本文简单录对齐微调的一些方法,部分方法的详细内容可以在本人其他博客搜索到
熵的定义
- 熵的一般定义:
$$ H = -\sum_a \pi(a) \log \pi(a) = - \mathbb{E}_{a\sim \pi(a)} \log \pi(a)$$
SFT 的 Loss
- SFT 的目标为最大化 Next Token 的对数概率和(本质是最大化所有 Token 的联合概率分布):
$$ \mathcal{J}_\text{SFT}(\theta) = \max_\theta \mathbb{E}_{q,o\sim P_\text{SFT}(Q,o)}\left[\frac{1}{|o|} \sum_t \log \pi_\theta(o_t| x,o_{< t})\right]$$ - SFT 下的 Loss 为:
$$ L_\text{SFT} = -\frac{1}{|o|} \sum_t \log \pi_\theta(o_t| x,o_{< t}) $$
RM 的 Loss
- 遵循 Bradley-Terry 模型,论文使用如下所述的奖励函数 \(r_{\psi}(x, y)\) 来制定偏好分布:
$$
\begin{aligned}
p_{\psi}(y_{c} \succ y_{r}|x) & = \frac{\exp(r_{\psi}(x, y_{c}))}{\exp(r_{\psi}(x, y_{c})) + \exp(r_{\psi}(x, y_{r}))}, \\
& = \sigma(r_{\psi}(x, y_{c}) - r_{\psi}(x, y_{r})),
\end{aligned}
$$- 其中 \(\sigma\) 是逻辑函数
- 理解:这相当于是将正样本大于负样本的概率定义为一个 sigmoid 函数
- 将该问题视为二分类任务,得到负对数似然损失函数(negative log-likelihood loss function):
$$
\mathcal{L}(r_{\psi}) = -\mathbb{E}_{(x, y) \sim \mathcal{D}_\text{rm} }[\log\sigma(r_{\psi}(x, y_{c}) - r_{\psi}(x, y_{r}))],
$$- 理解:这里的损失函数本质上是相当于是二元交叉熵损失(Binary Cross-Entropy, BCE)函数,但因为已知有正负样本了,所以不需要分 label=1 和 label=0 来分别计算了
$$
L_\text{BCE} = -\frac{1}{N}\sum_{i=1}^N \big[y_i\log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)\big]
$$- \(y_i\):真实标签(0 或 1),在 RM 中固定为 1(因为我们已知 Chosen 比 Rejected 更好)
- \(\hat{y}_i\):模型预测概率 \(\sigma(r_{\psi}(x, y_{c}) - r_{\psi}(x, y_{r}))\)
- 将 \(y_i=1\) 带入上面的 BCE 即可化简得到
$$
\begin{align}
L_\text{BCE}
&= -\frac{1}{N}\sum_{i=1}^N 1 \cdot \log(\hat{y}_i) \\
&= -\frac{1}{N}\sum_{i=1}^N \log \sigma(r_{\psi}(x, y_{c}) - r_{\psi}(x, y_{r})) \\
\end{align}
$$
- 其中数据集由表示为 \(D_\text{rm} = \{x^{(i)}, y_{c}^{(i)}, y_{r}^{(i)}\}_{i=1}^{N}\) 的 comparisons 组成
- 在语言模型(LMs)领域,网络 \(r_{\psi}(x, y)\) 通常使用 SFT 模型 \(\pi^\text{SFT}(y|x)\) 进行初始化,并在它在最终的 Transformer 层上加入一个额外的线性层,以生成单个标量预测(singular scalar prediction)来表示奖励值
- 理解:这里的损失函数本质上是相当于是二元交叉熵损失(Binary Cross-Entropy, BCE)函数,但因为已知有正负样本了,所以不需要分 label=1 和 label=0 来分别计算了
PPO
- PPO 是最原始的 RLHF 方法
- PPO 的替代目标函数定义为:
$$
\mathcal{L}^{CLIP}(\theta) = \hat{\mathbb{E} }_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right]
$$- \( \pi_\theta(a|s) \) 为当前策略,\( \pi_{\theta_{\text{old} } }(a|s) \) 为上一轮迭代的旧策略
- \( r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old} } }(a_t|s_t)} \) 是概率比
- \( \hat{A}_t \) 是时间步 \( t \) 的优势估计
- \( \epsilon \) 是控制裁剪范围的超参数
- 广义优势估计 (GAE) 是一种用于在 PPO 中更准确估计优势函数的技术
- 对于长度为 \( T \) 的轨迹,时间步 \( t \) 的优势估计 \( \hat{A}_t \) 计算如下:
$$
\hat{A}_t = \sum_{l=0}^{T-t-1} (\gamma \lambda)^l \delta_{t+l}
$$- \( \gamma \) 是折扣因子
- \( \lambda \in [0,1] \) 是 GAE 参数
- \( \delta_t = R(s_t, a_t) + \gamma V(s_{t+1}) - V(s_t) \) 是时序差分(Temporal-Difference, TD)误差
- 这里 \( R(s_t, a_t) \) 是时间步 \( t \) 的奖励,\( V(s) \) 是价值函数
- 对于长度为 \( T \) 的轨迹,时间步 \( t \) 的优势估计 \( \hat{A}_t \) 计算如下:
- 注:在 RLHF 中通常设置折扣因子 \( \gamma = 1.0 \),为简化表示,论文后续章节将省略 \( \gamma \)
- LLM 中,更具体的写法可以是:
$$
\mathcal{J}_{\textit{PPO}}(\theta)=\mathbb{E}_{q\sim P(Q),o\sim\pi_{\theta_{old}}(O|q)}\frac{1}{|o|}\sum_{t=1}^{|o|}\min\left[\frac{\pi_{\theta}(o_ {t}|q,o_{<t})}{\pi_{\theta_{old}}(o_{t}|q,o_{<t})}A_{t},\textrm{clip}\left( \frac{\pi_{\theta}(o_{t}|q,o_{<t})}{\pi_{\theta_{old}}(o_{t}|q,o_{<t})},1-\epsilon ,1+\epsilon\right)A_{t}\right],
$$
CPPO(Continual Proximal Policy Optimization)
- 原始论文:CPPO: Continual Learning for Reinforcement Learning with Human Feedback, ICLR 2024, Harbin Institute of Technology (Shenzhen):截止到 20250612,cited by 25
- 其他容易误解论文:CPPO: Accelerating the Training of Group Relative Policy Optimization-Based Reasoning Models, arXiv 202503, Xiamen University:截止到 20250612,cited by 12
- 不厚道,命名与别人相同,容易造成读者误解
REINFORCE
- 不需要 Value Model,蒙特卡罗法评估奖励
- 对 PPO 的简化
REINFORCE++
- 原始论文:REINFORCE++: An Efficient RLHF Algorithm with Robustness to Both Prompt and Reward Models, 20250104-20251110, Jian Hu & Jason Klein Liu & Wei Shen
- REINFORCE++ 方法介绍
- 本质可以理解为 REINFORCE 方法(不是基于 Prompt 组的,有一个基于历史全局的基线)
- 在 REINFORCE 的基础上,记录历史平均奖励作为基线,判断模型是否在进步(相比 GRPO,基线不是 Prompt 粒度的,而是历史)
- 使用历史奖励的均值和方差做归一化,类似 Batch Normalization(论文认为 GRPO 的方法会出现 Prompt 粒度的有偏问题)
- REINFORCE++ 方法出现在 ReMax, GRPO 和 RLOO 之后,对比如下:
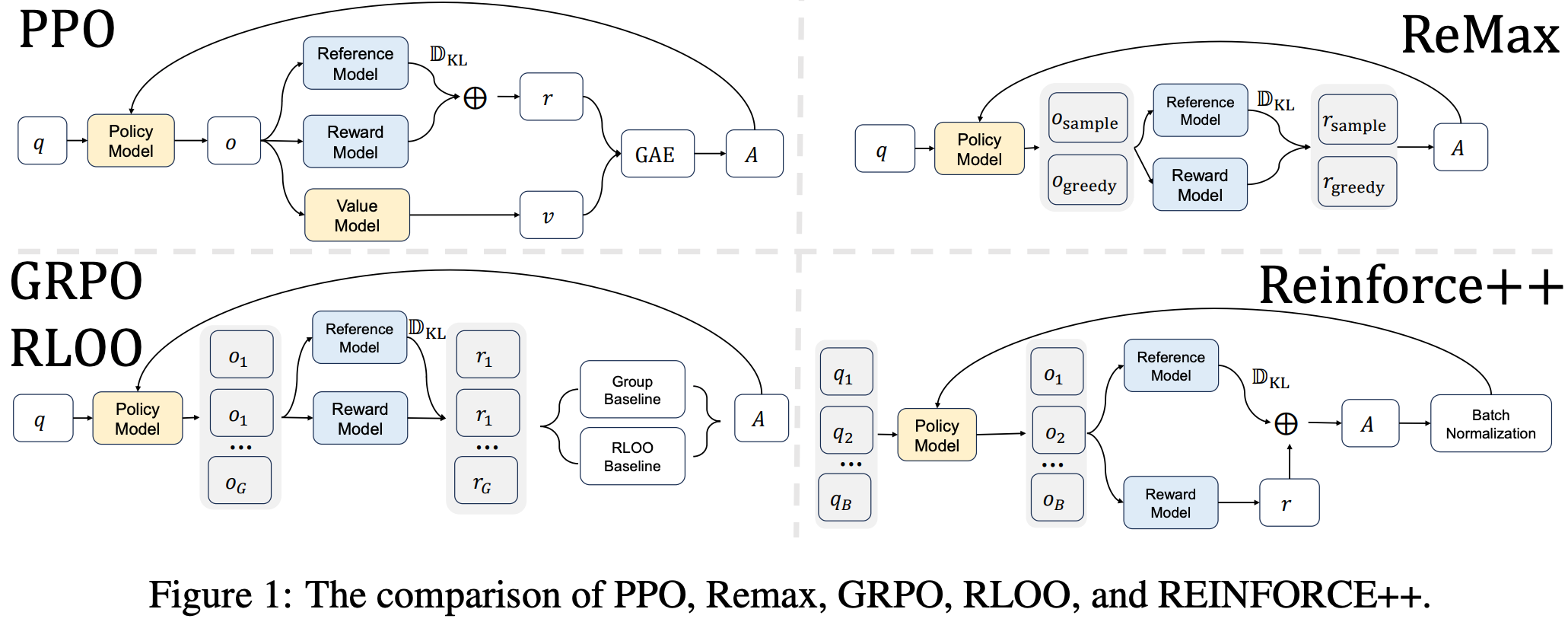
- 其他讨论:
- REINFORCE++ 使用的是 k2 KL 散度估计而不是 k3,论文参考了博客 Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization 中的内容
ReMax
- 参考链接:ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models, 2023, ICML 2024, 香港中文大学,南京大学
- 本质是 REINFORCE 方法
- 使用当前策略下每个状态下概率最高的动作对应的样本的奖励作为基线(每一步都贪心决策)
- 注意:概率最高的动作会持续走到最后直到拿到一个完整的 rollout,再来计算奖励
- 注意:与 GRPO 和 RLOO 不同,每次仅采样两个样本(其中一个是目标样本,另一个是贪心决策的样本)
- ReMax 在 RLOO 之前一点点提出,算是并行的工作
1
2
3
4
5
6
7
8
9
10# Algorithm 1: ReMax for Aligning LLMs
1 Input: reward_model(rm), language_model(lm)
2 for prompt in datasets:
3 seq=lm.sample(prompt, greedy=False)
4 seq_max=lm.sample(prompt, greedy=True)
5 rew=rm(prompt, seq)−rm(prompt, seq_max)
6 logp=lm.inference(prompt, seq)
7 loss=−(logp.sum(dim=−1)*rew).mean()
8 lm.minimize(loss)
9 Output: language_model
GRPO(Group Relative Policy Optimization)
- 每次生成一组样本,并对这组样本进行归一化
- 具体公式:
$$
\begin{split}
\mathcal{J}_{GRPO}(\theta)&=\mathbb{E}_{q\sim p(Q),\{\mathbf{o}_i\}_{i=1}^{G}\sim\pi_{\theta_{old}}(O|q)}\\
&\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|\mathbf{o}_i|}\sum_{t=1}^{|o_{t}|}\left\{\min\left[\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})}\hat{A}_{i,t},\text{clip}\left(\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})},1-\epsilon,1+\epsilon\right)\hat{A}_{i,t}\right]-\beta\text{D}_{\text{KL}}\left[\pi_{\theta}||\pi_{ref}|\right) \right\},
\end{split}
$$- 其中 \(\hat{A}_{i,t}\) 的计算方式为在同一个 Query 采样的多个 Response 内部做归一化:
$$\hat{A}_{i,t}=\overline{r}_{i}=\frac{r_{i}-\text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})}$$
- 其中 \(\hat{A}_{i,t}\) 的计算方式为在同一个 Query 采样的多个 Response 内部做归一化:
RLOO(REINFORCE Leave-One-Out)
- 参考链接:LLM RLHF 2024论文(四)RLOO - sanmuyang的文章 - 知乎
- 类似于 GRPO(发表时间也类似),每次生成一组样本
- 与 GRPO 的主要区别是:减去的是其他样本(不包含当前样本)的均值,且没有除以方差
- RLOO 没有使用限制 KL 散度约束?
