注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:Welcome to the Era of Experience, David Silver & Richard S. Sutton
- 注:这篇论文是即将面世的书籍《Designing an Intelligence》中的一个章节的 preprint
TLDR
- 本人对论文的一句话核心总结 :RL is all you Need!
- 作者观点 1:当前人们因为 LLM 的崛起而不关注 RL,但这只是暂时的,要实现最终的 AGI ,最终还是需要 RL
- 作者观点 2:RL 的春天要来了,超越人类智能的 Agent 实现路径是基于 Experience 的 RL
Abstract
- 我们正站在人工智能新时代的门槛上,这个时代有望实现前所未有的能力水平
- 新一代的 Agent 将主要通过从 Experience 中学习来获得超人的能力
- 论文探讨了将定义这个即将到来的时代的关键特征
The Era of Human Data
- 人工智能 (AI) 通过在大量人类生成的数据上进行训练,并用人类专家的示例和偏好进行微调,取得了显著进步
- LLM 就是这种方法的典范,LLMs 已经达到了广泛的通用性
- 一个单一的 LLM 现在可以执行从写诗和解决物理问题到诊断医疗问题和总结法律文件等任务
- However,虽然模仿人类足以在许多能力上达到合格水平,但孤立地使用这种方法尚未、并且很可能无法在许多重要主题和任务上实现超人智能(superhuman intelligence)
- 在数学、编程和科学等关键领域,从人类数据中提取的知识正在迅速接近极限
- 大多数高质量数据源(特指那些确实能够提升强 Agent 性能的数据源)要么已经被消耗,要么很快将被消耗殆尽
- 仅靠人类数据监督学习推动的进展速度明显在放缓,这表明需要一种新的方法
- Furthermore,有价值的新 Insights,如新定理、新技术或科学突破,超出了当前人类理解的边界,无法被现有的人类数据所捕捉
Experience 时代 (The Era of Experience)
- 为了取得显著进步,需要一种新的数据来源
- 这种数据必须以 Agent 变得更强而持续改进的方式生成;任何静态的合成数据生成程序都将迅速被超越
- 这可以通过允许 Agent 从其自身 Experience (即 Agent 与其环境交互生成的数据)中持续学习来实现
- experience , i.e., data that is generated by the agent interacting with its environment
- 人工智能正处在一个新时期的边缘, Experience 将成为主要的改进媒介,并最终使当今系统中使用的人类数据的规模相形见绌
- 这种转变可能已经开始了,即使对于体现以人为中心的人工智能的 LLM 也是如此
- 数学能力就是一个例子
- AlphaProof (2024) 最近成为第一个在国际数学奥林匹克竞赛中获得奖牌的程序,超越了以人类为中心的方法的性能 (2025, 2024, 2025)
- 在最初接触了由人类数学家多年来创建的大约十万个形式化证明之后,AlphaProof 的强化学习算法1随后通过与形式化证明系统的持续交互,生成了一亿多个证明
- 注:RL 算法是一种通过试错来学习实现目标的算法,即从其与环境交互的 Experience 中调整其行为
- 调整可以通过任何方式进行,例如更新神经网络的权重,或根据环境的反馈进行上下文内调整
- 注:RL 算法是一种通过试错来学习实现目标的算法,即从其与环境交互的 Experience 中调整其行为
- 这种对交互 Experience 的关注使得 AlphaProof 能够探索超出预先存在的形式化证明范围的数学可能性,从而发现解决新颖且具有挑战性问题的方案
- 非形式数学也通过用自我生成的数据替代专家生成的数据取得了成功;例如,DeepSeek 最近的工作
- “强调了强化学习的力量和美感:论文不是明确地教导模型如何解决问题,而是简单地为其提供正确的激励,它就能自主地发展出高级的问题解决策略”(2025)
underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies.
- “强调了强化学习的力量和美感:论文不是明确地教导模型如何解决问题,而是简单地为其提供正确的激励,它就能自主地发展出高级的问题解决策略”(2025)
- 论文的论点是,一旦充分发挥 Experience 学习的潜力,将会出现令人难以置信的新能力
- 这个 Experience 时代的特征很可能在于 Agent 和环境,除了从大量 Experience 数据中学习之外,还将在几个更深的维度上突破以人类为中心的人工智能系统的局限:
- Agent 将生存在 Experience 流 (streams of experience) 中,而非简短的交互片段中
- 它们的行动和观察将根植于环境 (richly grounded in the environment),而非仅仅通过人类对话进行交互
- 它们的奖励 (rewards) 将基于其在环境中的 Experience ,而非来自人类的预判
- 它们将对 Experience 进行 规划和/或推理 (plan and/or reason about experience),而非仅以人类术语进行推理
- 作者相信,今天的技术,配合适当选择的算法,已经为取得这些突破提供了足够强大的基础
- Furthermore,人工智能界对此议程的追求将推动这些方向的新创新,迅速推动人工智能走向真正的超人类 Agent
Streams(流)
- 一个 Experience 式 Agent 可以在一生中持续学习
- 在人类数据时代,基于语言的人工智能主要关注简短的交互片段:e.g.,用户提出问题, Agent (可能在几个思考步骤或工具使用动作后)做出回应
- Typically,几乎没有或根本没有信息从一个片段延续到下一个片段,排除了任何随时间推移的适应
- Furthermore, Agent 只专注于在当前片段内取得结果,例如直接回答用户的问题
- In contrast,人类(和其他动物)存在于一个持续多年的行动和观察流中
- 信息在整个流中传递,它们的行为根据过去的 Experience 进行调整以自我纠正和改进
- Furthermore,goals 可以用延伸至流未来的行动和观察来指定
- For Example,人类可以选择行动以实现长期目标,如改善健康、学习一门语言或实现科学突破
- 强大的 Agent 应该拥有自己的 Experience 流,像人类一样在长时间尺度上推进
- 这将允许 Agent 采取行动以实现未来目标,并随时间不断适应新的行为模式
- For example,
- 一个连接到用户可穿戴设备的健康和保健 Agent ,可以连续数月监测睡眠模式、活动水平和饮食习惯
- 然后它可以提供个性化的建议、鼓励,并根据长期趋势和用户的特定健康目标调整其指导
- Similarly,个性化教育 Agent 可以跟踪用户在学习一门新语言方面的进展,识别知识差距,适应其学习风格,并在数月甚至数年内调整其教学方法
- Furthermore,一个科学 Agent 可以追求雄心勃勃的目标,例如发现一种新材料或减少二氧化碳排放
- 一个连接到用户可穿戴设备的健康和保健 Agent ,可以连续数月监测睡眠模式、活动水平和饮食习惯
- 这样的 Agent 可以在较长时间内分析现实世界的观察数据,开发和运行模拟,并提出现实世界的实验或干预措施
- 在每种情况下, Agent 都采取一系列步骤,以最大化相对于指定目标的长期成功
- 单个步骤可能不会提供任何即时利益,甚至可能在短期内不利,但总体上可能有助于长期成功
- 这与当前的人工智能系统形成鲜明对比,当前人工智能系统对请求提供即时响应,没有任何能力衡量或优化其行动对环境产生的未来后果
Actions and Observations
- Experience 时代的 Agent 将在现实世界中自主行动
- 人类数据时代的 LLM 主要关注人类特权行动和观察,即向用户输出文本,并从用户接收文本输入到 Agent
- 这与自然智能形成鲜明对比,在自然智能中,动物通过运动控制和传感器与其环境交互
- 虽然动物(尤其是人类)可能与其他动物交流,但这是通过与其他感觉运动控制相同的接口进行的,而不是通过特权通道(理解:这里说的是不是专门为输入文本准备的通道)
- 人们早已认识到, LLM 也可以在数字世界中调用行动,例如通过调用 API(例如,参见 (2023))
- Initially,这些能力主要来自人类使用工具的示例,而不是 Agent 的 Experience
- However,Coding 和 tool-use 能力越来越依赖于执行反馈 (2022, 2023, 2025),即 Agent 实际运行代码并观察发生的情况
- Recently,新一代原型 Agent 开始以更通用的方式与计算机交互,即使用人类操作计算机所用的相同接口 (2024, 2024, 2025)
- 这些变化预示着从纯粹的人类特权通信,向更自主的交互过渡,使得 Agent 能够在世界中独立行动
- 这样的 Agent 将能够积极探索世界,适应不断变化的环境,并发现人类可能从未想到过的策略
- 这些更丰富的交互将提供一种自主理解和控制数字世界的手段
- Agent 可以使用“用户友好”的行动和观察,如用户界面,自然地促进与用户的沟通和协作
- Agent 也可以采取“机器友好”的行动来执行代码和调用 API,允许 Agent 自主行动以服务于其目标
- 在 Experience 时代, Agent 还将通过数字接口与真实世界交互
- For Example,一个科学 Agent 可以监测环境传感器,远程操作望远镜,或在实验室中控制机器人手臂以自主进行实验
Rewards
- 如果 Experience 式 Agent 可以从外部事件和信号中学习,而不仅仅是人类偏好,会怎样?
- 以人类为中心的 LLM 通常根据人类预判来优化奖励:
- 专家观察 Agent 的行动并决定其是否是一个好行动,或者在多个备选方案中选择最佳 Agent 行动
- For Example,专家可以评判健康 Agent 的建议、教育助理的教学或科学家 Agent 建议的实验
- 这些奖励或偏好是由人类在缺乏其后果的情况下决定的,而不是衡量这些行动对环境的影响,这意味着它们并非直接植根于现实世界
- 依赖这种人类预判的方式通常会给 Agent 的性能带来一个难以逾越的上限:
- Agent 无法发现被人类评估者低估的更好策略
- 要发现远远超出人类现有知识的新思想,需要使用根植于现实的奖励 (grounded rewards):源于环境本身的信号
- For Example,一个健康助理可以将用户的健康目标转化为基于静息心率、睡眠持续时间和活动水平等信号组合的奖励,而教育助理可以使用考试成绩为语言学习提供根植于现实的奖励
- Similarly,一个以减少全球变暖为目标的科学 Agent 可能使用基于二氧化碳水平实证观察的奖励,而一个发现更强材料的目标可能基于材料模拟器的测量组合,如拉伸强度或杨氏模量
- 根植于现实的奖励也可能来自作为 Agent 环境一部分的人类
- 注:Experience 和人类数据并非完全对立,For Example,狗完全从 Experience 中学习,但人类互动是其 Experience 的一部分
- For Example,人类用户可以报告他们是否觉得蛋糕美味,运动后有多疲劳,或头痛的疼痛程度,使助理 Agent 能够提供更好的食谱,完善其健身建议,或改进其推荐药物
- 此类奖励衡量 Agent 行动在其环境中的后果,最终应能提供比预判蛋糕食谱、锻炼计划或治疗计划的人类专家更好的帮助
- 如果奖励不来自人类数据,那它们来自哪里?
- 一旦 Agent 通过丰富的行动和观察空间(见上文)连接到世界,将不缺乏根植于现实的信号作为奖励的基础
- 事实上,世界充满了各种量化指标,如成本、错误率、饥饿感、生产力、健康指标、气候指标、利润、销售额、考试成绩、成功、访问量、产量、库存、点赞、收入、快乐/痛苦、经济指标、准确性、功率、距离、速度、效率或能源消耗
such as cost, error rates, hunger, pro- ductivity, health metrics, climate metrics, profit, sales, exam results, success, visits, yields, stocks, likes, income, pleasure/pain, economic indicators, accuracy, power, distance, speed, efficiency, or energy consump- tion
- 此外,还有无数源自特定事件发生、或从原始观察和行动序列中提取特征的额外信号
- 原则上,可以创建多种不同的 Agent ,每个 Agent 优化一个根植于现实的信号作为其奖励
- 有观点认为,即使是单个这样的奖励信号,若能被高度有效地优化,也可能足以诱导出广泛的能力性智能 (2021)
- 注:奖励即足够假说 (The reward-is-enough hypothesis) 认为,智能及其相关能力可以从奖励最大化中自然涌现
- 这可能包括包含人类交互的环境和基于人类反馈的奖励
- 这是因为在一个复杂环境中实现一个简单的目标,通常需要掌握各种各样的技能
- 有观点认为,即使是单个这样的奖励信号,若能被高度有效地优化,也可能足以诱导出广泛的能力性智能 (2021)
- However,追求单一奖励信号在表面上似乎不符合通用人工智能的要求,即能够可靠地引导向任意用户期望的行为
- 那么,自主优化根植于现实的、非人类奖励信号是否与现代人工智能系统的要求相悖?
- 作者认为并非必然如此
- 论文概述一种可能满足这些要求的方法;其他方法也可能存在:其思想是以用户引导的方式,基于根植于现实的信号灵活调整奖励
- For Example,奖励函数可以由一个神经网络定义,该网络将 Agent 与用户和环境的交互作为输入,并输出一个标量奖励
- 这允许奖励以取决于用户目标的方式从环境中选择或组合信号
- For Example,用户可以指定一个广泛的目标,如“改善我的健康状况”,奖励函数可能返回用户心率、睡眠持续时间和步数的函数
- Or,用户可以指定“帮助我学习西班牙语”的目标,奖励函数可以返回用户的西班牙语考试成绩
- For Example,奖励函数可以由一个神经网络定义,该网络将 Agent 与用户和环境的交互作为输入,并输出一个标量奖励
- Furthermore,用户可以在学习过程中提供反馈,例如他们的满意度,可用于微调奖励函数
- 奖励函数可以随时间调整,以改进其选择或组合信号的方式,并识别和纠正任何偏差
- 这也可以理解为一个双层优化过程,将用户反馈优化作为顶层目标,将环境中的根植于现实的信号优化作为底层目标(这样,少量的人类数据可以促进大量的自主学习)
- 注:In this case, one may also view grounded human feedback as a singular reward function forming the agent’s overall objective, which is maximised by constructing and optimising an intrinsic reward function (2004) based on rich, grounded feedback.
Planning and Reasoning
- Experience 时代会改变 Agent 规划和推理的方式吗?
- Recently,在使用能够推理或“think” with language 的 LLM 方面取得了重大进展 (2024, 2024, 2025),它们在输出响应之前还会输出一个思维链 (2022)
- 从概念上讲(Conceptually), LLM 可以充当通用计算机 (2023): LLM 可以将 Token 附加到其自身上下文中,使其能够在输出最终结果之前执行任意算法
- 在人类数据时代,这些推理方法被明确设计来模仿人类的思维过程
- For Example, LLM 被提示生成类人的思维链 (2022),模仿人类思维轨迹 (2022),或强化与人类示例匹配的思维步骤 (2023)
- 推理过程可以进一步微调,以产生与人类专家确定的正确答案相匹配的思维轨迹 (2022)
- However,人类语言几乎不可能提供通用计算机的最佳实例(it is highly unlikely that human language provides the optimal instance of a universal computer)
- 肯定存在更高效的思维机制,使用非人类语言,例如利用符号、分布式、连续或可微分计算
- 一个自学习系统原则上可以通过从 Experience 中学习如何思考来发现或改进此类方法
- For Example,AlphaProof 学会了以一种与人类数学家截然不同的方式形式化证明复杂定理 (2024)
