注:本文包含 AI 辅助创作
Paper Summary
- SDPO 整体总结:
- RLVR 方法仅从每次尝试的标量结果奖励中学习,存在信用分配瓶颈
- 许多可验证环境实际上提供了丰富的文本反馈,比如运行时错误或评判员评估,这些反馈解释了尝试失败的原因
- 注:
- 将 RLVR 描述为仅结果奖励的方法也不一定准确吧,RLVR 主要是指有可验证奖励的 RL 场景,其实也可以有 PRM 等
- 个人感觉 RLVR 更像一种场景,而不是一种方法
- 本文将此设定形式化为具有丰富反馈的强化学习,并提出了 SDPO
- SDPO(Self-Distillation Policy Optimization)是一种针对 LLM 在可验证环境(如代码、数学推理)中进行强化学习的方法
- 理解:其实只要有反馈信号(比如 开放问答领域的 Reference Answer 或者 Reward Model 的打分),也可以考虑使用(做一些信号处理后输入 Teacher 模型的上下文)
- SDPO 基本思路:
- 通过利用环境提供的反馈(如运行时错误、测试失败信息、评语等)
- 以自蒸馏的方式实现密集信用分配(Dense Credit Assignment)
- 克服传统 RL 方法中因标量奖励导致的奖励稀疏性 带来的信用分配瓶颈
- 理解:SDPO 的本意实际上就是想使用更丰富的奖励信号来给 Token 训练提效
- 本文的范式可称为 RLRF 范式(带 Rich Feedback 的 RL)
- 环境提供超出标量奖励的 Tokenized Feedback,这论证了这移除了 RLVR 的一个关键信息瓶颈
- 作者强调 SDPO 的优点:
- 在缺乏 Rich Feedback 的标准 RLVR 环境中进行训练,SDPO 在推理任务上也展现出比 GRPO 更优的样本效率和实际收敛时间
- SDPO 的收益随着模型规模的增大而增长
- 表明自我修正的能力与模型的上下文学习能力共同扩展
- 在 Test-time 对单个困难的二元奖励任务执行 SDPO,与强基线相比,能加速解的发现
- SDPO 能够以一种更接近人类认知的方式从 Rich Feedback 中学习:利用精确的结果而不仅仅是二元奖励
- 通过允许模型回顾性地确定它本应如何行动
- RLVR 方法仅从每次尝试的标量结果奖励中学习,存在信用分配瓶颈
- SDPO(本文) vs OPSD 方法:
- 除了 OPSD 强调信号来自已有数据集 \(\mathcal{D}\) 的参考答案外,OPSD 几乎和本文 SDPO 思路一致,都是 On-policy 蒸馏的
- SDPO 强调外部评估环境信号
- 实际上,在 SDPO 原始论文的表 2 中可以看到:如果存在正确 Rollout 的话,Teacher 的 Prompt 中可能会包含之前生成的正确 Rollout 作为 Hint
- OPSD 强调参考答案 \(y^*\),类似 SFT 的样本(注意:OPSD 要求包含的参考答案 \(y^*\) 是原始数据集中必须存在的,不是 Student 也不是 Teacher 生成的)
- 两者算法上几乎没有差异(两篇文章几乎同时发出 20260126 vs 20260128,算是并发的工作,OPSD 引用了 SDPO )
- 总结来说:两者核心区别在于 hint 信号不同:
- OPSD 更强调仅使用自身(能生成至少一次正确答案的自身)模型,数据集必须包含参考答案 \(y^*\)(类似 SFT 的样本)
- SDPO 则强调外部评估信号的引入(数据集中只需要 Query,不需要参考答案 \(y^*\),但需要外部评估的反馈信号)
- 对 SDPO 评价:
- 新颖的想法:将符号化反馈转化为密集学习信号;在 Token-level 分配 Advantage ,提升学习效率
- 训练提效:在仅返回标量反馈的标准 RLVR 环境中
- SDPO 将成功的 Rollout 作为失败尝试的隐式反馈,同样优于基线方法
- Test-time 提效:
- 在 Test-time 将 SDPO 应用于单个问题,可以加速在困难的二元奖励任务上的发现过程
- 在达到与 Best-of-\(k\) 采样或多轮对话相同的发现概率时,所需的尝试次数减少了 \(3 \times\)
- 无需外部 Teacher :完全自监督,适用于在线学习
- 适配性强:可作为标准 RLVR 方法的即插即用替代
- 可能存在问题:
- 性能依赖于模型的上下文学习能力 ,对较弱模型可能还不如 GRPO
- 反馈质量直接影响学习效果,要重点关注

Introduction and Discussion
- 背景 & 分析:
- 传统 RL:对经验(行动、接收反馈、更新策略)进行迭代,可以解锁仅从静态监督中难以获得的能力 (2015; 2016; 2017; 2019)
- 在 LLM RL:RL 显著提高了在重推理任务上的性能,尤其是在具有程序化或其他可验证评估的环境中 (2024; 2025; 2025; 2025)
- 目前 LLM 后训练的主流 RL 方法仍然受限于信用分配
- 大多数现有方法在 “RLVR” 设定下运行:
- 给定一个问题 \(x\),模型采样一个答案 \(y \sim \pi_{\theta}(\cdot | x)\) 并接收一个标量奖励 \(r \in \mathbb{R}\),通常是二元的(例如,代码生成中的单元测试通过/失败)
- 现代策略梯度 RLVR 方法(如 GRPO)从这些稀疏的结果奖励中估计 Advantage
- 而且:当一个组中的所有 Rollout 都获得相同(通常为零)奖励时,GRPO 的 Advantage 会坍缩为零,导致学习停滞
- 大多数现有方法在 “RLVR” 设定下运行:
- 已有一些解法:
- 一些方法从强大的 Teacher 那里进行蒸馏 (2025; 2026)
- 可以提供密集的 Token-level 监督
- 但在在线学习中,当目标是提升现有模型的能力上限时,强大的 Teacher 通常是不可用的
- 一些方法从强大的 Teacher 那里进行蒸馏 (2025; 2026)
- 本文认为关键的限制不在于 RL 本身,而在于标量结果奖励所施加的信息瓶颈
- 许多可验证环境暴露了超出标量奖励 \(r\) 的丰富 Tokenized 反馈,例如运行时错误、失败的单元测试或来自 LLM 评判员的评估
- 这种反馈不仅揭示了 Rollout 是否正确,还揭示了错误所在
- 本文将这个更一般的设定形式化为 Reinforcement Learning with Rich Feedback (RLRF)
- 图 2 中说明了其与 RLVR 的区别
- RLRF 中,反馈可以是 Agentic 系统达到的任何状态的任何 Tokenized 表示

- 核心问题提出:如何在不依赖外部强大 Teacher 提供监督的情况下,将丰富的反馈转化为有效的信用分配?
- 本文出发点是观察到 LLM 已经拥有一个使用反馈的强大机制(上下文学习)
- 当以反馈为条件时,同一个模型通常能够识别出可能的错误并提出修正方法
- 这种反馈的一个常见例子是像 LeetCode 这样的编码平台上失败测试用例的总结(图 3)
- 许多近期的工作利用这种返回机制来迭代生成修正 (2021a; 2023; 2023; 2024; 2025; 2025)
- 本文使用当前的策略作为一个 “Self-Teacher”
- 在接收到丰富的反馈后,不是采样一个新的 Response,而是重新评估现有的 Rollout
- 将反馈包含在上下文中会改变模型的下一 Token 分布,使得 Self-Teacher 能够在特定 Token 上同意或不同意 Student 原先的选择
- 这产生了密集的、Logit-level 信用分配
- 当提供图 3 中的反馈时, Self-Teacher 可以识别出应如何修改最初的尝试以避免运行时错误
- 这种机制不会产生采样的开销:只需在 Self-Teacher 以反馈增强的上下文中重新计算原始尝试的对数概率
- 这种机制不会产生采样的开销:只需在 Self-Teacher 以反馈增强的上下文中重新计算原始尝试的对数概率
- 本文提出一种通过自蒸馏执行 RL 的 On-Policy 算法 SDPO
- SDPO 从当前策略中采样 Rollout,获得丰富的环境反馈,然后最小化一个 Logit-level 蒸馏损失,该损失使当前策略的下一 Token 分布与 Self-Teacher 的分布相匹配
- SDPO 解决了将蒸馏应用于 Online Learning 时的核心限制:缺乏更强的外部 Teacher
- SDPO 不依赖于固定的 Teacher ,而是利用模型事后识别自身错误的能力
- Self-Teacher 以刚刚收到的丰富反馈为条件来构建当前策略 ,提供了蒸馏的密集监督,同时保留了 On-Policy RL 的探索 Advantage
- 表 1 总结了 SDPO 相对于 RLVR 和蒸馏基线所处的位置(这里强调 OPD 和 SDPO 的区别主要是前者需要一个 更强的 Teacher 模型)
- 注:本文在第 6 节中包含了相关工作的全面总结
- 注:SDPO 是一种策略梯度算法,其 Advantage 是使用 Self-Teacher 估计的
- SDPO 只需替换掉 Advantage 项,就能对标准的 RLVR 流程进行微小改动来实现
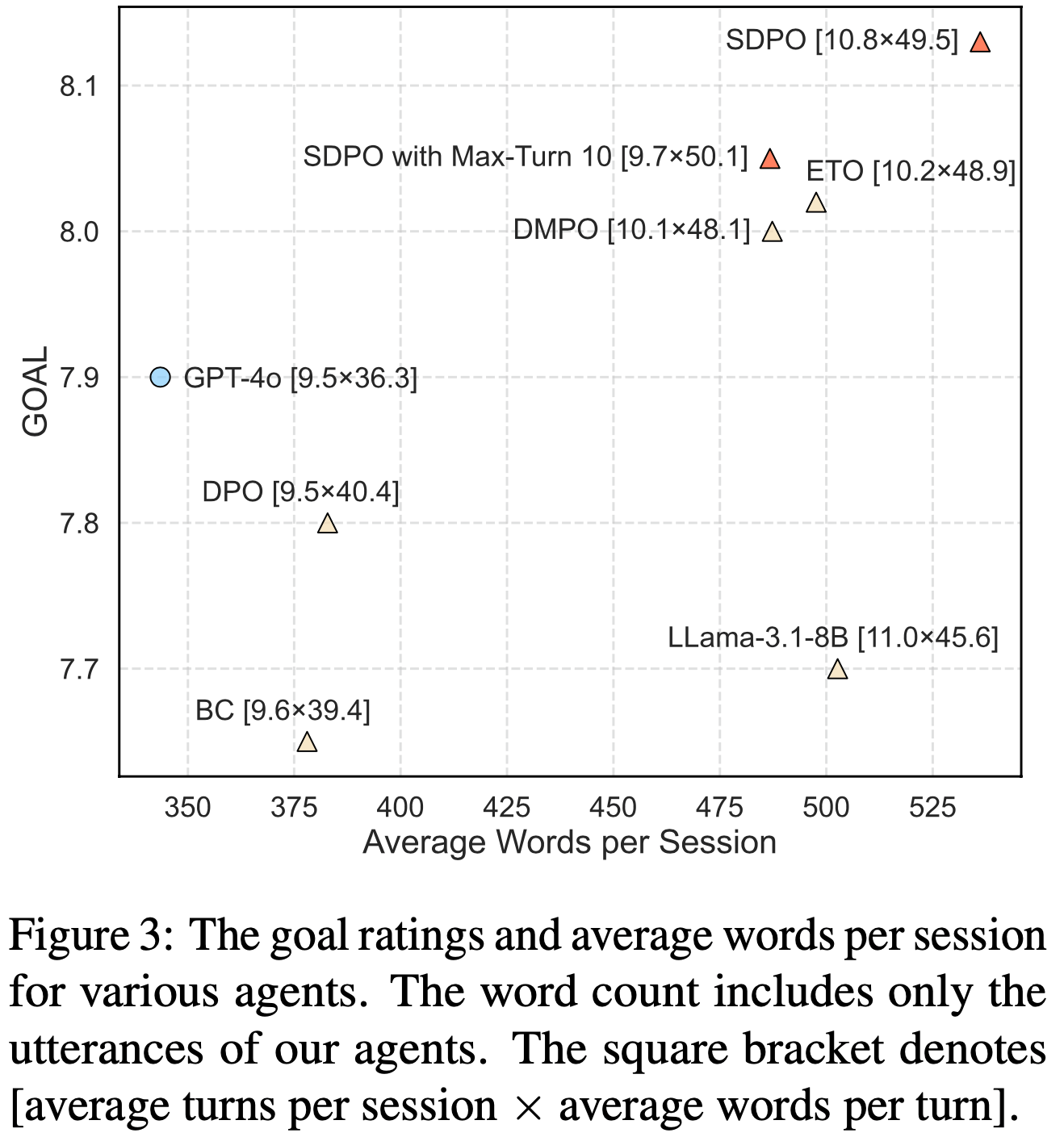
- 本文在三种在线 RL 设定中评估 SDPO:
- Learning without rich feedback (§3):
- 评估场景:不返回任何标量奖励之外反馈的标准 RLVR 环境
- SDPO 将当前批次中采样到的成功尝试视为对同一问题上失败尝试的“反馈”
- 使用 Qwen3-8B 和 Olmo3-7B-Instruct 作为起点,在科学推理和工具使用任务上进行了训练
- 结果:
- SDPO 在总体最终准确率上优于整合了近期改进的强 GRPO 基线(分别为 \(70.2%\) 和 \(66.6%\))
- 与 GRPO 相比,SDPO 在实现更高准确率的同时,生成长度最多可缩短 \(11\times\)
- 这表明有效的推理不一定需要冗长
- Learning with rich feedback (§4):
- 评估场景:来自 LiveCodeBench v6 的、带有 LeetCode 风格反馈的竞争性编程问题
- 如图 1 所示
- SDPO 显著优于 GRPO,达到了更高的最终准确率(分别为 \(48.8%\) 和 \(41.2%\)),并且达到 GRPO 最终准确率所需的生成次数减少了 \(4\times\)
- SDPO 的增益随着模型规模的扩大而增长,这表明自教学的能力随着模型成为更强的上下文学习者而出现
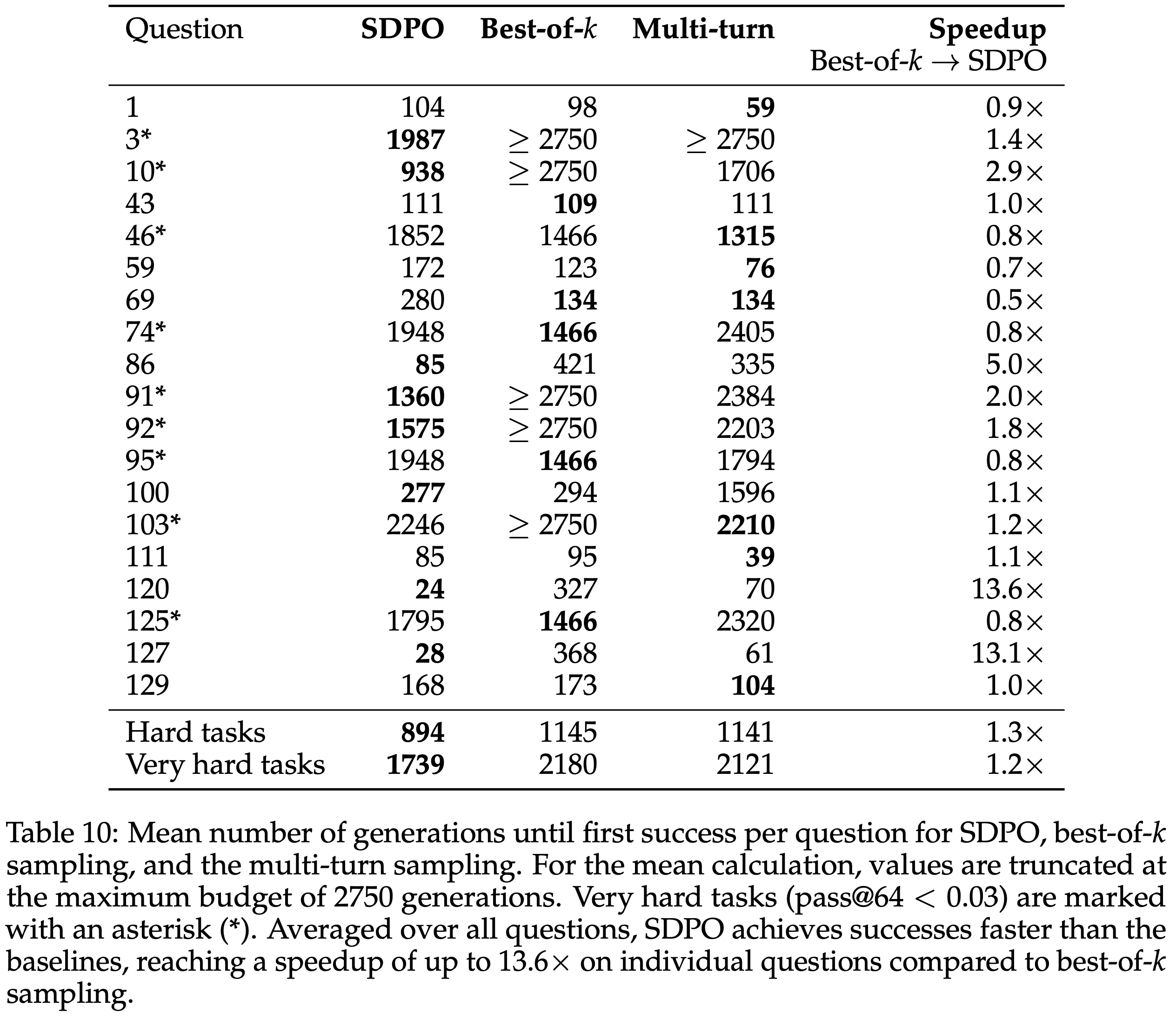
- Discovering novel solutions to hard tasks at test-time(§5): 评估模型在推理阶段,发现困难任务的新颖解决方案
- SDPO 可以加速在困难的二元奖励问题上找到解决方案的过程
- RLVR 只有在找到第一个解决方案后才会开始学习
- 利用 SDPO 进行 Test-time 自蒸馏,这是一种模型针对单个测试问题进行特化的 Test-time 训练形式
- 这里针对的是 LiveCodeBench 中非常困难的问题(基础模型的
pass@64低于 0.03) - SDPO 将发现解决方案的速度加快了 \(3\times\)
- SDPO 可以加速在困难的二元奖励问题上找到解决方案的过程
- Learning without rich feedback (§3):
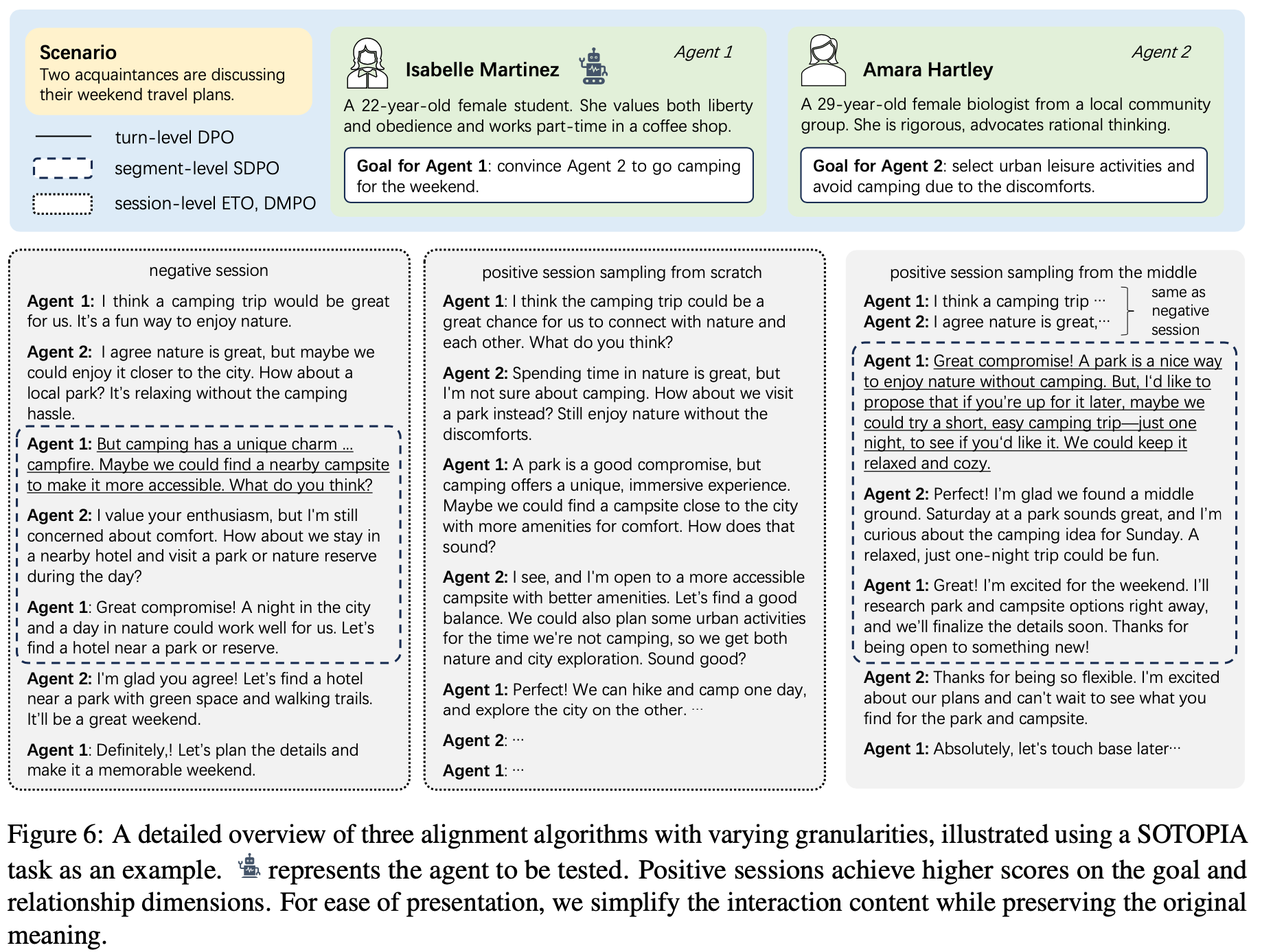
SDPO: Self-Distillation Policy Optimization
- SDPO 利用当前策略的上下文学习能力来进行信用分配
- Self-Teacher 是 \(\pi_{\theta}(\cdot \mid x,f)\),以问题 \(x\) 和丰富反馈 \(f\) 为条件的当前策略(“Student”)
- 除了 Student 最初的尝试 \(y\),\(f\) 可以包含两种关键的反馈信息:
- 任何环境输出:例如来自代码环境的运行时错误
- 已有解决方案:比如 \(x\) 已经在 Rollout 组中被另一个尝试解决了的样本解决方案
- Self-Teacher \(\pi_{\theta}(\cdot |x,f)\) 应该比 Student \(\pi_{\theta}(\cdot |x)\) 有更高的准确率,因为它在上下文中看到了额外的信息
- 除了 Student 最初的尝试 \(y\),\(f\) 可以包含两种关键的反馈信息:
- 这引导作者得出如下观察:
可以将同一个策略用于两种不同的角色:作为 Student 进行最初的尝试,以及作为 Teacher 来确定行动在事后的价值
- SDPO 反复地将 Self-Teacher 蒸馏到 Student 中
- 给定一个问题 \(x\)
- 首先从 Student \(\pi_{\theta}\) 中采样 Rollout,并获得相应的环境反馈
- 然后使用 KL 散度,作为 Student 和 Teacher 下一 Token 分布之间的距离度量
$$ \text{KL}(p| q) = \sum_{i}p(i)\log \frac{p(i)}{q(i)} $$ - 并优化一个标准的 Logit 蒸馏损失:
$$\mathcal{L}_{\text{SDPO} }(\theta):= \sum_{t}\text{KL}(\pi_{\theta}(\cdot |x,y_{< t})| \text{stopgrad}(\pi_{\theta}(\cdot |x,f,y_{< t}))) \tag{1}$$- stopgrad 运算符阻止梯度通过 Teacher 传播,防止 Teacher 向 Student 退化而忽略 \(f\)
- Teacher 的直观作用是,基于反馈 \(f\) 通过回溯来确定 Student 的原始尝试 \(y\) 在何处以及如何出错
- 给定一个问题 \(x\)
- 图 4 展示了使用 Qwen3-8B 作为 Student 和 Self-Teacher 的自教学示例
- 算法 1 中总结了 SDPO

- 表 2 中展示了 Teacher 的报告模板
- prompt 替换为问题
- 一个先前由 Student 生成的样本解决方案被替换为 successful previous rollout(如果该问题有的话;否则跳过该段落)
- environment_output 被替换为环境输出(例如,见图 3),该输出来自模型的原始尝试(如果尝试不成功且没有解决方案;否则跳过该段落)
- 如果模型的原始尝试成功,则将此尝试作为正确的解决方案传递
- original_response 被替换为模型的原始尝试,以便在 Self-Teacher 下重新评估其对数概率
Proposition 2.1,SDPO 的梯度
- 本节详情参见附录 A.1
- \(\mathcal{L}_{\text{SDPO} }\) 的梯度是
$$\nabla \mathcal{L}_{\text{SDPO} }(\theta) = \mathbb{E}_{y\sim \pi_{\theta}(\cdot |x)}\left[\sum_{t = 1}^{|y|}\mathbb{E}_{\hat{y}_{t}\sim \pi_{\theta}(\cdot |x,y_{< t})}\left[\log \frac{\pi_{\theta}(\hat{y}_{t}\mid x,y_{< t})}{\pi_{\theta}(\hat{y}_{t}\mid x,f,y_{< t})}\cdot \nabla_{\theta}\log \pi_{\theta}(\hat{y}_{t}\mid x,y_{< t})\right]\right]. \tag{2}$$
Comparison to RLVR
- SDPO 梯度是一个(负的)Logit-level 策略梯度,其 Advantage 是使用 Self-Teacher 估计的
- 也就是说:SDPO 可以重用标准的 RLVR 实现,只需替换掉 Advantage 项
- 设 \(y_{i}\) 是问题 \(x\) 的规模为 \(G\) 的 Rollout 组中的第 \(i\) 个 Rollout,那么比较 GRPO 和 SDPO,有:
$$
\begin{align}
A_{i,t}^{\text{GRPO} }:&=r_{i}-\text{mean}\{r_{i}\}_{i=1}^{G}(\text{constant in }t),\\
A_{i,t}^{\text{SDPO} }(\hat{y}_{i,t})&=\log\frac{\pi_{\theta}(\hat{y}_{i,t}\mid x,f_{i},y_{i,t})}{\pi_{\theta}(\hat{y}_{i,t}\mid x,y_{i,t})}
\end{align}
$$- GRPO 的 Advantage 仅应用于 Sampled Token \(y_{i,t}\),并且在 Rollout \(y_{i}\) 内是常数
- 问题:这里有必要强调 Advantage 仅应用于 Sampled Token 吗?