DPO(Direct Preference Optimization)
- DPO 及其相关改进参见 NLP——LLM对齐微调-DPO 和 NLP——LLM对齐微调-DPO相关改进
- DPO 目标:
$$\mathcal{L}_{\text{DPO} }(\pi_{\theta};\pi_{\text{ref} })=-\mathbb{E}_{(x,y_{w},y_ {l})\sim\mathcal{D} }\bigg{[}\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_{w} \mid x)}{\pi_{\text{ref} }(y_{w} \mid x)}-\beta\log\frac{\pi_{\theta}(y_{l} \mid x)}{\pi_{\text{ref} }(y_{l} \mid x)}\right)\bigg{]}. \tag{7}$$ - DPO 梯度:关于参数 \(\theta\) 的梯度可以写成:
$$\nabla_{\theta}\mathcal{L}_{\text{DPO} }(\pi_{\theta};\pi_{\text{ref } })=\ -\beta\mathbb{E}_{(x,y_{w},y_{l})\sim\mathcal{D} }\bigg{[}\underbrace{\sigma(\hat{r}_{\theta}(x,y_{l})-\hat{r}_{\theta}(x,y_{w}))}_{\text{higher weight when reward estimate is wrong} }\quad\bigg{[}\underbrace{\nabla_{\theta}\log\pi(y_{w} \mid x)}_{\text{increase likelihood of } y_{w}}-\underbrace{\nabla_{\theta}\log\pi (y_{l} \mid x)}_{\text{decrease likelihood of } y_{l} }\bigg{]}\bigg{]}$$- 其中 \(\hat{r}_{\theta}(x,y)=\beta\log\frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)}\) 是由语言模型 \(\pi_{\theta}\) 和参考模型 \(\pi_{\text{ref} }\) 隐式定义的奖励(更多内容在第 5 节)
- 直观地说:损失函数 \(\mathcal{L}_{\text{DPO} }\) 的梯度增加了优选补全 \(y_{w}\) 的似然,并降低了非优选补全 \(y_{l}\) 的似然
- 样本的权重由隐式奖励模型 \(\hat{r}_{\theta}\) 对非优选补全评分高出多少来衡量,按 \(\beta\) 缩放,即隐式奖励模型对补全排序的错误程度,同时考虑了 KL 约束的强度
- 论文的实验表明了这种加权的重要性,因为没有加权系数的朴素版本的方法会导致语言模型退化(附录表 3)
RAFT(Reward rAnked FineTuning)
- RAFT,即 Reward rAnked FineTuning,出自 Raft: Reward ranked finetuning for generative foundation model alignment, 2023.
- RAFT 是 RL-free 方法,其核心步骤包括:
- 数据收集:可以利用正在训练的生成模型、预训练模型或它们的混合模型作为生成器,提升数据生成的多样性和质量
- 数据排序:利用与目标需求对齐的分类器或者回归器,筛选出最符合人类需求的样本
- 模型微调:利用筛选出的样本对模型进行微调,使训练后的模型与人类需求相匹配
RAHF(Representation Alignment from Human Feedback)
- (RAHF)Aligning Large Language Models with Human Preferences through Representation Engineering, 2024, Fudan
- RAHF(Representation Alignment from Human Feedback)的训练流程聚焦于通过表示工程实现大语言模型与人类偏好的对齐,整体方法描述如下
步骤一:指导LLM理解人类偏好
- 单模型对比指令微调(RAHF-SCIT) (Single Large Language Model through Contrastive Instruction Tuning (SCIT))
- 使用对比指令(如“生成受人类偏好的响应”和“生成不受人类偏好的响应”)对单个LLM进行微调
- 训练目标:通过最小化损失函数,使模型在给定正偏好指令时提高生成偏好响应的概率,给定负偏好指令时降低该概率
- 优势:通过同一模型学习偏好与非偏好的差异,避免特征空间不一致问题
- 双模型监督训练(RAHF-Dual)
- 分别微调两个LLM:
- 偏好模型 :使用偏好响应数据进行监督训练,学习生成符合人类偏好的输出
- 非偏好模型 :使用非偏好响应数据训练,学习生成不符合偏好的输出
- 特点:通过不同模型分别捕捉偏好与非偏好的表征,但需注意双模型特征空间可能存在的偏差
- 分别微调两个LLM:
步骤二:收集模型 Activity Pattern
- 输入处理 :将查询-响应对与偏好/非偏好指令拼接,输入模型以获取中间层隐藏状态(即内部表征)。为确保长度一致,对指令和响应进行 padding 处理
- 差异向量计算 :提取偏好刺激(\(A_{p^{+}, \pi, l}\))和非偏好刺激(\(A_{p^{-}, \pi, l}\))下的隐藏状态,计算差值 \(v_l = A_{p^{+}, \pi, l} - A_{p^{-}, \pi, l}\),该向量表征人类偏好相关的 Activity Pattern 差异
步骤三:构建最终对齐模型
- LoRA适配器微调 :利用低秩适配器(LoRA)拟合差异向量 \(v_l\),通过均方误差(MSE)损失函数将差异向量融入模型表征:
$$
\mathcal{L}_{Align} = \left| A_{p, \pi_{LoRA}, l} - (A_{p, \pi_{base}, l} + \alpha v_l) \right|_2
$$
其中 \(\alpha\) 控制差异向量的干预强度,通过调整该超参数平衡模型原始能力与偏好对齐效果 - 目标层选择 :优先选择模型中间层(如LLaMA2-7B的第10、20层)进行操作,因中间层更易捕捉与偏好相关的全局表征,避免顶层任务特异性或底层表征不完整的问题
SimpleRL
- 原始论文:SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild, HKUST & TikTok Meituan, 20250524 & 202508076
- 没有提出新的方法,就是原始的 GRPO 方法,但是对 GRPO 方法进行了微调
- 与 DAPO 类似,SimpleRL 将 GRPO 公式中的长度归一化挪到更外层的循环中去
- SimpleRL 这篇论文提出了适用于多种开源基础模型的 Zero RL 训练方法
- 注:Zero RL:指直接基于基础模型训练的方法,这种方法不依赖 SFT
- SimpleRL 的贡献在于通过优化奖励设计、数据难度匹配等关键策略,实现 Zero RL 训练方法下推理能力提升
- 具体设计:
- 训练方法:直接从基础模型出发进行强化学习,不进行任何前置的 SFT,采用GRPO算法作为训练核心,仅依赖基于正确性的规则奖励和简单训练设置
- 关键训练组件
- 算法:采用移除目标函数中长度归一化的 GRPO 算法,优化计算效率,无需单独价值模型,直接通过组归一化奖励估计优势函数
- 奖励函数:仅基于答案正确性设计,正确答案奖励+1,错误奖励0,摒弃严格格式奖励(如强制答案入盒),避免限制模型探索
- 数据处理:将 GSM8K 和 MATH 数据集按难度分为 Easy(GSM8K+MATH lv.1)、Medium(MATH lv.1-4)、Hard(MATH lv.3-5)三类,每类含约 8000 个样本,根据模型能力匹配对应难度数据
- 模型与 Prompt:覆盖 10 种不同家族和规模的模型(Llama3-8B、Mistral 系列、Qwen2.5 系列等),对指令跟随能力弱的模型采用简单提示(仅要求分步推理),能力强的模型采用复杂提示
- 对 GRPO 目标函数作为微小修改(实际上这种改法与 DAPO 一致)
$$
\mathcal{J}_{\text{GRPO}}(\theta)=\underbrace{\frac{1}{\color{red}{\sum_{i=1}^{G}\left|o_{i}\right|}} \color{red}{\sum_{i=1}^{G} \sum_{t=1}^{\left|o_{i}\right|}} min \left[r_{i, t}(\theta) \hat{A}_{i}, clip\left(r_{i, t}(\theta) ; 1-\epsilon, 1+\epsilon\right) \hat{A}_{i}\right]}_{\text{Clipped policy update } }-\underbrace{\beta \mathbb{D}_{KL}\left[\pi_{\theta} | \pi_{ref }\right]}_{\text{KL penalty } }
$$- 理解:这样可以消除长度归一化对模型响应长度的不当约束,更贴合 Zero RL 训练中“鼓励模型自由探索合理推理长度”的需求
- 总结思考: SimpleRL 关键优化策略
- 1)摒弃刚性格式奖励,优先保证响应可验证性,避免抑制模型探索
- 2)严格匹配训练数据难度与模型固有能力,难度不匹配会导致训练崩溃或效果不佳
- 3)调整探索相关超参数:采用较大采样量(N≥8)和合适温度(训练温度 1.0-1.2),稳定训练过程
- 4)避免传统 SFT 冷启动:传统 SFT 会限制模型探索能力,降低RL阶段的推理行为涌现潜力
SEED-GRPO(Semantic Entropy EnhanceD GRPO)
DAPO
- 在 GRPO 的基础上提出四个改进:
- 提升上界
- 动态过滤(全对或全错的)
- 损失平均方式:Sequence 内部的 Token Loss 平均 -> 批次粒度的 Token Loss 平均
- 长度惩罚(
[0;L_max - L_cache;L_max;+inf],在[L_max - L_cache;L_max]长度区间内,使用逐步增大惩罚,超过L_max部分,固定惩罚)
VAPO(Value-model-based Augmented Proximal Policy Optimization)
- VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, arXiv 202504, ByteDance Seed
- 字节 Seed 团队的作品,是对 DAPO 的进一步改进
- 在 DAPO 的基础上,增加了:
- Value Pretraining
- Decoupled-GAE,即 \(\lambda_\text{critic} = 1.0\),\(\lambda_\text{actor} = 0.95\)
- 长度自适应的 GAE
VC-PPO(Value-Calibrated PPO)
- (VC-PPO)What’s Behind PPO’s Collapse in Long-CoT? Value Optimization Holds the Secret, arXiv 20250303, ByteDance Seed
- 核心贡献:
- Pretrained value:开始 RL 前先预训练价值网络
- Decoupled-GAE:计算 Advantage (for Actor 损失)时和 计算 Target Reward(for Critic 损失)时使用不同的 \(\lambda\)
ORZ(Open-Reasoner-Zero)
- 原始论文:Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model, arXiv 20250401, StepFun & THU
- 第一个开源的 LLM 上面向推理的 zero RL 实现(即从 Base Model 直接进入 RL)
- 相关链接
- 效果:
- ORZ-32B 在 GPQA Diamond 基准上优于 DeepSeek-R1-Zero-Qwen-32B,训练步骤仅为其 1/30
- ORZ-32B 在 AIME 2024 上获得 48.1分(同 Size 模型上,后来字节的 VAPO 做到了 60分)
- ORZ-7B 做到了 17.9 分
- 注:包含很多训练经验,值得一看
GVPO(Group Variance Policy Optimization)
- 原始论文:GVPO: Group Variance Policy Optimization for Large Language Model Post-Training, arXiv 20250319, HKUST
- 核心贡献:
- GVPO 推到了一个 RL 约束优化问题的唯一最优解
- 提出一种灵活的采样分布避免了 on-policy 和 重要性采样
- 结果:用 Qwen-7B 模型为基线,在 AIME 2024 上,做到了 20.72分(注:比 ORZ 和 GRPO 等都高)
GPG(Group Policy Gradient)
- 原始论文:GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning, arXiv 20250501, AMAP Alibaba:AMAP是高德地图的简称
- 效果明显优于 GRPO
- GPG 方法的特点:移除所有花里胡哨的组件(问题:效果真的好吗?)

