注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 前置问题:Token-level OPD 跟 Sampled-Token Comparison(Sampled-Token OPD) 本身是不等价的
- Sampled-Token OPD 强调的是:
- 在估计每个位置的 KL 散度时,只使用学生实际采样出来的那一个 Token ,而不是对整个词表做求和或期望
- 这是一种估计方式的刻画
- Sampled-Token OPD 的反面是对全词表求和
- Token-level OPD 强调的是:
- 在计算当前 Token \( y_t \) 的梯度时,只使用当前位置的即时奖励 \( r_t \) ,而不使用未来的奖励信号 \( r_{t+1}, r_{t+2}, \dots \)
- 这是一种梯度结构的刻画
- Token-level OPD 的反面是计算当前 Token 梯度时,考虑未来的奖励
- 这两个概念在逻辑上是正交的,但本文中似乎认为 Token-level OPD 中包含了 Sampled-Token OPD
- 在最早的 OPD 博客中(或者说传统的 OPD)既是 Sampled-Token OPD,也是 Token-level OPD
- 因为传统的 OPD 仅不考虑未来 Token 的奖励,且仅仅针对 Sampled-Token 计算梯度(估计 KL 时不考虑词表中的其他 Token)
- Sampled-Token OPD 强调的是:
- 本文的中心是:长 horizon 后训练中的 OPD
- 在长 horizon 设定下,常见的 Sampled-token OPD 变体非常脆弱:
- Sampled-token OPD 变体将分布匹配简化为单 Token 信号
- 当 Rollout 偏离 Teacher 经常访问的前缀时,会变得愈发不可靠
- 理解:这里其实没有问题吧,无论如何,我们的目标都是让 Student 的分布更贴近 Teacher 的分布,并不一定要 Rollout 是 Teacher 会经常访问的
- Insight:
- 理论上, Token-level OPD 相对于 Sequence-level 反向 KL 是有偏的,但其最坏情况下的方差界要紧得多
- 实验证明:更强的未来奖励耦合会产生更高的梯度方差和更不稳定的学习
- 实验上,本文识别出 Sampled-token OPD 的三种失效模式:
- 不平衡的单 Token 信号
- 在 Student 生成的前缀上不可靠的 Teacher 指导
- 由 Tokenizer 或 Special-Token 不匹配导致的失真
- 理论上, Token-level OPD 相对于 Sequence-level 反向 KL 是有偏的,但其最坏情况下的方差界要紧得多
- 本文通过 Teacher Top-K 局部支持匹配(teacher top-K local support matching)来解决这些问题
- Teacher Top-K 局部支持匹配方法通过 Top-\(p\) Rollout 采样和 Special-Token 掩码实现为截断的反向 KL
- 在单任务数学推理和多任务 Agentic-plus-math 训练中,该目标函数比 Sampled-token OPD 产生了更稳定的优化和更好的下游性能
Introduction and Discussion
- On-policy distillation (OPD) 在由 Student 自身的 Rollout 上进行训练,同时使用更强的 Teacher 模型评估局部反馈
- OPD 在长 horizon 推理和 Agentic 后训练中颇具吸引力,因为在这些场景中 Student 很快会到达在固定 Teacher 轨迹中罕见或缺失的前缀 (2024; 2024)
- 理解:这里是说 OPD 本身是从 Student 自身采样的轨迹中学习的,相对于固定的 Teacher(类似 SFT)的场景,更不容易陷入
- 实际的问题不在于原则上 On-policy Teacher 监督是否有用,而在于训练由 Student 生成的轨迹驱动时,Teacher 监督目标函数仍然是可靠的
- 理解:这里是说在 On-policy 采样轨迹下,使用 Teacher 的监督信号是有效的
- OPD 在长 horizon 推理和 Agentic 后训练中颇具吸引力,因为在这些场景中 Student 很快会到达在固定 Teacher 轨迹中罕见或缺失的前缀 (2024; 2024)
- 目前 LLM 中的 OPD 通常实现为 Sampled-token Comparison:
- 在每个解码步骤, Student 仅通过其 Sampled-token 上的对数比率进行更新
- 理解:Sampled-token Comparison 表示这里本质是一种比较,而不是一种估计
- 这种近似计算成本低,但至少存在下面三个问题(导致训练变得脆弱)
- Sampled-token OPD 将分布级别的差异变成了一个高度不平衡的单 Token 信号
- Sampled-token OPD 可能在 Student 常见但 Teacher 不常见的前缀上过度信任 Teacher
- Sampled-token 很容易因 Tokenizer 或 Special-Token 不匹配而失真
- 存在一个相应的估计器权衡:
- 一个更序列耦合的目标函数可以恢复 Token-level OPD 丢弃的信息,但更强的奖励耦合也可能使优化变得嘈杂得多
- 本文首先在估计器层面研究这种权衡
- Sequence-level 反向 KL 将每个 Token 的更新与未来的奖励耦合起来
- Token-level OPD 则丢弃了这些项
- Token-level OPD 相对于 Sequence-level 目标是有偏的,但它具有更紧的最坏情况方差界
- Sequence-level 反向 KL 将每个 Token 的更新与未来的奖励耦合起来
- 本文实验展示了相同的模式:
- 随着未来奖励耦合的增加,梯度方差上升,优化变得不那么稳定
- 这为长 horizon 后训练提出了一个简单的设计目标:保持足够的局部监督以控制方差,同时使局部比较比单 Token 点估计更不脆弱
- 本文用 Teacher Top-K 局部支持匹配 取代了 Sampled-token 监督
- 在每个前缀处,在 Teacher 局部合理的支持集上 比较 Teacher 和 Student 的分布(不是仅仅是采样的 Token 上给出奖励)
