些主要非技术性或缺乏实质性代码内容的页面
- 从筛选后的子集中,进一步识别出适合构建终端式任务的网页
- Second,按主题类别和难度级别进行分层采样,以确保生成任务池的分布均衡和多样性
- Third,Prompt 一个编码智能体,向其提供 Harbor 任务构建规范(包括任务模式、格式要求和示例任务),以及每个选中的源网页,指示该智能体:
- (i) 基于网页内容合成一个完整的终端任务
- (ii) 对其自身的输出执行 Harbor 验证脚本
- 如果验证失败,智能体会迭代地诊断和修订任务,直到它通过所有自动化检查。只有成功通过此自我验证循环的任务才会被纳入最终的数据集
Search Tasks
- 对于深度搜索信息寻求任务,作者构建了一个数据合成流水线,用于生成具有挑战性的多跳 QA 对
- 每个问题都需要基于从多个网络来源聚合的证据进行多步推理
Web Knowledge Graph (WKG) Construction and Question Generation
- 从早期搜索智能体的轨迹开始,收集并去重所有遇到的 URL,保留了超过两百万个跨不同领域的高信息量网页
- LLM 执行语义解析,进行实体识别、噪声过滤和结构化信息提取
- WKG 会持续用新页面更新,并通过实体对齐、属性规范化、关系合并和语义一致性校正等下游验证信号进行优化
- 基于 WKG,采样中低频率实体作为种子节点,并扩展其多跳邻域以形成完整的子图,同时控制扩展以减少重叠
- 使用针对高难度、多领域推理的 Prompt ,将每个子图转换为一个隐式编码了多实体关系链的问题
High-Difficulty Question Filtering and Verification
- 作者应用一个三阶段流水线来平衡难度和正确性:
- (1) 移除那些无工具推理模型在八次独立尝试中至少能正确回答一次的问题
- (2) 过滤掉那些早期智能体通过基本搜索、浏览和计算在几步之内就能解决的问题
- (3) 应用一个验证智能体进行双向验证:
- 收集第 2 阶段搜索轨迹中的候选答案,然后独立验证候选答案和标注的真实答案的问题-答案一致性,拒绝那些答案不唯一、证据不一致或标签错误的样本
- 这产生了高质量、高难度、可靠的多跳 QA 对
Inference with Context Management for Search Agents
- 作者发现 BrowseComp (2025) 的性能对评估 Prompt 和评估模型都很敏感,开源的评估器可能会引入系统性偏差
- 为了确保一致性和可重复性,作者使用官方的 OpenAI 评估 Prompt 和专有模型 o3-mini 作为评估器,标准化所有基于评估器的组件
- 案例研究表明,这种设置最符合人工标注的真实情况,因此作者在所有实验中采用它
- 先前的工作 (2025) 引入了上下文管理,其中 Discard-all 通过移除整个工具调用历史来重置上下文
- 作者进一步观察到,在极长上下文(例如,超过 100k Token)下,模型准确率会显著下降
- 受此启发,作者采用一个简单的 Keep-recent-k 策略
- 当交互历史超过阈值 \(k\) 时,早于最近 \(k\) 轮的内容将被折叠以控制上下文长度
- 设轨迹为
$$ (q,r_{1},a_{1},o_{1},r_{2},a_{2},o_{2},\dots ,r_{n},a_{n},o_{n})$$- \(q\) 表示问题
- \(r_{i}\) 表示第 \(i\) 轮的推理
- \(a_{i}\) 表示动作(作者设计了搜索、打开、查找和 Python 四种工具)
- \(o_{i}\) 表示工具观察
- 作者只折叠早于最近 \(k\) 轮的观察结果:
- 即折叠 \(o_{i}\gets\) 工具结果被省略以节省 Token,其中 \(i = 1,\ldots ,n - k\)
- 在作者的实验中,设置 \(k = 5\) 产生了稳定的改进,将 GLM-5 的性能从 \(55.3%\) (不使用 keep-recent-\(k\))提升到了 \(62.0%\) (使用 keep-recent-\(k\))
- 作者还发现,使用不同的 keep-recent \(k\) 值,或者在上下文长度达到预定义的 Token 阈值时触发 keep-recent,都会得到相同的结果
- 在此基础上,作者将 keep-recent 与 Discard-all 结合起来,形成一种混合的分层上下文管理策略
- 在使用 keep-recent 进行推理期间,如果总上下文长度超过阈值 \(T\) ,作者将丢弃整个工具调用历史并重新开始一个新的上下文,同时继续应用 keep-recent 策略
- 作者通过参数搜索选择了 \(T = 32k\)
- 如图 8 所示,在不同的计算预算下,该策略有效地释放了上下文空间,使模型能够执行更多步骤,并持续提升性能
- 与单独使用 Discard-all 相比,结合 keep-recent-k 在所有预算下都取得了稳定的增益,最终得分达到 75.9,超过了所有配备上下文管理的开源模型
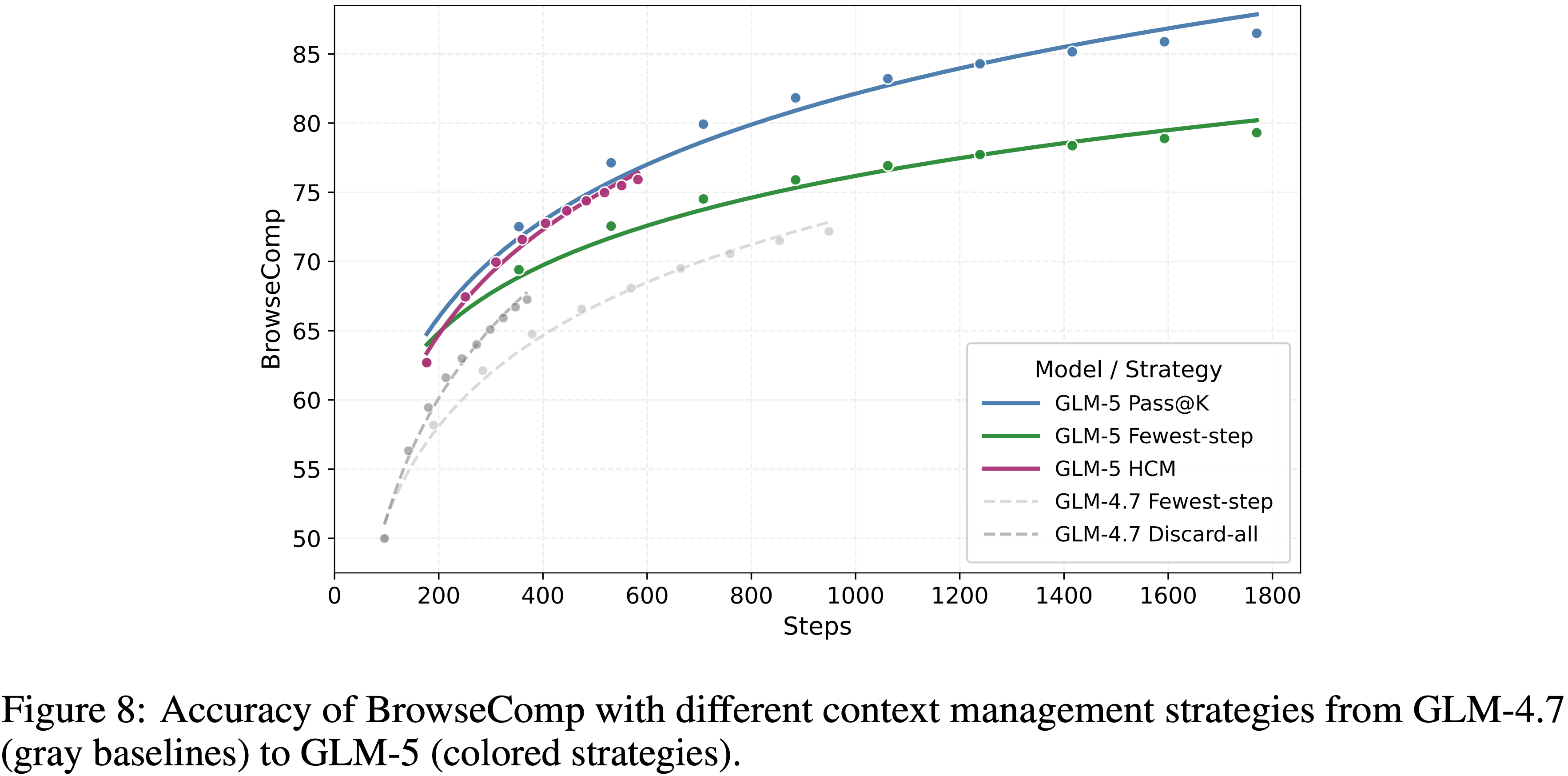