- GPG 方法的训练算法:

- 各种方法的损失函数比较:

- 补充趣事:GPG 对 Dr.GRPO 的批判:
In addition to these methods to improve efficiency and stability, a very recent and concurrent work Dr.GRPO [31] studies the details of reward and loss normalization and states GRPO tends to generate more tokens. However, although it reveals the reward bias in the advantage function, we observe that its performance did not significantly outperform GRPO.
ORPO(Odds Ratio Preference Optimization)
- 原始论文:ORPO: Monolithic Preference Optimization without Reference Model, arXiv 20240314, KAIST AI:截止到 20250616 日,cited by 244
- 注:KAIST AI 是韩国科学技术院(KAIST)的一个机构
- 核心思路:
- 偏好对齐的同时考虑 SFT 损失
ECPO(Early Clipped GRPO)
- 来源于快手的 OneREc OneRec Technical Report,用于 LLM4Rec 领域的偏好对齐
- 具体来说,对于用户 \( u \),论文使用旧策略模型生成 \( G \) 个物品。每个物品与用户一起输入偏好奖励模型,得到 P-Score 作为奖励 \( r_i \)。优化目标如下:
$$
\mathcal{J}_{\text{ECPO}}(\theta) = \mathbb{E}_{u \sim P(U), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old} } } \left[ \frac{1}{G} \sum_{i=1}^G \min \left( \frac{\pi_\theta(o_i|u)}{\color{red}{\pi’_{\theta_{old} }}(o_i|u)} A_i, \text{clip} \left( \frac{\pi_\theta(o_i|u)}{\color{red}{\pi’_{\theta_{old}} }(o_i|u)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right) \right], \\
A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \ldots, r_G\})}{\text{std}(\{r_1, r_2, \ldots, r_G\})},\\
\color{red}{\pi’_{\theta_{old} }(o_i|u) = \max \left( \frac{\text{sg}(\pi_\theta(o_i|u))}{1 + \epsilon + \delta}, \pi_{\theta_{old} }(o_i|u) \right), \quad \delta > 0,}
$$- \(\text{sg}\) 表示停止梯度操作(stop gradient operation)
- \(\delta\) 是一个大于 0 的超参数
- ECPO 对 GRPO(Group Policy Relative Optimization)(2024) 进行了修改,使其训练过程更加稳定
- 如图 6 所示,在原始 GRPO 中,允许负优势(negative advantages)的策略比率(\(\pi_\theta / \pi_{\theta_{old} }\))较大,这容易导致梯度爆炸
- 因此,论文预先对具有较大比率的策略进行截断,以确保训练稳定性,同时仍允许相应的负优势生效
- \(\delta\) 越大,可容忍的策略比率越大,意味着可容忍的梯度越大,这可以根据实际需求确定
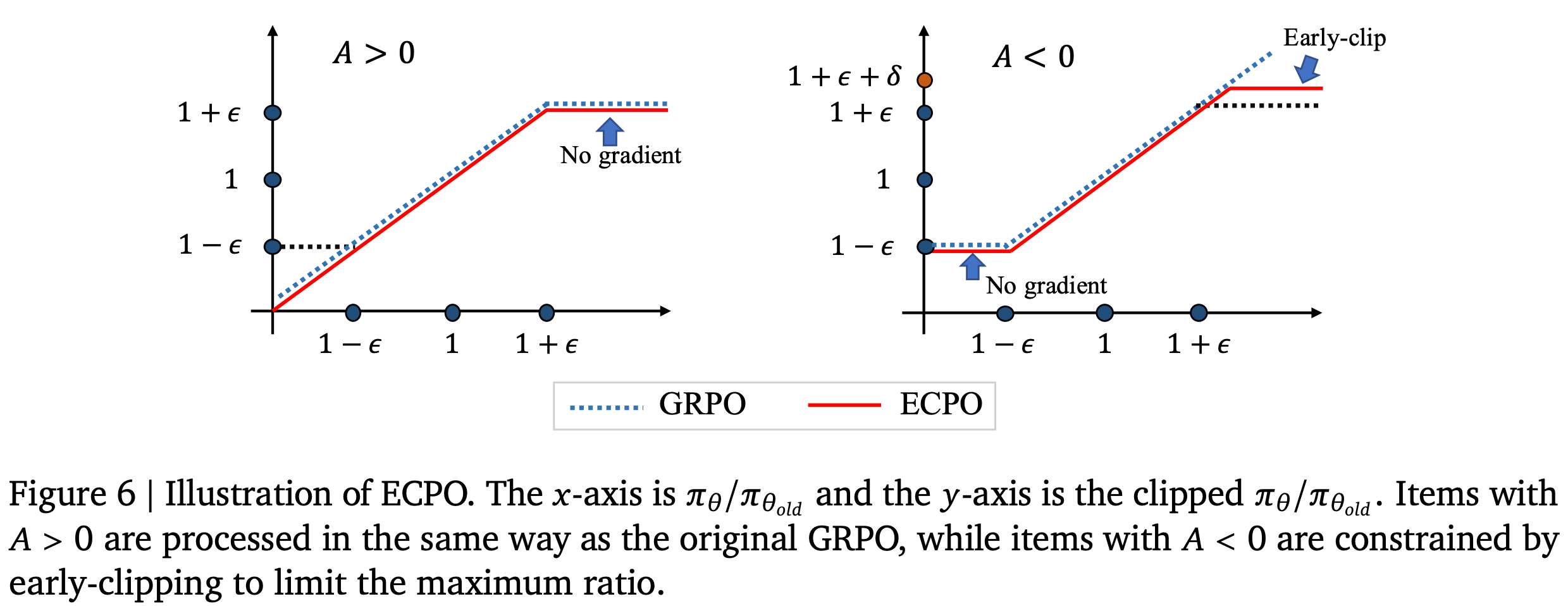
- 在 OneRec 中,论文将 \(\delta\) 设为 0.1,表示允许负优势的策略比率略微超过 \(1 + \epsilon\)
CISPO(Clipped IS-weight Policy Optimization)
- 原始论文:MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention, arXiv 20250616, MiniMax
- 名字说明:Clipped IS-weight Policy Optimization 中 IS 表示 Importance Sampling
- 效果:相对 DAPO,实现两倍加速
- 核心思路:不再裁剪 token 更新(影响是否反传梯度),而是裁剪重要性采样权重
- 注:思路和最近的 ECPO 有点相近
- 理解:这种做法是不对的,相当于忽略了 PPO 本身的优势
- CISPO 目标函数:
$$
\mathcal{J}_{\text{CISPO} }(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},\{o_i\}_{i=1}^G\sim\pi_{\theta_{\text{old} } }(\cdot|q)} \left[\frac{1}{\sum_{i=1}^G |o_i|} \sum_{i=1}^G \sum_{t=1}^{|o_i|} \mathbf{sg}(\hat{r}_{i,t}(\theta))\hat{A}_{i,t}\log\pi_\theta(o_{i,t} \mid q,o_{i,<t})\right], \tag{4}
$$- 其中 \(\hat{r}_{i,t}(\theta)\) 是裁剪后的重要性采样权重:
$$
\hat{r}_{i,t}(\theta) = \text{clip}\left(r_{i,t}(\theta),1-\epsilon_{low}^{IS},1+\epsilon_{high}^{IS}\right).
