整体说明
- 总体来说,各种并行策略包括了 DP、TP、PP、EP、CP/SP 等,并行意味着拆分,理解并行策略最重要的问题是回答并行策略到底在拆什么
- DP,Data Parallelism:数据并行(切 batch/sample)
- TP,Tensor Parallelism:张量并行(层内切权重矩阵)
- PP,Pipeline Parallelism:流水线并行(层间切网络深度)
- EP,Expert Parallelism:专家并行(仅 MoE 结构,切 Expert 层)
- CP/SP,Context/Sequence Parallelism 序列并行(切输入长序列)
- 各种并行策略的本质目标不外乎两个:
- 将大批量的数据分发到不同的机器上,实现更高的并行度,缩短训练时间
- 将一个巨大到无法在单个加速器(如 GPU)上训练的模型,高效地拆分到多个加速器上,以解决显存瓶颈并加速训练过程
- 各种并行策略之间并非简单的“依赖”关系,而更多的是一种 正交(Orthogonal)和互补(Complementary) 的关系
- 一般来说,它们可以独立应用,也可以组合使用,形成更复杂的混合并行策略
更详细一些的描述
- DP(Data Parallelism) :核心是对模型进行复制,对数据进行拆分
- DP 的拆分维度是数据(Batch),是最基础、最常见的并行方式;
- DP 将整个模型完整地复制到每个计算设备上,然后将一个大的全局批次(Global Batch)数据切分成多个微批次(Micro-batch),每个设备分配一个微批次进行独立的前向和后向计算
- 在所有设备完成梯度计算后,需要进行一次全局梯度同步(All-Reduce),将所有设备上的梯度规约(如求平均),然后每个设备用同步后的梯度更新自己的模型副本,以保证模型参数的一致性
- 作用在模型全局,同步发生在设备之间
- 对“单卡”来说不省任何权重,只提升系统吞吐;通常与 ZeRO-1/2/3 叠加才真正省显存
- TP(Tensor Parallelism) :把“一层里的单个矩阵”按行或列切到多张卡上
- TP 的拆分维度是模型参数(Tensor)
- 核心思想是:当模型中的某个算子(Operator),尤其是线性层(Linear Layer)或注意力头(Attention Head)的权重矩阵过大时,TP 将其在水平或垂直方向上切分到多个设备上
- 以一个线性层 \(Y = XA\) 为例,可以将权重矩阵 \(A\) 按列切分为 \([A_1, A_2]\),分别放到两个 GPU 上(注:也可以按行切分)
- 输入 \(X\) 被广播到两个 GPU,各自计算 \(Y_1 = XA_1\) 和 \(Y_2 = XA_2\),最后将结果拼接 \([Y_1, Y_2]\) 得到完整的 \(Y\)
- 重点:作用范围为 算子内部(Intra-Operator) ,它对模型的其它部分是透明的
- 每张卡与同一层所有卡进行交互,延迟敏感
- 单卡只存 1/TP 份权重 + 1/TP 份梯度,激活值也随 TP 线性下降
- PP(Pipeline Parallelism) :把“网络按层切成若干 stage”,每个 stage 占连续的若干层,数据按 micro-batch 流水推进
- PP 的拆分维度是模型结构(Layers)
- 核心思想是当模型的层数非常深时,将模型的不同层(或层块,Stage)顺序地放置在不同的设备上,构成一个“流水线”
- 数据在一个设备上完成前向计算后,将其激活值(Activations)传递给下一个设备继续计算
- 为了减少设备空闲(即“流水线气泡” Pipeline Bubble),通常会将一个批次数据再切分成多个微批次(Micro-batches),让多个微批次在流水线中流动起来,实现类似 GPipe 或 Interleaved 1F1B 的调度
- 重点:作用范围是 算子之间(Inter-Operator) ,跨越多个模型层
- 只有相邻 stage 之间传激活,带宽要求比 TP 低
- 每个 stage 只存自己那几层的权重与激活,层数越少显存越小;但流水会引入 bubble
- EP(Expert Parallelism,MoE 场景专有) :把“不同的 Expert 网络”放到不同 GPU,Attention 部分参数复制
- EP 的拆分维度 模型专家组件(Experts)
- EP 是专门为 MoE(Mixture of Experts)架构设计的并行策略
