注:本文包含 AI 辅助创作
Skywork-Reard Paper Summary
- 本文对 Reward Model 相关的数据集做了非常详细的分析,对数据的处理流程具有很强的实际参考价值,值得深刻学习
- Skywork-Reard 特点:数据优先、轻量化、高效率
- Skywork-Reard 贡献:
- 包含 80k 条偏好对的高质量数据集 Skywork-Reward Preference 80K
- 奖励模型 Skywork-Reward-Gemma-2-27B(在 RewardBench 排行榜上排名第一),注意:仅用上述 80K 数据
RM 当前面临的挑战
- 数据质量低 :开源偏好数据集中,“Chosen”与“Rejected”响应差异过小、标注噪声高、存在 bias(如长度 bias)
- 数据规模冗余 :现有数据集动辄数十万甚至上百万条,但并未带来相应性能提升
- 模型复杂度高 :许多研究引入复杂架构或损失函数,但收益有限
核心贡献总结
- 轻量化数据构建 :仅使用 80k 条偏好对,远小于现有数据集(比如光 Preference 就多达 700K),这个数据集非常火,很多工作都已经引入
- 精细化的数据筛选策略 :基于模型能力、任务类别、奖励分数等进行多级过滤
- 详细的损失函数对比实验 :验证 Bradley-Terry loss 在所有变体中表现最优(对后续 RM 的使用提供了很实际的参考)
- 解决数据污染问题 :识别并移除 RewardBench 中的污染样本,进一步提升模型性能
整体方法详细描述
初始数据:Dataset Mixture
- Skywork-Reward Preference 80K 由以下四个高质量开源数据集组成(原始总样本约 378K,经过筛选压缩至 80K):
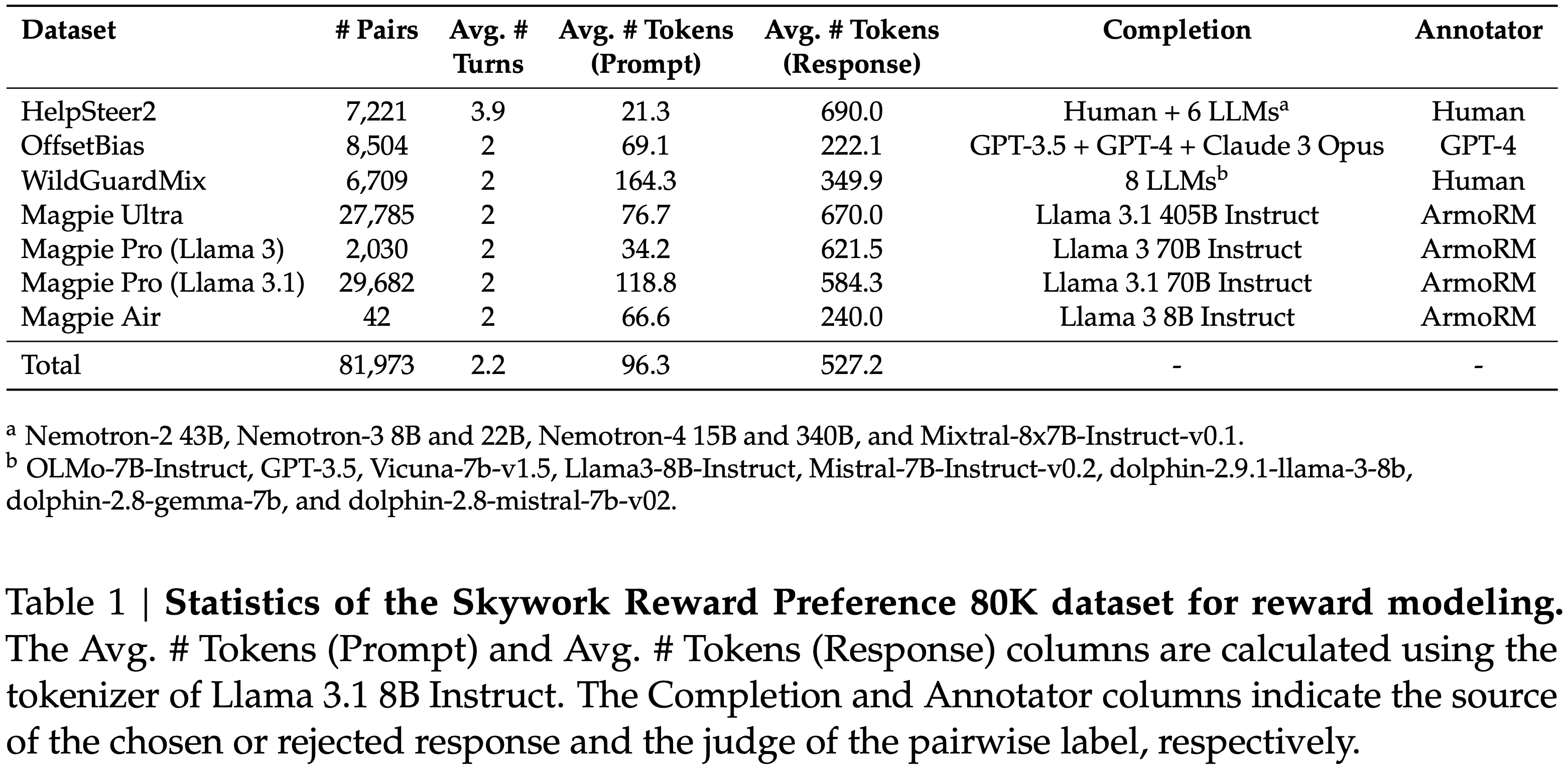
数据集 来源 规模 特点 HelpSteer2 ShareGPT + LLM/人工 10K 多维度评分(helpfulness, correctness, coherence, complexity, verbosity) OffsetBias 人工构建 8K 抗 bias,尤其对抗长度 bias WildGuardMix 合成 + 人工 87K(仅用部分) 安全偏好,拒绝 vs 遵从 Magpie 系列 Llama 系列自生成 约 350K(筛选后) 完全合成,按任务类别划分,含 ArmoRM 评分 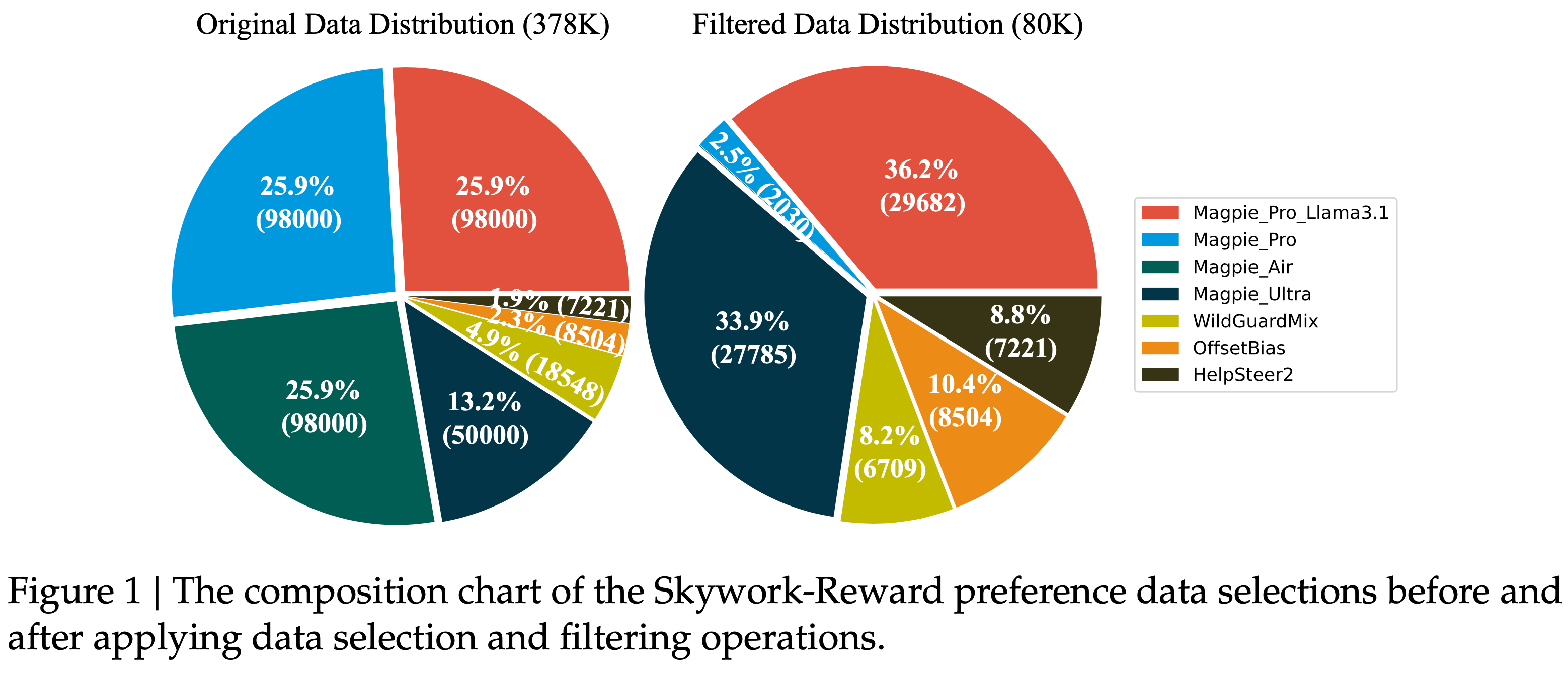