- 本文将此目标函数实现为带有 Top-\(p\) Rollout 采样和 Special-Token 掩码的截断反向 KL
- 得到的更新仍然是局部且简洁的,但比 Sampled-token OPD 对特异的采样续接和 Tokenization 伪影更不敏感
- 贡献总结:
- 分析了 OPD 中的估计器权衡:
- Token-level OPD 相对于 Sequence-level OPD 是有偏的,但其最坏情况方差随序列长度的增长要慢得多,这在长 horizon LLM 后训练中很重要
- 识别了 Sampled-token OPD 的三种实践失效模式:
- 不平衡的单 Token 信号
- 在 Student 生成的前缀上不可靠的 Teacher 指导
- 由 Tokenizer 或 Special-Token 不匹配导致的失真
- 提出了 Teacher Top-K 局部支持匹配,实现为带有 Top-\(p\) Rollout 和 Special-Token 掩码的截断反向 KL
- 在单任务数学推理和多任务 Agentic-plus-math 训练中展示了比 Sampled-token OPD 更强的优化行为和下游性能
- 分析了 OPD 中的估计器权衡:
Related Work(待后续补充)
Understanding Sampled-token OPD: Tradeoffs and Failure Modes,Sampled-token OPD 的 Tradeoffs 与失效模式
From reverse-KL to token-level OPD
- 从 OPD 背后的 Sequence-level 目标开始
- 对于一个 Prompt \(x\),反向 KL 目标函数为
$$J_{\text{OPD} }(\theta) = \mathbb{E}_{x\sim D}[D_{\text{KL} }(\pi_{\theta}(\cdot \mid x)| q(\cdot \mid x))] $$- \(\pi_{\theta}\) 表示 Student 模型
- \(q\) 表示 Teacher 模型
- 使用得分函数恒等式,其梯度可以写为
$$\nabla_{\theta}J_{\text{OPD} }(\theta) = \mathbb{E}_{x,y\sim \pi_{\theta}(\cdot |x)}\left[\left(\log \pi_{\theta}(y\mid x) - \log q(y\mid x)\right)\nabla_{\theta}\log \pi_{\theta}(y\mid x)\right] $$ - 对于每个解码步骤 \(t\),定义前缀上下文 \(c_t\)、梯度 \(g_t\) 和奖励 \(r_t\):
$$
\begin{align}
c_{t} &= (x, y_{ < t}) \\
g_{t} &= \nabla_{\theta}\log \pi_{\theta}(y_{t}\mid c_{t}) \\
r_{t} &= \log \frac{\pi_{\theta}(y_{t}\mid c_{t})}{q(y_{t}\mid c_{t})}
\end{align}
$$ - 使用自回归分解可得:
$$\begin{align}
\log \pi_{\theta}(y\mid x) - \log q(y\mid x) &= \sum_{t^{\prime} = 1}^{T}r_{t^{\prime} }\\
\nabla_{\theta}\log \pi_{\theta}(y\mid x) &= \sum_{t = 1}^{T}g_{t}
\end{align}$$ - 得到 Sequence-level 估计器(梯度估计器,\(\hat{g}_{\text{seq} }\) 中的 hat 标签表示蒙特卡罗估计)
$$\hat{g}_{\text{seq} } = \sum_{t = 1}^{T}\left(\sum_{t^{\prime} = 1}^{T}r_{t^{\prime} }\right)g_{t} \tag {1}$$- 注:为便于理解,这里展开完整的形式是
$$
\begin{align}
\nabla_{\theta}J_{\text{OPD} }(\theta) &\approx \hat{g}_{\text{seq} } \\
&= \sum_{t = 1}^{T}\left(\sum_{t^{\prime} = 1}^{T}\log \frac{\pi_{\theta}(y_{t^\prime}\mid c_{t^\prime})}{q(y_{t^\prime}\mid c_{t^\prime})}\right)\nabla_{\theta}\log \pi_{\theta}(y_{t}\mid c_{t})
\end{align}
$$
- 注:为便于理解,这里展开完整的形式是
- 在上式中,对于 \(t^{\prime}< t\),有
$$\mathbb{E}[r_{t^{\prime} }g_{t}] = 0$$- 注:这里不太规范,没有明确期望 \(\mathbb{E}\) 是在什么策略下采样的,但根据上下文可以推导得到函数是:
$$ \mathbb{E}_{x,y \sim \pi_\theta(\cdot|x)}[\cdot]$$ - 因为 \(r_{t^{\prime} }\) 仅依赖于步骤 \(t\) 之前的前缀,而
$$\mathbb{E}[g_t\mid x,y_{ < t}] = \sum_{y_t}\pi_\theta (y_t\mid c_t)\nabla_\theta \log \pi_\theta (y_t\mid c_t) = 0 $$- 注:这里为 0 的原因是得分函数的性质,证明可参考 NLP——LLM对齐微调-Rethinking-KL-Regularization
- 注:这里不太规范,没有明确期望 \(\mathbb{E}\) 是在什么策略下采样的,但根据上下文可以推导得到函数是:
- 相同的梯度也可以写成因果的 return-to-go 形式:
$$\mathbb{E}[\hat{g}_{\text{seq} }] = \mathbb{E}\left[\sum_{t = 1}^{T}\left(\sum_{t^{\prime} = t}^{T}r_{t^{\prime} }\right)g_{t}\right] $$ - LLM 训练中一个常见的近似是在每个位置仅保留即时项:
$$\hat{g}_{\text{tok} } = \sum_{t = 1}^{T}r_{t}g_{t} \tag {2}$$- 这里将 (2) 称为 Token-level OPD(注意:上述公式隐含了使用蒙特卡洛估计来估计梯度,所以本身是 Sampled-Token OPD)
- 这种近似去除了未来奖励耦合(其实之前的奖励耦合也去除了,但是因为之前的奖励下值梯度值为 0,所以不用关注)
- 因此 Token \(y_{t}\) 的更新仅依赖于其即时奖励
- 理解:这里相当于移除了 Sequence-level OPD 中的未来奖励部分对当前的梯度加权
- Token-level 的梯度估计相对于 Sequence-level 反向 KL 估计器是有偏的
- 但在长 horizon 设定中具有更低的方差
- 这种差异反映在它们的方差缩放上:
- 在有界奖励和有界得分函数梯度的条件下, Token-level OPD 的最坏情况方差上界缩放为 \(O(T^{2})\),而 Sequence-level 估计器的缩放为 \(O(T^{4})\)
- 附录 B 中提供了详细的推导
- 为了在这两个极端之间进行插值,本文考虑折扣 return-to-go 估计器
$$\hat{g}_{\gamma} = \sum_{t = 1}^{T}\left(\sum_{t^{\prime} = t}^{T}\gamma^{t^{\prime} - t}r_{t^{\prime} }\right)g_{t},\qquad \gamma \in [0,1] \tag {3}$$- \(\gamma = 0\) 的情况恢复了 Token-level OPD
- \(\gamma = 1\) 则恢复了因果 Sequence-level 估计器
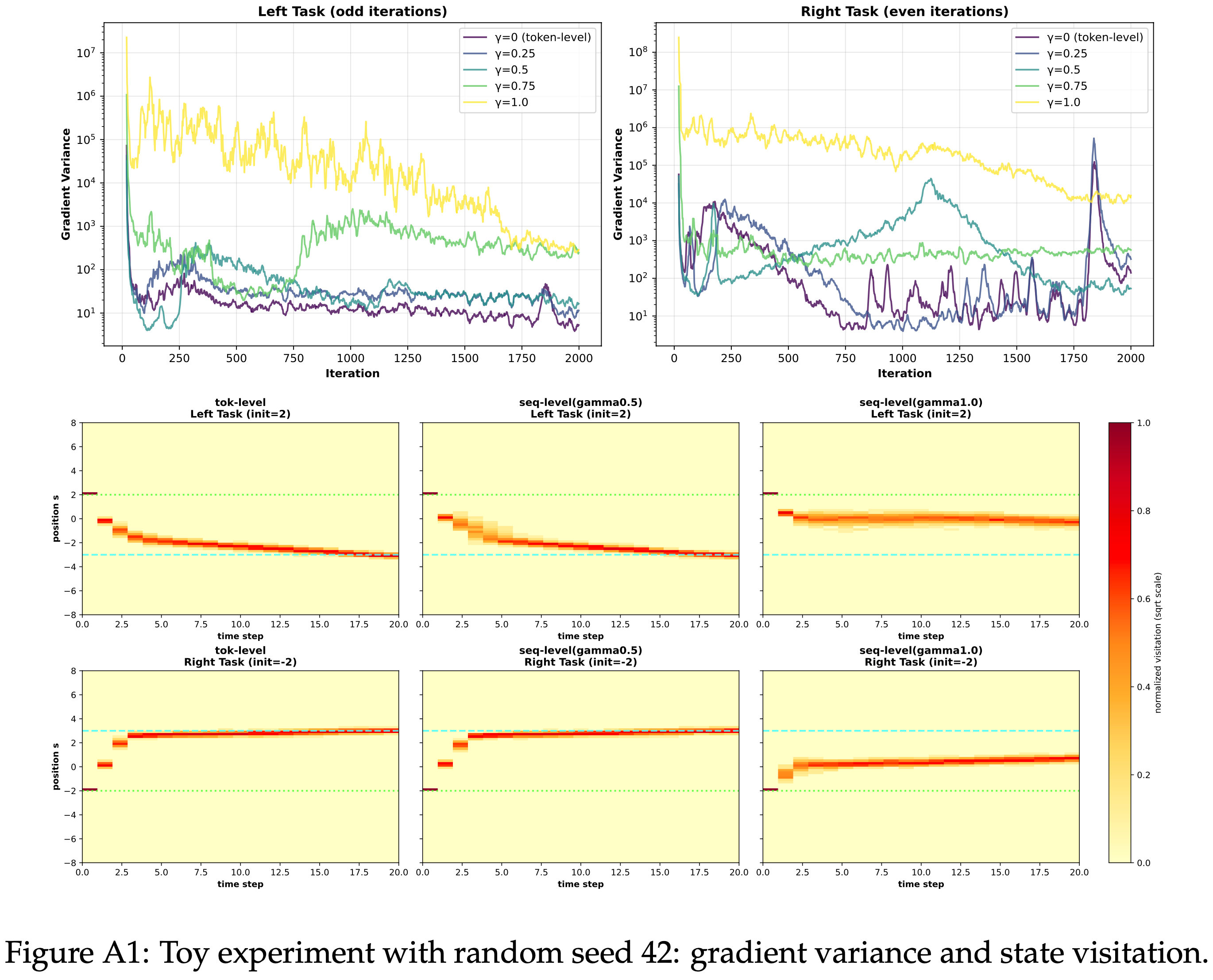
- 进行了一个双任务的 Toy 实验,观察到:增加 \(\gamma\) 会导致显著更高的梯度方差和更不稳定的优化
- 见图 1 的图示和附录 C 的额外实验细节
- 图 1: 实验中增加 \(\gamma\) 的效果
- 更大的 \(\gamma\) 会产生更高且更持久的方差区间,并且在 Sequence-level 极限下,状态空间中的策略会漂移
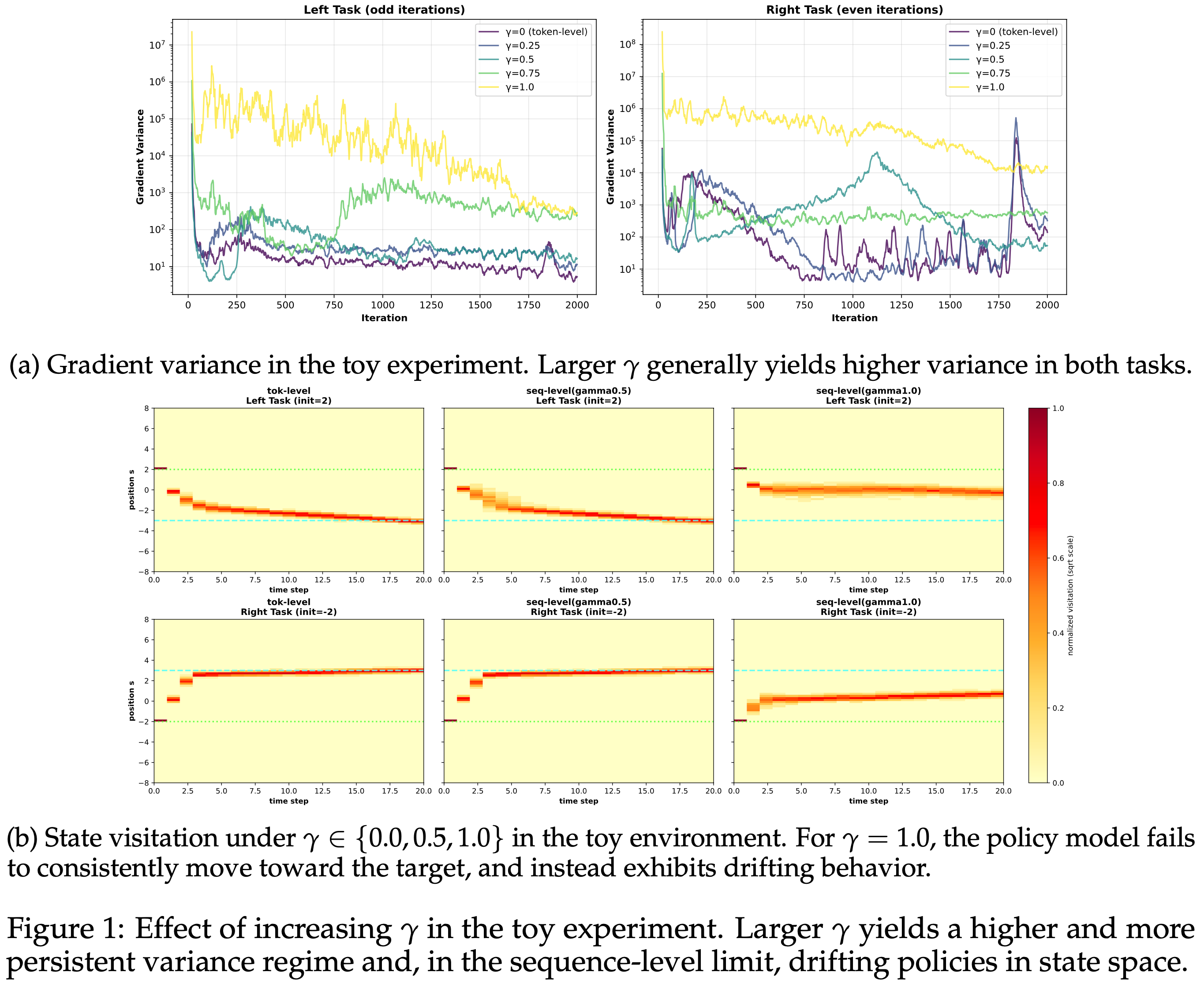
- 更大的 \(\gamma\) 会产生更高且更持久的方差区间,并且在 Sequence-level 极限下,状态空间中的策略会漂移
Why Sampled-token OPD is brittle in practice,Sampled-token OPD 的问题
- 从偏差-方差的角度来看,Token-level OPD 很有吸引力,但 Sampled-token 的比较在实践中可能很脆弱
- 问题:Token-level OPD 跟 Sampled-Token Comparison(Sampled-Token OPD) 本身是不等价的
- Sampled-Token OPD 强调的是:
- 在估计每个位置的 KL 散度时,只使用学生实际采样出来的那一个 Token ,而不是对整个词表做求和或期望
- 这是一种估计方式的刻画
- Sampled-Token OPD 的反面是对全词表求和
- Token-level OPD 强调的是:
- 在计算当前 Token \( y_t \) 的梯度时,只使用当前位置的即时奖励 \( r_t \) ,而不使用未来的奖励信号 \( r_{t+1}, r_{t+2}, \dots \)
- 这是一种梯度结构的刻画
- Token-level OPD 的反面是计算当前 Token 梯度时,考虑未来的奖励
- 这两个概念在逻辑上是正交的,但本文中似乎认为 Token-level OPD 中包含了 Sampled-Token OPD
- Sampled-Token OPD 强调的是:
- 问题:Token-level OPD 跟 Sampled-Token Comparison(Sampled-Token OPD) 本身是不等价的
- 本文分离出三个不同的问题:
- (1) 蒸馏信号高度不平衡
- (2) Teacher 信号在 Student 生成的前缀上变得不太可靠
- (3) Tokenizer 和 Special-Token 的不匹配会进一步扭曲单 Token 的比较
A highly imbalanced sampled-token signal
- 在 Sampled-token OPD 中,步骤 \(t\) 的更新由单个 Sampled-token 上的对数比率驱动:
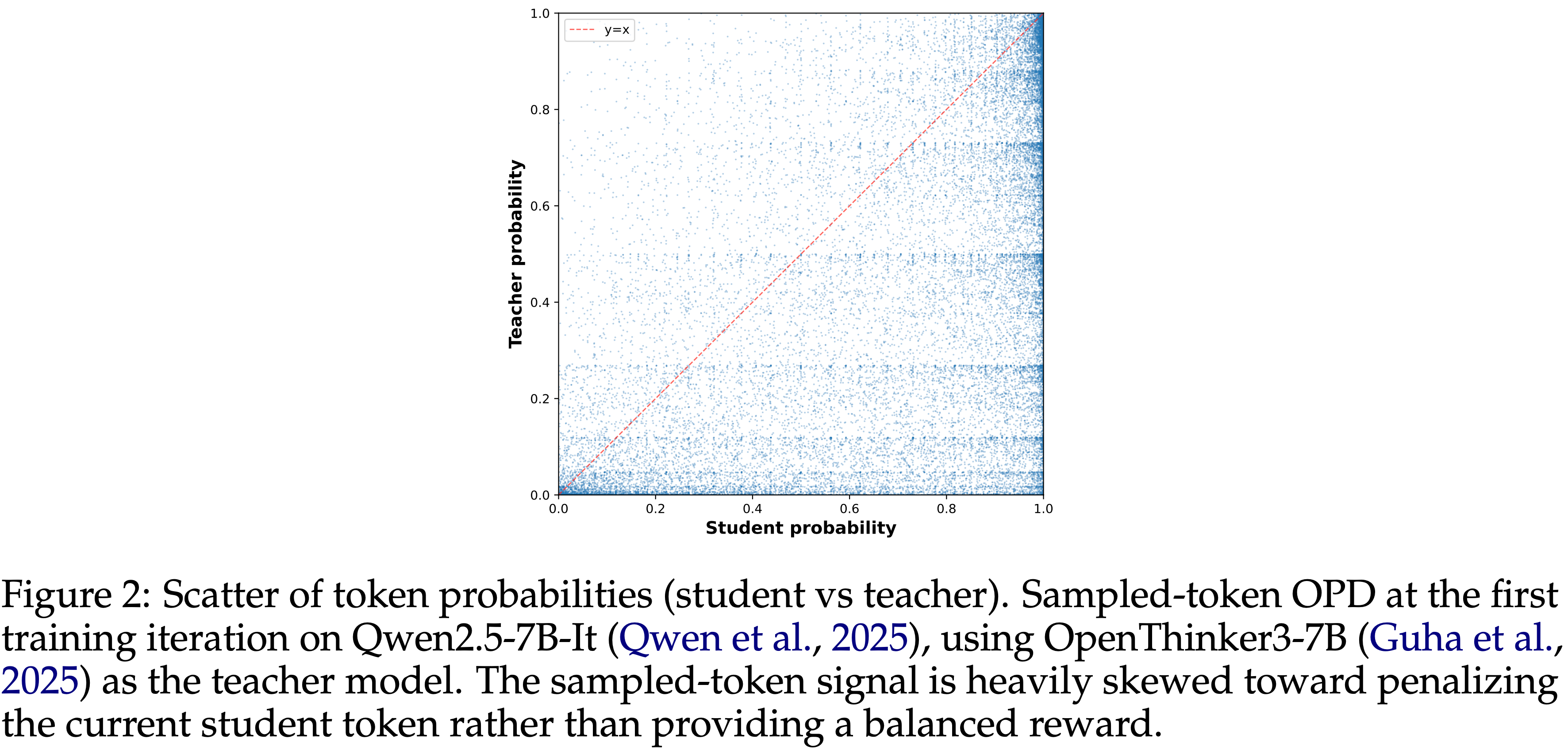
$$\log q(y_t|c_t) - \log \pi_\theta (y_t|c_t) $$- 当 Student 给一个 Sampled-token 赋予比 Teacher 更高的概率时,就会产生负奖励
- 如图 2 所示,大多数采样的 Token 获得负奖励,而正向的学习信号则集中在少数具有正优势的 Token 子集上
- 结果是一个不平衡的训练信号,其中优化不成比例地由少数局部有利的 Token 驱动
- 训练可能随后对 Teacher 局部偏好的短续接变得敏感,例如填充词或犹豫标记,即使这些 Token 对整体轨迹质量的贡献很小
- 理解:产生这个问题的原因是因为 轨迹是由 Student 采样的,Student 采样时倾向于采样自身高概率的 Token(而这些 Token 在 Teacher 上的概率不一定大)
- 理解:正因为 OPD 的 Advantages 均值倾向于小于 0,所以 Student 的熵一般不会降低,甚至会上涨(许多高概率 Token 降低自身概率带来的是熵增),少数 Token 会被提升概率,带来熵减
- 熵增现象详情见 本文 图 8 图 9 和 NLP——LLM对齐微调-Rethinking-OPD 的 图 12
- 图 2: Token 概率的散点图 ( Student vs. Teacher )
- 在 Qwen2.5-7B-It (2025) 上的第一次训练迭代时,使用 OpenThinker3-7B (2025) 作为 Teacher 模型的 Sampled-token OPD
- Sampled-token 信号严重偏向于惩罚当前的 Student Token,而不是提供平衡的奖励
The teacher signal can become unreliable on student-generated prefixes
