注:本文包含 AI 辅助创作
Paper Summary
- 背景:
- OPD:从 Teacher 模型获取密集、细粒度的信号
- RLVR:从环境中可验证的结果获得稀疏信号
- OPSD(On-policy self-distillation):同一个模型既作为 Teacher 又作为 Student , Teacher 接收额外的 Privileged information (如参考答案) 以实现自我进化
- OPSD方法的根本问题:
- 仅从 Privileged Teacher 那里获得的学习信号会导致严重的信息泄露 (information leakage) 和不稳定的长期训练
- 注:本文分别从目标层面和梯度层面理论分析了这个问题,解释了实验中观察到的早期收益随后系统性崩溃的模式问题
- 新的训练范式 RLSD(RLVR with Self-Distillation),集成了 OPSD 和 RLVR 的优点:
- From OPSD:利用自蒸馏来获取 Token-level 策略差异,以确定细粒度的更新幅度
- From RLVR:使用 RLVR 从环境反馈 (如 Response 的正确性) 中获得可靠的更新方向
- RLSD 不强迫 Student 模仿 Teacher 的条件分布,而是重新利用它们之间的差异来提供对每个 Token 更新幅度的精细控制,同时将更新方向锚定在环境奖励上
- 注:RLSD 已经不是常规的 OPD 方式了,RLSD 本质是对 GRPO 的改进,教师信号相当于仅仅影响 GRPO 的 Advantage 部分
- 注:RLSD 的同时拥有 OPSD 和 RLVR 的优点:
- 继承了 OPSD 的 Token-level 监督(密集奖励)
- 拥有 RLVR 可靠的环境信号基础
- 截止到 20260408 的版本,还有些内容没有补充:
- 本文当前主要在 Qwen 系列的多模态推理场景上实验
- 其他尝试已经在做,后续会补充
- 纯文本推理
- 视频理解
- 其他模型家族
Introduction and Discussion
- RLVR 中每个轨迹仅从环境获得一个由其结果决定的标量信号
- OPD 利用更强的 Teacher 模型,沿着 Student 自己采样的轨迹提供稠密的、Token-level Logits 作为学习信号,将轨迹级别的监督丰富到 Token-level ,从而实现更快的收敛
- 部分研究表明,来自高级 Teacher 的 OPD 可以媲美甚至超越 RLVR (2026)
- OPD 存在的问题:
- 依赖于一个独立的、通常大得多的 Teacher 模型,这带来了大量的计算开销
- Teacher 和 Student 模型必须共享相同的词汇表,因为 OPD 需要计算共享词汇表上的 Token-level 分布,OPD 可扩展性差
- OPSD 提供了一个有吸引力的替代方案:
- 单个模型同时充当 Teacher 和 Student ,其中 Teacher 以 Privileged 信息 \(r\) (例如,经过验证的推理轨迹或环境反馈) 为条件,而 Student 仅根据输入查询进行操作
- OPSD 在不需任何外部模型的情况下,实现了比 GRPO 高出数倍的 Token 效率
- 问题提出:
- 本文证明这种 OPSD 的效率增益是脆弱的:
- 如图 1(a) 中的红色曲线所示,性能在早期达到峰值,随后恶化
- 这伴随着系统性的 Privileged 信息泄露,即模型在推理过程中明确地引用了一个本不可见的参考解决方案 ,尽管本次 Prompt 从未访问过参考答案 (图 2 展示了一个代表性例子)
- 问题:为什么 OPD 有效而 OPSD 失败了?
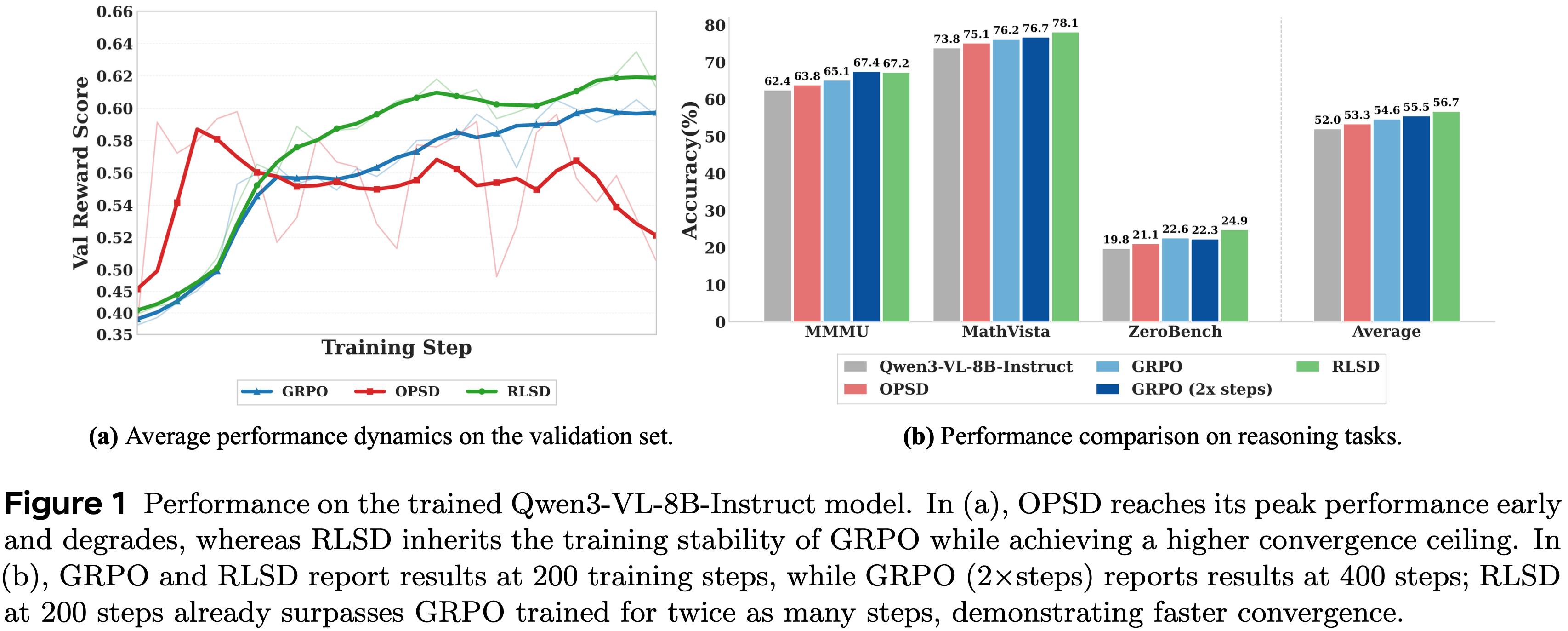

- 本文证明这种 OPSD 的效率增益是脆弱的:
- 目标层面问题分析:
- OPD 中, Teacher 和 Student 观察相同的输入 (信息对称),因此 Teacher 的密集信号反映了在共享信息访问下的卓越推理
- OPSD 中, Teacher 以 Student 无法观察到的 Privileged 信息为条件 (信息不对称),造成了根本性的不匹配
- 本文证明这种不对称性使得 OPSD 目标不适定 (ill-posed):
- 包含一个无法缩减的互信息 Gap
$$ I(Y_{t};R\mid X,Y_{< t}) > 0$$ - 无论 Student 的能力如何,这个 Gap 都无法消除 (定理 1)
- 包含一个无法缩减的互信息 Gap
- 梯度层面问题分析:
- 虽然预期的 OPSD 梯度是良性的,但每个样本的梯度携带一个 \(r\) 特定的偏差,其方差与该互信息成正比
- 本文实验直接证实了这些理论发现:
- 如图 3 所示,在 OPSD 下,** Teacher 和 Student 之间的 on-policy KL 散度没有持续减少**
- 注:on-policy KL 散度 指标在 OPD 下是稳步下降的
- 如图 3 所示,在 OPSD 下,** Teacher 和 Student 之间的 on-policy KL 散度没有持续减少**
- 原论文用两阶段分析动态精确地解释了观察到的早期收益随后逐渐退化的模式
- 在训练早期,有益的梯度分量占主导地位,产生快速改进
- 当 Student 接近 Teacher 的边际分布时,偏差接管,其路径依赖的累积驱动模型在其参数中编码 \(x \rightarrow r\) 的相关性
- 根本原因:
- OPSD 中, Teacher 的 Privileged 评估 \(P_{T}(y_{t} \mid r)\) 进入梯度方向,使得无论蒸馏目标如何压缩,泄漏在结构上都不可避免
- 注:比率 \(\frac{P_{T}(y_{t})}{P_{S}(y_{t})}\) 携带一个有用的信号:
- 这个比率衡量了 Privileged 信息对模型关于每个 Token 的信念修正了多少
- 作者认为:挑战不在于丢弃这个比率信号,而在于改变它的使用方式
- 本文设计的一个关键洞察是,控制更新方向和更新幅度的信号具有不对称的要求:
- 方向信号可以稀疏但必须可靠,因为错误的方向会损害策略
the directional signal can be sparse but must be reliable, as an erroneous direction harms the policy
- 幅度信号则受益于尽可能密集以实现 Token 间细粒度的区分
the magnitude signal, by contrast, benefits from being as dense as possible to enable fine-grained discrimination among tokens
- 方向信号可以稀疏但必须可靠,因为错误的方向会损害策略
- 本文设计的一个关键洞察是,控制更新方向和更新幅度的信号具有不对称的要求:
- RLSD 方法将上述原则落地,将 Teacher 从生成目标重新定位为幅度评估器
- 环境奖励决定每个 Token 的更新方向(强化或惩罚),而 Teacher 的证据比仅调节更新幅度
- 这种解耦将梯度方向完全锚定在可靠的环境奖励上,同时保留 Teacher 稠密的 Token-level 评估,用于轨迹内 Token 位置的细粒度信用分配
- 注:相对其他 Token-level 信用分配方法的优势:
- 之前的 Token-level 信用分配方法(如 PPO 中的价值函数估计),通常需要训练辅助网络或产生大量额外开销,且仍会产生有噪声的估计
- SD 提供了天然且几乎无成本的 per-token 信用信息来源,仅需一次额外前向传播
- 表 1 所示:RLSD 是唯一同时满足在线训练、高 token 效率、丰富更新信号、环境锚定优化 的范式,且可直接替换标准 GRPO 中的均匀优势函数,无需任何辅助损失或模型

Preliminaries
GRPO
- 每个回复相对于组内的序列级优势函数:
$$
A^{(i)}=\frac{R(x,y^{(i)})-\mu_{G} }{\sigma_{G} } \tag{1}
$$- \( \mu_{G} \) 与 \( \sigma_{G} \) 分别为组内奖励的均值与标准差
- 通过裁剪替代目标更新策略:
$$
\mathcal{L}_{GRPO}(\theta)=\mathbb{E}\left[\frac{1}{G} \sum_{i=1}^{G} \frac{1}{|y^{(i)}|} \sum_{t=1}^{|y^{(i)}|} min \left(\rho_{t}^{(i)} A^{(i)}, clip\left(\rho_{t}^{(i)}, 1-\epsilon, 1+\epsilon\right) A^{(i)}\right)\right]
$$- \( \rho_{t}^{(i)}=\pi_{\theta}(y_{t}^{(i)} | x, y_{ < t}^{(i)}) / \pi_{\theta_{old} }(y_{t}^{(i)} | x, y_{ < t}^{(i)}) \) 为当前策略与旧策略间的重要性采样比
- GRPO 的核心局限在于:
- 因为奖励信号仅在序列级提供,回复内所有 Token 共享同一优势 \( A^{(i)} \)
OPD and OPSD
- OPD:解决稀疏奖励问题
- Student \( \pi_{\theta} \) 采样自身轨迹
- 独立的、通常规模更大的 Teacher 模型 \( \pi_{\hat{\theta} } \) 提供稠密的 Token-level 监督
- 问题:全程维护独立 Teacher 模型会带来显著计算开销
- OPSD 由单一模型 \( \pi_{\theta} \) 同时充当 Teacher 与 Student :
- Teacher 的信息优势并非来自更大容量,而是以特权信息 \( r \)(如经过验证的推理轨迹)为条件
- OPD 和 OPSD 两种方法训练范式一致:
- 给定数据集
$$ \mathcal{S}=\{(x_{i}, r_{i})\}_{i=1}^{N} $$ - Student 生成在线 rollout
$$ \hat{y} \sim P_{S}(\cdot | x) $$ - 训练过程最小化 Student 轨迹上 Teacher 与 Student 分布间的 per-token 散度
- 给定数据集
- OPD 和 OPSD 的 Teacher 定义不同:
$$
\begin{align}
\text{Student:} & P_S(\cdot |y_{< t})\triangleq \pi_{\theta}(\cdot |x,y_{< t})\\
\text{OPD Teacher:} & P_T(\cdot |y_{< t})\triangleq \pi_{\theta}(\cdot |x,y_{< t})\\
\text{OPSD Teacher:} & P_T(\cdot |y_{< t})\triangleq \pi_{\theta}(\cdot |x,r,y_{< t}).