$$ - 优势计算与 GRPO 一致:
$$
\hat{A}_{i,t} = \frac{R_i - \text{mean}(\{R_j\}_{j=1}^G)}{\text{std}(\{R_j\}_{j=1}^G)},
$$- \(R_i\) 是响应的奖励,每个问题采样 \(G\) 个响应 \(\{o_i\}_{i=1}^G\)
- 其中 \(\hat{r}_{i,t}(\theta)\) 是裁剪后的重要性采样权重:
Efficient RL Scaling with CISPO
Background
- 对于数据集 \(\mathcal{D}\) 中的问题 \(q\),论文将策略模型表示为参数化的 \(\pi_\theta\),生成的响应为 \(o\)。PPO(2017)采用以下目标函数来优化策略以最大化预期回报,并通过裁剪操作稳定训练:
$$
\mathcal{J}_{\text{PPO} }(\theta) = \mathbb{E}_{q\sim\mathcal{D},o_i\sim\pi_{\theta_{\text{old} } }(\cdot|q)} \left[\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\min\left(r_{i,t}(\theta)\hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta),1-\epsilon,1+\epsilon)\hat{A}_{i,t}\right) - \beta D_{KL}(\pi_\theta||\pi_{\text{ref} })\right],
$$- 其中 \(r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t}|q,o_{i,< t})} {\pi_{\theta_{\text{old} } } (o_{i,t}|q,o_{i, < t})}\) 是重要性采样权重(Importance Sampling, IS),用于在 Off-policy 更新时校正分布
- PPO 需要一个单独的价值模型来计算优势 \(\hat{A}_{i,t}\),GRPO(2024)则通过将优势定义为响应组内相对奖励来消除价值模型:
$$
\hat{A}_{i,t} = \frac{R_i - \text{mean}(\{R_j\}_{j=1}^G)}{\text{std}(\{R_j\}_{j=1}^G)},
$$- 其中 \(R_i\) 是响应的奖励,每个问题采样 \(G\) 个响应 \(\{o_i\}_{i=1}^G\)
- 奖励可以来自基于规则的验证器(如数学问题求解)或奖励模型
- 对比,回顾带有校正分布(重要性采样)的原始 REINFORCE 目标函数 :
$$
\mathcal{J}_{\text{REINFORCE} }(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},o_t\sim\pi_{\theta_{\text{old} } }(\cdot|q)} \left[\frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \mathbf{sg}(r_{i,t}(\theta))\hat{A}_{i,t}\log\pi_\theta(o_{i,t} \mid q,o_{i,<t})\right], \tag{3}
$$ - GISPO 的本质 是:基于组计算 Advantage 的(类似GRPO),带重要性采样的(可 Off-policy 更新的)REINFORCE 方法
GPPO(Gradient-Preserving Clipping Policy Optimization)
- Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization, Klear, arXiv 20250812
- Hugging Face地址:https://huggingface.co/Suu/Klear-Reasoner-8B
- GitHub 地址:https://github.com/suu990901/KlearReasoner/tree/main
- GPPO 方法用于解决传统强化学习(如PPO、GRPO)中的剪辑机制(Clipping)存在两个关键问题:
- 高熵token梯度被抑制 :超出上阈值(\(1+\epsilon\))的高熵 token(对应关键探索行为)的梯度被直接丢弃,限制模型探索能力
- 负样本收敛延迟 :低于下阈值(\(1-\epsilon\))的次优轨迹梯度被截断,导致模型难以从负样本中学习,收敛速度减慢
- GPPO 不丢弃任何token的梯度,即使是超出剪辑范围的 token,其梯度也会被纳入反向传播计算图。通过有界且温和的梯度传播 ,平衡训练稳定性与有价值梯度信息的保留:
- 对高熵token(超出上阈值),保留其梯度以增强探索;
- 对次优轨迹(低于下阈值),保留其梯度以加速负样本学习
- GPPO 的优势:
- 增强探索能力 :保留高熵token的梯度,避免过早终止探索;
- 加速负样本学习 :利用次优轨迹的梯度,减少重复采样,加快收敛;
- 稳定训练 :通过有界梯度控制,避免梯度爆炸,维持训练稳定性
- 实验表明,GPPO 在数学(AIME)和编程(LiveCodeBench)任务上的性能优于传统剪辑方法(如 GRPO w/ Clip-Higher)和并发方法(如 CISPO)
- GPPO 损失函数(基于 GRPO 的 token-level 损失修改而来),公式如下:
$$\mathcal{L}^{GPPO}(\theta)=\mathbb{E}_{x \sim \mathcal{D}}\left[\frac{1}{\sum_{j=1}^{M} T_{j}} \sum_{j=1}^{M} \sum_{t=1}^{T_{j}} min \left(\delta \tilde{A}^{(j)}, clip\left(\delta, \frac{1-\epsilon_{l}}{sg(\delta)} \delta, \frac{1+\epsilon_{h}}{sg(\delta)} \delta\right) \overline{A}^{(j)}\right)\right]$$- \(\delta = r_{t}^{(j)}(\theta)\) :token 级重要性采样比(当前策略与旧策略的概率比);
- \(sg(\cdot)\) :停止梯度(stop-gradient)操作,确保 \(\frac{\delta}{sg(\delta)}\) 数值上恒为1,前向计算不变;
- \(\epsilon_l, \epsilon_h\) :剪辑的下、上阈值(如 \(\epsilon_l=0.2, \epsilon_h=0.28\));
- \(\tilde{A}^{(j)}\) :组相对优势(group-relative advantage),通过组内奖励标准化计算;
- \(\sum_{j=1}^{M} T_j\) :所有token的总长度,用于归一化
- GPPO 梯度表达式,(梯度计算保留所有 token 的贡献),公式如下:
$$\nabla_{\theta} \mathcal{L}^{GPPO}(\theta) = \mathbb{E}_{x \sim \mathcal{D}}\left[\frac{1}{\sum_{j=1}^{M} T_{j}} \sum_{j=1}^{M} \sum_{t=1}^{T_{j}} \mathcal{F}_{j, t}(\theta) \cdot \phi_{\theta}\left(a_{j, t}, s_{j, t}\right) \cdot \tilde{A}^{(j)}\right]$$- 其中,\(\mathcal{F}_{j, t}(\theta)\)(梯度权重函数)定义为:
$$\mathcal{F}_{j, t}(\theta) = \begin{cases}
1-\epsilon_{l} & \text{if } \delta<1-\epsilon_{l} \text{ and } \tilde{A}^{(j)}<0, \\
1+\epsilon_{h} & \text{if } \delta>1+\epsilon_{h} \text{ and } \tilde{A}^{(j)}>0, \\
\delta & \text{otherwise}
\end{cases}$$ - \(\phi_{\theta}(a_{j,t}, s_{j,t})\) :策略网络输出的 logits 关于参数 \(\theta\) 的导数(减去基线项);
- 当 \(\delta\) 超出剪辑范围时,\(\mathcal{F}_{j,t}(\theta)\) 被约束为 \(1-\epsilon_l\) 或 \(1+\epsilon_h\),确保梯度有界;
- 当 \(\delta\) 在范围内时,直接使用 \(\delta\),保留原始梯度
- 其中,\(\mathcal{F}_{j, t}(\theta)\)(梯度权重函数)定义为:
Reflect-Retry-Reward
- 原始论文:Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning, 20250530, Writer,Writer 是一家美国 AI 公司
- Reflect-Retry-Reward 机制的基本框架:
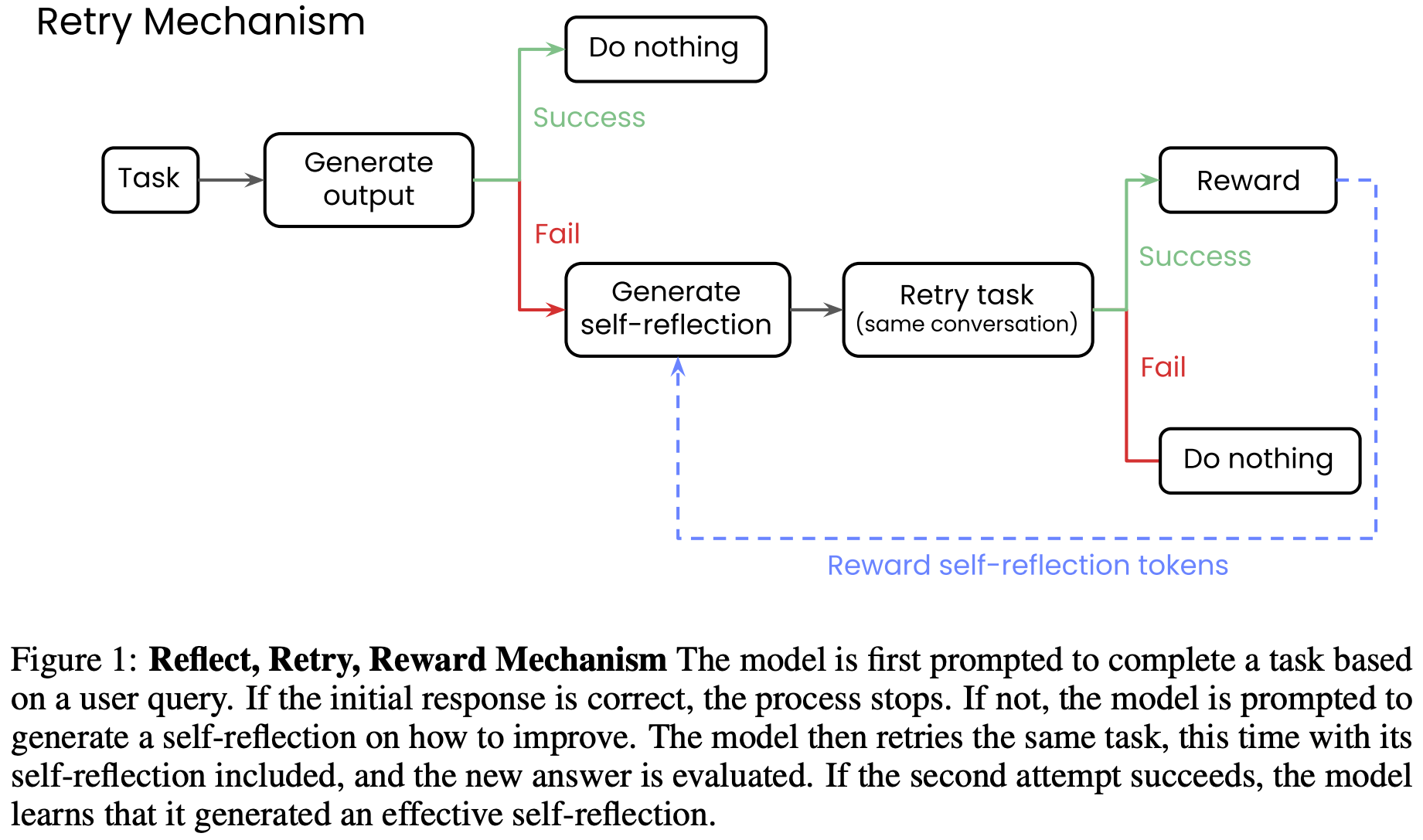
- 基本流程:
- 第一次生成结果
- 如果成功则不进行任何训练
- 如果失败则生成 Self-reflection token,重新将带着 Self-reflection token 的任务继续输入模型
- 第二次生成结果
- 如果成功则进行训练,并对刚刚 Self-reflection token 增加赋予奖励?
- 如果失败则不进行训练?