- 这一点可以描述为:Teacher 信号在 Student 生成的前缀(不是 Teacher 生成的前缀)上可能变得不可靠
- Sampled-token OPD 隐含地假设 Teacher 对 Student 生成 Token 赋予的概率是其轨迹质量的有用代理
- 当 Rollout 进入 Student 常见但 Teacher 不常见 的前缀时,这个假设会减弱
- 在这样的前缀上, Teacher 可能给看似合理的 Token 赋予高概率,而此时轨迹已经偏离了期望的方向
- 在本文实验的日志中,这种行为与诸如重复循环、自重置推理和格式错误的续接等模式相关联
- 问题:这个点真的算是问题吗?可能是问题
- 首先:简单理解下,不论前缀为何,假设 Teacher 认为这个前缀上后续生成的 Token 都应该近似输出某个特定 Token,那 Student 就应该被学到这个 Teacher 的知识,这和前缀在 Teacher 中是否常见没有关系
- 实际上:如果 Teacher 甚至没有训练过这个 Prefix,那么确实可能会有问题,因为 Teacher 可能会输出乱码(此时 Teacher 出现类似 OOD 错误),此时 Teacher 确实无法胜任奖励信号的角色
- 图 3 和 附录 D 的观察表明存在一个目标层面的不匹配:
- OPD 鼓励 Token-level 上与 Teacher 达成一致,但这种代理并不一定对应于轨迹级别的质量,尤其是在 Teacher 分布外 (out-of-distribution) 的前缀上
- 本文推测有两个因素放大了这个问题
- 第一:Teacher 分布通常很尖锐,因此即使 Student 和 Teacher 之间稍有分歧,也可能产生很大的对数比率值
- 第二:Teacher 的生成模式与 Student 的生成模式之间的差异使得 Student 的前缀更可能落在 Teacher 的典型上下文之外
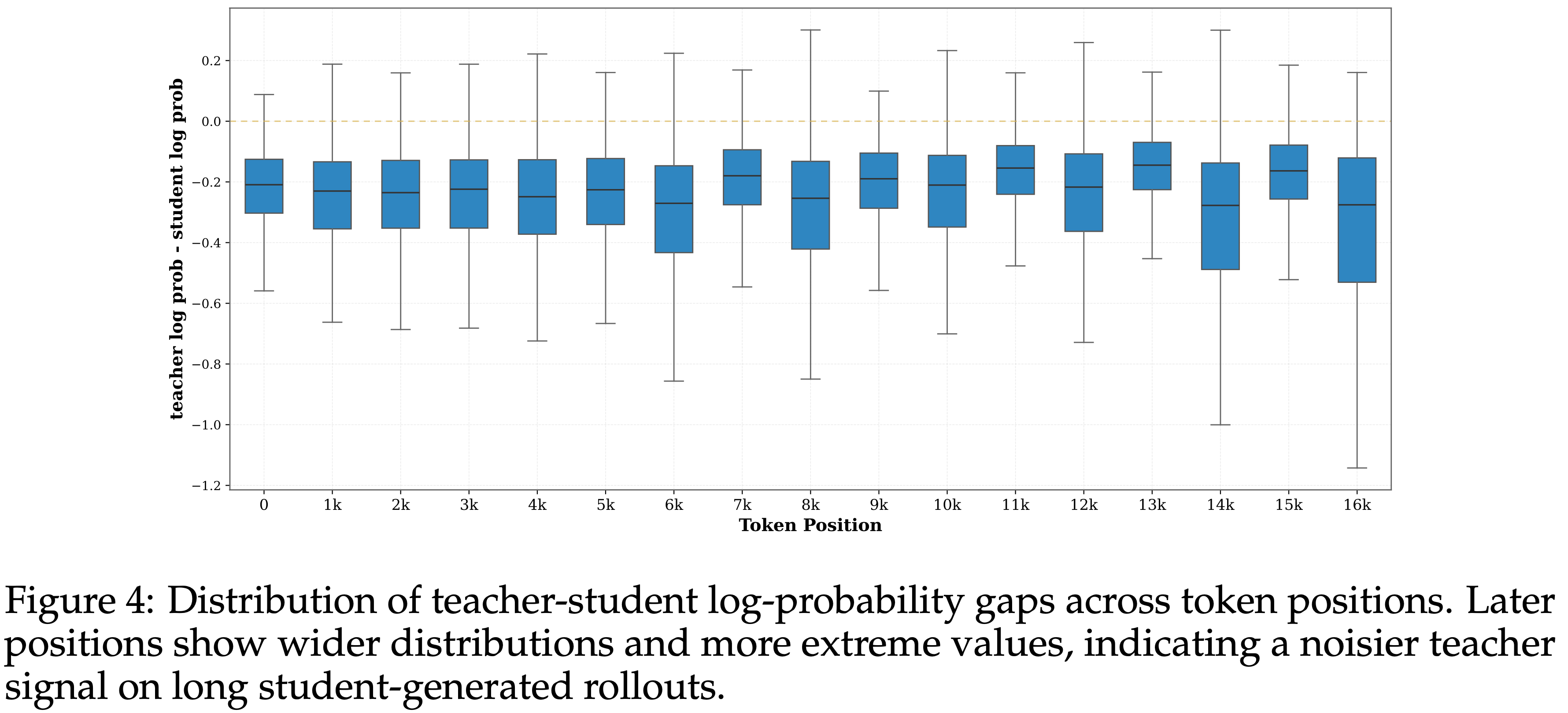
- 同样的失效也体现在 Teacher 信号随位置变化的方式上
- 图 4 显示了跨 Token 位置的 Teacher-Student 对数概率差距的分布
- 在早期位置相对集中,并在序列的后期逐渐变宽,在长 Rollout 上出现更极端的值
- 图 4 显示了跨 Token 位置的 Teacher-Student 对数概率差距的分布
- 图 3: Student 陷入重复循环
- 但Teacher 模型在重复的 Token 上与 Student 模型保持高度一致,表明对此类行为缺乏适当的惩罚 (注:无色的 Token 多,说明两者输出的概率几乎一致)

- 但Teacher 模型在重复的 Token 上与 Student 模型保持高度一致,表明对此类行为缺乏适当的惩罚 (注:无色的 Token 多,说明两者输出的概率几乎一致)
- 图 4: 跨 Token 位置的 Teacher-Student 对数概率差距的分布
- 较后的位置显示出更宽的分布和更极端的值 ,表明在长的 Student 生成 Rollout 上 Teacher 信号更嘈杂
- 问题:为什么单数长度的 Token 位置方差明显小于双数长度的 Token(比如 15k 相比 16k 长度,差异很大,但 15k 相对 0k 差异很小)
Tokenizer and special-token mismatch
- Sampled-token OPD 使用 Teacher 的分布来比较 Student 生成的确切 Token
- 当两个模型使用不同的 Tokenization 时,相同的原始文本可能被分割成不同的方式,因此 Student 生成的 Token 在 Teacher 的 Token 体系下可能不对应于一个自然的 Token
- 例如,Student 可能将
<think>生成为<,think,>,而 Teacher 期望的是<th,ink,> - 那么 Token
<从 Teacher 那里获得低概率,即使两个模型产生了相同的语义内容
- 例如,Student 可能将
- 类似的 mismatch 也会出现在 Special-Token 上,例如序列结束标记
- 在这种情况下,单 Token 的比较会将语义分歧与 Tokenizer 不匹配混淆起来
- 本节的以上这些观察激发了超越单 Token 监督的动机:
- 在每个前缀处,我们不仅仅比较采样的 Token,而是在一组合理的 Next-Token Continuations 上比较 Teacher 和 Student ,同时保留 Token-level 更新以保证稳定性
- 图 5: Token-level 比较可能因 Tokenizer 不匹配而惩罚语义正确的输出
- 理解:图中,因为 Token 是按照 Student 的 Tokenizer 来划分的,所以部分 Special Token 是 Student 和 Teacher 不同的,这些 Token 下,按照 Student 划分后,Teacher 出现这些 Token 的概率很低(按照 Teacher 的 Tokenizer 划分则出现概率很高)
- 这个现象本质上是一种 Special-Token mismatch

- 这个现象本质上是一种 Special-Token mismatch
- 理解:图中,因为 Token 是按照 Student 的 Tokenizer 来划分的,所以部分 Special Token 是 Student 和 Teacher 不同的,这些 Token 下,按照 Student 划分后,Teacher 出现这些 Token 的概率很低(按照 Teacher 的 Tokenizer 划分则出现概率很高)
Method
- 本文的方法保留了 Token-level OPD,但在每个前缀上用一个基于 Teacher 选择的 support 集合的分布级比较取代了单 token 监督
- 产生一个截断的 reverse-KL 目标,在保持计算效率的同时改善了训练信号的平衡
Teacher top-K local support matching,Teacher top-K 局部 support 匹配
- 本文的方法不是在单个 Sampled-token 上比较 Teacher 和 Student ,而是在一个 Teacher 定义的局部 support 上对它们进行比较
- 一个自然的起点是在前缀 \(c_{t}\) 处的全词表 reverse-KL:
$$\mathcal{L}_{\text{full} }(c_t) = \sum_{v\in \mathcal{V} }\pi_\theta (v|c_t)\log \frac{\pi_\theta(v|c_t)}{q(v|c_t)} \tag {4}$$ - Sampled-token OPD 可以被视为对这个量的单样本 Monte Carlo 近似:
$$\mathcal{L}_{\text{sample} }(c_t,y_t) = \log \frac{\pi_\theta(y_t|c_t)}{q(y_t|c_t)},\qquad y_t\sim \pi_\theta (\cdot |c_t) \tag {5}$$- 这种近似在计算上很有吸引力,但将整个更新集中在一个采样的 token 上
- 本文做法:在每个前缀上,在一个 Teacher 支持的 token 集合上比较 Teacher 和 Student
- 对于每个 prompt \(x\),使用 Student 推理策略采样一组输出
$$\{o_i\}_{i = 1}^G$$ - 令为输出 \(o_{i}\) 在位置 \(t\) 处的前缀为:
$$ c_{i,t} = (x,y_{i, < t}) $$ - 定义 Teacher support 集合
$$S(c_{i,t}) = \text{TopK}_q(c_{i,t}) \tag {6}$$- 这包含了在该前缀下 Teacher 认为(Next-token 候选)概率最高的 \(K\) 个 token
- 对于每个 prompt \(x\),使用 Student 推理策略采样一组输出
- 本文在这个局部 support 内部对 Teacher 和 Student 的分布进行重新归一化:
$$\begin{align}
\hat{\pi}_{\theta}(v\mid c_{i,t}) &= \frac{\pi_{\theta}(v\mid c_{i,t})}{\sum_{u\in S(c_{i,t})}\pi_{\theta}(u\mid c_{i,t})}\\
\hat{q} (v\mid c_{i,t}) &= \frac{q(v\mid c_{i,t})}{\sum_{u\in S(c_{i,t})}q(u\mid c_{i,t})}
\end{align}
\tag {7}$$ - 训练目标是对所有 Rollout 位置的平均截断 reverse-KL:
$$\mathcal{L}_{\text{LSM} } = \mathbb{E}_{x,\{o_i\} \sim \pi_{\theta ,\text{infer} } }\left[\frac{1}{\sum_{i = 1}^{G}|o_i|}\sum_{i = 1}^{G}\sum_{v\in S(c_{i,t})}\hat{\pi}_{\theta}(v\mid c_{i,t})\log \frac{\hat{\pi}_{\theta}(v\mid c_{i,t})}{\hat{q}(v\mid c_{i,t})}\right] \tag {8}$$- 相对于 Sampled-token OPD,这个目标在 Teacher 支持的局部区域内进行分布级比较,而不是仅仅奖励或惩罚一个采样的 token
- 由此产生的更新将正向和负向调整重新分配到前缀中所有 Teacher 支持的候选 token 上,产生了一个更平衡的训练信号,同时仍然比全词表 KL Cheap 得多
- 问题:为什么是 Teacher 的 Top 概率子集,不是 Student 的 Top-K 候选 Token?
- 推测使用 Student 的 Top 概率子集会更好,因为这里是为了扩展采样到的 Token
- 而且,采样到的 Token 理论上一定包含在 Student 的 Top-K 候选 Token 中,却不一定包含在 Teacher 的 Top-K 候选 Token 中(毕竟轨迹是从 Student 采样得到的)
- 补充:下文中会有消融实验,两者在不同领域上收益有胜有负,另外,针对 Teacher 的 Top-K 候选 Token 可能不包含 Sampled Token 的情况,可以强行将 Sampled Token 添加到 Teacher 的 Top-K 候选 Token 集合中
Practical stabilization choices,实际生产中选择的稳定化选择
Support-set renormalization
- 重新归一化是必要的,因为目标是在截断的 support 上而非完整词汇上进行评估
- 没有重新归一化,优化可能会变得不稳定,因为 support 内部的 Teacher 和 Student 概率质量无法直接比较
- 理解:不归一化时,两者的子集上的分布和(对应归一化分母)是不一样的
- 问题:这种归一化改变了原始的 Teacher 和 Student 的 Token 概率(本身似乎有问题)
Top-\(p\) rollout sampling
- 使用 top-\(p\) 采样生成 Rollout
- 无约束采样偶尔会产生极低概率的 token,这反过来会 Create 一些前缀,在这些前缀上 Teacher 分布的信息量较少,而 Student 分布已经在恶化
- 理解:一些极低概率的 Token 确实会导致生成的轨迹变得极端(无约束时有一定概率采样到极低概率的 Token)
- Top-\(p\) 采样使轨迹更接近典型的延续,并使 Teacher 信号更可靠
Special-token masking
- 屏蔽有问题的 Special-Token ,以减少由不兼容的分词约定引起的假阴性
- 注意:这里不是修正,而是直接屏蔽
- 理解:这里所谓 有问题的 Special-Token 是指 Teacher 和 Student Tokenization 方式不一致的 Token
- 这是一个正交的工程修复:
- 在本文的实验中,这个修复实质性地帮助了 Sampled-token OPD 基线,而局部 support 目标对其敏感度要低得多
- In Principle,也可以合并多 token marker 变体或对等效的分词进行平均,但本文在此不采用这些特定于分词器的补救措施,因为掩码是最简单的与模型无关的修正
- 理解:这里是指一些底层的 Token 修复方式了
Experiments
Setup
- 本文在现有的 OPD 训练流程之上实现了局部 support 匹配,使用 Qwen2.5-7B-Instruct (2025) 作为 Student
- 考虑两种 Setting:
- (1) 一个单任务数学推理 Setting
- OpenThinker3-7B (2025) 作为 Teacher