\end{align}
\tag {5}
$$ - OPD 和 OPSD 共享训练目标:
$$\mathcal{L}_{\text{OP}(S)\text{D} }(\theta) = \mathbb{E}_{(x,r)\sim \mathcal{S} }\mathbb{E}_{\hat{y}\sim P_S(\cdot |x)}\left[\frac{1}{|\hat{y}|}\sum_{t = 1}^{|\hat{y}|}D(P_T\parallel P_S)\right] \tag {6}$$- 理解:这里 OP(S)D 的含义是同时表示 OPD 和 OPSD
- \(D\) 是一个散度度量,例如广义 Jensen-Shannon 散度
- 梯度仅通过 \(P_S\) 反向传播,而 \(P_T\) 作为一个固定的目标
- OPSD 通过提供密集的、每个 Token 的监督,而不需要外部 Teacher 模型,实现了高 Token 效率
Why Does OPD Work While OPSD Fails?
Empirical Observations: Leakage and Performance Degradation,泄漏与性能退化
Privileged information leakage
- 观察: OPSD 训练的模型系统地引用了在推理时不可用的 Privileged 信息
- 图 2 展示了一个代表性例子,其中模型在生成过程中明确地引用了一个不可见的“参考解决方案”
- 这种行为并非个例,且这种泄漏在训练过程中逐渐加剧
- 这种行为并非个例,且这种泄漏在训练过程中逐渐加剧
Performance degradation
- 图 3(a) 跟踪了 100 个训练步中 Privileged 信息泄露的频率,显示出一个单调递增的趋势:
- 模型变得越来越依赖它在测试时无法访问的信息
- 图 3(b) 报告了相应的验证准确率,在前 10-20 步达到峰值,随后下降,这与不断升级的泄漏情况一致
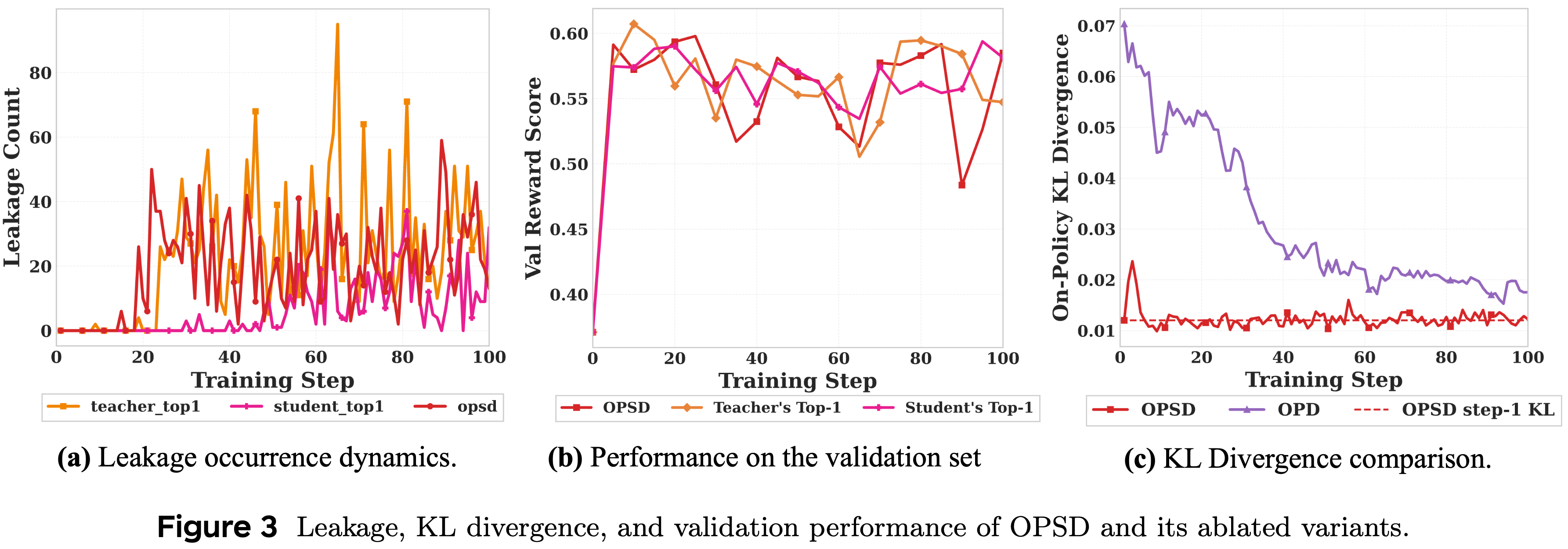
KL divergence stagnation, KL 散度停滞
- OPD 和 OPSD 下 Teacher 和 Student 之间的 on-policy KL 散度对比间 图 3(c)
- 在 OPD 下,KL 散度在整个训练过程中稳步下降,反映了真正的收敛
- 在 OPSD 下,散度在最初的几步短暂下降,但随后稳定在与初始值相当的水平,没有表现出持续的减少
- 这种停滞表明 OPSD 目标中存在一个 Irreducible Gap ,阻止了有意义的收敛
- 将在下一小节中形式化这个假设
- 理解:这里主要是说 Teacher 与 Student 之间的 KL 散度没有缩小,也就是训练目标没有变小?
- 两个问题:
- 为什么 OPSD 会导致泄漏?
- 为什么无法减少 KL 散度?
OPSD’s Failure: An Ill-Posed Objective,不适定的目标
- 本节从目标函数和梯度两方面,对 OPSD 及相关方法背后的分布匹配范式的结构性缺陷进行形式化
The Irreducible Mutual Information Gap,无法缩减的互信息 Gap
- 令 \(r\) 表示 Privileged 信息,它从条件分布 \(P(r\mid x)\) 中抽取
- 由于任何一个给定的问题 \(x\) 都允许多个语义上有效的推理路径,\(P(r\mid x)\) 是一个具有非零熵的非退化分布
- 即使每个训练实例 \(x_{i}\) 与一个单一的参考轨迹 \(r_{i}\) 配对,从 Student 的认知角度来看,它既不能观察到 \(r\) 也不能从 \(x\) 确定性地推导出 \(r\), Privileged 信息仍然是一个不确定的潜在变量,并且在概率建模框架内应将 \(P(r\mid x)\) 视为非退化的
- 最优 Student 策略 应该是 在不包含 \(r\) 为条件情况下,能 通过 全概率公式恢复边际 Teacher 分布:
$$P_{s}^{*}(y_{t}\mid x,y_{< t}) = \mathbb{E}_{r\sim P(r\mid x,y_{< t})}[P_{T}(y_{t}\mid x,r,y_{< t})] \tag {7}$$ - 令 \(\bar{P}_{T}(y_{t})\) 表示这个边际分布
$$ \bar{P}_{T}(y_{t})\triangleq \mathbb{E}_{r}[P_{T}(y_{t}\mid x,r,y_{< t})]$$ - 理想的蒸馏目标 是:
$$
\begin{align}
\mathcal{L}^{*}(\theta) &= \mathbb{E}_{x}\Big[D_{\text{KL} }\Big(\bar{P}_{T}(\cdot)\Big| P_{S}(\cdot \mid x)\Big)\Big] \\
&= \mathbb{E}_{x}\Big[D_{\text{KL} }\Big(\mathbb{E}_{r}[P_{T}(y_{t}\mid x,r,y_{< t})]\Big| P_{S}(\cdot \mid x)\Big)\Big]
\end{align}
\tag {8}
$$ - OPSD 目标强制每个样本 \((x,r)\) 匹配 \(P_{S}(\cdot \mid x)\to P_{T}(\cdot \mid x,r)\)
$$\mathcal{L}_{\text{OPSD} }(\theta) = \mathbb{E}_{x}\mathbb{E}_{r\sim P(r\mid x)}[D_{\text{KL} }(P_{T}(\cdot \mid x,r)\parallel P_{S}(\cdot \mid x))] \tag {9}$$- 注:这是在强制一个 条件独立的 \(P_{S}\) (不以 \(r\) 为输入)去 匹配 一个 条件依赖的目标 \(P_{T}\) (依赖于 \(r\))
- 这构成了一个根本上不适定的要求
- OPSD 目标和 理想的蒸馏目标 并不等价
- 注:这是在强制一个 条件独立的 \(P_{S}\) (不以 \(r\) 为输入)去 匹配 一个 条件依赖的目标 \(P_{T}\) (依赖于 \(r\))
- Theorem 1 (KL Decomposition)
- OPSD 目标和理想目标满足恒等式:
$$\mathcal{L}_{\text{OPSD} } = \mathcal{L}^{*} + I(Y_{t};R\mid X,Y_{< t}) \tag {10}$$- \(I(Y_{t};R\mid X,Y_{< t})\) 表示:在 Teacher 分布下,当前 Token \(Y_{t}\) 与 Privileged 信息 \(R\) 之间的条件互信息
- 理解:即当前 Token \(Y_{t}\) 本来和 Privileged 信息 \(R\) 没有关系,但是因为训练时强制让他们之间发生分布拟合,这个就导致了 当前 Token \(Y_{t}\) 本来和 Privileged 信息 \(R\) 之间发生关系了!