- Mo E模型中包含多个“专家”(通常是 FFN),一个门控网络(Gating Network)会为每个输入 Token 选择性地激活一个或少数几个专家
- EP 将这些专家分布到不同的设备上:假设有 E 个专家,我们把它们均匀拆到 N 张卡上,每张卡只存 E/N 个专家权重
- 基本流程:输入数据首先通过门控网络,然后根据门控结果,数据被路由(All-to-All 通信)到持有被激活专家的设备上进行计算,计算结果再被路由(All-to-All 通信)回来
- 一张卡上难免会出现 本卡 Token 选中其他远端专家 的情况,于是必须做 跨卡 All-to-All 重排(先把 Token 发送到目标路由 Expert,走完专家再返回至 Token 所在机器)
- 每 Token 前向过程需要 2 次 All-To-All,带宽压力最大
- 第一次 All-to-All:把 token 特征发给真正拥有目标专家的卡;
- 第二次 All-to-All:把 token 计算结果再发回原卡(返回 Token 所在机器)
- EP 的作用范围是特定的 MoE 层内部,涉及跨设备的数据路由
- 注:仅考虑 EP 时,虽然单张显卡存储 Expert 参数总量 / EP,但 Attention 部分直接全量存储
- CP/SP (Context/Sequence Parallelism - 上下文/序列并行) :把“同一条超长序列”按 token 维度横切到多卡
- CP/SP 拆分维度是输入序列(Sequence),将输入序列在长度维度上进行切分,分给不同的设备
- CP/SP 的方法很多,实现上各有不同:
- Megatron SP 核心是对 TP 进行补充:
- TP 只针对 Attention 和 MLP,Dropout 和 LayerNorm 的 激活层未得到拆分,SP 按照 seq 维度进一步拆分了 Attention 和 MLP 之间的层上的激活值(即拆分 Attention/MLP 输入和输出结果),进一步降低单卡激活值存储
- 注:这里 SP 中,Dropout 和 LayerNorm 的参数是全量存储的,并不进行拆分,仅拆分激活值
- Megatron CP 是对 Megatron SP 的升级,SP 仅关注 Dropout 和 LayerNorm,Megatron CP 还针对注意力的做拆分,基本思想是在计算自注意力时,每个设备只负责计算其拥有的那部分序列的 Query 向量,但需要获取所有序列的 Key 和 Value 向量(计算 softmax)
- 这需要在注意力计算中进行巧妙的通信(All-Gather),以收集完整的 K 和 V,它与 TP 协同工作,共同降低注意力计算的显存峰值
- 还可以针对 MLP 做 CP 策略
- Megatron SP 核心是对 TP 进行补充:
- 注意:序列并行切分维度是
sequence length(序列长度),序列并行生效时,激活值也被切分了(激活值是训练时显存的大头),所以能极大节省显存
Tensor Parallelism
- Tensor Parallelism 仅针对 MLP 和 Attention 做张量拆分,在 Attention 和 MLP 之间的部分,每张显卡上都存储了完整的(相同的)激活和参数
- 核心实现思路:
- 对 Attention 或 MLP 层进行张量拆分,在计算 Attention 或 MLP 时,每张卡独立计算自己的部分
- 在 Attention 或 MLP 之前或之后的部分,每张卡上的各种数据/激活是完全一致的
- 通信发生在每次 Attention/MLP 前后,保证 Attention/MLP 前后的输入或激活完全一致
- 补充 Megatron-LM 论文中 Tensor Parallelism 的图片:


- 具体来说,其交互方式为:
- 可以按照不同方式拆分权重:按照行或列切分权重,分别需要不同的通信逻辑
- 按行切分权重时:Forward 过程需要一次 All-Reduce;Backward 过程需要一次 All-Aather
- 按列切分权重时:Forward 过程需要一次 All-Gather;Backward 过程需要一次 All-Reduce
")
Sequence Parallelism(序列并行)
- 原始论文:Sequence Parallelism: Long Sequence Training from System Perspective, arXiv 2021, NUS
- 参考链接:
- Megatron 的 Sequence Parallelism 设计上是结合 Tensor Parallelism 一起使用的(MLP 和 Attention 做 TP,Dropout 和 LayerNorm 做 SP),核心目标是降低单卡激活值
/Megatron-LM-3-Figure5.png "来源于:Megatron-LM 第三篇论文")
- DeepSpeed-Ulysses 可以对 MLP 和 Attention 也进行 SP,让单张卡只需要维护和计算部分 Attention Head 等结果
- 补充背景:DeepSpeed Zero 1/2/3 的本质都是数据并行(形式上是模型并行),单张卡是需要过完整的 MHA 的,如果不做 Sequence Parallelism,长序列容易导致单卡显存压力过大
- Ring Attention 让每张卡只需要维护自己那部分 Sequence chunk 的 MHA
- Megatron 的 Context Parallelism ,是在保持 Megatron SP 的基础上,引入 CP,这里的 CP 本质是对 Attention 做优化
- Megatron 的 CP 也使用了类 Ring Attention 技术,相当于是 Megatron SP 的升级版本,在 Megatron SP 的基础上,增加了 Ring Attention,对 Attention 也做序列并行
Context Parallelism vs Sequence Parallelism
- Sequence Parallelism 概念最早来源于 Megatron-LM 论文和代码中,这种技术就被称为 “Tensor Parallelism” across sequence dimension 或直接称为 “Sequence Parallelism”;上下文并行(Context Parallelism,CP)则是一个更广泛、更抽象的概念;
- 在 Transformer 中讨论时,一般可以认为两者几乎是等价的,但是针对特定场景如 Megatron-LM 中,Context Parallelism 本质是升级版的 Sequence Parallelism
- 注:在 Transformer 的论文和讨论中,“序列(Sequence)”和“上下文(Context)”这两个词本身就经常混用,都指模型一次处理的最大token长度
Expert Parallelism(专家并行)
- 专家并行(Expert Parallelism, EP)是一种专为 MoE 设计的模型并行策略
- Expert Parallelism 将 MoE 层中的不同专家(Expert)分布到不同设备上,每个设备只负责一部分专家的计算;
- 输入 token 根据门控网络(Gating Network)动态路由到对应的专家设备,计算完成后再将结果聚合回原设备
- 专家并行降低单卡显存的核心思想是:将模型中的不同“专家”(Experts)分布到不同的设备上,每个设备只负责维护分配给它的那一部分专家
- 专家并行论文:GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, 2020, Google
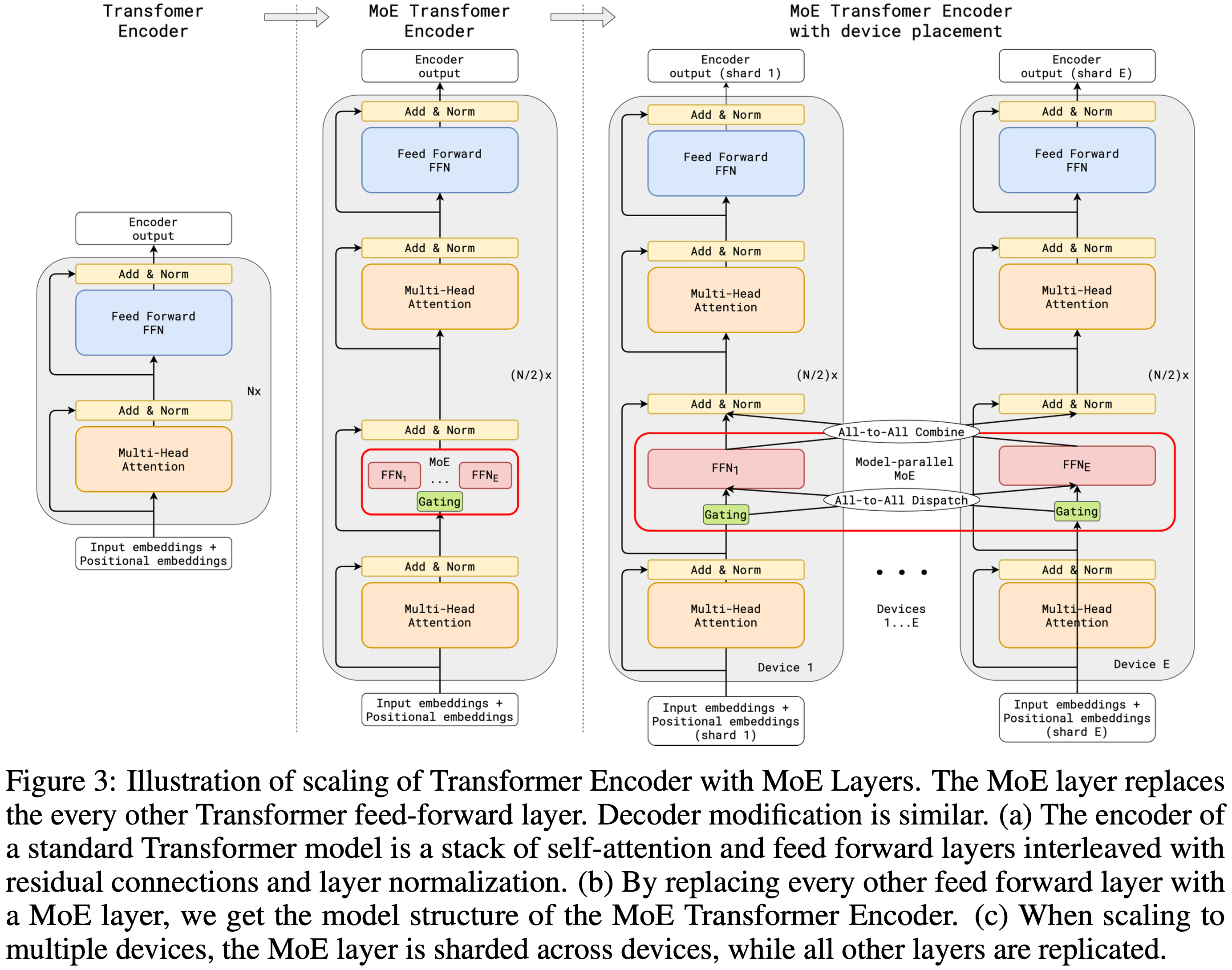
- EP 相关基本概念:
- 专家并行组(ep_group) :一组设备共同托管一组专家,组内设备通过 All-to-All 通信协作
- 数据并行组(dp_group) :在不同 ep_group 之间,相同专家的数据副本组成数据并行组,用于梯度同步
EP 具体详细流程
- EP 的具体流程如下:专家并行 = 专家分布 + 动态路由 + All-to-All 通信 + 本地计算 + 结果还原
- 1)EP 组划分与专家分配 :
- 将不同的专家分配到不同的设备组上,每个设备组称为一个 EP 组,每个 EP 组包含多个机器和显卡
- 例如,假设 MoE 层有 E 个专家,EP=4 那么可以将 E 个专家平均分配给 4 个 EP 组,每个EP组负责一部分专家
- 2)路由决策计算 :
- 输入数据首先经过路由层(Router),计算每个 Token 的路由分数/权重,每个设备本地运行共享的门控网络(通常在所有设备上复制)
- 具体来说,通过公式
Gating_logits = Y @ W_router计算,其中Y是输入张量,W_router是路由层的权重- 如果