补充: Magpie 方法 & 数据集
- Mapie 数据集合成策略参见:Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, 20240617 & 20241007, University of Washington & AI2
- Magpie 是一种 无需人工标注、无需种子指令、无需复杂提示工程* 的 *大规模对齐数据合成方法
- Magpie 作者的 核心发现:对齐后的 LLM(如 Llama-3-Instruct)在仅输入模板中用户消息位置之前的“预查询模板” 时,会自动生成一条用户指令
- 这是由于其自回归生成特性,模型会自然地“补全”对话。
- Magpie 方法流程:Step 1:指令生成
- 输入:仅包含模型对话模板中用户消息之前的固定模板部分(例如 Llama-3 的
<|start_header_id|>user<|end_header_id|>) - 输出:模型自回归生成一条用户指令
- 特点:无需人工编写提示词或种子问题
- 输入:仅包含模型对话模板中用户消息之前的固定模板部分(例如 Llama-3 的
- Magpie 方法流程: Step 2:响应生成
- 输入:将生成的指令放入完整对话模板中
- 输出:模型生成对应的助手回复
- 完成:形成一条完整的“指令-响应”对齐数据
- 特别设计:
- 使用不同模型来生成:指令 和 响应,扩展多样性
数据筛选与过滤策略(核心创新 从 378K 到 80K 的过滤逻辑)
- 理解:本文中,数据筛选与过滤策略 是整个研究的核心贡献 ,也是其能够用 80K小数据集击败700K大数据集的根本原因
- 原始数据集混合物(Preference 378K)的核心问题:
- Magpie占比过高(93%) :其他高质量小数据集的信号被稀释
- Magpie 数据集的合成方式:使用 Llama 3 家族中不同规模的模型来生成数据集
