注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 背景:OPD 容易出现不稳定性和负迁移 (instability and negative transfer)
- 本文通过数学推导,证明了 OPD 在理论上等价于策略优化
- 因此也继承了基本的优化不稳定性
- REOPOLD 结合了多个创新思路解决 vanilla distillation 的基本不稳定性(将 vanilla on-policy distillation 的简单模仿替换为更灵活、更稳定的训练)
- 改进1: 针对 Advantage 进行 stop-gradient(原始的 OPD 这里是有梯度的,有梯度时目标才是最小化 KL 散度)
- 改进2:mixture-based reward clipping
- 效果提升似乎有限?详情本文见 5.3.3 节的分析和 表 6
- 改进3:entropy-based token-level dynamic sampling
- 可加速训练,相当于提升学习率
- 理解:提升学习率也能拿到类似效果
- 改进4:unified exploration-to-refinement
- 两阶段的训练方式比较麻烦,是否需要这样搞有待思考
;reward clipping(2);token-level dynamic sampling(3);多阶段训练(4)")
- 两阶段的训练方式比较麻烦,是否需要这样搞有待思考
Introduction and Discussion
- vanilla OPD 存在不稳定性问题 (2023; 2024)
- 经常导致负迁移,即学生模型的表现相比其初始化的基础模型有所下降(第 5.1 节和图 7),并且遭遇熵迅速崩溃 (entropy collapse) 导致过早收敛(第 3.2 节和图 5)
- 经常导致负迁移,即学生模型的表现相比其初始化的基础模型有所下降(第 5.1 节和图 7),并且遭遇熵迅速崩溃 (entropy collapse) 导致过早收敛(第 3.2 节和图 5)
- 近期的文献 (2025) 中也提到了类似的局限性,该文献为了确保稳定性,限制教师模型必须与学生的规模匹配(例如,为 8B 的学生使用 8B 的教师,而非 32B)
- 问题:这些限制从根本上制约了当前蒸馏方法的实用性
- 本文通过 RL 的视角分析 OPD ,以诊断优化不稳定性
- 通过将教师-学生对数似然比解释为一个固定的奖励,作者将蒸馏视为策略优化,利用现代 RL 的见解来稳定训练
- 本文贡献:
- Diagnosing on-policy distillation :
- 本文证明,stop-gradient 使得目标函数等效于标准策略梯度,起到控制变量的作用,以减轻方差并建立一个稳健的基线
- 基于这个点,能够诊断 OPD 瓶颈,将 heavy-tailed 负奖励 (heavy-tailed negative rewards) 和信号低效 (signal inefficiencies) 识别为不稳定的主要原因
- Distillation-aware policy optimization :
- 为解决优化瓶颈,本文提出了 REOPOLD,它过滤掉有害的蒸馏信号,并通过温和且有选择地应用来自教师的学习信号来缓和激进的更新(图 2)

- 为解决优化瓶颈,本文提出了 REOPOLD,它过滤掉有害的蒸馏信号,并通过温和且有选择地应用来自教师的学习信号来缓和激进的更新(图 2)
- Diagnosing on-policy distillation :
Background and Related Work
Reinforcement Learning for Reasoning Models
- 策略优化通常依赖于由采样策略(例如,旧策略 \(\pi_{\theta_{\text{old} } }\))生成的样本
- 给定一个从数据集 \(\mathcal{Q}\) 中抽取的 Query \(q\),从 \(\pi_{\theta_{\text{old} } }\) 中采样一组 \(G\) 个 Response \(\{o_i\}_{i = 1}^G\),然后通过最大化以下目标来更新策略参数 \(\theta\):
$$
\begin{align}
\mathcal{J}_{\text{RL} }(\theta) = \mathbb{E}_{q\sim \mathcal{Q},\{o_i\}_{i = 1}^G\sim \pi_{\theta_{\text{old} } }(\cdot |q)} \left[\frac{1}{\sum_{i = 1}^G}\frac{G}{\left|o_i\right|}\sum_{i = 1}^G\sum_{t = 1}^G\rho_{i,t}(\theta)\hat{A}_{i,t}\right], \end{align} \tag {1}$$ - 其中
- \(\rho_{i,t}(\theta)\) 表示 Response \(o_i\) 在 Token 步 \(t\) 的重要性采样比率
$$\rho_{i,t}(\theta) = \frac{\pi_{\theta(o_{i,t}|q,o_{i,t}< t)} }{\pi_{\theta_{\text{old} }(o_{i,t}|q,o_{i,t}< t)} }$$ - \(\hat{A}_{i,t}\) 表示估计的 advantage
- 注:这里省略了一些裁剪操作
- \(\rho_{i,t}(\theta)\) 表示 Response \(o_i\) 在 Token 步 \(t\) 的重要性采样比率
On-Policy Distillation for Reasoning Models
- LLM 的蒸馏大致分为 off-policy 和 on-policy Settings
- off-policy Setting(如 SFT)中,学生模型从静态的教师生成输出中学习,这可能导致曝光偏差 (exposure bias) (2024)
- on-policy Setting (如 OPD) 中,通过训练从学生策略自身采样的轨迹来缓解曝光偏差问题
- OPD 过程最小化 RKL,这等价于最大化对数似然比的期望:
$$\mathbb{D}_{\text{KL} }(\pi_{\theta}| \pi_{T}) = -\mathbb{E}_{q\sim \mathcal{Q},\sigma \sim \pi_{\theta}(\cdot |q)}\left[\log \frac{\pi_{T}(o|q)}{\pi_{\theta}(o|q)}\right] \tag {2}$$- \(\pi_{T}\) 表示教师策略
- 已有工作表明, OPD 能有效弥合训练-测试差异,从而提高生成质量 (2024; 2024)
Analysis of On-Policy Distillation
Theoretical Equivalence to RL and Strong Baseline,与 RL 的理论等价性及强基线
- 本文建立 OPD 和 RL 之间的关系:遵循 (2025; 2025),结合公式 (1) 和公式 (2) 来公式化 OPD 的目标:
$$\begin{align}
\mathcal{R}_{\text{RL} }(\theta) = \mathbb{E}_{q\sim \mathcal{Q},\{o_i\}_{i = 1}^G\sim \pi_{\theta_{\text{old} }(\cdot |q)} } \left[\frac{1}{\sum_{i = 1}^G|o_i|}\sum_{i = 1}^G\sum_{t = 1}^{|o_i|}\rho_{i,t}(\theta)R_{i,t}(\theta)\right]
\end{align} \tag {3}$$- \(R_{i,t}(\theta)\) 表示 Token-level 对数似然比:
$$ R_{i,t}(\theta) = \log \frac{\pi_{T}(o_{i,t}|q,o_{i,t}< t)}{\pi_{\theta}(o_{i,t}|q,o_{i,t}< t)} $$ - 与在整个词汇表上计算差异的传统蒸馏 (2024; 2024) 不同,这种方法对采样到的 Token 进行操作,避免了存储完整分布所带来的过高内存成本,如附录 D 所示
- \(R_{i,t}(\theta)\) 表示 Token-level 对数似然比:
- 与奖励固定的标准 RL 不同,项 \(R_{i,t}(\theta)\) 本身依赖于 \(\theta\)
- 虽然像 MiniLLM (2024) 这样的先前工作已经探索了这一联系,但本文明确采用固定奖励的视角来稳定优化
- 本文使用一个 Stop Gradient 算子将 \(R_{i,t}(\theta)\) 视为一个恒定的外部信号
- 理解:原始的 OPD 中并没有强调需要对 Advantages 做 Stop Gradient,所以本质是带着梯度的(真实的目标是最小化 KL 散度,本身也是带着梯度的)
- 本文的含义是:将 OPD 中的 Advantage 变成 Stop Gradient 的,才能完全等价于朴素 RL 下的策略梯度方法
- 让 \(\mathcal{J}_{\text{RKL} }^{\text{(sg)} }\) 表示这个带 Stop Gradient 的目标,那么,以下 Remark 3.1 性质成立
Remark 3.1
- 在标准正则性条件下,\(\mathcal{J}_{\text{RKL} }(\theta)\) 和 \(\mathcal{J}_{\text{RKL} }^{\text{(sg)} }\) 的期望梯度是一致的:
$$\begin{align}
\nabla_{\theta}\mathcal{J}_{\text{RKL} }(\theta) = \nabla_{\theta}\mathcal{J}_{\text{RKL} }^{\text{(sg)} }(\theta) = \mathbb{E}_{q\sim \mathcal{Q},\{o_i\}_{i = 1}^G\sim \pi_{\theta_{\text{old} }(\cdot |q)} } {\left[\frac{1}{\sum_{i = 1}^G|o_i|}\sum_{i = 1}^G\sum_{t = 1}^{|o_i|}\rho_{i,t}(\theta)R_{i,t}(\theta)\nabla \log \pi_{\theta}(o_t|q,o_{< t})\right],} \end{align} \tag {4}$$- 完整的证明在附录 A.1 中提供,显示来自奖励项的梯度贡献在期望中消失
- 这确立了 OPD 在形式上等价于一个 on-policy 的策略梯度方法,其中奖励由 \(R_{i,t}(\theta)\) 定义
- Remark 3.1 确保了期望中的理论一致性,但在随机优化的有限样本情况下,动态是不同的
- 关键:被省略的项 \(\nabla_{\theta}R_{i,t}(\theta)\) 具有零期望但非零方差
- 通过移除这一项, Stop Gradient 算子有效地充当了一个控制变量,压制了梯度估计中的高方差噪声
- 理解:从观察看来,还是存在一些梯度 spike 现象,且 Gradient Norm 明显降低了,是因为屏蔽了一条路径上的整体梯度
- 问题:这种 Stop Gradient 的方式下,最终优化目标已经不再是最小化 Teacher 和 Student 的 KL 散度
- 实验观察:这带来了梯度范数的降低,意味着方差减小 (2004; 2018),并产生了稳定的训练动态,从而带来更好的验证性能,如图 3(以及表 6)所示
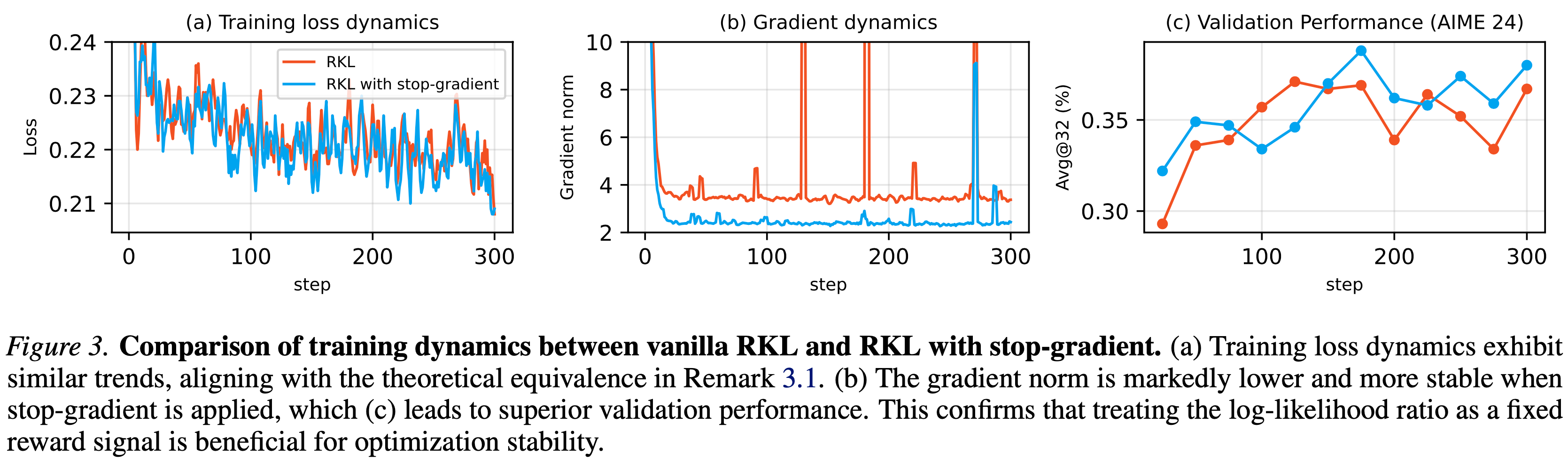
- 通过移除这一项, Stop Gradient 算子有效地充当了一个控制变量,压制了梯度估计中的高方差噪声
- 关键:被省略的项 \(\nabla_{\theta}R_{i,t}(\theta)\) 具有零期望但非零方差
Optimization Challenges in On-policy Distillation,OPD 中的优化挑战
- 带 Stop Gradient 的公式化通过稳定训练动态建立了一个强基线
- 问题: OPD 继承了策略梯度方法所特有的基本挑战
- 通过透过策略梯度的视角来审视蒸馏,本文作者整理出三个阻碍性能的关键问题
Instability from heavy-tailed negative rewards,来自 heavy-tailed 负奖励的不稳定性
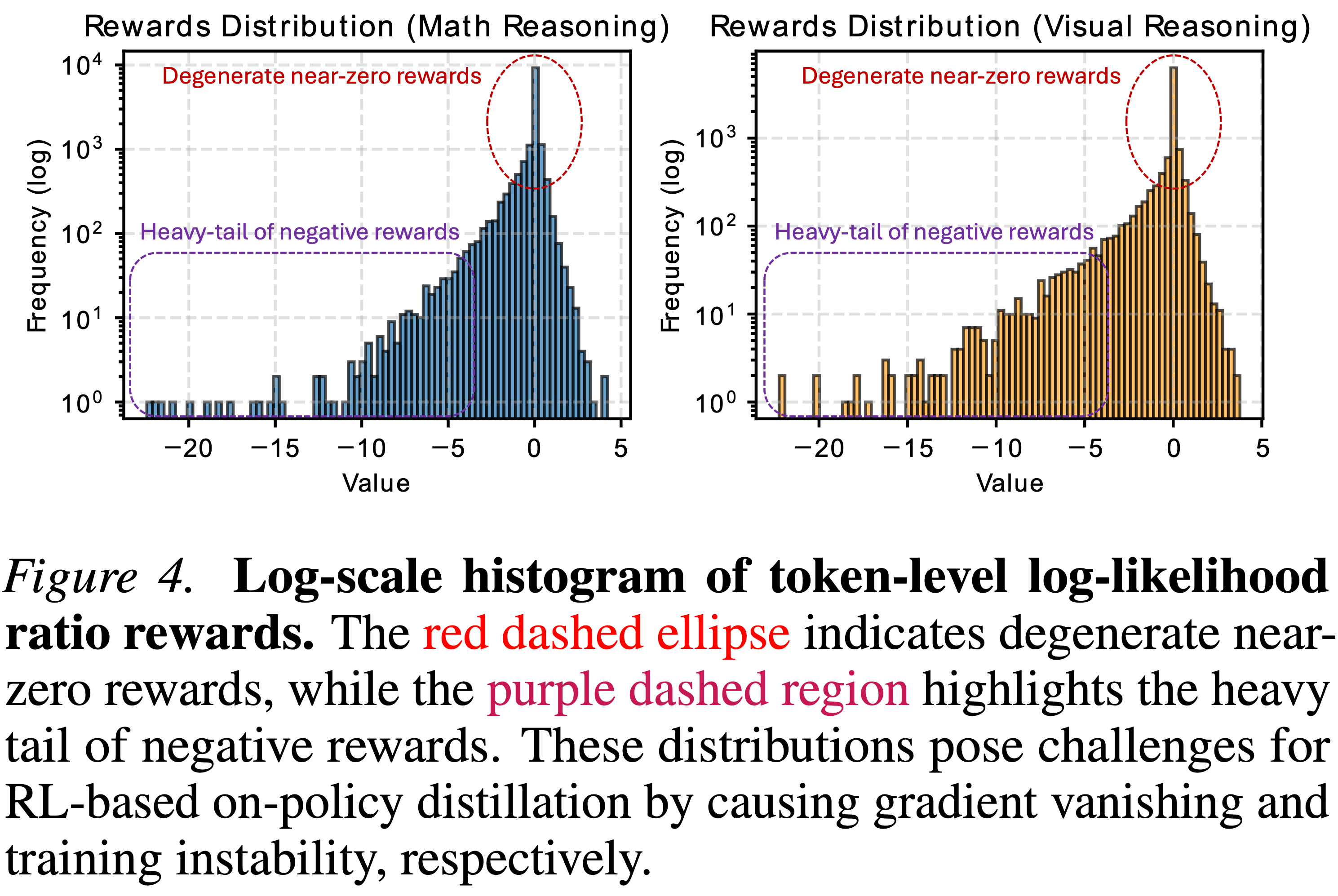
- 当学生策略采样到教师分配可忽略概率的 Token(即 \(\pi_{T}(o_{t}|q,o_{< t})\to 0\))时,观察到一个严重的错位问题
- 如图 4 所示,这导致对数似然比趋近于 \(- \infty\),形成一个 heavy-tailed 分布的负奖励
- 这些极端值主导了梯度估计,导致优化不稳定
- 破坏性的参数更新抑制了特定的 Token,导致模型显著偏离其原始分布(表 1,表 2)
- 图 4. Token-level 对数似然比奖励的对数尺度直方图
- 红色虚线椭圆表示退化的接近零的奖励,而紫色虚线区域突出显示了负奖励的 heavy-tailed
- 这些分布通过导致梯度消失和训练不稳定,分别给基于 RL 的 OPD 带来了挑战
Inefficiency from near-zero rewards, 来自接近零奖励的低效性
- 对于大多数 Token,学生和教师分布是良好对齐的,产生的对数似然比接近零(参见图 4)
- 从 RL 的角度来看,这些趋近于零的 advantage 在消耗批处理内存和计算资源的同时,提供了微不足道的学习信号
- 这种信号稀释降低了有效样本量,损害了样本效率
- 与允许 Prompt 级别过滤的标准 RL (2025) 不同, OPD 在 Token-level 运行,使得这种粗粒度的策略无效
- 问题:这个点其实还好吧,除了变相地降低了学习率以外,本身也不太影响训练(比如增加一下学习率就缓解了)
Entropy-collapse and exploration-alignment trade-off,熵崩溃与探索-对齐权衡
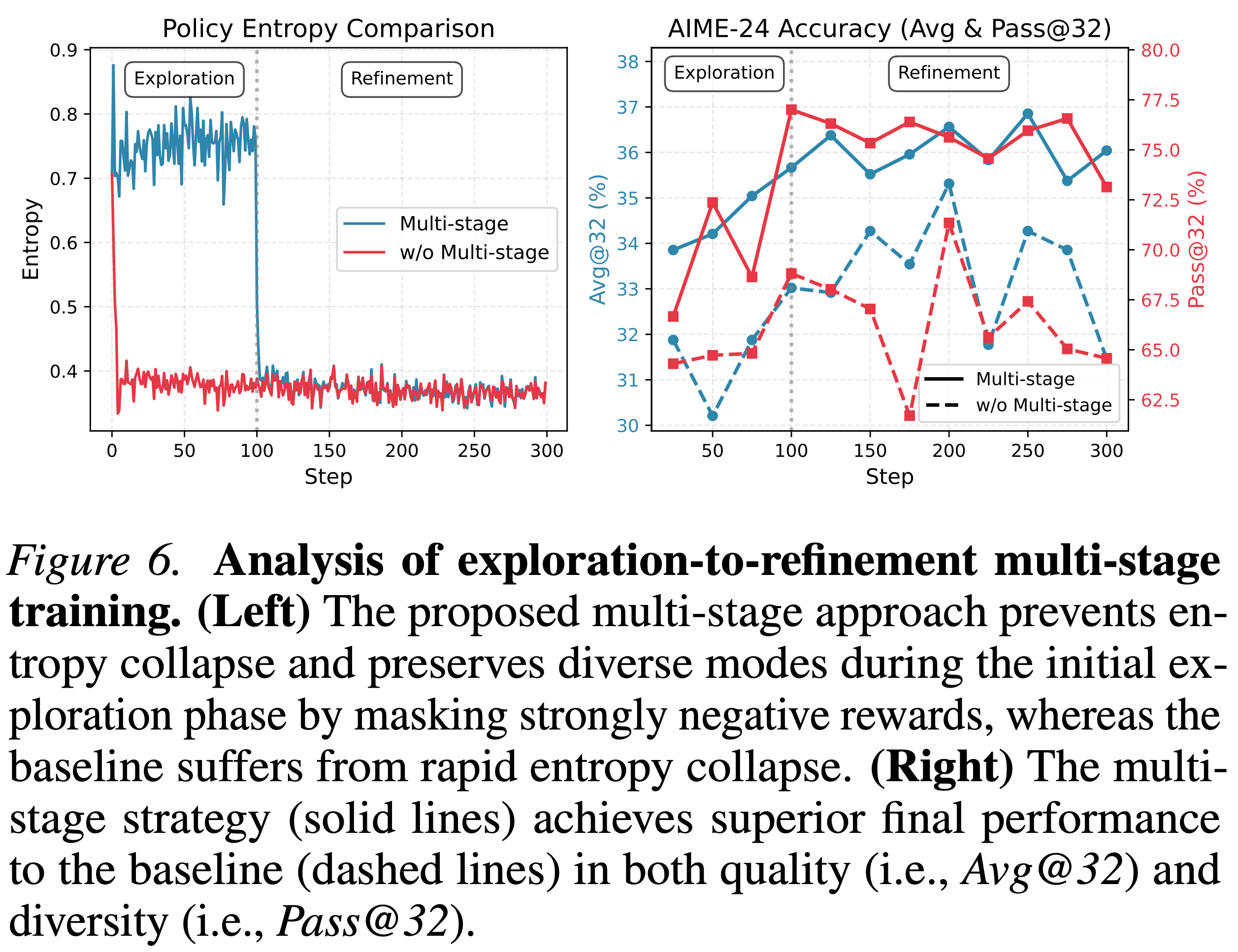
- 观察:在训练期间策略的熵迅速下降(参见图 6),导致在狭窄的输出集上过早收敛(有效的推理需要探索多样化的解决方案路径)
- 个人理解:这里在 OPD 中其实对探索的需求没有这么高了,但是仍然需要探索一下,确保自己知道自己生成的链路是否正确(符合教师分布),相当于让学习自己做作业,然后老师来改错,如果直接让老师或者其他同学来做,自己没有上手,是不知道自己如果上手会发生什么样的错误的
- 其他理解:OPD 中的熵还是可能会下降的,具体是熵增还是下降跟教师模型、学生模型的分布、数据分布以及学习时屏蔽了哪些 Token 都有关系
- 已知一定会降低熵的 Token:
- 学生概率高的 Token ,然后 Advantage 为正
- 学生概率低的 Token ,然后 Advantage 为负(一般来说都会降低整体熵,详情见:Math——多项式分布下的熵变化详细讨论)
- 已知一定会降低熵的 Token:
- 提高采样温度是标准 RL 中用于探索的补救措施,但实验发现这在此处是有害的:
- 更高的温度会引入与教师分布进一步偏离的 Token,从而加剧上述的奖励方差
- 这导致了一个在维持探索和确保学生-教师对齐之间的艰难权衡
REOPOLD: Relaxed On-Policy Distillation for Compact Reasoning Models,REOPOLD:用于紧凑推理模型的宽松 OPD
- REOPOLD 制定一个统一的、动态的目标函数,该函数明确地跨训练阶段调整学习信号
- 形式上,对于从 Query 集 \(\mathcal{Q}\) 采样的每个批次 \(\mathcal{B}\),REOPOLD 最大化以下目标:
$$
\begin{align}
\mathcal{J}_{\text{REOPOLD} }(\theta) = \mathbb{E}_{\mathcal{B}\sim \mathcal{Q},q\sim \mathcal{B},\{o_i\}_{i = 1}^G\sim \pi_{\theta_{\text{old} } }(\cdot |q)} \left[\frac{1}{\sum_{i = 1}^G\sum_{t = 1}^{|o_i|} }M_{i,t}^{(k)}\sum_{i = 1}^G\sum_{t = 1}^{|o_i|}\rho_{i,t}(\theta)\hat{R}_{i,t}^{(k)}(\theta)M_{i,t}^{(k)}\right],
\end{align} \tag {4}
$$ - 其中
$$\begin{align}
\hat{R}_{i,t}^{(k)}(\theta) &= \max \left(\text{sg}(R_{i,t}(\theta)),\frac{\log\lambda}{1 - \lambda}\right) \\ M_{i,t}^{(k)} &= \begin{cases} \mathbb{I}\left[R_{i,t}(\theta)\geq \frac{\log\lambda}{1 - \lambda}\right] & \text{if }k< T_{\text{switch} }\\ \mathbb{I}\left[H_{i}\geq \tau_{\beta}\right] & \text{if }k\geq T_{\text{switch} } \end{cases}
\end{align} \tag {5}$$ - 完整的训练流程总结在算法 1 中

Reward Clipping via Mixture-Based Regularization,通过基于混合的正则化进行奖励裁剪
- 裁剪重要性采样比率 (2017) 在 RL 中是标准的,但它仅限制了策略更新的幅度,而不是学习信号本身的完整性
- 在 OPD 中,主要的不稳定性源于 heavy-tailed 的奖励分布(图 4),其中 \(\pi_{T}(o_{t}|q,o_{< t})\to 0\)
- 为了缓解这一问题,作者提出了一个原则性的裁剪阈值,该阈值受混合分布稳定性分析的启发
- 观察:对数似然比受教师和学生分布的凸混合(系数为 \(\lambda \in [0,1)\))所界定 (Ko 等 2024; 推导见附录 A.2):
$$R_{i,t}(\theta) = \log \frac{\pi_T}{\pi_\theta}\leq \frac{1}{1 - \lambda}\log \frac{(1 - \lambda)\cdot\pi_T + \lambda\pi_\theta}{\pi_\theta}.$$ - 关键的 Insight:这两项在渐近行为上的差异
- 当教师概率趋近于零时,左侧的原始奖励 \(R_{i,t}\) 发散到 \(- \infty\),而右侧基于混合的项收敛到一个有限常数 \(\frac{\log\lambda}{1 - \lambda}\)
- 这表明一个稳健的基于混合的目标函数内在地对所分配的惩罚有一个理论下界,从而防止了标准 RKL 中观察到的梯度爆炸
- 受此启发,本文使用这个渐近极限作为原则性的下限来截断 heavy-tailed 的负奖励:
$$\hat{R}_{i,t}^{\lambda}(\theta) = \max \left(\text{sg}(R_{i,t}(\theta)),\frac{\log\lambda}{1 - \lambda}\right) \tag {7}$$- \(\frac{\log\lambda}{1 - \lambda}\) 代表在稳健的混合框架中允许的最大理论上惩罚
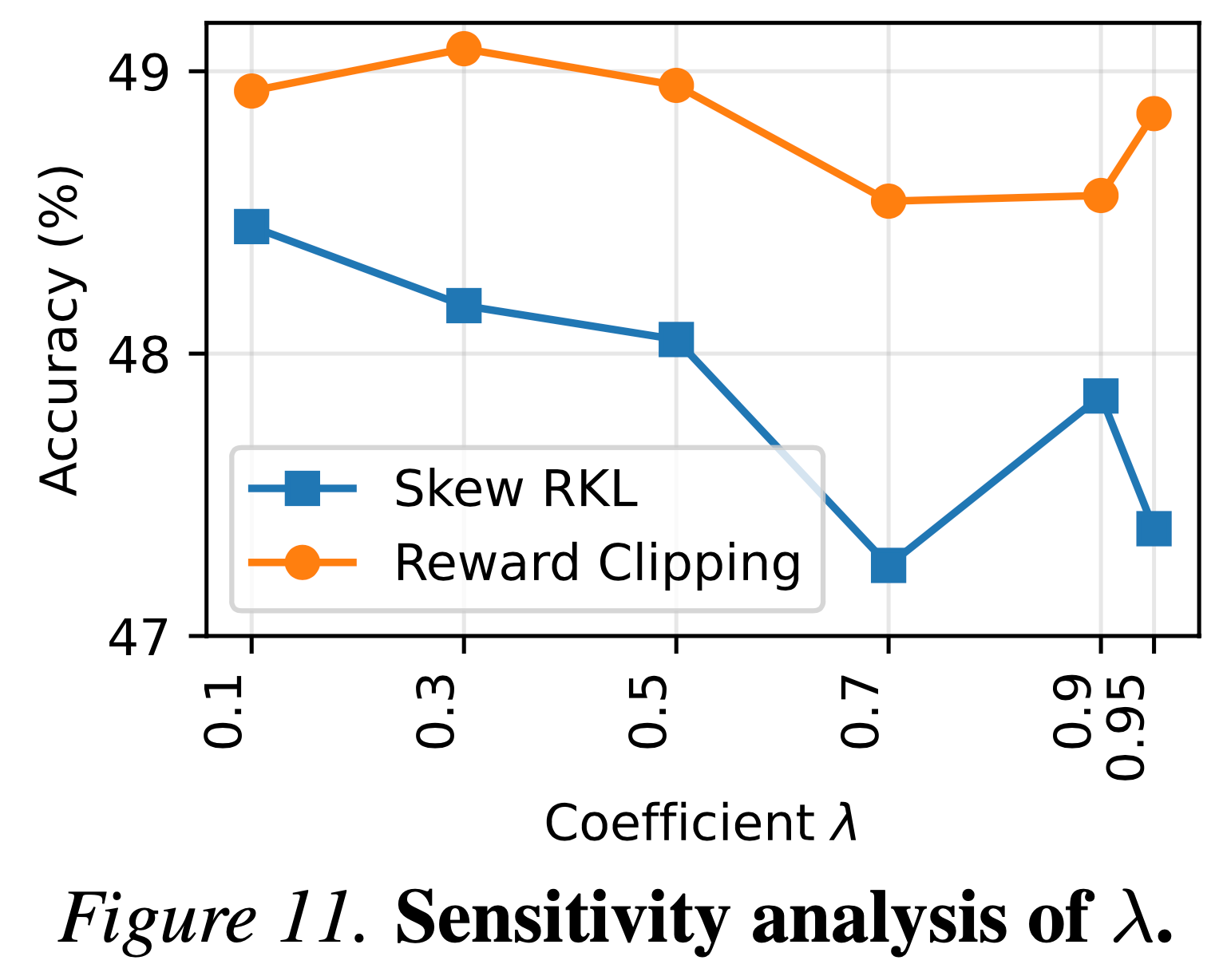
- 与全局改变目标函数且对 \(\lambda\) 敏感的 Skew RKL (2024) 不同, REOPOLD 选择性地针对异常值
- 这在保留了 RKL 的模式追求 (mode-seeking) 特性的同时,确保了对超参数变化的鲁棒性(图 11)
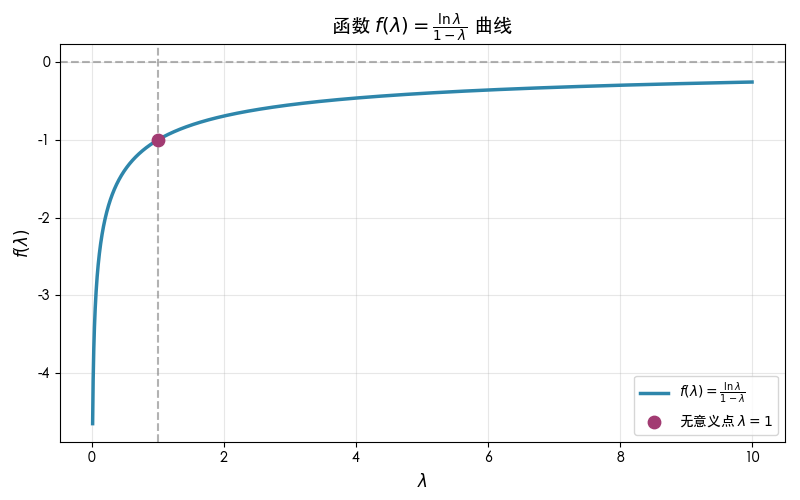
- 补充:函数 \(f(\lambda) = \frac{\log\lambda}{1 - \lambda}\) 的函数图像为:
- 注:这个曲线类似对数曲线,在 \(\lambda=1\) 时无意义,在两边都是单调递增的函数
- 由于 \(\lambda \in [0,1)\),所以 \(f(\lambda)\) 的最大值是 -1
- 当 \(\lambda \rightarrow 1^-\) 时,\(f(\lambda) = -1\)
- 证明:\(\log x\) 在 \(x \approx 1\) 处的近似函数是 \(x - 1\)
Entropy-Guided Token-Level Dynamic Sampling,基于熵的 Token-level 动态采样
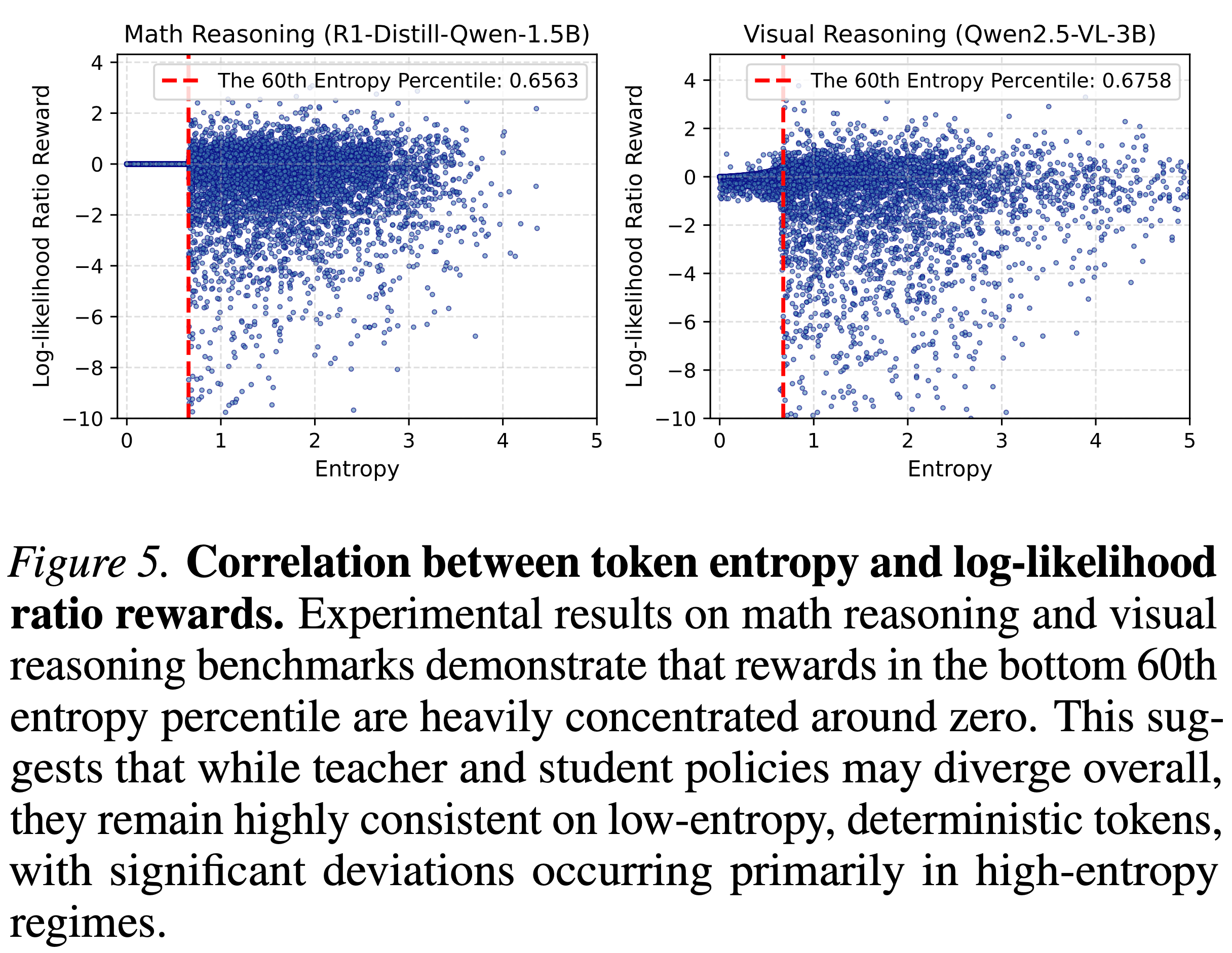
- 观察:对数似然比奖励表现出高度退化的分布,尤其是在低熵区域
- 如图 5 所示,在各种设置下
- 按熵排序处于最低 60 个百分位数的 Token 的奖励值高度集中在零附近
- 这种现象出现的原因是大多数 Token 是足够确定性的
- 学生和教师策略都分配了几乎相同的高概率,导致梯度消失
- 这种现象出现的原因是大多数 Token 是足够确定性的
- 高熵 Token 通常包含关键的分支点 (2025a),提供了更有意义的学习信号
- 含义:教师和学生策略可能在全局上存在分歧,但它们在低熵 Token 上保持高度一致
- 针对这些区域进行学习可以过滤掉无信息的 Token,并提高整体训练效率
- 按熵排序处于最低 60 个百分位数的 Token 的奖励值高度集中在零附近
- 图 5. Token 熵与对数似然比奖励之间的相关性
- 在数学推理和视觉推理基准上的实验结果表明,处于熵最低的 60 个百分位数内的奖励高度集中在零附近
- 这表明,尽管教师和学生策略可能整体上存在分歧,但它们在低熵、确定性的 Token 上保持高度一致,显著偏差主要发生在高熵区域
- 本文利用熵作为信息密度的代理来解决这个问题
- 定义一个二元掩码 \(\mathbb{I}\left[H_{t}^{i}\geq \tau_{\beta}\right]\) 来分离具有高预测不确定性的 Token
- 其中 \(H_{t}^{i}\) 表示学生策略在 Token \(o_{i,t}\) 上的熵,\(\tau_{\beta}\) 对应于批次 \(\mathcal{B}\) 内的前 \(\beta\) 百分位数阈值
- 专门为高熵 Token 实例化目标函数:
$$
\begin{align}
\mathcal{J}_{\text{Ent} }(\theta) = \mathbb{E}_{\mathcal{B}\sim \mathcal{Q},q\sim \mathcal{B},\{o_i\}_{i = 1}^G\sim \pi_{\theta_{\text{old} } }(\cdot |q)} \left[\frac{1}{\sum_{i = 1}^G\sum_{t = 1}^{|\alpha_i|}\mathbb{I}\left[H_t^i\geq \tau_\beta\right]}\sum_{i = 1}^G\sum_{t = 1}^{|\alpha_i|}\rho_{i,t}(\theta)\hat{R}_{i,t}^{\lambda}(\theta)\mathbb{I}\left[H_t^i\geq \tau_\beta\right]\right]
\end{align}
\tag {8}
$$ - 仅在计算高熵 Token 上的梯度(即 \(\mathbb{I}[H_t^i\geq \tau_\beta ] = 1\))创建了一个由信息密度驱动的动态批次
- 这通过在归一化过程中过滤掉零奖励噪声,有效地缓解了梯度稀释
- 这种方法与 DAPO (2025) 中的动态采样一致,但将其调整到了推理所需的 Token-level 粒度
- 图 8 中的实证结果证实,专注于学生-教师分歧最大的点,在更快的收敛速度和更优的最佳准确率方面都带来了显著的提升
- 理解:当然会提升,因为相当于提升了学习率,其实如果每个 Step 之间的分布差异类似的话,整体提升学习率可能也会有类似效果
- 与为 Response 中的所有 Token 分配单个优势值的 Wang 等 (2025a) 不同,本文的 Token-level 公式在广泛的模型尺寸范围内保持稳健
- 图 8 中的实证结果证实,专注于学生-教师分歧最大的点,在更快的收敛速度和更优的最佳准确率方面都带来了显著的提升
Exploration-to-Refinement Multi-Stage Training,exploration-to-refinement 的多阶段训练
- REOPOLD 的统一公式 :仅需要向 RKL 目标函数引入一个 Token-level 掩码
- 这提供了一个灵活的机制,可以明确控制探索多样化解决方案与精炼推理信号之间的权衡:
$$
\begin{align}
\mathcal{J}_{\text{REOPOLD} }(\theta) = \mathbb{E}_{\mathcal{B}\sim \mathcal{Q},q\sim \mathcal{B},\{o_i\}_{i = 1}^G\sim \pi_{\theta_{\text{old} } }(\cdot |q)} \left[\frac{1}{\sum_{i = 1}^G\sum_{t = 1}^{|o_i|}M_{i,t} }\sum_{i = 1}^G\sum_{t = 1}^{|o_i|}\rho_{i,t}(\theta)\hat{R}_{i,t}^\lambda (\theta)M_{i,t}\right]
\end{align}
\tag {1}$$
- 这提供了一个灵活的机制,可以明确控制探索多样化解决方案与精炼推理信号之间的权衡:
- 通过动态控制掩码 \(M_{i,t}\),本文实例化了一个两阶段训练流程:
- 一个初始的探索阶段,鼓励多样化的合理解决方案(类似于 SFT)
- 随后是一个 Refinement 阶段,分离并放大正确的推理路径(类似于 RL)
- 如图 6 所示,该策略通过有效平衡探索和利用,在早期促进多样性,并在后期将策略巩固到高质量轨迹上,从而稳定了训练
Exploration phase
- 在初始阶段(即前 \(T_{\text{switch} }\) 步),定义掩码以过滤掉过度的惩罚:
$$M_{i,t} = \mathbb{I}\left[R_{i,t}(\theta)\geq \frac{\log\lambda}{1 - \lambda}\right] \tag {9}$$ - 该掩码选择性地移除与强负奖励相关的 Token 的梯度
- 实验发现该策略对于减轻熵崩溃至关重要(参见图 6)
- 理解:这个是可以解释的,推测强负奖励相关的 Token 一般是一些 Student 概率也不大的 Token,一般来说,降低这部分 Token 会导致整体的熵降低,详情见 Math——多项式分布下的熵变化详细讨论
- 通过抑制通常会消除低概率 Token 的大幅负梯度,该目标函数模仿了 SFT 的动态:它强化正向行为,而不会激进地惩罚探索性错误。这允许策略维持多个与教师对齐的模式 (2025a),并探索解空间的更广阔区域
- 图 6 中 Avg@32 和 Pass@32 的同时提升证明了这一优势
- 本文在此阶段禁用了 Token-level 动态采样 (第 4.2 节),以确保密集的监督,严格与 SFT 视角保持一致
- 实验发现该策略对于减轻熵崩溃至关重要(参见图 6)
Refinement phase
- Refinement phase 阶段切换掩码策略以重新引入负反馈,从而在 Token 之间进行更清晰的区分
- 本文应用第 4.2 节中引入的基于熵的掩码:
$$M_{i,t} = \mathbb{I}\left[H_{i}^{i}\geq \tau_{\beta}\right] \tag {10}$$ - 这种转换通过将学习重点放在高熵 Token(即教师和学生策略分歧最大的点)上来促进策略精炼和收敛
- 通过允许对这些关键的、不确定的 Token 进行负反馈,精炼阶段确保了学习策略的有效巩固
Experimental Results
Extension: Math Reasoning
Setup
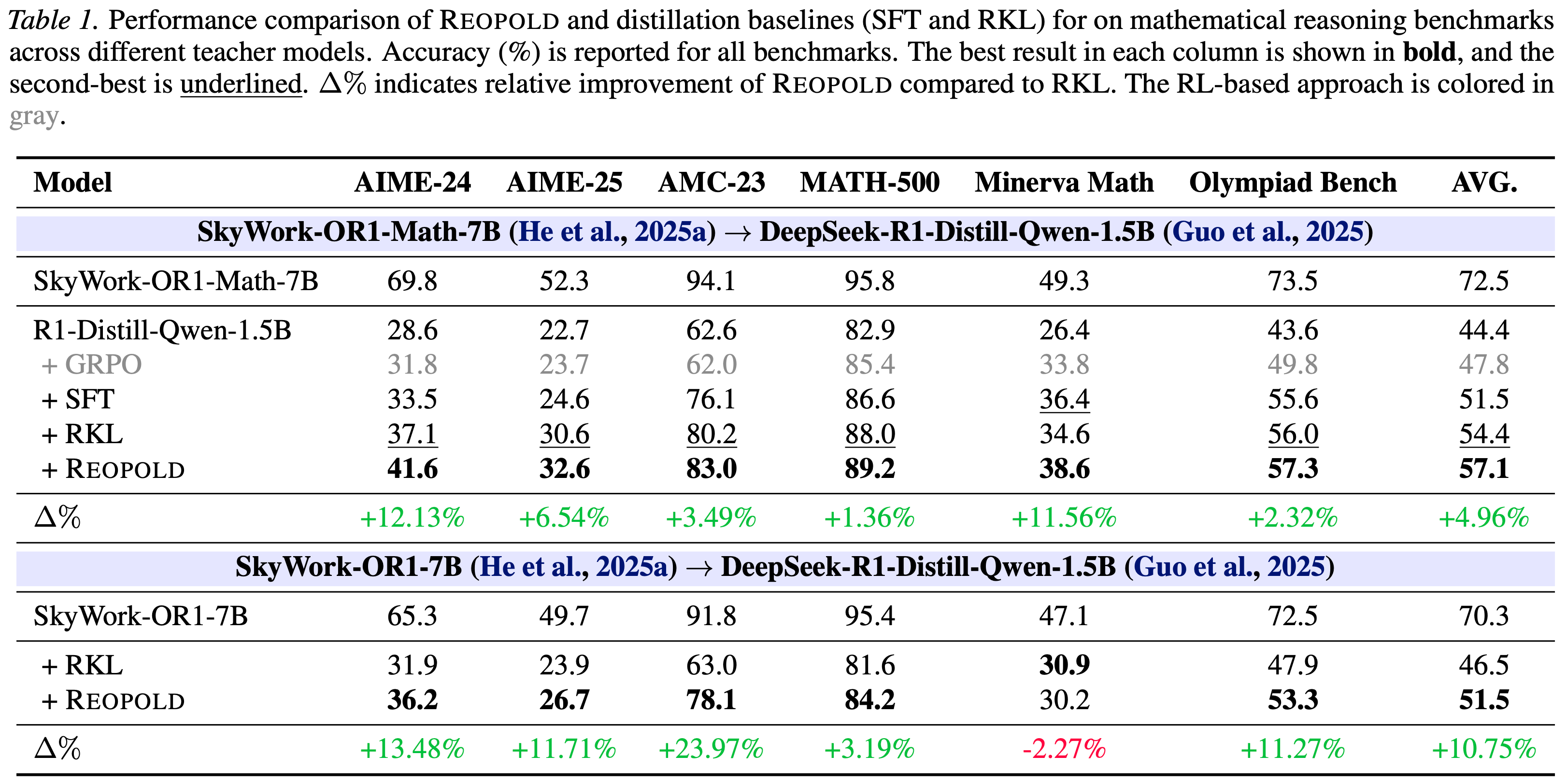
- 在 DeepSeek-R1-Distill-Qwen-1.5B 和 7B (2025) 上进行 on-policy distillation,分别采用 SkyWork-OR1(-Math)-7B 和 SkyWork-OR1-32B-Preview (2025a) 作为教师
- 训练时,使用 Yan 等人 (2025) 提出的数据集,该数据集包含 45k 个 prompts
- 表 1 中的所有 1.5B 模型均为公平比较而训练了 300 步,本文为图 1(a) 中的样本效率分析将 REOPOLD 的训练延长至 600 步
- 详细的训练设置见附录 C
Evaluation
- 在六个竞赛级别的数学推理基准上评估所有模型:AIME-24、AIME-25、AMC-23、MATH-500 (2020)、Minerva Math (2022) 和 Olympiad Bench (2024)
- 对于 AIME-24、AIME-25 和 AMC-23,考虑到测试集相对较小,报告 Avg@32
- 对于其余三个基准,报告 Pass@1
- 在所有评估中,使用温度为 0.6 和 top-p 值为 0.95
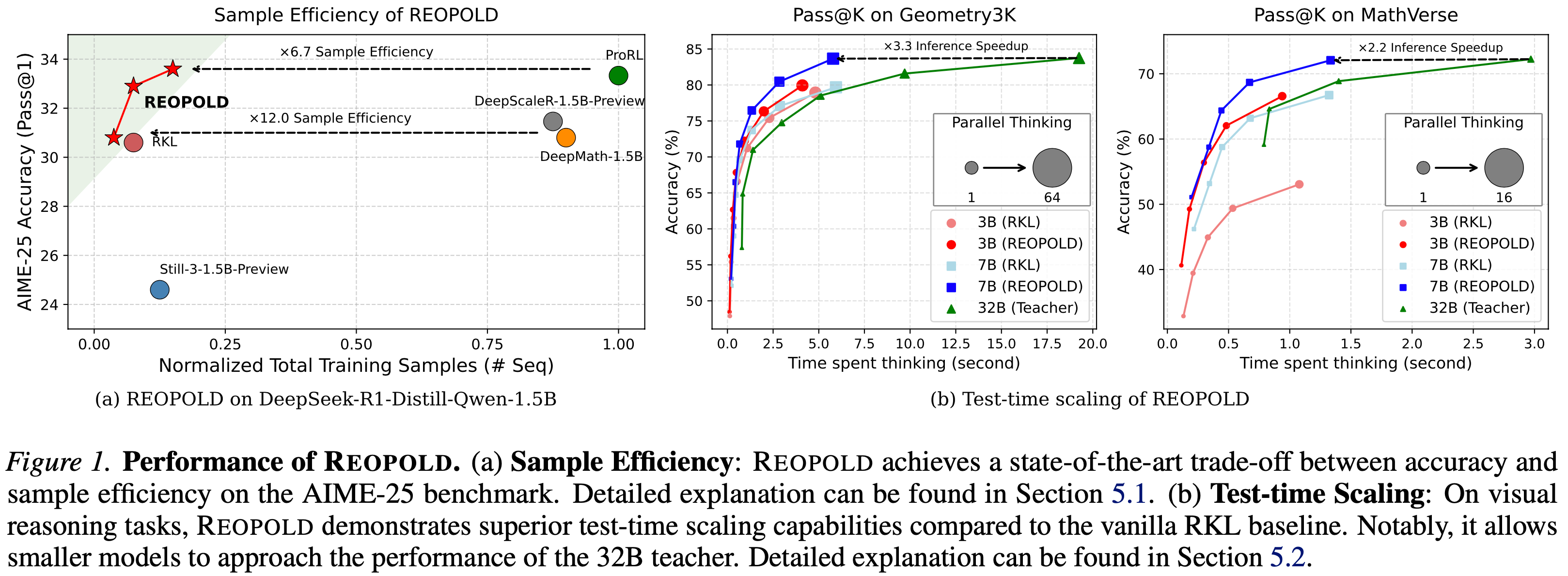
Result 1: Better training sample-efficiency
- 如图 1(a) 所示,REOPOLD 在 600 步时与 ProRL (2025a) 表现相当(而 ProRL 需要 2000 步)
- 当通过总训练样本数(考虑 batch 大小)进行归一化时,这产生了 \(>6.7\times\) 的效率增益
- REOPOLD 在 300 步时甚至更早就超越了 DeepScaleR-1.5B-Preview (2025) 和 DeepMath-1.5B (2025b)(\(>12\times\) 效率),并且特别值得注意的是,仅用 150 步就显著优于 vanilla RKL(300 步)
- 在相同条件下,重新实现的 GRPO 上表现更优(表 1),证实了本文增益源于算法效能而非实验设置
Result 2: Robustness to teacher selection
- 如表 1 详述,REOPOLD 相比 RKL 表现出更优的鲁棒性
- REOPOLD 在所有指标上持续优于 SFT 基线
- vanilla RKL 表现出对教师选择的敏感性
- 当从 SkyWork-OR1-7B 进行蒸馏时,RKL 显示出微不足道的改进
- 无论使用何种教师模型,REOPOLD 都能提供一致的性能提升
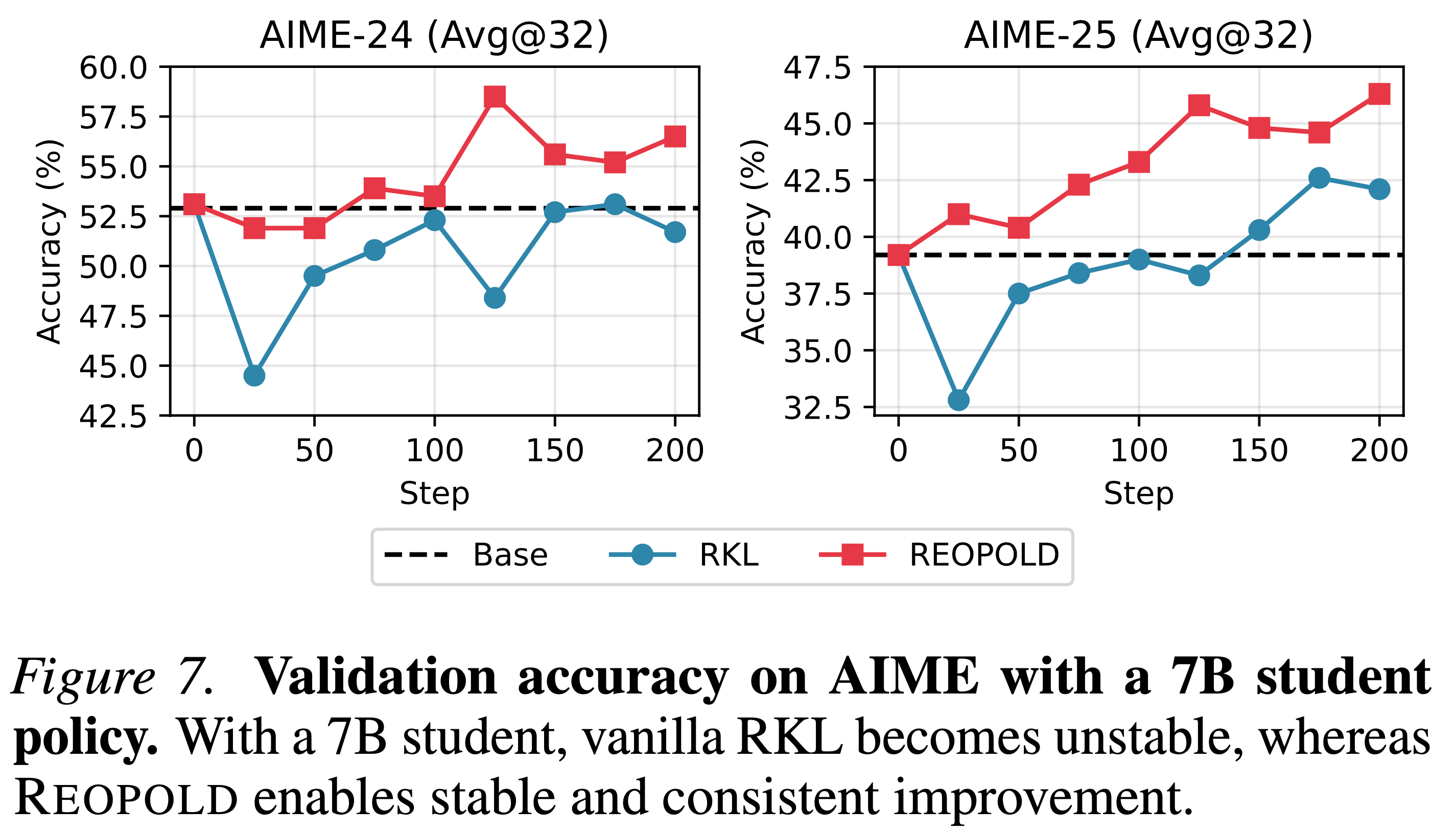
Result 3: Scaling to large policy models.
- 当扩展到更强的学生模型(如 DeepSeek-R1-Distill-Qwen-7B)时,vanilla RKL 由于模型已经固化的推理能力而遭受严重的训练不稳定性
- 如图 7 所示,RKL 在早期阶段表现出急剧的性能下降,并且对于 AIME-24,无法提升到超过基础模型的性能
- REOPOLD 利用其多样化的组件确保训练稳定
- 它成功防止了性能退化,并在各个基准上展示了持续的改进,证明了其在大规模蒸馏中的鲁棒性
- 它成功防止了性能退化,并在各个基准上展示了持续的改进,证明了其在大规模蒸馏中的鲁棒性
Main Results: Visual Reasoning
Setup
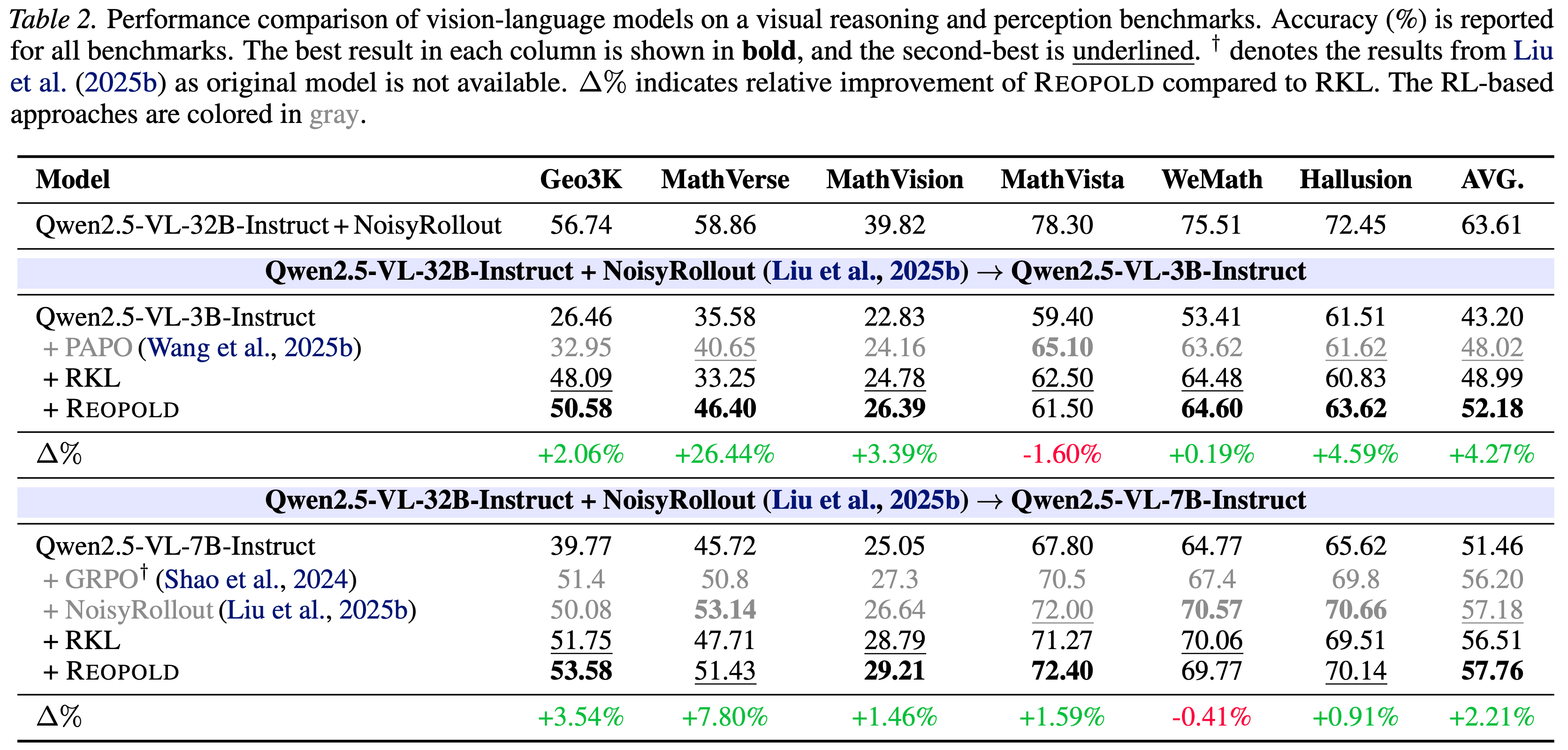
- 采用 Qwen2.5-VL-3/7B-Instruct (2025) 作为学生策略,采用经过 NoisyRollout (2025b) 训练的 Qwen2.5-VL-32B-Instruct 作为教师
- 在 Geometry3K (2021) 上训练学生模型,该数据集专注于几何问题求解,包含大约 2.1K 个训练样本
- 遵循 Liu 等人 (2025b) 的协议,通过将所有多项选择题转换为自由形式的答案格式来预处理该数据集,以减轻 reward hacking 并减少答案猜测的可能性
- 详细的训练设置见附录 C
Evaluation
- 在六个基准上进行评估:五个视觉推理基准,包括 Geometry3K 的测试集、MathVerse (2024a)、MathVision (2024)、MathVista (2023) 和 WeMath (2025),以及一个视觉感知基准 HallusionBench (2024)
- 遵循 Liu 等人 (2025b) 的评估协议,对模型推理采用 greedy sampling 和温度为 0.6、top-p 为 0.95 的 nucleus sampling (2020),并使用 Gemini-2.0-Flash-001 (2023) 作为评判模型来解析生成的回答
Result 1: Efficacy on compact models
- 如表 2 所示
- 对于 3B 和 7B 模型,REOPOLD 在视觉推理和感知基准上相比 GRPO 和 RKL 基线取得了更优的整体性能
- REOPOLD 也超越了专门的感知算法,如 NoisyRollout(7B)和 PAPO (2025b;3B)
- 附录 D 中跨不同设置(包括不同的教师模型和训练步数)的扩展实验证实了 REOPOLD 相对于 vanilla RKL 的一致性优势
- 这凸显了其对紧凑模型的鲁棒性,源于 refined teacher rewards 限制了低容量机制中的不必要模仿
Superior test-time scaling
- 基准测试了并行思考延迟 (parallel thinking latency),定义为每个问题并行生成多个响应所需的平均时间
- 实验使用 vLLM 在单个 NVIDIA Blackwell 6000 GPU 上进行,生成 cutoff 为 4096 个 tokens。在 Geometry3K 和 MathVerse 上,报告了 Pass@K 准确率与 \(K\) 个样本(从 1 扩展到 16 或 64)的推理时间的关系
- 图 1(b) 表明 REOPOLD 实现了卓越的测试时扩展曲线,在 Pass@K 方面达到了高达 \(3.32 \times\) 的推理效率,这得益于
- (1) 相比 RKL 更优的生成质量
- (2) 相比 Qwen2.5-VL-32B 教师更高的性能与延迟比,这归因于学生模型的紧凑尺寸
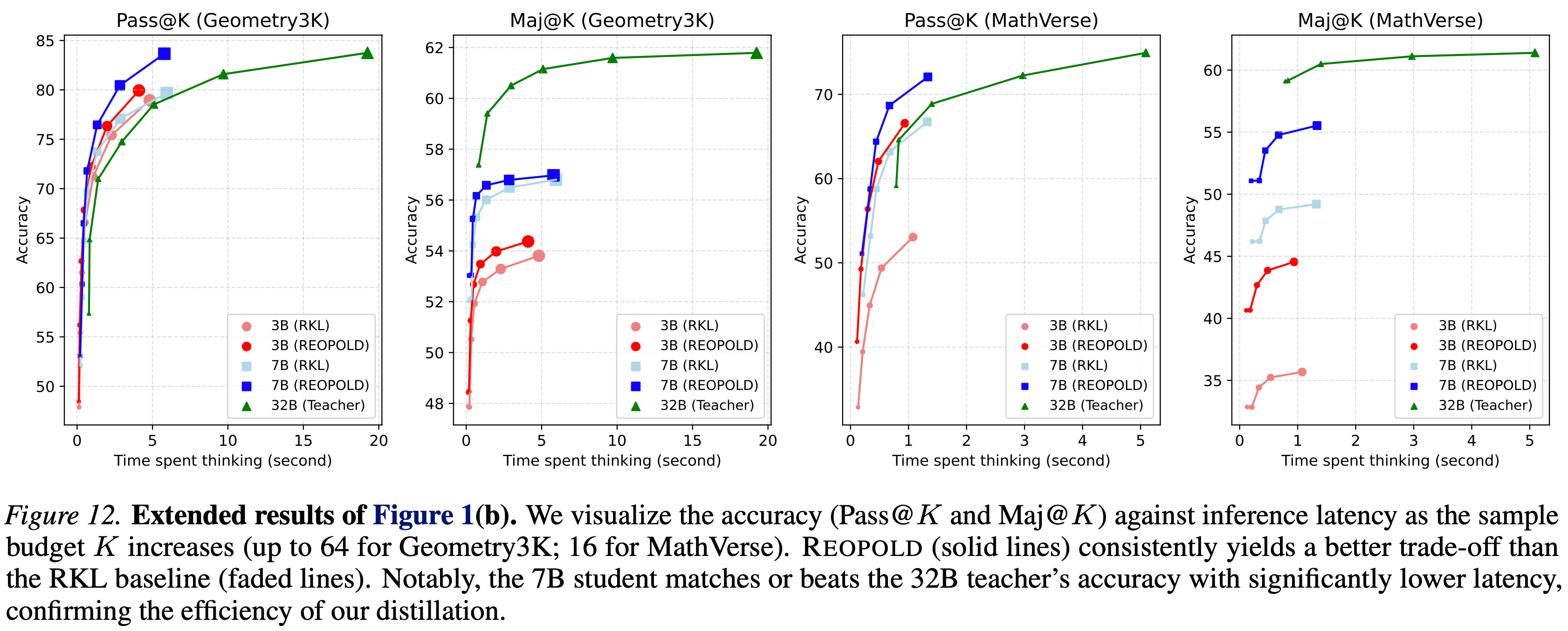
- 图 12 中使用 Maj@K 的扩展结果证实,在不同的测试时扩展指标上,REOPOLD 相比 RKL 基线始终保持着更好的扩展轨迹
Analysis: Visual Reasoning
Result 1: Training on different teacher
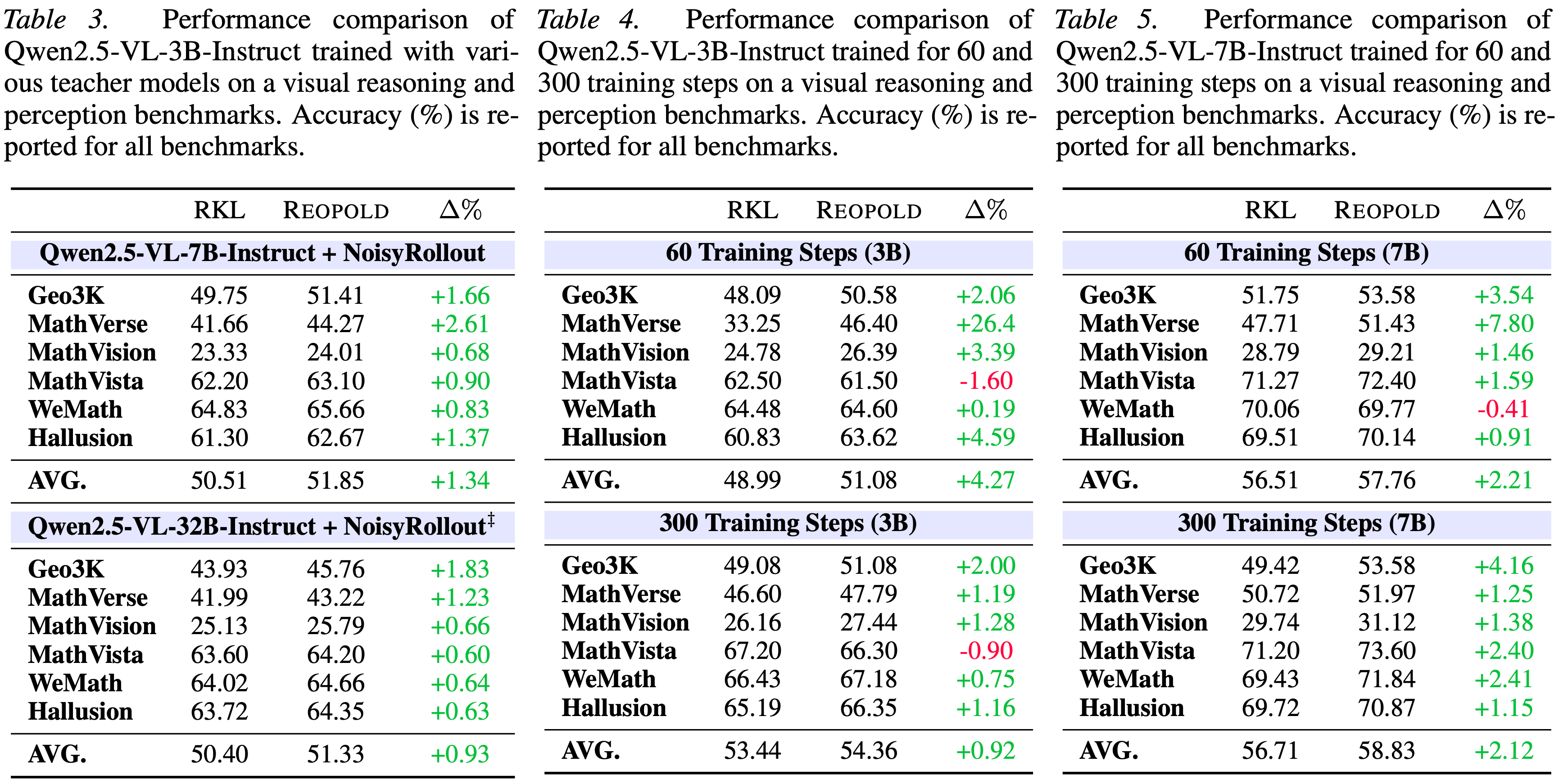
- 进一步通过从不同的教师模型进行蒸馏来评估 REOPOLD ,以评估泛化能力
- 如表 3 详述,利用分别通过 NoisyRollout (2025b) 在 Geometry3K 和 MMK12 上微调的 Qwen2.5-VL-7B-Instruct 和 32B-Instruct 模型作为教师
- 结果证明了 REOPOLD 的一致有效性
- 与 RKL 基线相比,REOPOLD 在两种教师设置下的所有六个基准上都产生了统一的改进
- 使用 7B 教师时平均准确率提高了 \(1.34%\),使用 32B 教师时提高了 \(0.93%\)
- 这证实了 REOPOLD 对教师架构和领域特定专业知识的变化具有鲁棒性,能够可靠地增强学生的视觉推理和感知能力
- 与 RKL 基线相比,REOPOLD 在两种教师设置下的所有六个基准上都产生了统一的改进
Result 2: Scalability with longer trainin
- 通过将训练持续时间延长至 300 步,并为 Qwen2.5-VL-3B-Instruct(表 4)和 Qwen2.5-VL-7B-Instruct(表 5)整合 Geometry3K 和 MMK12 数据集来研究 REOPOLD 的可扩展性
- 如表 4 和表 5 所示,延长训练时间对基线和 REOPOLD 方法都带来了性能提升,证实了更大规模训练的好处
- 更长的训练通常会全面提高性能, REOPOLD 始终表现出更好的可扩展性(在两种模型大小上都优于 RKL 基线)
- 使用 3B 模型实现了 \(54.36%\) 的最高平均准确率,使用 7B 模型实现了 \(58.83%\)
- 这些结果表明,给定更多的计算和数据, REOPOLD 能够持续优化其策略,从而在视觉推理和感知任务上带来稳健的改进
- 更长的训练通常会全面提高性能, REOPOLD 始终表现出更好的可扩展性(在两种模型大小上都优于 RKL 基线)
Result 3: Impact of module design
- 表 6 验证了每个技术组件的贡献
- RKL 基线表现出有限的性能,应用 stop-gradient(1) 提供了显著的初始提升
- 添加 reward clipping(2) 和 token-level dynamic sampling(3) 在多个基准上带来了一致的改进
- 关于(3),图 8 中的敏感性分析表明,更严格的阈值(例如 \(\beta = 0.2\))优于较宽松的设置(\(\beta = 0.5\))
- 这证实了过滤低熵 tokens 能有效缓解梯度稀释,使模型能够专注于关键的推理步骤
- 多阶段训练(4) 完成了整个流程,取得了最佳的整体性能
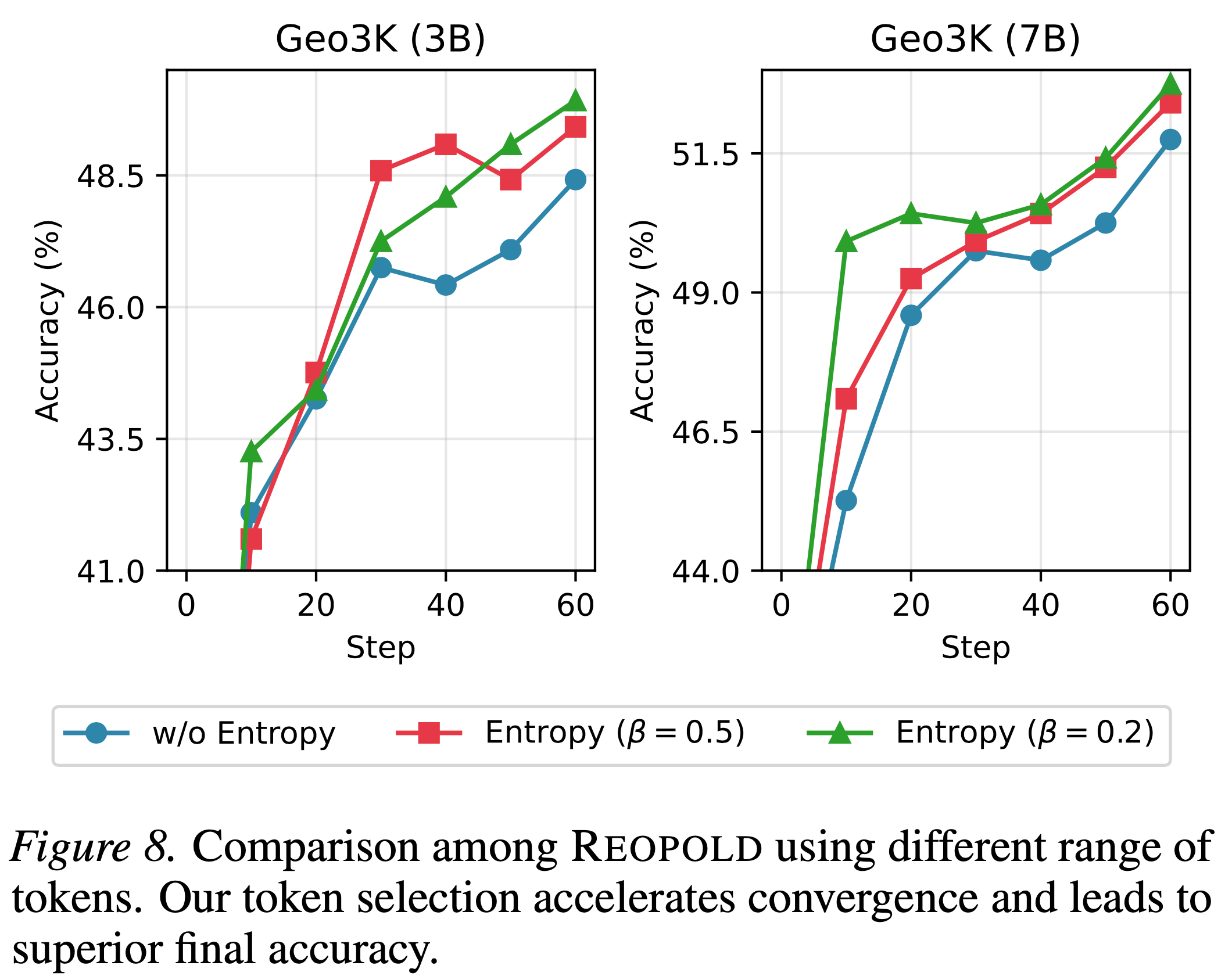
- 理解:在一些场景上看着涨幅有限,特别是 reward clipping(2) 和 token-level dynamic sampling(3) 操作似乎没有任何涨幅
- 可参考图 3、图 11 和图 6,分别获取关于 stop-gradient、reward clipping 和多阶段训练的扩展分析
Extension: Agentic Reasoning with Visual Tool-Use
- 传统的视觉推理方法通常将图像视为静态输入,限制了模型主动探索视觉信息的能力
- 本文实现了图像操作工具,使 Agent 能够放大特定区域、选择关键帧并执行其他视觉操作
- 这种方法遵循 Pixel-Reasoner (2025),增强了在密集视觉数据上的推理能力
Setup
- 基于 VeriTool (2025) 框架实现 REOPOLD
- 采用经过 SFT 的 Qwen2.5-VL-3B-Instruct (2025) 作为学生策略,采用 Pixel-Reasoner-7B (2025) 作为教师
- 使用 Pixel-Reasoner 的官方训练数据集,该数据集包含来自 InfographicVQA 的 15K 个 Query ,并辅以其他公共数据集
- 详细的训练设置见附录 C
Evaluation
- 遵循 Su 等人 (2025) 的方法,在四个具有代表性的多模态基准上使用温度为 1.0、top-p 为 1.0 的 nucleus sampling 来评估模型和基线:Pixel-Reasoner 的测试集、V-Star (2024)、InfographicVQA (2022) 和 TallyQA (2019)
- 这一选择提供了广泛的视觉理解任务,从细粒度对象识别到静态和动态场景中的高层次推理
Results
- 如表 7 所报告,REOPOLD 优于 vanilla RKL 和 GRPO,显著超越了 GRPO,即使 GRPO 利用了 Su 等人 (2025) 提出的复杂 reward 设计
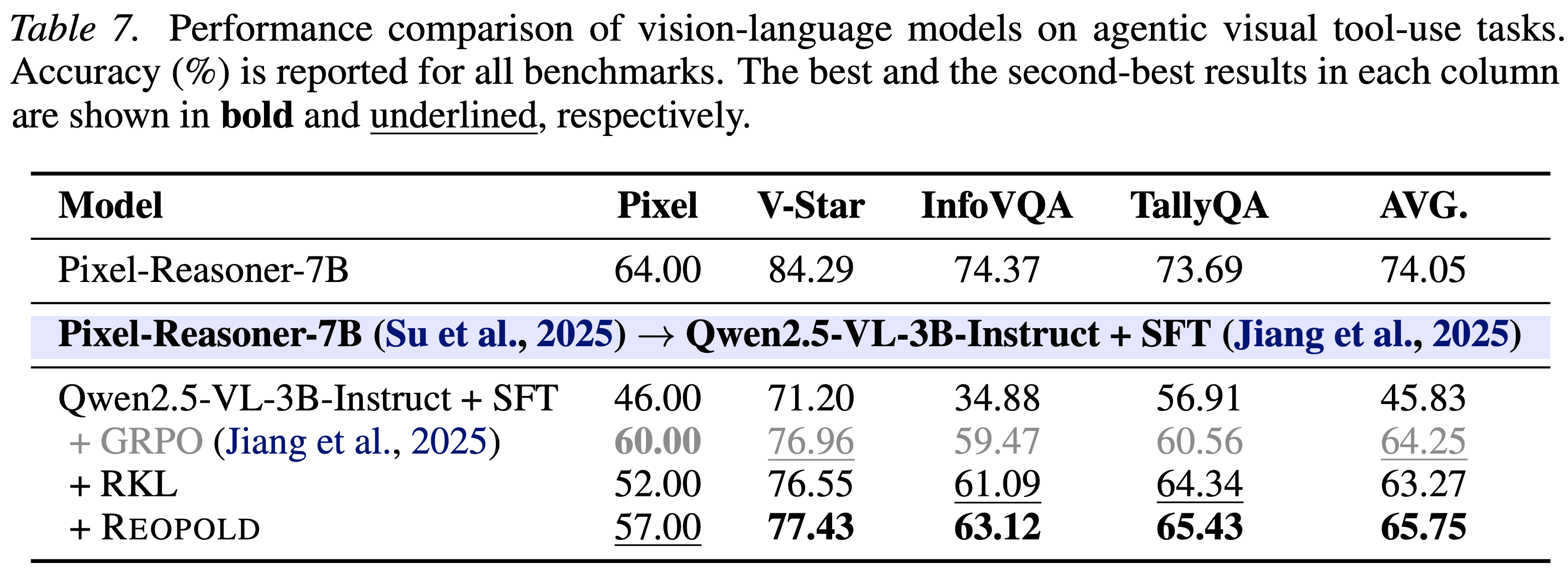
- GRPO 在 Pixel 测试集上实现了略高的准确率,但 REOPOLD 在其他基准上表现出更优的性能,表明其具有更强的泛化能力
- 本文在图 9 中展示了 REOPOLD 相比 RKL 和 GRPO 具有更好的样本效率
- 与需要为复杂的 Agentic 任务进行复杂 reward 工程的传统 RL 方法不同,REOPOLD 可以直接应用
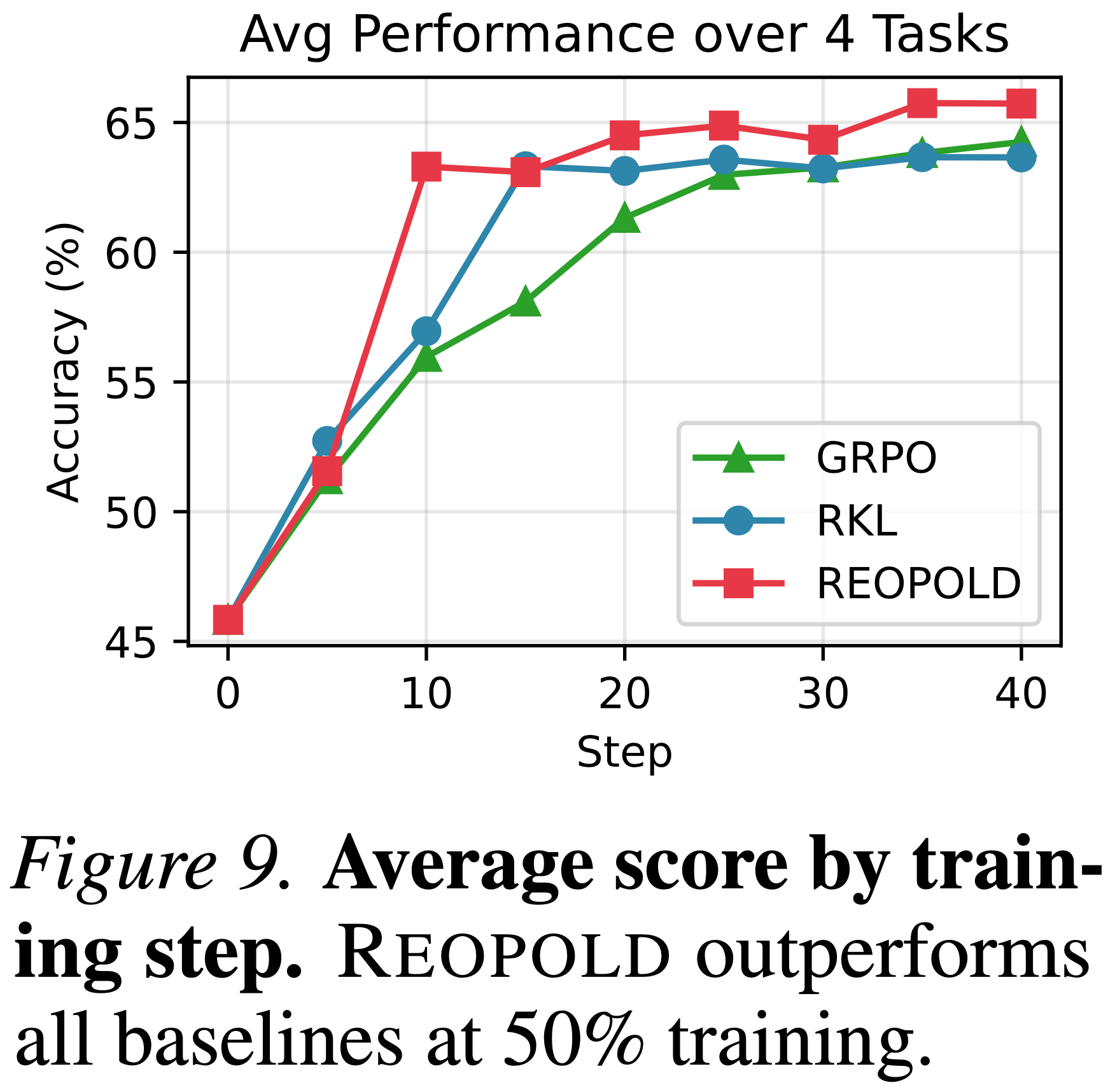
- 与需要为复杂的 Agentic 任务进行复杂 reward 工程的传统 RL 方法不同,REOPOLD 可以直接应用
- 吐槽:其实差异没有那么明显?
附录 A:Mathematical Derivations
A.1. RKL
- Assumption & Justification :为了确保推导的有效性,本文假设以下标准正则性条件成立:
- 可微性 (Differentiability) :
- 策略 \( \pi_{\theta}(o|q) \) 在其整个定义域上关于 \( \theta \) 是连续可微的
- 这种平滑性条件,结合梯度被一个可积函数所界定的假设(满足莱布尼茨积分法则和控制收敛定理的条件),允许作者交换梯度算子 \( \nabla_{\theta} \) 和期望 \( \mathbb{E} \)
- 绝对连续性 (Absolute Continuity) (支持覆盖 (Support Coverage)) :
- 假设目标分布关于采样分布是绝对连续的,记为 \( \pi_{\theta} \ll \pi_{\theta_{\text{old} } } \)
- 对于任何观测值 \( o \),如果 \( \pi_{\theta_{\text{old} } }(o|q) = 0 \),那么 \( \pi_{\theta}(o|q) \) 也必定为 0
- 这保证了重要性采样比率 \( \rho_{t}(\theta) \) 和对数似然比 \( R_{t}(\theta) \) 几乎处处定义良好且有限
- 可微性 (Differentiability) :
- 推导 RKL 的梯度
- 当采用类似于 PPO 或 GRPO 的技术时,RKL 目标及其梯度为:
$$
\mathcal{J}_{\text{RKL} }(\theta) = \mathbb{E}_{q\sim Q,\alpha \sim \pi_{\theta_{\text{old} } }(\cdot |q)}\left[\frac{1}{|\alpha|}\sum_{t = 1}^{|\alpha |}\rho_{t}(\theta)R_{t}(\theta)\right] \tag {11}
$$- 其中 \( \rho_{t}(\theta) = \frac{\pi_{\theta}(o_{t}|q,o_{< t})}{\pi_{\theta_{\text{old} } }(o_{t}|q,o_{< t})} \) 且 \( R_{t}(\theta) = \log \frac{\pi_{T}(o_{t}|q,o_{< t})}{\pi_{\theta}(o_{t}|q,o_{< t})} \)
- 则以下关系成立:
$$
\begin{align}
&{\nabla_{\theta}\mathcal{J}_{\text{RKL} }(\theta)=\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta_{\text{old} } }(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\rho_{t}(\theta)\nabla_{\theta}R_{t}(\theta)+R_{t}(\theta)\nabla_{\theta}\rho_{t}(\theta)\right],}\\
&{\quad=\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta_{\text{old} } }(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\rho_{t}(\theta)R_{t}(\theta)\nabla_{\theta}\log\pi_{\theta}(\alpha|q,\alpha_{< t})\right]-\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta_{\text{old} } }(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\frac{\nabla_{\theta}\pi_{\theta}(\alpha|q,\alpha_{< t})}{\pi_{\theta_{\text{old} } }(\alpha|q,\alpha_{< t})}\right],}\\
&{\quad=\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta_{\text{old} } }(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\rho_{t}(\theta)R_{t}(\theta)\nabla_{\theta}\log\pi_{\theta}(\alpha|q,\alpha_{< t})\right]-\nabla_{\theta}\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta_{\text{old} } }(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\frac{\pi_{\theta}(\alpha|q,\alpha_{< t})}{\pi_{\theta_{\text{old} } }(\alpha|q,\alpha_{< t})}\right],}\\
&{\quad=\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta_{\text{old} } }(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\rho_{t}(\theta)R_{t}(\theta)\nabla_{\theta}\log\pi_{\theta}(\alpha|q,\alpha_{< t})\right]-\nabla_{\theta}\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta}(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\frac{\pi_{\theta}(\alpha|q,\alpha_{< t})}{\pi_{\theta_{\text{old} } }(\alpha|q,\alpha_{< t})}\right],}\\
&{\quad=\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta_{\text{old} } }(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\rho_{t}(\theta)R_{t}(\theta)\nabla_{\theta}\log\pi_{\theta}(\alpha|q,\alpha_{< t})\right]-\nabla_{\theta}\mathbb{E}_{q\sim Q,\alpha\sim\pi_{\theta}(\cdot|q)}\left[\frac{1}{|\alpha|}\sum_{t=1}^{|\alpha|}\frac{\pi_{\theta}(\alpha|q,\alpha_{< t})}{\pi_{\theta_{\text{old} } }(\alpha|q,\alpha_{< t})}\right],}
\end{align} \tag {19}
$$
- 当采用类似于 PPO 或 GRPO 的技术时,RKL 目标及其梯度为:
- 推导结果表明:
- 优化 RKL 目标在数学上等价于最大化一个标准的策略梯度目标,其中优势由项 \( R_{t}(\theta) \) 给出,并由重要性采样比率 \( \rho_{t}(\theta) \) 加权
- 问题:要忽略后面的梯度时才可以吧
A.2. Derivation of Clipping Threshold,裁剪阈值的推导
- 本节推导用于激励裁剪阈值的标准对数似然比与凸混合比之间的关系
- 由于对数是一个凹函数,对于 \( \forall \lambda \in [0,1) \),詹森不等式意味着:
$$
(1 - \lambda)\cdot \log \pi_{T}(o_{t}|q,o_{< t}) + \lambda \cdot \log \pi_{\theta}(o_{t}|q,o_{< t})\leq \log [(1 - \lambda)\cdot \pi_{T}(o_{t}|q,o_{< t}) + \lambda \cdot \pi_{\theta}(o_{t}|q,o_{< t})] \tag {20}
$$ - 为了分离出对数似然比 \( R_{i,t}(\theta) = \log \frac{\pi_{T}(o_{t}|q,o_{< t})}{\pi_{\theta}(o_{t}|q,o_{< t})} \),作者从两边减去 \( \log \pi_{\theta}(o_{t}|q,o_{< t}) \) 并除以 \( (1 - \lambda) \):
$$
R_{i,t}(\theta) = \log \frac{\pi_{T}(o_{t}|q,o_{< t})}{\pi_{\theta}(o_{t}|q,o_{< t})}\leq \frac{1}{1 - \lambda}\log \frac{(1 - \lambda)\pi_{T}(o_{t}|q,o_{< t}) + \lambda\pi_{\theta}(o_{t}|q,o_{< t})}{\pi_{\theta}(o_{t}|q,o_{< t})} \tag {21}
$$ - 该不等式将教师策略和学生策略之间的对数比的上界定为由两者凸混合所诱导的对数比
Comparison to \( \rho (\theta) \) clipping in RL
- 如第 4.1 节所述,裁剪操作最初是在 PPO (2017) 中引入的,目的是通过约束策略更新来稳定优化
- 本文在 OPD 环境中研究了这种重要性权重裁剪的有效性
- 如图 10 所示,在整个训练过程中,被裁剪样本的比例微乎其微,在初始步骤之后始终低于 \( 0.2% \)
- 这表明策略并未显著偏离行为策略,使得裁剪机制在很大程度上是多余的,尤其是在训练的初始阶段之后
- 与标准 RL 任务相比,\( \rho (\theta) \) 裁剪的稳定效果微乎其微
- 注意:这里作者的理解似乎有误, PPO 也只是在 Off-policy 场景下使用,而且是针对上一步的旧策略和新策略进行的,目的是实现近端优化,跟当前教师与学生之间的 Ratio 没啥关系
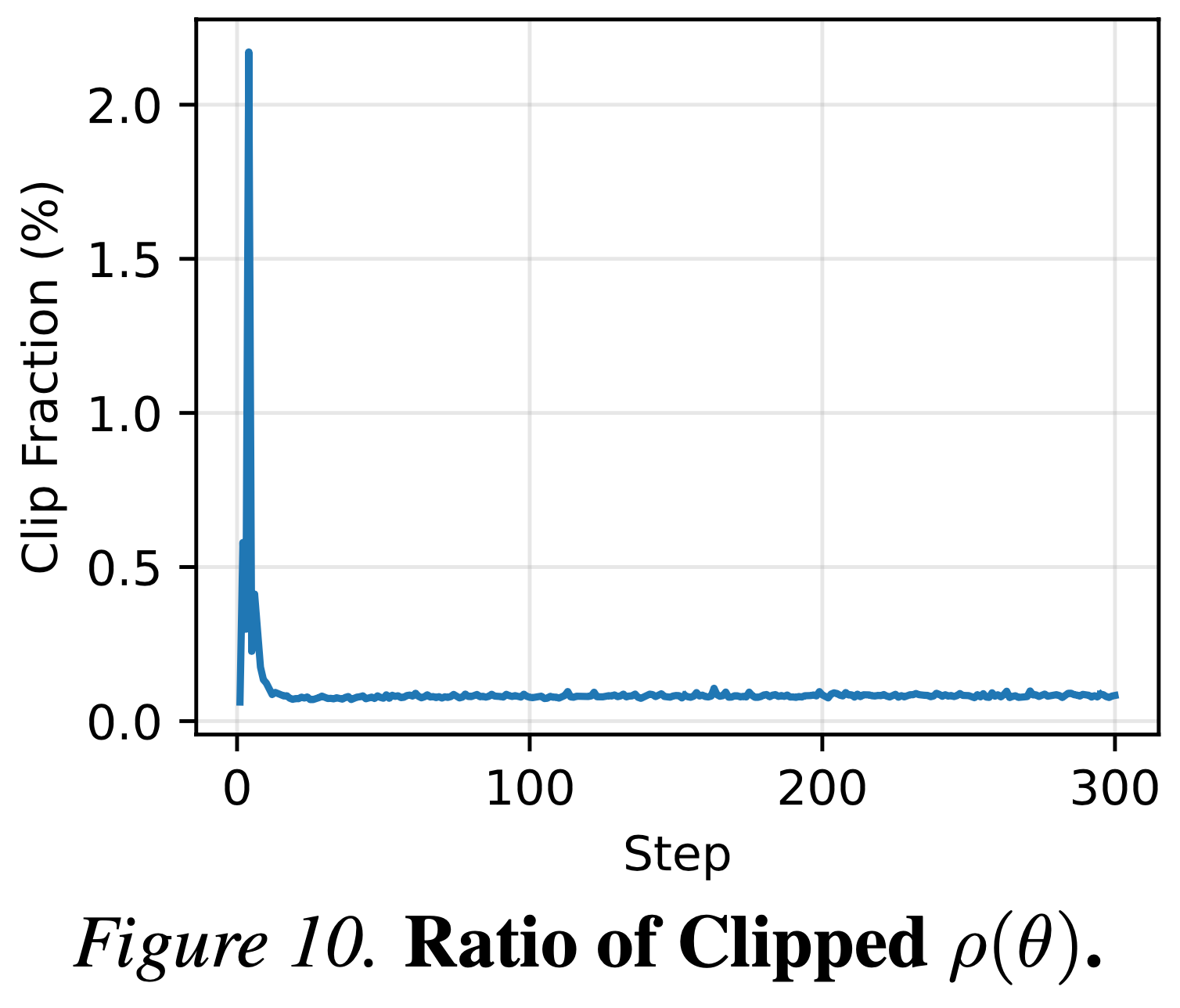
- 这与图 4 中显示的奖励分布形成对比,该分布在负区域呈现出 heavy-tailed 特征,如果不加以处理,罕见的极端值可能会主导梯度
Comparison to Skew RKL(2024)
- 等式 (20) 的右侧与 Skew RKL (2024) 相同,但 REOPOLD 在应用上有所不同,本文严格地将界限 \( \frac{\log \lambda}{1 - \lambda} \) 用作裁剪阈值,而不是修改全局目标
- 图 11 表明,虽然 Skew RKL 对 \( \lambda \) 高度敏感(例如,在 \( \lambda = 0.7 \) 时显著下降),但 REOPOLD 仍然稳健
- 本文的最低准确率甚至超过了 Skew RKL 的峰值性能
- 这证实了选择性地裁剪 heavy-tailed 离群值比改变全局散度更能有效地稳定训练
- 这证实了选择性地裁剪 heavy-tailed 离群值比改变全局散度更能有效地稳定训练
附录 B:Additional Related Work
Policy optimization for reasoning models
- 近期在策略优化方面的进展集中在提高 LLM 的样本效率、稳定性和推理深度上
- 虽然最初的方法依赖于基于结果的 RL,最近的工作表明,在较小的架构上扩展 RL,如 DeepScaleR (2025) 和 Skywork OpenReasner (2025a) 所示,可以达到与 OpenAI-o1 等专有前沿模型相媲美的性能
- 改善超越基本群组相对更新的算法稳定性:
- GSPO (2025) 引入了步骤级别的粒度以实现精确的信用分配
- GMPO (2025) 则采用了群组最小最大公式来增强对分布偏移的鲁棒性
- KDRL (2025) 提出了一个统一框架,协同知识蒸馏和 RL,有效地平衡了教师监督和自我探索
- 解决探索与利用之间的关键平衡问题
- 熵机制 (2025) 动态调节策略熵以防止过早收敛
- LUFFY (2025) 通过有效利用多样化的 off-policy 轨迹来提高优化效率
- ProRL (2025a) 强调了生成扩展推理链的重要性,明确激励延长思考过程以扩展模型的推理边界,这种能力支撑了最先进的大规模系统,如 MiniMax-M1 (2025a)
On-policy distillation for reasoning models
- 传统的知识蒸馏通常依赖于教师模型生成的离线数据集,这会由于学生策略偏离静态训练数据而产生分布不匹配 (2023; 2023; 2025b)
- For 弥补这一差距:
- OPD 通过直接在从学生当前策略采样的轨迹上进行训练,使学生与教师的分布对齐 (2024; 2024; 2024)
- 这种范式对于推理任务尤其重要,因为模型必须学会从自身的逻辑错误中恢复,而不仅仅是模仿完美的教师路径 (2025; 2025)
- 越来越多的工作致力于使 OPD 适应推理任务
- 前沿模型如 Qwen3 (2025) 利用迭代的同策略反馈来细化长链推理能力
- MiMo-V2-Flash (2026) 证明,此类方法通过针对学生置信度与教师出现分歧的“困难”样本,实现了卓越的计算效率
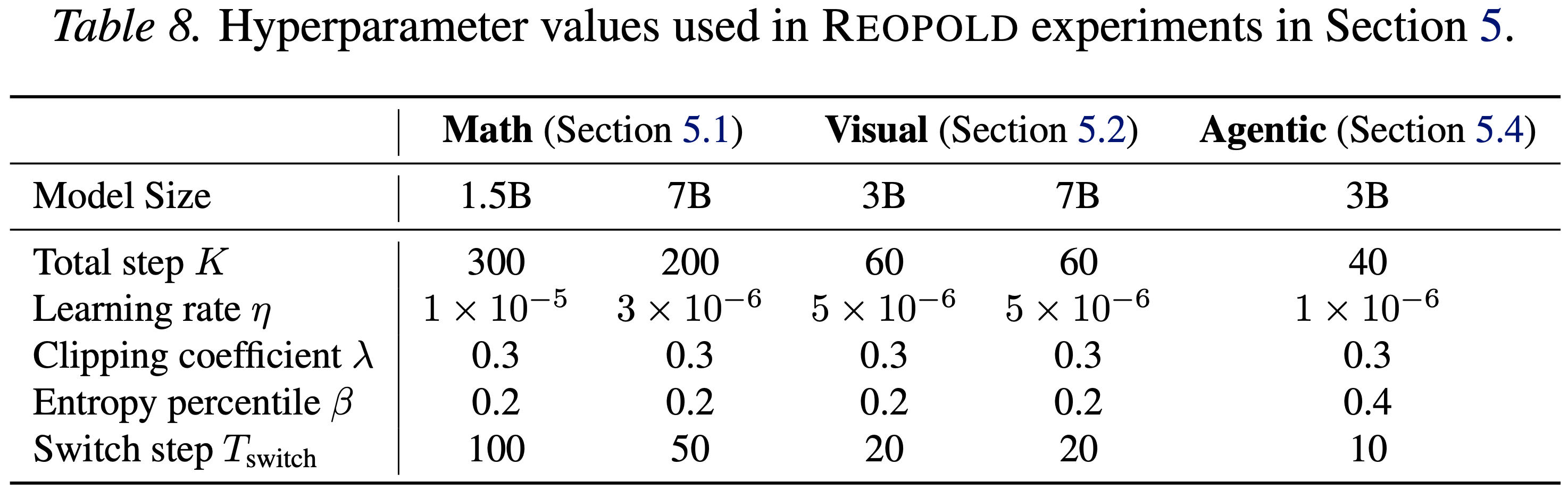
附录 C:Detailed Experimental Setup
- 第 5 节详细介绍了实验设置
- 表 8 中列出了每种设置的超参数值
- 对附加超参数 \( \lambda \) 和 \( \rho \) 的敏感性分析分别在图 11 和图 8 中给出
- 关于第 4.3 节中引入的切换步数 \( T_{\text{switch} } \),没有执行特定的超参数调整;而是将其设置为大约总训练步数的 \( 1 / 3 \)
- 对于 \( K \) 和 \( \eta \),本文采用了与基线相同的值,其中 \( \eta \) 是基于 vanilla RKL 结果通过超参数调整确定的
Math reasoning
- 使用 Verl (2025) 进行 OPD
- 在 Rollout 期间
- 为每个 Prompt 采样 \( n = 8 \) 个 Response,最大 Response 长度为 8192,采样温度为 1.0
- 全局批次大小设置为 128,微批次大小为 32,相当于每个 Rollout 步进行 4 次梯度更新
- 学生策略训练 300 次迭代
- 使用 AdamW 优化器 (2019),恒定学习率为 \( 1 \times 10^{- 5} \)
- 所有训练运行均在配备 \( 8 \times \) NVIDIA H100 80GB GPU 的单节点上进行,1.5B 和 7B 模型分别需要大约 200 和 312 GPU 小时
- 对于评估
- 使用最大 Response 长度 32768,采样温度 0.6 和 top-p 0.95
- 评估协议遵循 Qwen2.5-Math (2024) 建立的设置,使用 Verl (2025) 进行实现
- 使用来自 LUFFY (2025) 的训练和评估数据
Visual reasoning
- 对于视觉任务,使用 Verl (2025) 进行 OPD
- 为每个 Prompt 生成 \( n = 12 \) 个 Response,强制最大 Response 长度为 2048,采样温度为 1.0
- 遵循 Liu 等人 (2025b) 的协议
- 模型训练 60 次迭代,批次大小为 128,微批次大小为 64(相当于每步 2 次梯度更新)
- 通过 AdamW (2019) 进行优化,学习率为 \( 5 \times 10^{- 6} \)
- 使用相同的硬件配置(单个 \( 8 \times \) NVIDIA H100 节点),3B 和 7B 模型的训练分别需要大约 20 和 24 GPU 小时
- 对于评估,使用最大 Response 长度 8192,采样温度 0.6 和 top-p 0.95 进行 nucleus 采样
- 使用来自 NoisyRollout (2025b) 的训练和数据
Agentic reasoning with visual tool-use
- 基于 VerlTool 框架 (2025) 实现了 OPD 和 RL
- 对于 Rollout
- 策略为每个 Prompt 采样 \( n = 8 \) 个轨迹,最大 Response 长度为 8192,温度为 1.0
- 将最大轮次设置为 2
- 保持批次大小为 128,微批次大小为 64,对应于每个 Rollout 步进行 2 次梯度更新
- 学生策略使用 AdamW 优化器 (2019) 进行 40 次迭代训练,恒定学习率为 \( 1 \times 10^{- 6} \)
- 整个过程在配备 \( 8 \times \) NVIDIA H100 80GB GPU 的单节点上消耗大约 120 GPU 小时
- 遵循 Su 等人 (2025) 的方法,将最大轮次设置为 5,最大 Response 长度为 8192,采样温度为 1.0,top-p 为 1.0
- 对于训练,使用 PixelReasoner-RL 数据集
- 对于评估,使用 PixelReasoner (2025) 提供的 InfoVQA、TallyQA 和 VStar 数据集
附录 D:Additional Analyses and Discussions
- 本节提供全面的分析,以更深入地理解 REOPOLD 的内部工作机制和鲁棒性
- 除非另有说明,所有实验均遵循第 5.2 节中介绍的视觉推理评估协议
Extended test-time scaling results
- 在 Geometry3K (2021) 和 MathVerse (2024a) 基准上对 REOPOLD 的测试时扩展能力进行了全面评估
- 图 12 表明
- REOPOLD 的卓越扩展性并不局限于覆盖率指标 (Pass \( @K \))
- 3B 和 7B 模型在 Maj \( @K \)(衡量共识鲁棒性的指标)上都保持着持续的领先优势
- 这证实了 REOPOLD 从根本上提高了正确推理链的概率,而不仅仅是生成多样化的“幸运猜测”来提升 Pass \( @K \)
- 图 12. Extended results of Figure 1(b)
- 可视化了随着样本预算 \( K \) 增加(Geometry3K 最高到 64;MathVerse 最高到 16),准确率 (Pass \( @K \) 和 Maj \( @K \) ) 与推理延迟的关系
- REOPOLD(实线)始终比 RKL 基线(淡线)产生更好的权衡
- 7B 学生以显著更低的延迟匹配或超越了 32B 教师的准确率,证实了 REOPOLD 蒸馏的效率
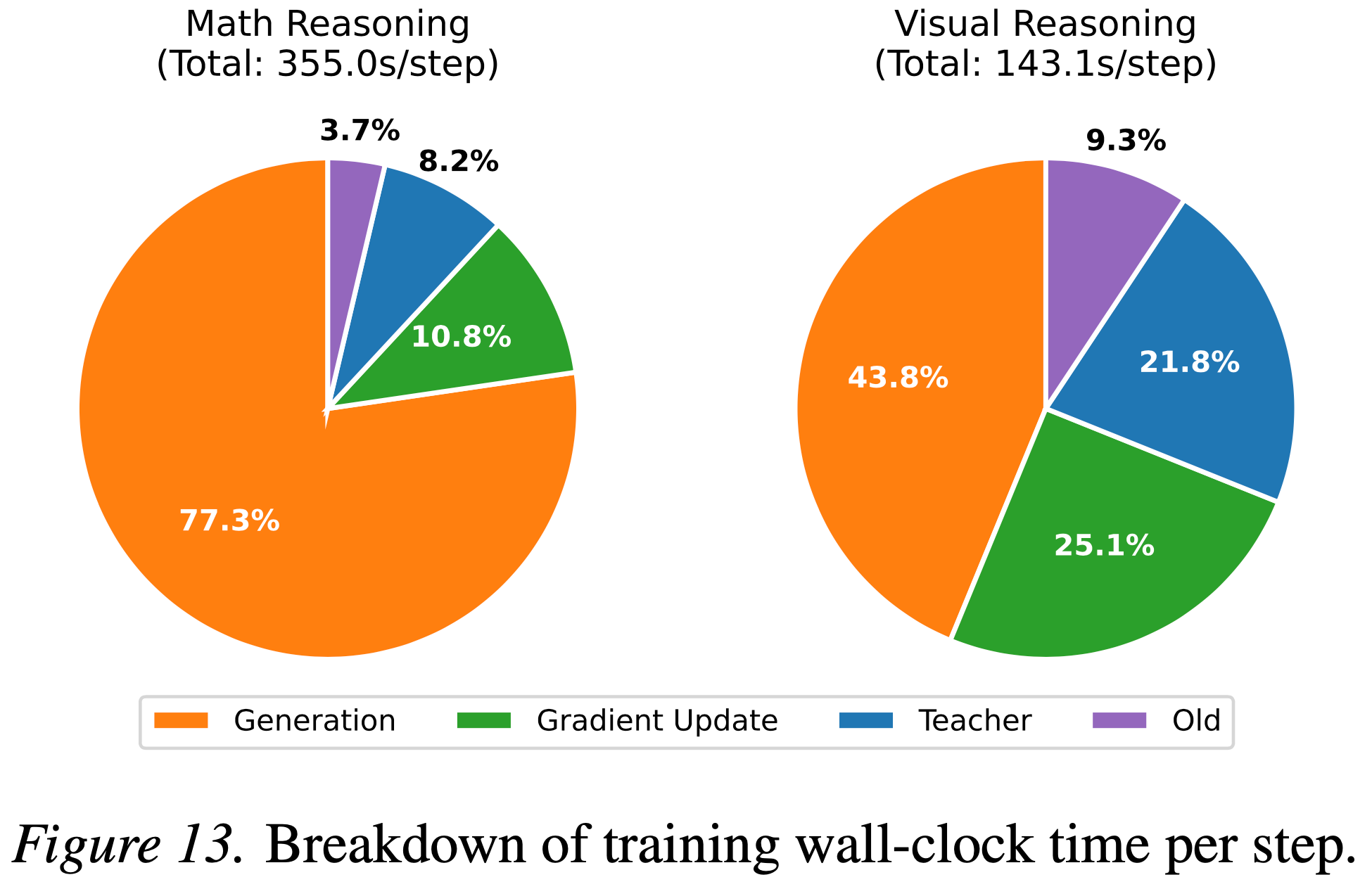
Training time analysis
- 本节分析了训练 wall-clock 时间以量化计算开销,如图 13 所示
- 与关于 OPD 中教师成本的担忧相反,分解显示它仅占总步数的一小部分 (\( 8% - 22% \))
- 这种相对成本与生成长度成反比。在长上下文数学任务 (8192 tokens) 中,学生生成占运行时间的主导地位 (\( 77.3% \)),使得教师的影响微乎其微 (\( 8.2% \))
- 即使在较短的视觉推理任务 (2048 tokens) 中,教师的份额上升到 \( 21.8% \),主要瓶颈仍然是学生的生成过程,而不是教师的监督
- 图 13. 每一步的训练 wall-clock 时间分解 (Breakdown of training wall-clock time per step)
Comparison to full vocabulary distillation
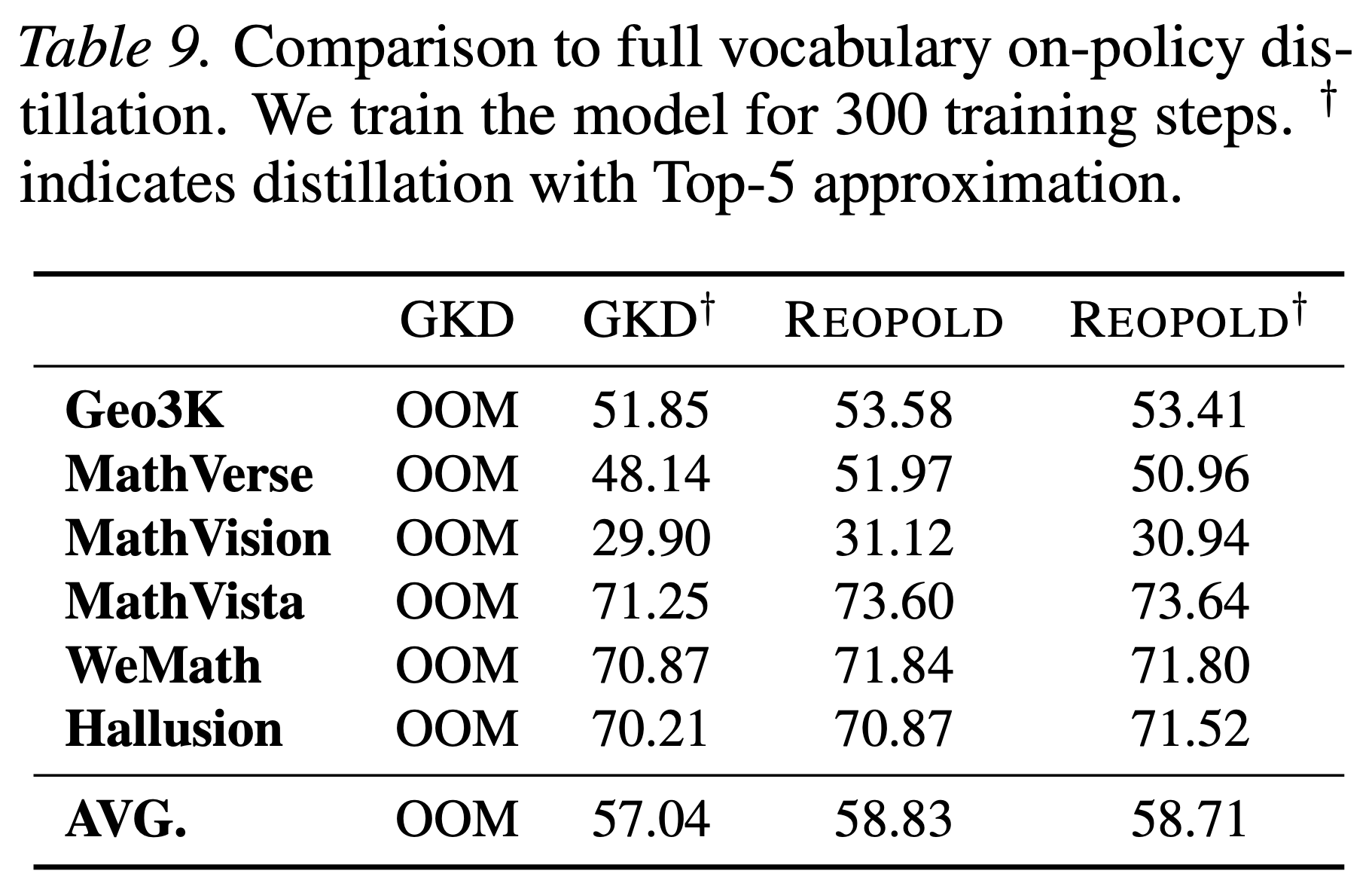
- 本节将 REOPOLD 与 GKD (2024) 进行了进一步比较
- GKD 是一种完整词表的 OPD
- 如表 9 所示,具有完整词表的 GKD 会遇到内存不足 (OOM) 问题,因为它们需要为学生模型和教师模型存储 150K 词表大小的值
- 为了缓解这个问题,本文应用了常用的 Top-5 近似(但这种近似效果不佳,与基于采样 Token 的方法相比效率较低)
- 即使应用于 REOPOLD,使用完整词表或应用 Top-5 近似也没有带来任何有意义的改进 ,表明这种近似对 REOPOLD 也没有益处
- 理解:其实 DeepSeek 中所强调的,使用全词表或更多 Top-K Token 估计 KL 的话,能得到更稳定的更新
附录 E:Qualitative Evaluation
- 定性评估 详情见原文