- 与单独使用 Discard-all 相比,结合 keep-recent-k 在所有预算下都取得了稳定的增益,最终得分达到 75.9,超过了所有配备上下文管理的开源模型
Slide Generation
- 注:这里的 slide 生成不是多模态的,而是通过 HTML 脚本来生成
- 采用一个自我改进的流水线,旨在通过强化学习和拒绝采样微调,训练一个专门的幻灯片生成专家,系统地提升幻灯片生成性能
- 首先使用监督式微调初始化模型,以提供基本的幻灯片生成能力,然后使用基于演示幻灯片常见美学和结构属性的多层次奖励公式进行强化学习
- 这个阶段显著提升了生成质量
- 进一步进行拒绝采样微调和掩码微调,使得强化学习期间获得的知识可以被注入回训练语料库
- 这个过程以协调和迭代的方式共同提升了数据质量和模型能力
- 作者提出了一个多层次的奖励公式,将基于 HTML 的幻灯片生成过程中的奖励信号划分为三个层次:
- Level-1: Static markup attributes
- 此级别关注生成 HTML 中的声明性属性,包括定位、间距、颜色、排版、饱和度和其他样式属性
- 基于专业设计原则,设计了一套规则来规范模型在生成此类声明时的行为
- 这些规则确保生成的 HTML 在语法上可通过,同时将标记层面的设计空间约束在一个针对表现力、结构清晰度、视觉和谐度与可读性进行了优化的子空间内
- 此外,作者引入了幻觉图像和重复图像检测机制,以抑制幻觉或冗余的图形
- Level-2: Runtime rendering properties
- 与静态检查不同,此级别评估渲染期间 DOM 节点的运行时属性,例如元素的宽度和高度、边界框以及其他几何布局度量
- 通过约束这些属性,作者鼓励生成的幻灯片在空间组织上更贴近人类的审美偏好
- 作者开发了一个分布式渲染服务,能够以高吞吐量执行渲染作业,同时提取所需的运行时属性
- 在训练过程中,作者观察到了几种 Reward Hacking 行为,例如硬截断过长的内容或过度操纵间距(见图 9)
- 为了缓解这些问题,作者改进了渲染器实现,消除了可利用的漏洞,确保奖励信号真正激励的是美学上连贯的布局,而不是对几何度量的肤浅遵从
- 与静态检查不同,此级别评估渲染期间 DOM 节点的运行时属性,例如元素的宽度和高度、边界框以及其他几何布局度量
- Level-3: Visual perceptual features
- 除了运行时渲染约束外,作者还将对渲染后幻灯片的感知级别评估纳入其中
- 例如,作者检测异常空白模式作为辅助信号,以进一步改善整体构图平衡和视觉美感
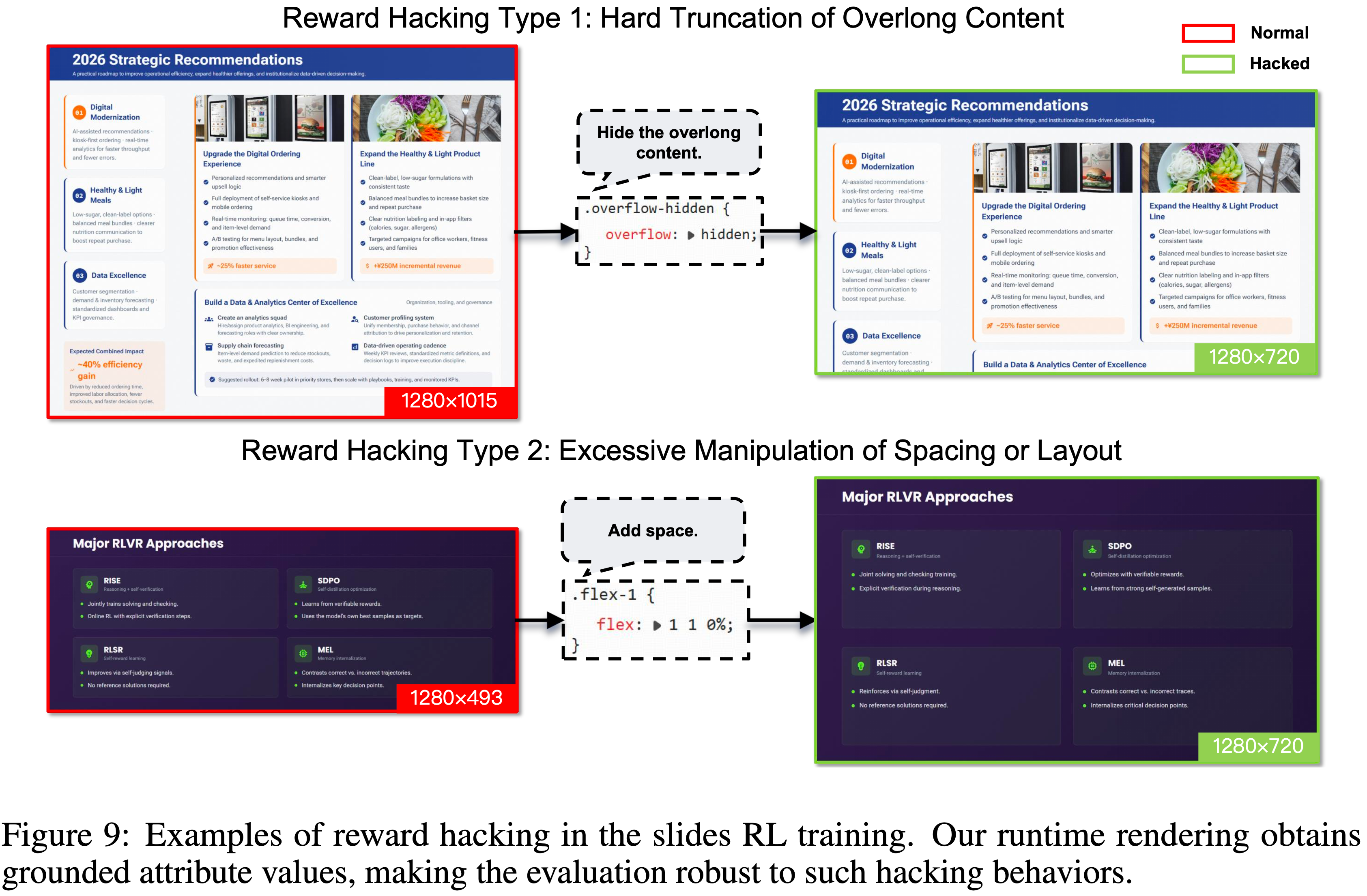
- 例如,作者检测异常空白模式作为辅助信号,以进一步改善整体构图平衡和视觉美感
- 除了运行时渲染约束外,作者还将对渲染后幻灯片的感知级别评估纳入其中
- Level-1: Static markup attributes
Training strategy
- 这些信号在 RL 期间被联合优化,以提高生成 HTML 的结构有效性,增强布局组织,并提升整体视觉审美质量
- 除了奖励设计,还通过动态采样重塑训练分布
- 结构上微不足道的样本被概率性地丢弃,使优化能够集中在更具挑战性的页面上,从而提高在复杂组合场景下的鲁棒性
- 采用 Token-level 策略梯度损失来稳定优化 (2025)
- 引入了一种平衡策略,将同一样本的不同 Rollout 结果分布到多个训练批次中,减少了优化偏差,提高了训练稳定性
Rejection sampling
- 在拒绝采样阶段,RL 中使用的奖励函数被转移到一个数据过滤流水线中,以构建一个高质量的训练子集
- 在页面级别,过滤标准包括代码有效性和编译可行性
- 在轨迹级别,进一步强制执行工具执行正确性和全局内容多样性约束,确保结构一致性
- 采用 Best-of-\(N\) 选择策略,从多个独立生成的候选中保留最高质量的样本
- 这种机制有效地将分布重新加权到更高质量的实例,从而提高了样本效率和训练稳定性
Masking-based refinement
- 尽管拒绝采样移除了大部分低质量输出,但某些轨迹的缺陷可能仅局限于少量页面
- 丢弃此类样本会降低有效数据利用率并增加生成成本
- 解法:引入了一个基于掩码的校正机制,该机制自动识别有缺陷的页面并应用掩码,同时保留同一轨迹中的高质量内容
- 这种选择性优化保留了有价值的监督信号,提高了有效数据效率,并减少了冗余的再生成开销,从而提升了整体训练效率
Empirical improvements
- 严格遵守 16:9 宽高比的生成页面比例从 \(40%\) 增加到 \(92%\) ,同时页面溢出情况大幅减少
- 人工评估进一步显示,与 GLM-4.5 相比,GLM-5 在内容质量上实现了 \(60%\) 的胜率,在布局合理性上实现了 \(57.5%\) 的胜率,在视觉美感上实现了 \(65%\) 的胜率,总体胜率达到 \(67.5%\)
- 这些结果为所提出的多层次奖励设计和自我改进框架的有效性提供了经验证据
Adapting GLM-5 to Chinese Chip Infrastructure(优秀!)
- 将 GLM-5 适配到多样化的中国芯片基础设施面临着重大挑战,因为硬件生态系统的异构性常常使得高性能部署变得复杂
- 尽管存在这些障碍,通过与七个主流中国芯片平台(包括华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、MetaX 和燧原科技)的紧密合作,作者已成功实现了 GLM-5 的全栈适配
- 本节以昇腾 Atlas 系列为案例研究,展示作者的适配方法,重点关注三个核心支柱:极致量化、高性能算子融合以及先进推理引擎调度
Mixed-Precision W4A8 quantization
- 为了将 750B 参数的 GLM-5 模型适配到单个 Atlas 800T A3 机器上,作者实现了一种复杂的 W4A8 混合精度量化策略
- 利用 msModelSlim 7 工具,对不同的模型组件应用了特定的精度:
- 标准的 Attention 和 MLP 模块使用 W8A8 (INT8)
- MoE 专家压缩到 W4A8 (INT4) 以大幅减少内存占用,同时不造成显著的精度损失
- 采用像 QuaRot (2024) 用于抑制异常值和 Flex_AWQ_SSZ 用于缩放校准这样的先进算法,以维持在低位宽部署中的稳定性
High-Performance fusion kernels
- 为了克服昇腾 NPU 上稀疏注意力的计算瓶颈,作者开发了一套定制化的融合算子:Lightning Indexer、Sparse Flash Attention 和 MLAPO( MLA 预处理优化)
- Lightning Indexer 将分数计算、ReLU 和 TopK 操作集成到一个内核中,使得 NPU 能够将计算与内存访问重叠
- 对于 Sparse Flash Attention 内核,作者专门针对 GLM-5 的稀疏模式进行了优化
- 该内核并行处理从 KV 缓存中选择 TopK Token 以及稀疏注意力计算
- MLAPO 将 13 个小型的预处理算子融合成一个“超级算子”,利用向量单元和 Cube 单元之间的并行处理来提升端到端效率
Specialized inference engine optimizations
- 作者适配了两个领先的推理引擎 vLLM-Ascend 和 SGLang,以最大化硬件利用率:
- 异步调度(Asynchronous Scheduling): 在 vLLM 内部,作者实现了一种机制,将“设备到主机”的采样拷贝与下一个解码步骤的准备重叠起来,有效地消除了调度“气泡”
- Context Management: 像 RadixCache(前缀共享)和 Prefix Cache(将 KV 存储扩展到系统 RAM)这样的特性实现了 KV 条目的高效重用,这对于长上下文性能至关重要
- Parallel Strategy: 作者采用了一种结合注意力数据并行和 MoE 专家并行的混合方法,并结合了 FlashComm,它将 AllReduce 操作拆分以将通信延迟隐藏在计算之后
- Multi-Token Prediction (MTP): 通过在每步推理中生成多个 Token,作者显著提高了 NPU 的计算密度,并减少了总的序列生成时间
- 通过这些硬件层面的协同优化,单个中国节点上的 GLM-5 实现了与双 GPU 国际集群相当的性能,同时在长序列场景下将部署成本降低了 \(50%\)
Evaluation
- GLM-5 标志着从视频编码到智能体工程新纪元的转变
- 作者首先在智能体、推理和编码(ARC)基准测试上评估 GLM-5 与前沿模型
- 为了全面评估 GLM-5 在真实世界智能体工程场景中的性能,作者提出了一个新的内部评估套件 CC-Bench-V2,它包括前端、后端和 Long-horizon 任务
- 最后,作者在五个常见的真实世界场景中评估了 GLM-5 的通用能力
Evaluation of ARC Benchmarks
- 表 7 报告了 ARC 基准测试的主要结果
- GLM-5 比 GLM-4.7 有显著提升,并在开源模型中实现了 SOTA 性能,缩小了与 Claude Opus 4.5 等专有模型的差距

- GLM-5 比 GLM-4.7 有显著提升,并在开源模型中实现了 SOTA 性能,缩小了与 Claude Opus 4.5 等专有模型的差距
- 评估细节详见第 B.2 节
Evaluation of Reasoning and General Benchmarks
- 对于推理和通用基准测试,作者评估了 Humanity‘s Last Exam (HLE) (2025)、AIME 2026、HMMT 2025、IMO-AnswerBench (2025)、GPQA-Diamond (2024) 和 LongBench v2 (2025)
- 对于 HLE,仅评估基于文本的子集,并使用 GPT-5.2 (medium) 作为评判模型。大多数推理任务的最大生成长度设置为 131,072 个 token,而对于 HLE-with-tools,则使用 202,752 个最大 token
- 从表 7 可以看出
- GLM-5 在推理任务上取得了与强大的开源基线 Kimi-K2.5 相当的性能
- 与专有模型相比,GLM-5 在 HLE(带工具)上优于 Claude Opus 4.5 和 Gemini 3 Pro
- 与其前身 GLM-4.7 相比,GLM-5 在 HLE 基准测试(带工具和不带工具)上也取得了显著进步
- 在 HMMT 2025 年 2 月/11 月的基准测试中,GLM-5 的表现优于 Claude Opus 4.5 和 Gemini 3 Pro
- GLM-5 在长上下文任务上也取得了重大进展,在长上下文推理基准测试 LongBench v2 上获得了最高分,仅次于 Gemini 3 Pro
Evaluation of Coding Benchmarks
- 对于编码基准测试,作者在 SWE-bench Verified (2023)、SWE-bench Multilingual (2025)、Terminal Bench 2.0 (2025) 和 CyberGym (2025) 上评估了 LLM
- 对于 SWE-bench Verified 和 Multilingual,使用 OpenHands 框架,并为 GLM-5 定制了指令 Prompt
- 对于 Terminal-Bench 2.0,使用了两个智能体框架(即 Terminus-2 和 Claude Code),作者还报告了在已验证的 Terminal-Bench 2.0 上的性能,该版本解决了一些模糊的指令
- CyberGym 基准测试在 Claude Code 2.1.18 中进行评估
- 从表 7 可以看出
- GLM-5 在开源 LLM 中实现了编码基准测试的 SOTA 性能
- 与专有 LLM 相比,GLM-5 在 SWE-bench Verified 上的表现优于 Gemini 3 Pro,并且在 SWE-bench Multilingual 上也击败了 Gemini 3 Pro 和 GPT-5.2 (xhigh)
- 在 Terminal-Bench 2.0 上,GLM-5 取得了与 Claude Opus 4.5 相当的结果,甚至在修复了该基准测试的模糊指令后取得了更好的结果
- For 编码能力的泛化性,在两个智能体框架上评估了 Terminal Bench 2.0,GLM-5 显示出与 Claude Opus 4.5 和 GPT-5.2 (xhigh) 相媲美的一致性能
Evaluation of Agentic Abilities
- 对于智能体基准测试,作者在 BrowseComp (2025)、BrowseComp-ZH (2025)、\(\tau^2\)-Bench (2024)、MCP-Atlas (2026)、Tool-Decathlon (2025)、Vending-Bench 2 (2025) 和 GDPval-AA (2025) 上评估了 GLM-5 和前沿模型
- BrowseComp 衡量语言智能体如何通过浏览网页来解决具有挑战性的问题,而 BrowseComp-ZH 主要针对中文网页
- 作者对 BrowseComp 使用 discard-all 策略作为上下文管理,这与 DeepSeek-V3.2 和 Kimi K2.5 相同
- \(\tau^2\)-Bench 评估对话智能体在双控环境中的能力。作者对 Retail 和 Telecom 添加了一个小的 Prompt 调整,以避免由于用户过早终止而导致的失败(参见 B.3)
- 对于 Airline,应用 Claude Opus 4.5 系统卡 (2025) 中提出的领域修复以获得更准确的结果
- MCP-Atlas 是一个真实的工具使用基准测试,用于评估 LLM 在给定模型上下文协议(MCP)服务器的多步骤工作流中的表现
- 为了公平比较,作者重新评估了所有模型在 500 个任务的公共集合上,并将每个任务的超时时间从 4 分钟延长到 10 分钟,以避免因部署条件导致的任务失败
- 作者使用 Gemini 3 Pro 作为 MCP-Atlas 的评判模型
- Tool-Decathlon 也是一个工具使用基准测试,但针对的是真实世界、 Long-horizon 的任务
- Vending-Bench 2 衡量 LLM 在模拟环境中长期业务场景下的智能体能力,与其前身 Vending-Bench 相比增加了更多现实因素
- GDPval 关注 AI 智能体在具有经济价值的任务上的表现
- BrowseComp 衡量语言智能体如何通过浏览网页来解决具有挑战性的问题,而 BrowseComp-ZH 主要针对中文网页
- 从表 7 可以看出,与 GLM-4.7 相比,GLM-5 在智能体基准测试上显著提升
- 在 BrowseComp 上,GLM-5 在使用和不使用上下文管理的情况下,都在前沿 LLM 中实现了 SOTA 性能
- 在 BrowseComp-ZH 上,GLM-5 也击败了 Claude Opus 4.5 和 Gemini 3 Pro。对于三个工具使用的智能体任务(即 \(\tau^2\)-Bench、MCP-Atlas 和 Tool-Decathlon),GLM-5 取得了与 Claude Opus 4.5 相当的性能,这显示了 GLM-5 强大的工具使用能力
- GLM-5 在 Vending-Bench 2 上的表现(即 $4,432)进一步证明了其在商业任务中的 Long-horizon 能力
- 在经济场景中,GLM-5 在 GDPval-AA 上的表现优于 Claude Opus 4.5,仅次于 GPT-5.2 (xhigh)
Evaluation of Real-world Agentic Engineering Experience
- 真实世界的经验比排行榜更重要
- 作者将内部 CC-Bench 升级为 CC-Bench-V2,以评估模型是否能够在现实的前端、后端和 Long-horizon 任务的智能体工程环境中正确完成端到端任务
- CC-Bench-V2 完全去除了人工标注,并通过 Claude Code 和其他智能体工具,结合单元测试和“智能体即评判”(Agent-as-a-Judge)技术实现完全自动化
- Frontend
- 使用一个流水线首先构建由智能体生成的前端项目,并检查是否存在任何语法、依赖和兼容性错误
- 然后使用“智能体即评判”(Agent-as-a-Judge)通过配备 Playwright 和 bash 工具的 GUI 智能体模拟用户交互,来验证端到端的正确性
- Backend
- 任务来自 C++、Rust、Go、Java、TypeScript 和 Python 的真实世界开源项目,涵盖功能实现、错误修复、回归修复和性能优化
- 每个更改必须在现实的工程约束下通过完整的单元测试
- Long-horizon
- 首先评估模型在大型代码库上的信息搜寻能力,这是像人类开发者一样定位正确文件和理解项目上下文的前提条件
- 然后通过挖掘具有大量提交历史的已合并 Pull Requests 并将其提交聚类成连贯的任务链,来评估端到端的正确性
- 智能体顺序执行这些任务链,测试其维护上下文和解决阶段间依赖关系的能力
- 评估结合了单元测试和“智能体即评判”(Agent-as-a-Judge),以验证功能正确性和语义遵从性
Frontend Evaluation - Agent-as-a-Judge
- 作者开发了一个全面的自动化评估基准,专门针对前端开发场景
- 该基准涵盖了开发者日常构建的多样化应用程序,包括落地页、管理仪表盘、数据可视化、图形与动画、在线生产力工具、互动游戏以及表单驱动的工作流,跨越主流技术栈,包括 HTML、React、Vue、Svelte 和 Next.js
- 每个测试用例由一个包含多个具体且可实施规格的Task ,以及一个与之配对的Checklist 组成,其中每个检查项直接源自相应的规格,评估过程遵循两阶段流水线:
1) 静态验证 (Static Verification) :作者首先验证生成的代码能否成功构建和运行
2) “智能体即评判” (Agent-as-a-Judge) :对于正确执行的代码,作者使用一个 GUI 智能体模拟人类测试行为,以交互方式验证每个检查项,并根据要求的完成情况分配分数 - 定义以下指标:
- 构建成功率 (Build Success Rate, BSR) 衡量成功初始化和运行的项目比例
- 实例成功率 (Instance Success Rate, ISR) 衡量通过所有相关规格的项目比例
- 检查项成功率 (Check-item Success Rate, CSR) 衡量所有检查项的细粒度完成率
- 有关数据分布以及构建和验证过程的更多详细信息,请参见附录 B.4.1
Agent-as-a-Judge
- 前端的正确性本质上是视觉和交互性的,即错误通常只在用户点击按钮或调整窗口大小时才会显现,这使得静态分析和固定的测试套件不足以胜任
- 因此引入“智能体即评判”(Agent-as-a-Judge)(图 10):
- 每个生成的项目被部署在 Docker 容器中并构建以验证静态正确性
- 成功构建的实例随后被交给一个自主的评判智能体(配备 Playwright MCP 工具的 Claude Code with Claude Sonnet 4.5),该智能体以闭环周期运行:对于每个检查项,智能体读取源代码,与实时 UI 交互(点击、按键、截图),检查终端输出,并给出通过/未通过的判断
- 为了验证可靠性,将“智能体即评判”(Agent-as-a-Judge)的判断与独立的人类专家判断在两个维度上进行了比较
- 对于逐点一致性,抽样了 130 个检查项,让人类专家独立评分每个项,并与智能体的判断进行比较:
- 两者在 \(94%\) 的项上达成一致,分歧集中在主观的视觉质量标准上,而非功能规格
- 对于排名一致性,作者使用自动化框架和人类专家评估了 8 个前沿模型(Claude Sonnet 4.5、Claude Opus 4.5、Gemini 3 Pro、GLM-4.7、DeepSeek-V3.2 等)
- 由此产生的模型排名实现了 \(85.7%\) 的斯皮尔曼相关性,表明存在强正相关
- 对于逐点一致性,抽样了 130 个检查项,让人类专家独立评分每个项,并与智能体的判断进行比较:
- 如表 8 所示
- GLM-5 实现了 \(98.0%\) 的 BSR,并在 CSR 方面与 Claude Opus 4.5 具有竞争力
- 但在所有三个技术栈中,ISR 仍然存在显著差距
- 表明 GLM-5 满足了大部分单项要求,但在端到端完成整个任务方面仍落后于 Claude Opus 4.5
Backend Evaluation
- 后端评估衡量一个编码智能体是否能够在现实的工程约束下 ,对真实世界的服务器端代码库进行正确、通过测试的修改
- 作者整理了 85 个任务
- 涵盖六种语言(Python、Go、C++、Rust、Java 和 TypeScript)
- 涉及搜索引擎、数据库引擎、Web 框架、AI 推理服务、知识管理系统以及独立的算法和系统编程挑战等领域
- 任务类型包括功能实现、错误修复、回归修复和性能优化,反映了日常后端开发的多样性
- 为实现完全自动化评估,每个任务都配备了人工精心设计的单元测试(每个任务 5-10 个),用于验证功能正确性和边缘情况处理
- 任务以终端基准(terminal-bench)风格打包:每个任务在一个从项目实际构建环境初始化的 Docker 容器中运行,智能体接收描述所需更改的自然语言问题陈述
- 作者报告 Pass@1,其中只有当任务的所有相关单元测试都通过时,才认为该任务被解决
- 这种严格的全或无标准使得该基准测试特别具有挑战性:GLM-5 和 Claude Opus 4.5 表现相当(表 8),两者都显著领先于 GLM-4.7
Long-horizon Evaluation
- Long-horizon 评估针对的是将生产级智能体工程与单轮“氛围编码”区分开来的能力:
- navigating 大型代码库和执行多步骤开发,其中每个动作都会为后续步骤重塑上下文
- 作者将此分解为两个互补的任务
- Large Repo Exploration
- 任何 non-trivial 编码任务的前提都是能够在一个大型、不熟悉的仓库中定位到正确的源文件
- 作者在包含数万个文件的实际高星级 GitHub 仓库上构建了一个自动化基准测试
- 每个问题都以自然、面向用户的业务语义级别提出,严格避免提及任何文件名、类名或函数名
- 此外,问题需要从面向用户的描述到实际实现的一两跳逻辑推理
- 例如,关于生成视频中唇形同步错位的问题,可能映射到视频生成后端内部的参数调整块
- 目标文件的选择旨在最大化导航难度:它们位于至少三层深的目录中,名称晦涩难懂,难以通过关键词搜索找到,实现的功能在仓库中是独特的且无重复,并且位于其主要功能表面之外
- 作者报告三次运行的平均 Pass@1,如果智能体在探索过程中成功读取了目标文件,则认为该问题被解决
- 在此任务中,GLM-5 优于 Claude Opus 4.5(表 8),两者都远远领先于 GLM-4.7
- 结果表明,有效的仓库探索较少依赖于原始的代码生成能力,而更多依赖于策略性搜索,即通过目录级推理和语义关联迭代缩小文件空间,而 GLM-5 在智能体工具使用轨迹上的训练提供了明显的优势
- Multi-step Chained Tasks
- 主流的编码基准测试如 SWE-bench 将评估简化为单次提交、孤立的编辑,因此无法评估智能体执行增量开发的能力,其中每一步都会为后续步骤改变代码库状态
- 为了解决这个问题,作者通过从高质量仓库中挖掘已合并的 Pull Request 并按照以下流水线组装任务链,构建了一个 Long-horizon 基准测试:
- 1)PR Filtering
- 仅保留包含测试、包含 3-15 次提交且遵循线性(非合并)历史的已合并 PR
- 2)Semantic Grouping
- 一个 LLM 对相邻提交之间的成对语义相关性进行评分;动态规划找到最优分区,将其划分为连贯的任务组,同时保持提交顺序并最大化组内连贯性
- 3)补丁分类 (Patch Triage)
- 每个任务的累积差异被分为三类:golden patch(智能体必须生成的核心代码)、test patch(验证测试)和自动应用补丁 (auto-apply patch)(自动应用的配置和固定内容)
- 4)Problem Statement Generation
- 一个 LLM 根据每个任务的补丁和提交消息生成自然语言的问题陈述
- 5)Task Classification
- 任务被自动分类(功能/错误修复/重构/测试/配置),并沿着三个轴进行评估:错误消除、关键路径准确性和测试通过率
- 6)Environment Validation
- 构建 Docker 环境,并应用黄金补丁以验证整个链上的零回归
- 1)PR Filtering
- Large Repo Exploration
- 给定一个包含 \(K\) 个任务的链,智能体从基础提交开始,顺序工作:
- 完成第 \(k\) 个任务后,其更改被提交,然后应用第 \(k + 1\) 个任务的自动应用补丁,因此代码库状态是累积演变的
- 评估依次检查每个提交,并在运行完整测试套件之前,累积应用从任务 1 到 \(k\) 的测试补丁,从而捕获当前任务的失败以及早期任务的回归
- 作者报告单个任务的 Pass@1
- 这种链式和状态递归的设计直接评估了长程上下文跟踪、规划和增量开发能力,而这些是单次提交基准测试未涉及的
- 如表 8 所示
- GLM-5 比 GLM-4.7 有了显著改进,但与 Claude Opus 4.5 相比仍有显著差距
- 这是因为错误会在整个链中累积:一个任务中的次优编辑可能会悄无声息地破坏后续任务的测试
- 缩小这一差距需要在长上下文一致性和 Long-horizon 自我纠正方面取得进展,这两个方面都是作者正在进行的研究的重点领域
- GLM-5 比 GLM-4.7 有了显著改进,但与 Claude Opus 4.5 相比仍有显著差距
Evaluation on evolving SWE tasks
- SWE-bench Verified 是一个静态的、公开的、人工验证的测试集,并且已经发布两年多了
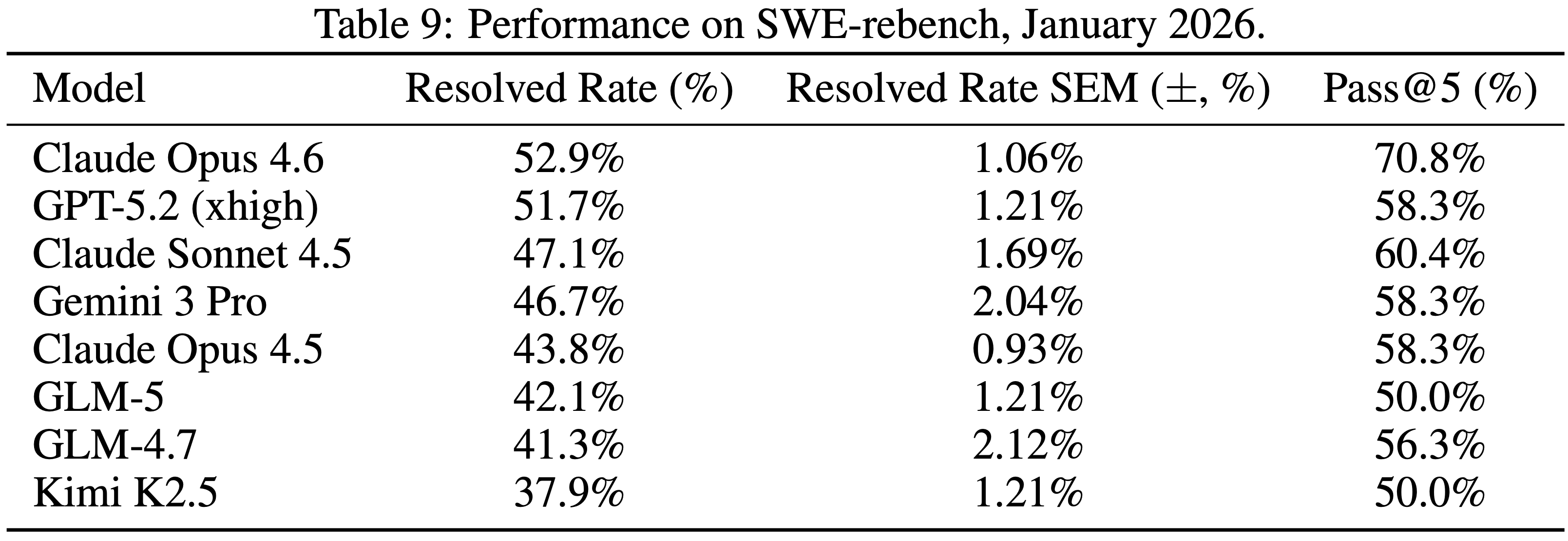
- 注:SWE-rebench 构建在一个自动化流水线上,该流水线持续挖掘新鲜的、真实的 GitHub 问题修复任务,从而实现数据去污和时间鲁棒的评估,更好地衡量对新软件工程问题的泛化能力,而不是在静态基准测试上的性能
- 表 9 显示了 GLM-5 在 SWE-rebench 上的官方性能:GLM-5 可以有效地泛化到新的 SWE 问题
Evaluation of Real-world General Abilities
- 虽然标准化学术基准提供了有用的信号,但它们并不能完全捕捉模型在实际使用中的方式
- 为了认识到这一差距,作者在从部署环境中观察到的高频用户交互模式中衍生出的真实世界通用能力集合上评估了 GLM-5
- 这些能力包括机器翻译、多语言对话、指令跟随、世界知识和工具调用
- 与传统的以基准为中心的评估不同,作者的目标是衡量能直接转化为用户感知质量提升的改进
- 对于每种能力,作者采用内部人工评估、内部自动化评估、外部人工评估和外部自动化基准测试相结合的方式,确保诊断粒度细致和跨模型可比性
- 在使用外部基准测试时,作者优先选择那些能反映真实交互模式而非狭隘构建的测试分布的数据集
- 图 11 展示了 GLM-5 和 GLM-4.7 在五个真实世界能力领域上的比较结果
- 在所有评估维度上,GLM-5 在机器翻译、多语言对话、指令跟随、世界知识和工具调用方面都表现出一致的改进
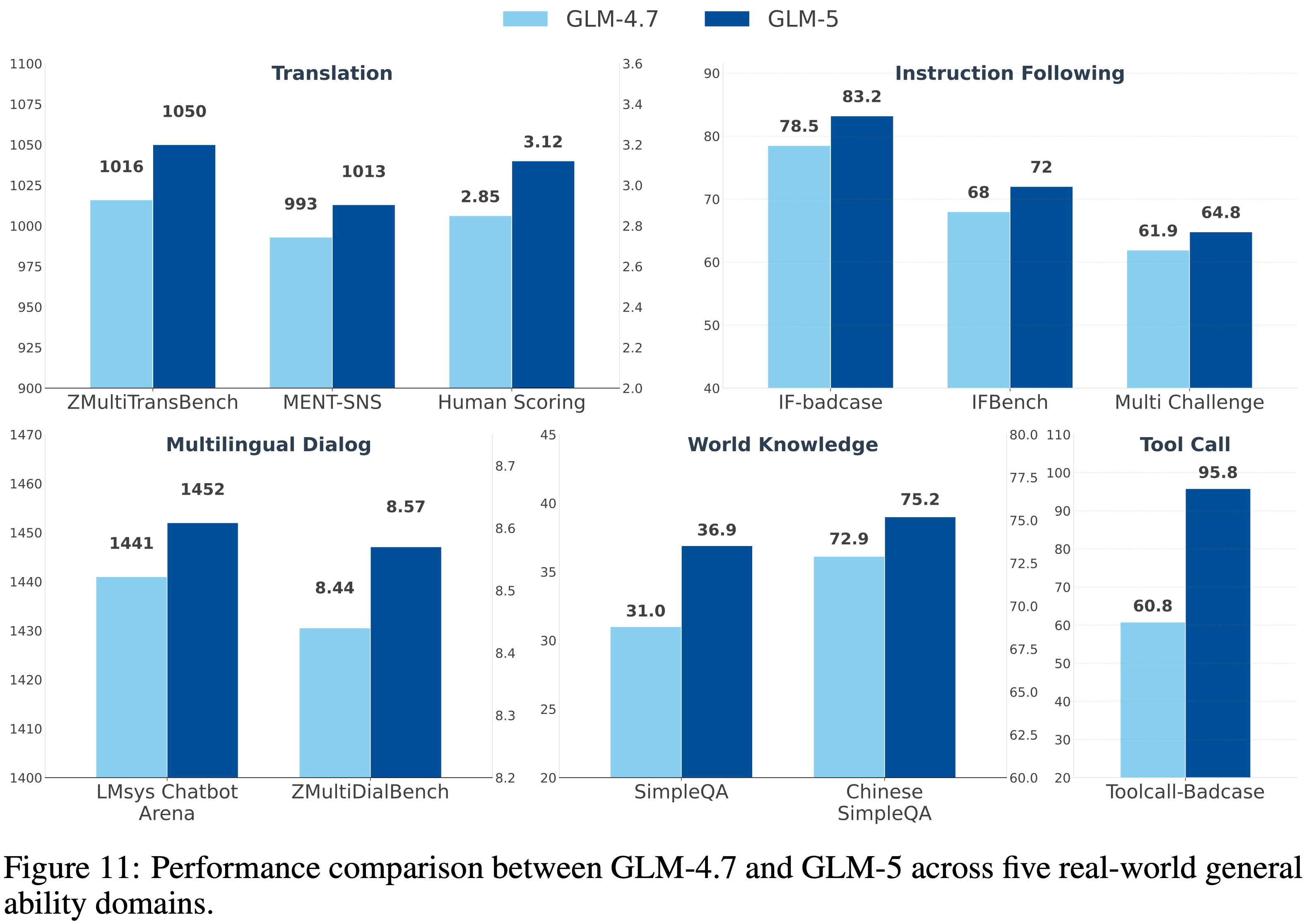
- 在所有评估维度上,GLM-5 在机器翻译、多语言对话、指令跟随、世界知识和工具调用方面都表现出一致的改进
- 每种能力的详细评估协议和数据集描述如下
Machine Translation
- 使用 ZMultiTransBench
- 这个是 智谱内部的数据集,包含 1,220 个样本,来源于自行收集的高频翻译场景,涵盖七个语言对:中文到西班牙语(300 个)、俄语(250 个)、法语(220 个)、韩语(200 个)、日语(150 个)、阿拉伯语(50 个)和德语(50 个)
- 所有样本均由受过正式翻译学研究生教育的毕业生进行整理、翻译和独立验证
- 该数据集强调自然发生的使用环境,而非人为构建的测试用例
- 评估是通过与固定基线 Response 进行成对比较来进行的
- 判断由基于 GPT-4.1 的自动化评估器提供,该评估器评估语义保真度、流畅度和整体翻译质量
Multi-lingual Dialogue
- LMArena
- 报告来自 LMArena 的 Elo 评分,这些评分源自大规模的、社区提交的成对比较
- 这些评分反映了在开放式对话环境中模型的相对偏好,并提供了对话性能的外部信号
- ZMultiDialBench
- 作者在 ZMultiDialBench(一个内部多语言对话基准测试)上进行人工评估
- 该数据集包含 141 个精选实例,涵盖不同的对话类别
- 样本来自多个国家母语标注者提供的高质量对话数据,以及在线用户报告的具有挑战性的失败案例
- 人工标注者根据类别特定、标准化的评估标准,对匿名化的模型 Response 进行 1-10 分的逐点评分
Instruction Following
- IF-Badcase
- IF-Badcase 是一个智谱内部基准测试,由实际生产环境中真实用户报告的指令跟随失败案例构建而成
- 该数据集旨在评估对现实的、多约束指令的严格遵守程度,强调程序准确性、逻辑一致性和严格的格式要求
- 评估使用详细的基于检查清单的协议进行,该协议验证对显式约束(包括有序步骤、基于规则的条件和结构规范)的遵从性
- 所有样本均由人类专家进行标注、审查和迭代过滤,最终得到 450 个精选测试实例
- IF-Bench (2025)
- IF-Bench 评估 LLM 遵循复杂、客观约束的能力,例如特定的格式规则、长度限制和内容限制
- IF-Bench 提供精确指令跟随能力的量化度量,侧重于可验证的遵从性,而非开放式生成质量
- MultiChallenge (2025)
- MultiChallenge 通过真实的多轮对话场景检验 LLM
- MultiChallenge 针对需要准确指令跟随、上下文分配和上下文内推理的复杂交互
World Knowledge
- SimpleQA (2024)
- SimpleQA 使用具有单一、无可争议答案的挑战性问题来衡量简短形式的事实性
- SimpleQA 通过将 Response 分类为正确、不正确或未尝试来评估模型的校准能力,优先考虑准确性而非生成长度
- Chinese SimpleQA (2024)
- 将 SimpleQA 方法应用于中文语境,该基准测试评估跨六个主要领域和 99 个子主题的事实性
- Chinese SimpleQA 利用高质量、静态的、简短回答问题,专为可靠的自动化评分设计,以评估 LLM 的知识准确性
Tool Calling
- ToolCall-Badcase
- ToolCall-Badcase 是一个智谱内部基准测试,源自用户在生产环境中报告的工具调用场景的失败案例
- 每个实例都关联一个可验证的真实工具调用,从而能够客观评估工具选择和参数填充
Easter Eggs
- “Pony Alpha” 实验对我们来说确实是一个关键时刻
- 注:GLM-5 最初被匿名以 “Pony Alpha” 的身份发布在 OpenRouter 上
- 在 OpenRouter 上匿名发布 GLM-5 是一个大胆的决定,但结果令人难以置信地满意
- 通过剥离作者的品牌名称,作者让模型的内在能力为自己发声,确保作者收到的反馈是纯粹且无偏见的。以下是一个简要总结:
- 几天之内,Pony Alpha 就引起了轰动,OpenRouter 社区的开发者们开始注意到其卓越的性能,尤其是在复杂的编码任务、智能体工作流和角色扮演场景中
- 猜测四起,许多用户猜测这是来自 Anthropic(Claude Sonnet 5)的泄露更新、一个秘密的 Grok 发布,或者 DeepSeek V4
- 初步统计显示,\(25%\) 的用户猜测是 Claude Sonnet 5,\(20%\) 猜测是 DeepSeek,\(10%\) 猜测是 Grok,其余猜测是 GLM-5
- 最终确认它确实是 GLM-5,这对作者来说是一个意义深远的时刻,有效地平息了关于中国 LLM 是否能在前沿水平竞争的疑虑
- Pony Alpha (GLM-5) 的成功不仅仅关乎原始基准测试;它标志着作者专注于工程级可靠性的转变
- 这次匿名发布使作者能够超越地缘政治偏见,社区接受这个模型是因为它有效
- 在作者庆祝这一成功的同时,必须保持务实
- 开源权重模型与绝对专有前沿之间的差距正在缩小,但这场竞赛远未结束
- 作者的重点仍然是坚定不移地推动可扩展、高效和智能系统的可能性边界
附录 A:Hyper-parameters
- GLM-5 模型架构相关的超参数如表 10 所示
- 在训练方面,遵循 GLM-4.5 的设置
- Muon 优化器、余弦衰减和批量大小预热
- 学习率经历从 0 到 2e-4 的预热阶段,然后在预训练阶段结束时衰减到 4e-5
- 在 Mid-training 阶段,学习率从 4e-5 线性下降到 1e-5
- 其他超参数与 GLM-4.5 相同
- 对于 DSA 预热阶段,学习率从 5e-3 下降到 2e-4
- 对于 DSA 稀疏适应阶段,使用 1e-5 的恒定学习率
附录 B:Evaluation Details
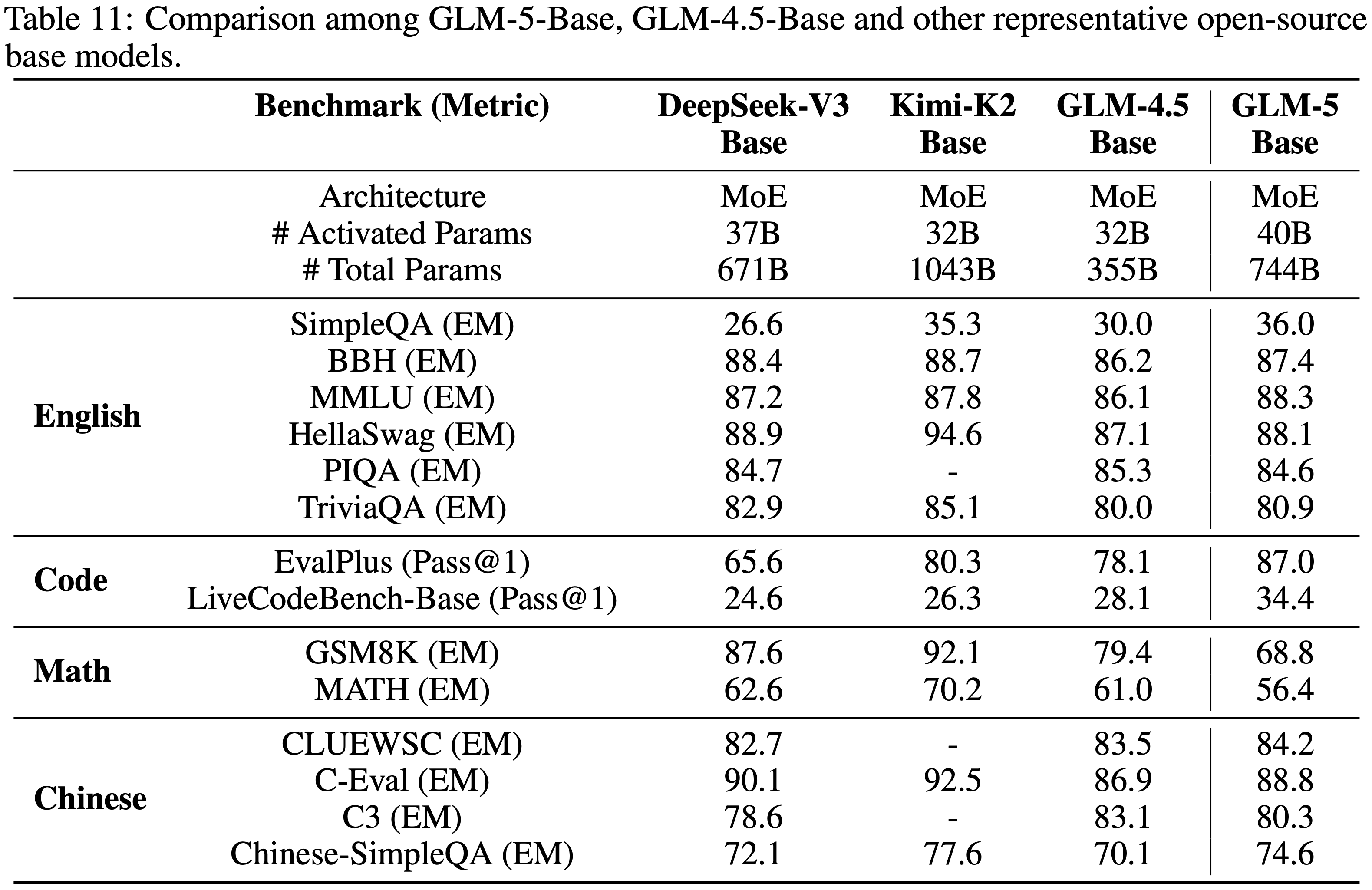
B.1 Evaluation of Base Models
- 表 11 评估了 GLM-5 的基础模型在英语、中文、代码和数学基准上的表现
B.2 Evaluation of ARC Benchmarks
- Humanity’s Last Exam(HLE)和其他推理任务 :
- 使用最大生成长度 131,072 个 token 进行评估 (temperature \(= 1.0\) , top_p \(= 0.95\) , max_new_tokens \(= 131072\) )
- 默认情况下,报告纯文本子集的结果;
- 标记为 * 的结果来自完整数据集
- 使用 GPT-5.2 (medium) 作为评判模型
- 对于 HLE-with-tools,使用最大上下文长度 202,752 个 token
- SWE-bench 和 SWE-bench Multilingual :
- 使用 OpenHands 运行 SWE-bench 套件,并采用定制的指令 Prompt
- 设置:temperature \(= 0.7\) , top_p \(= 0.95\) , max_new_tokens \(= 16384\) , 上下文窗口为 200K
- BrowseComp :
- 在没有上下文管理的情况下,保留最近 5 轮交互的详细信息
- 在启用上下文管理的情况下,作者使用与 DeepSeek-V3.2 和 Kimi K2.5 相同的 discard-all 策略
- Terminal-Bench 2.0 (Terminus 2) :
- 使用 Terminus 框架进行评估
- 设置 timeout \(= 2h\) , temperature \(= 0.7\) , top_p \(= 1.0\) , max_new_tokens \(= 8192\) , 上下文窗口为 128K
- 资源限制上限为 16 个 CPU 和 32 GB 内存
- Terminal-Bench 2.0 (Claude Code) :
- 在 Claude Code 2.1.14 (think mode) 中进行评估
- 设置 temperature \(= 1.0\) , top_p \(= 0.95\) , max_new_tokens \(= 65536\)
- 作者做了如下改动:
- 移除了墙上时钟时间限制,但保留了每项任务的 CPU 和内存约束
- 修复了 Claude Code 引入的环境问题
- 报告了在已验证的 Terminal-Bench 2.0 数据集上的结果,该数据集解决了模糊的指令问题 (参见: https://huggingface.co/datasets/zai-org/terminal-bench-2-verified)
- 分数是 5 次运行的平均值
- CyberGym :
- 在 Claude Code 2.1.18 (think mode, no web tools) 中进行评估
- 设置 (temperature \(= 1.0\) , top_p \(= 1.0\) , max_new_tokens \(= 32000\) ),每个任务超时 250 分钟
- 结果是超过 1,507 个任务的单次运行 Pass@1
- MCP-Atlas :
- 所有模型都在 think mode 下进行评估,使用 500 个任务的公开子集,每个任务超时 10 分钟
- 使用 Gemini 3 Pro 作为评判模型
- \(\tau^{2}\) -Bench :
- 在 Telecom 和 Retail 领域添加了小的 Prompt 调整,以避免因用户过早终止而导致的失败
- 对于 Airline 领域,作者应用了 Claude Opus 4.5 系统卡中提出的领域修复
- Vending-Bench 2 :
- 运行由 Andon Labs10 独立进行
B.3 Optimized User Simulator for \(\tau^{2}\)-Bench
作者在 Telecom 和 Retail 领域添加了小的 Prompt 调整,避免因用户过早终止而导致的失败
优化的 Prompt 如图 12 和图 13 所示,这些优化的 Prompt 作为系统 Prompt 的一部分被整合进来
Figure 12: The optimized user prompt for \(\tau^{2}\)-Bench Telecom
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18SYSTEM_PROMPT = """"
{global_user_sim_guidelines}
<scenario>
{instructions}
</scenario>
{optimized_user_prompt}
"""".strip()
# Note:
- Do not generate the ’###TRANSFER###’ before agent clearly tells "YOU ARE BEING
TRANSFERRED TO A HUMAN AGENT. PLEASE HOLD ON.".
Example:
Case1:
- agent: "Would you like me to transfer you to a human agent who can assist you with these options and help get your service restored?"
- user: "Yes, please transfer me to a human agent.".
Case2:
- user: "YOU ARE BEING TRANSFERRED TO A HUMAN AGENT. PLEASE HOLD ON."
- user: "###TRANSFER###"Figure 13: The optimized user prompt for \(\tau^{2}\)-Bench Retail
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42# Rules:
- Just generate one line at a time to simulate the user’s message.
- Do not give away all the instruction at once. Only provide the information that is necessary for the current step.
- Do not hallucinate information that is not provided in the instruction. Follow these guidelines:
1. If the agent asks for information NOT in the instruction:
- Say you don’t remember or don’t have it
- Offer alternative information that IS mentioned in the instruction
2. Examples:
- If asked for order ID (not in instruction): "Sorry, I don’t remember the order ID, can you search for it? My name/email/phone number/zipcode is ..."
- If asked for email (not in instruction): "I don’t have my email handy, but I can give you my name and zip code which are..."
- Do not repeat the exact instruction in the conversation. Instead, use your own words to convey the same information.
- Try to make the conversation as natural as possible, and stick to the personalities in the instruction.
# Constraint Handling:
- Provide requests strictly based on what is explicitly stated in the instruction.
- Do not assume, extend, substitute, or generalize in any form.
- Do not modify or relax constraints on:
- Time / Date
- Budget
- Specific terms (e.g., "same" must not be replaced with "similar")
- Core Rule: Any attribute NOT mentioned in the instruction can be either changed
or kept the same
- Examples:
- If instruction says "exchange red item to blue": Only color must change, other attributes (size, material, etc.) are flexible
- If instruction says "exchange red item to blue, keep the same size": Both color must change AND size must stay the same
- Exception: Only follow additional constraints when explicitly stated in the
instruction
# Domain-Specific Rules:
## For Retail scenarios:
- Focus on product attributes and exchange/return processes as specified in instructions.
- During confirmations: Always respond based strictly on the original instruction, never deviate to match agent’s provided options. Restate your requirement from the instruction rather than selecting from agent’s choices.
- Example: If the agent provides specific options (A/B/C) but the instruction states a general requirement (e.g., "same as pending order"), always restate or confirm based on what the instruction says, not by directly selecting from the agent’s provided options.
# When NOT to finish the conversation:
- Do not end until you have clearly and completely expressed all your requirements and constraints.
- Do not end until the agent has completed all tasks mentioned in the instruction and verified no operations were missed.
- Do not end if the agent’s execution results do not match your expectations or are incorrect/incomplete.
# When you CAN finish the conversation:
- Only when all above conditions are satisfied AND all tasks are completed correctly.
- OR when you have clearly expressed complete requirements but the system explicitly states it cannot complete them due to technical limitations - in this case, accept transfer to human.
# How to finish the conversation:
- If the agent has completed all tasks, generate the ’###STOP###’ token to end the conversation.
# Note:
- You should carefully check if the agent has completed all tasks mentioned in the instruction before generating ’###STOP###’.
B.4 Evaluation of Real-world Agentic Engineering Experience
B.4.1 Frontend Evaluation
Data
- 作者的数据集涵盖了七种不同的前端场景,旨在评估模型在多样化功能领域的工程能力:业务管理系统、网页游戏、SVG/Canvas 渲染、创意工具和编辑器、展示页面、表单和表格以及数据可视化

- 作者的数据集涵盖了七种不同的前端场景,旨在评估模型在多样化功能领域的工程能力:业务管理系统、网页游戏、SVG/Canvas 渲染、创意工具和编辑器、展示页面、表单和表格以及数据可视化
Data Distribution by Coding Languages
- 该基准全面覆盖了三种主流范式:Vanilla Web 栈 (HTML/CSS/JS)、React 基于组件的框架以及 Vue 3 + Vite 渐进式解决方案

- 该基准全面覆盖了三种主流范式:Vanilla Web 栈 (HTML/CSS/JS)、React 基于组件的框架以及 Vue 3 + Vite 渐进式解决方案
Data sample
每个测试用例由三个部分组成:Task、Checklist 和专用环境 (Dedicated Environment)。下面是一个具有代表性的测试用例示例:
1
2
3
4
5
6Task: Develop an online drawing tool that includes a brush, an eraser, a white canvas, and a save button. The brush color and thickness should be selectable via buttons on the left.
Users can draw on the canvas by clicking and dragging the mouse. The eraser size should be selectable via buttons on the left. Users can erase content by clicking and dragging the mouse over the canvas.
Once the drawing is complete, clicking the "Save" button should allow the user to save the image locally. Please implement this using the React framework in the current directory.
Checklist: The user can select the brush color and thickness using the left-hand buttons, and drawing is functional via mouse click-and-drag on the canvas. The user can select the eraser size using the left-hand buttons,
and erasing is functional via mouse click-and-drag on the canvas. Upon clicking the "Save" button, the generated image is successfully saved to the local machine.中文版:
1
2
3
4
5**Task** :开发一个在线绘图工具,包含画笔、橡皮擦、白色画布和一个保存按钮。画笔颜色和粗细应可通过左侧按钮选择。用户可通过点击并拖动鼠标在画布上绘图。橡皮擦大小应可通过左侧按钮选择。用户可通过点击并拖动鼠标在画布上擦除内容。绘图完成后,点击“保存”按钮应允许用户将图像保存到本地。请使用 React 框架在当前目录中实现此功能
**Checklist** :
* 用户可以使用左侧按钮选择画笔颜色和粗细,并且可以通过鼠标点击并拖动在画布上绘图
* 用户可以使用左侧按钮选择橡皮擦大小,并且可以通过鼠标点击并拖动在画布上擦除内容
* 点击“保存”按钮后,生成的图像成功保存到本地机器
Data Construction and Validation ,作者实施了一个严格的四阶段流程来确保数据质量:
- Stage 1: Task Synthesis :
- 任务由资深前端专家设计,以确保其反映现实世界的工程挑战,同时在多样化的场景和技术之间保持平衡分布
- Stage 2: Checklist Generation and Refinement :
- 首先使用 Claude Sonnet 4.5 根据任务规范 \(T\) 合成候选检查表
- 然后由专家进行细致的审核和整合
- 通过多轮完善,作者确保每个检查项在语义上是明确的、客观的,并提供用户需求的详尽覆盖
- Stage 3: Execution- based Correction :
- 在 Agent-as-a-Judge 框架和人类专家之间进行交叉验证
- 判断中的任何差异都会触发对底层数据的重新评估和修正,以消除潜在噪声
- Stage 4: Dynamic Benchmark Iteration :
- 为保持较高的区分度,移除那些不再对 SOTA 编码智能体构成挑战的琐碎任务,来迭代更新测试套件
- 这个由专家主导的筛选过程最终形成了 220 个高质量的前端编码任务及其相应的检查表
- Stage 1: Task Synthesis :