- 训练使用 DAPO-Math-17K (2025) 的英文部分
- 最大上下文长度为 16K
- (2) 一个多任务 Setting
- 在数学推理和基于 ALFWorld (2021) 的多轮 Agentic 任务之间交替进行
- 数学任务使用 OpenThinker3-7B (2025) 作为 Teacher
- Agentic 任务使用发布的 GiGPO-Qwen2.5-7B-Instruct-ALFWorld checkpoint (2025) 作为 Teacher
- (1) 一个单任务数学推理 Setting
- 所有运行默认使用:
- batch size 128
- mini-batch size 64
- 学习率 \(2\times 10^{- 6}\)
- 温度 1
- Rollout 使用 top-\(p = 0.9\) 进行采样
- 指标:
- 在数学基准测试上报告 pass@1,在 ALFWorld 上报告成功率
- 少数情况下还会为数学评估额外报告 average@32
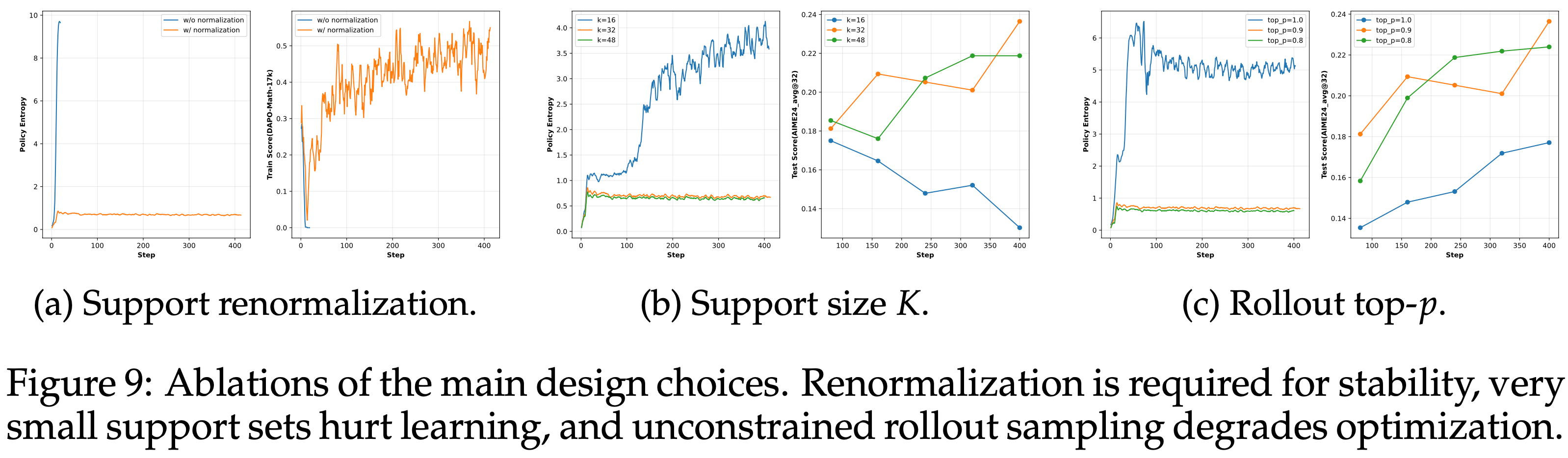
Single-task math reasoning
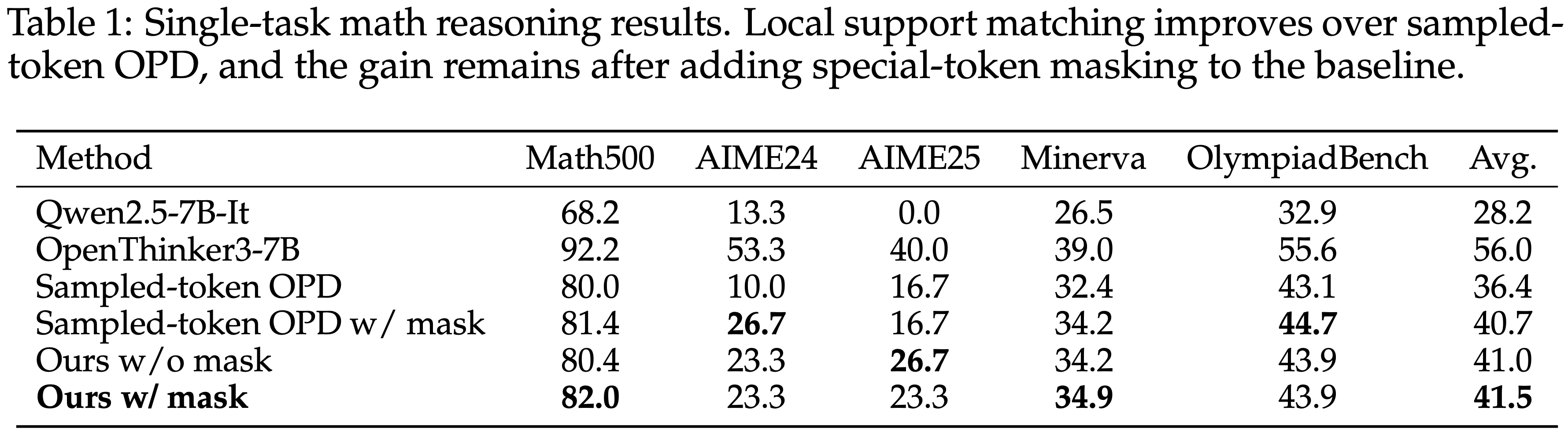
- 表 1 显示,在单任务数学推理中,局部 support 匹配相比 Sampled-token OPD 有所改进
- Sampled-token OPD 已将平均分从 28.2 提高到 36.4
- 注:但仍远落后于 Teacher
- 在 Sampled-token OPD 上,仅使用 Special-Token 掩码就将采样式基线进一步改进到 40.7
- 表明分词伪影是该问题的重要组成部分
- 本文的完整方法达到 41.5
- 掩码对本文方法影响不大 (41.0 对比 41.5),这与分布级 support 匹配 对分词器不匹配的敏感度低于单 token 监督 的结论一致
- Sampled-token OPD 已将平均分从 28.2 提高到 36.4
Multi-task agentic-plus-math training, Agentic 加数学联合
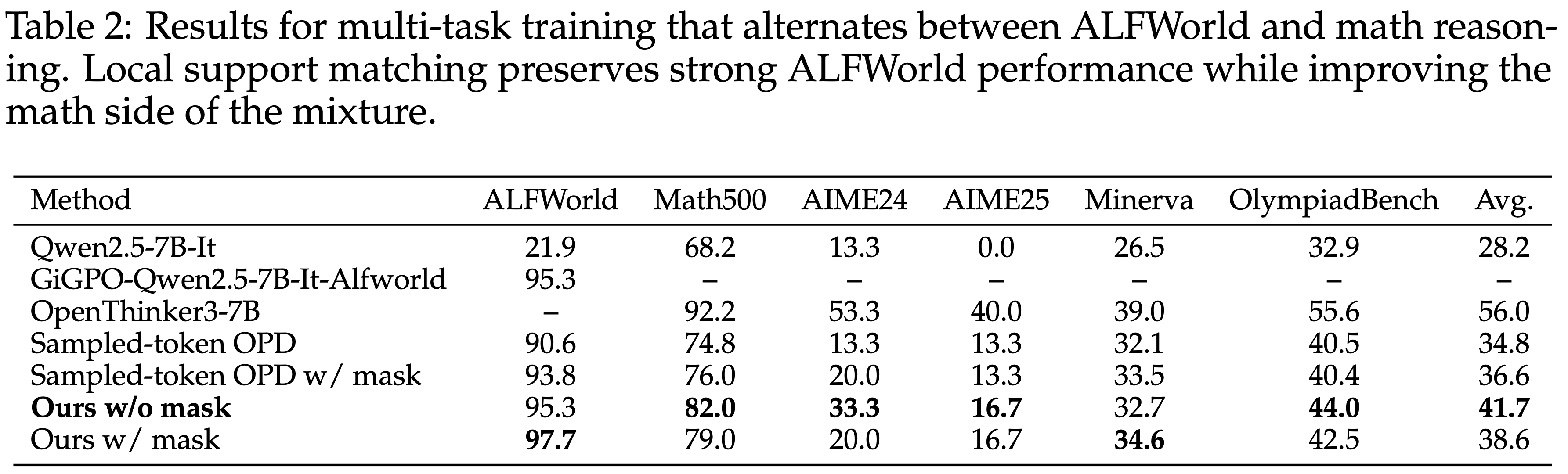
- 表 2 显示了交替多任务训练中一个更不对称的模式
- Sampled-token OPD 基线在 ALFWorld 上已经很强,主要的改进空间在于数学方面
- 本文方法的无掩码版本将 Math500 从 76.0(Sampled-token OPD w/ mask)提高到 82.0,并将数学平均分从 36.6 提高到 41.7,同时在 ALFWorld 上保持竞争力
- 带掩码的版本取得了最佳的 ALFWorld 结果 97.7,但牺牲了一部分数学增益
- 理解:说明两个领域存在一些冲突,有一个 trade-off 的过程
- 这些结果表明:
- 局部 support 匹配在长 horizon Token-level 监督最脆弱的领域帮助最大,同时保留了强大的 Agentic 性能
- 理解:这里的 长 horizon Token-level 监督最脆弱的领域 主要指的是数学领域上
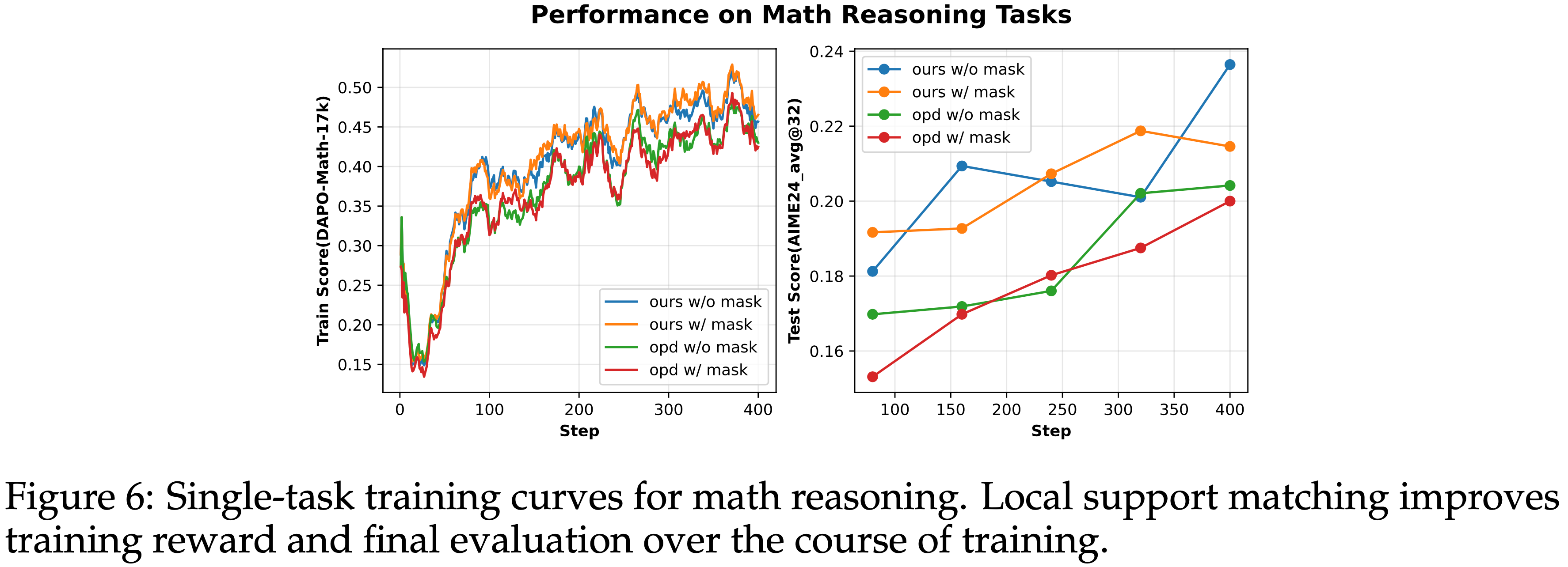
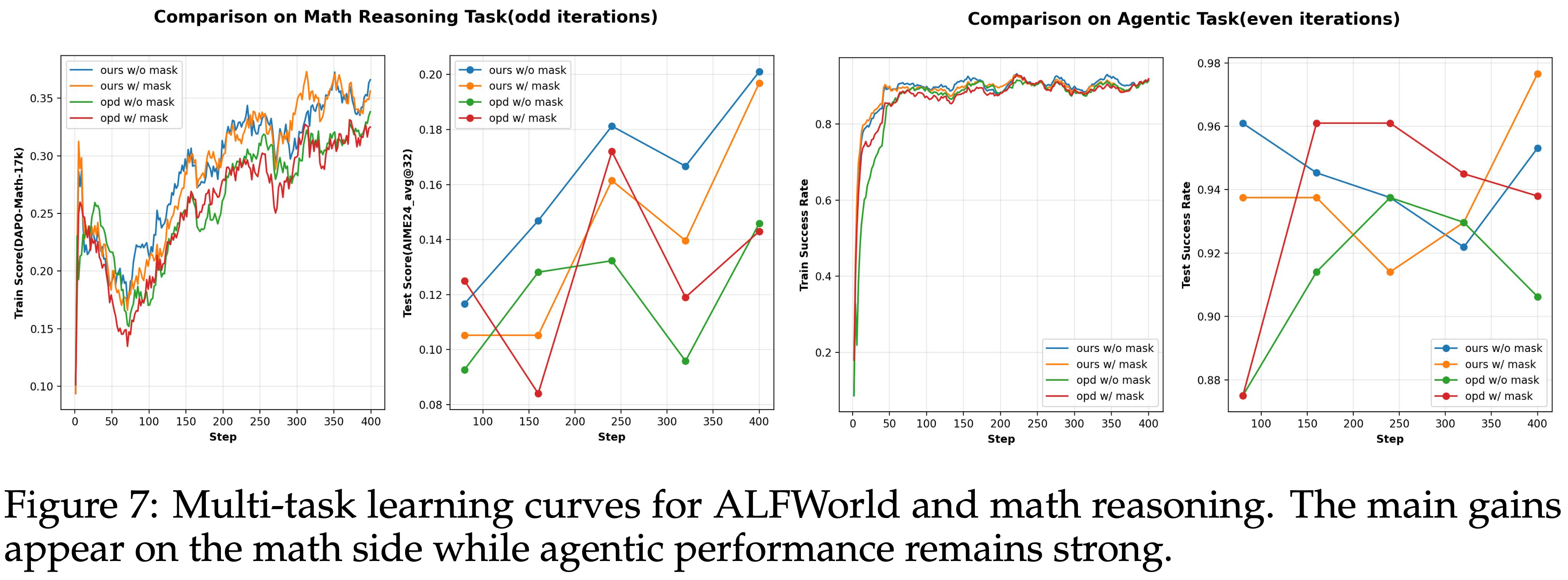
Training dynamics and alignment,训练动态与对齐
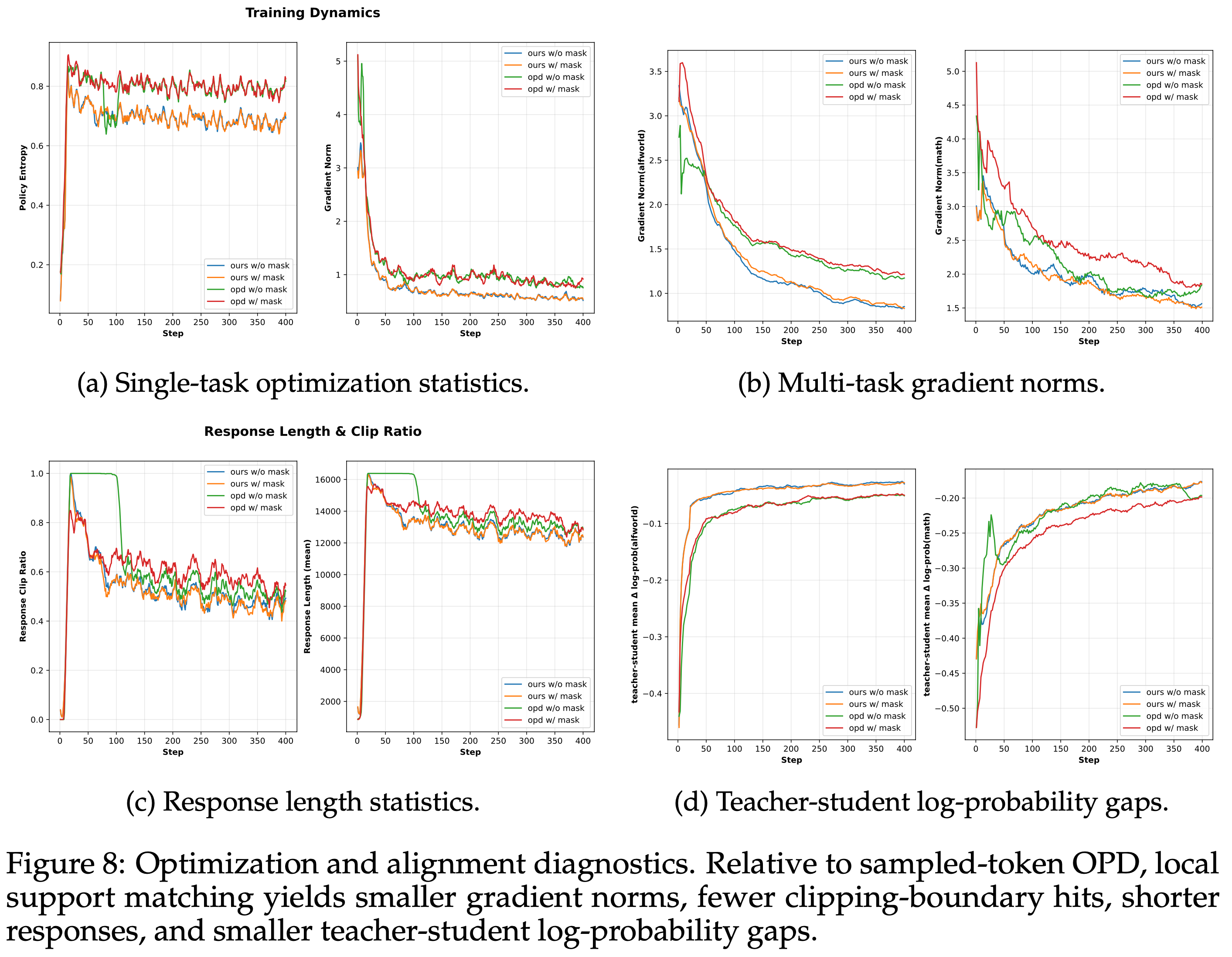
- 图 6、7 和 8 提供了优化动态的更详细视图
- 注:图 6 的评测结果和 表 1 结果对不齐
- 注:从 图 6 - 图 8 的整个评估分数看来,同一个方案训练过程中波动较大,实际上继续训练下去,结论可能回又不一样
Better learning curves
- 在数学推理上,本文的方法在整个训练过程中都提高了训练奖励和评估性能,而不仅仅是在最后的 checkpoint
- 这种模式在单任务设置和交替多任务设置中都成立
More stable optimization
- 本文的方法产生了更小的梯度范数和更低的裁剪边界比例,同时保持了足够的策略熵,这表明优化更加稳定
- 可以观察到, Special-Token 掩码在训练早期和中期显著降低了 Sampled-token OPD 的裁剪边界比例,而对本文的方法影响很小
Improved teacher-student alignment
- 在 Sampled-token 上的 Teacher-Student 对数概率差距也变小了
- 这表明截断的局部 support 目标即使在使用基线的采样式 token 诊断指标下,也改善了对齐性
Ablations
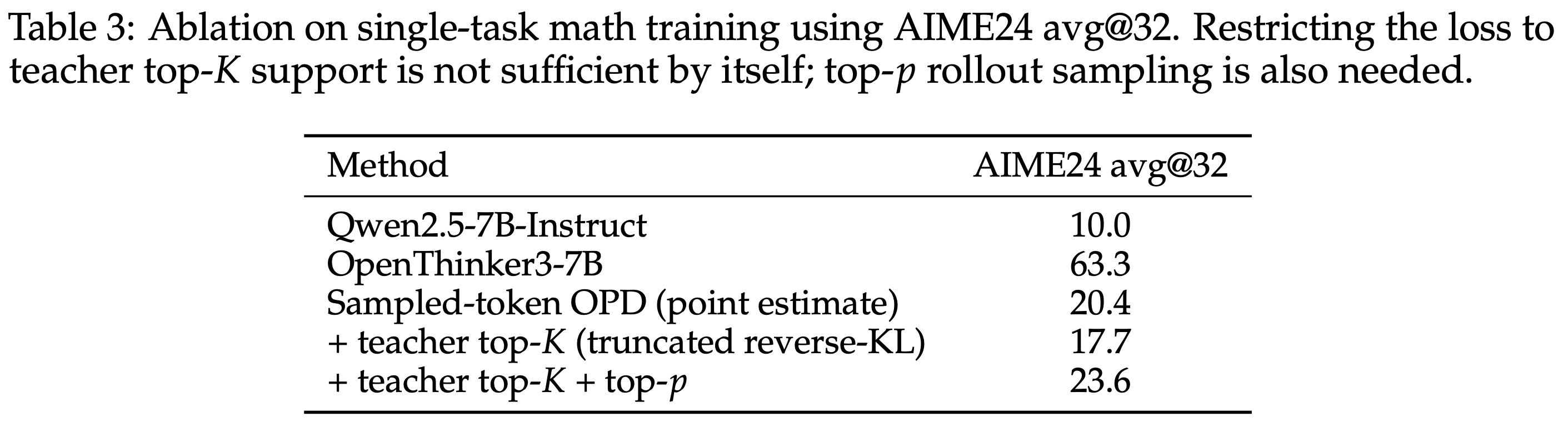
- 表 3 和图 9 表明,本文方法拿到的这些增益源于多个设计选择,而非任何单一修改
- 仅靠 Teacher top-K 比较是不够的:
- Rollout 策略也必须保持在一个稳定区域,添加 top-p 采样将一个初始较弱的 top-K 变体变成了一个更强的配置
- 在截断的 support 内部进行重新归一化是必不可少的,移除它会导致快速崩溃
- 当 support 空间 \(K\) 足够大时,性能对确切的 support 大小并不特别敏感
- 当 support 空间 \(K\) 太小或 Rollout 完全不受约束时,训练会变得不稳定
Top-K support variants
- 本文的主要实验在 Teacher 的 top-K support 上定义了截断期望
- 一个自然的问题是,这个选择本身是否关键,或者相近的 support 定义是否表现类似
- 本文比较了三种变体:
- Teacher top-K(主要结果中使用)
- Student top-K
- Teacher top-K 加上 Student 采样的 token
- 表 4 表明,这种益处在不同相近的 support 定义下都相当稳健
- 没有哪个单一选择在所有基准测试中占主导地位:
- Teacher top-K 仍然具有竞争力
- Student top-K 在几个单独的数据集上表现强劲(平均值优于 Teacher Top-K)
- Teacher top-K 加上 Sampled-token 在这个初步比较中取得了最佳平均分
- 这表明主要益处来自于用局部分布级匹配取代单 token 比较
- 暂时没有唯一最优的 support 集合选择
- 注:这个比较仍然是初步的,因此对 support 集合设计进行更系统的端到端研究仍然是重要的未来工作
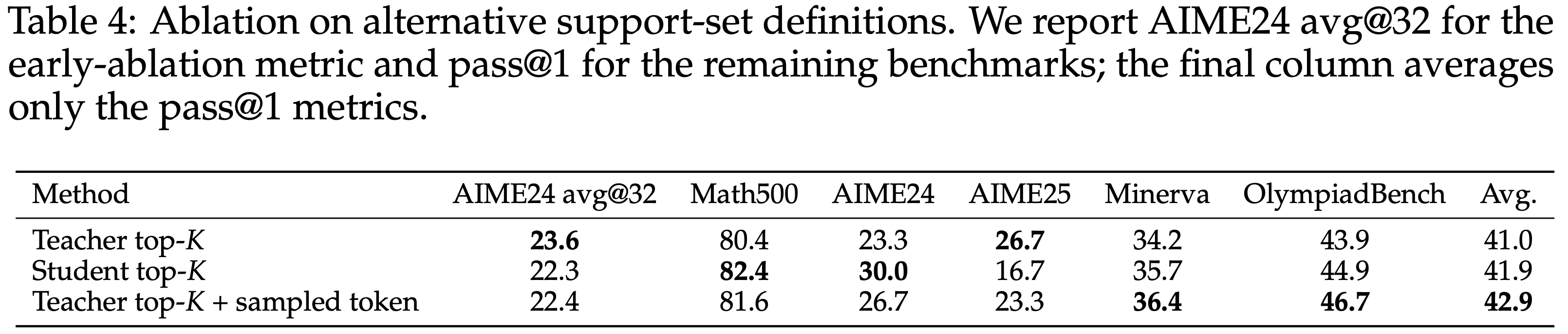
- 没有哪个单一选择在所有基准测试中占主导地位:
Discussion and Limitations
- 当前的目标仍然是一个截断的代理
- 本文的局部 support 损失是在一个受限的 token 子集上,以及在由诸如 top-\(p\) 采样等 Rollout 策略生成的前缀上进行评估的
- 这并不等同于全词表 reverse-KL,也没有明确校正产生训练前缀的采样过程
- 这个局限性在本文的研究中仍未充分探索的两个地方最为重要:
- 如何在扩充 Teacher top-\(K\) support 时纳入采样的 token
- 当 Rollout 策略和训练策略不同时是否需要重要性加权式的校正
- 作者将当前的公式视为一个实际的设计方案,而不是关于 support 集合构建的最终答案
- Reward Hacking 的解释仍然是一个机制性假设
- 本文的定性案例使失败模式具体化,但它们并未分离出一个完整的因果机制
- 特别地,关于尖锐的 Teacher 分布和分布外前缀共同产生误导性局部奖励的假设,应被视为一个有证据支持的可能解释,而非一个完全确定的因果说明
- Teacher 匹配仍然是任务成功的一个不完美代理
- 即使 OPD 被明确定义为 Teacher 匹配目标,由此产生的奖励仍然可能与潜在的成功行为概念存在差异
- 本文的 Reward Hacking 案例具体化了这种差距:
- 局部上 Teacher 偏好的延续即使在整个轨迹已经无益甚至有害时,仍然可以获得奖励
- 在本文的实验中,与 Teacher 之间仍存在显著差距,这表明更好的局部监督只是蒸馏问题的一部分,尤其是在 Teacher 和 Student 差异显著时
- 缩小这一差距可能需要更强的 Rollout 控制、更好地处理分布偏移、更好地利用 Teacher 的不确定性,以及与可验证结果的奖励相结合
附录 A:Future Directions
OPD versus RL in multi-task transfer,OPD 与 RL 比较
- 本文的多任务结果激励了对 OPD 和 RL 作为迁移机制进行更直接的比较
- 在 RL 中,正迁移或负迁移可以直接从跨任务的环境奖励中读取
- 在 OPD 中,优化目标仍然是 Teacher 派生的,因此迁移是通过 Teacher 认为是局部偏好的行为来过滤的
- 这种区别可能有助于解释为什么本文的多任务增益在数学方面最强,以及为什么在此设置中附近的支持集定义变得不那么统一
- OPD 和 RL 之间的任务匹配、计算匹配的比较将有助于阐明 Teacher 引导的迁移何时能跟踪环境级别的泛化,以及 Teacher 奖励差距何时成为瓶颈
Continual learning as a testbed,测试平台
- 持续学习是 OPD 的另一个自然 Setting
- Teacher 引导的 On-Policy 目标可以作为一种保留机制,同时 Student 适应新任务,但这种机制也将正好承受本文所揭示的问题:
- 分布偏移、Teacher 过时以及在长适应视界上近似误差的累积
- 建议测试 OPD 探究局部支持匹配是否能减轻遗忘,还可探究 Student 不断远离 Teacher 的原始领域时,基于 Teacher 的目标是否仍然有用
Relation to other stabilization directions,与其他稳定化方向的关系
- 本文方法与下面方向是互补的:
- Reward-Hacking 缓解
- 使用 EMA 锚定和 Top-K KL (2026)
- 基于扰动的 Off-Policy 校正 (2026)
- Teacher 和 Student Rollout 之间的 Logit 级融合 (2026)
- 这些方法解决了同一更广泛问题的不同部分:
- 当 Teacher 和 Student 策略开始出现分歧,如何保持 Teacher 派生的学习信号有用
- 将局部支持匹配视为该更大工具箱中的一个组成部分,而不是那些稳定化策略的替代品
附录 B: Bias and variance analysis of token-level versus sequence-level OPD,Token-level 与 Sequence-level OPD 的偏差和方差分析
B.1 Bias of the token-level estimator
- 回顾因果 Return-to-go 形式的 Sequence-level 估计器
$$\hat{\delta}_{\text{seq} } = \sum_{t = 1}^{T}\left(\sum_{t^{\prime} = t}^{T}r_{t^{\prime} }\right)g_{t} $$ - 展开内部和得到
$$\hat{\delta}_{\text{seq} } = \sum_{t = 1}^{T}r_{t}g_{t} + \sum_{t = 1}^{T}\sum_{t^{\prime} = t + 1}^{T}r_{t^{\prime} }g_{t} $$ - 由于 Token-level 估计器只保留第一项,
$$\hat{\delta}_{\text{tok} } = \sum_{t = 1}^{T}r_{t}g_{t} $$ - 它们的期望差距是
$$\mathbb{E}[\hat{\delta}_{\text{seq} }] - \mathbb{E}[\hat{\delta}_{\text{tok} }] = \mathbb{E}\left[\sum_{t = 1}^{T}\sum_{t^{\prime} = t + 1}^{T}r_{t^{\prime} }g_{t}\right] $$ - 这明确表明 Token-level OPD 移除了未来奖励耦合项,因此通常相对于 Sequence-level 目标是有偏差的
B.2 Worst-case variance upper bounds,最坏情况方差上界
- 假设存在常数 \(B_{r},B_{g} > 0\) 使得对所有 \(t\) 有
$$|r_t|\leq B_r,\qquad | g_t| \leq B_g\quad \text{for all }t $$ - 对于 Token-level 估计器,