- 传统合成数据生成通常是:人类写prompt + LLM生成response + 人类/模型打分 + 构建偏好对
- Magpie 的合成策略:只给一个固定前缀,让 LLM 同时扮演“用户”和“助手”两个角色,全自动生成完整的对话对
- Magpie 内部质量不均 :不同模型生成、不同任务类别、不同评分分布
- WildGuardMix 存在副作用 :过度强化安全会损害通用偏好能力
- 过滤目标
- 降量 :从 378K 压缩至 80K(压缩比 78%)
- 提质 :优先保留高质量、高信息密度的偏好对
- 平衡 :维持任务多样性、安全与通用能力的平衡
Magpie 子集的精细化筛选(核心)
- 整体流程如下:
- Step 1: 分数提取
- 输入为 原始偏好对,输出为 带 PairScore 的样本
- 核心逻辑: (chosen_score + rejected_score)/2
- Step 2: 分数校正
- 输入为 PairScore,输出为 校正后 PairScore
- 核心逻辑: Air -0.1, Pro3 -0.05, 其他不变
- Step 3: 类别识别
- 输入为 全量样本,输出为 按任务类别分组
- 核心逻辑: 区分 Math/Code 与其他
- Step 4: 类别内排序
- 输入为 各组样本,输出为 各组头部样本
- 核心逻辑: Math/Code: top30%, 其他: top10%
- Step 5: 跨子集合并
- 输入为 四子集头部样本,输出为 ~59.5K筛选后样本
- 核心逻辑: 保留原始子集标签
- Step 6: 最终集成
- 输入为 Magpie筛选结果,输出为 Skywork-Reward 80K
- 核心逻辑: + HelpSteer2 + OffsetBias + WildGuardMix
- Step 1: 分数提取
- 核心思路:不是“全局择优”,而是“类别保底、核心强化、偏差校正”的三位一体筛选策略
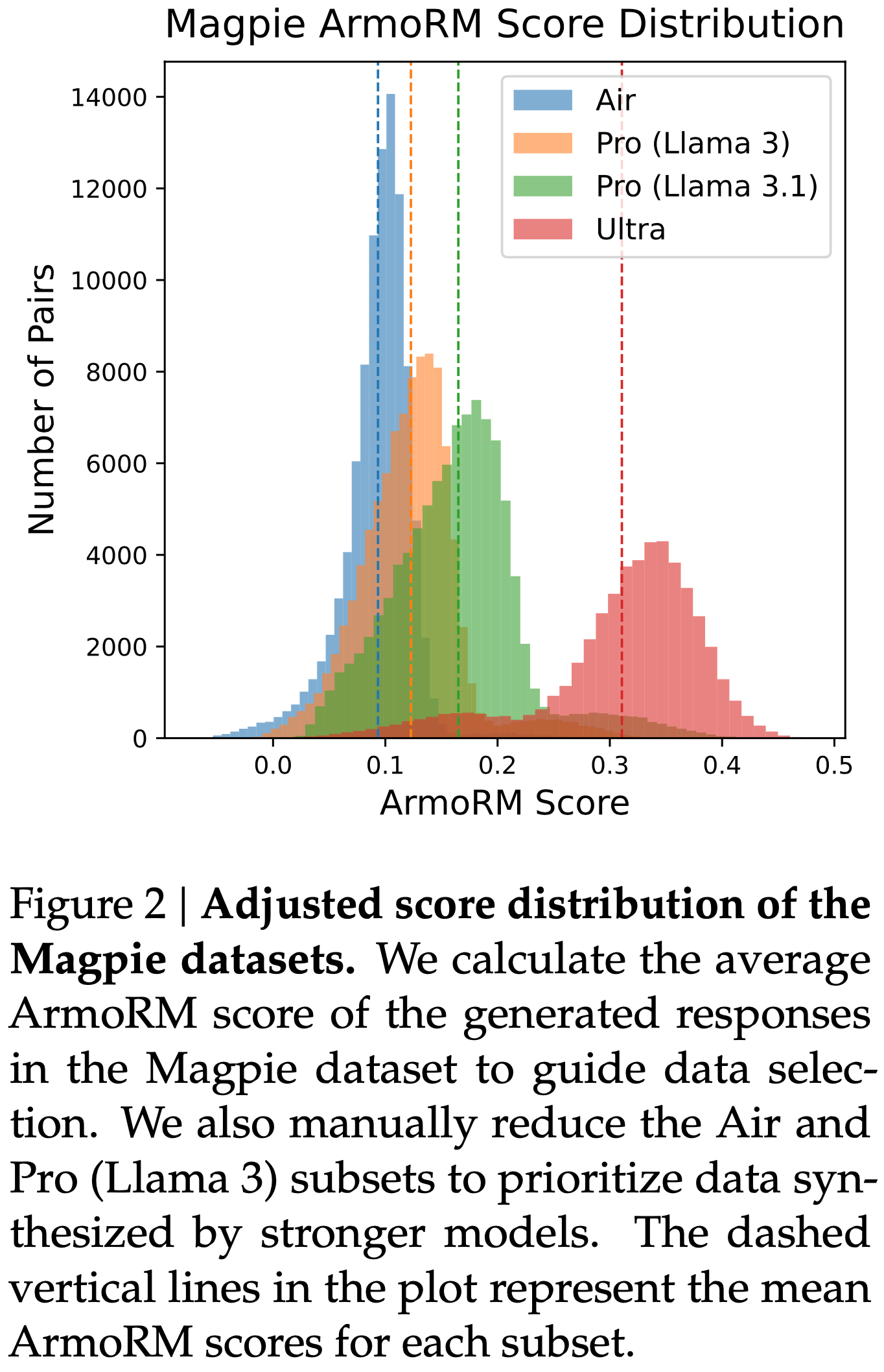
Magpie 子集-打分修正原理:按生成模型能力优先
- 问题诊断:ArmoRM 评分存在模型规模反向偏差 :
- Llama 3 8B Instruct(Air 子集):得分虚高
- Llama 3 70B Instruct(Pro 子集): 得分偏低
- Llama 3.1 70B Instruct(Pro 子集): 得分偏低
- 理解:在 Magpie 数据集中, Air 子集是 Llama 4 8B Instruct 生成的,却分数虚高于其他子集(如 70B)
- 解决方案:启发式分数校正 ,引入基于先验知识的分数平移 :
$$
\text{Score}_{\text{adjusted} } =
\begin{cases}
\text{Score}_{\text{original} } - 0.10, & \text{if subset = Air (8B)} \\
\text{Score}_{\text{original} } - 0.05, & \text{if subset = Pro (Llama 3 70B)} \\
\text{Score}_{\text{original} }, & \text{if subset = Pro (Llama 3.1 70B)}
\end{cases}
$$ - 校正逻辑理解:
- 减0.10 :Air子集虚高最严重,强力下调
- 减0.05 :Llama 3 70B 也存在一定虚高,适度下调
- 不减 :Llama 3.1 70B 作为最强模型,作为基准
- 校正后,三个子集的分数分布峰值与模型能力排序对齐(Figure 2)
Magpie 子集-分任务采样:按任务类别差异化采样
- 核心洞察:
- Math 和 Code 是 RLHF 最难优化的能力,也是奖励模型最需要强化的领域
- 注:后来有了 RLVR 了
- 其他任务(如创意写作、角色扮演)的边际收益较低
- Math 和 Code 是 RLHF 最难优化的能力,也是奖励模型最需要强化的领域
- 采样策略
- 数学 & 代码类别 :保留比例:前30%
- 依据:校正后的 ArmoRM 分数
- 目的:只保留最高质量的数学/代码偏好对
- 其他类别(Reasoning、Planning、Brainstorming、Creative writing等): 保留比例:前10%
- 依据:校正后的 ArmoRM 分数
- 目的:维持任务多样性,但严格控制冗余样本
- 数学 & 代码类别 :保留比例:前30%
- 问题:为什么不直接取全局top%?