- Furthermore,通用计算机的原则只涉及 Agent 的内部计算;它并未将其与外部世界的现实联系起来
- 一个被训练来模仿人类思想甚至匹配人类专家答案的 Agent ,可能会继承深植于该数据中的错误思维方法,例如有缺陷的假设或固有偏见
- For Example,Agent 使用不同的数据会得到不同的思想:
- 若使用 5000 年前的人类思想和专家答案进行推理,它可能以万物有灵论的方式思考物理问题;
- 1000年前可能是神学方式;300年前可能是牛顿力学方式;
- 50年前可能是量子力学方式
- 要超越每种思维方式,都需要与现实世界交互:提出假设、进行实验、观察结果并相应地更新原理
- For Example,Agent 使用不同的数据会得到不同的思想:
- Similarly, Agent 必须根植于现实世界的数据,才能推翻错误的思维方法
- 这种根植性提供了一个反馈循环,允许 Agent 根据现实检验其继承的假设,并发现不受当前主流人类思维模式限制的新原理
- 没有这种根植性,无论多么复杂的 Agent ,都将成为现有人类知识的回声室(echo chamber)
- 为了超越这一点, Agent 必须积极与世界互动,收集观察数据,并使用这些数据迭代地完善其理解,这在许多方面反映了推动人类科学进步的过程
- 将思维直接根植于外部世界的一种可能方式是构建一个世界模型 (world model) (2018),用于预测 Agent 行动对世界的后果,包括预测奖励
- For Example,一个健康助理可能考虑推荐一家本地健身房或一个健康播客
- Agent 的世界模型可能会预测用户的静息心率或睡眠模式在此行动后可能如何变化,以及预测与用户的未来对话
- 这允许 Agent 直接根据其自身行动及其对世界的因果效应进行规划 (1990, 2020)
- 随着 Agent 在其 Experience 流中持续与世界互动,其动态模型不断更新以纠正其预测中的任何错误
- 给定一个世界模型, Agent 可以应用可扩展的规划方法来提高 Agent 的预测性能
- Planning 方法和 Reasoning 方法并不相互排斥:
- Agent 可以在规划过程中应用内部 LLM 计算来选择每个行动,或者模拟和评估这些行动的后果
Why Now?
- 从 Experience 中学习并非新鲜事
- 强化学习系统以前已经掌握了大量在模拟器中表示并具有明确奖励信号的复杂任务(参见图1中大致对应的“模拟时代”)
- For Example, 强化学习方法在
- 双陆棋 (1994)、围棋 (2016)、国际象棋 (2018)、扑克 (2017, 2018) 和 Stratego (2022) 等棋盘游戏中通过自我对弈达到或超越了人类水平;
- 在雅达利游戏(Atari) (2015)、星际争霸II (2019)、Dota 2 (2019) 和 Gran Turismo (2022) 等视频游戏中;
- 在如魔方 (2019) 等灵巧操作任务中;
- 在如数据中心冷却 (2016) 等资源管理任务中
- Furthermore,像 AlphaZero (2017) 这样强大的强化学习 Agent ,随着神经网络规模、交互 Experience 数量和思考时间的增加,展现出令人印象深刻且可能无限的扩展性