- 回答:有的,这里是想强调 SDPO 本身的 Advantage 是词表上所有可能的 Token 都有的
- SDPO 的 Advantage 仅当 Student 和 Teacher 在 Token (对数概率)上完全一致时才为零
- 在 Teacher 下更有可能出现的 Token(相对 Student),SDPO Advantage 为正
- 在 Teacher 下不太可能出现的 Token(相对 Student),SDPO Advantage 为负
- SDPO 可以在两个方面被视为标准 RLVR 方法的直接扩展:
- 1)从 1-bit 反馈扩展到允许任意 Token 序列作为反馈
- 2)利用这种丰富的反馈来估计密集的 Logit-level Advantage
- GRPO 的 Advantage 仅应用于 Sampled Token \(y_{i,t}\),并且在 Rollout \(y_{i}\) 内是常数
- Off-policy 实现:
- SDPO 方法本身是与 RLVR 方法解耦的,我们可以通过 PPO 风格的裁剪重要性采样,从而将公式 (2) 中的 SDPO 梯度轻松扩展到 Off-Policy 数据
- 详见附录 A.4
Compute time & memory
- 与 GRPO 相比,SDPO 唯一的计算开销是需要额外计算 Self-Teacher 的对数概率,这可以有效地并行化,并且比顺序生成快得多
- 图 5 比较了 SDPO 和 GRPO 的计算时间
- SDPO 的计算开销相对较小 (+17.1% 或 +5.8%)
- 注:这里使用的 Micro Batch Size 为 \(2\),通过使用更大的 Micro Batch Size 可以进一步减少计算时间
- 这里的 MBS 对应一次累计梯度使用的 Rollout 数量

- 这里的 MBS 对应一次累计梯度使用的 Rollout 数量
- 朴素地计算 Student 和 Teacher 之间的 KL 散度需要在内存中保存两者的完整 Logits
- 为避免这种情况,在 SDPO 损失中执行 Top-\(K\) 蒸馏来近似 KL 散度
- 即:仅计算两部分:
- 1) Student 的 Top-\(K\) Logits 和 Teacher 对应的 Logits
- 2)一个捕捉尾概率的项
- 参见附录 A.3
- 通过合理选择 \(K\)(例如,\(K = 100\)),这几乎可以避免任何内存开销,同时捕获大部分信息
- 即:仅计算两部分:
- 为避免这种情况,在 SDPO 损失中执行 Top-\(K\) 蒸馏来近似 KL 散度
Stability improvements
- 两个实际的修改可以显著增强 SDPO 的训练稳定性
- 1)采用正则化的 Self-Teacher ,通过 Student 参数的指数移动平均或通过将当前 Teacher 与初始 Teacher 进行插值来实现(参见附录 A.2)
- 后面会详述,这两种策略都能有效地稳定学习
- 2)采用对称的 Jensen-Shannon 散度作为蒸馏损失
- 已有研究表明,这种形式也能提高从外部 Teacher 进行 On-Policy 蒸馏时的稳定性 (2024)
- 1)采用正则化的 Self-Teacher ,通过 Student 参数的指数移动平均或通过将当前 Teacher 与初始 Teacher 进行插值来实现(参见附录 A.2)
Learning without Rich Environment Feedback
- 标准的 RLVR 环境中的反馈仅限于标量奖励
- 在这个场景下,SDPO 不使用标量奖励,而是将当前批次中采样到的成功尝试视为对同一问题上失败尝试的“反馈”
- 通过将 Student 的尝试与正确的解决方案进行比较
- Self-Teacher 可以识别出 Student 在何处出错,并提供密集的信用分配
Experimental setting
- 评估模型尚未经过显式微调的任务:
- Science Q&A (化学、物理、生物学、材料科学): 使用 SciKnowEval (2024a) 中的推理子集 (L3) 进行本科水平的科学推理
- Tool use: 根据 ToolAlpaca (2023),将工具 API 规范和用户请求映射到正确的工具调用
- 对数据进行训练/测试分割以测试领域内的泛化能力
- 使用 Qwen3-8B (2025a) 和 Olmo3-7B-Instruct (2025) 作为初始检查点
- 报告相对于实际训练时间(不包括初始化和验证)的
avg@16
Baselines
- 将 SDPO 与一个改进版的 GRPO 进行比较
- 该版本 GRPO 整合了最近的几项修改 (2025; 2026),例如非对称裁剪 (2025)、避免有偏归一化 (2025b) 以及在使用高效推理框架时校正 Off-Policy 数据 (2025)
- 将这些修改整合到一个 GRPO 实现中,代表了一个强基线,详见附录 A.4 中的公式 (12)
- GRPO 通过 PPO 的裁剪重要性加权支持 Off-Policy 训练 (2017)
- 本文还报告了 On-Policy GRPO 的特例(与原始 SDPO 的超参数匹配)
- 对于这两个基线,执行了超参数扫描,并报告了在所有目标任务上实现最高验证性能的模型的结果
- 超参数和训练细节在附录 E 中提供
- 使用 ver1 库 (2025) 进行快速的多 GPU 训练
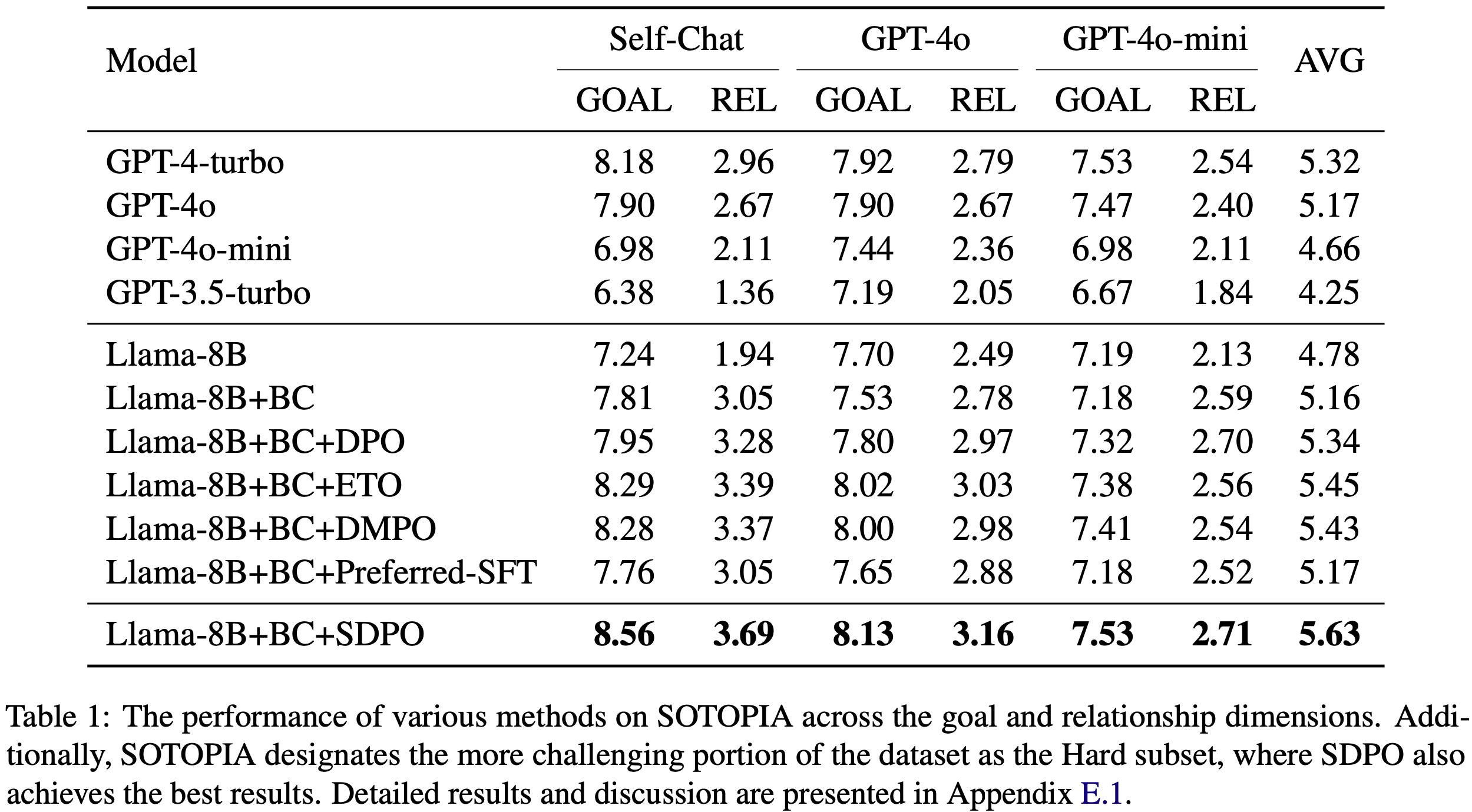
Results
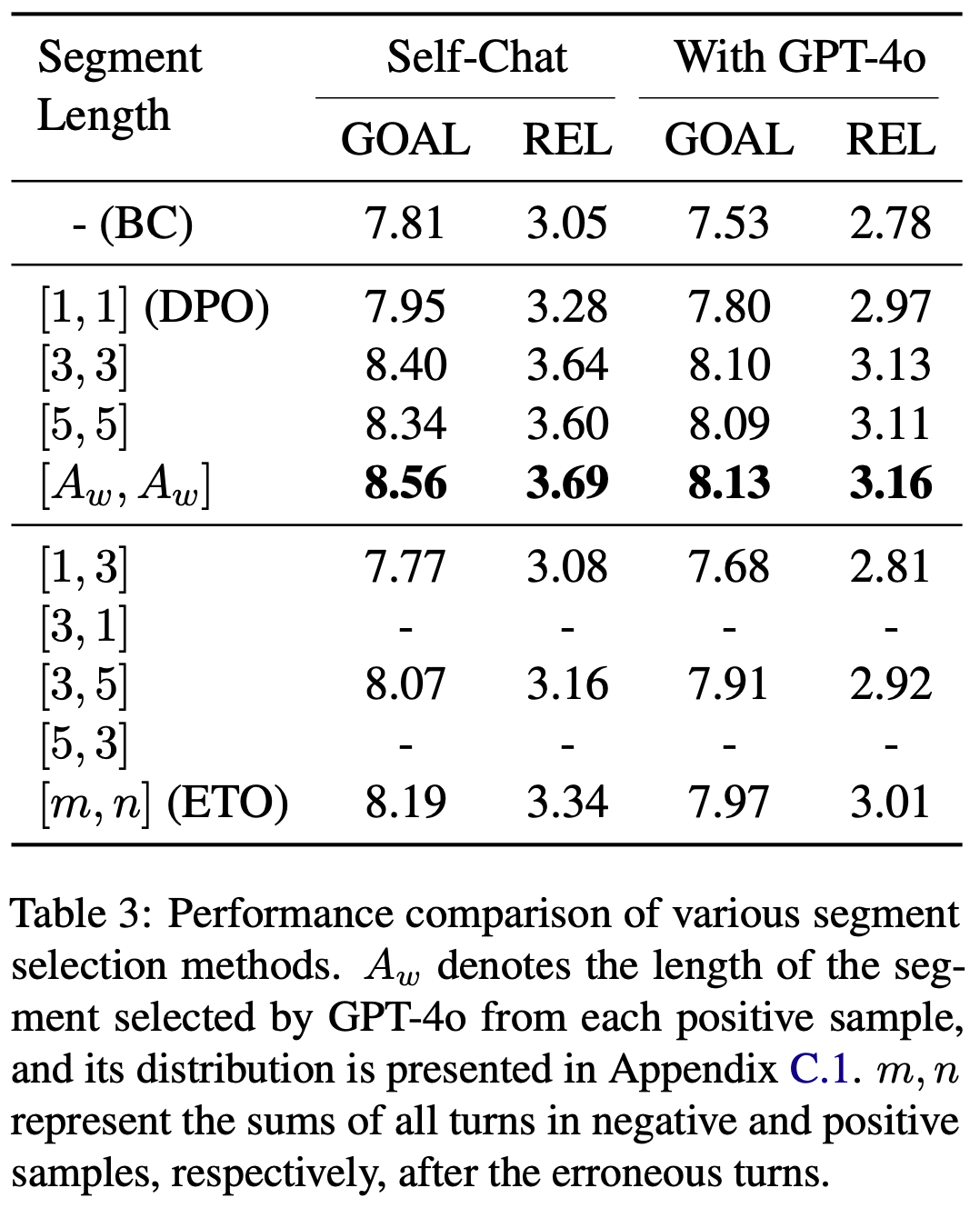
- 表 3 总结了本文的结果
- SDPO 在几乎所有运行中都优于 GRPO,通常带来显著的改进
- SDPO 的学习速度明显快于 GRPO
- 在几种情况下,SDPO 仅训练 1 小时就达到了 GRPO 训练 5 小时的性能
- 在几种情况下,SDPO 仅训练 1 小时就达到了 GRPO 训练 5 小时的性能
- 如图 6(左)所示,SDPO 在化学任务上比 GRPO 取得了特别显著的改进
- 使用 Olmo3-7B-Instruct,SDPO 在 50 分钟的实际训练时间内就达到了 GRPO 5 小时的准确率,速度提升了 \(6\times\)
- SDPO 的 5 小时准确率比 GRPO 高出超过 \(10%\) 的百分点
- 使用 SDPO 的结果严格采用了 On-Policy 训练(即,每个生成批次只进行一次梯度更新)
- 考虑到 Off-Policy 方法(每个生成批次执行多次梯度更新)已知的效率 Advantage
- 注:作者认为研究 SDPO 与 Off-Policy 更新相结合是一个令人兴奋的未来方向
Takeaway 1
- SDPO 能够学习有效地进行推理,泛化到具有挑战性的推理任务
- 无需对现有的 RLVR 环境进行任何修改,SDPO 在多个案例中显著优于 GRPO
Self-distillation learns to reason concisely