- 补充互信息的定义:若 \(X\) 和 \(Y\) 为离散随机变量,联合概率分布为 \(P(X,Y)\),边缘概率分布分别为 \(P(X)\) 和 \(P(Y)\),则互信息的定义为:
$$
I(X;Y)=\sum_{x\in X}\sum_{y\in Y}P(x,y)\log\frac{P(x,y)}{P(x)P(y)}
$$- 当 \(X\) 和 \(Y\) 相互独立时,\(P(x,y)=P(x)P(y)\),此时 \(I(X;Y)=0\);
- 当 \(X\) 和 \(Y\) 完全依赖时,\(I(X;Y)\) 达到最大值,等于 \(X\) 或 \(Y\) 的熵(\(H(X)\) 或 \(H(Y)\))
- 补充互信息的定义:若 \(X\) 和 \(Y\) 为离散随机变量,联合概率分布为 \(P(X,Y)\),边缘概率分布分别为 \(P(X)\) 和 \(P(Y)\),则互信息的定义为:
- Theorem 1 证明见附录 A.1
- OPSD 目标和理想目标满足恒等式:
- 注:互信息项 \(I(Y_{t};R\mid X,Y_{< t})\) 量化了** Teacher 的 Token-level 预测对 Privileged 信息的依赖程度** (互信息越大,依赖越大)
- 但该信息对 Student 来说,是不可访问的
- 而且,\(I(Y_{t};R\mid X,Y_{< t})\) 与 \(\theta\) 无关:
- \(I(Y_{t};R\mid X,Y_{< t})\) 完全由 Teacher 的条件分布和 \(P(r\mid x)\) 决定
- 针对 Student 参数的优化无法消除这个 Gap ,或者说无论如何更新 Student 的参数 \(\theta\),这个 Gap 都不会变化
- 在下面的可行集内
$$ \mathcal{F} = \{Q:Q(\cdot \mid x,y_{< t}) \text{ does not condition on } r\} $$- 全局最优是
$$ P_{S}^{*} = \bar{P}_{T}$$ - 此时的残差损失等于
$$ I(Y_{t};R\mid X,Y_{< t}) > 0$$- 这是一个严格为正、 Irreducible 下界,并且随着 Privileged 信号信息量的增加而增加
- 全局最优是
- 这个结果为图 3(c) 中观察到的 KL 停滞提供了一个形式化的解释:
- OPSD 散度趋于平稳,因为 Student 迅速接近 \(\bar{P}_{T}\) 的邻域,此后残差 \(I(Y_{t};R\mid X,Y_{< t}) > 0\) 无法通过合法的优化来减少
- 图 3(c) 中标记 OPSD 在第 1 步 KL 值的虚线直观地证实了,这个损失下界实际上在最初的几步内就达到了
- 特别是:这个 Irreducible 残差会积极破坏优化过程
- 在一个有偏的目标下,优化器持续接收到非零的损失信号,并被驱使将有害的噪声吸收到模型参数中
- 这个残差项直接污染了梯度方向,使参数更新偏离真正的推理改进,转而将输入与 Privileged 信息之间的虚假相关性编码到模型中
- Privileged 信息泄露的数学根源 :
- Student 的架构排除了直接以 \(r\) 为条件,唯一可用的途径是在参数 \(\theta\) 中编码 \(x\) 和 \(r\) 之间的统计相关性,从而有效地学习一个映射 \(x \rightarrow r\)
- 问题:这里的理解不对吧?当模型的参数与这一项无关时,梯度为 0 啊,不会影响模型的收敛
- 注:OPD 与 OPSD 不同,OPD 使用一个外部 Teacher ,其预测不以 Student 无法访问的 Privileged 信息为条件,因此互信息 Gap 不会出现,并且 KL 散度稳步下降
Gradient Structure: The Mechanism of Leakage,梯度结构:泄漏的机制
- 定理 1 确立了 \(I(Y_{t};R\mid X)\) 是与 \(\theta\) 无关的,这可能暗示它对梯度没有影响
- 本节证明,虽然这对期望梯度成立,但每个样本的梯度携带一个偏差项,其方差直接由这个互信息控制
Benign expected gradien,良性的期望梯度
- 由于 \(I(Y_{t};R\mid X)\) 不依赖于 \(\theta\) ,我们有
$$\nabla_{\theta}\mathcal{L}_{\text{OPSD} } = \color{red}{\nabla_{\theta}\mathcal{L}^{*}} = - \sum_{v}\bar{P}_{T}(v)\nabla_{\theta}\log P_{S}(v)$$- 在总体水平上,OPSD 梯度与理想边际匹配目标的梯度相同
- \(\bar{P}_{T}(y_{t})\) 表示边际分布:
$$ \bar{P}_{T}(y_{t})\triangleq \mathbb{E}_{r}[P_{T}(y_{t}\mid x,r,y_{< t})]$$- 理解:这个分布是一个边际分布,要求对所有可能的奖励 \(r\) 进行积分求期望才可以
- 现实场景中,往往一个样本对应一个奖励 \(r\) ,即使采样多个 \(r\) ,也很难还原出来当前的分布 \(p(r|x)\)
- 理解:这个分布是一个边际分布,要求对所有可能的奖励 \(r\) 进行积分求期望才可以
Pathological per-sample gradients,病理性的 per-sample 梯度
- 在实践中,优化是在具体的样本 \((x,r)\) 上进行的:
$$g(\theta ;r) = -\sum_{v\in \mathcal{V} }P_{T}(v\mid r)\cdot \nabla_{\theta}\log P_{S}(v) \tag {11}$$ - Proposition 1 (Per-Sample Gradient Decomposition)
- 对于任何具体的 \(r\) 实现,每个样本的梯度可以分解为:
$$
\begin{align}
g(\theta ;r) &= -\underbrace{\sum_{v}\bar{P}_{T}(v)\nabla_{\theta}\log P_{S}(v)}_{\substack{g^{*}(\theta):\text{ marginal matching} } } + \underbrace{-\sum_{v}[P_{T}(v\mid r) - \bar{P}_{T}(v)]\nabla_{\theta}\log P_{S}(v)}_{\substack{\delta(\theta;r):\text{ r-specific deviation} } } \tag {12} \\
&= g^{*}(\theta) + \delta(\theta;r)
\end{align}
$$- 可将 \(g^*(\theta)\) 视为一个梯度,它来源于最小化一个 KL 散度:
$$
\begin{align}
g^*(\theta) &= -\sum_v \bar{P}_T(v) \nabla_\theta \log P_S(v) \\
&=\nabla_\theta D_{\text{KL} }(\bar{P}_T || P_S) \\
&=\nabla \mathcal{L}^*(\theta)
\end{align}
$$- 即:按照梯度 \(g^*(\theta)\) 更新,等价于 让学生的分布 \(P_S\) 去匹配教师的边际分布 \(\bar{P}_T\) ,是一个标准的 KL 散度最小化问题
- 当 \(P_S = \bar{P}_T\) 时,KL 散度达到最小值 0
- 此时梯度 \(g^*(\theta) = 0\)
- 当 \(P_S\) 接近 \(\bar{P}_T\) 时
- 梯度范数 \(|g^*(\theta)|\) 也趋近于 0
- 可将 \(g^*(\theta)\) 视为一个梯度,它来源于最小化一个 KL 散度:
- 且满足以下两点性质:
- 性质(i),误差期望为 0:
$$ \mathbb{E}_{r}[\delta (\theta ;r)] = 0 $$ - 性质(ii),误差方差不为 0:
$$ \mathbb{E}_{r}[| \delta (\theta ;r)|^{2}] = \sum_{v}\text{Var}_{r}[P_{T}(v\mid r)]\cdot | \nabla_{\theta}\log P_{S}(v)|^{2}$$- 当 \(I(Y_{t};R\mid X) = 0\) 时偏差消失,方差随互信息单调增加
- 性质(i),误差期望为 0:
- 证明见附录 A.2
- 对于任何具体的 \(r\) 实现,每个样本的梯度可以分解为:
- 性质 (i) 可能表明偏差在平均意义上是无害的
- 但任何在单个样本或小批量上计算梯度的优化器,例如 SGD 和 Adam,本质上是路径依赖的
- 在非线性优化中,零均值的扰动不一定会随着训练的进行而抵消
Two-phase training dynamics
- 命题 1 中的分解将每个样本的梯度划分为一个有益分量 \(g^{*}\) 和一个偏差分量 \(\delta\)
- 它们的相对大小在训练过程中演变,并产生了两个截然不同的阶段,这正好对应于 §3.1 中报告的实证现象
- 在训练早期, Student \(P_{S}\) 远离 Teacher 的边际分布 \(\bar{P}_{T}\) ,因此有益分量占主导地位:
$$ | g^{*}(\theta)| \gg | \delta (\theta ;r)|$$- 在这个阶段,梯度主要驱动边际匹配, Student 迅速获得一般的推理能力
- 对应于图 3(b) 中前 10-20 步观察到的验证准确率的急剧上升
- 在这个阶段,梯度主要驱动边际匹配, Student 迅速获得一般的推理能力
- 随着训练的进行和 \(P_{S}\) 接近 \(\bar{P}_{T}\) ,有益分量 \(| g^{*}(\theta)|\) 趋近于零(详情见前一小节的补充分析)
- 偏差分量 \(| \delta (\theta ;r)|\) 保持远离零:
- 其方差由 \(I(Y_{t};R\mid X)\) 控制,该值与 \(\theta\) 无关,因此不会随着优化进展而衰减
- 参数更新变得越来越由 \(\delta\) 主导,并且这些扰动的路径依赖累积将模型推向编码 \(x \rightarrow r\) 相关性的参数空间区域,触发自我强化的退化
- 这个转变标志着图 3(b) 中性能下降的开始和图 3(a) 中泄漏计数的单调增加
- 偏差分量 \(| \delta (\theta ;r)|\) 保持远离零:
Leakage bandwidth: controlled experiments
- 梯度分解不仅解释了标准 OPSD 的失败,还做出了一个精确的预测:
- 任何 Teacher Privileged 评估 \(P_{T}(\cdot \mid r)\) 进入梯度方向的变体都会遭受泄漏,无论蒸馏目标如何压缩
- 为了验证这个预测,本文设计了两个消融变体与标准 OPSD 进行比较:
- (i) Teacher’s Top-1:仅保留 Teacher 最可能的 Token 作为目标
$$ \arg \max_{v}P_{T}(v \mid r) $$ - (ii) Student’s Top-1:将目标 Target Support 在 Student 最可能的 Token
$$ \arg \max_{v}P_{S}(v) $$- 理解:这里表述是 Target Support,但因为是 \(\arg \max_{v} \),所以是只有一个 Token 被选中
- 之所以叫做 Target Support,本质上是说明仅仅是影响了计算梯度的 Token 的选择,但不影响计算梯度的 Token 的权重计算等(OPD 的 Token 梯度权重是 Teacher 的概率和 Student 概率的比值 或 对数概率的差)
- 理解:这里表述是 Target Support,但因为是 \(\arg \max_{v} \),所以是只有一个 Token 被选中
- (i) Teacher’s Top-1:仅保留 Teacher 最可能的 Token 作为目标
- 图 3(a,b) 中报告了所有三个变体在 100 个训练步中的泄漏计数和验证准确率
- 所有三个变体都证实了预测:每种情况下泄漏都增加了
- 梯度框架通过泄漏带宽 (leakage bandwidth) 的概念解释了泄漏的普遍性和严重性排序,本文将泄漏带宽定义为 \(r\) 特定信息进入梯度方向的有效 Token 位置数量
- (带宽最宽)完整的 OPSD 在整个词汇表 \(\nu\) 上操作:
- Teacher 的 Privileged 偏好 \(P_{T}(v \mid r)\) 加权了每个 Token 的梯度贡献
- 带宽最宽
- (最严重的泄漏)Teacher Top-1 将目标坍缩为单个 Token
$$\arg \max_{v}P_{T}(v \mid r)$$- 该 Token 完全由 \(r\) 决定,缩小了带宽但产生了最集中的 Privileged 信息注入
- 这解释了为什么它表现出最严重的泄漏
- (速率最低)Student Top-1 将目标支持限制在 (单个 Token 上)
$$ \arg \max_{v}P_{S}(v)$$- 产生了最窄的带宽(理解:因为选择什么 Token 完全不由 \(r\) 来决定)
- 但是:在选定 Token 上的梯度权重 仍然是 \(r\) 的函数
$$ \frac{P_{T}(v_{S}^{r} \mid r)}{P_{S}(v_{S}^{s})}$$- 因此泄漏仍然存在(但泄露导致的问题速率最低,受影响最小)
- 问题:这里应该是 \(\log \frac{P_{T}(v_{S}^{r} \mid r)}{P_{S}(v_{S}^{s})}\) 吧?
- 在所有三种情况下,梯度对 \(r\) 的方向依赖是 Irreducible (证明见附录 A.3)
- 这解释了图 3(a) 中观察到的泄漏普遍发生
- 图 3(b) 中的性能退化直接由此导致:
- 更强的泄漏加速了从第一阶段到第二阶段的过渡,并导致更快速的性能下降
- 附录 A.4 中进一步分析了共享参数耦合的含义,其中展示了梯度级泄漏与共享参数下的 Teacher 漂移之间的相互作用导致了一个不可能三角 (impossibility trilemma)
- 在任意的参数管理策略下,目标稳定性、持续改进和无泄漏训练不能同时成立
RLSD: Self-Distillation as RLVR’s Wingman,RLVR 的辅助
- 前面的分析确定了根本原因:
- 分布匹配之所以失败,是因为 Privileged 信息进入了梯度方向,污染了优化轨迹
- 即证据比(evidence ratio)\(\frac{P_{T}(y_{t})}{P_{S}(y_{t})}\) 就包含了梯度信息
- 同时,evidence ratio \(\frac{P_{T}(y_{t})}{P_{S}(y_{t})}\) 也携带着有用的信号:
- \(\frac{P_{T}(y_{t})}{P_{S}(y_{t})}\) 衡量了 Privileged 信息对模型关于每个 Token 的信念进行了多大程度的修正
- 我们的目标不是丢弃这个信号,而改变它的使用方式
- 本文提出了 RLSD,重新定义了 Teacher 的角色:
- Teacher 不再作为分布匹配的生成目标,而是将 \(P_{T}\) 和 \(P_{S}\) 之间的差异用作策略梯度框架内的 Token-level 信用分配信号
- Privileged 信息仅影响每个 Token 获得多少信用 (credit),而不影响哪些 Token 被强化或惩罚,也不影响参数更新的方向
- 问题:这样做的理论依据是什么?为什么 \(\frac{P_{T}(y_{t})}{P_{S}(y_{t})}\) 大的 Token 应该分配更多的信用?
From Distribution Matching to Credit Assignment
Step 1: Privileged information gain
- 给定一个 Student 采样的轨迹
$$ y = (y_{1}, \ldots , y_{T})$$ - 计算每个 Token 在仅 Student 上下文(仅有 \(x\) )和 Teacher 上下文(有 \(x\) 和 \(r\) )下的对数概率,并定义每个位置的 Privileged 信息增益:
$$\Delta_{t} = \mathbf{sg}(\log P_{T}(y_{t}) - \log P_{S}(y_{t})) \tag {13}$$- \(\mathbf{sg}\) 表示 stop-gradient 操作符
- 由于 Teacher 和 Student 共享同一个模型,\(\Delta_{t}\) 隔离了 Privileged 信息 \(r\) 对预测 \(y_{t}\) 的边际贡献
- 大的正 \(\Delta_{t}\) 表明 \(r\) 强烈支持该 Token
- 负值则表明 \(r\) 不支持它
- \(\Delta_{t}\) 提供了一个密集的、 Token-level 信号
- \(\Delta_{t}\) 自然地反映了每个 Token 受 Privileged 信息影响的程度,使其成为在轨迹内进行细粒度信用分配的一个原则性且轻量级的基础
Step 2: Direction-aware evidence reweighting
- 利用 Privileged 信息增益构建每个 Token 的权重,并通过序列级别优势 (advantage) 的符号进行调制:
$$w_{t} = \exp (\text{sign}(A)\cdot \Delta_{t}) = \left(\frac{P_{T}(y_{t})}{P_{S}(y_{t})}\right)^{\text{sign}(A)} \tag {14}$$ - 这个公式有一个自然的贝叶斯解释:
- \(P_{S}(y_{t})\) 代表了模型仅基于问题 \(x\) 对 Token \(y_{t}\) 的先验评估
- \(P_{T}(y_{t})\) 代表了观察到 Privileged 信息 \(r\) 后的后验评估
- 因此,比值 \(\frac{P_{T}(y_{t})}{P_{S}(y_{t})}\) 是一个证据比:
- 即 Privileged 信息修正模型关于每个 Token 的信念的因子
- 在温和的建模假设下,可以证明这个比值等于贝叶斯信念更新
$$ \frac{P(r \mid x, y_{\color{red}{\leq} t})}{P(r \mid x, y_{< t})}$$- 即生成 \(y_{t}\) 在多大程度上增加了 Privileged 信息 \(r\) 与轨迹一致的后验概率(附录 A.5 中的定理 4)
- 指数中的 \(\text{sign}(A)\) 实现了方向感知的信用分配
- 当 \(A > 0\) 时,\(w_{t} = \frac{P_{T} }{P_{S}}\):
- 理解:整体 Token 都会被提升概率
- 受到 Privileged 信息支持的 Token 获得更大的权重,将正向信用集中在与正确推理轨迹最一致的 Token 上
- Privileged 信息不支持的 Token 获得更小的权重(少更新一些)更相信 Teacher 对准确 Token 贡献的判断
- 理解:整体 Token 都会被提升概率
- 当 \(A < 0\) 时,\(w_{t} = \frac{P_{S}}{P_{T}}\):
- 比值被反转,因此 Privileged 信息不支持的 Token 承担更大的责任,而它支持的 Token 则受到较轻的惩罚
- 理解:整体 Token 都会被降低概率
- 本质:还是相信教师的判断,即使 Rollout 整体都错了,但是让教师信号来判断哪些 Token 大概率问题不大,哪些 Token 问题比较大
- Privileged 信息不支持的 Token 承担更大的责任
- 教师低概率,学生低概率的 Token,让 Token 降低的幅度大一些(因为教师也觉得它有问题,学生确生成太高)
- Privileged 支持的 Token 则受到较轻的惩罚
- 教师高概率,学生低概率的 Token,让 Token 降低的幅度小一些
- Privileged 信息不支持的 Token 承担更大的责任
- 本质:还是相信教师的判断,即使 Rollout 整体都错了,但是让教师信号来判断哪些 Token 大概率问题不大,哪些 Token 问题比较大
- 由于 \(\exp (\cdot) > 0\) 对所有输入都成立,权重严格为正,保证了重加权永远不会翻转 Token-level 优势的符号
- 环境奖励保留了对一个轨迹是被强化还是被惩罚的专属决定权
- Teacher 仅调节一个轨迹内各个 Token 之间信用的相对大小
- 当 \(A > 0\) 时,\(w_{t} = \frac{P_{T} }{P_{S}}\):
- 这种设计类似于 GRPO 中用于策略更新的重要性采样比率 \(\frac{\pi_{\theta}}{\pi_{\text{old} }}\)
- GRPO 使用当前策略与旧策略的比率来控制更新的步长(理解:这里的理解有问题吧,GRPO 中是重要性采样恢复 On-policy 等价梯度,RLSD 并不是类似功能)
- RLSD 使用后验与先验的比率来控制跨 Token 的信用分布
- 两者都是在同一策略梯度框架内运行的重要性比率,形成了一个结构统一的公式
Step 3: Clipped credit assignment
- 遵循 PPO 和 GRPO 中裁剪代理目标的设计理念,本文对证据权重进行裁剪,以限制任何单个 Token 的最大影响:
$$\hat{A}_{t} = A\cdot \text{clip}(w_{t},1 - \epsilon_{w},1 + \epsilon_{w}) \tag {15}$$- \(\epsilon_{w}\) 限制了每个 Token 的信用偏差
- 公式 (15) 中的裁剪扮演着类似于 GRPO 中重要性比率裁剪的角色:
- GRPO 裁剪策略更新的步长,而 RLSD 裁剪信用重新分布的幅度
- 两种机制都作为信任区域约束,以稳定训练
- 实践中,为了避免在训练开始时出现突变:
- 在训练步骤中使用 \(\lambda \in [0,1]\) 在线性插值均匀优势和重加权优势之间进行平滑过渡,逐渐过渡到均匀优势
- 理解:这个做法相当于是说在未经过重加权的优势 \(A^{(i)}\) 和 重加权优势 \(A\cdot \text{clip}(w_{t},1 - \epsilon_{w},1 + \epsilon_{w})\) 之间做平滑过渡,训练过程中 \(\lambda\) 逐渐缩小,最终生效的变成 优势 \(A^{(i)}\) ,此时 重加权优势 \(A\cdot \text{clip}(w_{t},1 - \epsilon_{w},1 + \epsilon_{w})\) 不再对训练产生影响
- RLSD 的最终目标 如下:
$$\mathcal{L}_{\text{RLSD} }(\theta) = \mathbb{E}\left\{\frac{1}{G}\sum_{i = 1}^{G}\frac{1}{|y^{(i)}|}\sum_{t = 1}^{|y^{(i)}|}\min \left[w_{t}A^{(i)},\text{clip}(w_{t},1 - \epsilon_{w},1 + \epsilon_{w})A^{(i)}\right]\right\} \tag {16}$$
Integration with GRPO
- 修改后的优势 \(\hat{A}_{t}\) 是标准 GRPO 目标中均匀优势的直接代理
- 完整的训练流程总结在算法 1 中

- 没有引入额外的蒸馏损失,对标准 GRPO 流程的唯一修改是每个轨迹内部信用的重新分配
- 额外的计算成本相当于每个 Response 进行一次前向传播以获得 Teacher logits,与主导 wall-clock 时间的 Rollout 生成相比,这可以忽略不计
A Unified Token-Level Advantage Perspective,统一视角