- 这是关键设计智慧 :
- 如果全局取 top 30%,结果会严重偏向数学和代码(因为它们本身就占 Magpie 的大头)
- 按类别独立采样,可以在压缩总量的同时,维持任务分布的多样性
- 这是关键设计智慧 :
- 最终结果(Figure 3):
- 数学 + 代码:占总筛选后样本的 63.57%
- 其他7个类别合计:36.43%
- 既强化了核心能力,又保留了多任务泛化性
Magpie 子集-(Chosen+Rejected)/2打分依据:基于评分差异的隐式筛选
- (Chosen+Rejected)/2 的本质,是在测量“这个prompt下,模型能稳定产出高质量response的程度
- 未显式说明,但实际存在的机制 :
- 在 Magpie 的原始构建中,每个 prompt 生成 5 个 response,ArmoRM 打分后:
- Chosen = 最高分response
- Rejected = 最低分response
- 在 Magpie 的原始构建中,每个 prompt 生成 5 个 response,ArmoRM 打分后:
- 将chosen score和rejected score的平均值作为该偏好对的整体质量分
- 这意味着得到的是两种样本:
- 1)如果 5 个 response 质量都很接近,那么 chosen 和 rejected 分差小,即平均分可能不低,学习难度大
- 理解:这属于困难样本
- 2)如果 5 个 response 质量差异大,即分差大,那么平均分更能代表高质量 chosen 的存在
- 理解:这属于高质量样本(强调 Chosen 的正确性?)
- 1)如果 5 个 response 质量都很接近,那么 chosen 和 rejected 分差小,即平均分可能不低,学习难度大
- 虽然没有直接按分差过滤,但高分差样本天然更容易进入 top 30% ,因为 chosen 的高分拉高了平均值
WildGuardMix 对抗性筛选(安全)
WildGuardMix 数据构建逻辑
- WildGuardMix 原始结构:
- 每个 prompt 带多个 response
- 每个 response 标注:
- 是否拒绝(refusal)
- prompt 是否有害
- 偏好构造规则为 :
Prompt 类型 Chosen response Rejected response 有害(harmful) 拒绝回答 遵从回答 无害(benign) 遵从回答 拒绝回答
WildGuardMix 第一阶段:移除非对抗样本
- 背景:
- 早期版本的 Skywork-Reward 模型已经在非对抗的 WildGuardMix 样本上表现极好(准确率 > 95%)
- 继续训练这些样本 边际收益接近 0
- 操作 :
- 移除非对抗子集
- 仅保留对抗子集(Adversarial subset)
- 对抗子集的来源 :
- 基于 WildTeaming框架 生成
- 从良性/有害 prompt 出发,自动化生成越狱攻击变体
- 模拟真实世界中用户绕过安全护栏的尝试
WildGuardMix 第二阶段:控制对抗样本比例
- 新问题出现 :
- 仅用对抗子集 + 其他数据集训练 得到 模型安全能力提升 ,但通用偏好能力下降
- 内部验证集上观察到明显 trade-off
- 根本原因 :
- 对抗样本的分布与正常用户请求差异较大
- 过度拟合对抗模式会扭曲奖励模型的 核心偏好表征
- 解决方案 :
- 仅保留部分高质量、代表性强的对抗偏好对
- 具体比例未公开,但策略方向明确:在不牺牲通用能力的前提下,注入安全偏好