- 实验观察可知,SDPO 生成的 Response 比 GRPO 短得多,同时实现了更高的准确率
- 平均而言,SDPO 的 Response 比 GRPO 短 \(3\times\) 以上(参见附录 D 的表 8)
- 在化学任务上使用 Olmo3-7B-Instruct,SDPO 甚至将 Response 长度减少了 \(11\times\),同时保持了更高的准确率(图 6(右))
- 注:RLVR 上的实验表明,扩展 Response 长度是激发新兴推理能力的强大驱动力 (2024; 2025; 2025)
- 本文的结果表明,有效的推理不一定总是冗长的(比如 SDPO 就提高了推理的效率)
- 定性地看,GRPO 较长的 Response 通常源于“表面”的推理,而非必要的分析步骤
- GRPO 经常生成诸如“Hmm”和“Wait”之类的填充短语,或者进入循环逻辑,逐字重复之前的步骤
- 图 7 显示了这种现象的一个代表性例子
- SDPO 的生成保持简洁,避免了这些表面模式
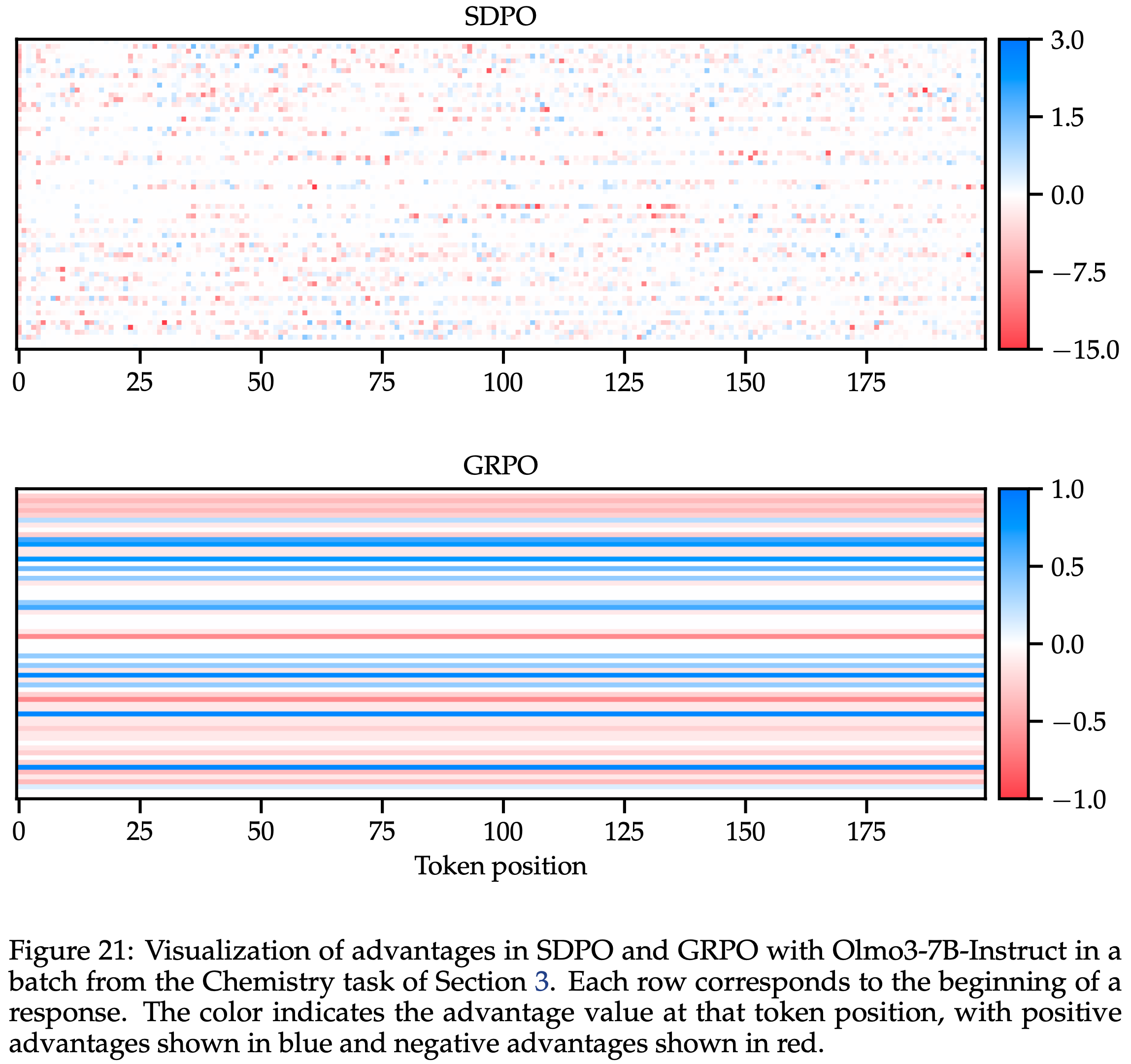
- 这可以通过 SDPO 的密集信用分配来解释,它为每个下一 Token 预测分配一个特定的 Advantage ,从而产生稀疏的 Advantage (参见附录 F 的图 21)
- 通过提高推理效率,SDPO 减少了推理生成时间,并表明推理性能可以通过改进模型的推理方式(而不仅仅是推理长度)来提高

Learning with Rich Environment Feedback
- 本节在编码任务上评估 SDPO,编码是一个典型的 RL 环境示例,提供了丰富的反馈,例如运行时错误和失败的单元测试
- 学习解决这些编码问题需要强大的信用分配,因为模型必须识别其精确的错误,以避免在未来重复这些错误
- LiveCodeBench (2025) 提供了一组竞赛风格的编码问题,范围从简单到竞赛级别
- 本文将评估限定在 LCB 的最新子集 LCBv6 上,该子集包含 2025 年 2 月至 5 月发布的 131 个问题
- 本文考虑一个包含公开和私有单元测试的设置,这在代码竞赛和 LeetCode 等编码平台中很常见,其中公开测试用于训练期间的评估,私有测试用于验证 (2022; 2022; El-2025; 2025)
- 本文在实验中使用 Qwen3 (2025a) 模型系列,除非另有说明,默认使用 Qwen3-8B
- 本文报告 4 次 Rollout 的平均准确率,并使用与第 3.1 节中概述的相同的 GRPO 基线
- Results
- 图 1 比较了 SDPO 和 GRPO 在 LCBv6 上的学习曲线
- SDPO 达到了比 GRPO 显著更高的最终准确率 \((48.8%)\),相比 GRPO 的 \((41.2%)\),同时也优于公开 LCBv6 排行榜上最强的指令模型(Claude Sonnet 4 \((40.5%)\) 和 Claude Opus 4 \((39.7%)\))
- SDPO 达到 GRPO 最终准确率所需的生成次数减少了 \(4\times\)
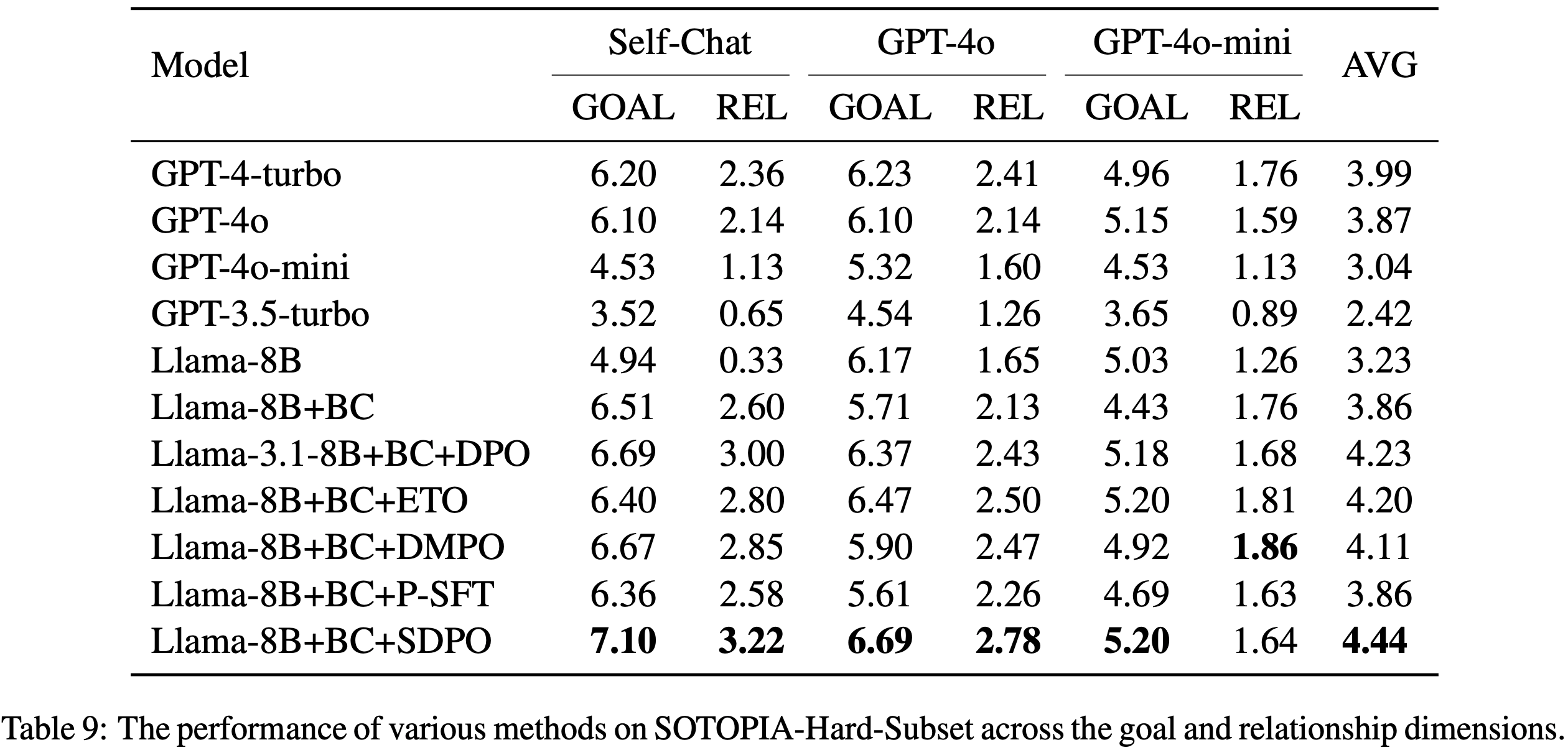
- 在附录的表 9 中包含了与其他性能与 GRPO 相似的 RLVR 基线的扩展比较
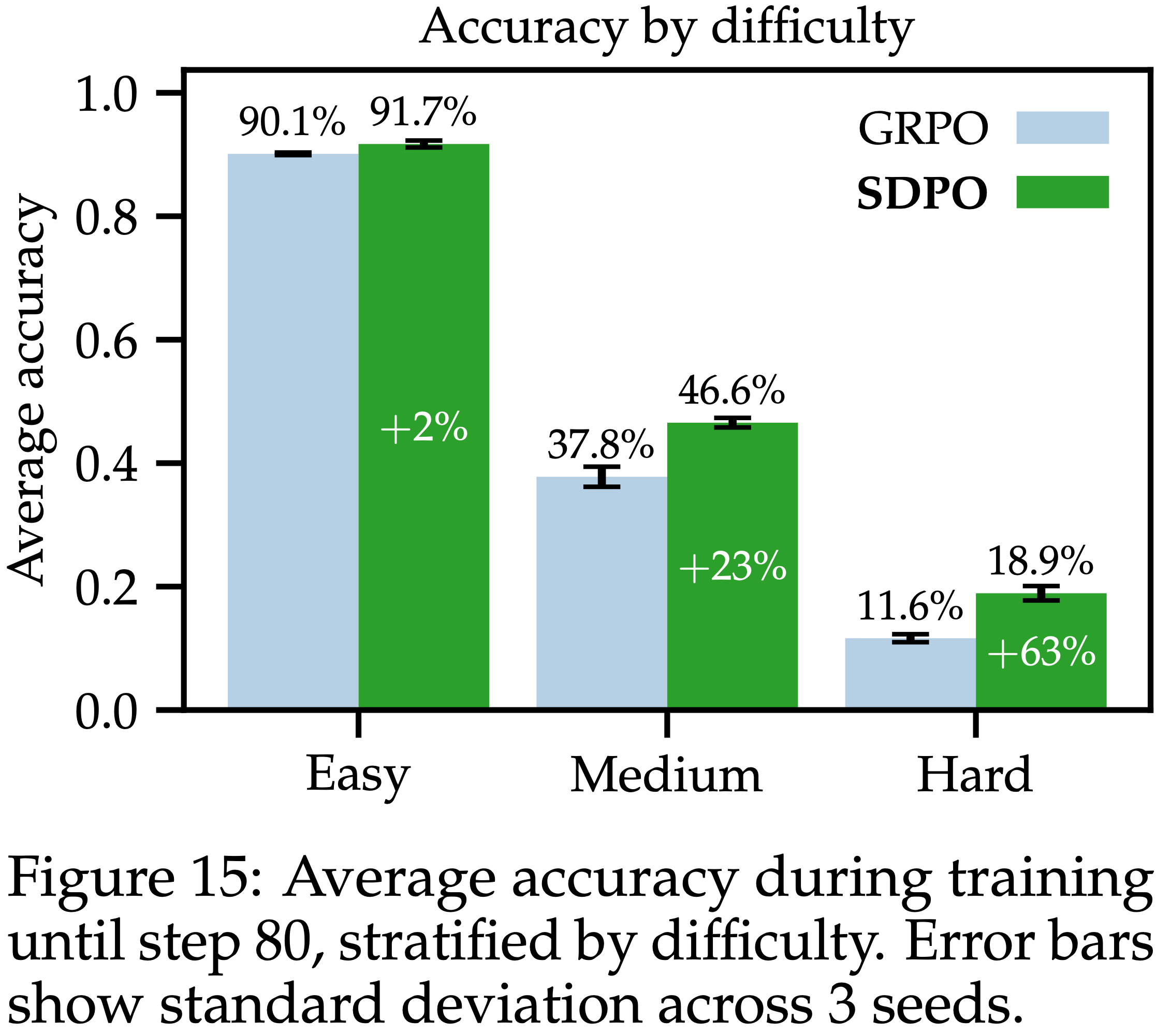
- 本文根据 LCB 的简单、中等和困难问题进行分类,SDPO 在解决中等和困难问题方面相比 GRPO 有特别显著的改进(参见附录的图 15)
- 本文根据 LCB 的简单、中等和困难问题进行分类,SDPO 在解决中等和困难问题方面相比 GRPO 有特别显著的改进(参见附录的图 15)
Self-distillation benefits from stronger models
- 本文工作的一个核心问题是 SDPO 是否对基础模型的上下文学习能力敏感
- 我们期望 SDPO 受益于强大的上下文学习器,因为这使得 Teacher 能够执行更准确的回顾
- 为了回答这个问题,本文对 Qwen3 系列的不同模型大小进行了扩展研究
- 正如大量先前工作所证明的,上下文学习的能力随着模型大小的增加而增强(例如,2020)
- 如图 8 所示
- SDPO 在较大模型上显著优于 GRPO,而在较小模型上仅略微优于 GRPO

- SDPO 在较大模型上显著优于 GRPO,而在较小模型上仅略微优于 GRPO
- 为了确定 SDPO 在比 Qwen3-0.6B 更弱的模型上是否也可能表现不如 GRPO,本文使用 Qwen2.5-Instruct (2024) 进行了额外的扩展研究
- 在使用 Qwen2.5-7B 时 SDPO 优于 GRPO,在使用 Qwen2.5-8B 时 SDPO 和 GRPO 表现相当
- SDPO 在 Qwen2.5-1.5B 上表现不如 GRPO,如附录 D 的图 17 所示
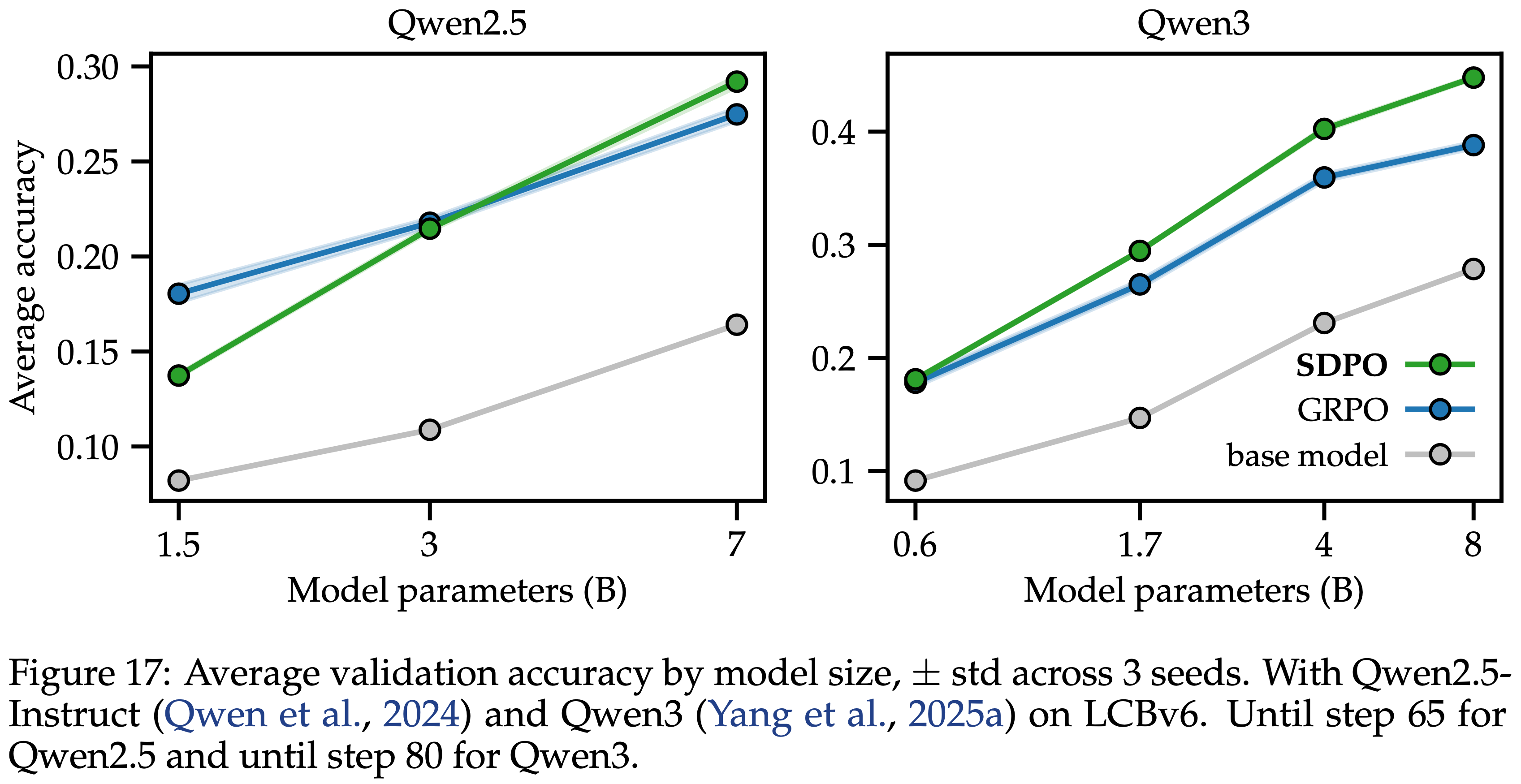
Takeaway 2
- 本文实验结果表明:SDPO 相对于 GRPO 的边际改进与基础模型的强度紧密相关
- 就像上下文学习是随着规模扩展而出现的一种现象一样
- SDPO 中 Self-Teacher 的准确回顾能力似乎也是随着规模扩展而出现的
- 未来建议对比 Qwen3-8B 更强的模型进行研究
Self-distillation performs dense credit assignment
- GRPO 为每个生成的 Token 分配一个恒定的 Advantage (Sequence-level)
- SDPO 根据 Student 和 Teacher 的一致性,为生成序列中每个位置上的每个可能的下一个 Token 分配一个单独的 Advantage (Token-level)
- 在生成序列 \(y\) 的每个位置 \(t\),有 \(|\nu|\) 个可能的下一个 Token,其中 \(\nu\) 是词表
- 在蒸馏中,这个层级通常被称为 Logit 层级,因为它对应于模型的 Logits
- 在实践中,本文通过前 \(K\) 个 Token 加上 尾部来近似完整的下一个 Token 分布
- 也就是说:SDPO 为每个序列分配 \(|y|\cdot (K + 1)\) 个唯一的 Advantage
- 注:这里的 \(|y|\) 是当前序列的 Token 数
- 如图 9 所示,这允许 SDPO 执行密集的信用分配
- 在图 4 的示例中,SDPO 的密集信用分配
- 蓝色显示的是在 Self-Teacher 下变得更有可能的 Token
- Self-Teacher 识别出返回的
range语句必须如何修改,以便它不包含n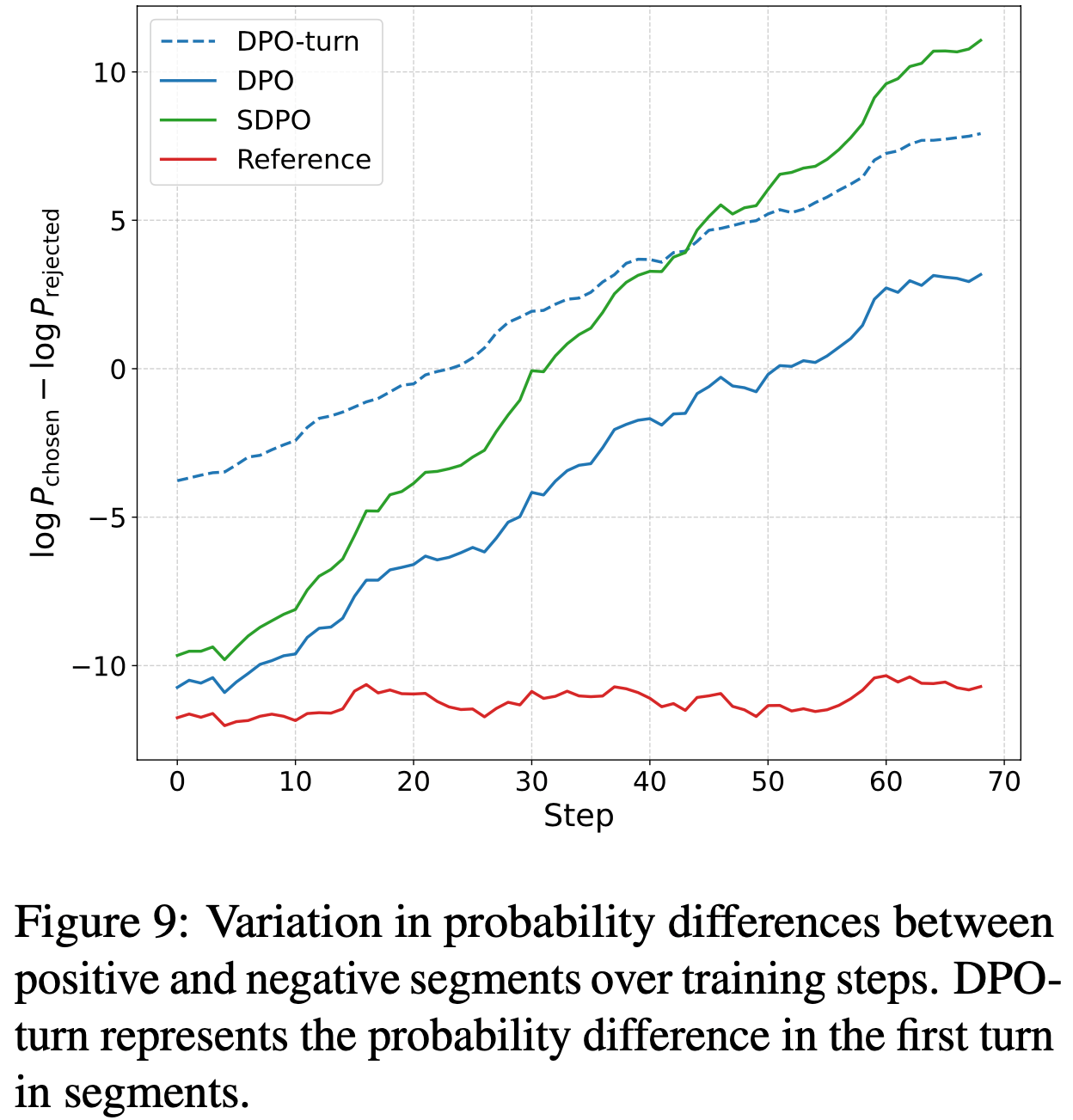
- 一个自然的问题是,SDPO 的性能提升是由于利用了 RLRF 中的丰富反馈,还是由于 SDPO 的密集信用分配?