- 第一次生成结果
DFT(Dynamic Fine-Tuning)
- 今天在损失函数上添加一个权重,将 SFT 的损失函数对齐 RLHF
- 不能做到像 RL 一样探索,但是能尽量让 SFT 的损失函数贴近 RL
- 注意:
- SFT 的原始目标是最大化专家数据集的似然函数,故而其极大似然法推导出来的损失交(即叉熵损失)
- 经过修改以后,SFT 的损失函数已经不太能说得上其含义了,目标是最大化专家数据对应的奖励?
iw-SFT(Importance Weighted Supervised Fine-tuning)
- iw-SFT 是 Importance weighted supervised fine-tuning,详情见论文:Supervised Fine Tuning on Curated Data is Reinforcement Learning (and can be improved), 20250717
- 待补充
CHORD(Controllable Harmonization of On-and Off-Policy Reinforcement Learning via Dynamic Weighting)
- 原始论文:(CHORD)On-Policy RL Meets Off-Policy Experts: Harmonizing Supervised Fine-Tuning and Reinforcement Learning via Dynamic Weighting, arXiv 20250815, Alibaba Group
- 解读博客:【千问大模型官方】先SFT后RL但是效果不佳?你可能没用好“离线专家数据”!
- CHORD(Controllable Harmonization of On-and Off-Policy Reinforcement Learning via Dynamic Weighting)是一种结合了 RL 和 SFT 的方法,可以在 Token 粒度上识别重要性,从而调整学习损失函数或权重
- CHORD 提出了思路相似的两种变体 CHORD-\(\mu\) 和 CHORD-\(\phi\),实验结果如下:
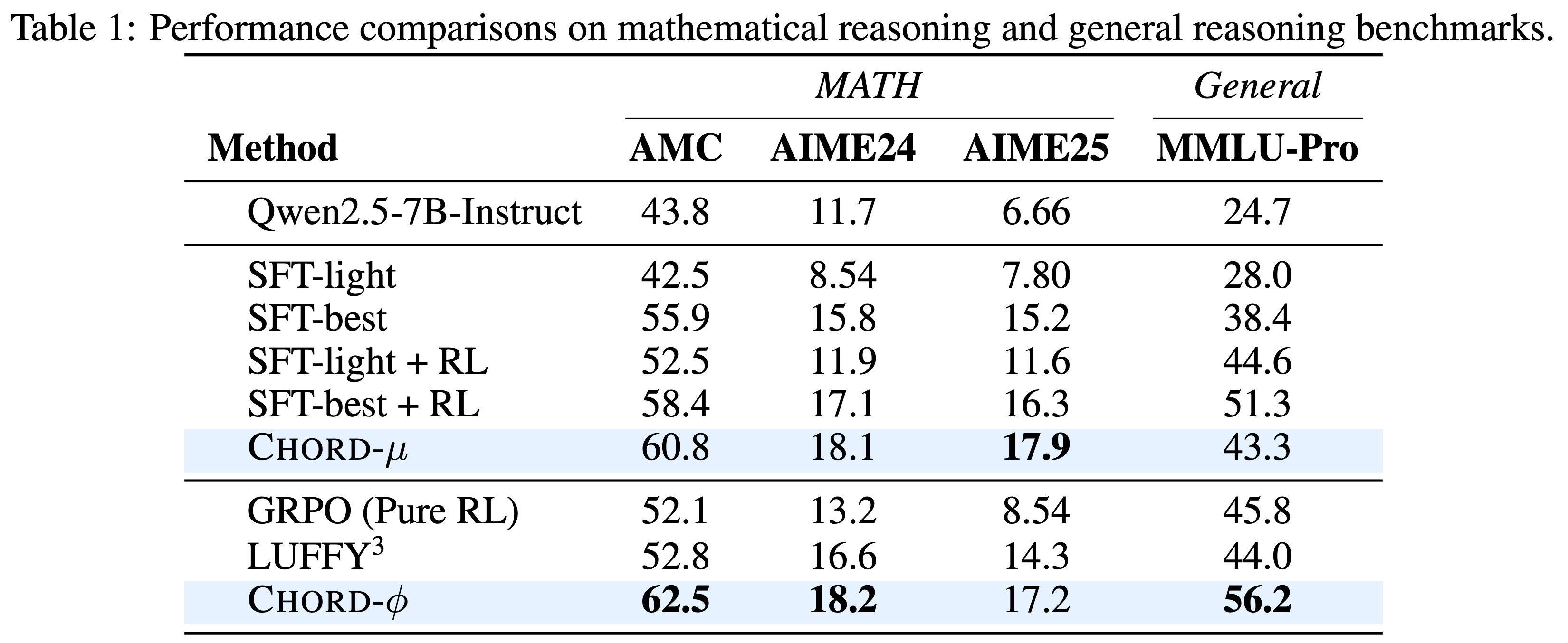
CHORD-\(\mu\)
- CHORD-\(\mu\) 通过动态调整全局系数 \(\mu\) 来平衡 off-policy 专家数据(SFT 损失)和 on-policy 探索(GRPO 损失)的影响,其混合损失函数表达式为:
$$
\mathcal{L}_{\text{Hybrid}}(\theta) = (1-\mu) \mathcal{L}_{\text{GRPO}}(\theta) + \mu \mathcal{L}_{\text{SFT}}(\theta)
$$ - \(\mathcal{L}_{\text{GRPO}}(\theta)\) 是基于 GRPO 的 RL 损失函数,定义为:
$$
\mathcal{L}_{\text{GRPO}}(\theta) = -\frac{1}{\sum_{i=1}^{\hat{B}} \sum_{k=1}^{K} |\tau_{i,k}|} \sum_{i=1}^{\hat{B}} \sum_{k=1}^{K} \sum_{t=1}^{|\tau_{i,k}|} \min\left(r_{i,k,t}(\theta) A_{i,k}, \text{clip}(r_{i,k,t}(\theta), 1-\epsilon, 1+\epsilon) A_{i,k}\right)
$$- 式中 \(r_{i,k,t}(\theta)\) 为 token-level 重要性采样比率,\(A_{i,k}\) 为优势值,\(\hat{B}\) 为批量提示数,\(K\) 为每个提示的候选响应数
- \(\mathcal{L}_{\text{SFT}}(\theta)\) 是监督微调损失函数,定义为:
$$
\mathcal{L}_{\text{SFT}}(\theta) = -\frac{1}{\sum_{i=1}^{B} |y_i^*|} \sum_{i=1}^{B} \sum_{t=1}^{|y_i^*|} \log \pi_{\theta}(y_{i,t}^* | x_i, y_{i,< t}^*)
$$- 式中 \(B\) 为批量大小,\(y_i^*\) 为专家响应序列,\(\pi_{\theta}\) 为模型策略
- \(\mu \in [0,1]\) 是动态衰减的全局系数 ,初始值较高(侧重 SFT),随训练逐步降低(侧重 RL)
CHORD-\(\phi\)
- CHORD-\(\phi\) 在 CHORD-\(\mu\) 的基础上引入 token-level 加权函数 \(\phi(\cdot)\),进一步细化对 off-policy 数据的控制,其损失函数表达式为:
$$
\mathcal{L}_{\text{Hybrid-}\phi}(\theta) = (1-\mu) \mathcal{L}_{\text{GRPO}}(\theta) + \mu \mathcal{L}_{\text{SFT-}\phi}(\theta)
$$ - \(\mathcal{L}_{\text{SFT-}\phi}(\theta)\) 是带 token 加权的 SFT 损失函数,定义为:
$$
\mathcal{L}_{\text{SFT-}\phi}(\theta) = -\mathbb{E}_{(x,y^*) \sim \mathcal{D}_{\text{SFT}}} \left[ \sum_{t=1}^{|y^*|} \phi(y_t^*; \pi_{\theta}) \cdot \log \pi_{\theta}(y_t^* | x, y_{<t}^*) \right]
$$ - 加权函数 \(\phi(y_t^*; \pi_{\theta})\) 基于模型对专家 token 的生成概率 \(p_t = \pi_{\theta}(y_t^* | x, y_{< t}^*)\) 定义为:
$$
\phi(y_t^*; \pi_{\theta}) = p_t (1 - p_t)
$$- 该函数呈抛物线形,在 \(p_t=0.5\) 时权重最大,对高概率(\(p_t \to 1\))和低概率(\(p_t \to 0\))的 token 均降权,平衡探索与稳定性
BAPO(Balanced Policy Optimization with Adaptive Clipping)
- 原始论文:BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMsvia Balanced Policy Optimization with Adaptive Clipping, 20251021, Fudan
- GitHub 链接:github.com/WooooDyy/BAPO
- BAPO 用于解决 Off-policy RL 训练中 “优化失衡(imbalance in optimization)” 和 “熵坍缩” 两大问题,通过动态调整裁剪边界实现正 / 负样本贡献平衡与熵保留,最终提升训练稳定性、数据效率与模型性能
- 优化失衡 :负优势样本(Advantage < 0)在策略梯度中占主导,抑制有效行为且易引发梯度爆炸;
- 熵坍缩 :PPO 类方法的固定对称裁剪机制会系统性阻断“熵增更新”(排除低概率正样本、过度惩罚低概率负样本),导致策略过度利用(Exploitation)而丧失探索能力(Exploration)
- 注:BAPO 是针对 PPO 进行改进的
- BAPO 上述问题,提出动态非对称裁剪机制 ,核心目标是:
- 平衡正/负样本对损失的贡献;
- 保留低概率正样本以维持熵,过滤过度负样本以避免梯度爆炸;
- 无需复杂手动调参,适配不同离线场景(样本重放、部分轨迹生成、不同数据陈旧度)
- BAPO 核心优势
- 稳定性:在不同数据陈旧度(2×、4×)、部分轨迹生成场景下,训练奖励持续上升,熵保持稳定(无坍缩),梯度范数可控;
- 通用性:适配 DeepSeek-R1、Llama3.2 等不同底座模型,无需针对模型规模重新调参
- 注:论文中看起来得分似乎没有比 GRPO 高太多
BAPO 目标函数(动态裁剪改进)
- BAPO 保留 PPO 的“最小化裁剪项”结构,但将固定对称边界替换为动态非对称边界(\(c_{low}\) 为下边界,\(c_{high}\) 为上边界),目标函数为:
$$
J^{BAPO}(\theta) = \mathbb{E}_{y \sim \pi_{\theta_{rollout} }(\cdot | x)} \sum_{t=1}^{T} min\left(r_t \cdot A_t, clip\left(r_t, c_{low}, c_{high}\right) \cdot A_t\right)
$$- 其中,\(c_{low}\) 和 \(c_{high}\) 不再是固定值,而是通过每批次数据动态调整 ,核心约束是“正样本对策略梯度损失的贡献达到目标阈值 \(\rho_0\)”
- 注意:再次强调 BAPO 是针对 PPO 的改进
动态裁剪边界调整规则
- BAPO 每轮训练(Step)中,通过迭代调整 \(c_{low}\) 和 \(c_{high}\),满足“正样本贡献目标 \(\rho_0\)”,具体规则如下:
- (1)调整目标约束
- 设 \(\rho\) 为当前批次中正样本对策略梯度损失的实际贡献占比,需满足:
$$
\rho \geq \rho_0
$$- 其中 \(\rho_0\) 为预设目标(实验中设为 0.4),确保正样本不被负样本压制
- 理解:在 BAPO 论文中,当前批次中正样本对策略梯度损失的实际贡献占比 \(\rho\) 的评估方式,论文并未给出显式的计算公式 ,下面从其描述和算法目标中推导出清晰的评估逻辑
- 原论文(第6页,Equation 8)中,BAPO 的目标是找到一个 clipping 上下界 \((c_{\text{low} }, c_{\text{high} })\),使得:
$$
\frac{|\sum_{A_t > 0} \pi_{\theta_{\text{rollout} } }(y_t) \cdot [\min(r_t \cdot A_t, \text{clip}(r_t, 0, c_{\text{high} }) \cdot A_t)]|}
{|\sum_{A_t} \pi_{\theta_{\text{rollout} } }(y_t) \cdot [\min(r_t \cdot A_t, \text{clip}(r_t, c_{\text{low} }, c_{\text{high} }) \cdot A_t)]|} \geq \rho_0
$$- 其中 \(\rho_0\) 是目标正样本贡献比例(target contribution of positive signals),论文中设置为 \(0.4\)