HelpSteer2 与 OffsetBasis 的处理
HelpSteer2
- HelpSteer2 论文自己的原始筛选逻辑:
- HelpSteer2 为每个 response 标注 5 个维度的分数:
- helpfulness, correctness, coherence, complexity, verbosity
- 偏好构造 :只保留那些 chosen response 的 helpfulness分数 > rejected response 的 helpfulness 分数 的样本
- HelpSteer2 为每个 response 标注 5 个维度的分数:
- 对于 HelpSteer2 数据集的处理:
- 不做额外过滤,完整纳入 10K 样本
- 原因:HelpSteer2 已经是人工+LLM混合标注的高质量小数据集 ,本身噪声低、信息密度高
OffsetBias
- 原始设计目的 :
- 专门针对奖励模型的长度 bias 、格式 bias 等伪相关信号
- 构造对抗性偏好对 :rejected response 看起来写得很完整,但包含特定错误
- 对于 OffsetBias 数据集的处理 :
- 完整纳入 8K 样本
- 原因:OffsetBias本身就是抗bias的“解毒剂” ,规模小但价值高
训练目标与损失函数实验
基础损失函数
- 使用 Bradley-Terry 模型 :
$$
\mathcal{L}_{\mathrm{ranking} } = -\log \sigma (r_\theta (x,y_c) - r_\theta (x,y_r))
$$- \( r_\theta(x, y) \) 是奖励模型对响应 \( y \) 的标量输出
- \( \sigma \) 是 sigmoid 函数
实验的损失函数变体(作者系统对比了以下 6 种变体)
- 变体1 Focal Loss :关注难分样本
$$
\mathcal{L}_{\mathrm{Focal} } = -\log \sigma(\Delta) \cdot (1 - \sigma(\Delta))^\gamma
$$ - 变体2 Focal Loss with Penalty :
- 进一步惩罚模糊判断
- 变体3 Hinge Loss :
- 强制 margin (非下面的 margin)
$$
\mathcal{L}_{\mathrm{Hinge} } = \max(0, m - \Delta)
$$
- 强制 margin (非下面的 margin)
- 变体4 Margin MSE :回归到 margin
$$
\mathcal{L}_{\mathrm{Margin-MSE} } = (r_\theta(x,y_c) - (r_\theta(x,y_r) + m))^2
$$ - 变体5 Cross-Entropy :
- 作为二分类任务
- 变体6 BT with Tempered Log / Temperature :
- 修改对数曲率或分布平滑度
- 最总实验 结论 :
- Bradley-Terry loss 在所有任务类别上表现最均衡
- 其他变体在某些类别有提升,但牺牲了整体性能(见表 3)
实验设计与结果分析
训练设置
- 基座模型:Llama-3.1-8B-Instruct、Gemma-2-27B-it
- 替换最后一层为 reward head,随机初始化
- 优化器:AdamW,weight decay 1e-3
- 学习率:2e-6(8B)、1e-6(27B)
- 训练轮数:2 epochs
- 全局 batch size:128