- 为了回答上述问题,作者在三种配置中进行了 SDPO 性能的消融实验:
- Logit-level SDPO : 在每个位置上对(Student 认为的)最有可能的 100 个 Token 进行信用分配
- Token-level SDPO : 在每个位置上只对最有可能的 Token 进行信用分配
- Sequence-level SDPO : 在整个序列上计算 Generated Token 的 SDPO Advantage 的均值
- 这产生的是每个序列的单个标量 Advantage (如 GRPO 中那样)
- 注:Sequence-level SDPO 并不比 GRPO 执行更密集的信用分配,但仍然利用了丰富的反馈 \(f\)
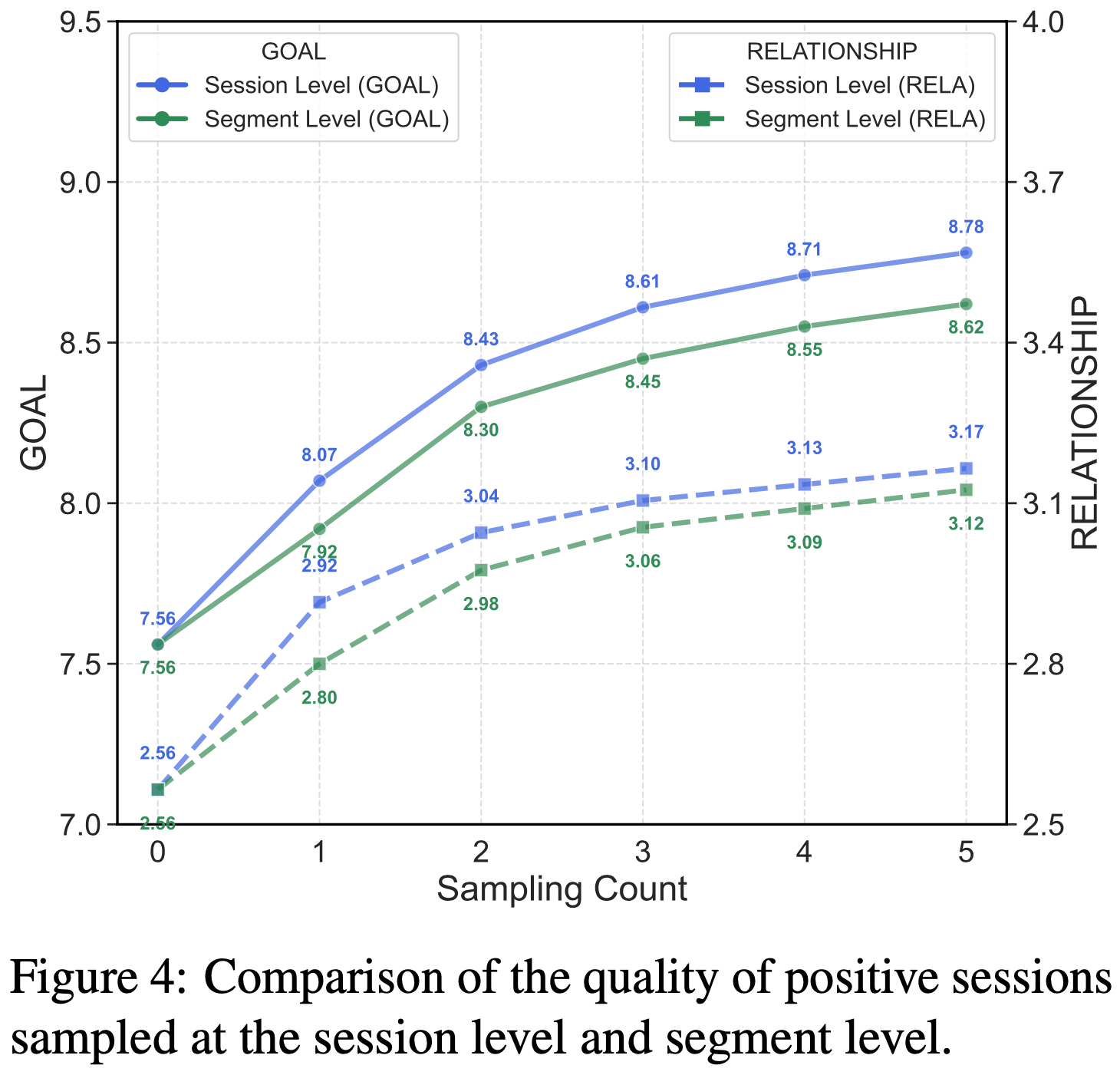
- 如图 10(左)所示,Logit-level SDPO 的密集信用分配带来了比 Token-level SDPO 和 Sequence-level SDPO 显著的性能提升
- 但即使 Sequence-level SDPO 也优于 GRPO
- 这表明即使在没有密集信用分配的情况下,在 RLRF 中利用丰富的反馈也能带来比 RLRV 方法实质性的收益
- 但即使 Sequence-level SDPO 也优于 GRPO
- 图 10:
- 左图: RLRF 中的丰富反馈和 SDPO 的密集信用分配是互补的
- 本文比较了 Logit-level、Token-level 和 Sequence-level 的 SDPO Advantage 与 GRPO
- 虽然 SDPO 中更密集的信用分配是有益的(Logit-level > Token-level > Sequence-level),但即使 Sequence-level SDPO 也因利用了丰富的反馈而显著优于 GRPO
- 误差线表示 3 次随机种子的标准误差
- 右图: Self-Teacher 在训练过程中得到改进
- Self-Teacher 与 Student 相比在当前训练批次上的生成准确率(5 步滚动平均)
- 最终 Student 得分在第 80 步取得
- Student 的性能显著超过了初始 Teacher 的准确率
- 误差线表示 3 次随机种子的标准差
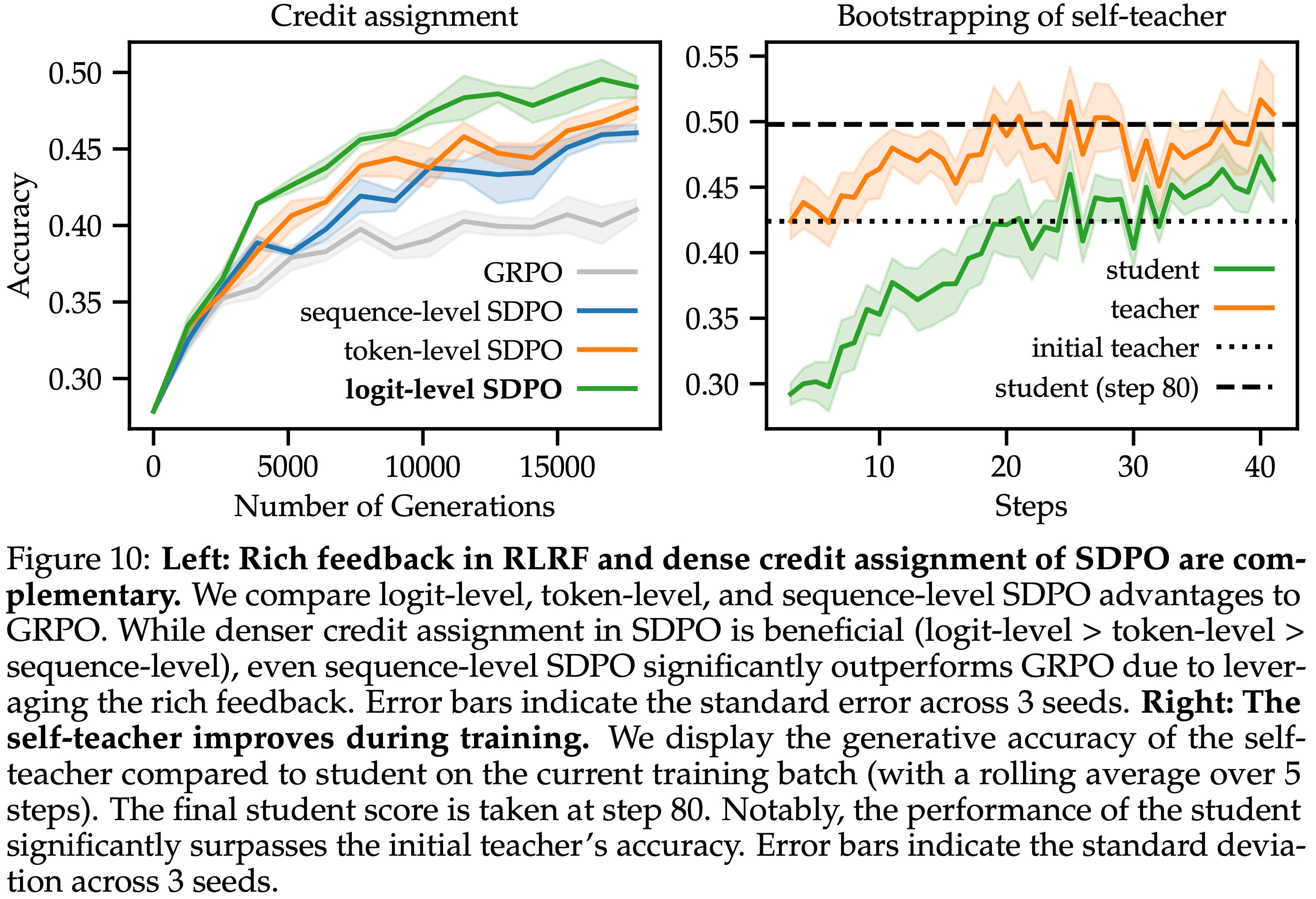
- Self-Teacher 与 Student 相比在当前训练批次上的生成准确率(5 步滚动平均)
- 左图: RLRF 中的丰富反馈和 SDPO 的密集信用分配是互补的
The self-teacher improves during training
- 与标准的蒸馏相反,SDPO 中的 Self-Teacher 不是冻结的,而是在整个训练过程中更新
- 这是 SDPO 的一个关键组成部分,因为它使 Teacher 能够随着时间的推移而改进,这意味着 Student 可以从更强的目标中学习
- 为了研究 Self-Teacher 是否在训练过程中得到改进,本文在图 10(右)中绘制了使用 Self-Teacher 生成时的平均准确率
- Self-Teacher 在训练过程中显著提高
- 最值得注意的是, Student 的在训练的后期阶段, Student 的准确率超过了初始 Teacher 的准确率。这表明 SDPO 能够实现从弱模型到强模型的真正的自举,而不受初始 Self-Teacher 性能对最终 Student 的限制
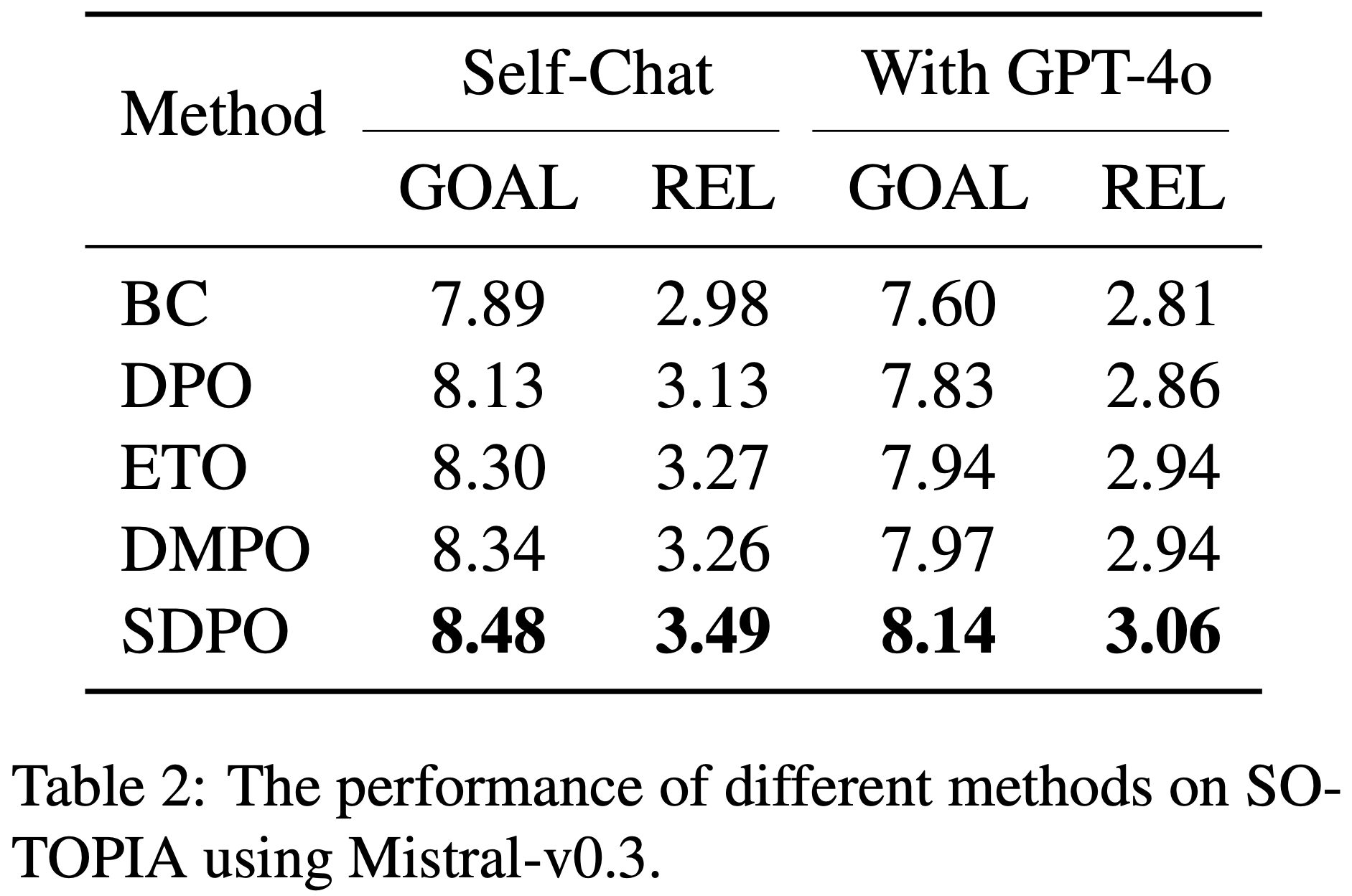
- 表 4: 第 90 步之前各种 Teacher 正则化方法的最佳/平均准确率
- Trust-region 和 EMA Teacher 使用 \(\alpha = 0.01\)。\(q_{\theta}\) 的训练最终发散
- 误差范围表示 3 次随机种子的标准误差
- 如第 2.3 节所述,SDPO 使用正则化的 Teacher 来稳定训练
- 从表 4 可以看出,未正则化的 Teacher 性能显著低于正则化的 Teacher
- 信任区域 (Trust-region) 和 EMA Teacher 的表现优于冻结在初始 Teacher 参数上的 Teacher ,这表明 Teacher 通过与 Student 的参数共享得到了改进
- 即使使用冻结的 Teacher ,SDPO 也表现良好
On-policy self-distillation avoids catastrophic forgetting,OPSD 防止了灾难性遗忘
- 先前的工作表明,On-policy 算法(如 GRPO)的一个关键好处是模型往往不会忘记先前获得的能力 (2026b; 2025b; 2025)
- 这在实践上是可取的,因为它支持持续训练流程,即模型可以在不同任务上顺序训练,而无需从头开始重新训练
- 为了评估遗忘,本文在各种保留任务上测试了 GRPO 和 SDPO 的最终检查点:
- IFEval (2023):测试模型遵循精确格式指令的能力
- ArenaHard-v2 (2025a):基于 LLM 评判的真实世界指令跟随 Prompt 的基准,源自 LMArena (2024)
- MMLU-Pro (2024b):测试广泛的多任务知识和推理能力
- 如表 5 所示,SDPO 在学习新任务的同时减轻了初始能力的退化,总体上实现了比 GRPO 更好的性能-遗忘权衡
- 注:这里看起来 SDPO 相对 GRPO 的提升不太明显
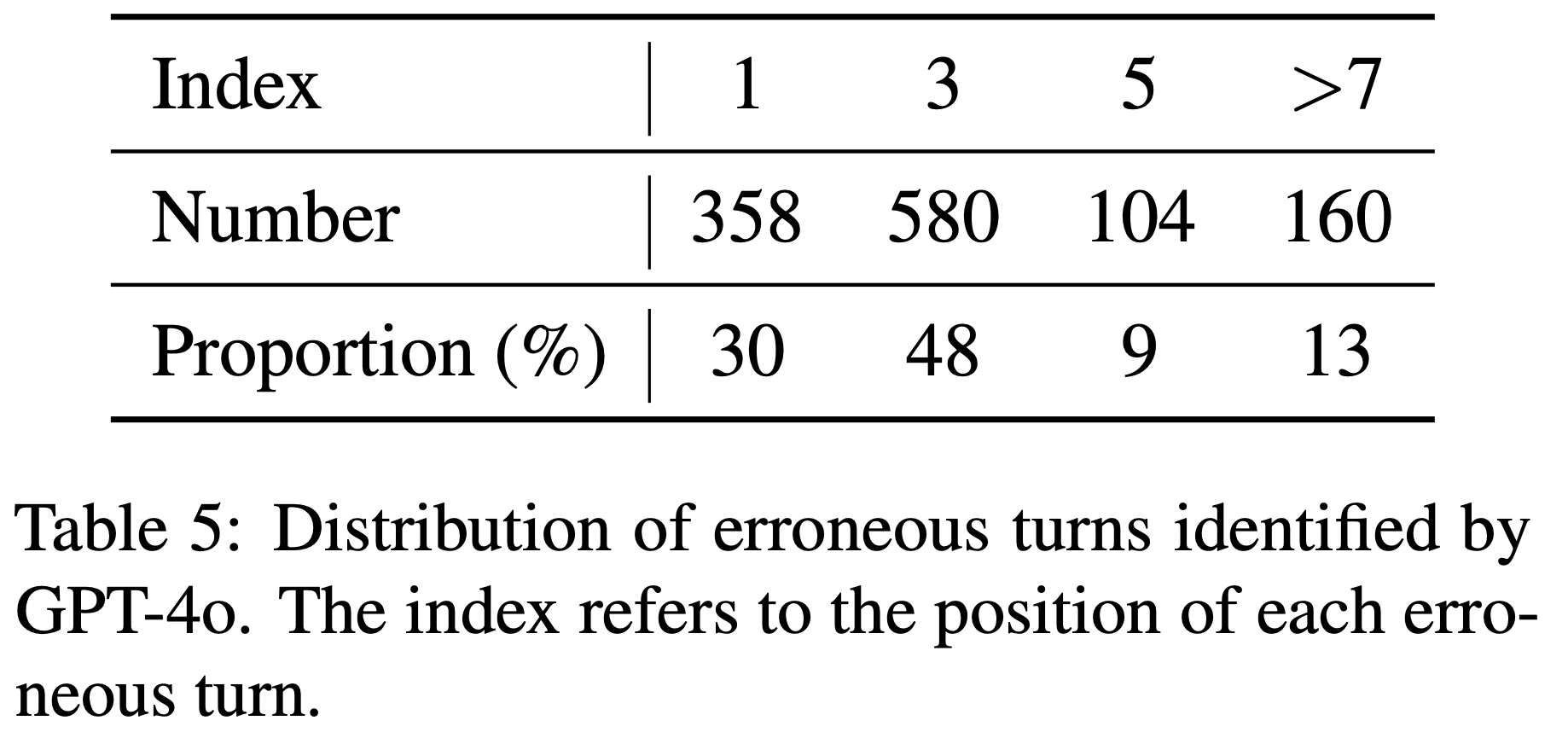
- 注:这里看起来 SDPO 相对 GRPO 的提升不太明显
Off-policy self-distillation baseline
- 作为一个额外的基线,考虑通过 SFT 来训练 Student ,使用来自 Self-Teacher 的成功生成 (2023; 2024; 2025)
- 对于相同数量的步骤,这需要 \(2\times\) 的 SDPO 生成次数,因为必须同时从 Student 和 Teacher 生成
- 本文报告了对 Self-Teacher 的成功生成进行 SFT 的结果
- 这比在 SFT 数据中同时包含来自 Student 的初始成功取得了更高的准确率
- 如表 5 所示,对 Self-Teacher 进行 SFT 在 LCBv6 上的表现显著不如 SDPO,同时导致对先前能力的遗忘更严重
- 这反映了先前关于 Off-policy 模仿不稳定的发现(例如,2024)
Can GRPO and SDPO be combined?
- GRPO 使用蒙特卡洛 Advantage ,这对于最大化期望奖励的目标是无偏的:
$$J(\theta) := \mathbb{E}_{y\sim \pi_{\theta}(\cdot |x)}[r(y|x)]$$ - SDPO Advantage 相对于 \(J(\theta)\) 本质上是有偏的,因为它们是由丰富的反馈和 Self-Teacher 计算得出的
- 这种二分法类似于 RL 中蒙特卡洛和 Bootstrapped Advantage 之间的根本区别:
- 虽然后者有偏,但它们通常具有更低的方差 (1998; 2016)
- 这激发了一种混合方法,结合了从奖励派生的 GRPO Advantage 和从反馈派生的 SDPO Advantage :
$$A_{i,t}^{\text{SDPO + GRPO} }(\hat{y}_{i,t}) := \lambda A_{i,t}^{\text{GRPO} }(\hat{y}_{i,t}) + (1 - \lambda) A_{i,t}^{\text{SDPO} }(\hat{y}_{i,t}), \quad \lambda \in [0,1]. \tag{3}$$
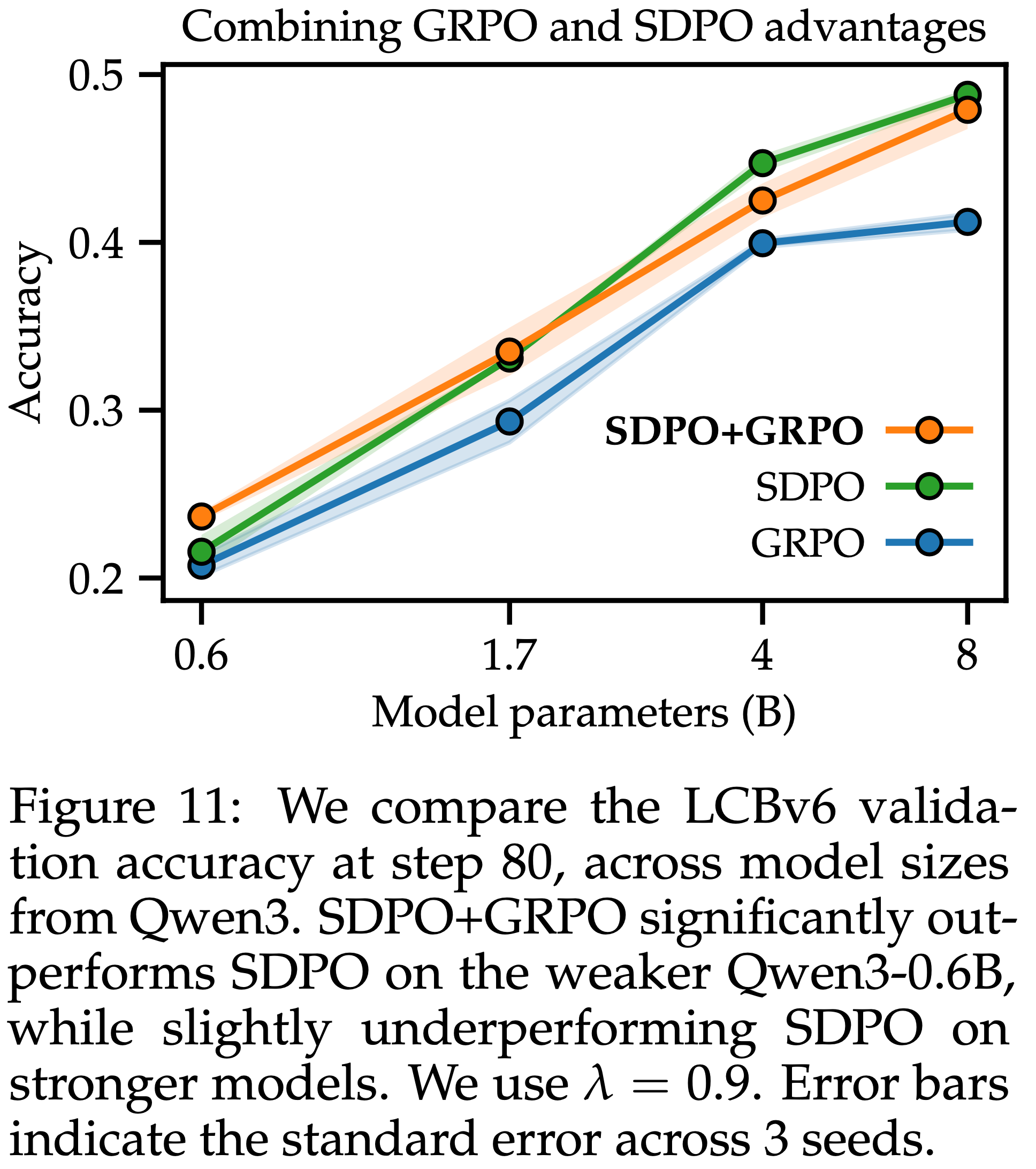
- 如图 11 所示,SDPO+GRPO 在较弱模型上似乎比 SDPO 更鲁棒
- 在像 Qwen3-0.6B 这样的较弱模型中,SDPO Advantage 的可靠性较低,因此包含 GRPO Advantage 有助于稳定训练
- 在像 Qwen3-8B 这样的强模型中,SDPO+GRPO 略逊于 SDPO
- 这表明,仅由标量奖励提供信息的 GRPO 信号,在初始模型较强时可能是有害的
Which feedback is most informative?