- However,基于这种范式的 Agent 未能跨越从模拟(具有单一、精确定义奖励的封闭问题)到现实(具有多种看似定义不清奖励的开放式问题)的鸿沟
- 人类数据时代提供了一个有吸引力的解决方案
- 海量的人类数据包含了针对海量多样化任务的自然语言示例
- 在此数据上训练的 Agent ,与模拟时代较窄的成功相比,取得了广泛的能力
- Consequently,Experience 式强化学习的方法论在很大程度上被弃用,转而青睐更 General-purpose 的 Agent ,导致了向以人类为中心的人工智能的广泛过渡
- However,在这种转变中失去了一些东西: Agent 自我发现其自身知识的能力
- For Example,AlphaZero 发现了国际象棋和围棋的全新策略,改变了人类玩这些游戏的方式 (2019, 2018)
- Experience 时代将把这种能力与人类数据时代所达到的任务通用性水平结合起来
- 如上所述,当 Agent 能够在现实世界的 Experience 流中自主行动和观察 (2024),并且奖励可以灵活地连接到任何丰富的、根植于现实的真实世界信号时,这将成为可能
- 能够与复杂的、现实世界行动空间交互的自主 Agent (2024, 2024, 2025) 的出现,以及能够在丰富推理空间中解决开放式问题的强大强化学习方法 (2024, 2025),表明向 Experience 时代的过渡已迫在眉睫
- 图1:主流人工智能范式的草图年表
- 纵轴表示:专注于强化学习的努力/该领域总努力
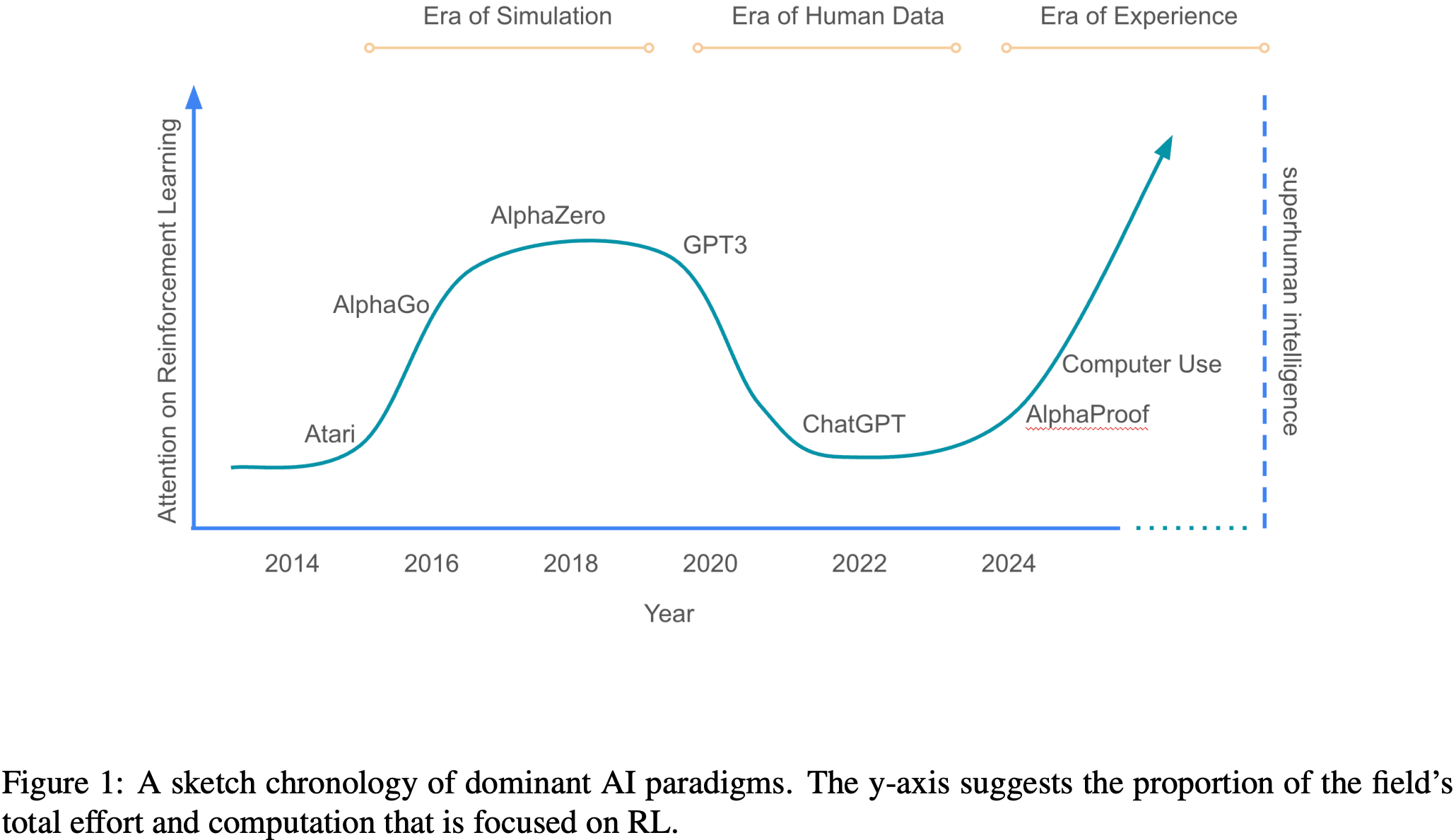
- 纵轴表示:专注于强化学习的努力/该领域总努力
Reinforcement Learning Methods
- 强化学习有着深厚的历史渊源,根植于自主学习,即 Agent 通过与其环境直接交互为自己学习
- 早期的强化学习研究产生了一系列强大的概念和算法
- For Example,时间差分学习 (1988) 使 Agent 能够估计未来奖励,从而取得了诸如在双陆棋中超越人类水平 (1994) 等突破
- 以乐观或好奇心驱动的探索技术被开发出来,以帮助 Agent 发现创造性的新行为并避免陷入次优的常规 (2021)
- 像 Dyna 算法这样的方法使 Agent 能够构建和学习其世界模型,从而允许它们对未来行动进行规划和推理 (1990, 2020)
- 选项 (options) 和选项内/选项间学习等概念促进了时间抽象,使 Agent 能够在更长时间尺度上进行推理,并将复杂任务分解为可管理的子目标 (1999)
- 注:Option 是分层强化学习的经典时间抽象工具,由 Sutton 等人在 1999 年提出,用于将多步行为封装为可复用的 “宏动作 / 子策略”,实现跨时间尺度的决策与规划,适配复杂任务的分解与迁移
- However,以人类为中心的 LLM 的兴起,将焦点从自主学习转移到了利用人类知识上
- 像 RLHF (2017, 2022) 和使语言模型与人类推理保持一致的方法 (2022) 等技术被证明极其有效,推动了人工智能能力的快速进步
- 这些方法虽然强大,但往往绕过了强化学习的核心概念:RLHF 通过调用人类专家替代机器估计的价值,回避了对价值函数的需求;
