注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 本文创新性很高,有很 Solid 的理论依据,非常值得一读
- 本文提出了内生奖励(Endogenous Reward)的概念
- 本文通过内生奖励证明了:任何预训练的自回归模型可以提取出一个通用的奖励函数
- 主要贡献:
- 理论证明1:严格证明了标准的 NTP 目标自然产生了一个奖励函数,该函数等价于一个离线逆强化学习算法
- 理论证明2:证明了使用这种提取的奖励进行 RL 微调不仅仅是避免数据收集的启发式方法
- 由此推导出的最终策略具有比基础模型可证明更紧的性能界限,有效地减轻了简单模仿的复合误差
- 实践:通过实验验证推导结果的有效性
- 作者的观点:
- 不需要构造 RM,直接使用 NTP 得到的模型即可(个人理解:其实还是需要,毕竟部分类似安全等指标并不是基础模型本身具有的)
Introduction and Discussion
- 创建一个最先进的 RM 以前需要构建大规模、高质量的人类偏好数据集,这是出了名的缓慢、昂贵且难以扩展
- 基于 AI 反馈的强化学习(RLAIF)(2022b; 2023; 2024a) 或 LLM-as-a-judge 框架 (2023; 2025),使用强大的专有 LLM 来生成奖励信号或偏好标签,从而绕过了对人类标注者的需求
- 这些方法通常是启发式的;缺乏严格的理论基础,并且容易继承评判模型的风格怪癖和偏见
- 关键问题:高质量奖励信号真的必须从外部获取吗?
- 本文观点:强大的通用奖励模型已经隐含地存在于任何通过标准 NTP 训练的语言模型中(内生奖励 )
- 本文证明了:
- 来自特定形式的离线逆向强化学习(IRL)的奖励函数 可以从标准的 NTP 目标中恢复出来
- 该 NTP 目标既可以是预训练也可以是 SFT
- 来自特定形式的离线逆向强化学习(IRL)的奖励函数 可以从标准的 NTP 目标中恢复出来
- 本文建立了一种原则性的方法来提取语言模型在训练期间隐式学习的奖励函数
- 语言模型的 Logits 可以直接解释为 Soft Q 函数,从中可以通过逆 Soft Bellman 算子恢复奖励函数
- 此外,作者还证明了,使用模型自身的内生奖励对模型进行微调,会得到一个策略,其可证明的误差界优于基础模型
- RL 过程有效地纠正了困扰标准模仿学习(即 NTP)的复合误差 ,将性能差距从对任务范围的二次依赖 \(\mathcal{O}(H^2)\) 降低到更优的线性依赖 \(\mathcal{O}(H)\)
- 这是第一个证明强化学习对 LLM 有效性的理论证明?
- 实验结果:提取这种内生奖励不仅优于现有的 LLM 作为评判者的方法,而且可以超越在昂贵的人类标注数据上显式训练的奖励模型的性能
Preliminaries
LLM and its MDP Formulation
Basic Introduction on LLM
- LLM 是一种生成模型,通过概率建模预测序列中的下一个 Token 来运作
- 一个 LLM \(\pi\) 从下面有限词汇表 中选择 Token,并以自回归的方式生成序列
$$\mathcal{V} = \{1,2,\ldots ,|\mathcal{V}|\}$$ - 在第 \(h\) 步,给定上下文序列
$$(a_{1},\ldots ,a_{h - 1})$$,LLM 根据条件分布生成下一个 Token,即
$$a_{h}\sim \pi (\cdot |a_{1},\ldots ,a_{h - 1})$$ - 这个自回归生成过程一直持续,直到生成指定的句子结束(EOS)Token 或达到预定的最大长度 \(H\)
- 假设响应长度统一为 \(H\),在 EOS Token 之后进行适当的填充
MDP Formulation of LLM
- 本文采用强化学习的视角来看待 LLM,并将语言生成任务形式化为一个 MDP (2023),由一个元组定义
$$\mathcal{M} = \langle \mathcal{S},\mathcal{V},r,P,\rho ,H\rangle$$ - 状态空间 \(\mathcal{S}\) 是由 \(\mathcal{V}\) 中元素连接形成的所有有限长字符串的集合,动作空间是词汇表集合 \(\mathcal{V}\)
- 在每个轨迹的开始,一个长度为 \(m\) 的 Prompt \(s_1 = (x_1,x_2,\dots ,x_m)\) 从初始状态分布 \(\rho\) 中采样,其中 \(m\in \mathbb{N}\) 且 \(\forall i\in [m],x_i\in \mathcal{V}\)
- 在每个步骤 \(h\in [H]\),LLM 根据 \(\pi (\cdot |s_h)\) 选择一个动作(或等价地,一个 Token)\(a_h\in \mathcal{V}\)。然后环境转换到下一个状态 \(s_{h + 1} = (x,a_1,\dots ,a_h)\),并给予 LLM 奖励 \(r(s_{h},a_{h})\in [0,1]\)
- 转移模型 \(P:\mathcal{S}\times \mathcal{V}\to \Delta (\mathcal{S})\) 是确定性的
- 当且仅当 \(s_{h + 1} = s_h\oplus a_h\) 时,\(P(s_{h + 1}|s_h,a_h) = 1\),其中 \(\oplus\) 表示连接
- 轨迹在总共 \(H\) 步后结束
- 在 RL 的背景下,也称 \(\pi\) 为 策略 (Policy)
- 通过策略值 \(\mathcal{V}^{\pi}\) 来衡量策略 \(\pi\) 的质量,定义为
$$\begin{array}{r}V^{\pi} = \mathbb{E}_{\tau \sim \pi}\left[\sum_{h = 1}^{H}r(s_{h},a_{h})\right] \end{array}$$
NTP for Training LLMs
- NTP (2017) 是 LLM 的基本训练目标,其目标是训练 LLM 在给定前面 Token 序列的情况下最大化预测下一个 Token 的可能性
- 给定数据集 \(\mathcal{D} = \{(s_1^j,a_{1:H}^j)\}_{i = 1}^n\),NTP 解决以下最大化问题:
$$\max_{\pi}\sum_{i = 1}^{n}\sum_{h = 1}^{H}\log \left(\pi \left(a_{h}^{i}|s_{h}^{i}\right)\right) \tag {1}$$ - 这个目标在多个 LLM 训练阶段中被采用:
- 在预训练期间 (2019; 2020) 使用大规模的通用网络数据集,以及在监督微调期间 (2022) 使用较小规模的高质量人类响应集合
- 注:从模仿学习(IL)的角度来看 (2018),NTP 可以被视为著名的行为克隆方法 (1991) 的一个实例,其中模型在状态中模仿专家的动作
RLHF: Reinforcement Learning from Human Feedback
- NTP 能有效地教会模型模仿高质量的演示,但使其行为与人类价值观对齐通常需要一种更直接的反馈形式
- RLHF (2022) 是完成此任务的标准范式,它使用从人类偏好中得出的奖励信号来精炼 SFT 模型
- 该过程通常包括两个后续阶段:奖励建模和 RL 微调
Reward Modeling
- 首先需要训练一个独立的 RM 来预测人类会更偏好哪个响应,记 RM 为 \(R_{\phi}\)(参数为 \(\phi\))
- 需要一个偏好数据集
$$\mathcal{D}_{\text{pref} } = \{(x,y_{w},y_{l})_{i}\}$$- 对于给定的 Prompt \(x\)
- \(y_{w}\) 是人类标注者偏好的响应
- \(y_{l}\) 是不被偏好的响应
- 对于给定的 Prompt \(x\)
- 根据 Bradley-Terry(BT)模型 (Bradley and Terry, 1952),\(y_{w}\) 被偏好于 \(y_{l}\) 的概率被建模为:
$$P(y_{w}\succ y_{l}|x) = \sigma (R_{\phi}(x,y_{w}) - R_{\phi}(x,y_{l})) \tag {2}$$- \(\sigma\) 是 Sigmoid 函数
- RM 的参数 \(\phi\) 通过最小化数据集中观察到的偏好的负对数似然来优化:
$$\mathcal{L}_{\text{RM} }(\phi) = -\mathbb{E}_{(x,y_{w},y_{l})\sim \mathcal{D}_{\text{pref} } }\left[\log \sigma (R_{\phi}(x,y_{w}) - R_{\phi}(x,y_{l}))\right] \tag {3}$$
Reinforcement Learning Fine-Tuning
- SFT 模型被视为初始策略 \(\pi_{\theta}\),RL 更新 SFT 模型以最大化 RM 分配的期望奖励
- 为防止策略偏离从 SFT 学习到的分布太远,并减轻 “Reward Hacking”(即找到对抗性方法来最大化奖励分数),在目标中添加了一个 KL 散度惩罚项,最终的优化问题是:
$$\max_{\theta}\mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[R_{\phi}(x,y) - \beta \cdot D_{\text{KL} }(\pi_{\theta}(\cdot |x)\parallel \pi_{\text{SFT} }(\cdot |x))\right] \tag {4}$$- \(\mathcal{D}\) 是 Prompt 的分布
- \(y\) 是由策略 \(\pi_{\theta}\) 生成的完整响应
- \(\beta\) 是控制 KL 惩罚强度的超参数
Inverse Reinforcement Learning,逆强化学习
- 逆向强化学习(IRL)(2000) 是一类基本的模仿学习方法,用于解决 RL 的逆问题
- IRL 不是从已知的奖励函数中学习策略,而是试图从专家演示中恢复奖励模型 (IRL 一般假设是这些演示是最优或接近最优的)
- 一个突出且具有理论基础的方法是最大熵(MaxEnt)IRL (2008)
- MaxEnt IRL 通过寻求一个既能合理化专家演示,又能对数据中未发现的行为保持最大非承诺性的奖励,来解决许多奖励函数可以解释相同行为的模糊性问题
- 这个原理引出了一个极小极大优化问题(注:这里的引出结果不是 (MaxEnt IRL)Maximum Entropy Inverse Reinforcement Learning, AAAI 2008, CMU 论文给出的,而是 Generative Adversarial Imitation Learning, NIPS 2016, OpenAI给出的):
$$\max_{r}\min_{\pi}\left(\mathbb{E}_{\tau \sim \pi^{\text{E} } }\left[\sum_{h = 1}^{H}r(s_{h},a_{h})\right] - \mathbb{E}_{\tau \sim \pi}\left[\sum_{h = 1}^{H}r(s_{h},a_{h}) + \alpha H(\pi (\cdot |s_{h}))\right]\right) \tag {5}$$- 这里的期望 \(\mathbb{E}_{\tau \sim \pi^{\text{E} } }\) 是在专家策略 \(\pi^{\text{E} }\)(由数据集 \(\mathcal{D}\) 近似)诱导的轨迹分布上取的,而期望 \(\mathbb{E}_{\tau \sim \pi}\) 是在一个学习到的策略 \(\pi\) 生成的轨迹分布上取的
- \(\begin{array}{r}{H(\pi (\cdot |s_h)) = \mathbb{E}_{a_h\sim \pi (\cdot |s_h)}[-\log \pi (a_h|s_h)]} \end{array}\) 表示 \(\pi (\cdot |s_h)\) 的熵
- \(\alpha >0\) 是正则化系数
- 这个目标是寻求一个奖励函数 \(r\),它能最大化专家的期望回报与在同一奖励 \(r\) 下最优策略 \(\pi\) 的熵正则化回报之间的差距
Connection to Reward Modeling in RLHF,与 RLHF 中奖励建模的联系
- 可以将 MaxEnt IRL 目标视为 BT 模型原理的、更一般的分布层面形式化
- 在 RLHF 中使用的 BT 模型下的目标,如 Eq.(3) 所示,通过最大化特定 轨迹 \(y_{w}\) 和 轨迹 \(y_{l}\) 之间的分数差来学习奖励函数
- 这从根本上说是一种成对或样本层面的比较
- Eq.(5) 中的 MaxEnt IRL 目标可以被视为其分布层面的类似物
- 它不是比较两个采样的轨迹,而是将整个专家分布 \((\pi^{\text{E} })\) 与在奖励函数 \(r\) 下产生的最优竞争策略 \(\pi\) 进行比较
- \(\text{min}_{\pi^{\prime} }\) 项积极寻求可能的最强竞争策略,而 \(\text{max}_{\pi^{\prime} }\) 项则调整奖励以创造最大的性能差距
- 从这个角度来看,RLHF 奖励建模过程可以被解释为 IRL 原理的一个实用、计算上易于处理的实例化
- RLHF 没有解决复杂的 \(\text{min}_{\pi^{\prime} }\) 优化问题,而是简化了它,并直接最大化偏好数据集中 “Chosen” 和 “Rejected” 之间的奖励差距
- 因此,BT 模型是 IRL 提供的更广泛理论框架内的一个特例
- 工作回归到这个更通用的 IRL 公式,以直接推导出一个奖励函数,而无需显式的成对比较
Finding the Endogenous Reward Within the Language Model, 在语言模型内部寻找内生奖励
- 本文主张:一个原则性的奖励函数可以直接从任何使用标准 NTP 训练的语言模型的 Logits 中恢复出来
Reward Learning from Inverse Reinforcement Learning,从逆向强化学习中学习奖励
- RLHF 中奖励建模的标准实践可以看作是一个更基本范式:逆向强化学习(IRL)的一个实用、简化的实例
- 这种联系表明:IRL 是从数据中学习奖励函数的自然且最原则性的框架
- 与其依赖 RLHF 中常见的成对比较启发式方法,不如应用一种更基础的 IRL 方法来恢复能最好地解释专家数据集 \(\mathcal{D}\) 的最优奖励函数
- 历史上阻碍这种直接方法的主要挑战是,大多数 IRL 方法是为在线环境制定的,需要计算成本高昂的交互
- 一种更直接、更实用的方法是使用基于逆 Soft Q 学习 (2021) 的离线 IRL 方法来公式化这个问题
- 在静态数据集 \(\mathcal{D} = \{(s_{1}^{i},a_{1:H}^{i})\}_{i = 1}^{n}\) 中找到一个能最好地解释专家数据的 Q 函数
- 目标是解决以下优化问题:
$$\max_{\mathcal{Q} }\frac{1}{n}\sum_{i = 1}^{n}\sum_{h = 1}^{H}\left[Q(s_{h}^{i},a_{h}^{i}) - \alpha \log \left(\sum_{a_{h}\in \mathcal{V} }\exp \left(Q(s_{h}^{i},a_{h})\right) / \alpha\right)\right] \tag {6}$$- 注:先看 公式 8 更容易看懂 公式 6
- 找到最大化这个目标的最优 Q 函数 \(Q^{*}\) 后,相应的理想奖励函数 \(r^{*}\) 就可以通过逆 Soft Bellman 算子 (2021) 恢复:
$$r^{*}(s_{h},a_{h}):= Q^{*}(s_{h},a_{h}) - \alpha \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q^{*}(s_{h + 1},a_{h + 1})\right) / \alpha\right) \tag {7}$$ - 注:这提供了一种原则性的、离线的寻找奖励函数的方法
- 关键问题:这个问题的最优解 \(Q^{*}\) 是什么?
- 注:接下来,我们能在不进行复杂、新的优化过程的情况下找到它
NTP Recovers the IRL Solution,NTP 恢复了 IRL 解
- 现在证明:在 Eq.(6) 中提出的 \(Q^{*}\) 的解不是需要从头计算的东西
- \(Q^{*}\) 已经被任何使用标准 NTP 目标训练的语言模型的 Logits 所体现
- 首先分析一下 IRL 目标寻求什么样的解
- 通过应用一个简单的指数对数变换,Eq.(6) 中的目标可以表示为一个最大似然问题:
$$\max_{\mathcal{Q} }\frac{1}{n}\sum_{i = 1}^{n}\sum_{h = 1}^{H}\log \left(\frac{\exp(Q(s_{h}^{i},a_{h}^{i}) / \alpha)}{\sum_{a_{h}^{i}\in \mathcal{V} }\exp(Q(s_{h}^{i},a_{h}^{i}) / \alpha)}\right) \tag {8}$$- 这个公式在:RL——SAC 中也有出现
- 通过应用一个简单的指数对数变换,Eq.(6) 中的目标可以表示为一个最大似然问题:
- 对数内部的项可以看作一个策略
$$ \pi_{Q}(\cdot |s_{h}) = \text{softmax}(Q(s_{h},\cdot);\alpha) $$ - 因此,优化问题寻求这样一个 Q 函数,其对应的策略 \(\pi_{Q}\) 能最大化数据集 \(\mathcal{D}\) 中专家演示的似然
- 这正是通过 NTP 训练语言模型的目标 !!
- 在训练期间,语言模型 \(\hat{\pi}\) 被优化以最大化 Eq.(1) 中所示的数据对数似然
- 产生的策略 \(\hat{\pi}\) 根据定义是数据生成分布的最大似然估计。这个策略被参数化为模型 Logits 上的 Softmax,作者将其记为 \(\hat{f}\):
$$\hat{\pi} (\cdot |s_h) = \text{softmax}(\hat{f} (s_h,\cdot);\alpha) \tag {9}$$
- 产生的策略 \(\hat{\pi}\) 根据定义是数据生成分布的最大似然估计。这个策略被参数化为模型 Logits 上的 Softmax,作者将其记为 \(\hat{f}\):
- 由于语言模型的策略 \(\hat{\pi}\) 是最大似然问题的解,因此直接得出其底层的 Logits \(\hat{f}\) 是 Eq.(6) 中 IRL 优化问题的一个有效解
- 作者将这种直接联系形式化如下:
Proposition 1
- 命题 1:
- 设 \(\hat{\pi}\) 是一个在数据集 \(\mathcal{D}\) 上通过 NTP 训练的语言模型,产生策略
$$ \hat{\pi} (\cdot |s_h) = \text{softmax}(\hat{f} (s_h,\cdot);\alpha) $$- 其中 \(\hat{f}\) 是模型的 Logits
- 那么 Logits 函数 \(\hat{f}\) 是 Eq.(6) 中原则性离线 IRL 目标的一个解
- 设 \(\hat{\pi}\) 是一个在数据集 \(\mathcal{D}\) 上通过 NTP 训练的语言模型,产生策略
- 命题 1 为作者工作的理论基石
- 命题 1 揭示了语言模型的 Logits 不仅仅是任意的分数;它们是原则性的 Q 函数,隐含地代表了模型所训练数据的最优奖励函数
- 这一发现为生成和评估提供了一个统一的视角,其中模型的策略 \(\hat{\pi}\) 负责生成,而其 Logits \(\hat{f}\)(充当 Q 函数)负责评估
The Endogenous Reward
- 在命题 1 中建立的直接联系为我们提供了一种强大的、无需训练的方法来获得奖励模型
- 给定任何通过 NTP 训练的语言模型,无论是在预训练还是微调阶段,只需取其 Logits \(\hat{Q} = \hat{f}\),并将它们代入 Eq.(7) 的逆 Soft Bellman 算子中
$$\hat{r} (s_h,a_h) = \hat{Q} (s_h,a_h) - \alpha \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(\hat{Q} (s_{h + 1},a_{h + 1})\right) / \alpha\right) \tag {10}$$ - 定义价值函数
$$ V_{\hat{Q} }(s_h):= \alpha \log (\sum_{a_h\in \mathcal{V} }\exp (\hat{Q} (s_h,a_h) / \alpha))$$- 它表示从状态 \(s\) 出发的期望未来回报
- 这样就得到了内生奖励,写作:
$$\hat{r} (s_h,a_h) = \alpha \log (\hat{\pi} (a_h|s_h)) + V_{\hat{Q} }(s_h) - V_{\hat{Q} }(s_{h + 1}) \tag {11}$$- 注:\(\hat{\pi}\) 是在数据集 \(\mathcal{D}\) 上通过 NTP 训练的语言模型
- 在以下三个方面阐述这种内生奖励
Reward Shaping
- 从 Eq.(11) 中,内生奖励 \(\hat{r}\) 可以被视为由语言模型的 Log-Probability 表示的 的一种 带 势函数(potential function) \(V_{\hat{Q} }\) 的 Shaped Reward
$$ \tilde{r} (s_h,a_h):= \log (\hat{\pi} (a_h|s_h))$$- 根据 Reward Shaping 理论 (1999),\(\hat{r}\) 和 \(\tilde{r}\) 诱导出相同的最优策略和价值函数
- 理解:可以证明,因为这里的 \(V_{\hat{Q} }(s_h), \ V_{\hat{Q} }(s_{h + 1})\) 都和 动作没有关系,所以添加他们与否梯度的期望都是无偏的
- 根据 Reward Shaping 理论 (1999),\(\hat{r}\) 和 \(\tilde{r}\) 诱导出相同的最优策略和价值函数
Outcome Reward
- 对于一个完整的响应 \(\tau = (s_1,a_1,\ldots ,s_H,a_H)\),最终的结果奖励可以计算为
$$
\begin{align}
\hat{r} (\tau)
&= \sum_{h = 1}^{H}\hat{r} (s_h,a_h) \\
&= \alpha \sum_{h = 1}^{H}\log (\hat{\pi} (a_h|s_h)) + V_{\hat{Q} }(s_1) \\
&= \alpha \log (\hat{\pi} (\tau |s_1)) + V_{\hat{Q} }(s_1)
\end{align}
\tag {12}
$$- 注:这里的第二个等式成立是因为边界条件
$$\hat{Q}(s_{H + 1}, \cdot) \equiv 0$$
- 注:这里的第二个等式成立是因为边界条件
- 在 \(\hat{\pi}\) 下完整响应 \(\tau\) 的概率
$$\hat{\pi} (\tau |s_1) := \prod_{h = 1}^{H} \hat{\pi} (a_h |s_h)$$ - 可以观察到
- 结果奖励 等于 整个轨迹的 Log 概率之和,再加上一个仅依赖于初始状态(即 Prompt)的项 \(V_Q(s_1)\)
- 如果一个响应在训练数据(例如,海量预训练数据)中频繁出现,那么训练好的 LLM 将以更高的可能性生成这个响应,这也意味着这个响应的奖励值更高
Existing Generative Reward Models as Special Cases,现有 GRM 是特例
- Eq.(12) 引入了一个通用公式,利用 LLM 的概率来构建奖励,而现有的生成式奖励模型 (2024; 2024) 成为该框架的特定实例
- 例如,对于一个问题-答案对 \((\mathbf{x},\mathbf{y})\)
- [2024] 中的生成式验证器 (Generative Verifier) 使用下面的 Prompt
- Prompt:\(\mathbf{P} = \mathbf{\Omega}^{\text{is} }\) the answer correct?
- 并将奖励表示为在上下文和 Prompt 下单个 Token ‘Yes’ 的概率,即
$$ \hat{\pi} (\text{Yes}|\mathbf{x},\mathbf{y},\mathbf{P})$$
- [2024] 中的生成式验证器 (Generative Verifier) 使用下面的 Prompt
- 这对应于本文的方法,当设置 \(s_1 = (\mathbf{x},\mathbf{y},\mathbf{P})\) 和 \(a_1 = \text{Yes}\) 时,得到的奖励 \(\hat{r} (\tau)\) 与他们的方法一致
$$\hat{r} (\tau) = \alpha \log (\hat{\pi} (\text{Yes}|\mathbf{x},\mathbf{y},\mathbf{P}))$$ - 对于 [2024] 中为成对比较设计的生成式奖励模型方法,也可以提出类似的论点
- 基于这种联系,已建立的命题 1 也可以为这些方法提供理论依据
Theoretical Justifications for the Endogenous Reward,理论证明
- 本节通过分析奖励误差和由此产生的策略误差,为内生奖励提供理论证明
Error Analysis of the Endogenous Reward,内生奖励误差分析
- 遵循最大熵逆强化学习 (2008),假设专家策略 \(\pi^{\text{E} }\) 是关于未知真实奖励 \(r^*\) 的熵正则化最优策略
- 根据正则化 MDP 的理论 (2019),有:
$$r^{*}(s_{h},a_{h}) = \alpha \log \left(\pi^{\text{E} }(a_{h}|s_{h})\right) + V_{Q_{r^{*} } }(s_{h}) - V_{Q_{r^{*} } }(s_{h + 1}) \tag {13}$$- 这里 \(Q_{r^*}^*\) 是真实奖励 \(r^*\) 的熵正则化最优 Q 值函数
- 由于奖励模糊性问题,多个奖励函数可以推导出相同的专家策略 (1999),即使完全了解 \(\pi^{\text{E} }\),也不可能逼近真实奖励 \(r^*\)
- 因此,我们无法对绝对误差 \(|\hat{r} (s_h, a_h) - r^* (s_h, a_h)|\) 得出任何理论结论
- 本文中,作者不分析绝对误差,而是分析利用奖励模型对两个 Reponse 进行评估时的性能
- 定理 1 表明(注:定理 1 更多详情见原文),如果用于提取奖励的 LLM \(\hat{\pi}\) 在响应的对数概率上接近底层专家 \(\pi^{\text{E} }\),那么由 \(\hat{r}\) 诱导的偏好分布就接近由 \(r^*\) 诱导的偏好分布
- 这表明从 LLM 中提取的所提出的内生奖励可以证明地继承其性能
Error Analysis of the LLM Finetuned by the Endogenous Reward,使用内生奖励微调的 LLM 的误差分析
- 提取奖励函数的最终目标是使用它通过强化学习来训练一个新的、改进的策略
- 这里作者分析了新学习策略的性能,并与基础策略进行比较
- 本文分析两种方法
- 第一种方法直接在 Demo 上应用 NTP(即行为克隆),得到基础策略 \(\hat{\pi}\)
- 另一种方法首先基于方程 (10) 从 \(\hat{\pi}\) 构建内生奖励,然后使用 \(\hat{\pi}\) 应用强化学习,得到新策略 \(\pi^{\text{RL} } = \text{argmax}_{\pi}V_{T}^{\pi}\)
- 这里,我们忽略求解最优策略时的任何优化误差
- 理论目标是分析并比较 \(\pi^{\text{RL} }\) 和 \(\hat{\pi}\) 在真实奖励 \(r^{\star}\) 下的次优性
Theorem 2
- 在具有未知真实奖励 \(r^{\star}\) 的 Token-level MDP 中,假设专家策略 \(\pi^{\text{E} }\) 是熵正则化最优策略
- 考虑 \(\hat{\pi}\) 是通过 NTP 训练的策略,\(\hat{r}\) 是方程 (10) 中定义的提取奖励
- 使用提取的奖励 \(\hat{r}\) 应用强化学习来学习一个新策略 \(\pi^{\text{RL} }\),即 \(\pi^{\text{RL} } = \text{argmax}_{\pi}V_{T}^{\pi}\),那么有:
$$V_{T}^{\pi^{\text{E} } } - V_{T}^{\hat{\pi} }\prec H^{2}\epsilon_{\pi}\qquad \text{ and }\qquad V_{T}^{\pi^{\text{E} } } - V_{T}^{\pi^{\text{RL} } }\prec H\epsilon_{\pi} $$- 其中 \(V_{T}^{\pi}\) 表示 \(\pi\) 在奖励 \(r\) 下的值
- \(\epsilon_{\pi}\) 定义为:
$$ \epsilon_{\pi} := \max_{h \in [H]} \max_{(s_{h},a_{h})} | \log (\pi^{\text{E} }(a_{h} | s_{h})) - \log (\hat{\pi} (a_{h} | s_{h}))|$$
- 定理 2 表明 \(\pi^{\text{RL} }\) 在次优性界限中实现了对响应长度 \(H\) 的线性依赖,而 \(\hat{\pi}\) 则受到二次依赖的影响
- 注:这里一次依赖和二次依赖的更多理解见附录部分
- 这种二次依赖反映了模仿学习中的复合误差问题 (Ross and Bagnell, 2010; 2021),其中单步误差 \(\epsilon_{\pi}\) 沿轨迹累积。\(\pi^{\text{RL} }\) 实现的优越线性依赖揭示了逆强化学习的基本优势。不是直接模仿专家动作,而是恢复底层奖励函数并使用该奖励执行 RL,消除了复合误差问题。作为技术说明,尽管本文关注有限视野设置,但定理 2 可以通过 (2021) 中发展的分析扩展到无限视野设置
Ineffectiveness of Iterative Improvement,迭代改进的无效性
- 能否采用改进后的策略 \(\pi^{\text{RL} }\),提取其自身的内生奖励,并执行另一次 RL 步骤以获得进一步的改进?
- 答案是否定的
- 根据构造,策略 \(\pi^{\text{RL} }\) 是奖励 \(\hat{r}\) 的最优策略
- 因此,从 \(\pi^{\text{RL} }\) 提取的内生奖励正是 \(\pi^{\text{RL} }\) 已经最优的那个奖励
- 应用另一个 RL 步骤将产生相同的策略,所以这种方式做迭代改进无效
Experiments
- 实验设置
- 使用模型:Qwen2.5-Math-7B 等
- 数据集:RM-Bench(reward 评估)、DSP(instruction-following)、MATH 等
- 对比方法:LLM-as-a-judge、GenRM、DPO 等
- 结果总结
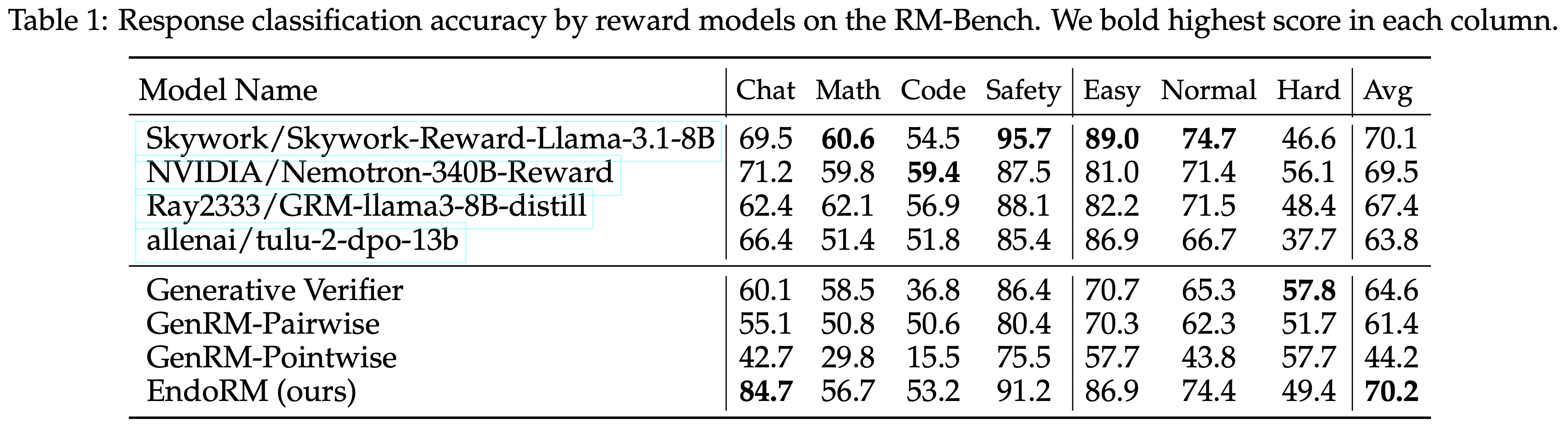
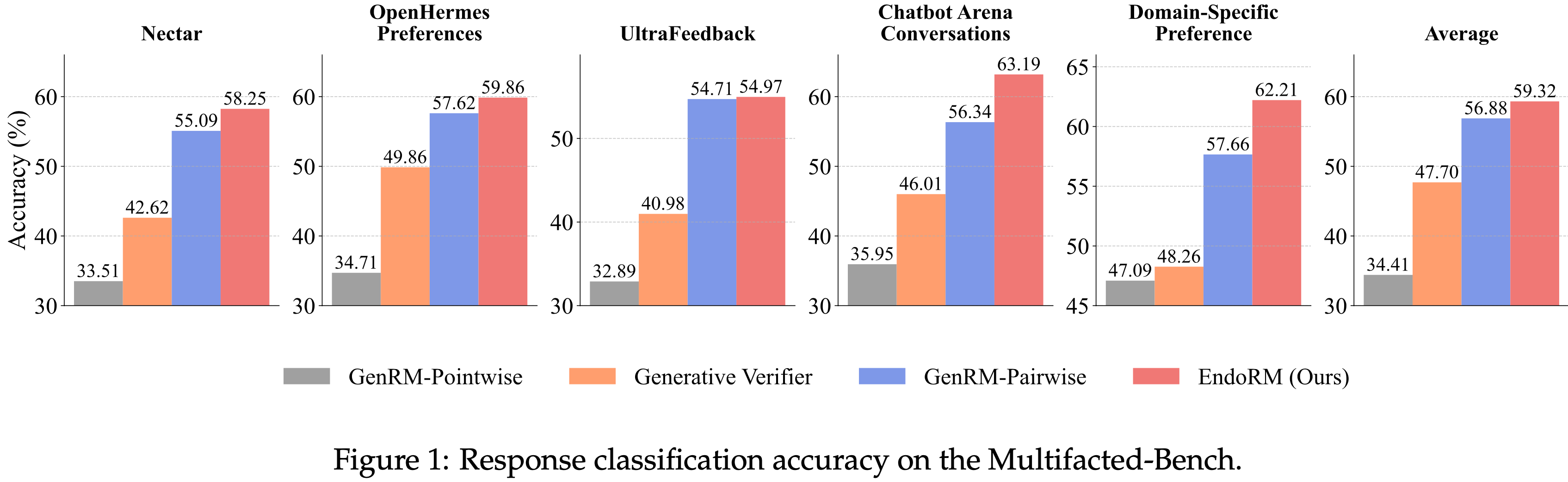
研究问题 实验结论 Q1: EndoRM 是否优于现有 reward model? 是
在 RM-Bench 上,EndoRM 显著优于 heuristic 方法,甚至优于某些显式训练的 reward modelQ2: EndoRM 是否支持 instruction-following? 是
通过 prompt 改变 evaluation 标准,EndoRM 在不同领域(如 Academy, Business)上表现出明显的 diagonal patternQ3: RL with EndoRM 是否能提升 policy? 是
在 MATH 等 5 个 benchmark 上,RL fine-tuning 后平均提升 +5.8% - 示例分析
- 附录中展示了一个数学问题的生成例子:base model 出现错误并输出 Python 代码,而 RL fine-tuned model 能给出清晰、正确的数学推导

- 附录中展示了一个数学问题的生成例子:base model 出现错误并输出 Python 代码,而 RL fine-tuned model 能给出清晰、正确的数学推导
Discussion
- 对齐范式的转变
- 传统的三阶段对齐(SFT → Reward Modeling → RL)可简化为两阶段:SFT → RL
- Reward modeling 阶段被完全消除,极大降低工程复杂度
- 个性化与可控制性
- 传统 reward model 是静态的、one-size-fits-all;
- EndoRM 是 promptable 的,可动态调整 evaluation criteria,支持个性化对齐
- 强化学习蒸馏
- 可以用 teacher LLM 的 endogenous reward 指导 student LLM 的 RL fine-tuning,实现更高效的 distillation
- 多模态扩展
- 只要模型是 autoregressive(如视频、音频生成模型),该方法即可应用
附录 A:An Offline Inverse Reinforcement Learning Approach for Token-level MDPs
- 本节提供第 3.1 节中介绍的离线 IRL 方法的完整推导
- 从最大熵 IRL 的极小化极大公式开始,如公式 (5) 所示,正如第 2.4 节中讨论的,内层优化是带有奖励 \(r\) 的最大熵强化学习问题 [2017, 2019] ,其解如下:
$$\pi_{r}^{*}(a_{h}|s_{h}) = \frac{\exp\left(Q_{r}^{*}(s_{h},a_{h}) / \alpha\right)}{\sum_{a_{h}^{\prime}\in \mathcal{V} }\exp\left(Q_{r}^{*}(s_{h},a_{h}^{\prime}) / \alpha\right)} \tag {14}$$ - 这里 \(Q_{r}^{*}\) 是带有奖励 \(r\) 的熵正则化最优 Q 值函数,定义为对于任意第 \(h\) 步的 \((s_{h},a_{h})\) ,有
$$ Q_{r}^{*}(s_{h},a_{h}):= r_{h}(s_{h},a_{h}) + \max_{\tau}\mathbb{E}[\sum_{h = h + 1}^{H}r_{h^{\prime} }(s_{h^{\prime} },a_{h^{\prime} }) + \alpha H(\pi (\cdot |s_{h^{\prime} }))|s_{h},a_{h}] $$ - 此外,如果定义熵正则化 Bellman 算子为
$$[\mathcal{T}Q](s_{h},a_{h}):= r(s_{h},a_{h}) + \alpha \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q(s_{h + 1},a_{h + 1})\right) / \alpha\right) \text{ where } s_{h + 1} = P(s_{h},a_{h}),$$ - 有 \(Q_{r}^{*}\) 是 \(\mathcal{T}\) 的不动点 [2019] ,即
$$Q_{r}^{*}(s_{h},a_{h}) = [\mathcal{T}Q_{r}^{*}](s_{h},a_{h})$$ - 将公式 (14) 的内层问题解代入公式 (5) 得到一个单一的最大化问题
$$\max_{r}\frac{1}{n}\sum_{i = 1}^{n}\sum_{h = 1}^{H}r(s_{h}^{i},a_{h}^{i}) - \alpha \mathbb{E}_{s_{1}\sim \rho}\left[\log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q_{r}^{*}(s_{1},a_{1}) / \alpha\right)\right)\right].$$ - 遵循 IRL 方法 inverse soft Q-learning [2021] ,进行变量替换,基于所谓的逆 Bellman 算子用 Q 值函数替换奖励函数
$$r(s_{h},a_{h}) = [\mathcal{T}^{-1}Q](s_{h},a_{h}):= Q(s_{h},a_{h}) - \alpha \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q(s_{h + 1},a_{h + 1})\right) / \alpha\right) \tag {15}$$ - 然后基于数据集 \(\mathcal{D} = \{(x^{i},a_{1:H}^{i})\}_{i = 1}^{n}\) 得到关于 Q 值函数的最终目标
$$\max_{Q}\frac{1}{n}\sum_{i = 1}^{n}\sum_{h = 1}^{H}\left(Q(s_{h}^{i},a_{h}^{i}) - \alpha \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q(s_{h + 1}^{i},a_{h + 1})\right) / \alpha\right)\right) -\alpha \mathbb{E}_{s_{1}\sim \rho}\left[\log \left(\sum_{a_{1}\in \mathcal{V} }\exp \left(Q(s_{1},a_{1}) / \alpha\right)\right)\right].$$ - 对于上述目标中的第二项,利用 telescoping 论证得到
$$\alpha \mathbb{E}_{s_1\sim \rho}\left[\log \left(\sum_{a_1\in \mathcal{V} }\exp \left(Q(s_1,a_1) / \alpha\right)\right)\right] = \alpha \mathbb{E}_{\tau \sim \tau^{\mathbb{E} } }\left[\sum_{h = 1}^{H}\log \left(\sum_{a_h\in \mathcal{V} }\exp \left(Q(s_h,a_h) / \alpha\right)\right) - \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q(s_{h + 1},a_{h + 1}) / \alpha\right)\right)\right]$$ - 将上述方程代入目标函数得到
$$\begin{align} \max \frac{1}{Q}\sum_{i = 1}^{n}\sum_{h = 1}^{H}\left(Q(s_{h}^{i},a_{h}^{i}) - \alpha \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q(s_{h + 1}^{i},a_{h + 1})\right) / \alpha\right)\right) -\alpha \mathbb{E}_{\tau \sim \tau^{\mathbb{E} } }\left[\sum_{h = 1}^{H}\log \left(\sum_{a_{h}\in \mathcal{V} }\exp \left(Q(s_{h},a_{h}) / \alpha\right)\right) - \log \left(\sum_{a_{h + 1}\in \mathcal{V} }\exp \left(Q(s_{h + 1},a_{h + 1}) / \alpha\right)\right)\right] \end{align} \tag {15}$$ - 可以利用 demonstrations \(\mathcal{D}\) 来无偏估计期望项,得到最终目标
$$\max_{Q}\frac{1}{n}\sum_{i = 1}^{n}\sum_{h = 1}^{H}\left[Q(s_{h}^{i},a_{h}^{i}) - \alpha \log \left(\sum_{a_{h}\in \mathcal{V} }\exp \left(Q(s_{h}^{i},a_{h})\right) / \alpha\right)\right].$$
附录 B:Omitted Proofs
B.1 Proof of Proposition 1
- 证明主要基于定义
- 由于 \(\hat{\pi}(\cdot|s_h) = \text{softmax}(\hat{f}(s_h, \cdot); \alpha)\) 是公式 (1) 中 NTP 的最优解,我们有
$$\hat{\pi} \in \arg\max_{\pi} \sum_{i=1}^{n} \sum_{h=1}^{H} \log \left( \pi \left( a_t^i | x^i, a_{1:h-1}^i \right) \right).$$
- 由于 \(\hat{\pi}(\cdot|s_h) = \text{softmax}(\hat{f}(s_h, \cdot); \alpha)\) 是公式 (1) 中 NTP 的最优解,我们有
- 这直接蕴含了
$$
\begin{align}
\hat{f} &\in \arg\max_{f} \frac{1}{n} \sum_{i=1}^{n} \sum_{h=1}^{H} \log \left( \frac{\exp(f(s_h^i, a_h^i)/\alpha)}{\sum_{a_h’ \in \mathcal{V} } \exp(f(s_h^i, a_h’)/\alpha)} \right) \\
&= \arg\max_{f} \frac{1}{n} \sum_{i=1}^{n} \sum_{h=1}^{H} \left( f(s_h^i, a_h^i) - \alpha \log \left( \sum_{a_h \in \mathcal{V} } \exp(f(s_h^i, a_h)) / \alpha \right) \right) \tag {16}
\end{align}
$$ - 通过比较公式 (16) 和公式 (6),作者可以得出结论:\(\hat{f}\) 是公式 (6) 中离线 IRL 目标的最优解
B.2 Proof of Theorem 1
- 详情见原论文
B.3 Proof of Theorem 2
- 详情见原论文
附录 C:Outcome Reward Calculation
- 对于一个完整的 Response \(\tau\),结果奖励可以计算为
$$
\hat{r}(\tau) = \sum_{h=1}^{H} \hat{r}(s_h, a_h),
$$- 其中 \(\hat{r}(s_h, a_h)\) 如公式 (10) 所定义
- 由于语言模型自回归地生成文本,较早的 Token 会影响后续的输出
- 在实现中,按如下方式计算 Response 的奖励:
$$
\hat{r}(\tau) = \sum_{h=1}^{H} \max\left( \gamma^{h-1}, \beta \right) \hat{r}(s_h, a_h),
$$- \(\gamma \in (0, 1]\) 是折扣因子
- \(\beta \geq 0\)
- 在实现中,按如下方式计算 Response 的奖励:
- 超参设置:
- 对于 Multifacted-Bench 上的实验以及在 MATH-lighteval 数据集上的 RL:使用 \(\gamma = 0.95, \beta = 0\)
- 对于 RM-bench 上的实验,使用 \(\gamma = 0.93, \beta = 0.03\)
- 所有采样温度均设为 1.0
附录 D:Prompt Templates
用于在 Multifacted-Bench [2024b] 上 Benchmark 奖励模型的所有方法的 Prompt 模板如下所示
由于 RM-Bench 没有为每个样本提供具体指令,所有方法都使用默认的 System Prompt,并且 User 部分 Prompt 模板中的指令也将被移除
Figure 2: Prompt template of our Endogenous Reward Model.
1
2
3
4
5
6
7System:
{instruction}
User:
### Query
{query}
### Response
{response}Figure 3: Prompt template of Generative Verifier.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17System:
You are an AI evaluator. Your role is to assess AI-generated text for its quality and adherence to instructions.
User:
You need to determine if the ‘Response’ is a good response to the ‘Query’, based on the standards set by the
‘Instruction’. A ‘good’ response MUST satisfy the following conditions:
1. **Adherence to Instruction:** The answer’s tone, style, and content must perfectly match the provided instruction.
2. **Relevance to Query:** The answer must directly and comprehensively address the user’s query without any
irrelevant information.
3. **Factuality and Helpfulness:** The information in the answer should be accurate and useful.
Please carefully review the following materials.
### Instruction
{instruction}
### Query
{query}
### Response
{response}
Based on your evaluation, is the answer a good response? Answer with only “YES” or “NO”.Figure 4: Prompt template of GenRM-Pairwise
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23System:
You are an AI evaluator. Your role is to assess AI-generated text for its quality and adherence to instructions.
User:
You are asked to evaluate two answers, ‘Response 1’ and ‘Response 2’, in relation to a ‘Query’ and a ‘Instruction’.
**Evaluation Criteria:**
1. **Adherence to Instruction:** Does the answer’s tone, style, and content align with the specified instruction?
2. **Relevance to Query:** Does the answer directly and comprehensively address the user’s query?
3. **Factuality and Helpfulness:** Is the information accurate and useful?
Based on these criteria, please review the following:
### Instruction
{instruction}
### Query
{query}
### Response 1
{response1}
### Response 2
{response2}
**Your Task:**
Is ‘Response 2’ better than ‘Response 1’?
**Rules for Your Response:**
1. Respond with only “YES” or “NO”. Do not include explanations or any other text.
2. “YES” means ‘Response 2’ is clearly better than ‘Response 1’.
3. “NO” means ‘Response 2’ is not better (it is either worse or of equal quality) than ‘Response 1’Figure 5: Prompt template of GenRM-Pointwise.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24System:
You are an AI evaluator. Your role is to assess AI-generated text for its quality and adherence to instructions.
User:
You need to evaluate the ‘Response’ in response to the ‘Query’, based on the ‘Instruction’. Your evaluation should be a
score from 1 to 10.
**Evaluation Criteria:**
1. **Adherence to Instruction:** Does the answer’s tone, style, and content match the instruction?
2. **Relevance to Query:** Does the answer directly and comprehensively address the user’s query?
3. **Factuality and Helpfulness:** Is the information accurate and useful?
Please review the following:
### Instruction
{instruction}
### Query
{query}
### Response
{response}
Based on your assessment, provide a single integer score from 1 to 10.
**Scoring Guide:**
- **1-2:** Very Poor. Fails on most criteria.
- **3-4:** Poor. Significant issues in multiple areas.
- **5-6:** Average. Meets basic requirements but has clear flaws.
- **7-8:** Good. Solid response with minor issues.
- **9-10:** Excellent. A nearly perfect response that excels in all criteria.