- 为了理解哪种类型的丰富反馈信息最丰富,本文消融了在像代码生成这样的可验证环境中存在的三种反馈类型:
- 样本解决方案:仅在当前 Rollout 组中有一个成功的 Rollout 时可用
- 环境输出:例如运行时错误
- Student 的原始尝试
- 问题:Student 的原始尝试没有任何反馈要怎么用?
- 回答:这里只是写出来作为验证,下文会证明这个做法没有用,而且是有害的
Sample solutions
- 在失败尝试的 Rollout 组中包含一个样本解决方案,这与 GRPO 的组相对 Advantage 非常相似
- 注:这些样本解决方案总是由 Student 生成的,就像在 GRPO 中一样,并且不需要专家模型
- 如果模型已经能够解决问题,可以用来抑制不成功的方法
- (但与 GRPO 中所有 Token 都收到相同负 Advantage 不同) Self-Teacher 可以识别特定的错误并提供关于如何修复它们的反馈
Environment output
- 环境输出描述了 Student 尝试后的环境状态
- 这与样本解决方案是互补的,因为即使 Student 以前从未解决过该问题,它也能提供有用的信号(作者将在第 5 节中广泛探讨这种设置)
- 利用环境输出是 RLRF 和 RLVR 设置之间的一个关键区别因素
Student‘s original attempt
- Student 的原始尝试 \(y\) 不必包含在 Teacher 的 Reprompting 模板中
- 事实上,包含它会使 Teacher 偏向于 Student 的尝试(参见表 6)
- 这降低了 Student 分布的熵(特别是在最初不确定的 Token 上),从而减少了探索
- 表 6 中总结了结果,本文评估了对 SDPO 训练的影响以及对 Self-Teacher 的直接影响
- 本文发现环境输出和样本解决方案是互补的,各自提供信息丰富的反馈
- 注:通常,性能对表 2 中 Reprompting 模板的句法变化不敏感

- 表 6 的说明:
- 本文根据 SDPO 训练(直到第 60 步)以及对 Self-Teacher 的直接影响来评估反馈的信息量
- “相同输出” 衡量:Teacher 收到与 Student 初始尝试相同的环境输出的情况百分比(即,不探索替代方法)
- 问题:这句话如何理解?
“Same output” measures the percentage of cases where the teacher receives the same environment output as the student’s initial attempt (i.e., not exploring alternative approaches).
- 环境输出和样本解决方案是互补的,各自提供信息丰富的反馈
- 问题:这句话如何理解?
- 仅包含解决方案或初始尝试 \(y\) 会显著降低 Teacher 和 Student 的多样性
- 样本解决方案是由 Student 生成的,这使得类似于 GRPO 的组相对 Advantage 估计成为可能
- 误差线表示 3 次随机种子的标准差
Solving Hard Questions via Test-Time Self-Distillation
- 第 3 节和第 4 节已证明了 SDPO 能够在推理任务的 “train-time RL” 中显著优于 RLVR 方法
- 本节转向一个 Test-time 设定,其中模型仅被给予一个困难的(二元奖励)问题 \(x\) ,并且必须尽快发现一个解:
- Definition 5.1(Discovery time)
- 发现时间是直到找到解所需的尝试次数(即最小的 \(k\) ,使得第 \(k\) 次尝试 \(y_{k}\) 获得奖励 1)
- 基于这个概念,我们可以定义发现效率的度量:
$$
\begin{align}
\text{discovery@k}:&= \mathbb{P}(\text{discovery time}\leq k)\\
&= \mathbb{P}(r(y_1\mid x) = 1\text{ or }r(y_2\mid x) = 1\text{ or }\ldots \text{ or }r(y_k\mid x) = 1)
\end{align}
\tag{4}
$$- 其中概率覆盖了生成 \(y_{k}\) 的算法以及奖励中的所有随机性
discovery@k度量了在 \(k\) 次内发现解的概率
- 原文中一句难以理解的话:
While prior work has studied discovery with continuous rewards (2025;2026), discovery with language models in sparse or binary-reward settings does not allow “hill-climbing” a continuous reward and has remained less well understood.
- 个人理解:这句话的意思是,在不同环境中,模型学习(Discovery)过程不同:
- 在连续奖励环境 中,模型可通过逐步 优化(“Climbing”) 奖励梯度来逼近最优解
- 在稀疏奖励 或二元奖励 的环境中,语言模型的 “Discovery” 过程无法像在连续奖励环境 中逐步 Climbing
- 个人理解:这句话的意思是,在不同环境中,模型学习(Discovery)过程不同:
- 在二元奖励任务中最朴素发现方法是重复地从基础模型中独立同分布地采样,也称为 best-of-\(k\)
- 用于 best-of-\(k\) 采样的标准
pass@k指标正是从固定模型中进行 \(k\) 次独立采样时至少发现一个解的概率(与discovery@k一致) discovery@k指标将pass@k推广到顺序采样尝试的算法- 一种常见的顺序方法是使用来自先前尝试的额外上下文来 Reprompting 基础模型(2023;2023)
- 这可称为多轮采样(multi-turn) ,此时模型本身并未改变,只有其上下文随时间演化
- 用于 best-of-\(k\) 采样的标准
- 论文中一个核心的 Insight:
- 对问题 \(x\) 执行 RLVR 并不会比从基础模型进行 best-of-\(k\) 采样有所改进
- 因为在第一个解被发现之前,二元奖励不提供任何信号
- 像 SDPO 这样的 RLRF 方法则没有同样的限制,因为它在每次尝试后都会从环境中接收到 Rich Feedback
- 这种 Rich Feedback 使得模型能够在遇到错误并收到反馈后反复“修正”其错误,甚至在发现解之前就能做到
- 与多轮采样相比,SDPO 通过将 \(\pi_{\theta}(\cdot | x, c)\) 蒸馏到模型 \(\pi_{\theta^{\prime} }(\cdot | x)\) 中,反复压缩上下文
$$c = (y_{k}, f_{k})$$- 如图 12 所示
- 这种自蒸馏使得 SDPO 能够在长上下文中持续学习,而 Transformer 的内存瓶颈从根本上限制了多轮采样的上下文长度(2017)
- 对问题 \(x\) 执行 RLVR 并不会比从基础模型进行 best-of-\(k\) 采样有所改进
- 本节试图回答以下问题:通过自蒸馏反复将上下文压缩到模型权重中能否加速困难问题的发现?
Experimental setting
- 本文考虑 LCBv6 中一个特别具有挑战性的子集
- 这些问题是 Qwen3-8B 性能的上限,需要大量的 Test-time 采样才能找到解
- 本文使用 Qwen3-8B 的
pass@k定义了两组任务:- 困难任务 (Hard tasks),其
pass@64 < 0.5 - 非常困难的任务 (very hard tasks),其
pass@64 < 0.03
- 困难任务 (Hard tasks),其
- 在这些任务中,仅保留那些 best-of-\(k\)、多轮或 SDPO 方法在 5 个随机种子的 512 步内至少找到一个解的问题
- 这产生了 19 个困难问题和 9 个非常困难的问题
- 问题:这里的 512 步是指 512 轮交互吗?
- 对于基础模型下的 best-of-\(k\) 采样
- 本文报告来自 2944 次独立 Rollout 的标准
pass@k估计值 (2021b)
- 本文报告来自 2944 次独立 Rollout 的标准
- 对于多轮采样下,使用先前尝试的串联反馈在上下文中顺序地 Reprompting 模型
- 为了保持在 Qwen3-8B 的 40k Token 上下文限制内,本文采用先进先出的滑动窗口,一旦达到最大提示长度(32k Token),就丢弃最早的反馈
- 附录 D 的图 19 中消融了多轮 Reprompting 策略
- 发现:遗忘过去尝试(仅保留过去反馈) 显著优于 保留过去尝试(过去尝试 + 过去反馈)
- 本文使用 16 的 Batch size 评估 SDPO,并在附录 D 的图 19 中消融了这个选择
- 发现:总体性能差异很小,但有点差异
- 较小的 Batch size 有利于在低生成预算下取得改进
- 较大的 Batch size 能产生更稳定的更新,这些更新在运行的后期阶段仍然能够学习解决问题
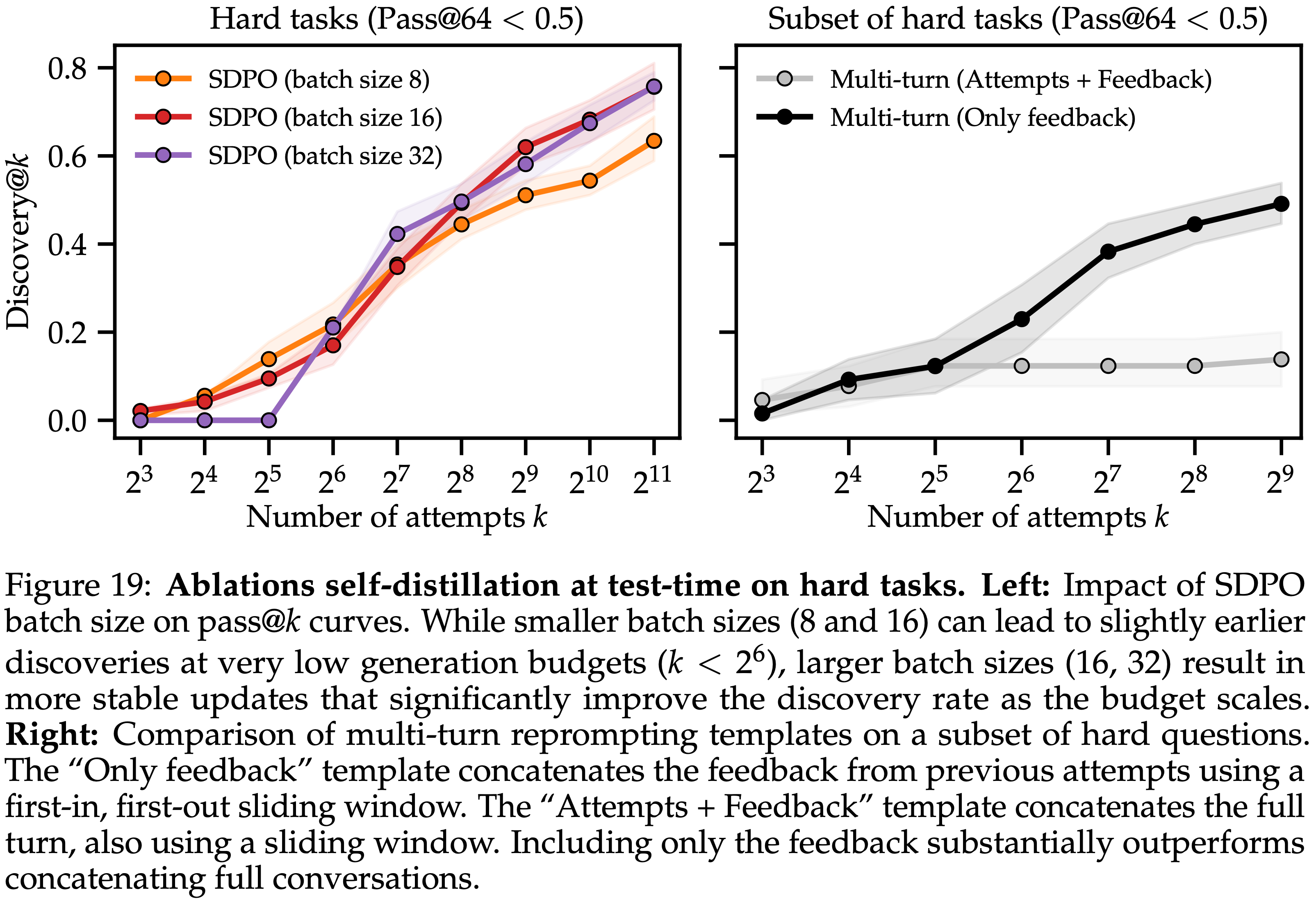
- 发现:总体性能差异很小,但有点差异
Results
- 图 13 比较了 SDPO、多轮采样和 best-of-\(k\) 采样在 LCBv6 的非常困难(左)和困难(右)问题上的
discovery@k- 在几乎所有生成预算下,SDPO 都实现了显著更高的
discovery@k比率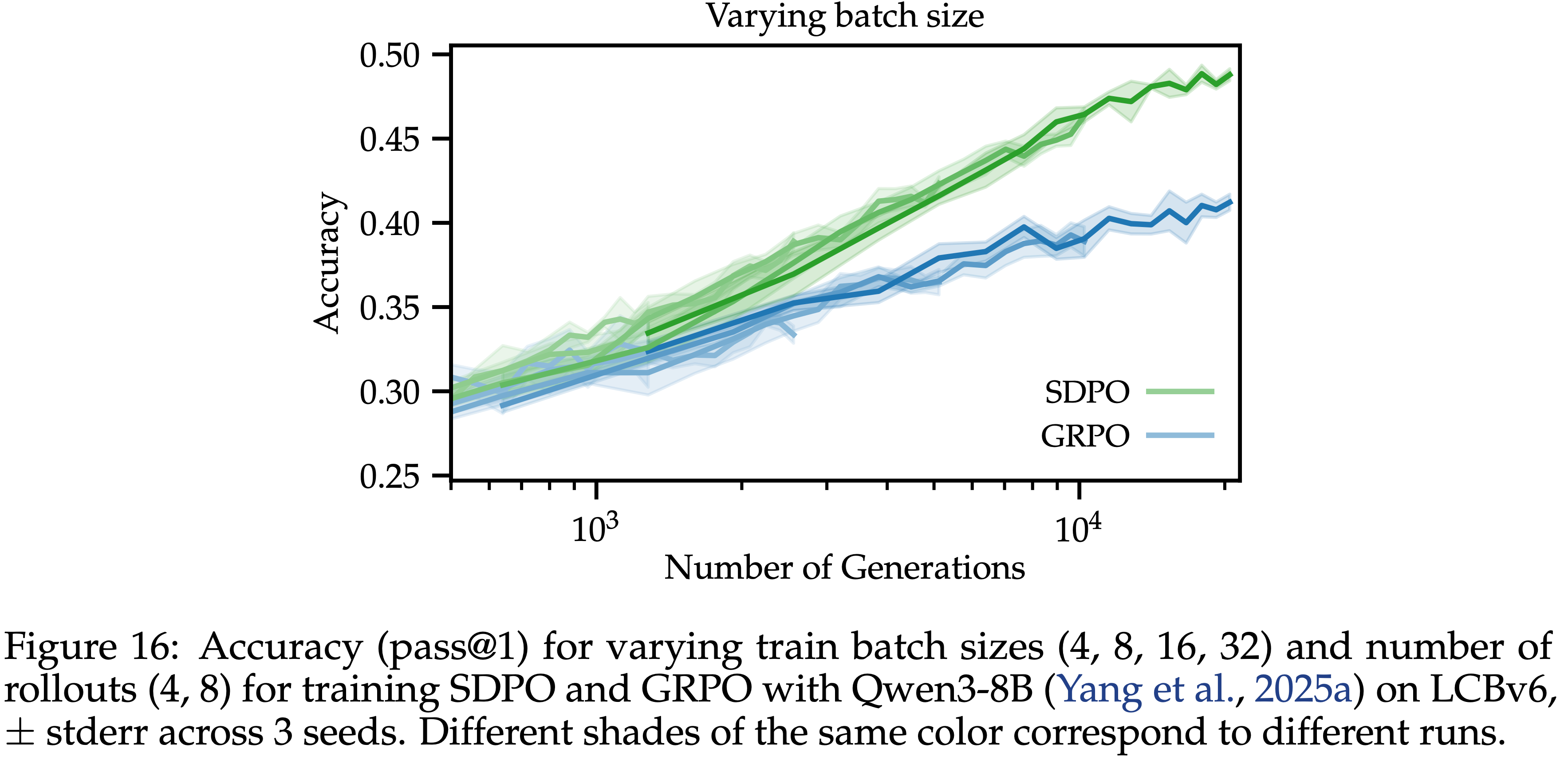
- 在几乎所有生成预算下,SDPO 都实现了显著更高的
- 在非常困难的任务上:
- 多轮和 best-of-\(k\) 在可用的生成预算内很大程度上未能解决问题
discovery@2750分别仅为 \(35.6%\) 和 \(41.5%\)
- SDPO 表现最好
- 在 \(53.2%\) 的情况下发现了解
- SDPO 不仅在总体上解决了更多问题,而且使用的尝试次数也少得多
- 为了在非常困难的问题上达到 \(22%\) 的发现概率,SDPO 所需的生成次数比 best-of-\(k\) 和多轮采样少大约 \(3\times\)
- 多轮和 best-of-\(k\) 在可用的生成预算内很大程度上未能解决问题
- 在困难任务上
- SDPO 达到了 \(78%\) 的
discovery@2750概率- 且以比 best-of-\(k\) 和多轮采样少大约 \(2.4\times\) 的生成次数实现了 \(67%\) 的发现概率
- 多轮和 best-of-\(k\) 采样分别只解决了 \(68.4%\) 和 \(72.3%\) 的问题
- 多轮采样的上下文窗口长度在困难问题的 837 (\(\pm 466\)) 步后和非常困难问题的 1007 (\(\pm 349\)) 步后达到极限
- 这为其在高生成预算下收益递减提供了一个可能的解释
- SDPO 达到了 \(78%\) 的
Question 3 is only solved by SDPO
- SDPO 解决了所有被 best-of-\(k\) 和多轮采样解决的问题,且只有 SDPO 能为 Q3 发现了一个解
- 该问题在 2750 次尝试内既无法通过多轮采样也无法通过 best-of-\(k\) 采样解决
- SDPO 在 321 次尝试后首次为 Q3 发现了一个解
- 这对应于使用 16 的 Batch size 进行 20 次基于反馈的自蒸馏迭代步骤
- 在附录 D 的表 10 中包含了详细的每个问题的结果
The initial self-teacher does not solve hard questions
- 对于几乎所有问题, Self-Teacher 的初始准确率都 \(< 1%\) ,甚至在 \(78%\) 的问题上精确为 \(0%\) (附录 D 的表 11)
- 这表明单轮上下文中的反馈不足以解决问题,但 Self-Teacher 的信用分配对于 SDPO 迭代地精炼策略并最终解决这些问题来说已经足够有效
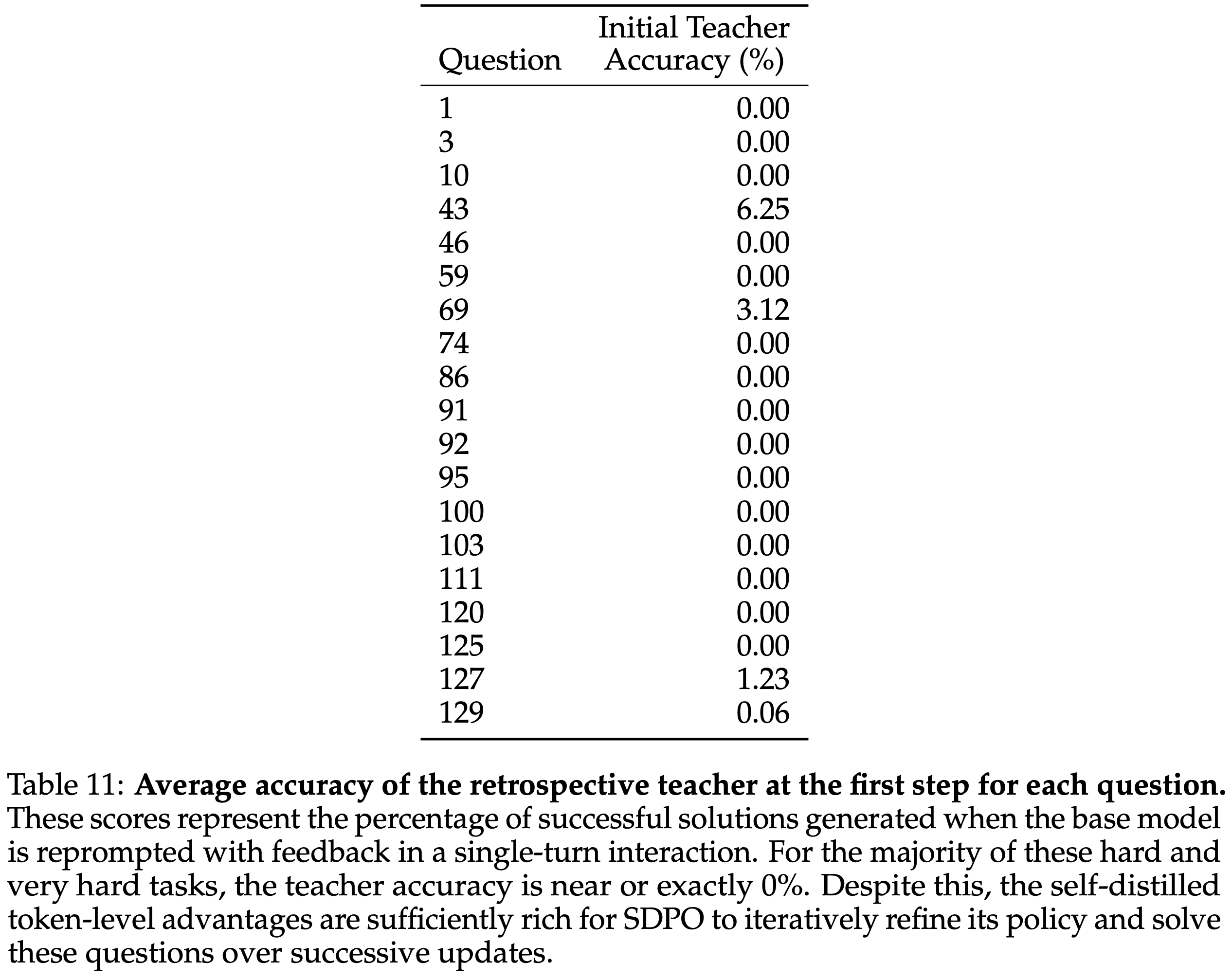
- 这表明单轮上下文中的反馈不足以解决问题,但 Self-Teacher 的信用分配对于 SDPO 迭代地精炼策略并最终解决这些问题来说已经足够有效
Takeaway 3
- 本文证明了丰富的环境反馈使 SDPO 能够显著加速困难问题的发现
- 对比 RLVR:RLVR 方法仅接收二元奖励信号,因此只有在第一个解已经被找到后才能开始学习
Related Work
Reinforcement Learning with LLMs
- LLM 在 RL 上的进展主要得益于使用奖励的蒙特卡洛估计的 RLVR 方法,例如 STaR 或 GRPO (2022;2024),类似于经典的 REINFORCE 算法 (1992)
- 几种传统的 RLVR 算法依赖于学习独立的价值网络 (2017):
- 会带来显著的内存成本
- 存在标量奖励的信息瓶颈
- 几种传统的 RLVR 算法依赖于学习独立的价值网络 (2017):
- RLVR 设定通常(结果)奖励仅在序列结束时给出
- 为了改进信用分配,一些工作学习了过程奖励模型 (PRM),用于估计序列中每一步的奖励 (2023;2024a;2025)
- 与本文 RLRF 设定不同,PRM 通常在标量奖励上进行训练,要么基于中间状态的价值估计,要么基于结果奖励 (2025)
- 与 SDPO 中的 Self-Teacher 也不同,PRM 是与 Student 不同的模型,引入了显著的内存开销
- 本文工作表明,如果给予 Rich Feedback,每个语言模型通过 retrospection 隐式地就是一个 PRM
- 从概念上讲,本文工作与 “bootstrapping your own latent”(BYOL;2020) 和 “expert iteration”(2017) 相关
- 这些方法中 Student 通过反复模仿自身的改进版本(称为 “expert”)来引导自身
- 通常,expert 将 Student 与 Test-time 搜索(如树搜索 (2017) 或多数投票 (2025))相结合
- 本文的 SDPO 利用 Student 从上下文中提供的 Rich Feedback 中学习的能力,这与 BYOL 中的 “augmented views” 相关
- 这些方法中 Student 通过反复模仿自身的改进版本(称为 “expert”)来引导自身
Learning from Rich Feedback and through Retrospection,从 Rich Feedback 和通过 Retrospection 学习
- 除了标量的结果奖励之外,近期工作还利用丰富的执行或口头反馈来指导生成 (2025;2024b;2025)
- 一个主要的研究方向集中在将口头反馈转化为 RL 的奖励函数
- 这通常通过使用外部冻结模型将反馈映射到离散的 Token-level 奖励 (2026),或通过使用强大的外部 LLM 显式构建状态级奖励函数来实现 (2019;2024;2026)
- 也可以在没有显式奖励建模的情况下利用反馈
- 有几种方法专注于上下文中的改进,而没有将这个过程整合到 RL 优化循环中 (2021a;2023;2023;2024;2025;2025)
- 其他方法通过配对反馈前后的 Response 来手动构建偏好数据集,以便使用直接偏好优化进行训练 (2024;2024)
- 但这需要额外的生成,并且缺乏 SDPO 的直接信用分配
- 最近的几项工作从已知答案中引导思考轨迹,使用这些答案作为 Rich Feedback (2026;2026;2025)
- 近期几项工作的核心对象是反馈条件策略 \(\pi_{\theta}(y \mid x, f)\) ,学习能够导致反馈 \(f\) 的答案 \(y\) (2023;2023;2025),通常通过监督目标来实现
- 这些方法背后的思想是部署一个以期望的(即正面的)反馈为条件的策略
- 这种方法在概念上与目标条件 RL (2015;2025a) 相关,在该方法中,可以通过目标重新标记 (2017) 从负例中学习
- 区别:
- 反馈条件策略将反馈视为一个目标
- RLRF 将反馈视为一个状态,可用于确定目标 \(x\) 是否实现
- 总结:与 SDPO 不同,这些方法不使用反馈来对负面轨迹进行信用分配,而是作为目标重新标记的数据转换
Distillation
- 当强大的 Teacher 模型可用时,蒸馏经常被用作 SFT 的替代方案
- 蒸馏通过训练 Student 模仿 Teacher 的输出分布或中间表示来迁移能力 (2015;2015;2016;2019;2020)
- 蒸馏通常是在固定的 Off-Policy 数据集上进行的
- 为了解决训练和推理之间的分布偏移,近期的工作探索了 On-Policy 蒸馏
- Student 从外部 Teacher 对 Student 生成结果的反馈中学习 (2024;2024;2025a;2025)
- 这减轻了训练-测试不匹配的问题,与早期关于在线模仿学习的工作密切相关 (2011)
Self-Distillation
- 自蒸馏的概念首先由 Snell 等人 (2022) 在类似于监督学习的设定中提出,引入了从提供了额外上下文的模型中采样 ,并训练同一模型在没有该上下文的情况下模仿这些预测 的思想
- 这种机制已被证明能有效地将行为 (2022;2022;2024;2025b) 和事实信息 (2026;2025;2025a) 压缩到模型权重中
- 除了将固定上下文压缩到模型权重之外,近期的工作还使用自蒸馏从环境反馈中学习 (2023;2024;2025;2025;2026)
- 这些方法使用 Off-Policy 自蒸馏目标
- 本文发现其性能显著低于 SDPO 的 On-Policy 学习
- Off-Policy 自蒸馏训练 Student 在 Teacher 的生成结果上进行学习
- SDPO 则训练 Student 避免在其自身生成中犯错
- 在同时进行的工作中
- Chen 等人 (2025c) 将 On-Policy 自蒸馏应用于反馈为标量奖励的网格世界环境,并在 Self-Teacher 中设置了一个反思阶段来诊断可能的错误
- · 09o展示了与学习价值网络进行 Advantage 估计相比有所改进的信用分配
- 其他同时进行的工作研究了在固定专家演示数据集上的 SDPO,没有在线环境交互 (2026a;2026)
- Chen 等人 (2025c) 将 On-Policy 自蒸馏应用于反馈为标量奖励的网格世界环境,并在 Self-Teacher 中设置了一个反思阶段来诊断可能的错误
Limitations & Future Work
Limitations
- SDPO 的性能依赖于模型的上下文学习能力
- SDPO 主要适用于 RL 训练较强的基础模型,在较弱的模型上可能不如 GRPO
- SDPO 性能取决于环境反馈的质量
- 如果环境提供的信息不足或具有误导性,模型可能无法通过 SDPO 从中学习
- 与 GRPO 相比,SDPO 在计算回顾性模型的 Logit 概率时增加了少量的计算开销
- 通常可以忽略不计,但对于生成长度较短(生成时间相对较小)的小型模型来说,这可能是一个较大的开销
- 注:此时相对成本会增加
- 通常可以忽略不计,但对于生成长度较短(生成时间相对较小)的小型模型来说,这可能是一个较大的开销
Future Work
Long-horizon and agentic settings
- 当轨迹很长或暴露关于中间状态的信息时,RLRF 尤其具有吸引力
- 在 Agentic 环境中 SDPO 可能会有收益
Training dynamics at scale
- 除了本文在 LiveCodeBench 上的评估之外,可考虑将 SDPO 扩展到大规模的多任务 RL 训练运行,并进一步研究其在前沿基础模型上的扩展特性
Beyond verifiable rewards
- 本文专注于可验证的代码生成,但许多任务提供文本反馈却没有一个 ground-truth 验证器
- 后续可考虑研究 SDPO 的 retrospection 机制能否应用于 开放式文本生成 或 连续奖励任务
Behavioral differences in reasoning
- 实验中看到 SDPO 诱导出与 GRPO 本质上不同的推理模式
- SDPO 避免了 GRPO 倾向于冗长和表面化推理的倾向
- 未来的工作可以系统地研究各个方面的因素(例如 Reprompting 模板)如何影响行为
附录 A:Implementation of SDPO
Figure 14: The pseudo-code of SDPO within a standard RL training pipeline. Omitted here is the filtering to top-K logprobs for student and teacher (including a tail term) as described in Appendix A.3. Further, we omit here any importance sampling weights to correct for off-policy data. reprompt modifies the batch to incorporate teacher context (i.e., rich feedback). divergence implements any per-token divergence such as reverse-KL, forward-KL, or Jensen-Shannon.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def compute_sdpo_loss(batch, teacher_context, loss_mask):
"""
Computes probabilities of response y under the self-teacher
and the per-logit SDPO loss.
"""
# Compute model probabilities for response y
logprobs_student = compute_log_prob(batch) # (T,V)
probs_student = logprobs_student.exp() # (T,V),注:实际上,这一样没有用
# Compute self-teacher probabilities for response y
teacher_batch = reprompt(batch, teacher_context)
logprobs_teacher = compute_log_prob(teacher_batch).detach() # (T,V)
# Compute SDPO loss: per-token divergence
per_token_loss = divergence(logprobs_student, logprobs_teacher) # (T,)
return agg_loss(per_token_loss, loss_mask, loss_agg_mode="token-mean")附录 A 的下文内容包括:
- 本文实现中使用的梯度估计器 (附录 A.1)
- Teacher 正则化 (Teacher regularization) (附录 A.2)
- 通过 top-K logits 近似 logit 蒸馏以节省 GPU 内存 (附录 A.3)
- 将 PPO 风格的策略梯度算法泛化到 Logit-level Advantage (附录 A.4)
为了区分 Self-Teacher 的符号,下文中使用
$$ q_{\theta}(\cdot |x,f):= \pi_{\theta}(\cdot |\text{reprompt}(x,f))$$- 这里,
reprompt表示 Self-Teacher 的重提示模板
- 这里,
A.1 Gradient Estimators
- 本节讨论当前策略 \(\pi_{\theta}(y|x)\) 和 Teacher 策略 \(q_{\theta}(y|x,f)\) 之间 KL 散度的两种可能的梯度估计器
Per-token estimator
- 推导公式 (1) 定义的 SDPO 损失的梯度:
$$\mathcal{L}_{\text{token} }(\theta):= \mathbb{E}_{y\sim \text{stopgrad}(\pi_{\theta}(\cdot |x))}\left[\sum_{t = 1}^{T}\text{KL}(\pi_{\theta}(\cdot |x,y_{< t})||\text{stopgrad}(\pi_{\theta}(\cdot |x,f,y_{< t})))\right] \tag{5}$$ - 得到以下估计器(详细证明见附录 B.1),它对应于每个 token 处 KL 散度的梯度之和:
$$\nabla \mathcal{L}_{\text{token} }(\theta) = \mathbb{E}_{y\sim \pi_{\theta}(\cdot |x)}\left[\sum_{t = 1}^{T}\mathbb{E}_{\hat{y}_{t}\sim \pi_{\theta}(\cdot |x,y_{< t})}\left[\nabla_{\theta}\log \pi_{\theta}(\hat{y}_{t}\mid x,y_{< t})\cdot \log \frac{\pi_{\theta}(\hat{y}_{t}\mid x,y_{< t})}{\pi_{\theta}(\hat{y}_{t}\mid x,f,y_{< t})}\right]\right]. \tag{6}$$ - 这对应于命题 2.1 中提出的估计器
- 该梯度估计器有效地假定了生成 \(y\) 的采样分布是固定的
Sequence-level estimator
- 另一种自蒸馏目标是最小化 Student 和 Self-Teacher 之间的 Sequence-level KL 散度,即:
$$\begin{align} \mathcal{L}_{\text{seq} }(\theta):&= \text{KL}(\pi_{\theta}| q_{\theta}) = \mathbb{E}_{y\sim \pi_{\theta}(\cdot |x)}\left[\log \frac{\pi_{\theta}(y\mid x)}{q_{\theta}(y\mid x,f)}\right]\\
&= \sum_{t = 1}^{T}\mathbb{E}_{s_{t}\sim \Pi_{\theta} }\left[\text{KL}(\pi_{\theta}(\cdot \mid s_{t})| q_{\theta}(\cdot \mid s_{t},f))\right] \end{align} \tag{7}$$- \(s_{t} = (x,y_{< t})\) 是前缀(“状态”)
- \(\Pi_{\theta}\) 表示策略 \(\pi_{\theta}\) 下的前缀分布
- 理解,即zhuangtai状态 \(s_t\) 的分布
- 估计该目标的梯度还会考虑 \(y_{t}\) 的选择如何影响未来的状态 \(y_{> t}\)(由于对 \(\Pi_{\theta}\) 的额外依赖性)
- Amini 等人 (2025) 表明相应的梯度估计器由下式给出:
$$\pmb {\nabla}\mathcal{L}_{\text{seq} }(\theta) = \pmb {\nabla}\mathcal{L}_{\text{token} }(\theta) + \mathbb{E}_{y\sim \pi_{\theta}(\cdot |x)}\left[\sum_{t = 1}^{T}\text{KL}(\pi_{\theta}(\cdot \mid s_{t})| q_{\theta}(\cdot \mid s_{t},f))\pmb {\nabla}_{\theta}\log \Pi_{\theta}(s_{t})\right]. \tag{8}$$ - Sequence-level 梯度的额外项捕捉了前缀如何影响未来 token 的自蒸馏散度
- 本文也实验了这种 Sequence-level 梯度估计器,但没有发现相对于其额外复杂性的可衡量的收益
A.2 Regularized teacher
- 与标准蒸馏不同,SDPO 中的 Teacher 在训练过程中会发生变化
- 这种自举 (bootstrapping) 使得 Teacher 能够改进,但也可能导致训练不稳定
- 为了稳定训练,本文尝试防止 Teacher \(q\) 快速偏离初始 Teacher \(\color{red}{q_{\theta_{\text{ref} } }}\)
- 可以通过对 \(q\) 施加一个明确的信任域约束 (trust-region constraint) (2015; 019) 来实现这一点,即:
$$\sum_{t}\text{KL}(q(y_{t}\mid x,f,y_{< t})| \color{red}{q_{\theta_{\text{ref} } }}(y_{t}\mid x,f,y_{< t}))\leq \epsilon ,\quad \epsilon >0. \tag{9}$$ - 这个信任域可以通过两种方式实现:
- 1)Explicit trust-region: 将 Teacher 定义为在满足信任域约束的同时最接近 \(q_{\theta}\) 的策略,这个 Teacher 可以表示为
$$q(y_{t}\mid x,f,y_{< t})\propto \exp ((1 - \alpha)\log \color{red}{q_{\theta_{\text{ref} } }}(y_{t}\mid x,f,y_{< t}) + \alpha \log q_{\theta}(y_{t}\mid x,f,y_{< t})), \tag{10}$$- 其中 \(\alpha \in (0,1)\) 是信任域约束的逆拉格朗日乘子
- 本文在附录 B.2 中包含了完整的推导
- 可以将这个显式约束的 Teacher 直接代入 SDPO 目标
- 2)Exponential moving average, EMA: 直接稳定 Teacher 的参数
- 将 \(q_{\theta}\) 参数化为 \(\theta^{\prime}\) 并更新为
$$ \theta^{\prime}\leftarrow (1 - \alpha)\theta^{\prime} + \alpha \theta$$- 其中 \(\alpha \in (0,1)\)
- 将 \(q_{\theta}\) 参数化为 \(\theta^{\prime}\) 并更新为
- 1)Explicit trust-region: 将 Teacher 定义为在满足信任域约束的同时最接近 \(q_{\theta}\) 的策略,这个 Teacher 可以表示为
- 每种实现都有不同的实际 Advantage :
- EMA Teacher 需要额外的 GPU 内存来存储 \(\theta^{\prime}\)
- 但不引入任何运行时间开销
- 信任域 Teacher 需要额外的 log-prob 计算与 \(\color{red}{q_{\theta_{\text{ref} } }}\)
- 但如果 \(\theta_{\text{ref} }\) 用于显式的 KL 正则化 ,则不需要额外的 GPU 内存
- EMA Teacher 需要额外的 GPU 内存来存储 \(\theta^{\prime}\)
A.3 Approximate Logit Distillation
- 为了节省 GPU 内存,本文仅对 Student 预测的 top-\(K\) 个 token 进行蒸馏:
$$\begin{aligned}
\mathcal{L}_{\text{SDPO} }(\theta) &= \sum_{t=1}^{T} \text{KL}(\pi_{\theta}(\cdot | x, y_{ < t}) | \text{stopgrad}(q_{\theta}(\cdot | x, f, y_{ < t}))) \\
&\approx \sum_{t=1}^{T} \left[ \sum_{\hat{y}_t \in \text{top}_K(\pi_{\theta})} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \cdot \log \frac{\pi_{\theta}(\hat{y}_t | x, y_{ < t})}{\text{stopgrad}(q_{\theta}(\hat{y}_t | x, f, y_{ < t}))} \\
\quad \quad \quad + \underbrace{\left(1 - \sum_{\hat{y}_t \in \text{top}_K(\pi_{\theta})} \pi_{\theta}(\hat{y}_t | x, y_{ < t})\right) \cdot \log \frac{1 - \sum_{\hat{y}_t \in \text{top}_K(\pi_{\theta})} \pi_{\theta}(\hat{y}_t | x, y_{ < t})}{\text{stopgrad}\left(1 - \sum_{\hat{y}_t \in \text{top}_K(\pi_{\theta})} q_{\theta}(\hat{y}_t | x, f, y_{ < t})\right)}}_{\text{tail}} \right]
\end{aligned}
\tag{11}
$$- top-\(K\) 是相对于 Student 的
- 如果没有 top-K 蒸馏,我们将不得不在内存中保留两份 logits 副本:一份给 Student ,一份给 Teacher
- Top-K 蒸馏避免了几乎所有的内存开销,且不会显著影响性能,因为在每个 Token 点(Step \(t\)),词表中的大部分 token 在并不包含信息
A.4 Off-Policy Training: Generalization to Logit-Level Losses, 泛化到 Logit-level
- 下面的 Token-level Off-policy 损失函数为:
$$\mathcal{L}_{\text{token} }(\theta) := -\color{red}{\frac{1}{\sum_{i=1}^{G} |y_i|}} \sum_{i=1}^{G} \sum_{t=1}^{|y_i|} \color{red}{\min \left( w_{i,t}^{\text{TIS} }, \rho \right)} \min \left( w_{i,t} A_{i,t}, \text{clip}(w_{i,t}, 1 - \varepsilon_{\text{low} }, 1 + \color{red}{\varepsilon_{\text{high} }}) A_{i,t} \right), \tag{12}$$- PPO 风格的裁剪 (clipping) (2017) :
$$ \color{red}{\frac{1}{\sum_{i=1}^{G} |y_i|}} $$ - 截断重要性采样 (truncated importance sampling) (2025):
$$ \color{red}{\min \left( w_{i,t}^{\text{TIS} }, \rho \right)} $$- 其中:
$$ w_{i,t}^{\text{TIS} } := \frac{\pi_{\theta_{\text{old} } }(y_{i,t}|x,y_{i,<t})}{\pi_{\text{rollout} }^{\theta_{\text{old} } }(y_{i,t}|x,y_{i,<t})} $$
- 其中:
clip-higher(2025) 和固定长度归一化 (2025b):
$$ \color{red}{\varepsilon_{\text{high} }} $$- 其中 \(A_{i,t}\) 表示每个 token 的 Advantage ,且
$$
\begin{align}
w_{i,t} &:= \frac{\pi_{\theta}(y_{i,t}|x,y_{i,<t})}{\pi_{\theta_{\text{old} } }(y_{i,t}|x,y_{i,<t})} \\
\end{align}
$$
- PPO 风格的裁剪 (clipping) (2017) :
- 将其扩展到 Logit-level 损失:
$$
\begin{align}
\mathcal{L}_{\text{logit} }(\theta) := -\color{red}{\frac{1}{\sum_{i=1}^{G} |y_i|}} \sum_{i=1}^{G} \sum_{t=1}^{|y_i|} \color{blue}{\sum_{\hat{y}_{i,t} }} &\color{red}{\min \left( \pi_{\theta_{\text{old} } }(\hat{y}_{i,t} | x, y_{i,<t}), \rho \pi_{\text{rollout} }^{\theta_{\text{old} } }(\hat{y}_{i,t} | x, y_{i,<t}) \right)}\\
\cdot &\min \left( w_{i,t}(\hat{y}_{i,t}) A_{i,t}(\hat{y}_{i,t}), \text{clip}(w_{i,t}(\hat{y}_{i,t}), 1 - \varepsilon_{\text{low} }, 1 + \color{red}{\varepsilon_{\text{high} }}) A_{i,t}(\hat{y}_{i,t}) \right)
\end{align}
\tag{13}$$- 其中 \(\hat{y}_{i,t}\) 对位置 \(t\) 处 Rollout \(i\) 的所有可能 token(或 \(\pi_{\theta_{\text{old} } }\) 下最可能的 \(K\) 个 token)求和
- \(\pi_{\theta_{\text{old} } }\) 下最可能的 \(K\) 个 token 详情参见附录 A.3
- TIS (Truncated Importance Sampling) 发生了变化
$$\color{red}{\min \left( \pi_{\theta_{\text{old} } }(\hat{y}_{i,t} | x, y_{i,<t}), \rho \pi_{\text{rollout} }^{\theta_{\text{old} } }(\hat{y}_{i,t} | x, y_{i,< t}) \right)} $$- 这里明确地使用 \(\pi_{\theta_{\text{old} } }\) 下的概率来加权每个 logit,而不是依赖对下一个 token 预测期望的蒙特卡洛估计
- 问题:这里 TIS 为什么相对前面 Token-level 的式子同时乘以了 \(\pi_{\text{rollout} }^{\theta_{\text{old} } }(\hat{y}_{i,t} | x, y_{i,< t})\) ?
- 采样使用的是 \(\pi_{\text{rollout} }^{\theta_{\text{old} } }\),这本身就相当于乘过 \(\pi_{\text{rollout} }^{\theta_{\text{old} } }\) 了吧
- 这里 \(A_{i,t}(\hat{y}_{i,t})\) 是每个 logit 的 Advantage
- 其中 \(\hat{y}_{i,t}\) 对位置 \(t\) 处 Rollout \(i\) 的所有可能 token(或 \(\pi_{\theta_{\text{old} } }\) 下最可能的 \(K\) 个 token)求和
- 注:在本文对 SDPO 的实验中,在 Token-level 而非 Logit-level 应用 TIS 项
附录 B:Theoretical Analysis
- 附录 B.1 推导命题 2.1 中的 SDPO 梯度
- 附录 B.2 推导附录 A.2 中讨论的信任域正则化 Teacher
- 注:同附录 A,下文中使用:
$$ q_{\theta}(\cdot | x, f ) := \pi_{\theta}(\cdot | \text{reprompt}(x, f )) $$reprompt表示 Self-Teacher 的重提示模板
B.1 Proof of Proposition 2.1.
