注:本文包含 AI 辅助创作
Paper Summary
- 整体总结:
- 本文提出了新方法 OPSD(On-Policy Self-Distillation)
- 无需外部 Teacher 模型 ,也无需奖励建模 ,仅利用模型自身的生成和评估能力进行自我提升
- 显著提升样本效率 :比 GRPO 节省 8–12 倍生成 token(推测是奖励更密集导致)
- 一些认知:
- 成功的自蒸馏需要足够大的语言模型
- 在 On-policy 采样阶段生成更多 Token 以及使用全词表 Logit 蒸馏能带来更好的学习效果
- 本文提出了新方法 OPSD(On-Policy Self-Distillation)
- 问题提出:
- 现有 RLVR 方法(如 GRPO)存在一些问题:
- 样本效率低(每组需生成多个回复)
- 奖励稀疏(仅 Sequence-level 反馈)
- 梯度消失(当所有样本都对或错时)
- 注:这里将 GRPO/PPO 等与 RLVR 强绑定描述非常奇怪,RLVR 更像是描述一类具有 Variable Reward 的 RL 信号建模方法,并不太适合描述为一个具体的 RL 训练方法
- 本文中存在大量将 RLVR 和 GRPO 的方法等价来描述的错误措辞,需要小心辨别
- 传统知识蒸馏:通过压缩 Teacher LLM 的知识来训练较小的 LLM
- 依赖外部 Teacher 模型,存在分布偏移问题
- On-policy 蒸馏:通过让 Student 模型采样自己的轨迹,同时 Teacher LLM 提供密集的 Token-level 监督,解决 Off-policy 蒸馏方法中训练和推理之间的分布不匹配问题
- On-policy 蒸馏通常需要一个单独的、通常更大的 Teacher LLM,并且没有明确 利用推理数据集中的 ground-truth 的解决方案
- 现有 RLVR 方法(如 GRPO)存在一些问题:
- Insight:一个足够强大的推理 LLM(Student)在看到正确答案后,可以理解并修正自己的错误
- 可让 LLM 利用外部信息教导较弱的自身(即无法外部信息的版本)
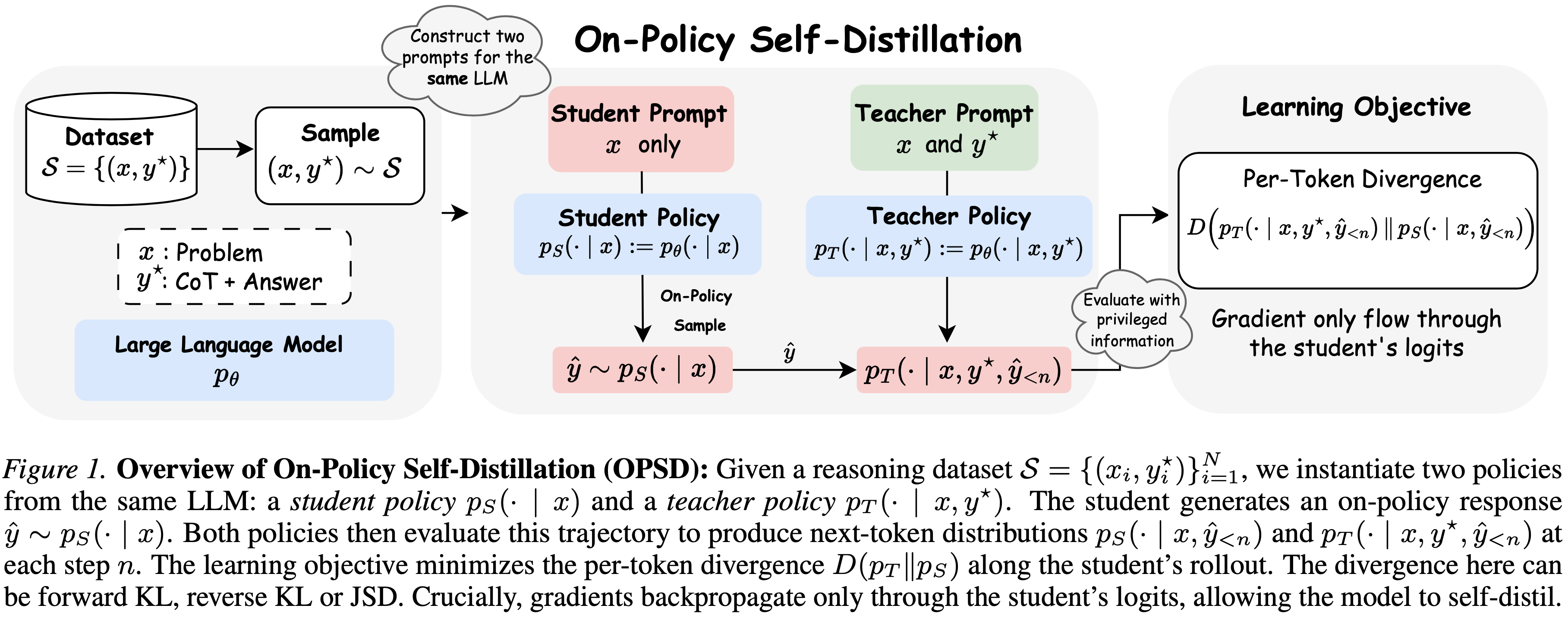
- On-policy Self-Distillation (OPSD) 核心思路:
- 让同一个模型同时扮演 Teacher 和 Student ,通过不同的上下文条件生成不同的分布,并在 Student 自己的生成轨迹上进行逐 token 的分布匹配
- 给定一个数据集 \(\mathcal{S} = \{(x_i, y_i^*)\}\),其中 \(x\) 是问题,\(y^*\) 是参考答案(包括推理过程)
- Student 策略 :\(p_S(\cdot | x)\),仅基于问题生成答案
- Teacher 策略 :\(p_T(\cdot | x, y^*)\),基于问题和参考答案生成答案
- 两者共享模型参数 \(\theta\),仅输入不同
- 基本思路:从 Student 策略采样, Student 生成一个回答,然后逐 token 分布匹配
- OPSD 算法流程总结
- Step 1:初始化模型参数 \(\theta\)
- Step 2:对每个样本 \((x, y^*)\):
- Student 生成回答 \(\hat{y} \sim p_S(\cdot | x)\)
- 对每个token位置 \(n\):
- 计算 Teacher 分布 \(p_T(\cdot | x, y^*, \hat{y}_{<n})\)
- 计算 Student 分布 \(p_S(\cdot | x, \hat{y}_{<n})\)
- 计算分布差异 \(D\)
- 平均所有 token 的差异
- Step 3:反向传播更新 Student 策略( