注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 作者创新性地使用 Scientific Taste 来量化 生成/评判 High Potential Impact Research Ideas 的能力
- 其实在本文就是使用引用量来评判依据,Pairwise 作为信号,同时对齐发表时间和领域进行消偏
- 本文将 Scientific Taste 学习形式化为一个偏好建模和偏好对齐问题
- 本文提出了一种新的方法(RLCF,RL from Community Feedback)
- 顾名思义:利用引用信号作为社区反馈进行偏好建模和对齐 (即使用 社区信号作为监督)
- 训练了两个模型:
- 奖励模型:用于科学判断的 Scientific Judge
- Scientific Judge 随着数据和模型规模的扩大而扩展,并能跨时间、领域和同行评审偏好进行泛化,可以作为 Scientific Thinker 的生成式奖励模型
- 实验表明: Scientific Judge 优于 GPT-5.2 和 Gemini 3 Pro,且可以泛化到未来年份和未见过的领域
- 问题 & 思考:这里模型学到的可能是一些特征,如是否 Survey、具体方向(同一个领域内不同方向引用量也不同)等
- Generator:用于科学构思的 Scientific Thinker
- Scientific Thinker 提出的 Research Idea 比 Baseline 具有更高的潜在影响力
- 问题 & 思考:这里的评估使用的是 SOTA 模型来投票判断 Scientific Thinker vs Baseline 的胜率,其实并不严谨,因为 Scientific Taste 本身是不太可通过 LLM 直接评估的
- 奖励模型:用于科学判断的 Scientific Judge
- 核心贡献:证明了 Scientific Taste 可以从大规模的社区反馈中学习,算是 LLM for Science 的一步探索
- 作者创新性地使用 Scientific Taste 来量化 生成/评判 High Potential Impact Research Ideas 的能力
Introduction and Discussion
- 大多数研究都集中在提高 AI Scientists 的执行能力上,增强 AI 的 Scientific Taste 这一方向仍未得到充分探索
- Scientific Taste 并不仅仅是主观偏好的问题
- Hume(苏格兰哲学家)认为,品味的标准可以从合格评判者的共同评判中产生,而非来自任意的个人偏好 (2026)
- Kant (1994) 将品味引入为一种“共通感”,一种共享的感受,它考虑了他人的可能评判,而不仅仅是个人感受
- 在科学背景下,这种社区评判通过研究社区内的长期互动得以体现
- 与这种 Scientific Taste 相符的工作更有可能被后续研究复用和扩展
- 最终,社区反馈通过信号表达出来,主要是通过引用,这是衡量科学研究影响力最常见的方式
- 作者提出了一种利用大规模社区反馈来构建社区偏好信号的训练范式(RLCF)
- 并将 Scientific Taste 学习形式化为一个偏好建模和偏好对齐问题
- 特殊设计(与常规方式不同):为了将原始社区反馈(例如,引用)转化为可学习的偏好信号,将绝对反馈转换为匹配的 Pairwise 比较,并构建了 SciJudgeBench (SciJudgeBench)
- SciJudgeBench包含 700K 对论文摘要(高被引 vs. 低被引),其中每一对都通过研究领域和发表时间进行匹配,这样得到的 Pairwise 信号能更直接地反映社区对高潜在影响力想法的偏好
- 对于偏好建模(学会评判), 本文训练了一个生成式奖励模型 Scientific Judge
- 基于自身的评估标准比较两篇论文,然后在推理后做出判断,选出更好的一篇
- 除了作为奖励模型, Scientific Judge 还可以在新生论文获得任何引用之前对其进行排名
- 使用 GRPO 训练 Scientific Judge ,并根据其偏好判断是否正确来分配奖励
- 对于生成:for 提出有前景的研究方向,本文 训练一个策略模型 Scientific Thinker
- 奖励模型为 Scientific Judge ,通过 RL 训练
- Scientific Thinker 能生成具有高学术价值和潜在影响力的科学想法(与社区偏好对齐)
- 场景设定:
- 人类科学家通常在受到一篇新论文启发时会产生新的 Research Idea
- 类似地,本文作者向 Scientific Thinker 提供一篇论文的标题和摘要,Prompt 它在思考后提出一个具有高潜在影响力的后续 Research Idea
- Scientific Judge 评估:
- 在 SciJudgeBench 上的表现显著优于 GPT-5.2, Gemini 3 Pro 等 SOTA 模型
- 能泛化到未来年份的数据、未见过的领域以及同行评议偏好
- 这表明它学习到了一种可迁移的 “Taste” 表征
- 作者认为, Scientific Taste 并非一种神秘的人类特质,而是一个可学习的目标
- 理解:这有待商榷
- 本文贡献总结:
- 将 Scientific Taste 学习形式化为一个偏好建模和偏好对齐问题,提出了 RLCF 训练范式
- RLCF 利用社区信号(例如,引用)作为监督信号
- 构建了用于训练和评估 AI 科学 Judgement Capability 的 SciJudgeBench ,它由70万对基于引用、按领域和时间匹配的论文摘要对组成
- 训练了用于科学判断的 Scientific Judge ,其表现优于当前 SOTA,并能跨时间、跨领域和跨同行评议分数进行泛化
- 训练了用于创意生成的 Scientific Thinker ,该模型在经过训练后能提出具有更高潜在影响力的想法


- 将 Scientific Taste 学习形式化为一个偏好建模和偏好对齐问题,提出了 RLCF 训练范式
Background and Related Work
Definition Scientific Taste
- 伟大的科学家拥有强大的判断力和远见,这与 Scientific Taste 密切相关
- 本文呢使用 Scientific Taste 这个术语来指代判断和提出具有高潜在影响力的 Research Idea 的能力
Potential Impact
- 首先形式化一个 Research Idea 具有潜在影响力的含义
- 引用是衡量科学研究影响力的最常见方式
- 考虑一篇已发表的论文 \(p\)
- 设 \(c_{t}(p)\) 是论文 \(p\) 在发表后第 \(t\) 年获得的新引用次数
- 将 \(c_{t}(p)\) 建模为一个非负随机变量,其分布取决于该论文及其时间背景
- 论文 \(p\) 的累积期望影响力定义为:
$$I(p) = \lim_{N\to \infty}\sum_{t = 1}^{N}\mathbb{E}[c_t(p)] \tag{1}$$- 其中 \(\mathbb{E}[c_t(p)]\) 表示第 \(t\) 年的期望引用增量
- 具有更大 \(I(p)\) 的论文被认为具有更高的潜在影响力
Judgement Capability
- 模型 \(\theta\) 的 Judgement Capability 通过比较论文对累积期望影响力的期望准确率来衡量
- 令 \(\mathcal{D}\) 表示一个按领域和时间匹配的论文对的分布
- 对于单个对 \((p_a,p_b)\),其真实标签为:
$$y(p_a,p_b) = \begin{cases} 1, & \text{if } I(p_a) > I(p_b),\\ 0, & \text{otherwise}. \end{cases} \tag{2}$$ - 注意,即使 \(I(p_a)\) 和 \(I(p_b)\) 都发散,这个标签也是良定义的(见附录 G 的形式化证明)
- 在实践中,本文使用有限期近似
$$ I_N(p) = \sum_{t = 1}^{N}\mathbb{E}[c_t(p)]$$ - Judgement Capability 是:
$$\text{JUDGE}_\text{cap}(\theta) = \mathbb{E}_{(p_a,p_b)\sim \mathcal{D} }\left[\mathbb{I}\left[\text{JUDGE}_\theta (p_a,p_b) = y(p_a,p_b)\right]\right] \tag{3}$$- 其中 \(\text{JUDGE}_{\theta}(p_{a},p_{b})\) 是模型的预测结果
- 更高的 \(\text{JUDGE}_{\text{cap} }(\theta)\) 表示更强的 Judgement Capability
Ideation Capability
- 模型 \(\phi\) 的创意生成能力由其提出的想法的期望影响力来刻画
- 给定一个种子参考论文 \(s\in S\),模型 \(\phi\) 生成一个新的 Research Idea \(\text{THINKER}_{\phi}(s)\)
- 创意生成能力是:
$$\text{THINKER}_\text{cap}(\phi) = \mathbb{E}_{s\sim S}\left[I(\text{THINKER}_{\phi}(s))\right] \tag{4}$$
- 创意生成能力是:
- 对于两个模型 \(\phi_{A}\) 和 \(\phi_{B}\),如果满足下面的条件,则称 \(\phi_{A}\) 比 \(\phi_{B}\) 具有更强的创意生成能力:
$$ \text{THINKER}_\text{cap}(\phi_{A}) > \text{THINKER}_\text{cap}(\phi_{B}) $$
Scientific Taste
- 本文将 Judgement Capability 和创意生成能力的结合称为 Scientific Taste
- 形式上,如果一个模型同时实现了高 \(\text{JUDGE}_{\text{cap} }\) 和高 \(\text{THINKER}_{\text{cap} }\),则称其拥有强大的 Scientific Taste
AI for Scientific Research
- 当前对 AI Scientists 的训练主要集中在文献搜索 (2025, 2025, 2025, 2026) 和实验执行 (2025, 2025, 2024, 2025, 2025, 2025, 2025) 上
- 这些能力解决的是如何进行研究,而不是哪些研究方向值得追求
- 人工评估显示,LLM 能够生成新颖的 Research Idea ,但通常难以可靠地区分具有高潜在影响力的方向和那些表面新颖但琐碎的想法 (2024)
- 这种差距构成了当今 AI Scientists 与人类专家之间的一个关键差异:Scientific Taste,Scientific Taste 包括两方面的能力:
- (1)评判候选想法的科学价值
- (2)提出具有高潜在影响力的研究问题、假设和方法
- 最近的研究探索了利用LLM来评估学术稿件、预测评审分数和生成反馈 (2024, 2024, 2025, 2024, 2025, 2025)
- 这些工作主要将语言模型用作审稿流程中的组件,而不是增强模型内在的科学 Judgement Capability
- 先前的工作 (2025, 2024) 通常使用监督微调在审稿人反馈上训练模型
- 本文通过 RL 使用社区反馈来训练模型,使其能够判断并提出具有高潜在影响力的想法,从而更紧密地与更广泛的社区偏好对齐
- 当前的创意生成方法也显示出明显的局限性
- 在实践中,创意生成的改进通常由随机启发式或简单的头脑风暴策略驱动 (2024)
- 近期如 OpenNovelty 等工作使用信息检索来衡量一个想法与先前工作的差异程度(即新颖性)(2026)
- 目前,创意生成的优化主要集中在外部检索和模型提示刺激上 (2024, 2026),而增强模型内在的创意生成能力这一方向仍未得到充分探索
RL Training Paradigms for LLMs
- RLHF 收集人类偏好标注,训练一个奖励模型来捕捉人类偏好,然后使用该奖励优化策略模型,从而能够更好地对齐主观偏好,例如乐于助人和无害
- 最近的工作进一步扩展了奖励建模的规模,并为评估奖励模型开发了标准化基准 (2025, 2024, 2025)
- 对于数学和编程等任务,RLVR 利用由标准答案、单元测试或形式化检查器提供的可验证奖励
- 已在数学推理、代码生成和更广泛的后训练流程中带来了巨大收益
- RLVR 本质上与具有可验证真实情况的任务相关联,使其难以应用于科学判断和创意生成等开放式任务 (2025)
- RLHF 受限于其对昂贵人工标注的依赖 (2022, 2022),并且无法仅通过个体偏好来反映社区层面的偏好
- 本工作提出了 RLCF ,利用从社区互动中自然涌现的可扩展的社区反馈信号
- 本质是在捕捉了社区偏好
RLCF:Reinforcement Learning from Community Feedback
- RLCF 包含三个阶段:
- (1)构建社区偏好,收集社区反馈信号来构建社区偏好数据
- (2)偏好建模,训练 Scientific Judge 来预测 Research Idea 的潜在影响力
- (3)偏好对齐,使用 Scientific Judge 作为奖励模型来监督 Scientific Thinker 生成具有高潜在影响力的科学想法
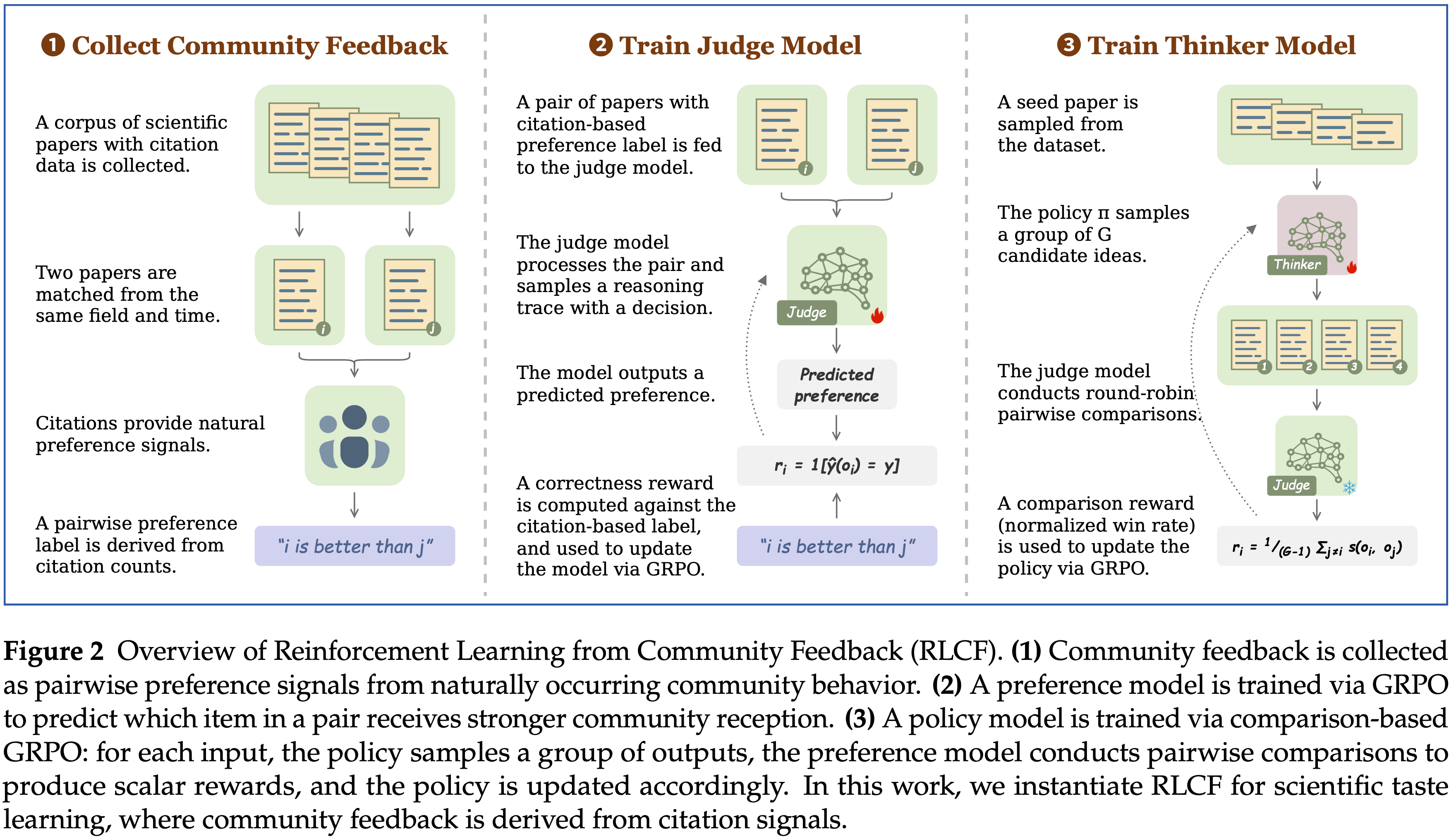
Community Feedback as Supervision
- 使用引用作为科学社区的反馈信号,因为引用计数是通过研究社区内的长期互动所反映的社区评判
- 高被引可以代表一项科学研究的高影响力 (2025)
- 为了减轻原始引用计数中的领域和时间偏差 ,通过配对来自同一领域和年份的文章 来构建训练数据
- 其中引用显著更高的文章被标记为 Perferred(Higher-impact)Item
- 每个训练示例由两个科学想法(由其标题和摘要代表)(2025, 2025) 和一个二元标签组成,该标签指示哪个想法具有相对更高的引用
- 本文将得到的数据集称为 SciJudgeBench ,将社区反馈转化为 Pairwise 监督信号,从而实现了可扩展的偏好学习
Preference Modeling: Scientific Judge
- Scientific Judge 通过 Pairwise 比较来预测哪个 Research Idea 具有更高的潜在影响力
- 在 SciJudgeBench 的训练集上使用 GRPO 来训练 Scientific Judge
- 对于每个输入 \(x\),策略 \(\pi_{\theta}\) 采样一组 \(G\) 个输出 \(\{o_i\}_{i = 1}^G\),每个输出包含一个推理轨迹和一个偏好预测,奖励是一个二元正确性信号:
$$r_{i} = \begin{cases} 1, & \text{if } \hat{y} (o_{i}) = y, \\ 0, & \text{otherwise}. \end{cases} \tag{5}$$- \(\hat{y} (o_i)\) 从输出 \(o_i\) 中提取预测的偏好
- \(y\) 是观察到的标签
- 在每个组内,优势被归一化:
$$ \hat{A}_i = \frac{(r_i - \text{mean}(\mathbf{r}))}{\text{std}(\mathbf{r})} $$ - 策略通过最大化一个带有 KL 惩罚的裁剪目标函数来更新,该惩罚指向一个参考策略 \(\pi_{\text{ref} }\):
$$\mathcal{I}(\theta) = \mathbb{E}_x\left[\frac{1}{G}\sum_{i = 1}^G\min \left(\rho_i\hat{A}_i,\text{clip}\left(\rho_i,1 - \epsilon ,1 + \epsilon\right)\hat{A}_i\right) - \beta D_{\text{KL} }(\pi_\theta | \pi_{\text{ref} })\right] \tag{6}$$- 其中 \(\rho_{i}\) 是重要性比率
$$ \rho_{i} = \frac{\pi_{\theta}(o_{i}\mid x)}{\pi_{\text{old} }(o_{i}\mid x)} $$ - \(\epsilon\) 是裁剪范围
- \(\beta\) 控制 KL 惩罚的强度
- 其中 \(\rho_{i}\) 是重要性比率
- 详细的超参数值在原论文的附录 B 中提供
Preference Alignment: Scientific Thinker
- 本文使用 Scientific Judge 作为生成式奖励模型来训练 Scientific Thinker
- Scientific Thinker 是一个学习提出具有高潜在影响力的科学想法的策略模型
- 优于这是一个没有真实标签的开放式任务,缺乏客观且通用的标准,对单个科学想法进行评分是困难的
- Pairwise 比较更为自然和可靠,因为比较两个想法更容易
- 作者设计了基于比较的 GRPO (2025, 2025, 2026),使用来自 Scientific Judge 的 Pairwise 偏好来计算每个想法在组内的胜率作为奖励
Comparison-Based GRPO
- 给定一个包含种子论文的提示 \(x\),策略 \(\pi_{\theta}\) 采样一组 \(G\) 个响应 \(\{o_1, \ldots , o_G\}\),每个响应提供一个候选 Research Idea
- 不直接对每个想法打分,而是进行由奖励模型评判的循环赛
- 每个候选想法与其他所有想法进行比较,由 Scientific Judge 进行判断,总共产生 \(\binom{G}{2}\) 个 Pairwise 比较结果
- 对于 \(o_{i}\),基于比较的奖励是其 Research Idea 在组内的胜率:
$$r_{i} = \frac{1}{G - 1}\sum_{j\neq i}s(o_{i},o_{j}) \tag{7}$$- \(s(o_{i},o_{j})\in \{0,1\}\) 表示在奖励模型的判断下,\(o_{i}\) 的 Research Idea 是否战胜了 \(o_{j}\) 的 Research Idea :
- \(s(o_{i},o_{j}) = 1\) 表示获胜
- \(s(o_{i},o_{j}) = 0\) 表示落败
- \(s(o_{i},o_{j})\in \{0,1\}\) 表示在奖励模型的判断下,\(o_{i}\) 的 Research Idea 是否战胜了 \(o_{j}\) 的 Research Idea :
- 给定这些奖励,训练目标与原始的 GRPO(公式 6)相同
- 基于比较的 GRPO 利用采样响应之间的比较来计算奖励,使其适用于科学创意生成等开放式任务
- 注:这会导致时的推理成本较高
AI Can Learn Scientific Judgement(Experiments 1)
- 本节重点关注训练 Scientific Judge
- 首先确立 Scientific Taste 训练的可扩展性趋势 (S4.2)
- 然后验证学到的 Scientific Taste 能够跨时间、领域和同行评审偏好进行泛化 (S4.3)
Experimental Setup
Training Data
- 从截至 2024 年发表的 2.1M 篇 arXiv 论文构建了 SciJudgeBench ,在计算机科学、数学、物理和其他领域生成了 696,758 个领域和时间匹配的偏好对
- 偏好标签来源于引用次数
- 详见附录 A 了解构建细节
Test Sets
- 在三种互补的设置下评估 Scientific Judge ,分别测试领域内判断、时间外推和跨指标迁移
- 在所有 Setting 中,每个对都按领域和发表时间进行匹配,以便在相似领域和时期的论文之间进行比较
- (1) Main (In-domain) :
- 728 个对,涵盖计算机科学、物理、数学和其他领域,衡量跨主要科学领域的分布内引用偏好预测
- 完整的领域到子类别的映射见附录 A
- (2) Temporal OOD :
- 514 个对,来自 2025 年发表的论文,在训练期之后,测试学到的引用偏好是否能外推到未来的论文
- (3) Metric OOD (ICLR) :
- 611 个对,来自 ICLR 投稿 (2017–2026),其中偏好由同行评审分数而非引用次数决定,测试基于引用的判断是否能迁移到基于同行评审的偏好
- 本文还在 160 个 bioRxiv 生物学的对上报告了结果 (附录 A.5)
- 详见附录 A 了解构建细节
- (1) Main (In-domain) :
Models
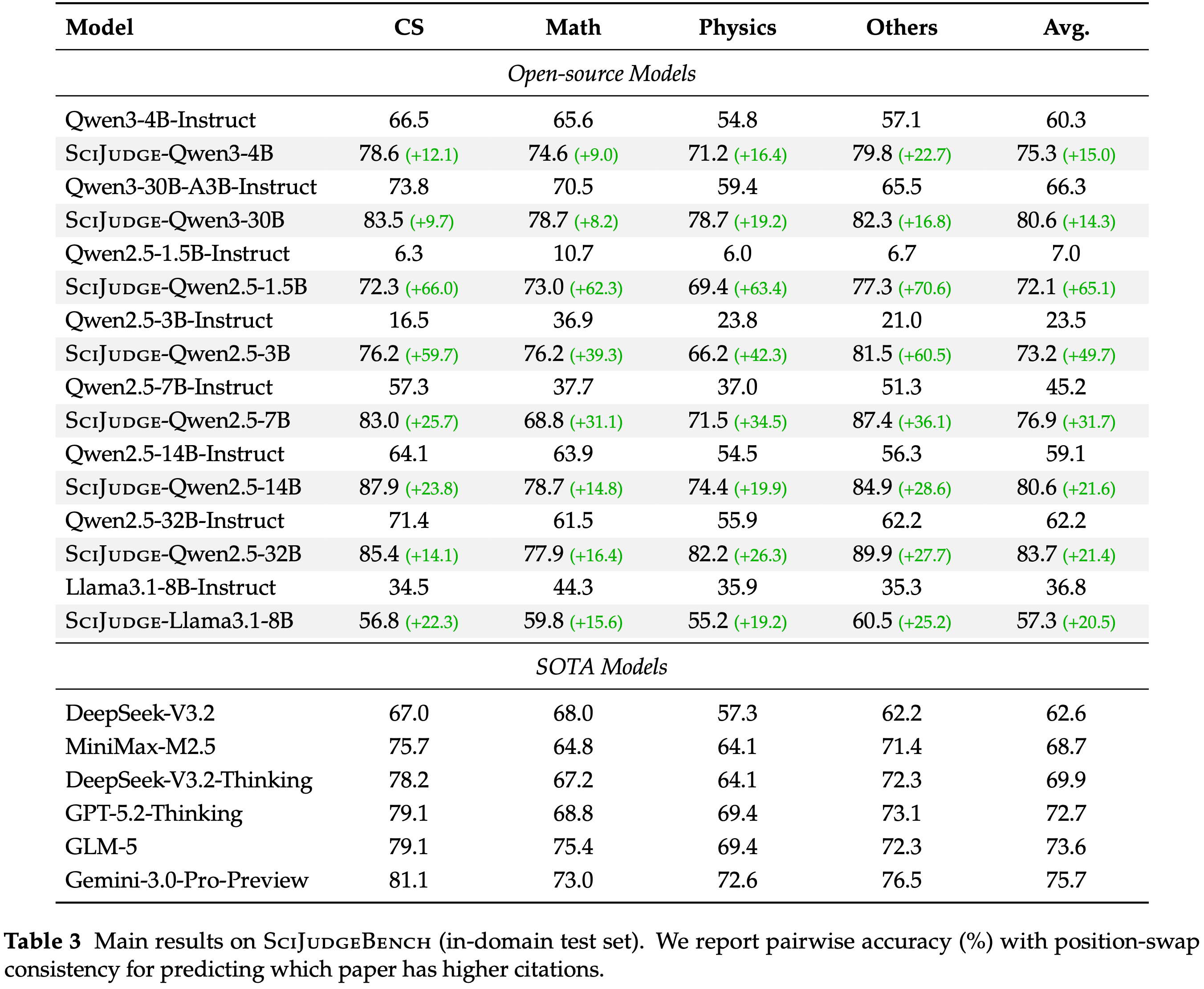
- 在 Qwen2.5-Instruct 系列 (1.5B, 3B, 7B, 14B, 32B 参数) (2024)、Qwen3-4B-Instruct-2507、Qwen3-30B-A3B-Instruct-2507 (2025) 和 Llama-3.1-8B-Instruct (2024) 上训练 Scientific Judge
- 每个训练后的模型被命名为 SciJUDGE-(base),例如 SciJUDGE-Qwen3-4B
- 与未训练的基础模型和闭源模型进行比较 (表 3)
- 完整的模型细节见附录 B
Training
- 使用 GRPO,以偏好预测正确性作为可验证奖励
- 模型生成一个推理轨迹,后跟一个预测 (A 或 B),如果正确则获得奖励 1,否则为 0
- 训练配置和计算资源见附录 B
Evaluation
- 为减轻位置偏差,通过交换论文顺序 (A ↔ B) 对每个对评估两次,仅当在两个顺序下模型都做出正确且一致的预测时才计为正确 (2023)
- 问题:这里的训练时的 Pairwise 对也是包含了交换顺序的吗?
- 详见附录 B.5
Scaling Trends
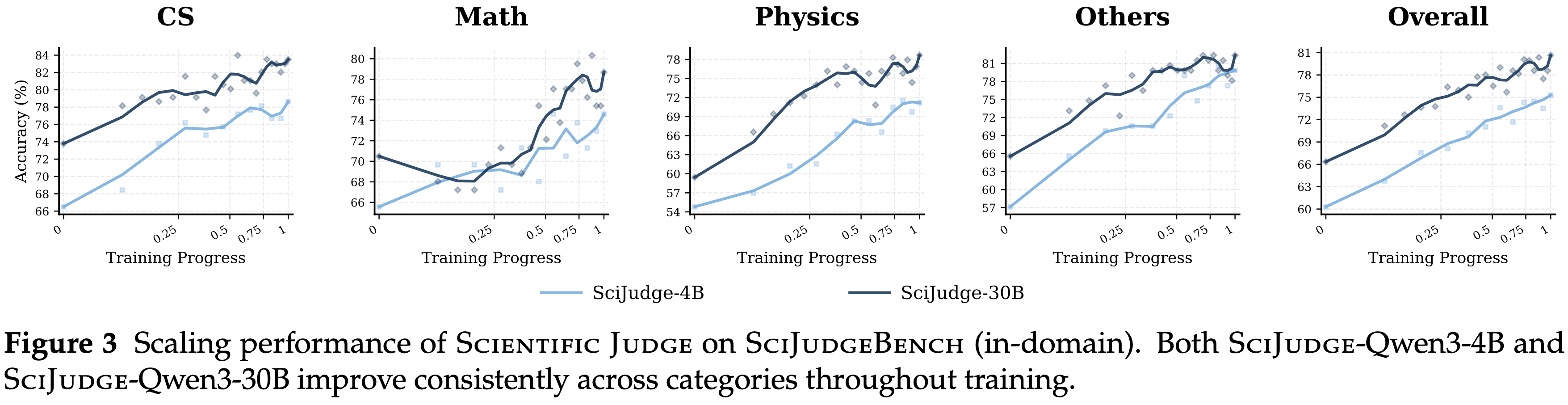
- Scientific Judge 在所有模型规模和系列上都有效地学习了 Scientific Taste ,揭示了与数据量和模型大小相关的扩展行为 (图 3,表 3)
Data scaling leads to better performance
- Scientific Judgement 性能随着更多训练数据的增加而稳步提升
- 学习曲线表明数据规模与性能之间大致呈对数线性关系
- 在训练过程中,Qwen3-4B 的总分从 60.3 上升到 75.3,Qwen3-30B-A3B 从 66.3 上升到 80.6,所有领域都有所提升
Model size scaling leads to better performance
- Scientific Judgement 性能随着模型大小的增加而持续提升
- 此外,SciJUDGE-Qwen3-30B 超越了所有列出的闭源基线,表明扩大模型规模为科学判断带来了显著提升
- 在 Qwen2.5 系列中,经过 SciJUDGE 训练后的平均准确率从 72.1 (1.5B) 增加到 73.2 (3B)、76.9 (7B)、80.6 (14B) 和 83.7 (32B)
- Qwen3 系列也呈现类似趋势,SciJUDGE-Qwen3-30B 的表现优于 SciJUDGE-Qwen3-4B (平均准确率 80.6 vs. 75.3)