- 令:
$$ A_{t,k} := \log \left( \frac{\text{stopgrad}(q_{\theta}(\hat{y}_t|x,f,y_{ < t}))}{\pi_{\theta}(\hat{y}_t|x,y_{ < t})} \right)$$ - 于是,从上文有 \(\mathcal{L}_{\text{SDPO} }\) 的梯度:
$$
\begin{aligned}
\nabla_{\theta} \mathcal{L}_{\text{SDPO} }(\theta) &= \nabla_{\theta} \sum_{t=1}^{T} \text{KL}(\pi_{\theta}(\cdot | x, y_{ < t}) | \text{stopgrad}(q_{\theta}(\cdot | x, f, y_{ < t}))) \\
&= \nabla_{\theta} \sum_{t=1}^{T} \sum_{\hat{y}_t} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \log \left( \frac{\pi_{\theta}(\hat{y}_t | x, y_{ < t})}{\text{stopgrad}(q_{\theta}(\hat{y}_t | x, f, y_{ < t}))} \right) \\
&= -\nabla_{\theta} \sum_{t=1}^{T} \sum_{\hat{y}_t} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) A_{t,k} \\
&= -\sum_{t=1}^{T} \sum_{\hat{y}_t} \left( \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \nabla_{\theta} A_{t,k} + A_{t,k} \nabla_{\theta} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \right)
\end{aligned}
$$ - 由于有
$$ \nabla_{\theta} A_{t,k} = -\nabla_{\theta} \log \pi_{\theta}(\hat{y}_t | x, y_{ < t})$$- 这是负的得分函数 (score function)
- 使用得分技巧 (score trick)
$$ \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \nabla_{\theta} \log \pi_{\theta}(\hat{y}_t | x, y_{ < t}) = \nabla_{\theta} \pi_{\theta}(\hat{y}_t | x, y_{ < t})$$ - 于是第一项简化为
$$-\sum_{t=1}^{T} \sum_{\hat{y}_t} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \nabla_{\theta} A_{t,k} = \sum_{t=1}^{T} \sum_{\hat{y}_t} \nabla_{\theta} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) = \sum_{t=1}^{T} \nabla_{\theta} \underbrace{\sum_{\hat{y}_t} \pi_{\theta}(\hat{y}_t | x, y_{ < t})}_{=1} = 0.$$ - 因此,\(\mathcal{L}_{\text{SDPO} }\) 的梯度是
$$\begin{aligned}
\nabla_{\theta} \mathcal{L}_{\text{SDPO} } &= -\sum_{t=1}^{T} \sum_{\hat{y}_t} A_{t,k} \nabla_{\theta} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \\
&= -\sum_{t=1}^{T} \sum_{\hat{y}_t} \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \left( A_{t,k} \nabla_{\theta} \log \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \right) \\
&= -\sum_{t=1}^{T} \mathbb{E}_{\hat{y}_t \sim \pi_{\theta}(\cdot | x, y_{ < t})} \left[ A_{t,k} \nabla_{\theta} \log \pi_{\theta}(\hat{y}_t | x, y_{ < t}) \right].
\end{aligned}$$ - 这意味着如果 \(A_{t,k} = \text{stopgrad}\left( \log \frac{q_{\theta}(y_t|x,f,y_{ < t})}{\pi_{\theta}(y_t|x,y_{ < t})} \right)\),则 \(\mathcal{L}_{\text{SDPO} }\) 的梯度等价于上述梯度
B.2 Trust-region Teacher
- 为稳定训练,本文尝试防止 Teacher \(q\) 偏离初始 Teacher \(\color{red}{q_{\theta_{\text{ref} } }}\)
- 可以通过对 Teacher \(q\) 施加一个明确的信任域约束 (2015; 2019) 来实现这一点,即:
$$\sum_{t} \text{KL}(q(y_t | x, f, y_{ < t}) | \color{red}{q_{\theta_{\text{ref} } }}(y_t | x, f, y_{ < t})) \le \epsilon, \quad \epsilon > 0. \tag{14}$$ - 下面本文推导出一个 Teacher \(q\),它满足信任域约束,同时保持接近目标 \(q_{\theta}\)
- 以下优化问题刻画了这样一个 \(q\) (2019):
$$\begin{array}{rl}
& \underset{q\in \Delta}{\arg \max} \sum_{t} \sum_{y_t} q(y_t \mid x, f, y_{< t}) \log \frac{q_{\theta}(y_t \mid x, f, y_{< t})}{\color{red}{q_{\theta_{\text{ref} } }}(y_t \mid x, f, y_{< t})} \\
& \qquad \text{s.t.} \sum_{t} \text{KL}(q(y_t \mid x, f, y_{< t}) | \color{red}{q_{\theta_{\text{ref} } }}(y_t \mid x, f, y_{< t})) \le \epsilon,
\end{array} \tag{15}$$- 其中 \(\Delta\) 表示概率单纯形
- 直观地说,解是满足信任域约束的、最接近 \(q_{\theta}\)(即与 \(q_{\theta}\) 的交叉熵最小)同时最远离 \(\color{red}{q_{\theta_{\text{ref} } }}\)(即与 \(\color{red}{q_{\theta_{\text{ref} } }}\) 的交叉熵最大)的 \(q\)
Proposition B.1.
- 公式 (15) 的解可以闭式表示为
$$q^{*}(y_{t}\mid x,f,y_{< t})\propto \exp ((1 - \alpha)\log \color{red}{q_{\theta_{\text{ref} } }}(y_{t}\mid x,f,y_{< t}) + \alpha \log q_{\theta}(y_{t}\mid x,f,y_{< t})). \tag{16}$$ - Proof
- 为简化符号,在下文中省略条件
- 拉格朗日函数(对于 KL 约束有 \(\lambda \ge 0\),对于归一化有 \(\nu\))为
$$\mathcal{L}(q,\lambda ,\nu) = \sum_{t}\sum_{y_{t} } q(y_{t}) \log \frac{q_{\theta}(y_{t})}{\color{red}{q_{\theta_{\text{ref} }} }(y_{t})} -\lambda \Big( \sum_{y_{t} } q(y_{t}) \log \frac{q(y_{t})}{\color{red}{q_{\theta_{\text{ref} } }}(y_{t})} -\epsilon \Big) + \nu \Big( \sum_{y_{t} } q(y_{t}) - 1 \Big).$$ - 平稳性条件给出,对于所有 \(y_t\)
$$0 = \frac{\partial \mathcal{L} }{\partial q(y_t)} = \log \frac{q_{\theta}(y_t)}{\color{red}{q_{\theta_{\text{ref} } }}(y_t)} - \lambda \Big( \log \frac{q(y_t)}{\color{red}{q_{\theta_{\text{ref} } }}(y_t)} + 1 \Big) + \nu.$$ - 令 \(\alpha := \frac{1}{\lambda}\),于是公式 (15) 的解可以闭式刻画为
$$
\begin{align}
q^{*}(y_t) &\propto \color{red}{q_{\theta_{\text{ref} } }}(y_t) \exp \Big( \alpha \log \frac{q_{\theta}(y_t)}{\color{red}{q_{\theta_{\text{ref} } }}(y_t)} \Big) \\
\qquad &\propto \exp \big( (1 - \alpha) \log \color{red}{q_{\theta_{\text{ref} } }}(y_t) + \alpha \log q_{\theta}(y_t) \big)
\end{align}
$$- \(\color{red}{q_{\theta_{\text{ref} } }}(y_t) \) 变成 \(\exp (\log \color{red}{q_{\theta_{\text{ref} } }}(y_t)) \) 即可推导得到
- 注:Chen 等人 (2025c) 进行了类似的推导,但使用参考策略 \(\pi_{\theta_{\text{ref} } }\)
- 本文作者观察到这比使用参考策略 \(\color{red}{q_{\theta_{\text{ref} } }}\) 表现更差
附录 C:Additional Related Work
Value networks and Monte Carlo advantage estimation
- 一些先前的方法旨在改进信用分配,但面临着与 GRPO 相同的信息瓶颈
- 经典 RL 经常训练价值网络来提供 Token-level Advantage ,但这些网络本身是从标量奖励中学习的 (2016; 2017)
- 而且价值网络会带来显著的计算和内存开销,因此通常不用于训练 LLM
- 其他近期工作通过从原始尝试中的不同位置开始执行额外的生成来估计 Token-level Advantage (2025; 2025b)
- 虽然这可以用比 GRPO 更少的梯度步骤进行学习,但它仍然仅使用标量奖励作为信号,并且需要昂贵的额外生成
Dense credit assignment with a reward model
- 近期几项工作研究了在能够访问外部奖励模型的情况下进行密集(每个 token)奖励分配,通常通过利用奖励模型的内部结构来实现 (2024; 2025b)
- 与此相关的是,Li 等人 (2025b) 认为,通过将下一个 token 预测与离线逆 RL 联系起来,LLM 的 logits 中隐含着一个 Token-level 奖励信号,这实际上为 RL 微调提供了一个无需训练 (training-free) 的奖励模型
Partial observability
- 从经典 RL 的角度来看,LLM 的许多可验证领域本质上是部分可观测的:
- 执行一个 Proposed 解决方案会引发一个潜在的环境状态(例如,失败的测试或 Agent 系统的状态),该状态仅通过丰富的反馈才会显现
- 这与部分可观测马尔可夫决策过程 (POMDP) 的形式化方法一致,其中 Agent 必须在状态观测不完整的情况下行动 (1998; 1998)
- 相反,RLVR 和 RLHF 流程通常会丢弃这个观测通道,并且仅从终端标量奖励或成对偏好中学习
- 从经典 RL 的角度来看,LLM 的许多可验证领域本质上是部分可观测的:
Relation to test-time training
- 本文在第 5 节中的设置可以被视为 Test-time 训练的一个特例
- 其中模型本身在 Test-time 通过自蒸馏进行更新
- 在 Test-time 更新模型被称为 Test-time 训练 (2020; 2025; 2024; 2025; 2025; 2026)
- 与以上提到的工作都不同,自蒸馏使用当前模型的上下文学习能力来在接收反馈后进行信用分配
- 这可以被视为通过将上下文周期性地压缩到模型权重中来模拟长上下文推理
- 本文在第 5 节中的设置可以被视为 Test-time 训练的一个特例
C.1 SDPO as Maximum Entropy RL
- SDPO 目标类似于最大熵 RL (例如,2018) 中的目标,但具有特定的奖励函数选择
Maximum Entropy RL
- Maximum Entropy RL 考虑优化
$$\arg \max_{\theta} \mathbb{E}_{y\sim \pi_{\theta}(\cdot |x)} \left[ \sum_t r(y_t \mid x, y_{ < t}) \right] + \lambda \text{H}[\pi_{\theta}(\cdot \mid x)], \quad \lambda > 0 \tag{17}$$- 其中 \(\pi_{\theta}(y\mid x) = \prod_{t=1}^{T} \pi_{\theta}(y_t \mid x, y_{ < t})\) 且 \(\text{H}[\pi_{\theta}(\cdot \mid x)] = \mathbb{E}_{y\sim \pi_{\theta}(\cdot \mid x)}[-\log \pi_{\theta}(y \mid x)]\) 是策略的熵
- 且 \(r(y_t \mid x, y_{ < t})\) 是一个任意的奖励函数,可能是“密集的”(即每个 token 的)
- 公式 (17) 被称为最大熵 RL
- 已知该目标等价于求解一个变分推理问题,本文接下来将讨论这个问题
- 本文定义一个伯努利随机变量 \(\mathcal{C}\)
- 如果尝试 \(y\) 正确则为 1,否则为 0
- 接着定义其分布为
$$ p(\mathcal{C} = 1 \mid x, y) \propto \exp \left( \frac{1}{\lambda} \sum_t r(y_t \mid x, y_{ < t}) \right)$$- 进一步假设在响应上的“先验”是均匀的,本文可以将在正确性事件条件下的后验表示为
$$\pi^{\star}(y \mid x) := p(y \mid x, \mathcal{C} = 1) \propto p(\mathcal{C} = 1 \mid x, y) \propto \exp \left( \frac{1}{\lambda} \sum_t r(y_t \mid x, y_{ < t}) \right). \tag{18}$$
- 进一步假设在响应上的“先验”是均匀的,本文可以将在正确性事件条件下的后验表示为
- 那么,公式 (17) 等价于最小化与 \(\pi^{*}\) 的 KL 散度:
$$\arg \min_{\theta} \sum_t \text{KL}(\pi_{\theta}(y_t \mid x, y_{ < t}) | \pi^{*}(y_t \mid x, y_{ < t})). \tag{19}$$
SDPO optimizes an implicit reward defined by the teacher
- 公式 (19) 等价于 SDPO 目标 (公式 (1)),其中隐式奖励
$$ r(y_{t} \mid x, y_{< t}) = \log q(y_{t} \mid x, f, y_{< t})$$- 注: \(\lambda = 1\)
- 从这个意义上说,SDPO 可以被视为一种最大熵 RL 算法,其密集奖励通过回顾模型 (retrospective model) 隐式构建
- 这也指出了 SDPO 与逆 RL (2000; 2008; 2023) 的联系,后者的目标是恢复未知的奖励函数
- 在 SDPO 中, Student 学习了由回顾模型定义的隐式奖励函数
附录 D:Additional Results & Ablations
D.1 Learning without rich environment feedback
- 表 7 报告了为每个模型/任务组合选择最优超参数时的结果,表 7 的具体实验细节如下
- 问题:
- 为什么没有数学场景?
- 本文报告了在 1 小时和 5 小时实际训练时间内达到的最高
avg@16 - 梯度更新步骤:
- SDPO 和 on-policy GRPO 每个生成批次执行一个梯度步骤
- GRPO 执行 4 个 off-policy 小批量步骤
- 本文根据 5 小时的准确率为 SDPO 和基线选择最优超参数
- 本文为每个模型和数据集独立执行此选择
- 每次运行在一个包含 4 个 NVIDIA GH200 GPU 的节点上执行
- 包括初始化和验证,每次运行大约需要 6 小时
- 与表 3(为每种方法全局选择最优超参数)不同,表 7 根据 5 小时准确率为每个模型/任务组合单独选择最优超参数
- 注:超参数网格在附录 E.2.1 中描述
- 问题:
- 表 8 比较了 SDPO 和 GRPO 的平均响应长度 (对第 3 节中的任务取平均)
- 两种算法均在 on-policy 设置下进行评估

- 两种算法均在 on-policy 设置下进行评估
- 核心结论:在 without rich environment feedback 的场景中,实验(比如工具调用和材料科学(Materials)等)的结果看,SDPO 训练相同时间得到的效果并没比 On-policy GRPO 和 GRPO 好太多(部分指标甚至没有提升)
D.2 Learning with rich environment feedback
D.2.1 Additional Results
- 图 15 显示了按问题难度分层的 SDPO 和 GRPO 的平均准确率(训练期间直至第 80 步的平均准确率,按难度分层)
- LCB 区分了简单 (easy)、中等 (medium) 和困难 (hard) 问题
- 注:这种问题分类与第 5 节中的不同
- 如图所示,SDPO 在解决中等和困难问题方面显著优于 GRPO
- 突显了丰富反馈对具有挑战性任务的重要性
- 突显了丰富反馈对具有挑战性任务的重要性
- LCB 区分了简单 (easy)、中等 (medium) 和困难 (hard) 问题
- 图 16 比较了在 LCBv6 上训练 GRPO 和 SDPO 时不同的 Training Batch Size 和 Rollout 数量
- 图 17 中展示了使用 Qwen2.5-Instruct (2024) 的额外结果(作为对图 8 所示结果的补充)
D.2.2 Training Stability
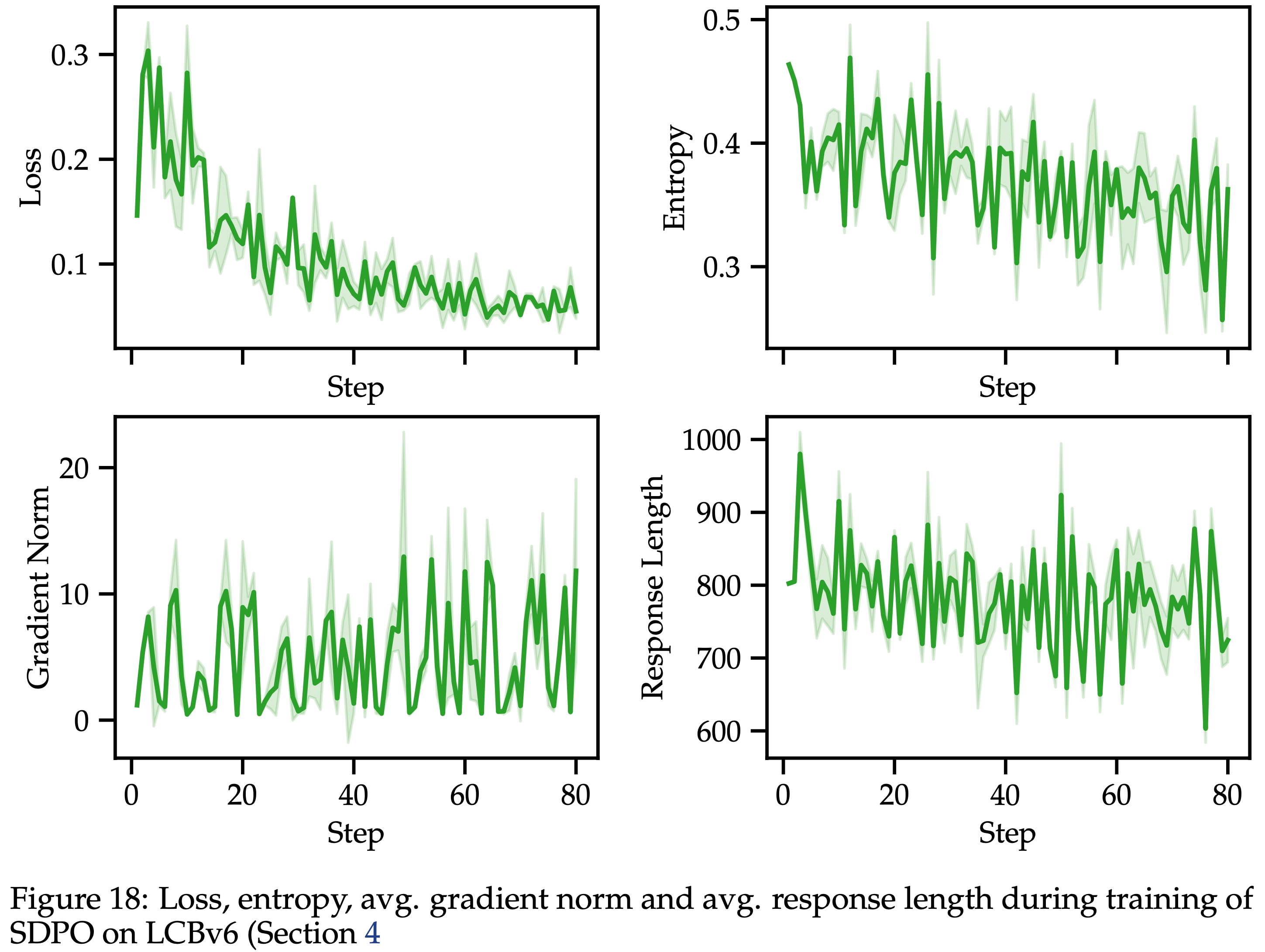
- 图 18 显示了训练期间记录的各种指标
D.2.3 Baselines
- 表 9 比较了 LCBv6 上各种基线的性能,包括 GRPO 的两种变体、GSPO 和 CISPO 与 SDPO(训练到 80 步的结果)
D.3 Test-time self-distillation
- 本节作为对第 5 节所示结果的补充
- 图 20 中展示了所有困难问题的
discovery@k曲线- 注:曲线表示每个问题 5 个随机种子的均值和 90% 置信区间
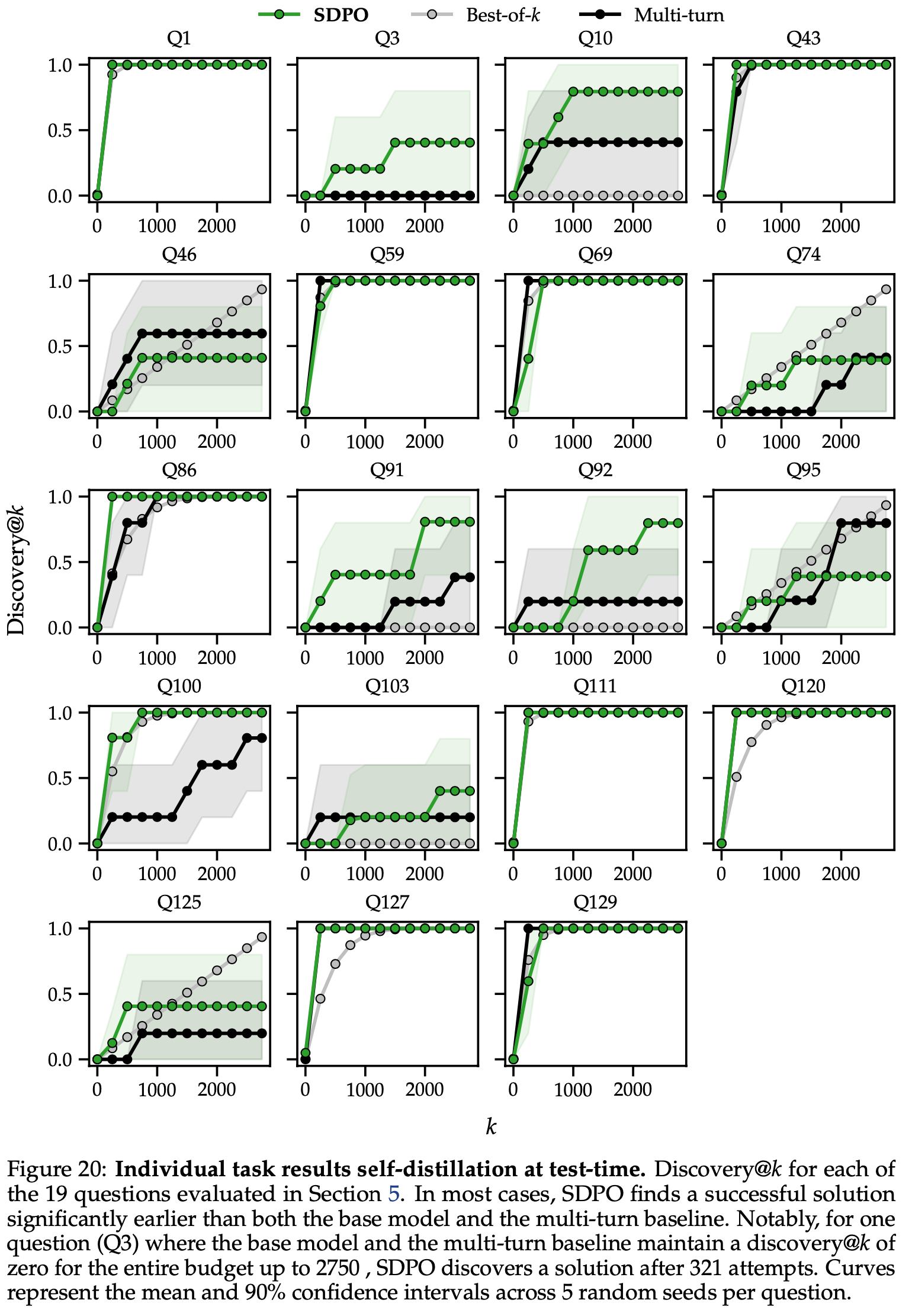
- 注:曲线表示每个问题 5 个随机种子的均值和 90% 置信区间
- 表 10 中报告了首次发现前的平均生成次数(这里的首次发现就是首次成功的尝试)
- 表 11 显示了 SDPO 初始训练步骤中 Self-Teacher 在每个问题上的准确率
- 对于这些困难和非常困难的任务中的大多数, Teacher 的准确率接近或正好为 \(0%\)
- 即便如此自蒸馏的 Token-level Advantage 仍然足够丰富,SDPO 能够迭代地改进其策略,并在后续的更新中解决这些问题
- 图 19 对 SDPO 的 Batch Size 和多轮采样的上下文内重提示策略进行了消融研究
- 左图:SDPO Batch Size 对 pass@k 曲线的影响
- 较小的 Batch Size (8 和 16) 可以在非常低的生成预算下 \((k< 2^{6})\) 导致稍早的发现
- 较大的 Batch Size (16, 32) 会产生更稳定的更新,随着预算的增加显著提高发现率
- 右图:在困难问题子集上多轮重提示模板的比较
- “仅反馈”模板使用先进先出滑动窗口连接来自先前尝试的反馈
- “尝试 + 反馈”模板也使用滑动窗口连接完整的对话轮次
- 仅包含反馈的方法显著优于连接完整对话的方法
- 左图:SDPO Batch Size 对 pass@k 曲线的影响
- 注:在困难问题的筛选中,本文丢弃了一个格式错误的问题 (Q9)
- 因为编码环境由于舍入不准确而无法正确验证解决方案,即使逻辑正确也会导致失败
附录 E:Experiment Details
E.1 Technical setup
- 所有实验均在配备四块 NVIDIA GH200 GPU(总计 378GB 显存)的单个节点上进行
- 每张显卡的显存是 94.5GB ?