W_router在张量并行(TP)组内切分,需要类似 AllGather 或 ReduceScatter 的通信来完成计算或收集结果,最终得到的 Gating_logits
- 如果
- 对 Gating_logits 应用 Top-K 和 Softmax 操作,得到每个 Token 的路由决策,即它应该被发送到哪 K 个专家以及对应的权重
- 3)按照路由决策重排 :
- 对输入的每个 token,门控网络决定其应被路由到哪些专家(Top-K 选择),即包含每个 token 到目标专家索引列表
- 根据门控结果,将发往同一专家的 token 聚合到一个连续的内存块中
- 这一步称为 permutation(重排) ,便于后续高效通信和计算
- 4)All-to-All Dispatch(Token 分发) :
- 使用 All-to-All 通信原语,将 token 从原始设备发送到目标专家所在的设备
- 每个设备只接收它需要处理的 token 子集
- 通信量取决于 batch 大小、专家数量和路由稀疏性
- 5)本地路由与专家计算 :
- 每个设备仅对其本地持有的专家进行前向计算(如 FFN)
- 由于专家数量被切分,内存和计算压力显著降低
- 计算是 并行进行 的,设备间无依赖
- 每张卡对自己筛选出来的 Tokens 应用本卡负责的专家网络进行计算
- 专家网络通常是标准的FFN(如
GeLU(W1 * x) * W2),并且专家网络的权重W1、W2在 TP 组(即 EP 组)内进行张量并行切分
- 专家网络通常是标准的FFN(如
- 6)All-to-All Combine(结果收集)
- 再次使用 All-to-All 通信,将专家计算结果发送回原始设备
- 每个设备根据原始 token 的顺序,恢复输出张量的布局
- 7)输出解码与加权求和
- 将各专家的输出按门控权重加权求和,得到最终的 MoE 层输出
- 输出与残差连接相加,继续进入下一层
通信成本
- 通信成本总结
并行维度 切分对象 单卡显存下降项 通信类型及量级 备注 TP 单层权重(列切/行切) 模型权重 \(\propto\) 1/TP
激活 \(\propto\) 1/TP每层 2×all-reduce,
带宽要求高节点内(NVLink)最佳 PP layer group 权重 \(\propto\) 1/PP
激活 \(\propto\) 1/PP
(开启gradient checkpoint 时)相邻 stage P2P,
量小但需频繁可跨节点;bubble 占比=PP-1/PP EP FFN MoE Experts Expert 权重 \(\propto\) 1/EP
Attention 权重完整复制每 token 2×all-to-all,
非对称仅 MoE 模型;EP≥1 CP 输入序列维度 激活 \(\propto\) 1/CP all-gather+reduce-scatter 一般超长上下文(>32k)才开 DP batch 维度 无 每 step 1×all-reduce 与 TP/PP/EP 正交;可用 ZeRO 1/2/3 进一步省显存 - EP 通信开销的详细描述:MoE 训练到底是开 TP 还是 EP? - xffxff的文章 - 知乎
常用组合约束
- TP、CP、EP 都是“横切”同一组层内数据,通信模式全是 All-Reduce/All-To-All,必须放在同一高速域(NVLink / HBM),俗称一个“node”
- PP 是“竖切”层,可以跨 node,通信量小,适合机间
- DP 是“最外层复制”,可跨任意节点,业界常用 3D/4D/5D 混合:
- 括号内必须落在一台 8-GPU 机器里,括号外可以跨机
- TP/CP/EP 负责“省显存、限节点”,PP 负责“再省一层、可跨机”,DP 负责“加吞吐”
- 补充:在 Megatron-LM 实现 中, 可以看到基本规则是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# megatron/core/parallel_state.py def initialize_model_parallel()
# 注:DP = world_size / (TP * PP * CP)
model_size = tensor_model_parallel_size * pipeline_model_parallel_size * context_parallel_size
if world_size % model_size != 0:
raise RuntimeError(f"world_size ({world_size}) is not divisible by {model_size}")
data_parallel_size: int = world_size // model_size
# 注:EP 相关的并行不占用独立的进程组 DP_ep = world_size / (ETP * EP * PP),其中 ETP 一般等于 TP
## EP:expert_model_parallel_size (int, default = 1): The number of Mixture of Experts parallel GPUs in each expert parallel group. 这个是真正的 EP
## ETP:expert_tensor_parallel_size (int, default = tp_size): The number of GPUs to split individual tensors of expert. 这个是 Expert内部张量并行的并行度,一般来说就等于 TP 本身
## 总结:可以看出,EP 和 CP 不会同时出现在分母中,即两者没有同时出现?
if expert_tensor_parallel_size is None:
expert_tensor_parallel_size = tensor_model_parallel_size # 如果 EP 没有指定,默认取 EP = TP
expert_tensor_model_pipeline_parallel_size = (
expert_tensor_parallel_size * expert_model_parallel_size * pipeline_model_parallel_size
)
expert_data_parallel_size = world_size // expert_tensor_model_pipeline_parallel_size
if world_size % expert_tensor_model_pipeline_parallel_size != 0:
raise RuntimeError(
f"world_size ({world_size}) is not divisible by expert_tensor_model_pipeline_parallel size ({expert_tensor_model_pipeline_parallel_size})"
)
附录:Megatron-LM 中的 expert_tensor_parallel_size 和 expert_model_parallel_size 的区别
- 在 Megatron-LM(特别是针对 Mixture of Experts (MoE) 模型)项目中,
expert_tensor_parallel_size和expert_model_parallel_size都与 MoE 专家的并行化有关,但它们侧重于不同类型的并行: expert_tensor_parallel_size(专家张量并行大小, 本质是专为专家配置的 TP):- 指的是应用于 单个 Expert(专家)内部 的 张量并行 (Tensor Parallelism, TP) 的大小
- 像处理标准 Transformer 层一样,它将单个专家(通常是一个大的前馈网络 FFN)的权重矩阵分解到多个 GPU 上
- 这减少了每个 GPU 上单个专家的内存占用
- 相关 GPU 组成一个 张量并行组 (Tensor Parallel Group)
- 通常在层内进行通信(例如 All-Reduce 操作)以完成计算
expert_model_parallel_size(专家模型并行大小,通常也称为专家并行 Expert Parallelism, EP):- 指的是所有 Experts在不同 GPU 上的分布 ,即 Expert Parallelism (EP) 的大小
- 在 MoE 模型中,通常有大量的专家
- 专家并行将不同的专家分配到不同的 GPU 上,使得每个 GPU 存储和计算一部分专家
- 这有效地扩展了专家数量和模型总大小的上限
- 相关 GPU 组成一个 专家并行组 (Expert Parallel Group)
- 主要在 MoE 层的路由(Routing)过程中,涉及Token在不同专家(GPU)之间的发送和接收(例如 All-to-All 或 Shuffle 操作)