Provide only the numeric score
附录:逆 Soft Bellman 算子(Inverse Soft Bellman Operator, ISBO)
- 逆 Soft Bellman 算子 (ISBO) 是本文推导内生奖励的核心数学工具
- ISBO 的作用是从已知的最优 Q 函数反推出对应的奖励函数
标准的 Soft Bellman 算子
- 在最大熵强化学习或正则化 MDP 中,Soft Bellman 算子 定义了如何从奖励函数 \( r \) 计算 Q 函数:
$$
[\mathcal{T} Q](s_h, a_h) = r(s_h, a_h) + \alpha \log \left( \sum_{a_{h+1} \in \mathcal{V} } \exp\left( Q(s_{h+1}, a_{h+1}) / \alpha \right) \right)
$$- \( s_{h+1} \) 是在状态 \( s_h \) 执行动作 \( a_h \) 后到达的下一状态(在 LLM 的确定性环境中,就是拼接了 \( a_h \) 后的新序列)
- \( \alpha \) 是熵正则化系数
- 第二项实际上就是软价值函数
$$ V(s_{h+1}) = \alpha \log \sum_{a} \exp(Q(s_{h+1}, a)/\alpha) $$
- 这个算子是前向的:给定 \( r \),可以求出 \( Q \)
逆 Soft Bellman 算子
- 逆 Soft Bellman 算子 就是反过来:给定 Q 函数,恢复奖励函数 \( r \)
- ISBO 定义:
$$
[\mathcal{T}^{-1} Q](s_h, a_h) := Q(s_h, a_h) - \alpha \log \left( \sum_{a_{h+1} \in \mathcal{V} } \exp\left( Q(s_{h+1}, a_{h+1}) / \alpha \right) \right)
$$ - 注:这对应论文中的 公式 (7) 和 公式 (15)
对 ISBO 直观理解
- 如果把 Soft Bellman 方程写成:
$$
Q(s_h, a_h) = r(s_h, a_h) + V(s_{h+1})
$$ - 那么逆算子就是移项:
$$
r(s_h, a_h) = Q(s_h, a_h) - V(s_{h+1})
$$ - 因为
$$ V(s_{h+1}) = \alpha \log \sum_{a} \exp(Q(s_{h+1}, a)/\alpha) $$- 因此上式就是逆 Soft Bellman 算子
- 本质是利用当前步的 Q 值和下一步的“软最大值”来剥离出即时奖励
结合论文理解 ISBO(在论文中的作用)
- 核心发现:通过 NTP 训练出的 LLM 的 Logits \( \hat{f} \) 天然就是一个最优的软 Q 函数,只需下面的步骤即可抽取出 RM:
- 1)取出 LLM 的 Logits 作为 \( \hat{Q} \)
- 2)应用逆 Soft Bellman 算子,得到 \( \hat{r} \)
- 3)这个 \( \hat{r} \) 就可以作为奖励信号用于后续的 RL 微调
附录:为什么说 「\(\pi^{\text{RL} }\) 在次优性界限中实现了对响应长度 \(H\) 的线性依赖,而 \(\hat{\pi}\) 则受到二次依赖的影响」
- 注:这个结论源于模仿学习与逆强化学习 + 强化学习在误差累积上的根本差异
- TLDR:
- \(\hat{\pi}\)(BC) :每步误差在后续步中持续累积,最终误差 \(\sim H^2\)
- \(\pi^{\text{RL} }\)(IRL+RL) :通过奖励信号进行全局优化,避免了误差在状态空间中的二次放大,最终误差 \(\sim H\)
- 简单理解:
- BC 是“一步错,步步错”,误差随轨迹长度平方增长
- IRL+RL 通过奖励信号修正错误,误差只随长度线性增长
为什么 \(\hat{\pi}\)(行为克隆)有 \(\mathcal{O}(H^2)\) 的次优性?
- 行为克隆直接模仿专家动作,即在每个状态 \(s_h\) 下,尽量输出与专家 \(\pi^E\) 相同的动作 \(a_h\)
- 误差传播机制
- 假设在每一步,策略 \(\hat{\pi}\) 与专家 \(\pi^E\) 的单步动作分布差异为 \(\epsilon_\pi\)(在对数概率意义下)
- 由于策略是自回归的(像 LLM 生成 token),第 \(h\) 步的状态分布已经因为前 \(h-1\) 步的误差而偏离了专家的状态分布
- 在偏离的状态下,即使策略在该状态下的动作误差仍然为 \(\epsilon_\pi\),但后续步数的误差会不断叠加
- 数学结果
- 根据模仿学习理论(如 2020),BC 策略的价值次优性满足:
$$
V^{\pi^E} - V^{\hat{\pi} } \le \mathcal{O}(H^2 \epsilon_\pi)
$$ - 这是因为:
- 第 \(h\) 步的误差贡献约为 \(h \cdot \epsilon_\pi\)
- 对 \(h = 1\) 到 \(H\) 求和:\(\sum_{h=1}^H h = \frac{H(H+1)}{2} = \mathcal{O}(H^2)\)
- 直观理解:BC 像是在没有导航的情况下“跟车”,前车稍微偏一点,后车就会越来越偏,到最后完全偏离路线
- 根据模仿学习理论(如 2020),BC 策略的价值次优性满足:
为什么 \(\pi^{\text{RL} }\)(IRL + RL)只有 \(\mathcal{O}(H)\) 的次优性?
- \(\pi^{\text{RL} }\) 是通过先从 \(\hat{\pi}\) 提取内生奖励 \(\hat{r}\),再对该奖励做 RL 得到的策略
- 关键机制
- RL 不是在每个状态模仿专家动作,而是优化一个全局奖励信号
- 即使中间状态分布有偏差,只要奖励函数 \(\hat{r}\) 能够正确评估整体轨迹的好坏,RL 就能通过长期回报引导策略回到正确轨道
- 这相当于把问题从“每一步都要对齐”放松为“最终结果要对齐”
- 数学结果(定理 2 给出):
$$
V^{\pi^E} - V^{\pi^{\text{RL} } } \le \mathcal{O}(H \epsilon_\pi)
$$- 线性依赖的原因:
- 奖励误差 \(\epsilon_\pi\) 会直接体现在每步的奖励值中,但不会因为状态偏差而被放大成二次累积
- 最终次优性正比于总步数乘以单步奖励误差 ,而不是步数的平方
- 直观理解:RL 像是给车装了一个导航系统(奖励信号),即使中途走错一小段,导航也会把车纠正回来,最终到达目的地的误差不会随时间平方放大
- 线性依赖的原因:
理解:一个简单例子
- 假设:
- 真实专家策略 \(\pi^E\) 要求一直输出“直行”
- 行为克隆策略 \(\hat{\pi}\) 每步有概率 \(p\) 输出“左转”,一旦左转就永久偏离轨道
- 那么在 \(H\) 步后
- \(\hat{\pi}\) 仍在正确轨道的概率约为 \((1-p)^H\),累积奖励损失约 \(\mathcal{O}(H^2 p)\)
- RL 策略 \(\pi^{\text{RL} }\) 即使中途左转,如果奖励函数给“最终到达目标”高分,它会在后续步骤中学习“右转”来补偿,从而误差不会随步数平方增长