- GRPO、OPSD 和 RLSD 都可以表示为单个策略梯度模板的实例:
$$\Delta \theta \propto \mathbb{E}_{y\sim P_S(\cdot |x)}\left[\sum_{t = 1}^{|y|}\hat{A}_t\nabla_\theta \log P_S(y_t\mid x,y_{< t})\right] \tag {17}$$- 其中,这些方法的区别仅在于它们如何定义 Token-level 优势 \(\hat{A}_t\)
GRPO
- 为所有 Token 分配一个均匀的优势:
$$ \hat{A}_t = A$$- \(A\) 是来自验证器的序列级别优势
- 这确保了优化方向完全基于环境奖励,但没有提供 Token-level 区分:
- 一个轨迹内的每个 Token,无论其对最终答案的贡献如何,都获得相同的信用
OPSD, On-policy self-distillation
- 用密集的 Teacher 信号取代了环境奖励
- \(\hat{A}_t\) 的具体形式取决于散度度量:
- 通过 log-derivative 技巧最小化反向 KL \(D_{\text{KL} }(P_S| P_T)\) 得到
$$ \hat{A}_t = \Delta_t = \log P_T(y_t) - \log P_S(y_t)$$
- 通过 log-derivative 技巧最小化反向 KL \(D_{\text{KL} }(P_S| P_T)\) 得到
- 即使一个轨迹产生了错误的答案 ( \(A< 0\) ),环境奖励 \(R(x,y)\) 也完全不存在于 \(\hat{A}_t\) 中,受到 Teacher 偏好的 Token ( \(\Delta_t > 0\) ) 仍然获得正的优势,从而将优化方向与可验证的正确性信号解耦
- 理解:此时的 Advantage 是 Token-level 的,且在不添加 ORM 的情况下,Advantage 与 Token 所在轨迹最终答案无关,仅与该 Token 与 Teacher Token 的 Token 概率比值有关
RLSD
- 通过结合两种信息来源解决了这一矛盾
- 其 Advantage (公式 15) 使用环境奖励来确定每个 Token 更新的方向 (符号)
- 用 Teacher 的 Privileged 评估来确定一个轨迹内的幅度 (相对信用)
- 附录 A.6 中提供了一个形式化的证明,表明这些属性使得 RLSD 在结构上对 Privileged 信息泄露具有免疫力,并验证了 RLSD 同时满足不可能三难困境 (附录 A.4) 的所有三个期望属性
Experiment
Experimental Setup
Training Data and Benchmarks
- 在 MMFineReason-123K (2026) 上训练模型
- 这是一个通过基于难度的过滤从 MMFineReason-1.8M 语料库中得出的具有挑战性的子集
- 使用 Qwen3-VL-4B-Thinking 对每个训练样本进行四次独立的 Rollout 推理,并且只保留模型在所有尝试中都失败的样本
- 这个保守的标准丢弃了琐碎的示例,将训练信号集中在具有挑战性的问题上 ,从而实现了更快的收敛和更高效的计算资源利用
- 在五个涵盖不同数学和通用推理能力的多模态推理基准上进行了评估
- MMMU (2024) 是一个大规模多学科基准,涵盖科学、工程和人文领域的大学水平科目,需要感知和领域知识
- MathVista (2024) 评估视觉情境中的数学推理
- MathVision (2024) 将数学推理评估扩展到更复杂和竞赛级别的视觉问题
- ZeroBench (2025) 是一个具有挑战性的基准,专门设计用于难倒当前最先进的模型,为推理鲁棒性提供了一个压力测试
- WeMath (2024) 评估具有结构化难度级别的细粒度数学问题解决能力
- 这些基准为评估多模态推理性能的广度和深度提供了一个全面而严格的评估
- 对于所有基准,报告准确率 (accuracy \((%)\) ) 作为评估指标
Models and Baselines
- 在 Qwen3-VL-8B-Instruct (2025) 作为基础模型上进行实验
- 将 RLSD 与以下基线进行比较
- GRPO:从序列级别的稀疏标量结果奖励中估计 Token-level 优势,作为主要 RL 基线
- OPSD (2026) 中单个模型同时充当 Teacher 和 Student
- Teacher 以 Privileged 信息(例如,已验证的推理轨迹)为条件,提供密集的每个 Token 监督
- SDPO (2026) 将自蒸馏扩展到具有丰富反馈的强化学习环境中 (除了 奖励信号/Hint 外,基本和 OPSD 方法一致)
- 将以环境反馈为条件的当前模型视为一个 Self-Teacher ,以推导密集的信用分配信号
- GRPO+OPSD 是一个直接的组合基线,受到 MIMO-v2-Flash (2026) 中提出的 MOPD 方法的启发,该方法联合优化强化学习和蒸馏目标
- 具体方法:通过线性插值和调整后的权重系数,将 GRPO 损失与蒸馏 KL 散度损失结合起来(理解:损失函数既有 ORM 的 GRPO Loss,也有 Token-level 的 OPD 损失/KL 散度)
- 与 MOPD 不同,MOPD 依赖单独训练的专家模型进行蒸馏,本文采用 OPSD 公式,使用模型自身的 Rollout 输出作为蒸馏目标,从而消除了对外部专家的需求,同时仍然利用密集的自蒸馏信号以及稀疏的环境奖励
- 本文还包括 Base LLM(即未经任何后训练的 Qwen3-VL-8B-Instruct)作为参考,以量化后训练带来的总体收益
Implementation Details
- 基于 VERL (2025) 和 EasyR1 (2025) 框架实现本文的方法
- 在训练期间(注:训练和评估期间一致使用相同的提示和 Response 长度设置)
- 模型的最大上下文长度设置为 8192,最大 Prompt 长度为 4096,最大 Response 长度为 4096
- 对于 GRPO、GRPO+OPSD 和 RLSD
- 学习率固定为 \(1 \times 10^{- 6}\)
- 对于 OPSD 和 SDPO
- 学习率设置为 \(1 \times 10^{- 5}\) (按照其原始实现)
- 训练批次大小设置为 256
- 对于每个提示,采样 8 个 Rollout
- 采样温度为 1.0
- 对于所有基于 GRPO 的方法,使用裁剪阈值 \(\epsilon_{\text{low} } = 0.2\) 和 \(\epsilon_{\text{high} } = 0.28\) ,并从目标函数中省略了 KL 惩罚损失和熵正则化损失
- RLSD 中的超参数 \(\lambda\) 初始化为 0.5,并在前 50 个训练步骤中线性衰减到 0,并且 \(\epsilon_{\text{w} }\) 设置为 0.2
- 为了保持稳定的自蒸馏信号,Teacher 模型参数每 10 个训练步骤与 Student 模型同步一次 ,并在其间保持冻结
- 关于不同方法所需的 Privileged 信息:
- OPSD 需要验证的推理轨迹,为此使用从 Qwen3-VL-235B-A22B-Thinking 中蒸馏出来并在 MMFineReason-123K 数据集中验证为正确的推理轨迹
- SDPO 使用一个成功的先前 Rollout 作为 Privileged 上下文(遵循其在论文中的原始设置)
- RLSD 仅需要最终的真实答案,不需要任何推理轨迹,它在 Privileged 信息方面的要求最低
- 所有实验均在 4 个计算节点上进行,每个节点配备 8 个 NVIDIA H200 140GB GPU
Experimental Results
Main Results
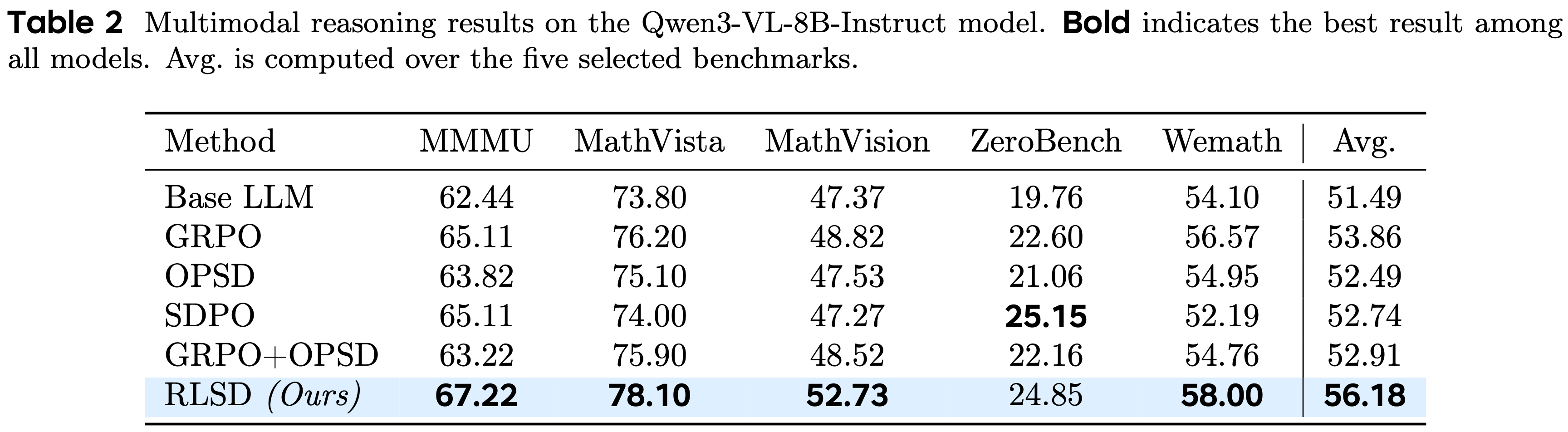
- 表 2 展示了在五个多模态推理基准上的评估结果
- RLSD 实现了最高的平均准确率,在 4K 设置下,平均超过基础 LLM 4.69%,超过 GRPO 2.32%
- 与 GRPO 相比,RLSD 受益于密集的 Token-level 信用分配,在具有挑战性的数学数据集上取得了显著的提升,例如 MathVista (+1.9%) 和 MathVision (+3.91%),在这些数据集上,推理步骤的细粒度区分最为重要
- RLSD 在平均准确率上也持续优于自蒸馏基线 (OPSD 和 SDPO)
- 这一实证差距与第 3.2 节中的理论诊断一致:
- 尽管 OPSD 由于信息不对称下的分布匹配而遭受 Privileged 信息泄露,但 RLSD 提取了密集的 Teacher 信号,同时将更新方向锚定在验证器奖励上,从而产生了更鲁棒的推理改进
- 这一实证差距与第 3.2 节中的理论诊断一致:
- RLSD 也以 3.27 个百分点的优势优于加法融合方法 GRPO+OPSD
- GRPO+OPSD 将有界的奖励与无界的、高方差的 KL 损失线性结合会导致严重的尺度不匹配,迫使进行次优的权衡,这常常使训练不稳定
- RLSD 通过乘法调制有效地规避了这些陷阱。通过将 Teacher 的信号指数化为一个动态有界的相对乘数,RLSD 在数学上保证了严格的符号保留
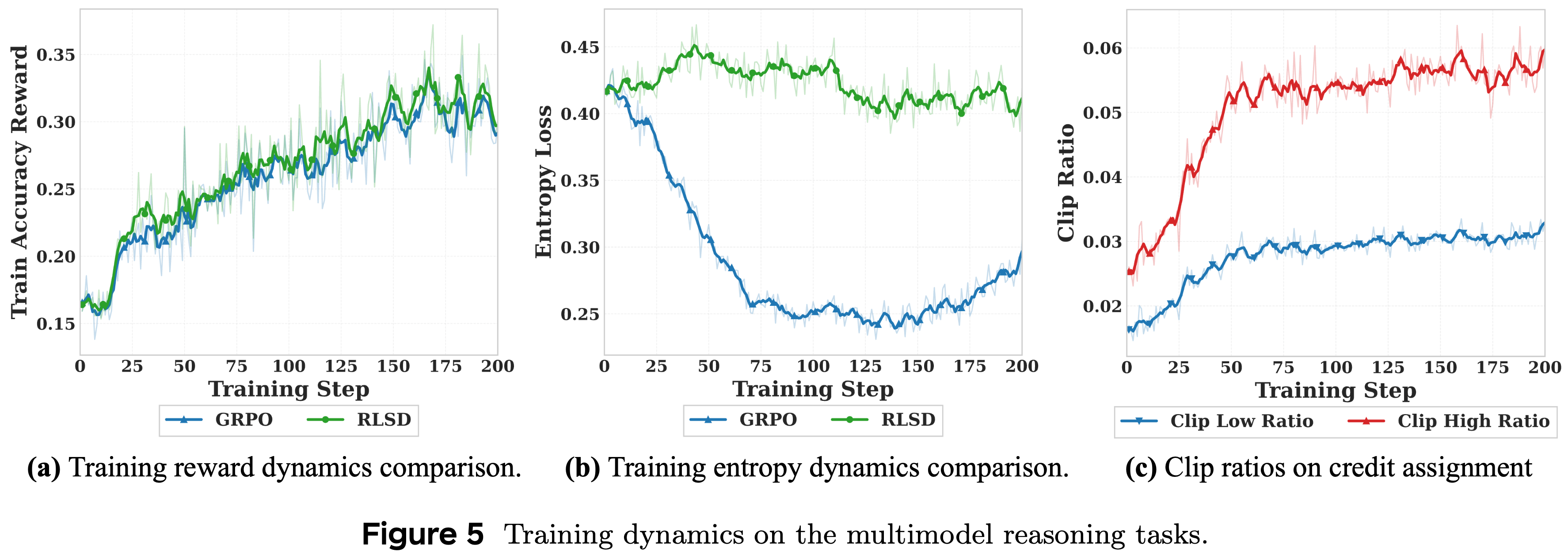
Training Dynamics
- 图 5 展示了 200 个优化步骤中的训练动态
- 如图 5(a) 所示,与标准 GRPO 相比,RLSD 表现出更陡峭的初始上升,并收敛到更高的准确率奖励上限,同时避免了 OPSD 中观察到的后期性能崩溃
- 图 5(b) 揭示了 GRPO 由于其统一的序列级别奖励而遭受快速熵崩溃,而 RLSD 通过选择性地加强关键的推理 Token,而不会在每个位置均匀地抑制替代 Token,从而保持了始终较高的熵水平
- 图 5(c) 确认了裁剪信用分配机制被积极使用,裁剪比率稳定在 \(3\% - 6\%\) 左右,成功地限制了 Teacher 对每个 Token 的影响,并充当了类似于 PPO/GRPO 中重要性比率裁剪的信任区域约束
Case Study
- 图 6 定性地展示了 RLSD 如何将序列级别奖励重新分配到 Token-level
- 注:
- 顶部:在一个正确的轨迹中,更大的信用集中在决定性的计数和减法步骤上