- 在 Megatron-LM 的 MoE 实现中,可以同时使用这两种并行策略:
- 先用
expert_model_parallel_size(EP) 将所有专家分布到多个 GPU 上 - 再在每个 GPU 组内,使用
expert_tensor_parallel_size(TP) 将每个专家内部的计算进行张量分割
- 先用
附录:数据并行下各种批次关系
micro_batch_size,有时简称mbz,是单个 GPU 在一次前向-反向里真正处理的样本数;gradient_accumulation_steps,有时简称GAS,是同一张 GPU 在做一次参数更新前把 micro_batch 跑几遍并累加梯度- 一般来说:
global_batch_size = DP_size * mini_batch_sizeglobal_batch_size = DP_size × micro_batch_size × grad_accum_steps
附录:使用注意事项
- 实用建议:超长 MoE 先开 CP 把序列压下来,再在一层内部用 EP 分散专家;或干脆“二选一”
- PP 的 stage 之间只传激活,不涉参数/梯度集合通信,通信量小,因此可以跨机器,所以分配 rank 时一般是最后考虑的;
- 唯一要注意的是:
micro_batches >= PP_size,否则流水线气泡 > 50%,吞吐腰斩
- 唯一要注意的是:
- TP 是需要通信量最大的,一般限制在同一台机器内部,这样可以提升通信效率,分配 rank 时一般是最优先考虑的,TP 进程组 rank 也一般是连续成对的
- ZeRO-1/2/3 本质仍是 DP,只是梯度/优化器/参数分片;
- ZeRO-3 与 TP 同时开时,同一 TP 组内必须关闭参数分片 ,否则一次 MatMul 要跨 ZeRO 组做 All-Gather,延迟爆炸
- DP 的本质是提升并行度,一般来说,DP 的目标是开启前后保证梯度更新是是一致的,实现时也是朝这个方向实现的,比如 DDP 或 Megatron 中,在聚合梯度时,都是按照 DP 求平均(先 all_reduce SUM,再除以 DP_size)
- DP 的通信量不算太高,也可以跨机器实现
附录:Megatron 中 DP 之间聚合梯度是平均还是累加 ?
和 DDP 中一样,Megatron 中 DP 之间的梯度聚合是分两步的:
- 先调用
all_reduce实现累加 - 然后再调用除法(除以 DP_Size)实现平均
- 先调用
简单代码阅读 github.com/NVIDIA/Megatron-LM/blob/main/megatron/training/training.py:
1
2
3
4
5
6
7
8
9
10...
torch.distributed.all_reduce(
val,
group=mpu.get_data_parallel_group(with_context_parallel=True)
)
val /= torch.distributed.get_world_size(
group=mpu.get_data_parallel_group(with_context_parallel=True)
)
loss_reduced[key] = val
...特别说明:如果是想做 Token 粒度的平均(每个样本的可学习 Token 数不一致),需要多维护一个 Token 数量的变量并执行一次
all_reduce通信- 当然,为了实现与不做 DP 完全一致的效果,这里其实是应该对 Token 也做聚合,再做除法才行的
补充:DDP 中的 DP 间梯度聚合
- DDP 中在 DP 间累积梯度后,做了平均,具体实现参见 github.com/pytorch/pytorch/blob/main/torch/csrc/distributed/c10d/reducer.cpp
1
2
3
4
5// 取值与 DP_size 有关(注意: 这里的 size 就是 DDP 中的 world_size,也就是 DP_size)
div_factor_ = process_group_->getSize();
...
// 做除法
bucket_view.div_(div_factor_);
不同并行配置下需要多少卡?
- 一般来说,Megatron-LM 官方实现给的结论是,所有维度的并行相乘得到总的卡数
- 部分框架实现下, 可以让 EP 复用 CP 或 DP 等, 实现 EP 不参与乘法得到总的卡数