- 本文的环境基于 NVIDIA PyTorch 容器 nvcr.io/nvidia/pytorch:25.02-py3 构建,使用 CUDA 12.8 和 PyTorch v2.7.0
- 本文的实现基于 ver1 库 (2025)
- 本文使用 PyTorch 全分片数据并行(FSDP2)进行分布式训练
- 对于 Rollout 生成,本文采用 vLLM (2023),它能在多 GPU 节点上实现高效的批量推理
E.2 Hyperparameters
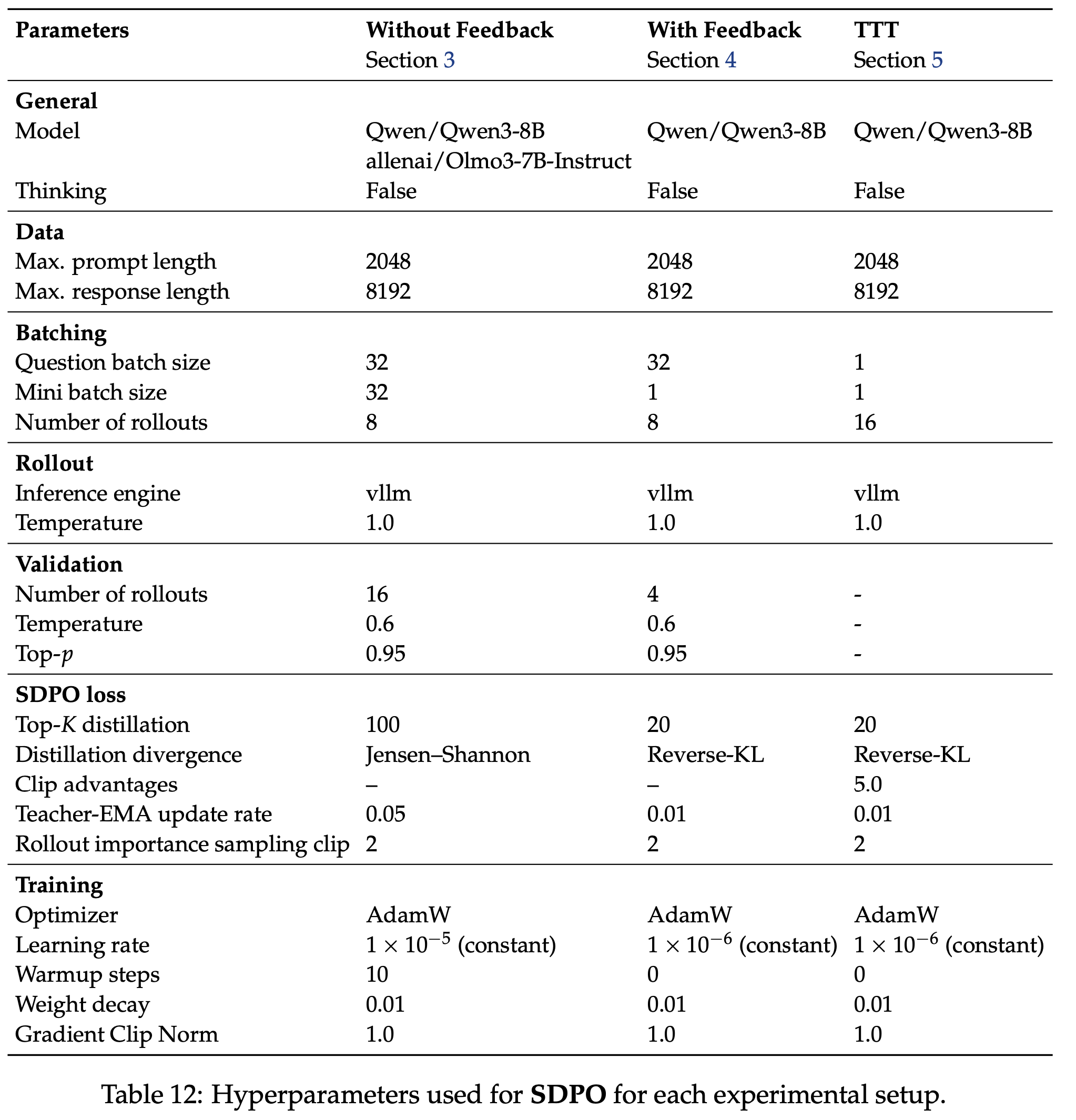
- 表 12 中总结了用于 SDPO 的超参数
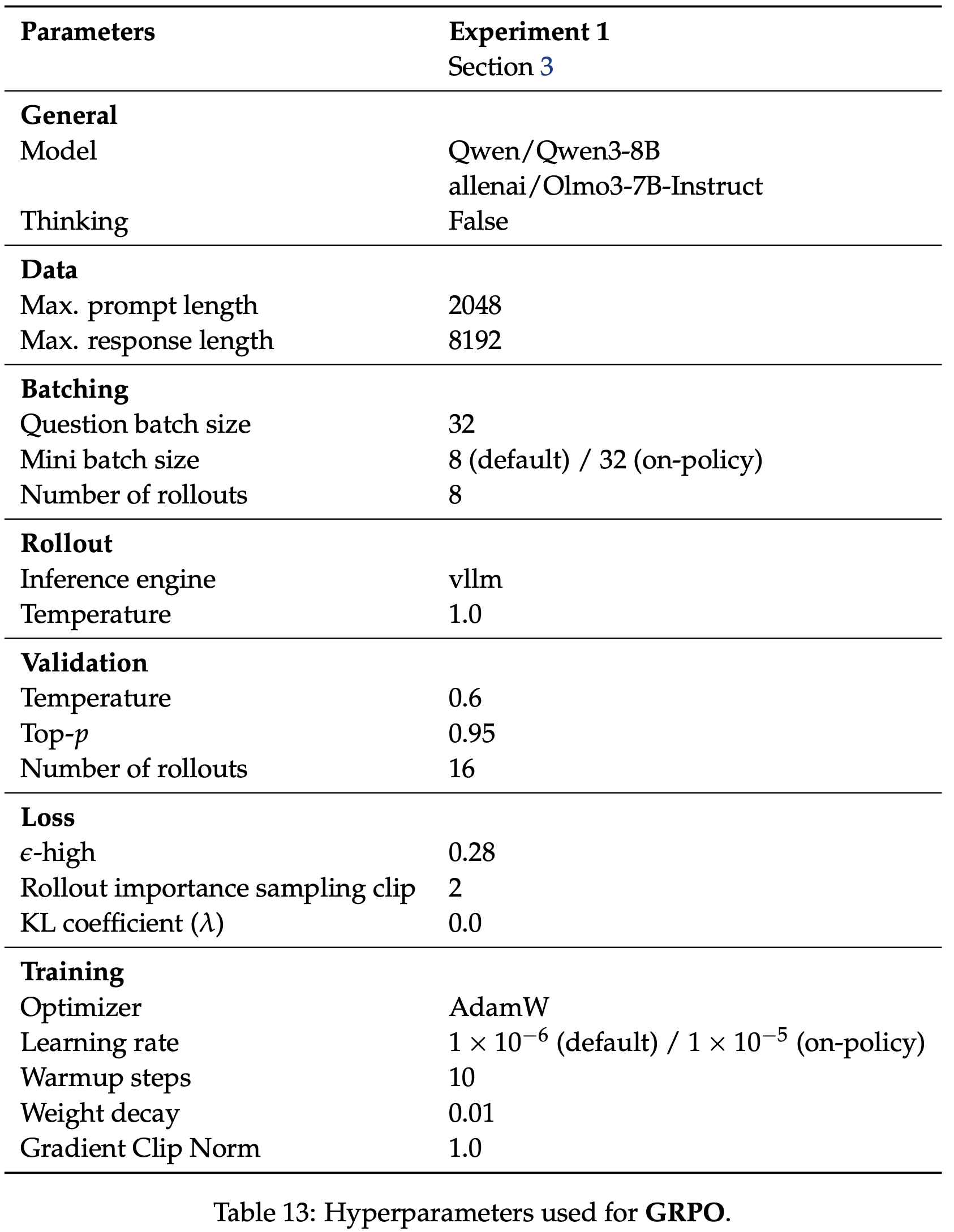
- 表 13 中总结了用于 GRPO 的超参数
- 对于第 3 节的实验,本文对 GRPO 进行了学习率 \(\{10^{-5}, 10^{-6}\}\) 和小 Batch Size {8, 32} 的网格搜索
- 对于 on-policy GRPO,本文在固定小 Batch Size 为 32 的情况下搜索相同的学习率
- 对于 SDPO,本文对 KL 变体(前向 KL,Jensen-Shannon)、学习率 \(\{10^{-5}, 10^{-6}\}\) 和小 Batch Size {8, 32} 进行了网格搜索
- 对于每种方法(GRPO、on-policy GRPO 和 SDPO),本文选择了一个超参数配置,该配置在训练的前 5 小时内,在第 3 节使用的所有数据集和模型上取得了最高的验证准确率
- 表 3 中报告了为每个模型和数据集单独选择最佳超参数配置所获得的结果
E.3 User Templates
对于多项选择题和工具使用,必须以特定于任务的方式提示模型
因此,本文在下面提供了用于这些设置的 Prompt 模板
Listing 1: System prompt: Multiple Choice Questions
1
2
3
4
5
6
7
8
9
10
11
12
13
14Given a question and four options, please select the right answer. Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
For the answer, only output the letter corresponding to the correct option (A, B, C, or D), and nothing else. Do not restate the answer text. For example, if the answer is "A", just output:
<answer>
A
</answer>Listing 2: User prompt: Multiple Choice Questions
1
{question} Please reason step by step.
Listing 3: Example user prompt: Tool use
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33Your task is to answer the user's question using available tools. You have access to the following tools:
Name: Axolotl
Description: Collection of axolotl pictures and facts
Documentation:
getRandomAxolotlImage: Retrieve a random axolotl image with information on the image source.
Parameters:
Output: Successful response.
- Format: application/json
- Structure: Object{url, source, description}
SearchAxolotlImages: Search for axolotl images based on specific criteria such as color, gender, and size.
Parameters:
{"color": "string. One of: [wild, leucistic, albino]. The color of the axolotl (e.g., 'wild', 'leucistic', 'albino', etc.)",
"gender": "string. One of: [male, female]. The gender of the axolotl ('male', 'female')",
"size": "string. One of: [small, medium, large]. The size of the axolotl ('small', 'medium', 'large')",
"page": "integer. The page number for pagination purposes."}
Output: Successful response.
- Format: application/json
- Structure: Object{results: Array[Object{url, source, description}], pagination: Object{current_page, total_pages, total_results} }
getAxolotlFacts: Retrieve interesting facts about axolotls such as their habits, habitats, and physical characteristics.
Parameters:
{"category": "string. One of: [habits, habitat, physical characteristics]. The category of facts to retrieve (e.g., 'habits', 'habitat', 'physical characteristics')",
"limit": "integer. The maximum number of facts to return."}
Output: Successful response.
- Format: application/json
- Structure: Array[Object{fact, source}]
Use the following format:
Thought: you should always think about what to do
Action: the action to take, should be one of the tool names.
Action Input: the input to the action, must be in JSON format. All of the action input must be realistic and from the user.
Begin!
Question: Hey, can you show me a random picture of an axolotl?
附录 F:Qualitative Examples
F.1 Visualization of Advantages
- 图 21 在一个代表性示例中比较了 SDPO 和 GRPO 的 Advantage
- SDPO 和 GRPO 中 Advantage 的可视化,使用 Olmo3-7B-Instruct,在第 3 节化学任务的一个批次中
- 每一行对应一个 Response 的开头
- 颜色表示该 Token 位置的 Advantage 值
- 蓝色表示正 Advantage
- 红色表示负 Advantage
F.2 Examples
- 下面是一个使用 Qwen3-8B 在 LCBv6 上训练 SDPO 的示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142[Prompt]
You are a coding expert. You will be given a coding problem, and you need to write a correct Python program that matches the specification and passes all tests. The time limit is 1 second. You may start by outlining your thought process. In the end, please provide the complete code in a code block enclosed with "``` ```".
You are given a binary string s of length n, where:
'1' represents an active section.
'0' represents an inactive section.
You can perform at most one trade to maximize the number of active sections in s. In a trade, you:
- Convert a contiguous block of '1's that is surrounded by '0's to all '0's.
- Afterward, convert a contiguous block of '0's that is surrounded by '1's to all '1's.
Return the maximum number of active sections in s after making the optimal trade.
Note: Treat s as if it is augmented with a '1' at both ends, forming t = '1' + s + '1'. The augmented '1's do not contribute to the final count.
Example 1:
Input: s = "01"
Output: 1
Explanation: Because there is no block of '1's surrounded by '0's, no valid trade is possible. The maximum number of active sections is 1.
Example 2:
Input: s = "0100"
Output: 4
Explanation:
String "0100" -> Augmented to "101001". Choose "0100", convert "101001" -> "100001" -> "111111". The final string without augmentation is "1111". The maximum number of active sections is 4.
Example 3:
Input: s = "1000100"
Output: 7
Explanation:
String "1000100" -> Augmented to "110001001". Choose "000100", convert "110001001" -> "110000001" -> "111111111". The final string without augmentation is "1111111". The maximum number of active sections is 7.
Example 4:
Input: s = "01010"
Output: 4
Explanation:
String "01010" -> Augmented to "1010101". Choose "010", convert "1010101" -> "1000101" -> "1111101". The final string without augmentation is "111110". The maximum number of active sections is 4.
Constraints:
1 <= n == s.length <= 10^5
s[i] is either '0' or '1'
Your solution should have the following signature: "python def maxActiveSectionsAfterTrade(s: str) -> int:"
[Response]
<think>
</think>
To solve this problem, we need to understand the structure of the string and the trade operation. Here's the plan:
### Key Insights:
1. We are given a binary string 's', and we are allowed **at most one trade**.
2. A **trade** consists of two steps:
- Convert a contiguous block of '1' that is **surrounded by '0'** into '0' (i.e., flip it).
- Then convert a contiguous block of '0' that is **surrounded by '1'** into '1' (i.e., flip it).
3. The actual count of active sections is the number of '1' characters **after** the trade. The augmented '1' at the beginning and end do not count in the final result.
### Strategy:
- We simulate the trade by considering each possible way to flip a block of "1" (bounded by "0") and then a block of "0" (bounded by "1").
- For each possible valid block, simulate the trade and compute the resulting number of "1" characters.
- We only need to consider the original string "s", not the augmented one (since we can simulate the trade directly on "s" by checking boundaries).
We'll use a sliding window technique to find contiguous blocks of "1" and "0" and simulate the trade.
### Implementation Steps:
1. Simulate the trade by checking for a block of "1" surrounded by "0" or at the edges (we simulate the augmented "1" at both sides).
2. For each such block, simulate converting it to "0", then convert a "0" block (again, surrounded by "1") to "1".
3. Count the number of "1" in the final string and track the maximum.
### Python Code:
'''python
def maxActiveSectionsAfterTrade(s: str) -> int:
if not s:
return 0
max_ones = 0
n = len(s)
# We are simulating the augmented "1" on both ends, so we treat the boundaries as '1's
# So '0' at index 0 or n-1 is considered surrounded by '1's
# Step 1: Find all candidate positions for the first part of the trade
# (convert a block of 1s surrounded by 0s into 0s)
for i in range(n):
if s[i] == '1':
start = i
while i < n and s[i] == '1':
i += 1
end = i - 1
# Check if this block is surrounded by '0's
left_boundary = (start == 0 or s[start - 1] == '0')
right_boundary = (end == n - 1 or s[end + 1] == '0')
if left_boundary and right_boundary:
# This is a candidate block of '1's to flip
# Now, look for a block of '0's surrounded by '1's in the remaining string
# Replace the '1' block with '0's
# Now find a '0' block surrounded by '1's
# We can simulate the remaining string
temp = list(s)
for j in range(start, end + 1):
temp[j] = '0'
# Now find a contiguous block of '0's surrounded by '1's
max_trade_ones = 0
for k in range(n):
if temp[k] == '0':
start0 = k
while k < n and temp[k] == '0':
k += 1
end0 = k - 1
# Check if this block is surrounded by '1's
left0 = (start0 == 0 or temp[start0 - 1] == '1')
right0 = (end0 == n - 1 or temp[end0 + 1] == '1')
if left0 and right0:
# Flip this block of '0's to '1's
for j in range(start0, end0 + 1):
temp[j] = '1'
# Count the number of '1's
count = sum(temp)
max_ones = max(max_ones, count)
break # Only take the first valid block for this trade
# After trying this '1' block, restore the original string
# No need, we just used a copy
return max_ones
'''
#### Optimization Note:
The above approach is **not optimal** for very large strings. A more efficient method would involve precomputing the positions of blocks of '1' and '0', and checking valid trades between these blocks in linear time.
But with the constraints given (up to 10^5), we need to ensure linear or near-linear performance. The current code is correct but **not efficient** for large inputs.
Would you like me to provide a more optimized version that runs in **O(n)** time and uses only one pass through the string?
[Feedback]
b'Runtime Error\nTypeError: unsupported operand type(s) for +: \'int\' and \'str\'\nLine 48 in maxActiveSectionsAfterTrade (Solution.py)\n\nLast Executed Input\n"11000"'
F.3 Environment Feedback
本文在代码环境中展示了三个反馈示例,灵感来自 LeetCode
Listing 4: Example of feedback “Wrong Answer” from our code environment in case of a wrong answer, inspired by LeetCode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Test Case 3: Wrong Answer
Input
[[3,6,1],[4,21,4]]
Output
6
Expected
22.87500
Test Case 6: Wrong Answer
Input
[[12,25,3],[3,14,2]]
Output
14
Expected
25.83333Listing 5: Example of feedback “Memory Error” from our code environment in case of a wrong answer, inspired by LeetCode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Runtime Error
MemoryError:
Line 91 in <module> (Solution.py)
Line 25 in solve (Solution.py)
Last Executed Input
10
633 9312
1314 8548
8857 1062
6410 3289
8594 1263
8549 733
3858 5973
(3 more lines)Listing 6: Example of feedback “Index Error” from our code environment in case of a wrong answer, inspired by LeetCode
1
2
3
4
5
6Runtime Error
IndexError: list index out of range
Line 28 in sortMatrix (Solution.py)
Last Executed Input
[[-1,-1,-1,-1,-1,-1,-1,-2,-1,-1,-1,-1,-1,-1,-
F.4 Illustrative Example,说明性示例
- 图 22 展示了 SDPO 中密集信用分配的一个说明性示例
- 图 22 为通过 SDPO 中的自教学进行密集信用分配
- 答案由模型(Qwen3-8B)在看到反馈之前生成
- 在看到反馈后,用 Self-Teacher 重新评估原始尝试的 log-prob
- 本文展示了每个 Token 的
$$ \log (\frac{\text{P}(\text{self-teacher})}{\text{P}(\text{student})})$$- 红色表示负值( Self-Teacher 不同意)
- 蓝色表示正值( Teacher 强化)
- 白色表示接近于零的值
- 奖励分配:
- GRPO 使用二元奖励,且会给序列中的所有 Token 分配相同的负 Advantage
- SDPO 将反馈转化为序列上的密集信用分配
- 第一行显示生成的 Response 的 Token
- 其他 3 行显示 Self-Teacher 用于自蒸馏的 top-\(k\) logits,暗示了替代 Token
- 理解:这里的三行表示每个 Token 位置最可能得前三个候选 Token
- 在这个例子中, Self-Teacher 通过回溯识别了错误,而没有明确的解决方案
- 对生成序列的信用分配,以及替代的 top-\(k\) logits,正确表明将 set 替换为 dict 可以保持元素的顺序
- 在第七个显示的位置,模型还识别了一个替代的解决方案路径,该路径从已看到的 Token 开始,而不是直接返回输出
- 激活是稀疏的,识别出错误发生的位置,并专门针对这几个 Token 调整 Student 的 Response 分布

- 激活是稀疏的,识别出错误发生的位置,并专门针对这几个 Token 调整 Student 的 Response 分布