- 注意:上面的分子分母都有绝对值
- 从上述不等式可以反推:
- 正样本贡献(分子):
$$
\text{PosContribution} = \left| \sum_{A_t > 0} \pi_{\theta_{\text{rollout} } }(y_t) \cdot \left[ \min\left(r_t \cdot A_t,; \text{clip}(r_t, 0, c_{\text{high} }) \cdot A_t\right) \right] \right|
$$- 注意:是基于 PPO 的损失函数,所以 Advantage 有正有负
- 总贡献(分母):
$$
\text{TotalContribution} = \left| \sum_{A_t} \pi_{\theta_{\text{rollout} } }(y_t) \cdot \left[ \min\left(r_t \cdot A_t,; \text{clip}(r_t, c_{\text{low} }, c_{\text{high} }) \cdot A_t\right) \right] \right|
$$- 注意:是基于 PPO 的损失函数,所以 Advantage 有正有负(即使样本为负样本时)
- 实际正样本贡献占比 为:
$$
\rho = \frac{\text{PosContribution} }{\text{TotalContribution} }
$$
- 正样本贡献(分子):
- 原论文(第6页,Equation 8)中,BAPO 的目标是找到一个 clipping 上下界 \((c_{\text{low} }, c_{\text{high} })\),使得:
- 设 \(\rho\) 为当前批次中正样本对策略梯度损失的实际贡献占比,需满足:
- (2)边界调整范围与步长
- 下边界 \(c_{low}\):取值范围 \([a^-, b^-]\)(实验中设为 [0.6, 0.9]),调整步长 \(\delta_2\)(实验中设为 0.02);
- 上边界 \(c_{high}\):取值范围 \([a^+, b^+]\)(实验中设为 [1.2, 3.0]),调整步长 \(\delta_1\)(实验中设为 0.05)
- (3)迭代调整逻辑
- 1)初始化:\(c_{low} = a^-\),\(c_{high} = a^+\);
- 2)若 \(\rho < \rho_0\) 且 \(c_{low} + \delta_2 \leq b^-\):
- 优先提升 \(c_{high}\)(若 \(c_{high} + \delta_1 \leq b^+\)),纳入更多低概率正样本(\(r_t\) 较大的正样本);
- 若 \(c_{high}\) 已达上限,则提升 \(c_{low}\),过滤更多过度负样本(\(r_t\) 过小的负样本);
- 3)重复步骤 2,直至 \(\rho \geq \rho_0\) 或边界达上限
一些关于熵的理论基础讨论
- BAPO 通过纳入低概率正样本维持熵,其理论基础是“熵-裁剪规则”(Entropy-Clip Rule):策略熵的变化由未裁剪样本的“对数概率与优势值的协方差”决定,公式推导如下(详细证明见附录 B):
$$
\Delta \mathcal{H}(\pi_{\theta} | x, y_{ < t}) \approx -\eta \cdot Cov_{y_t \sim \pi_{\theta} } \left( log \pi_{\theta}(y_t), A_t \cdot \mathcal{X}(y_t) \right) + C
$$ - 其中:
- \(\Delta \mathcal{H}\):策略熵的变化量;
- \(\eta\):学习率;
- \(\mathcal{X}(y_t)\):指示函数,\(\mathcal{X}(y_t)=1\) 表示样本未被裁剪,\(\mathcal{X}(y_t)=0\) 表示被裁剪;
- \(C\):与 \(y_t\) 无关的常数
- 关键结论:
- 低概率正样本(\(\pi_{\theta}(y_t) \to 0\),\(A_t > 0\))未被裁剪时,会增大协方差,进而提升熵;
- BAPO 动态提升 \(c_{high}\) 可纳入更多此类样本,避免熵坍缩
BAPO 训练流程:Algorithm 1
- BAPO 每轮训练包含“样本生成-动态裁剪-策略更新”三步,具体流程如下:
- 1)初始化输入:
- 初始 LLM 策略 \(\pi_{\theta}\)、训练数据集 \(\mathcal{D}\)、奖励函数 \(R\)、数据陈旧度上限 \(E\);
- 裁剪边界范围 \([a^-, b^-]\)(\(c_{low}\))和 \([a^+, b^+]\)(\(c_{high}\))、步长 \(\delta_1/\delta_2\)、正样本贡献阈值 \(\rho_0\)
- 2)样本生成与过滤(每轮 Step s):
- 更新行为策略:\(\pi_{\theta_{rollout} } \leftarrow \pi_{\theta}\);
- 从 \(\mathcal{D}\) 采样批次数据 \(\mathcal{D}_s\),基于 \(\pi_{\theta_{rollout} }\) 生成 G 条响应 \(y_i\);
- 计算每条响应的奖励(基于 \(R\))和优势值 \(A_t\)
- 3)动态调整裁剪边界(适配不同陈旧度):
- 初始化 \(c_{low} = a^-\),\(c_{high} = a^+\);
- 循环:若 \(\rho < \rho_0\) 且 \(c_{low} + \delta_2 \leq b^-\):
- 若 \(c_{high} + \delta_1 \leq b^+\),则 \(c_{high} \leftarrow c_{high} + \delta_1\);
- 否则,\(c_{low} \leftarrow c_{low} + \delta_2\)
- 4)策略更新:
- 通过最大化 \(J^{BAPO}(\theta)\) 更新 \(\pi_{\theta}\),完成一轮训练
Trianing-free GRPO
- 原始论文:Training-Free Group Relative Policy Optimization, 20251009, Tencent Youtu-Agent Team
- 亮点:不修改模型参数,仅通过改进上下文来提升模型推理能力
- Training-free GRPO 保留了传统 GRPO 的“多轮学习”框架,但将“参数更新”替换为“经验知识迭代优化”,核心流程可分为 4 步:
- 1)初始化:经验库与基础配置
- 初始化外部经验库 :存储领域相关的“语义优势知识”,初始为空或包含少量基础经验;
- 固定LLM参数:使用冻结的大模型(如 DeepSeek-V3.1-Terminus )作为基础策略,避免参数更新;
- 配置训练参数:仅需少量训练样本(如 100 个)、3-5轮迭代(epoch)、每组生成 5 个输出(group size=5)
- 2)Rollout 与奖励计算(复刻传统 GRPO):对每个查询(query)执行并行输出生成 :
- 基于当前经验库 \(\varepsilon\),让 LLM 生成一组输出(rollout,如 5 个不同推理轨迹),即策略 \(\pi_\theta(o_i | q, \varepsilon)\);
- 使用奖励模型(R)对每个输出 \(o_i\) 打分,得到 scalar reward \(r_i = R(q, o_i)\)(如数学推理的“答案正确性”、网页搜索的“任务完成率”)
- 3)群体语义优势计算(核心创新):传统 GRPO 通过数值优势( \(\hat{A}_i = \frac{r_i - mean(r)}{std(r)}\))指导参数更新,而Training-free GRPO 替换为语义优势(自然语言形式的经验知识),具体步骤:
- 轨迹总结 :用同一LLM对每个输出 \(o_i\) 生成结构化总结 \(s_i\),包含“推理步骤、工具使用、错误点(若有)”;
- 语义优势提炼 :基于总结 \(\{s_1,…,s_G\}\) 和当前经验库,让 LLM 分析“成功/失败原因”,提炼通用经验(如“几何题需验证解是否在边界内”),形成语义优势 \(A_{text}\);
- 筛选有效群体 :仅对“存在明显优劣差异”的群体(即 \(std(r) \neq 0\))提炼语义优势,避免无意义经验
- 4)经验库优化(无参数更新的“策略优化”):通过语义优势 \(A_{text}\) 迭代更新经验库,LLM 生成 4 类操作指令:
- Add(添加) :将新提炼的有效经验直接加入经验库;
- Delete(删除) :移除经验库中过时或低质量的经验;
- Modify(修改) :基于新经验优化现有经验的通用性(如扩展“几何题验证”到“代数题验证”);
- Keep(保留) :经验库无需调整时维持现状
- 更新后的经验库会作为“token 先验”注入下一轮 LLM 调用,引导模型输出向高奖励方向偏移,实现“参数冻结下的策略优化”
SRL(Supervised Reinforcement Learning)
- 原始论文:Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning, 20251029, Google Cloud AI Research, UCLA
- SRL 是一种针对复杂多步推理任务的 LLM 训练框架,核心是将问题拆解为序列决策过程,通过分步专家动作引导和密集奖励信号实现高效学习
- 用于弥补SFT(刚性逐 token 模仿易过拟合)和 RLVR(依赖最终结果奖励、稀疏信号难学难问题)的缺陷
- 核心思路是把专家解决方案分解为一系列“逻辑动作”,模型先生成内部推理独白,再输出每步动作,基于与专家动作的相似度获得分步奖励
整体流程概述
- 整体流程图
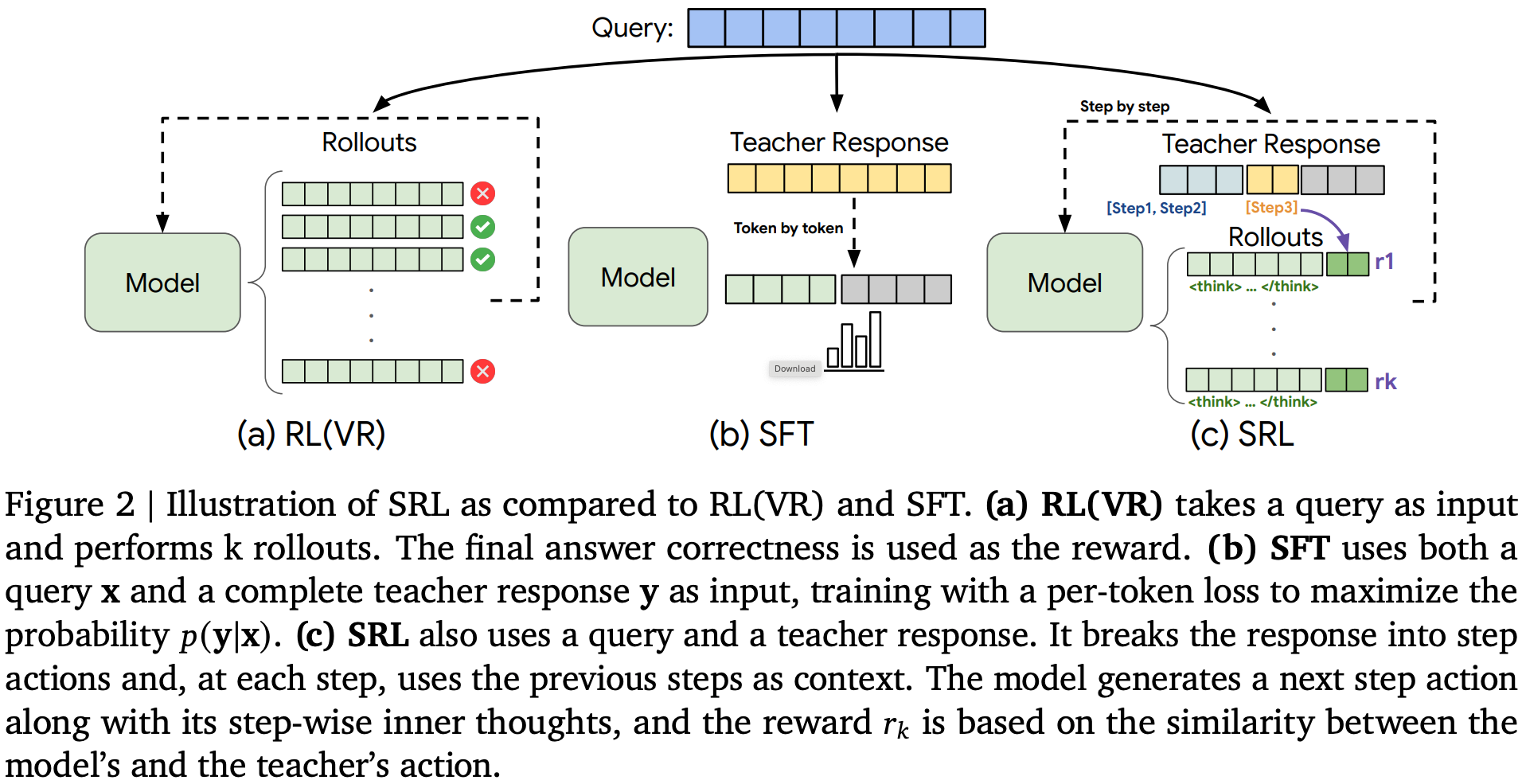

- 动作化问题构建
- 将专家(优秀的大模型)轨迹 \( \mathbf{y} \) 拆解为步骤动作序列 \( \mathbf{y} = \{\mathbf{y}_{\text{step}_n}\}_{n=1}^N \),每个动作代表一个有意义的决策步骤(如数学中的代数运算、软件任务中的命令执行)
- 构建分步训练数据:从单个专家解决方案生成 \( N-1 \) 个部分轨迹,输入提示 \( x_{\text{step}_k} = [x, \mathbf{y}_{\text{step}_1}, …, \mathbf{y}_{\text{step}_{k-1} }] \),目标是预测下一步动作 \( \mathbf{y}_{\text{step}_k} \)
- 分步推理与奖励计算