- 底部:在一个错误的轨迹中,最强的责任分配给了误读的条形模型关系和推导出的错误答案
- 绿色表示较大的 Token-level 信用幅度,红色表示较小的 Token-level 信用幅度

- 注:
- 在正确的计数立方体示例中,RLSD 将更大的信用分配给实际决定正确性的 Token
- 例如识别相关的黄色立方体并执行最终的减法,同时降低通用叙述(如“查看图像,我看到……”)的权重
- 在错误的条形模型示例中,RLSD 将最强的责任集中在误读的关系“ \(3x = 28.5\) ”和推导出的错误答案“ \(x = 9.5\) ”上
- 中性的设置 Token 则受到相对较小的惩罚
- 这种行为与 RLSD 的设计目标一致
- 环境奖励仍然决定一个轨迹是被强化还是被惩罚,但 Privileged Teacher 根据每个 Token 对最终结果的贡献来调节 Token-level 信用的相对大小
- 由此产生的更新模式既不像 GRPO 那样均匀,也不像 OPSD 那样进行分布匹配
- 相反,RLSD 充当了以验证器为基础的正确性为锚定的、有针对性的 Token-level 信用分配
Related Work
Credit Assignment in RLVR
- RLVR 主要局限性在于验证器提供的是序列级别的信号,因此一个 Rollout 中的每个 Token,无论它对应的是一个关键的推论还是一个风格化的填充词,都继承相同的优势
- 长时程推理从根本上成为一个信用分配问题
- 一个常见的应对方法是引入 PRM 或步骤级别的价值估计器来对中间推理步骤进行评分 (2024; 2024; 2025; 2024; 2024; 2024; 2025; 2025; 2025)
- 其中一些方法依赖于昂贵的人工步骤标注,而另一些则用自动或隐式监督来替代;
- 无论哪种情况,它们都需要在基础策略之外进行辅助奖励建模和额外计算
- 其中一些方法依赖于昂贵的人工步骤标注,而另一些则用自动或隐式监督来替代;
- 最近的工作试图在严格保持于 verifier-only RLVR 流程内实现细粒度的信用分配
- 这些方法使用模型内部的代理指标(如熵、不确定性、关键 Token 统计、注意力动态或结果敏感性)来重塑 Token-level 更新 (2025; 2026; 2026; 2025; 2025; 2025; 2025)。
- 它们表明统一的序列级别优势是不够的,它们从内在启发式方法中估计 Token 的重要性
- RLSD 的方法在动机上是互补的,但在机制上根本不同:
- RLSD 不依赖启发式代理,而是通过在 Privileged 上下文下的自蒸馏来提取严格的 Token-level 评估,同时将更新方向锚定在验证器奖励上
On-Policy Distillation
- 蒸馏也被探索作为推理模型密集 Token-level 监督的替代来源
- 在 OPD 中,一个更强的 Teacher 评估 Student 自身的 Rollout,并沿着 On-policy 轨迹提供 Token-level 目标 (2024; 2026; 2026; 2026)
- 最近的报告表明,强大的 Teacher 引导的蒸馏甚至可以与基于 RL 的后训练相媲美或对其进行补充 (2026)
- 但标准的 OPD 需要在整个训练过程中维护一个外部的、通常更大的 Teacher 模型
- 为了消除这一开销,自蒸馏方法让同一个模型同时充当 Student 和 Teacher
- 其中 Teacher 以 Privileged 信息(如参考解或验证器反馈)为条件 (2026; 2026)
- 密切相关的 On-policy 蒸馏变体也已被探索用于从演示中持续学习、上下文内化和推理压缩,其中 Teacher 以演示、辅助上下文或简洁指令为条件 (2026; 2026; 2026; 2026)
- 最近的一项同期工作 TRRD ((RLAD & TRRD)Reinforcement-aware Knowledge Distillation for LLM Reasoning, 20260226, AWS Agentic AI) 也指出了加法 KL 惩罚与奖励最大化之间的冲突,提出将 Teacher 概率注入策略重要性比率中
- 但 TRRD 作用于信任区域锚点,而 RLSD 通过贝叶斯证据比直接调制优势幅度
- 注:RLAD 方法 跟本文的 RLSD 方法几乎一样的,只是计算 Critic 时的式子不完全相等
- 都是比值,但对象不同,RLSD 是学生模型和教师模型的比值,RLAD 是学生模型和混合模型的比值
- RLSD 还有个指数控制
附录 A:Deferred Proofs and Extended Analysis
A.1 Proof of Theorem 1(待详细推导)
- 注:为简化符号,本文在整个证明过程中省略对 \((x, y_{< t})\) 的条件依赖
- 回顾 \(\mathcal{L}_{\text{OPSD} }\) 为:
$$\mathcal{L}_{\text{OPSD} }(\theta) = \mathbb{E}_{x}\mathbb{E}_{r\sim P(r\mid x)}[D_{\text{KL} }(P_{T}(\cdot \mid x,r)\parallel P_{S}(\cdot \mid x))] \tag {9}$$ - 省略对 \((x, y_{< t})\) 的条件依赖,并展开 \(\mathcal{L}_{\text{OPSD} }\):
$$
\begin{align}
\mathcal{L}_{\text{OPSD} } &= \mathbb{E}_r\left[\sum_v P_T(v\mid r)\log \frac{P_T(v\mid r)}{P_S(v)}\right] \tag {18} \\
&= \mathbb{E}_r\left[\sum_v P_T(v\mid r)\log \frac{P_T(v\mid r)}{\bar{P}_T(v)}\right] + \mathbb{E}_r\left[\sum_v P_T(v\mid r)\log \frac{\bar{P}_T(v)}{P_S(v)}\right] \tag {19}
\end{align}
$$- 其中:
$$ \bar{P}_{T}(y_{t})\triangleq \mathbb{E}_{r}[P_{T}(y_{t}\mid x,r,y_{< t})]$$- bar 标签的本质是对 \(P\) 求关于 \(r\) 的平均
- 其中:
- 第一项:由条件互信息的定义得出的,第一项等于(待详细推导)
$$ \mathbb{E}_r[D_{\text{KL} }(P_T(\cdot \mid r)| \bar{P}_T)] = I(Y_t;R\mid X,Y_{< t})$$- 补充互信息的定义(详情见后面的附录):若 \(X\) 和 \(Y\) 为离散随机变量,联合概率分布为 \(P(X,Y)\),边缘概率分布分别为 \(P(X)\) 和 \(P(Y)\),则互信息的定义为:
$$
I(X;Y)=\sum_{x\in X}\sum_{y\in Y}P(x,y)\log\frac{P(x,y)}{P(x)P(y)}
$$- 当 \(X\) 和 \(Y\) 相互独立时,\(P(x,y)=P(x)P(y)\),此时 \(I(X;Y)=0\);
- 当 \(X\) 和 \(Y\) 完全依赖时,\(I(X;Y)\) 达到最大值,等于 \(X\) 或 \(Y\) 的熵(\(H(X)\) 或 \(H(Y)\))
- 补充互信息的定义(详情见后面的附录):若 \(X\) 和 \(Y\) 为离散随机变量,联合概率分布为 \(P(X,Y)\),边缘概率分布分别为 \(P(X)\) 和 \(P(Y)\),则互信息的定义为:
- 第二项:注意到 \(\log \frac{\bar{P}_T(v)}{P_S(v)}\) 不依赖于 \(r\),因此对 \(r\) 的期望仅作用于 \(P_T(v\mid r)\):
$$\mathbb{E}_r\left[\sum_v P_T(v\mid r)\log \frac{\bar{P}_T(v)}{P_S(v)}\right] = \sum_v \bar{P}_T(v)\log \frac{\bar{P}_T(v)}{P_S(v)} = D_{\text{KL} }(\bar{P}_T| P_S) = \mathcal{L}^* \tag {20}$$- 上述推导依靠了:
$$ \mathbb{E}_r[P_T(v\mid r)] = \bar{P}_T(v) $$
- 上述推导依靠了:
- 合并两项得到
$$ \mathcal{L}_{\text{OPSD} } = \mathcal{L}^* + I(Y_t;R\mid X,Y_{< t})$$
A.2 Proof of Proposition 1 (Per-Sample Gradient Decomposition)
- 通过在求和内部加入和减去 \(\bar{P}_T(v)\) 来得到分解 \(g(\theta ;r) = g^{*}(\theta) + \delta (\theta ;r)\):
$$\begin{align} & g(\theta ;r) = -\sum_v P_T(v\mid r)\nabla_\theta \log P_S(v) \\
& \qquad = -\sum_v \bar{P}_T(v)\nabla_\theta \log P_S(v) - \sum_v [P_T(v\mid r) - \bar{P}_T(v)]\nabla_\theta \log P_S(v). \end{align} \tag {21}$$ - Property (i)
- 根据定义,\(\mathbb{E}_{r}[P_{T}(v \mid r)] = \bar{P}_{T}(v)\):
$$\mathbb{E}_{r}[\delta (\theta ;r)] = -\sum_{v}\mathbb{E}_{r}[P_{T}(v\mid r) - \bar{P}_{T}(v)]\nabla_{\theta}\log P_{S}(v) = 0 \tag {22}$$
- 根据定义,\(\mathbb{E}_{r}[P_{T}(v \mid r)] = \bar{P}_{T}(v)\):
- Property (ii)
- 由于 \(\nabla_{\theta} \log P_{S}(v)\) 独立于 \(r\):