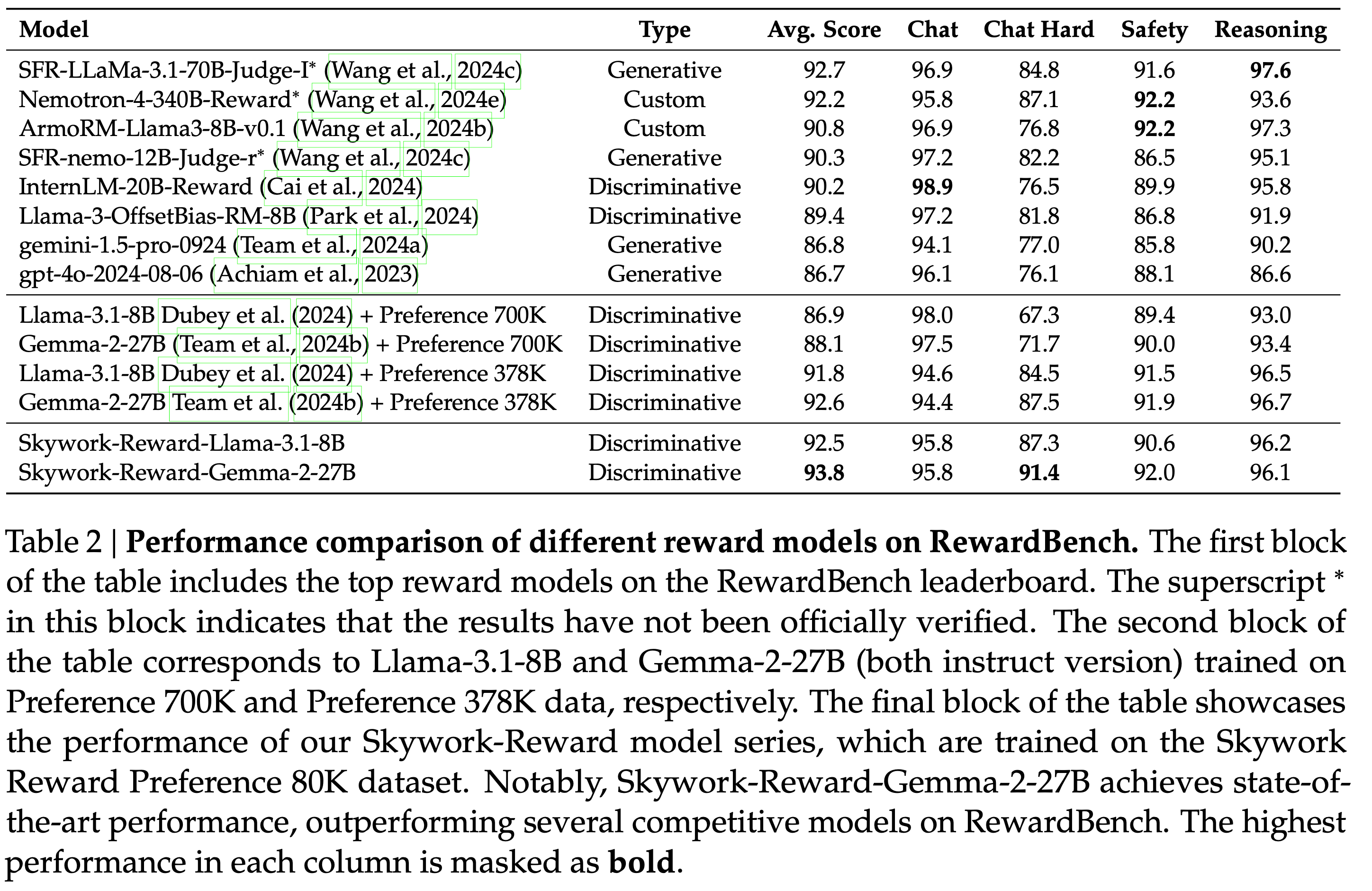
主要实验结果(表 2)
- Skywork-Reward-Gemma-2-27B :RewardBench 总分第一
- Skywork-Reward-Llama-3.1-8B :超越除 70B 外的所有模型
- Chat Hard 类别 :27B 模型首次突破 90 分,远超 Nemotron-4-340B-Reward
- 关键结论 : 小数据、高质量 > 大数据、低质量
- 378K 未筛选数据已优于 700K 数据集
- 80K 筛选数据进一步显著提升
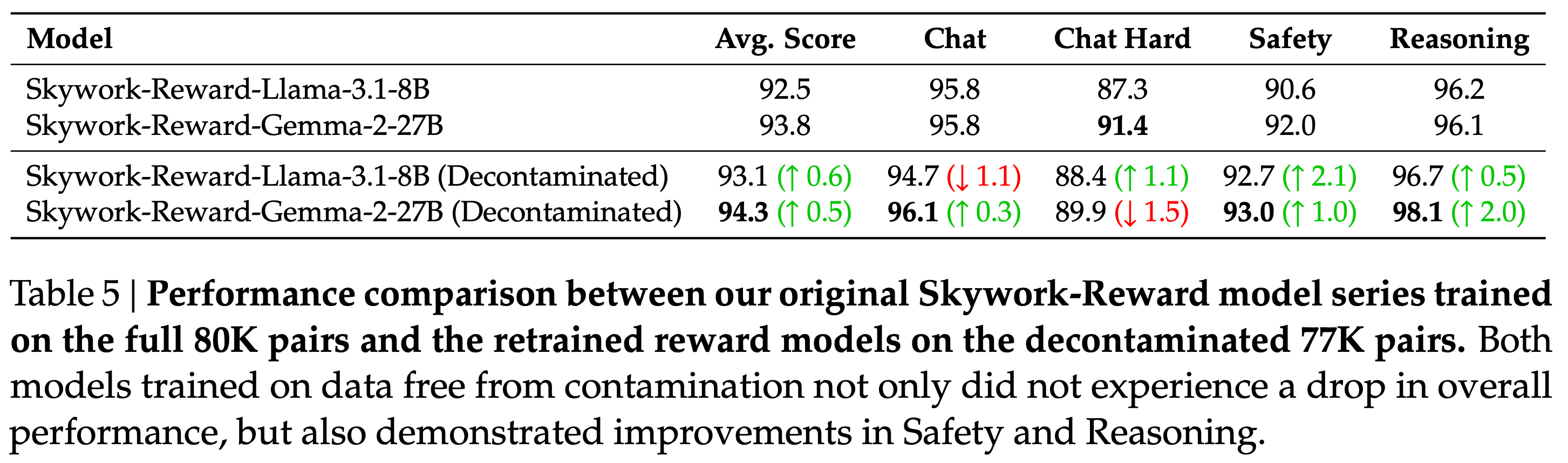
数据污染问题与去污染实验
问题发现:
- Magpie Ultra 子集中约 5K prompt 与 RewardBench 测试集重叠
- 推测原因:Llama-3.1-405B 训练数据中可能包含这些 prompt
解决方案:
- 使用 RewardBench 官方去污染脚本,移除 n-gram 匹配样本
- 发布 Skywork-Reward Preference 80K v0.2
意外发现:
- 去污染后模型性能不降反升(表 5)
- 推测:污染的样本可能与 RewardBench 的偏好不一致 ,移除后反而提升泛化能力
核心观点总结
- 观点 1:数据质量远重要于数量
- 80K 精心筛选样本 > 378K 原始样本 > 700K 混合样本
- 观点 2:Bradley-Terry loss 是最稳健的训练目标
- 观点 3:模型能力与评分工具可能存在分布偏移 ,需手动校正
- 观点 4:数据污染普遍存在,需系统性检测与移除
- 观点 5:实践建议
- 优先使用 HelpSteer2、OffsetBias 等高质量小数据集
- 对合成数据按生成模型能力和任务类别进行分级采样
- 避免盲目使用复杂损失函数
- 奖励模型训练前必须进行 contamination check
补充:ArmoRM
- 原始论文:(ArmoRM)Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts, 20240618, University of Illinois Urbana-Champaign
- 开源模型 & 代码 :github.com/RLHFlow/RLHF-Reward-Modeling
- for 传统 RM 在 RLHF 中存在的黑箱性、不可解释性、易受奖励黑客攻击等问题,论文提出了一种可解释、可调控的多目标奖励建模方法
背景:RLHF RM 现有问题
- 黑箱性 :传统 RM 输出单一标量分数,无法解释为何某回复更优
- 奖励黑客 :模型学会利用RM的漏洞(如生成长回复以获得高分)
- 不可调控 :无法根据用户需求或上下文动态调整评分标准
解决方案概述
- 提出多目标奖励模型(ArmoRM) ,使用绝对评分数据进行回归训练,输出多个可解释维度的评分
- 提出基于Mixture-of-Experts(MoE)的门控机制 ,根据上下文动态加权各目标,生成最终标量分数
- 在 RewardBench 上取得 SOTA ,超越 GPT-4 作为 Judge 的方法,逼近 Nemotron-4 340B 的性能
ArmoRM 方法详解(重点)
多目标奖励建模(Multi-Objective Reward Modeling)
- 目标:训练一个模型,为每个回复输出多个可解释维度的评分(如帮助性、诚实性、安全性、冗长度等)
- 输入输出:
- 输入:\( x \oplus y \)(提示+回复的拼接)