- 模型生成格式:
$$ \mathbf{y}’ \sim p_{\theta}(\cdot | x_{\text{step}_k}) = [\mathbf{y}_{think}’, \mathbf{y}_{\text{step}_k}’] $$- 其中 \( \mathbf{y}_{think}’ \) 是内部推理独白(用特定标签封装),\( \mathbf{y}_{\text{step}_k}’ \) 是预测动作
- 序列相似度奖励公式:
$$ R(\mathbf{y}_{\text{step}_k}’, \mathbf{y}_{\text{step}_k}) = \frac{2 \sum_{(i,j,n) \in \text{MatchingBlocks}} n}{|S_1| + |S_2|} $$- \( S_1 \) 为模型预测动作序列,\( S_2 \) 为专家动作序列
- \( \text{MatchingBlocks} \) 是两序列中非重叠匹配块的集合,\( n \) 为每个匹配块的长度
- 若输出格式错误,奖励为 -1,最终奖励范围 \( r \in [0,1] \cup \{-1\} \)
- 模型生成格式:
- 动态采样策略
- 过滤奖励方差接近零的样本,保留标准偏差超过阈值 \( \epsilon \) 的样本:
$$ \sqrt{\frac{\sum_{i=1}^G (r(o_i, \mathbf{y}) - \bar{r})^2}{G} } > \epsilon $$- \( G \) 为生成的轨迹数量,\( r(o_i, \mathbf{y}) \) 是第 \( i \) 条轨迹的奖励,\( \bar{r} \) 为样本平均奖励
- 过滤奖励方差接近零的样本,保留标准偏差超过阈值 \( \epsilon \) 的样本:
- 采用 GRPO 目标函数优化策略,仅基于逻辑动作计算奖励,不约束内部推理独白,兼顾动作一致性与推理灵活性
核心优势
- 密集奖励:即使所有轨迹均错误,仍能通过分步动作相似度提供有效学习信号
- 灵活推理:避免SFT的刚性模仿,允许模型发展自身推理风格
- 跨域通用:在数学推理和软件工程代理任务中均表现优异
性能表现
- 数学推理任务:在 AMC23、AIME24 等竞赛级基准上,SRL 平均性能超 SFT 和 RLVR,SRL+RLVR pipeline 实现最优(平均28.3%)
- 软件工程任务:在 SWE-Bench 上,Oracle 设置下 resolve rate 达 14.8%,较 SFT 基线提升 74%;端到端设置下性能翻倍
AWPO
- 原始论文:AWPO: Enhancing Tool-Use of Large Language Models through Explicit Integration of Reasoning Rewards
- AWPO(Advantage-Weighted Policy Optimization)是用于工具集成方向的 LLM,其核心思想是 通过显式地集成推理奖励(reasoning rewards)来提升模型在复杂任务中的推理和工具调用能力 ,同时避免与基于结果的奖励(outcome rewards)发生冲突
- 背景:
- 现有的基于 RL 的工具使用 LLM 训练方法通常仅依赖 可验证的结果奖励(如工具调用的格式正确性、执行结果匹配度),而 忽视了推理过程的质量(如逻辑连贯性、步骤合理性、工具选择恰当性)
- 若直接简单混合推理奖励与结果奖励可能导致:优化目标冲突、 训练不稳定、 性能提升有限 等问题
- AWPO 建立在 策略改进上界理论 之上,
核心:奖励设计与优势计算
- 结果奖励 \(R^{\text{out} }\) :基于规则计算,包括格式正确性(精确匹配)和执行正确性(工具名、参数名、参数值的相似度)
- 推理奖励 \(R^{\text{reasoning} }\) :由 LLM-as-a-Judge 模型评估生成推理链的逻辑连贯性、工具选择合理性、参数设置准确性等,得分范围 \([0, 1]\)
- 混合奖励 :
$$
R^{\text{mix} } = R^{\text{out} } + R^{\text{reasoning} }
$$ - 优势计算 :分别计算基于结果奖励和混合奖励的归一化优势:
$$
A^{\text{out} }_{g,j} = \frac{R^{\text{out} }_{g,j} - \bar{R}^{\text{out} }_{g} }{\widehat{\sigma}^{\text{out} }_{g} + \epsilon}, \quad
A^{\text{mix} }_{g,j} = \frac{R^{\text{mix} }_{g,j} - \bar{R}^{\text{mix} }_{g} }{\widehat{\sigma}^{\text{mix} }_{g} + \epsilon}
$$ - 最终加权优势 :结合门控权重与难度权重:
$$
A^{\text{hyper} }_{g,j} := d_{g}\left[ (1 - w_{g}^{\text{mix} }) A^{\text{out} }_{g,j} + w_{g}^{\text{mix} } A^{\text{mix} }_{g,j} \right]
$$
创新1:方差感知门控,Variance-Aware Gating
- 用于自适应调节推理奖励的权重,避免在结果奖励方差不足时引入噪声
- 对于每组样本,计算混合奖励与结果奖励的标准差比值:
$$
r_{g} := \frac{\widehat{\sigma}_{g}^{\text{mix} } }{\widehat{\sigma}_{g}^{\text{out} }+\widehat{\sigma}_{g}^{\text{mix} }+\varepsilon_{\text{std} } }
$$ - 最终得到 门控权重 :
$$
w_{g}^{\text{mix} } := \mathbf{1}(\bar{R}_{g}^{\text{out} } < R_{\text{out} }^{\text{max} }) \cdot \mathbf{1}(r_{g} < \varepsilon_{\text{mix} }) \cdot r_{g}
$$- 仅当结果奖励未饱和且混合奖励方差相对可控时,才引入推理奖励信号
创新2:Difficulty-Aware Weighting(难度感知加权)
- 优先从中等难度样本组中学习,避免过于简单或过于困难的样本主导优化过程
- 根据结果奖励的组内均值设定权重:
$$
d_{g} := \alpha_{\text{base} } + (\alpha_{\text{prio} } - \alpha_{\text{base} }) \cdot \mathbf{1}(\tau_{\text{low} } < \bar{R}_{g}^{\text{out} } < \tau_{\text{high} })
$$- 中等难度区间 \((\tau_{\text{low} }, \tau_{\text{high} })\) 内的样本获得更高权重 \(\alpha_{\text{prio} }\)
创新3:Dynamic Clipping
- 根据混合信号依赖程度动态调整 PPO 裁剪范围,在高方差信号下收紧信任域以控制噪声风险
- 裁剪半径随批次平均混合权重自适应调整:
$$
\varepsilon := \varepsilon_{\min} + (1 - \bar{w}_{\mathcal{B} })(\varepsilon_{\max} - \varepsilon_{\min})
$$- 当模型更多依赖高方差的推理奖励时(\(\bar{w}_{\mathcal{B} }\) 大),裁剪范围收紧,防止梯度更新过大
Self-Rewarding
- 原始论文:Self-Rewarding Language Models, ICML 2024, Meta
- Self-rewarding 是用模型自身替代独立外部奖励模型(RM),以自评估生成响应并提供奖励信号、驱动迭代对齐的范式,核心是单模型兼具生成(Actor)与评估(Judge)能力,降低对人类偏好标注的依赖
- 论文贡献:
- 提出了一体化框架,让模型同时具备指令生成、响应生成与自我评估能力,无需分离的奖励模型
- 验证了迭代式自奖励训练的可行性,实现模型在两大核心能力上的协同提升
- 为突破人类反馈瓶颈、实现模型持续自我改进提供了新路径
- 方法流程:
- 初始化:SFT
- 自指令生成(Self-Instruction Creation):
- 为每个指令生成多个候选响应(注:论文中似乎 Instruction 也是模型自己生成的)
- 模型通过 “LLM-as-a-Judge” 提示自我评估候选响应,给出 0-5 分评分(基于相关性、完整性、实用性等5个维度)
- 模型训练:从生成的候选响应中筛选出最高分(获胜者)和最低分(失败者)组成偏好对,通过直接偏好优化(DPO)训练下一轮模型
- 迭代优化:重复上述步骤
DLER
- 原始论文:DLER: Doing Length pEnalty Right - Incentivizing More Intelligence per Token via Reinforcement Learning, 20251016, NVIDIA
- DLER(Doing Length pEnalty Right)是一种通过 RL 优化推理语言模型效率的训练方案,核心目标是在不损失准确率的前提下最大化“每 token 智能度”(准确率与响应长度的比值),解决现有长链推理模型输出冗长、延迟高的问题
- DLER 的核心创新在于:无需复杂的长度惩罚设计,通过优化 RL 训练过程即可实现最优的准确率-效率权衡
- 长度缩减:相较于原始模型(如 DeepSeek-R1-7B),DLER 将响应长度削减 69%-77%,DA-DLER 进一步降至 80%;
- 准确率提升:在 MATH、AIME-24 等 5 个推理基准上,DLER 不仅恢复原始模型准确率,还实现 1%-3% 的提升;
- 推理效率:并行推理时,DLER-7B 生成多轮响应的 latency 降低6 2%,且准确率提升 28%;
- 泛化性:兼容多种长度惩罚函数(如 Cosine、Laser),且简单截断惩罚的效果优于复杂惩罚,同时训练成本更低
- 现有基于RL的长度优化方法常采用复杂长度惩罚函数,但存在三大关键问题:
- 1)优势估计偏差:GRPO 的分组奖励归一化在截断惩罚下产生显著奖励噪声,导致优势估计偏差
- 2)熵崩溃:重要性采样比率裁剪会过滤掉低概率、高熵的推理过渡 token,限制推理路径探索
- 3)奖励信号稀疏:大量训练样本因响应超截断长度被分配零奖励,导致训练信号失衡
- DLER 整合四大关键技术,针对性解决上述挑战:
- 1)批次级奖励归一化(Batch-wise Reward Normalization) :将GRPO的分组级优势归一化改为批次级归一化,缓解奖励噪声导致的偏差,优势计算方式为:
$$A_{i, t}^{norm }=\frac{A_{i, t}-mean_{batch}\left(A_{i, t}\right)}{std_{batch}\left(A_{i, t}\right)}$$- 其中 \(A_{i, t}=R_{i}’-mean(\{R_{i}’\}_{i=1}^{G})\),\(R_i’\) 为包含正确性奖励与长度惩罚的总奖励
- 2)更高裁剪阈值(Higher Clipping Threshold) :解耦GRPO中上下裁剪阈值,提高上阈值(\(\epsilon_{high}\)),保留高熵探索性token的梯度更新,避免熵崩溃
- 3)动态采样(Dynamic Sampling) :过滤所有rollout均为零奖励(过难样本)或全为正奖励(过易样本)的训练样本,重新采样至目标批次大小,构建均衡的训练信号
- 4)简单截断惩罚(Simple Truncation Penalty) :采用最简洁的长度惩罚机制——对超过固定长度限制的响应分配零奖励,避免复杂惩罚函数带来的训练不稳定
- 1)批次级奖励归一化(Batch-wise Reward Normalization) :将GRPO的分组级优势归一化改为批次级归一化,缓解奖励噪声导致的偏差,优势计算方式为:
DLER 扩展变体
- 难度感知DLER(DA-DLER) :根据问题难度动态调整截断长度,模型已可靠解答的简单问题进一步缩短截断长度,复杂问题保留更长token预算,额外降低11%-15%的响应长度
- 更新选择性权重融合(Update-selective Weight Merging) :针对公开训练数据质量不足导致的准确率下降,融合原始基线模型与DLER训练模型的权重(保留Top25%最大参数更新量并缩放),在恢复基线准确率的同时保持47%的长度缩减
GSPO(包含 GSPO 和 GSPO-Token 两个版本)
GSPO: Group Sequence Policy Optimization
- 原版的的 序列组策略优化(Group Sequence Policy Optimization, GSPO)算法采用以下 Sequence-level 的优化目标:
$$
\mathcal{J}_{\text{GSPO} }(\theta) = \mathbb{E}_{x\sim\mathcal{D},\{y_i\}_{i=1}^G \sim \pi_{\theta_{\text{old} } }(\cdot|x)} \left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta)\widehat{A}_i, \text{clip}(s_i(\theta), 1-\varepsilon, 1+\varepsilon) \widehat{A}_i\right)\right], \tag{5}
$$- 其中,论文采用基于组的优势估计:
$$
\widehat{A}_i = \frac{r(x,y_i) - \text{mean}(\{r(x,y_i)\}_{i=1}^G)}{\text{std}(\{r(x,y_i)\}_{i=1}^G)}, \tag{6}
$$ - 并基于序列似然(2023)定义重要性比率 \(s_i(\theta)\):
$$
s_i(\theta) = \left(\frac{\pi_{\theta}(y_i|x)}{\pi_{\theta_{\text{old} } }(y_i|x)}\right)^{\frac{1}{|y_i|} } = \exp\left(\frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \log \frac{\pi_{\theta}(y_{i,t}|x,y_{i,<t})}{\pi_{\theta_{\text{old} } }(y_{i,t}|x,y_{i,<t})}\right). \tag{7}
$$- 理解:这里是相当于有点对所有的 Token 的比例对数求平均,再求指数的意思,核心是将 Token 粒度的重要性比例替换成经过 “几何平均(Geometric Mean)“ 后的 Sequence 粒度的(同一个 Sequence 所有 Token 共享的)重要性比例
- 补充:几何平均(Geometric Mean,GM)的定义:
$$ \exp\left(\frac{1}{|x|} \sum_{t=1}^{|x|} \log x_t\right) = (\prod_{t=1}^{|x|} x_t)^{\frac{1}{|x|}}$$
- 补充:几何平均(Geometric Mean,GM)的定义:
- 理解:这里是相当于有点对所有的 Token 的比例对数求平均,再求指数的意思,核心是将 Token 粒度的重要性比例替换成经过 “几何平均(Geometric Mean)“ 后的 Sequence 粒度的(同一个 Sequence 所有 Token 共享的)重要性比例
- 其中,论文采用基于组的优势估计:
GSPO-token:A Token-level Objective Variant
- 在多轮强化学习等场景中,论文可能希望比 Sequence-level 更细粒度地调整优势
- 为此,论文引入了 GSPO 的 Token-level 目标变体,即 GSPO-token ,以实现 Token-level 的优势定制:
$$
\mathcal{J}_{\text{GSPO-token} }(\theta) = \mathbb{E}_{x\sim\mathcal{D},\{y_i\}_{i=1}^G \sim \pi_{\theta_{\text{old} } }(\cdot|x)} \left[\frac{1}{G} \sum_{i=1}^G \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \min \left(s_{i,t}(\theta)\widehat{A}_{i,t}, \text{clip}(s_{i,t}(\theta), 1-\varepsilon, 1+\varepsilon) \widehat{A}_{i,t}\right)\right], \tag{13}
$$- 其中
$$
s_{i,t}(\theta) = \text{sg}[s_i(\theta)] \cdot \frac{\pi_{\theta}(y_{i,t}|x,y_{i,<t})}{\text{sg}[\pi_{\theta}(y_{i,t}|x,y_{i,<t})]},
$$ - \(\text{sg}[\cdot]\) 表示仅取值但停止梯度,对应于 PyTorch 中的 detach 操作。GSPO-token 的梯度可以推导为:
$$
\begin{align}
\nabla_{\theta} \mathcal{J}_{\text{GSPO-token} }(\theta) &= \nabla_{\theta} \mathbb{E}_{x\sim\mathcal{D},\{y_i\}_{i=1}^G \sim \pi_{\theta_{\text{old} } }(\cdot|x)} \left[\frac{1}{G} \sum_{i=1}^G \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} s_{i,t}(\theta)\widehat{A}_{i,t}\right] \\
&= \mathbb{E}_{x\sim\mathcal{D},\{y_i\}_{i=1}^G \sim \pi_{\theta_{\text{old} } }(\cdot|x)} \left[\frac{1}{G} \sum_{i=1}^G s_i(\theta) \cdot \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \widehat{A}_{i,t} \frac{\nabla_{\theta} \pi_{\theta}(y_{i,t}|x,y_{i,<t})}{\pi_{\theta}(y_{i,t}|x,y_{i,<t})}\right] \\
&= \mathbb{E}_{x\sim\mathcal{D},\{y_i\}_{i=1}^G \sim \pi_{\theta_{\text{old} } }(\cdot|x)} \left[\frac{1}{G} \sum_{i=1}^G \left(\frac{\pi_{\theta}(y_i|x)}{\pi_{\theta_{\text{old} } }(y_i|x)}\right)^{\frac{1}{|y_i|} } \cdot \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \color{red}{\widehat{A}_{i,t}} \nabla_{\theta} \log \pi_{\theta}(y_{i,t}|x,y_{i,<t})\right]. \tag{15-17}
\end{align}
$$- GSPO-token 与原始 GSPO 的主要区别在于:
- GSPO 的目标函数中使用的优势函数是 Sequence-level 的 \(\widehat{A}_{i}\)
- GSPO-token 的目标函数中使用的优势函数是 Token-level 的 \(\color{red}{\widehat{A}_{i,t}}\),这允许同一个序列中,不同的 Token 使用不同的值
- GSPO-token 与原始 GSPO 的主要区别在于:
- 其中
- 当 Response \(y_i\) 中所有 token 的优势设置为相同值(即 \(\widehat{A}_{i,t} = \widehat{A}_i\))时,GSPO-token 和 GSPO 在优化目标、剪裁条件和理论梯度上是数值相同的
OPSD(On-Policy Self-Distillation)
- 原始论文:(OPSD)Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models, 20260126 - 20260305, UCLA & Meta
- OPSD 损失函数定义如下:
$$
\mathcal{L}_{\mathrm{OPSD} }(\theta) = \mathbb{E}_{(x,y^*)\sim \mathcal{S} } \mathbb{E}_{\hat{y} \sim p_S(\cdot | x)} \left[ \frac{1}{|\hat{y}|} \sum_{n=1}^{|\hat{y}|} D\big(p_T | p_S\big) \right]
$$- 用 hint 增强的 Prompt 得到教师模型