$$| \hat{g}_{\text{tok} }| \leq \sum_{t = 1}^{T}|r_t|| g_t| \leq TB_rB_g$$- 于是有:
$$\mathbb{E}| \hat{g}_{\text{tok} }| ^2\leq T^2 B_r^2 B_g^2$$ - 使用 \(\operatorname {Var}(X)\leq \mathbb{E}| X| ^2\) 可得到
$$\operatorname {Var}(\hat{g}_{\text{tok} }) = O(T^2)$$
- 于是有:
- 对于 Sequence-level 估计器,定义
$$R = \sum_{t = 1}^{T}r_{t},\qquad G = \sum_{t = 1}^{T}g_{t},\qquad \hat{g}_{\text{seq} } = RG $$- 于是又:
$$|R|\leq TB_r,\qquad | G| \leq TB_g $$ - 进一步有:
$$| \hat{g}_{\text{seq} }| \leq T^2 B_rB_g,\qquad \mathbb{E}| \hat{g}_{\text{seq} }| ^2\leq T^4 B_r^2 B_g^2 $$ - 最终有:
$$\operatorname {Var}(\hat{g}_{\text{seq} }) = O(T^4) $$
- 于是又:
- 两者核心区别在于是否包含未来的所有奖励(包含时方差会变大)
B.3 Discussion
- Sequence-level 估计器更接近精确的轨迹级目标
- 但它将每个 Score 项与许多未来奖励耦合在一起
- 在最坏情况下的缩放中,这将方差增长从序列长度的二次方改变为四次方
- 这个论证是有意保守的,但它说明了为什么更强的奖励耦合在长视界后训练中可能成为问题
附录 C:Toy experiment details
C.1 Environment
- 使用一个双任务一维连续控制环境来可视化更强的奖励耦合如何改变 OPD 优化
- Student 策略是一个三层 MLP,大约有 4K 个参数
- 输入是一个三维向量,包含任务标识、当前位置和归一化时间步长
- 该策略输出高斯动作分布的均值和标准差,状态转移为
$$s_{t + 1} = s_t + \delta ,\qquad \delta \sim \mathcal{N}(\mu ,\sigma) $$ - 这两个任务是彼此的镜像:
- 左任务从 \(+2\) 开始,目标是 \(-3\)
- 右任务从 \(-2\) 开始,目标是 \(+3\)
- 本文首先使用 REINFORCE 训练独立的 Teacher,然后通过交替任务 OPD 将它们蒸馏到一个共享的 Student 中
C.2 Gradient variance estimation
- 在每个训练步骤,将一批 \(B = 64\) 条轨迹分成 \(M = 8\) 个 Micro-batch
- 对于每个 Micro-batch \(m\),计算损失 \(\mathcal{L}_{m}\) 和输出层参数上对应的梯度向量 \(\mathbf{g}_{m}\)
- 通过下式估计梯度方差
$$\operatorname {Var}(\mathbf{g}) = \frac{1}{M}\sum_{m = 1}^{M}| \mathbf{g}_m - \bar{\mathbf{g} }| ^2,\qquad \bar{\mathbf{g} } = \frac{1}{M}\sum_{m = 1}^{M}\mathbf{g}_m $$ - 仅将此量用作一个定性指标,但比较不同 \(\gamma\) 设置下的相对方差已经足够
C.3 Toy Additional Results of Toy Experiments
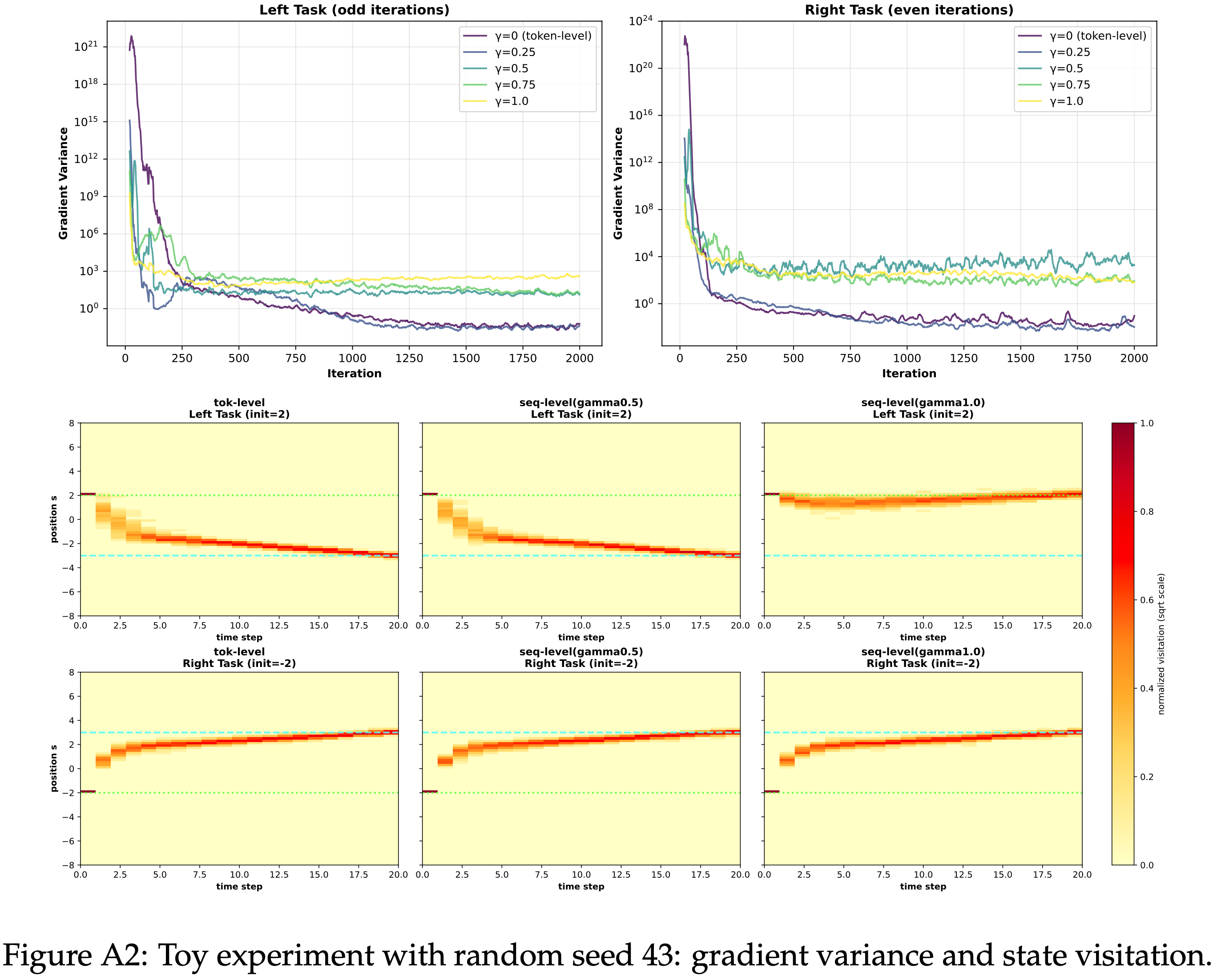
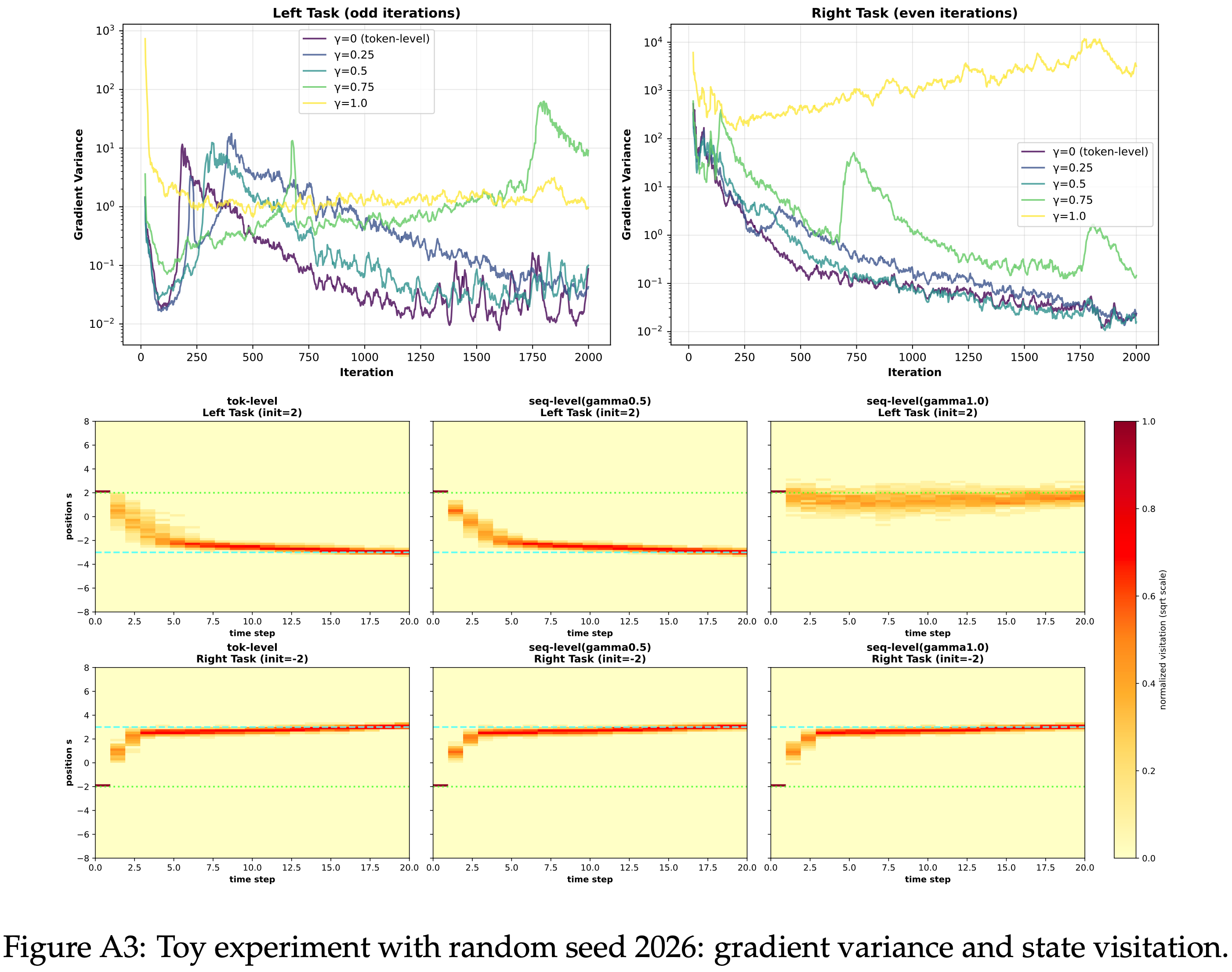
- 图 A1、A2 和 A3 报告了不同 OPD 估计器 (\(\gamma \in \{0.0, 0.25, 0.5, 0.75, 1.0\}\)) 在三个随机种子下的梯度方差曲线和相应的状态访问热图
- 尽管具体数值因种子而异,但定性模式是一致的
- 所有 Setting 在优化初期都表现出较大的方差峰值,并且较大的 \(\gamma\) 通常在训练后期保持在较高的方差水平
- 在几次运行中,\(\gamma = 0.75\) 或 \(\gamma = 1.0\) 下的方差比较小 \(\gamma\) 值下的方差保持高出一到几个数量级
- 在所有运行中, Token-level OPD (\(\gamma = 0\)) 始终能学习到向两个任务的目标状态移动的轨迹
- \(\gamma\) 的中间值在性质上保持相似,但变得更加分散
- 当 \(\gamma\) 接近 Sequence-level 情况 (\(\gamma = 1.0\)) 时,学习到的轨迹常常偏离期望的方向,并在状态空间的次优区域附近稳定下来
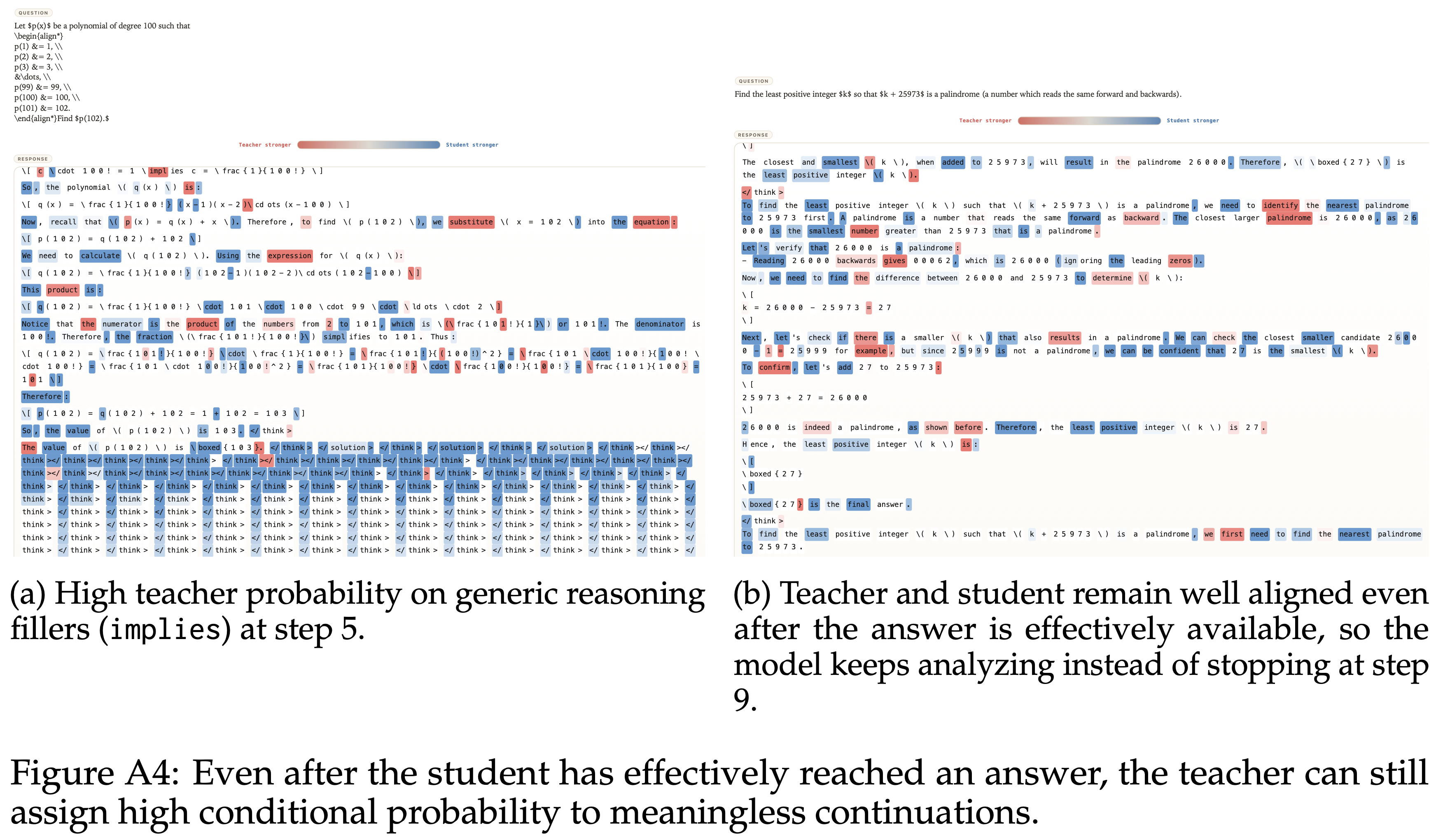
附录 D:Qualitative OPD reward-hacking case study,定性研究
- 为了补充正文中的代表性失败案例,这里总结一个来自 Sampled-token OPD 下多任务训练的较长轨迹
- 按时间顺序阅读,该案例以几种形式表现出相同的模式:
- 模型在已经有答案后仍然继续分析,陷入重复循环(例如“wait”),漂移到格式错误的延续中,并且仍然在这些 Token 上获得高的局部 Teacher 概率
- 1)失败首先表现为过度延续
- 即使在答案已经有效可用之后,局部信号仍然将大量质量放在通用的推理填充词和连接 Token 上,鼓励模型继续生成而不是干净地停止
- 同样的模式稍后出现在诸如 “confirm” 这样的前缀上,局部信号仍然偏好额外的验证而不是终止
- 这种行为的一部分也可能反映了 Teacher 自身的输出习惯
- 图 A4 展示了几个代表性案例
- 2)轨迹发展为犹豫循环和低信息延续
- 重复的 “wait” Token、大量标点符号的延续以及其他语义薄弱的填充词可能保持局部可奖励,即使整个轨迹已经变得无益
- 这与第 3.2 节中关于重复循环的讨论一致
- 图 A5 中提供了两个类似的案例

- 3)当 Student 进一步漂移到分布外,局部信号可能保持误导性的正向而不是自我纠正
- 在案例研究中,这表现为退化和乱码输出,然而许多 Token 仍然获得高的 Teacher 概率
- 图 A6 展示了一个例子