- 输出:\( k \)-维评分向量 \( r \in \mathbb{R}^k \)
- 模型架构:
- 使用 Llama-3 8B 作为特征提取器 \( f_\theta \)
- 在最后一层接一个线性层 \( w \in \mathbb{R}^{d \times k} \),输出多目标评分
- 训练目标为回归损失(均方误差):
$$
\min_{\theta, w} \mathbb{E}_{x,y,r \in D} | w^\top f_\theta(x \oplus y) - r |_2^2
$$
- 数据特点:
- 使用 8 个数据集,共 19 个目标维度
- 不同数据集评分尺度不同,统一线性归一化到 \([0,1]\)
- 缺失目标维度在损失计算中被忽略
基于 MoE 的目标加权机制(MoE Scalarization)
- 动机:不同上下文(如数学问题 vs. 安全敏感问题)对不同目标维度的重视程度不同,固定权重不灵活
MoE Scalarization 方法流程:
- 1. 提取提示特征 :使用冻结的 \( f_\theta \) 提取提示 \( x \) 的特征 \( f_\theta(x) \)
- 2. 门控网络 :一个浅层MLP \( g_\phi \) 将提示特征映射为 \( k \)-维权重向量,经Softmax归一化(非负且和为1)
$$
g_\phi(f_\theta(x)) \in \Delta^{k-1}
$$ - 3. 去偏处理(Verbosity Bias Removal) :
- 每个目标评分减去冗长度评分的加权项:
$$
r_i’ \gets r_i - \lambda_i r_{\text{verbose} }
$$ - 选择 \( \lambda_i \) 使得调整后的评分与冗长度评分在参考数据集上的Spearman相关系数为0;
- 每个目标评分减去冗长度评分的加权项:
- 4. 最终标量分数 :
$$
R = g_\phi(f_\theta(x))^\top r’
$$ - 5. 训练门控网络 :
- 冻结 \( f_\theta \) 与 \( w \);
- 仅训练 \( g_\phi \) 与一个缩放因子 \( \beta \);
- 使用 Bradley-Terry 损失:
$$
\min_{\phi, \beta} \mathbb{E} \left[ -\log \frac{\exp(\beta R_{\text{chosen} })}{\exp(\beta R_{\text{chosen} }) + \exp(\beta R_{\text{rejected} })} \right]
$$
ArmoRM 实验设置与结果
实验环境
- 硬件 :CPU 训练线性层,单张 A6000 训练门控网络;
- 超参数 :门控网络为 3 层 ReLU MLP(1024 hidden units),
lr=0.001,batch=1024,steps=10000; - 评估基准 :RewardBench(4主类+1先验类,权重1.0/0.5)
主要结果(原论文表1)
- 训练结果:
方法 参数量 总体得分 Nemotron-4 340B RM 340B 89.3 ArmoRM + MoE (Ours) 8B 89.0 GPT-4 Turbo(as judge) - 84.2 Llama-3 8B BT RM 8B 83.6 - 超越 Llama-3 8B BT RM ,验证了多目标+MoE的有效性
- 超越 GPT-4 Judge ,表明可作为低成本替代
- 逼近 340B 模型 ,展现方法的高效性