$$\begin{align} \mathbb{E}_{r}[| \delta (\theta ;r)|^{2}] &= \mathbb{E}_{r}\left[\left| \sum_{v}[P_{T}(v\mid r) - \bar{P}_{T}(v)]\nabla_{\theta}\log P_{S}(v)\right|^{2}\right] \\
&= \sum_{v}\mathbb{E}_{r}\left[(P_{T}(v\mid r) - \bar{P}_{T}(v))^{2}\right]| \nabla_{\theta}\log P_{S}(v)|^{2} \\
&\qquad \qquad \qquad +\sum_{v\neq v^{\prime} }\mathbb{E}_{r}[(P_{T}(v\mid r) - \bar{P}_{T}(v))(P_{T}(v^{\prime}\mid r) - \bar{P}_{T}(v^{\prime}))]\langle \nabla_{\theta}\log P_{S}(v),\nabla_{\theta}\log P_{S}(v^{\prime})\rangle \end{align} \tag {23}$$
- 由于 \(\nabla_{\theta} \log P_{S}(v)\) 独立于 \(r\):
- 对角线项得到 \(\sum_{v} \text{Var}_{r}[P_{T}(v \mid r)] \cdot | \nabla_{\theta} \log P_{S}(v)|^{2}\)
- 当 \(I(Y_{t}; R \mid X) = 0\) 时,对所有 \(r\) 有 \(P_{T}(v \mid r) = \bar{P}_{T}(v)\),因此 \(\delta(\theta; r) \equiv 0\)
- 理解:互信息为 0 时,说明两者完全独立,此时本质上,对所有 \(r\) 有 \(P_{T}(v \mid r) = \bar{P}_{T}(v)\) 恒成立,误差项为 0
A.3 Proof of Irreducibility of Leakage Across Pilot Variants, 跨变体泄漏 Irreducible 性的证明
- 本节通过推导每种变体的每个 Token 的梯度形式,验证了在三种情况下,对 \(r\) 的依赖方向都是 Irreducible
- 在每个变体中, Student 策略在 Token 位置 \(t\) 沿轨迹 \(\hat{y}\) 的梯度可以表示为
$$\hat{A}_{t} \cdot \nabla_{\theta} \log P_{S}(y_{t} \mid x, y_{< t})$$- 其中 \(\hat{A}_{t}\) 涉及 Teacher 的 Privileged 评估
- (i) Full OPSD
- 梯度对整个词汇表求和:
$$g_{t}(\theta ;r) = -\sum_{v\in \mathcal{V} }P_{T}(v\mid r)\nabla_{\theta}\log P_{S}(v) \tag {24}$$ - \(\nu\) 中的每个 Token 都收到一个由 \(P_{T}(v \mid r)\) 加权的梯度贡献,该值编码了 Teacher 的 Privileged 偏好
- 以下偏差在整个词汇表上运作,产生最宽的泄漏带宽
$$\delta_{t} = - \sum_{v}[P_{T}(v \mid r) - \bar{P}_{T}(v)] \nabla_{\theta} \log P_{S}(v)$$
- 梯度对整个词汇表求和:
- (ii) Teacher’s Top-1
- Teacher 分布被坍缩为 \(v_{T}^{*}\) 处的点质量,\(v_{T}^{*}\) 的定义为:
$$ v_{T}^{*} = \arg \max_{v} P_{T}(v \mid r) $$ - 有效梯度变为:
$$g_{t}(\theta ;r) = -\nabla_{\theta}\log P_{S}(v_{T}^{*}) \tag {25}$$- 其中 \(v_{T}^{*}\) 完全由 \(r\) 决定
- 偏差分量 \(\delta_{t}\) (即有效梯度和无偏梯度的偏差)集中在一个依赖于 \(r\) 的 Token 上,使得梯度方向对 \(r\) 的特定实现极度敏感
$$ \delta_{t} = - [\nabla_{\theta} \log P_{S}(v_{T}^{*}) - \sum_{v} \bar{P}_{T}(v) \nabla_{\theta} \log P_{S}(v)] $$ - 理解:此时说明 Token 的选择和梯度系数都与 \(r\) 有关
- Teacher 分布被坍缩为 \(v_{T}^{*}\) 处的点质量,\(v_{T}^{*}\) 的定义为:
- (iii) Student’s Top-1
- 这里目标被限制为 Student 最可能的 Token
$$ v_{S}^{*} = \arg \max_{v} P_{S}(v)$$ - 该 Token 处的梯度权重与 \(\frac{P_{T}(v_{S}^{*} \mid r)}{P_{S}(v_{S}^{*})}\) 成正比,它仍然依赖于 Teacher 的 Privileged 评估
- 理解:这里本质是表达 Token 的选择,虽然这里的 Token 选择与 \(r\) 无关,但所有 Token 的梯度都是经过
- 问题:准确的说,这里 Token 梯度的权重应该是 \(\log \frac{P_{T}(v_{S}^{*} \mid r)}{P_{S}(v_{S}^{*})}\)
- 尽管支持集锚定在 Student 分布上(最窄带宽),但梯度权重的 \(r\) 依赖性仍然存在
- 理解:称为支持集,但实际上就是确定的 Student 上的最大 Token?(即单个 Token)
- 这里目标被限制为 Student 最可能的 Token
- 在所有三种变体中,\(\hat{A}_{t}\) 都涉及 \(P_{T}(\cdot \mid r)\),确保偏差分量 \(\delta\) 将特定于 \(r\) 的信息带入参数更新方向
- 根据命题 1,只要 \(I(Y_{t};R\mid X) > 0\),偏差具有零均值但严格正的方差,无论目标分布如何压缩
- 这三种变体的区别在于有多少 Token 获得非零梯度权重(带宽),但对 \(r\) 的方向依赖是共同的,从而建立了泄漏的 Irreducible 性质
A.4 The Impossibility Trilemma Under Shared Parameters, 共享参数下的不可能三角
- §3.2.2 中的分析描述了分布匹配在每一步的梯度问题
- 在 OPSD 中,耦合更深: Teacher 和 Student 共享一组参数 \(\theta\):
$$
\begin{align}
P_S^\theta (\cdot |x,y_{< t}) &= \pi_\theta (\cdot |x,y_{< t})\\
P_T^\theta (\cdot |x,r,y_{< t}) &= \pi_\theta (\cdot |x,r,y_{< t})
\end{align} \tag {26}$$- 尽管在每个优化步骤中 \(P_{T}\) 被使用 Stop-gradient 处理,但对 \(\theta\) 的每次更新都会同时改变两个分布
- 这种耦合将梯度级别的泄漏与宏观层面的训练稳定性问题联系起来
- 本节证明它们的相互作用导致了一个不可能的结果
A.4.1 Strategy A: Frozen Teacher
- 一个自然的补救措施是固定在初始化时的 Teacher \(P_{T}^{\theta_0}\)
- 第 \(k\) 步的优化目标变为:
$$\mathcal{L}_A(\theta_k) = \mathbb{E}_r\Big[D_{\text{KL} }\Big(P_T^{\theta_0}(\cdot |r)| P_S^{\theta_k}(\cdot |x)\Big)\Big] \tag {27}$$ - 根据定理 1,全局最优是 \(P_S^* = \bar{P}_T^{\theta_0}\),即冻结 Teacher 的边际分布
- Proposition 2 (Capacity Ceiling)
- 当 \(P_S^{\theta_k}\to \bar{P}_T^{\theta_0}\) 时,蒸馏信号消失:
$$| \nabla_{\theta}\mathcal{L}_A(\theta_k)| \to 0$$ - Student 的表征能力严格受限于初始检查点 \(\theta_0\) 的质量,即使模型拥有足够的能力学习更优的策略,也无法进一步提升
- 当 \(P_S^{\theta_k}\to \bar{P}_T^{\theta_0}\) 时,蒸馏信号消失:
A.4.2 Strategy B: Online Teacher
- Teacher 可以与 Student 一起演化,在每一步 \(k\) 使用 \(P_{T}^{\theta_k}\):
$$
\begin{align}
\theta_{k + 1} &= \theta_k - \eta \nabla_\theta \mathcal{L}_k(\theta_k)\\ \text{where}\quad \mathcal{L}_k(\theta)&\triangleq \mathbb{E}_r\Big[D_{\text{KL} }\Big(P_T^{\theta_k}(\cdot |r)| P_S^{\theta_k}(\cdot |x)\Big)\Big]
\end{align}
\tag {28}$$- \(P_{T}^{\theta_k}\) 在每一步内通过 Stop-gradient 被视为固定目标,但更新 \(\theta_k\to \theta_{k + 1}\) 会为后续迭代改变 Teacher 分布
- Theorem 2 (Training Instability Under Online Teacher)
- 定义联合目标 \(\mathcal{L}(\theta)\triangleq \mathbb{E}_r[D_{\text{KL} }(P_T^{\theta_k}(\cdot |x))]\)。从第 \(k\) 步到第 \(k+1\) 步的变化分解为:
$$\begin{align}\mathcal{L}(\theta_{k + 1}) - \mathcal{L}(\theta_k) = \underbrace{\Delta_S}_{\leq 0(\text{ Student improvement})} + \underbrace{\Delta_T}_{\text{sign uncontrolled (teacher drift)} }, \end{align} \tag {29}$$- \(\Delta_S\) 捕获 Student 的提升(在当前 Teacher 下)
- \(\Delta_T\) 捕获由 Teacher 漂移引起的改变
- 当 \(|\Delta_T| > |\Delta_S|\) 且 \(\Delta_T > 0\) 时,尽管每一步都在其局部替代目标上执行了有效的梯度下降,但真实目标却恶化了
- 定义联合目标 \(\mathcal{L}(\theta)\triangleq \mathbb{E}_r[D_{\text{KL} }(P_T^{\theta_k}(\cdot |x))]\)。从第 \(k\) 步到第 \(k+1\) 步的变化分解为:
- 在 \(\mathcal{L}(\theta_{k + 1}) - \mathcal{L}(\theta_k)\) 中插入并减去 \(\mathbb{E}_r[D_{\text{KL} }(P_T^{\theta_k}(\cdot |r)| P_S^{\theta_{k + 1} })]\)
- 确切的表达式为:
$$\begin{align}\Delta_S &= \mathbb{E}_r\Big[D_{\text{KL} }\Big(P_T^{\theta_k}(\cdot |r)| P_S^{\theta_{k + 1} }\Big)\Big] - \mathbb{E}_r\Big[D_{\text{KL} }\Big(P_T^{\theta_k}(\cdot |r)| P_S^{\theta_k}\Big)\Big]\\
\Delta_T &= \mathbb{E}_r\Big[D_{\text{KL} }\Big(P_T^{\theta_{k + 1} }(\cdot |r)| P_S^{\theta_{k + 1} }\Big)\Big] - \mathbb{E}_r\Big[D_{\text{KL} }\Big(P_T^{\theta_k}(\cdot |r)| P_S^{\theta_{k + 1} }\Big)\Big]. \end{align} \tag {31}$$- 由于在 \(P_{T}^{\theta_k}\) 保持不变的情况下对 \(\mathcal{L}_k\) 进行梯度下降,因此 \(\Delta_S\leq 0\)
- \(\Delta_T\) 的符号不可控:同一更新在改进 \(P_{S}\) 的同时也会扰动 \(P_{T}\),并且 KL 散度的不对称性无法保证这种诱导偏移的方向
A.4.3 Self-Reinforcing Feedback
- §3.2.2 中的梯度级别泄漏和 Teacher 漂移通过一个正反馈循环相互作用
- Proposition 3 (Self-Reinforcing Feedback Loop)
- 将模型对 Privileged 信息的敏感性定义为
$$ S(\theta) \triangleq \mathbb{E}_r[D_{\text{KL} }(P_T^\theta (\cdot |r) | \bar{P}_T^\theta)] = I(Y_t; R | X, Y_{< t})$$ - 在 Strategy B 下,以下循环运作:
- (i) 每样本偏差 \(\delta (\theta ;r)\) 驱使参数朝向预测 \(r\) 的特征
- (ii) 这些特征被编码到共享的 \(\theta\) 中,增强了模型在充当 Teacher 时利用 \(r\) 的能力
- (iii) \(S(\theta_{k + 1}) \geq S(\theta_k)\),放大了 \(\text{Var}_r[P_T(v | r)]\)
- (iv) 根据命题 1(ii),偏差方差增大,强化了步骤 (i)
- 将模型对 Privileged 信息的敏感性定义为
- 根据命题 1,
- \(g(\theta ;r) = g^* (\theta) + \delta (\theta ;r)\) 且 \(\mathbb{E}_r[\delta ] = 0\)
- 每个随机更新 \(\theta_{k + 1} = \theta_k - \eta g(\theta_k;r_k)\) 都会引入一个扰动 \(- \eta \delta (\theta_k;r_k)\),其方向与 \(r_k\) 相关
- 在多个具有不同 \(r_k\) 的步骤上,这些扰动的路径依赖累积使参数偏向于编码 \(x \to r\) 相关性的区域:
- \(\delta\) 与此类相关性对齐的参数配置会产生更低的后续损失,导致优化器优先保留这些漂移
- 累积的漂移丰富了共享表示 \(\theta\),使其具有预测给定 \(x\) 的 \(r\) 的特征。由于 Teacher 和 Student 共享 \(\theta\),这些特征同时可用于两个角色
- 在下一步, Teacher \(P_T^{\theta_{k + 1} }(\cdot |x,r,y_{< t})\) 通过新编码的特征更有效地利用 \(r\),增加了 \(P_T(\cdot |r)\) 在不同 \(r\) 实现之间的离散度:
$$ S(\theta_{k + 1}) \geq S(\theta_k)$$ - 根据命题 1(ii),偏差方差 \(\mathbb{E}_r[| \delta | ^2 ]\) 随 \(S(\theta)\) 增长,并且循环以更大的偏差幅度重新开始
- 令 \(\rho_k \) 表示梯度方差中可归因于偏差分量的比例
$$ \rho_k \triangleq \frac{\mathbb{E}_r[| \delta (\theta_k;r)| ^2 ]}{\mathbb{E}_r[| g(\theta_k;r)| ^2 ]} $$- 反馈循环驱使 \(\rho_k\) 单调上升:
- 在训练早期,由于 \(| g^* |\) 占主导,\(\rho_k\) 保持较小;
- 随着 \(| g^* | \to 0\) 且 \(| \delta |\) 通过循环增长,\(\rho_k \to 1\)
- 此时,参数更新主要由泄漏信号决定,训练崩溃
- 反馈循环驱使 \(\rho_k\) 单调上升:
A.4.4 The Trilemma(不可能三角)
- 对策略 A 和 B 的分析,连同梯度分解,得出了 On-policy 自蒸馏的核心不可能性结果
- Theorem 3 (Impossibility Trilemma)
- 在任何 Teacher 和 Student 共享参数(即 \(P_T\) 和 \(P_S\) 由相同的 \(\theta\) 参数化)的分布匹配框架中,以下三个属性不能同时成立:
- (a) 目标稳定性:优化目标在连续步骤之间不漂移 \((\Delta_T = 0)\)
- (b) 持续改进:蒸馏信号不消失 \((| \nabla_\theta \mathcal{L}| \neq 0)\)
- (c) 无泄漏训练:偏差分量不驱动参数漂移
- 在任何 Teacher 和 Student 共享参数(即 \(P_T\) 和 \(P_S\) 由相同的 \(\theta\) 参数化)的分布匹配框架中,以下三个属性不能同时成立:
- Strategy A (frozen teacher) 通过构造满足 (a)(因为 \(P_T^{\theta_0}\) 是固定的,所以 \(\Delta_T = 0\)),但根据命题 2 违反了 (b)
- Strategy B (online teacher) 满足 (b),因为 Teacher 不断演化以提供不消失的信号,但根据定理 2 违反了 (a)
- 只要 \(I(Y_t;R\mid X) > 0\),属性 (c) 在任一策略下都会被违反:根据命题 1(ii),每样本偏差方差 \(\mathbb{E}_r[| \delta | ^2 ]\) 严格为正,与 Teacher 管理方案无关
- 在策略 B 下,命题 3 进一步保证了 \(\rho_k\) 单调非减,因此泄漏在训练过程中会加剧。混合策略(例如,周期性 Teacher 快照)只是在 (a) 和 (b) 之间插值:
- 在每个更新区间内:
- (a) 成立,但随着 Teacher 变得过时
- (b) 逐渐退化;
- 刷新 Teacher 可以恢复 (b),同时破坏 (a)
- 属性 (c) 始终不满足,因为底层的互信息差距与快照调度无关

- 在每个更新区间内:
A.5 Bayesian Interpretation of RLSD Evidence Weights,RLSD 证据权重的贝叶斯解释
- 本节提供了 §4.1 中介绍的 RLSD 证据比率 \(w_t = \frac{P_T(y_t)}{P_S(y_t)}\) 的正式概率推导,证明它对应于一个序列贝叶斯信念更新
- 详情见原始论文,待补充
附录:补充互信息的一些定义和推导
- 互信息可以通过熵(Entropy) 和条件熵(Conditional Entropy) 推导,核心等价关系为:
$$
I(X;Y)=H(X)-H(X|Y)=H(Y)-H(Y|X)=H(X)+H(Y)-H(X,Y)
$$- \(H(X)\) 是 \(X\) 的熵,衡量 \(X\) 的不确定性
- \(H(X|Y)\) 是给定 \(Y\) 时 \(X\) 的条件熵,衡量已知 \(Y\) 后 \(X\) 剩余的不确定性
- \(H(X,Y)\) 是 \(X\) 和 \(Y\) 的联合熵
- 条件互信息的定义为:
$$
I(Y; R \mid X) = H(Y \mid X) - H(Y \mid X, R)
$$ - 条件熵的期望形式:
$$
\begin{align}
H(Y \mid X) &= \mathbb{E}_{P(X)} \left[ -\sum_y P(y \mid X) \log P(y \mid X) \right] \\
H(Y \mid X, R) &= \mathbb{E}_{P(X, R)} \left[ -\sum_y P(y \mid X, R) \log P(y \mid X, R) \right]
\end{align}
$$