Takeaway 1
- Scientific Judgement 学习是可扩展的
- 随着训练数据量的增加,各领域的测试集性能呈对数线性提升
- 随着模型规模的增大,性能也随之提高
- SciJUDGE-Qwen3-30B 超越了所有列出的闭源基线
- 这一结果进一步表明,通过强化学习进行偏好建模是可扩展的
Generalization Results
- 本节主要测试学到的 Scientific Taste 是否能沿三个轴泛化到训练分布之外:时间、领域和评估标准
Temporal generalization to future preferences
- 使用 RLCF 训练显著提升了对未来论文偏好的预测能力
- 在 2025 年发表的论文上,大多数基础模型和领域都取得了一致的提升,平均准确率最高提升了 +55.1 个百分点 (表 4)
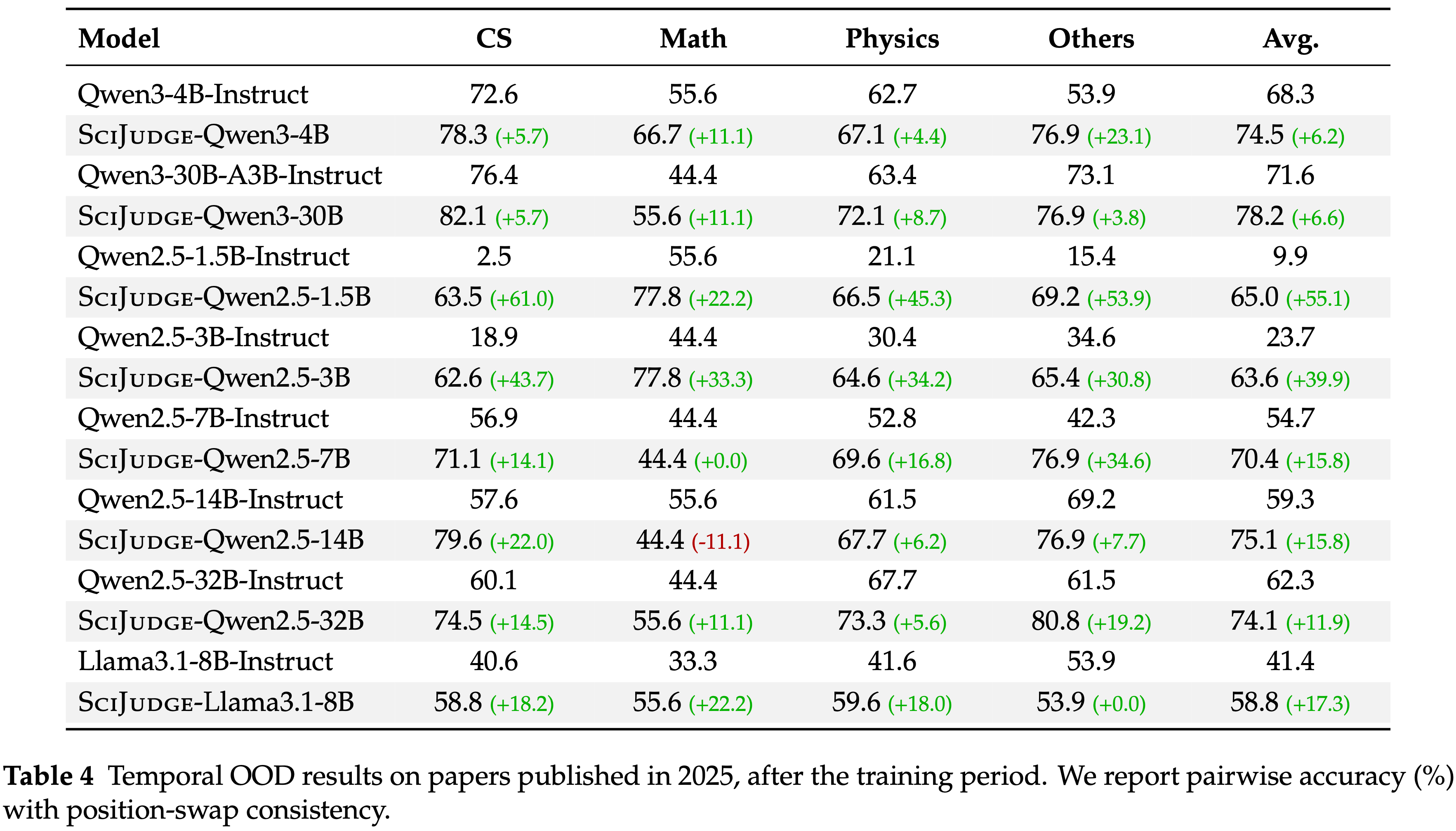
- 这些结果表明,引用数据捕捉到了社区价值的稳定信号,这些信号可以泛化到训练期之后
Generalization to unseen fields
- Scientific Judge 能有效地泛化到未见领域,表明从计算机科学论文中学到的科学判断可以迁移到训练领域分布之外
- 仅在计算机科学数据上训练
- 能持续提升对数学、物理和其他学科的影响力预测,所有基础模型都取得了显著的进步 (表 5)
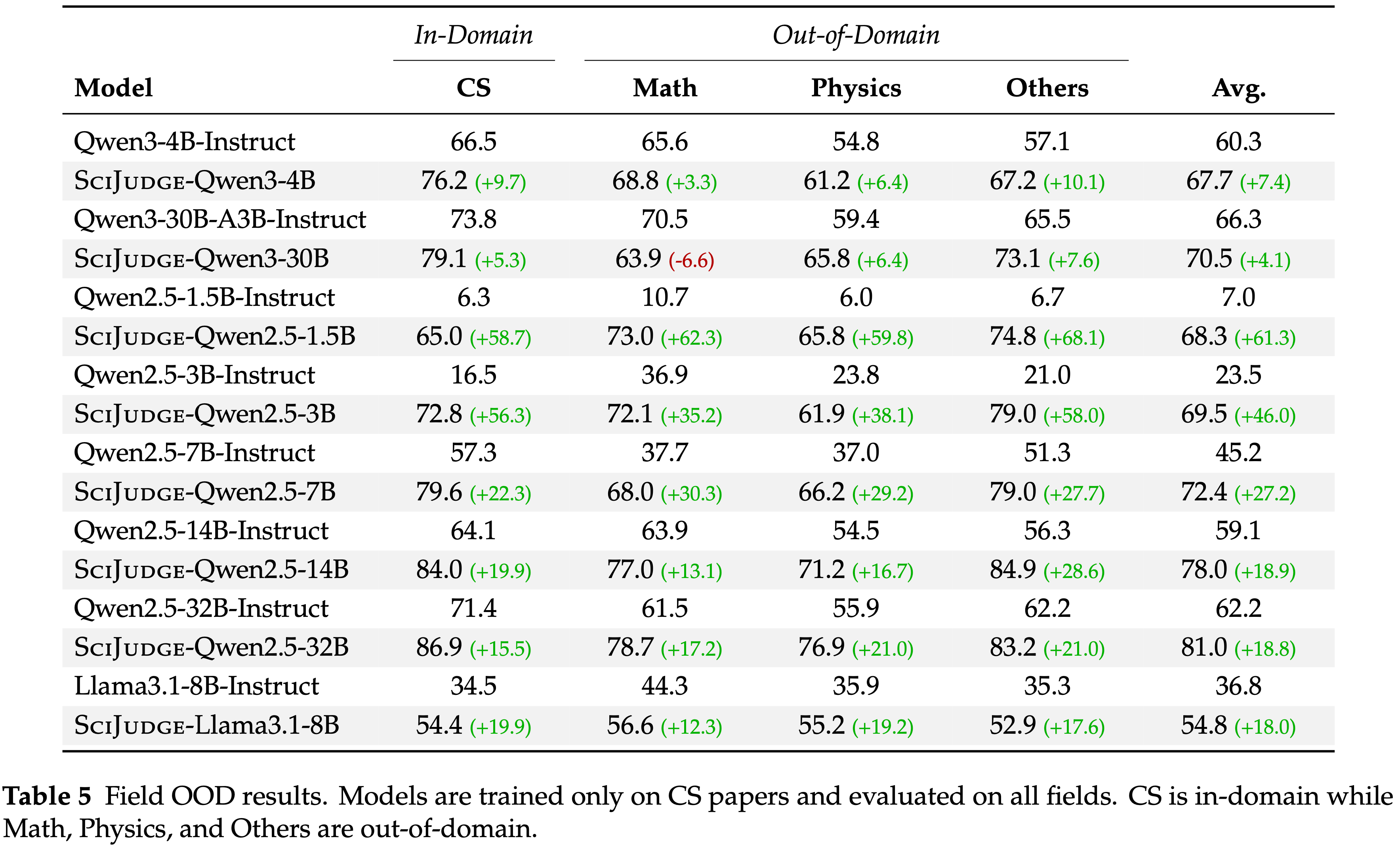
- 能持续提升对数学、物理和其他学科的影响力预测,所有基础模型都取得了显著的进步 (表 5)
- 这种跨领域迁移值得注意,因为不同学科在知识、风格和数据分布上存在很大差异
- 但仍然表现出可以学习和迁移的共享科学价值模式
- 这些结果表明,RLCF 有助于模型获得更可泛化的科学判断,而不仅仅是拟合特定领域的信号
Generalization to peer-review preference
- Scientific Judge (Scientific JUDE) 也显著提升了对同行评审偏好的预测一致性
- 在 ICLR 论文对上,所有基础模型的准确率都持续提升,最高提升了 +72.0 个百分点 (表 6)
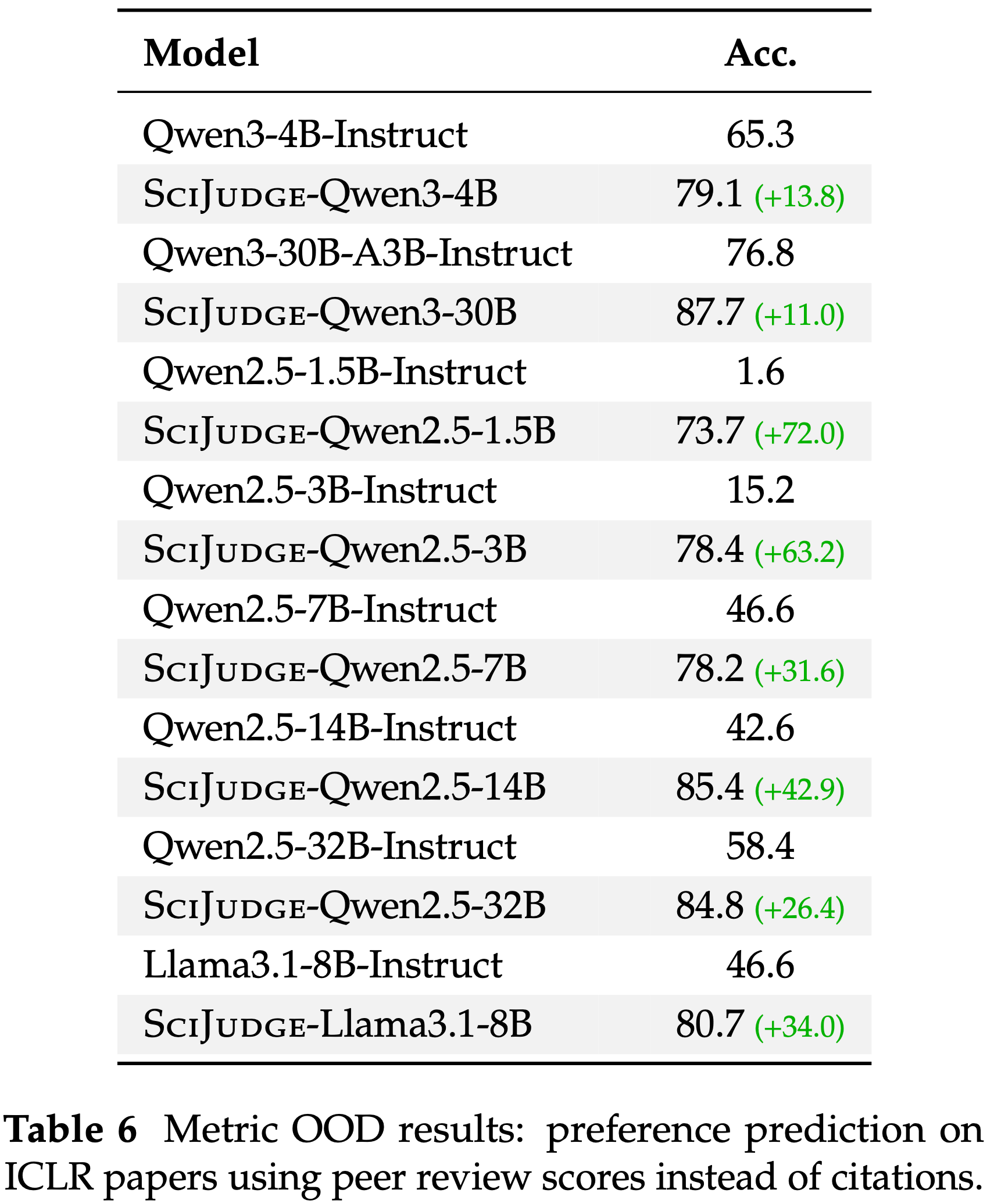
- 这种跨指标迁移表明,基于引用训练的模型捕获了社区偏好模式,这些模式可以扩展到训练期间使用的特定反馈信号之外
Takeaway 2
- 学到的 Scientific Taste 可以以三种方式进行泛化:
- 跨时间到未来的论文、跨领域到训练分布之外、以及跨指标到同行评审分数
- 这表明 Scientific Judge (Scientific JUDE) 从社区反馈中捕获了可迁移的模式,为 AI 可以学习广泛可泛化的 Scientific Taste 提供了证据
AI Can Learn Ideation with High Potential Impact(Experiments 1)
- 本节重点关注使用基于比较的 GRPO (Comparison-Based GRPO) (§3.3) 和 Scientific Judge 作为奖励模型 (§4) 来训练 Scientific Thinker
Experimental Setup
Data
- 使用 2025 年的高被引论文作为种子论文
- 训练集包含 1 月至 7 月发表的 4,000 篇论文
- 评估数据集:
- In-domian:使用同期发表的 200 篇论文作为领域内测试集
- OOD:8 月至 12 月发表的 200 篇论文作为领域外测试集
Models
- 在两个策略模型上训练 Scientific Thinker :Qwen3-30B-A3B-Thinking-2507 和 Qwen3-4B-Thinking-2507
- 两者都使用 SciJUDGE-Qwen3-4B 作为奖励模型
- 将这两个训练后的策略称为 SCI THINKER-30B 和 SCI THINKER-4B
- 为了探索偏好学习的增益,本文还使用 SciJUDGE-Qwen3-4B 的基础模型 (Qwen3-4B-Instruct) 作为奖励模型,训练了每个策略的版本
Evaluation
- 通过 Scientific Thinker 相对于基础策略的胜率来评估它
- 问题:这种评估方式并不严谨,毕竟 Scientific Taste 并不是可以通过模型评估的
- 对于每篇种子论文,两个模型都提出一个 Research Idea ,使用三个模型 (GPT-5.2-high, GLM-5 和 Gemini 3 Pro) 通过多数投票来判断哪个想法具有更高的潜在影响力,详见附录 C.2
- 以相同的方式,也评估了 SCI THINKER-30B 相对于这三个 SOTA 模型的胜率
Results
Substantial improvements in scientific ideation with high potential impact
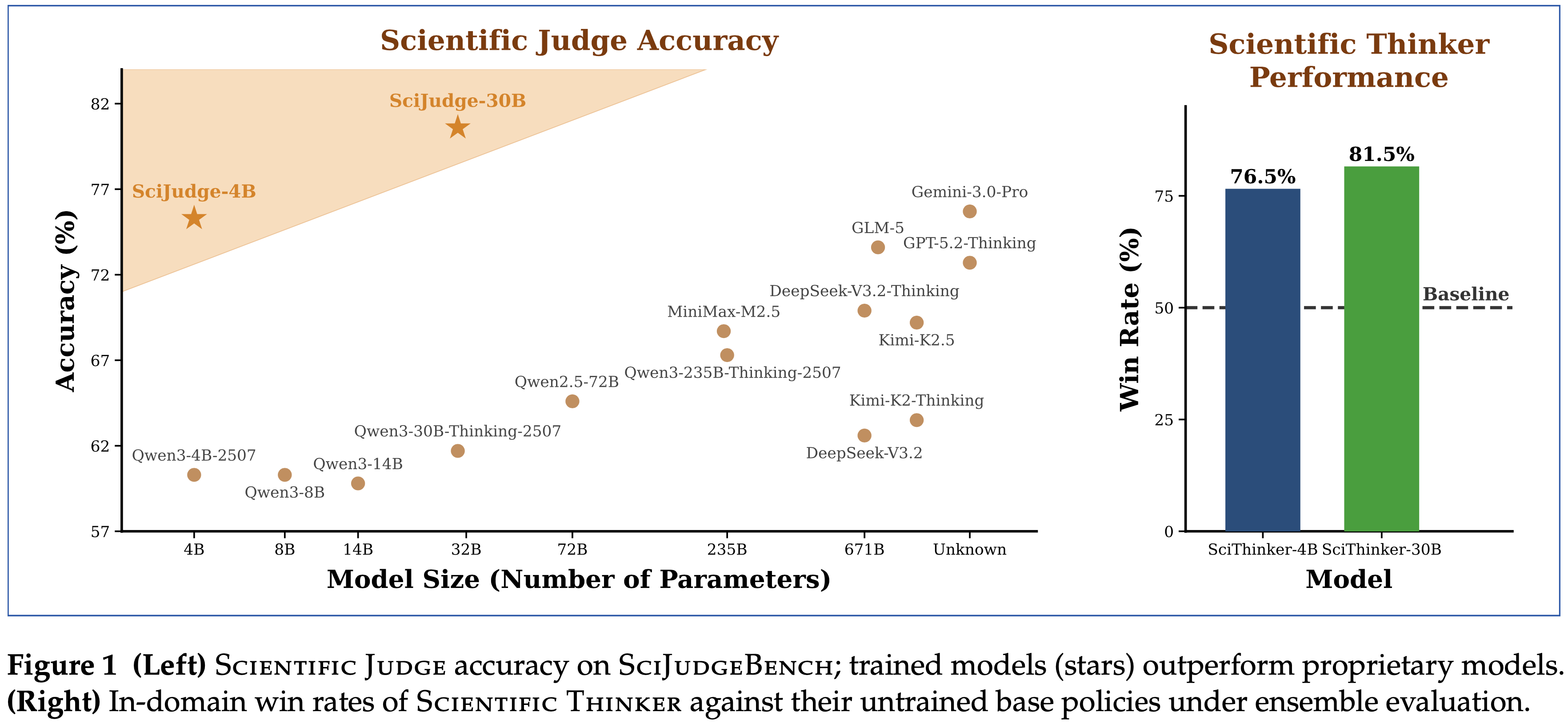
- 如图 4 所示,在使用 SciJUDGE-Qwen3-4B 奖励模型进行训练后, Scientific Thinker 在两个模型规模上都显著优于基础策略,30B 和 4B 模型在领域内分别实现了 81.5% 和 76.5% 的胜率
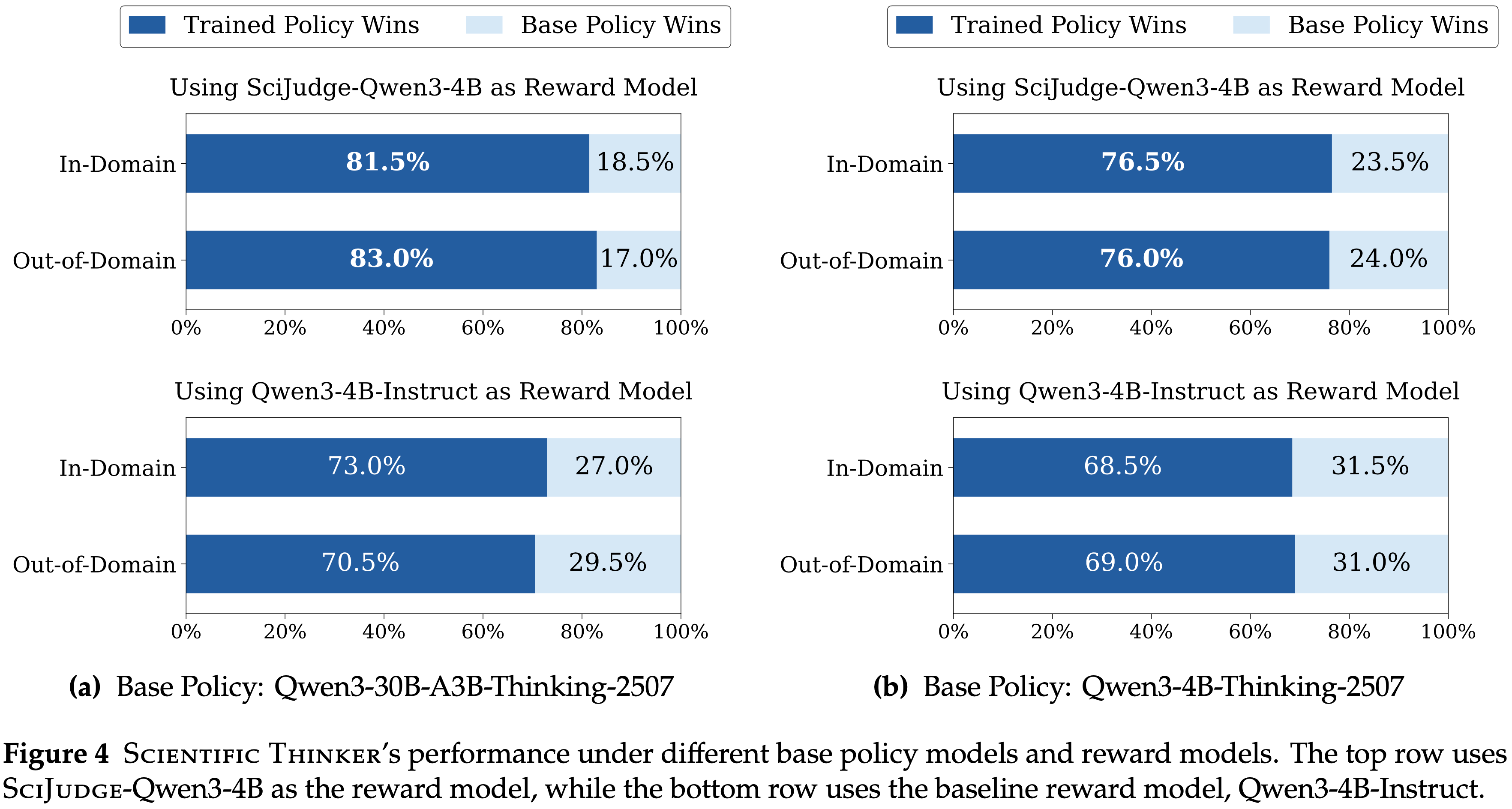
- 值得注意的是,性能提升稳健地泛化到了训练期之后发表的领域外论文 (30B: 83.0%,4B: 76.0%),表明 Scientific Thinker 已经学会了可泛化的构思能力,在“未来”研究主题上表现良好
Scientific Judge is a more effective generative reward model than the baseline,Scientific Judge 是比 Baseline 更有效的 GRM
- 对于两种模型规模,使用 SciJUDGE-Qwen3-4B 训练的策略在领域内 (例如,30B: 81.5% vs. 73.0%) 和领域外 (例如,30B: 83.0% vs. 70.5%) 测试集上都显著优于使用 Qwen3-4B-Instruct 训练的策略 (图 4)
Scientific Thinker is comparable to SOTA models in ideation(构思)
- 经过训练后,SciThinker-30B 超越了 GPT-5.2 和 GLM-5 (表 8),在三个最先进模型上平均胜率达到 54.2%

Takeaway 3
- AI 可以学习高潜在影响力的构思
- 通过强化学习训练, Scientific Thinker 提出的科学想法具有更高的潜在影响力,并能泛化到未来的研究主题
- Scientific Judge 是训练 Scientific Thinker 的有效且可靠的奖励模型
附录 A:Dataset Construction Details
- 本节展示 SciJudgeBench 的构建过程,包括训练数据和测试数据
A.1 Data Statistics
- 不同领域数据集统计见 表 9:
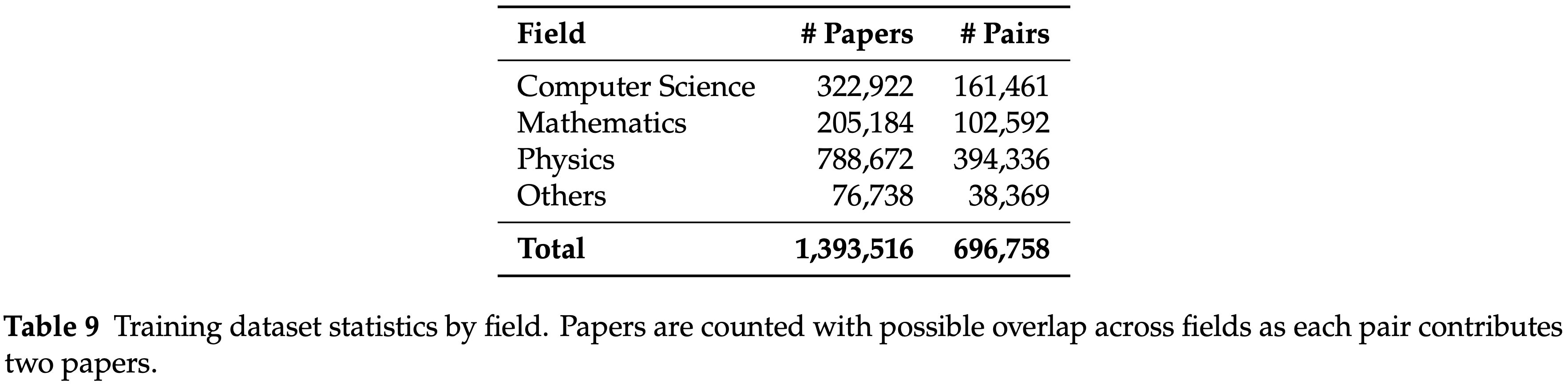
- 理解:
- 可以看出的是,组队时是两两一组,且论文仅参与一次配对,所以 #Paper 是 #Pairs 的双倍
- 表 9 的分类仅 4 类,实际上 arXiv 上类别很多,所以需要进行一下汇总分类(详情见原始论文附录 A)
- Others 是一个明确的聚合类别,涵盖了非计算机科学/数学/物理的领域,具体包括经济学、电气工程与系统科学、定量生物学、定量金融学和统计学,而不是一个剩余的杂项桶
A.2 Training Data Construction
Paper Collection
- 收集了截至 2025 年 12 月 7 日发布的 arXiv 论文
- 从包含 2.9M 篇论文的完整 arXiv 元数据存档中
- 获得了 2.3M 篇论文的引用数
- 训练论文池:
- 选取了截至 2024 年发表的 2.1M 篇论文
- 每条论文记录包括标题、摘要、发表日期、子类别和引用数
- 论文池涵盖了计算机科学、数学、物理和其他科学领域
Pair Generation
- 通过在相同子类别和相近发表时间窗口内匹配论文来生成偏好对
- 对于每一对,引用数较高的论文被标记为 Preferred
- 设 \(c_{\text{hi} }\) 和 \(c_{\text{lo} }\) 分别表示候选对中较高和较低的引用数
- 仅当满足以下条件时,才保留该对:
$$c_{\text{hi} } - c_{\text{lo} }\geq 8,\qquad \frac{c_{\text{hi} } - c_{\text{lo} } }{c_{\text{hi} } }\geq 0.3.$$
- 仅当满足以下条件时,才保留该对:
- 等价地,相对引用差是相对于引用数较高的论文计算的,这些标准对应:
- 绝对引用(Absolute citation)差 \(\geq 8\)
- 相对引用(Relative citation)差 \(\geq 30%\)
- 共产生了 696,758 个跨领域的,且按领域和时间匹配 的训练对,涵盖了 1.4M 篇 Unique 论文
A.3 Test Set Construction
Main Test Set
- Main(in-domain)测试集包含 728 个从与训练数据相同分布中采样的对,但采用了更严格的筛选条件:
- 绝对引用差 \(\geq 32\)
- 相对引用差 \(\geq 50%\),即
$$ \frac{c_{\text{hi} } - c_{\text{lo} }}{c_{\text{hi} }} \geq 0.5 $$ - 注:更严格的阈值确保了评估时偏好信号的清晰性
Temporal OOD Test Set
- 为了评估对未来论文的泛化能力,本文构建了一个时序分布外测试集
- 包含 514 个来自 2025 年发表论文的对,确保与训练数据(截至 2024 年发表)在时间上完全分离
- 由于近期发表的论文引用数远少于旧论文,本文在每个主要子类别 \(s\) 内使用自适应百分位数阈值
- 设 \(q_{s}^{(p)}\) 表示子类别 \(s\) 中(来自至少被引用一次的论文)的第 \(p\) 百分位引用数,设 \(c_{i}\) 为论文 \(i\) 的引用数,\(t_{i}\) 为其发表日期
- 在论文中,定义
$$\delta_{s} = \max \left(12,0.7(q_{s}^{(99)} - q_{s}^{(1)})\right)$$- 理解:这个阈值表示了当前子类中论文之间的分位数差异(不同类别阈值不同,用于后续区分该领域的正负样本差异应该是多少)
- 仅当两篇论文属于同一子类别且满足以下条件时,才创建候选对 \((i,j)\):
$$c_{i}\geq q_{s}^{(75)},\qquad c_{j}\leq q_{s}^{(25)},\qquad |t_{i} - t_{j}|\leq 5\text{ days} \\
c_{i} - c_{j}\geq \max (0.5c_{i},\delta_{s})$$- 理解:做了如下设置以提升 Pair 信号的准确性:
- 发表时间控制到相似(5 天内)
- 仅使用大于 75 分位数的作为正样本,小于 25 分位数的做为负样本
- 绝对引用差大于 \(\delta_s\),相对引用差 0.5 倍的正样本
- 理解:做了如下设置以提升 Pair 信号的准确性:
- 直观上,这会将同一子类别中引用数相对较高的 2025 年论文与引用数相对较低的同期论文配对,同时强制实施相对边际和子类别自适应的绝对边际
- 由此产生的类别分布(计算机科学:318对,物理:161对,其他:26对,数学:9对)反映了具有足够引用数的最新论文的自然可用性
ICLR Test Set (Metric OOD)
- 度量分布外的论文:Metric OOD
- ICLR 测试集用于评估从基于引用的训练到同行评议分数预测的迁移能力,使用了 2017 至 2026 年的 ICLR 投稿
- 每年应用两个质量过滤器:
- 剔除平均审稿人信心在后 \(50%\) 的论文
- 剔除评分方差在前 \(50%\) 的论文
- 仅保留每年平均评审评分在前 \(10%\) 和后 \(10%\) 的论文(每侧最多 75 篇)
- 将保留的论文按评分排序,在中位数处分成上半部分和下半部分,在每个半部分内随机打乱,然后将两半部分的论文一一配对
- 问题:这里需要保证匹配的 Pair 的年份一致吗?
- 在每一对中,来自上半部分的论文被标记为 Preferred
- 将保留的论文按评分排序,在中位数处分成上半部分和下半部分,在每个半部分内随机打乱,然后将两半部分的论文一一配对
- 产生了 611 个测试对,其中位评分差为 6.1 分(评分范围为 1-10 分)
- 注:
- 评估提示词询问的是:“哪篇论文更有可能被接收(which paper is more likely to be accepted)”
- 不同于训练提示词:“哪篇论文有更高的引用数(which paper has a higher citation count)”
- 这意味着度量分布外设置同时测试了不同的监督信号和不同的任务框架
A.4 Field OOD Training Data
- 对于领域分布外实验,通过将完整训练数据过滤到仅包含计算机科学论文,构建了一个仅限计算机科学的训练集
- 这使的本文能够评估在单一领域训练的模型是否能泛化到其他领域
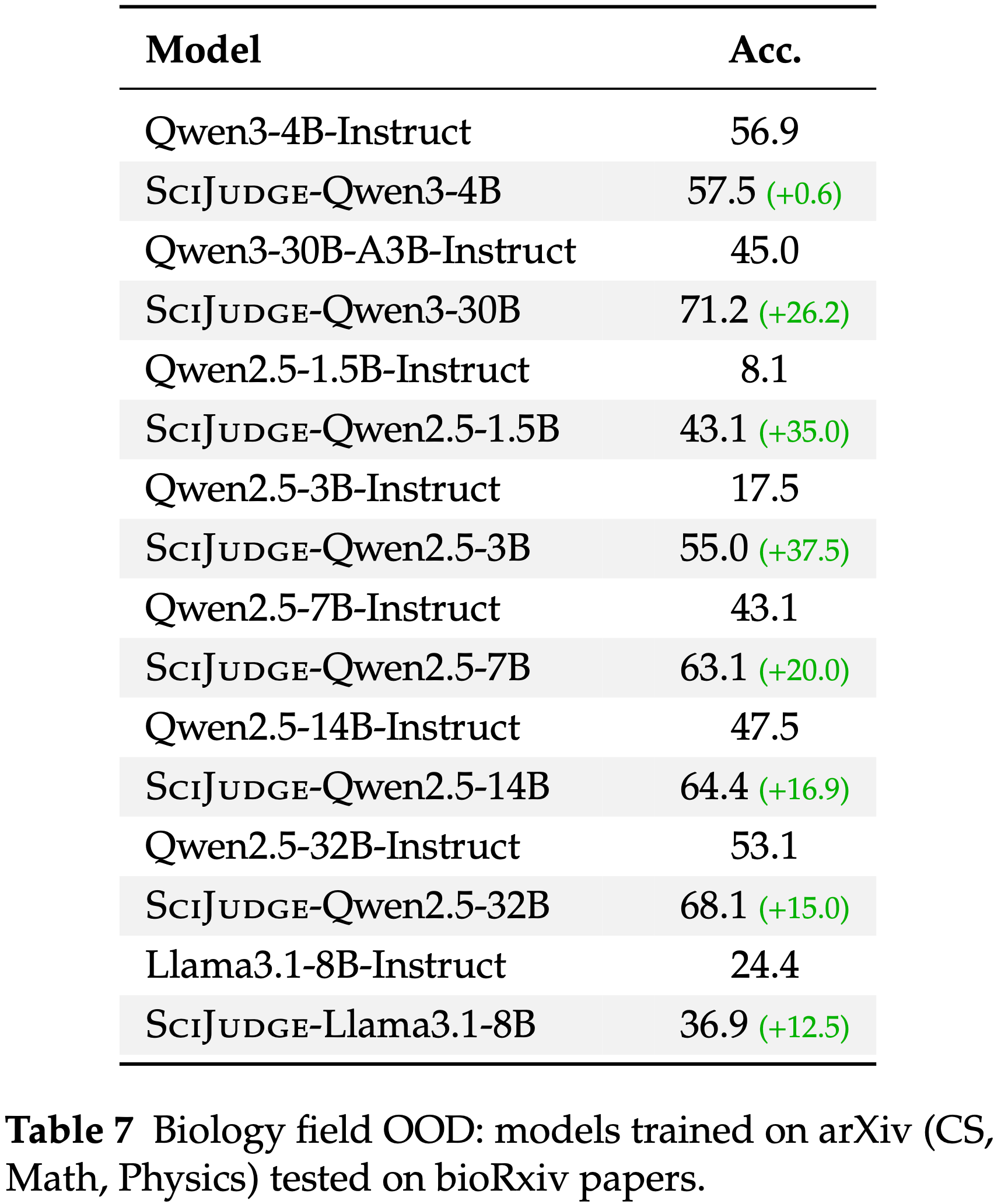
A.5 Biology Field OOD (bioRxiv)
- 为了进一步探究跨领域迁移,在 bioRxiv 论文(生物学领域)上评估了在 arXiv 论文(涵盖计算机科学、数学、物理和其他领域)上训练的模型
- 这是一个在训练数据中完全未出现的平台和领域
- 使用相同的基于引用的配对程序,从 bioRxiv 论文中构建了 160 个偏好对,阈值设为绝对引用差 \(\geq 24\) 和相对差 \(\geq 75%\)(中位引用差 = 134)
- 论文涵盖生物学子学科(例如,生物信息学、基因组学、神经科学),并在同一子学科内进行配对
- 结果见正文表 7
附录 B:Training Details of Scientific Judge
B.1 Base Models
- 在多个开源的指令微调语言模型上训练 Scientific Judge
- (1)通过包含 Qwen2.5-Instruct 系列(从 1.5B 到 32B 参数)来评估模型尺寸的扩展行为
- (2)通过整合不同系列的模型(Qwen2.5、Qwen3 和 Llama)来评估跨系列的泛化能力
Qwen2.5-Instruct Series
- 使用了 Qwen2.5-Instruct 系列的多个规模:1.5B、3B、7B、14B 和 32B 参数
- 这些模型是 Qwen2.5 的指令微调版本,Qwen2.5 是一个多语言数据上训练的 LM
- Qwen2.5 系列在推理、数学和代码生成任务上展现出强大的性能,同时通过 GQA 等技术保持了效率
Qwen3-Instruct Series
- 包含了来自 Qwen3 系列的两个指令微调模型:Qwen3-4B-Instruct-2507 和 Qwen3-30B-A3B-Instruct-2507
- 这些模型将评估扩展到 Qwen2.5 系列之外,并允许作者测试偏好训练方法是否能迁移到不同规模的新模型系列
Llama-3.1-8B-Instruct
- Llama-3.1-8B-Instruct 是 Meta 的 80 亿参数指令微调模型
- 具有 128K 个词元的扩展上下文长度,并在多样化多语言语料库上进行了训练
- 包含此模型以评估偏好训练方法在跨系列上的泛化能力
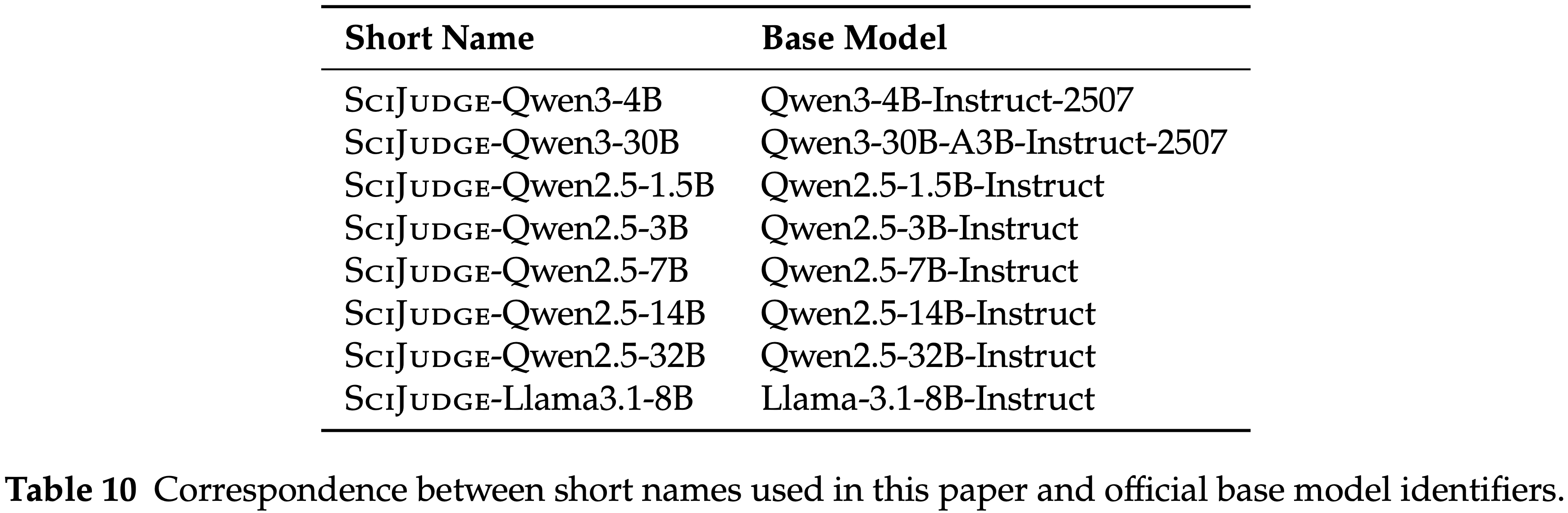
Model Naming Convention
- 表 10 列出了本文中使用的简称与官方基座模型标识符的对应关系
- 所有 Scientific Judge 变体都是从相应的基座模型使用 GRPO 在 SciJudgeBench 上训练而来
B.2 Hyperparameters
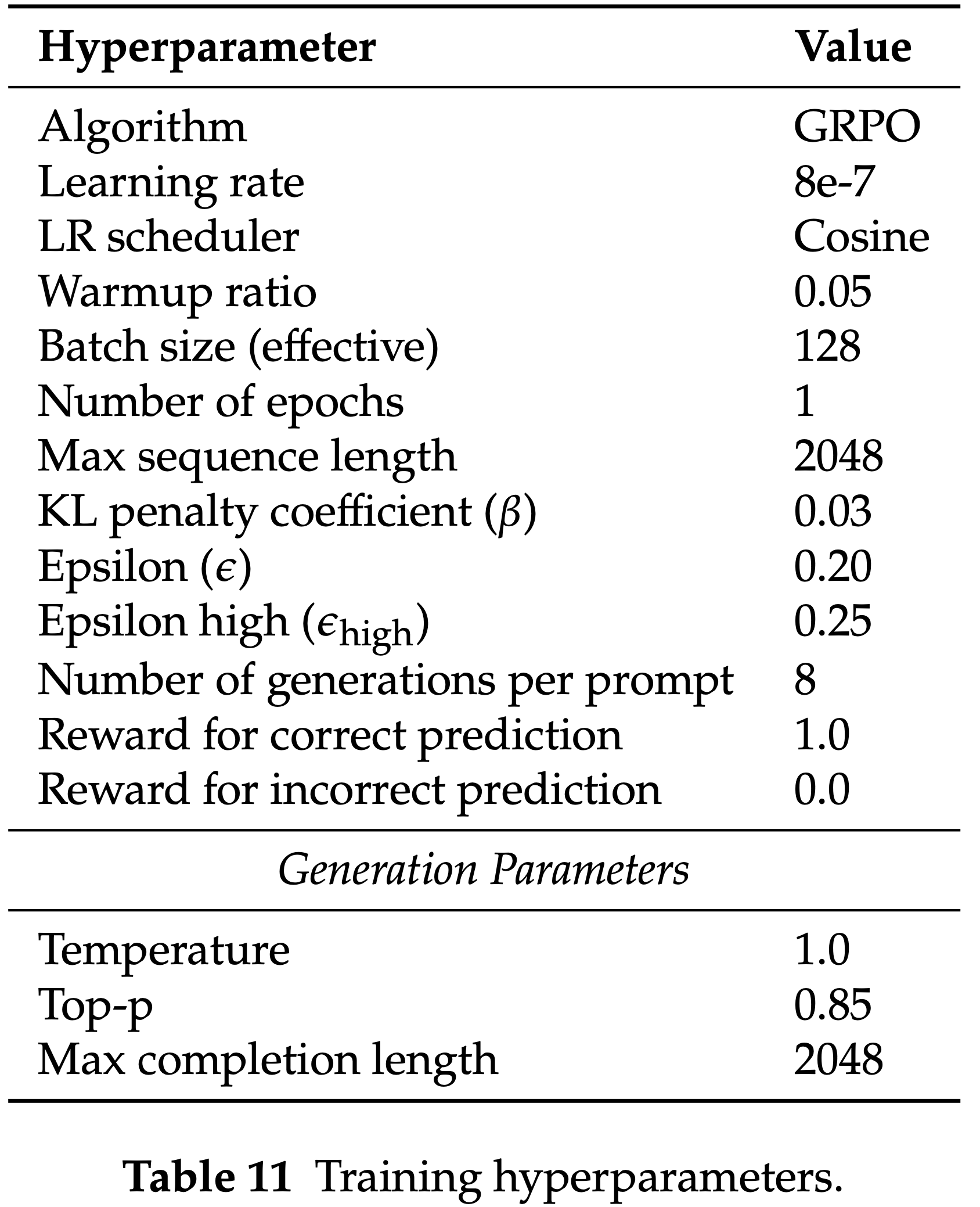
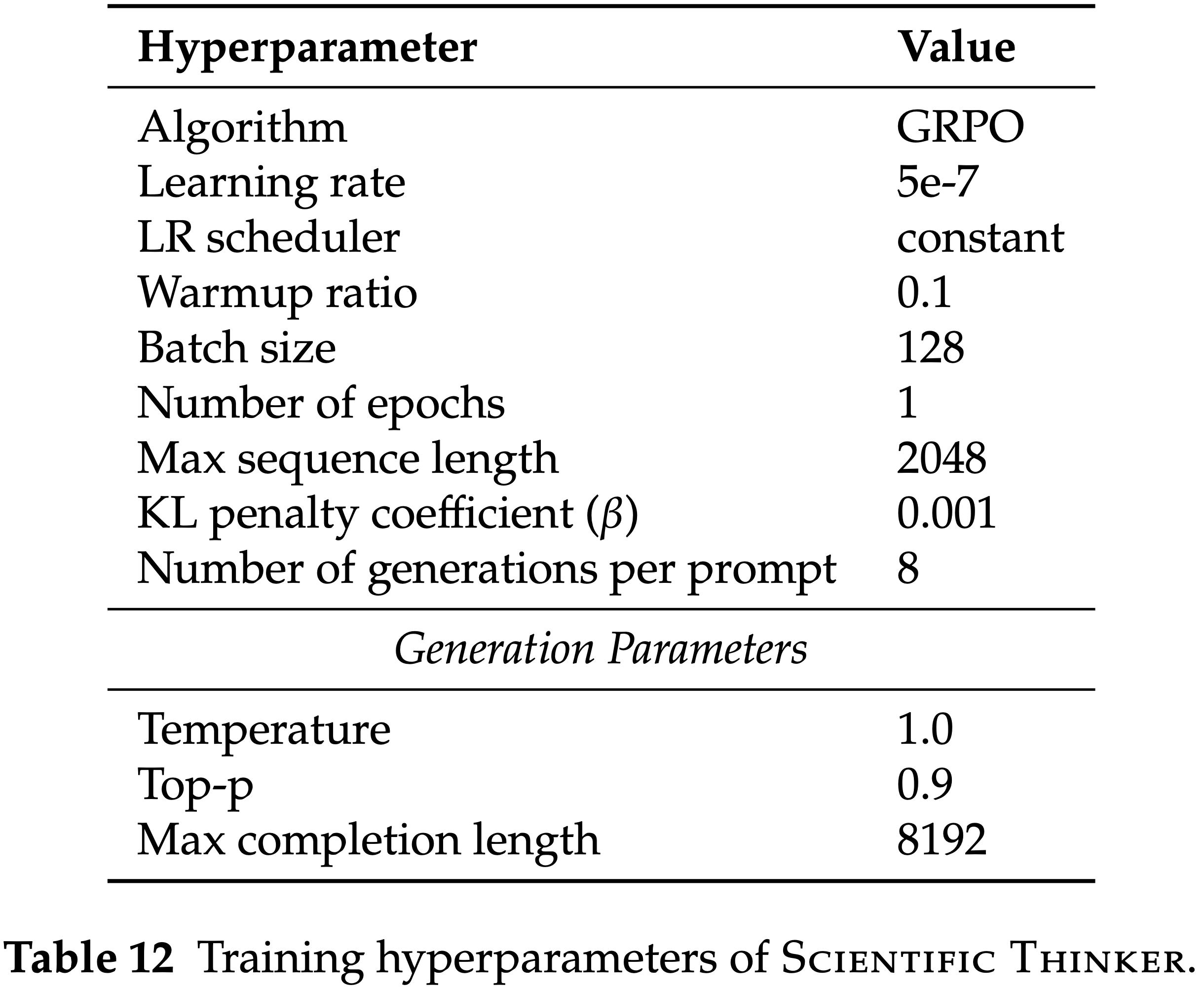
- 使用 MS-SWIFT 框架 (2024) 实现 Scientific Judge(进行 GRPO 训练)
- 表 11 列出了训练所用的超参数
B.3 Computational Resources
- 所有实验均使用 H200 等效 GPU 资源进行,并采用 DeepSpeed ZeRO-2/ZeRO-3 优化和 vLLM 进行高效推理
- 根据模型大小扩展 GPU 数量:
- 1.5B 模型:32 块 GPU(4 节点 × 8 块 GPU)
- 3B-7B 模型:64 块 GPU(8 节点 × 8 块 GPU)
- 14B 及更大模型:128 块 GPU(16 节点 × 8 块 GPU)
B.4 Prompt Template
- 用于偏好预测的 Prompt 模板如下所示:
- Preference Prediction Prompt
1
2
3
4
5
6
7**System**: You are a helpful assistant. You first think about the reasoning process in your mind and then provide the user with the answer.
**User**: Today is 2025-12-10. Based on the titles, abstracts, and publication dates of the following two papers A and B, determine which paper has a higher citation count.
Show your reasoning process in <think> </think> tags. And return the final answer in <answer> </answer> tags. The final answer should contain only the letter A or B.
Paper A (Published: [Publication Date A]):
[Title and Abstract of Paper A]
Paper B (Published: [Publication Date B]):
[Title and Abstract of Paper B]
B.5 Evaluation Protocol
- 为了减轻位置偏差(Position Bias)
- Position Bias: LLM 在成对评估中倾向于偏向首先出现的选项
- 本文对每个对进行两次评估,方法是交换论文的顺序(A 与 B)
- 只有当模型在两种顺序下都做出了一致且正确的预测时,该预测才计为 1 分
- 这种位置交换一致性(position-swap consistency)指标使评估成本翻倍,但提供了更可靠的评估:
- 确保报告的准确性反映了真实的偏好理解,而不是位置上的捷径
附录 C:Training Details of Scientific Thinker
C.1 Prompt Template
用于基于种子论文提出后续 Research Idea 的 Prompt 模板如下所示
Prompt for proposing follow-up research ideas
1
2
3
4
5
6
7
8**System**: You are a helpful assistant. You first think about the reasoning process in your mind and then provide the user with the answer.
**User**: You are a knowledgeable and insightful researcher. You have come across a new research paper with the following title and abstract:
[Title and Abstract of the Seed Paper]
Based on the core ideas, methods, or findings of this work, engage in heuristic thinking and propose a follow-up research idea. You need not confine yourself to the specific scenario or task of the original paper. You may consider shortcomings of the original method, propose improvements, apply its ideas to other tasks or domains, or even introduce entirely new problems and approaches. Aim to formulate an idea with high academic value and potential impact.
In your response, solely present your proposed title and abstract. Think independently and there is no need to imitate the format of the provided paper’s title and abstract, nor to intentionally cite it. You must ensure the abstract is of a moderate length, avoiding excessive length, as if you were writing it for a typical academic paper.
Output format (strict, no extra text):
Title: <your proposed paper title>
Abstract: <your proposed abstract>用于评判两个 Research Idea 的 Prompt 如下所示,该 Prompt 有两个用途:
- (1)在 Scientific Thinker 训练期间,由奖励模型用来比较生成的想法
- (2)在评估期间,由三个强大的 LLM 用来评判哪个想法具有更高的潜在影响力
- 与 Scientific Judge 用于评判两篇论文(附录 B.4)且包含发表日期的 Prompt 相比,此 Prompt 不包含具体日期,并明确假设两个想法是同时提出的
Prompt for Judging Model’s Research Ideas
1
2
3
4
5
6
7**System**: You are a helpful assistant. You first think about the reasoning process in your mind and then provide the user with the answer.
**User**: Based on the titles and abstracts of the following two papers A and B, determine which paper has a higher citation count. Suppose the two papers are published at the same time.
Show your reasoning process in <think> </think> tags. And return the final answer in <answer> </answer> tags. The final answer should contain only the letter A or B.
Paper A:
[Title and Abstract of Research Idea A]
Paper B:
[Title and Abstract of Research Idea B]
C.2 Evaluation Protocol
- 每对 Research Idea 由三个 LLM(GPT-5.2-high, GLM-5 和 Gemini 3 Pro)进行评估,温度设置为 0.0
- 采用多数投票(即获得至少两票的想法被视为胜出)
- Prompt 如附录 C.1 所示
- 在每次评估者进行评估之前,本文会以 \(50%\) 的概率随机交换两个想法(A 和 B)在 Prompt 中的顺序,以减轻潜在的位置偏差
- 问题:为什么不两种排序都评估一遍?以确保准确性
- 在 SciJudgeBench 上评估了上述多数投票方法,准确率达到 \(84.4%\)
- 这一高准确率表明,这种多数投票方法构成了一个合理的评估指标,可用于评估 Scientific Thinker
- 理解:84.4% 其实也不是很高,且 SciJudgeBench 的 Pair 过于严格,说明即使是 SOTA LLM,模型对这种 Scientific Taste 的认知也是不太足够的
C.3 Hyperparameters
- 表 12 列出了训练 SciThinker-30B 和 SciThinker-4B 所用的超参数
附录 D:General Capability Preservation
- 本节关注一个关键的问题:专门的训练是否会损害通用能力
- 本文在五个标准基准上评估了 Scientific Judge:
- MMLU-Pro(通用知识)
- GPQA(研究生级别科学)
- MATH(数学推理)
- GSM8K(小学数学)
- SimpleQA(事实准确性)
- 表 13 显示,Scientific Judge 在大多数基准测试中保持了性能,变化通常在基线的 \(\pm 3%\) 以内
- 仅针对研究论文偏好任务进行了训练后,模型在通用知识方面表现出最小的退化
- Qwen2.5-3B 在 MATH \((+0.8%)\) 和 GPQA \((+3.1%)\) 上显示出轻微改进
- Qwen3-4B 在 MATH (\(78.6% \rightarrow 78.8%\)) 和 GSM8K (\(93.3% \rightarrow 93.6%\)) 上表现几乎相同
- 跨 MMLU-Pro、MATH、GSM8K 和 SimpleQA 的变化幅度很小,这表明可以在不损害通用能力的情况下进行有针对性的偏好训练
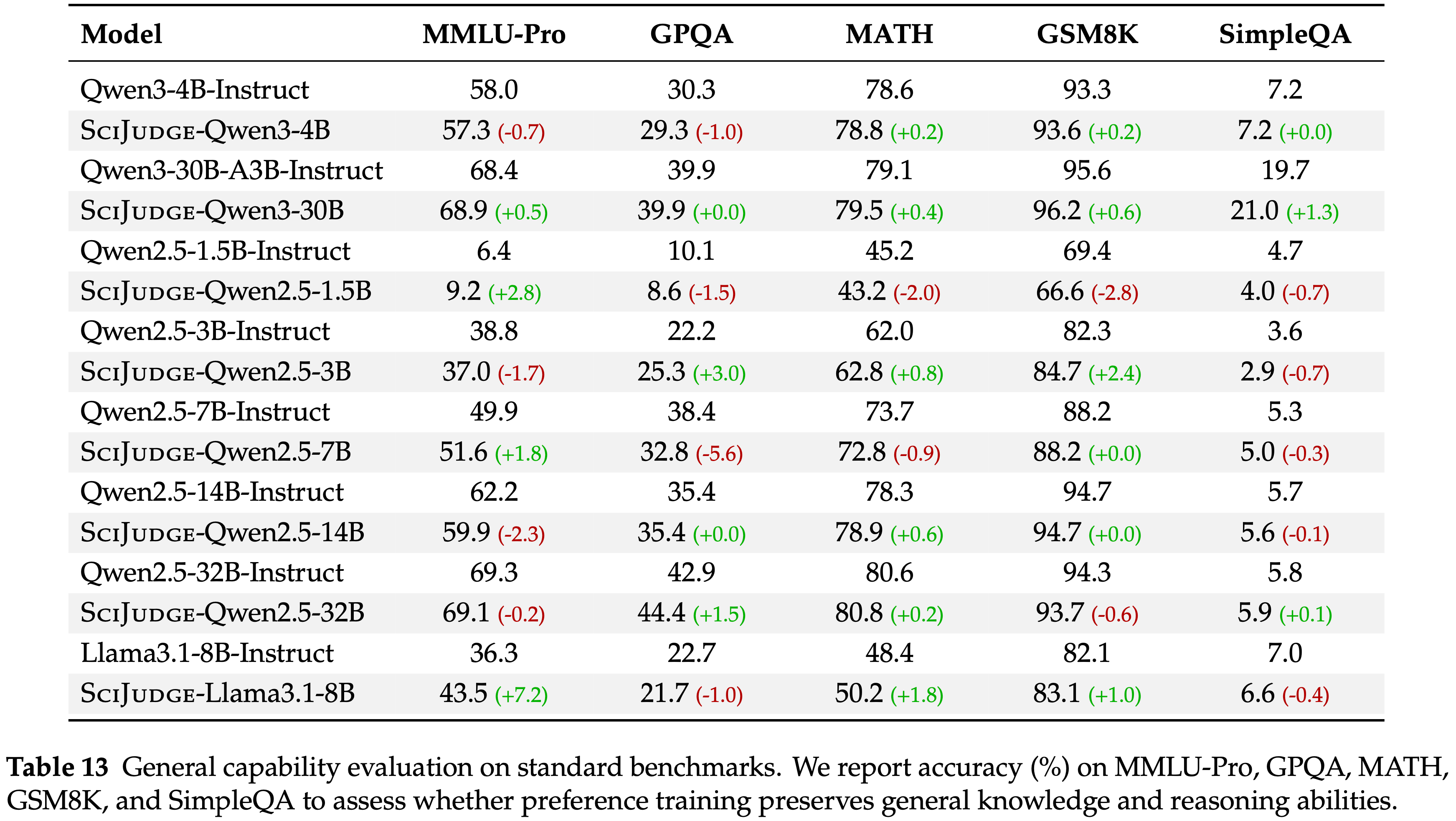
- 仅针对研究论文偏好任务进行了训练后,模型在通用知识方面表现出最小的退化
附录 E:Case Study of Scientific Thinker
- 详细示例见原论文
附录 F:Case Study of Scientific Judge
- 详细示例见原论文
附录 G:Pairwise Comparison of Divergent Impact Series,发散 Impact Series 的 Pairwise 比较
- 本文对潜在影响力的定义中(第 2.1 节),累积期望影响力
$$ I(p) = \lim_{N\to \infty}\sum_{t = 1}^{N}\mathbb{E}[c_{t}(p)]$$- 对于某些论文可能是发散的
- 问题:在当前时间有限,每年的引用数有限的情况下,不可能存在发散的情况吧?
- 本节推导表明:即使两个单独序列都发散,两篇论文的成对比较仍然是定义良好的
- 对于某些论文可能是发散的
- 详细证明见原论文