- 来自人类数据的强先验减少了对探索的依赖;以人类为中心的术语进行推理降低了对世界模型和时间抽象的需求
- 可以说这种范式的转变是“把婴儿和洗澡水一起倒掉了(has thrown out the baby with the bathwater)”
- 虽然以人类为中心的强化学习实现了前所未有的行为广度,但它也给 Agent 的性能强加了一个新的上限: Agent 无法超越现有的人类知识
- FurtherMore,人类数据时代主要关注那些为短片段(short episodes)、非根植的(ungrounded)人类交互设计的强化学习方法,这些方法并不适用于长期的、根植于现实的(grounded)自主交互流
the era of human data has focused predominantly on RL methods that are designed for short episodes of ungrounded, human interaction, and are not suitable for long streams of grounded, autonomous interaction.
- Experience 时代提供了一个重新审视和改进经典强化学习概念的机会
- 这个时代将带来关于奖励函数的新思考方式,使其灵活地植根于观察数据
- Experience 时代将重新审视价值函数以及从尚不完整的长期流中估计价值的方法
- Experience 时代将带来有原则且实用的现实世界探索方法,以发现与人类先验截然不同的新行为
- Experience 时代将开发新颖的世界模型方法来捕捉根植交互的复杂性
- 新的时间抽象方法将使 Agent 能够在 Experience 层面上,在更长的时间跨度上进行推理
- 通过在强化学习的基础上,并将其核心原理适应这个新时代的挑战,我们可以释放自主学习的全部潜力,并为通向真正的超人类智能铺平道路
Consequences
- Experience 时代的到来,即人工智能 Agent 从与世界的交互中学习,预示着与论文迄今为止所见任何事物都截然不同的未来
- 这种新范式虽然提供了巨大的潜力,也带来了重要的风险和挑战,需要仔细考虑,包括但不限于以下几点
- 积极方面(On the positive side), Experience 学习将释放前所未有的能力
- 在日常生活中,个性化助手将利用连续的 Experience 流,在数月或数年内,针对个人的健康、教育或职业需求,朝着长期目标进行调整
- 也许最具变革性的是科学发现的加速
- 人工智能 Agent 将自主设计和进行材料科学、医学或硬件设计等领域的实验
- 通过持续从自身实验结果中学习,这些 Agent 可以迅速探索新的知识前沿,以前所未有的速度开发出新颖的材料、药物和技术
- 在日常生活中,个性化助手将利用连续的 Experience 流,在数月或数年内,针对个人的健康、教育或职业需求,朝着长期目标进行调整
- However,这个新时代也带来了重大且新颖的挑战
- 虽然人类能力的自动化有望提高生产力,但这些改进也可能导致工作岗位的流失
- Agent 甚至可能展现出先前被认为是人类专属领域的能力,例如长期问题解决、创新以及对现实世界后果的深刻理解
- Furthermore,在对人工智能的潜在滥用存在普遍担忧的同时,那些能够自主与世界长时间交互以实现长期目标的 Agent 可能会带来更高的风险
- 默认情况下(By default),这为人类干预和调解 Agent 的行动提供了更少的机会,因此需要更高水平的信任和责任
- 远离人类数据和人类思维模式也可能使未来的人工智能系统更难以解释
- However,承认 Experience 学习会增加某些安全风险的同时,肯定需要进一步研究以确保安全过渡到 Experience 时代,我们也应认识到,它也可能提供一些重要的安全益处
- Firstly, Eexperiential Agent 了解自身所处的环境,其行为可以随时间推移适应环境的变化
- 注:任何预编程的系统,包括固定的人工智能系统,都可能不了解自身环境背景,并对其部署到的变化的世界 maladapted
- For Example,关键硬件可能发生故障,流行病可能导致快速的社会变化,或者新的科学发现可能引发一系列快速的技术发展
- By Contrast, Experiential Agent 可以观察并学习规避故障硬件,适应快速的社会变化,或者拥抱并基于新科学技术进行构建
- Perhaps even more importantly, Agent 可以识别其行为何时引发了人类的担忧、不满或痛苦,并自适应地修改其行为以避免这些负面后果
- 注:任何预编程的系统,包括固定的人工智能系统,都可能不了解自身环境背景,并对其部署到的变化的世界 maladapted
- Second, Agent 的奖励函数本身可以通过 Experience 进行调整,例如使用前面描述的双层优化(参见奖励部分)
- 重要的是,这意味着不一致的奖励函数通常可以通过试错随时间逐步纠正
- For Example,奖励函数可以基于人类担忧的迹象进行修改,而不是盲目地优化一个信号,例如最大化回形针生产 (2003),直到回形针生产耗尽地球资源
- 这类似于人类为彼此设定目标,然后如果观察到人们钻系统空子、忽视长期福祉或导致不希望看到的负面后果,则调整这些目标;
- 不过也像人类设定目标一样,无法保证完美的一致
- 重要的是,这意味着不一致的奖励函数通常可以通过试错随时间逐步纠正
- Finally,依赖于物理 Experience 的进步本身受到在现实世界中执行行动和观察其后果所需时间的限制
- For Example,一种新药的开发,即使有 AI 辅助设计(AI-assisted Design),仍然需要无法在一夜之间完成的现实世界试验
- 这可能为潜在的人工智能自我改进速度提供一个天然的制约
Conclusion
- Experience 时代标志着人工智能演进的关键时刻
- 建立在当今坚实的基础上,但超越人类衍生数据的局限, Agent 将越来越多地从自身与世界的交互中学习
- Agent 将通过丰富的观察和行动与环境自主交互
- Agent 将在终生的 Experience 流中持续适应
- Agent 的目标可以被引导至任何根植于现实的信号组合
- Furthermore, Agent 将利用强大的非人类推理能力,并构建基于 Agent 行动对其环境所产生后果的规划
- Ultimately, Experiential 数据将在规模和质量上超越人类生成的数据
- 这种范式转变,伴随着强化学习的算法进步,将在许多领域释放超越任何人类所拥有的新能力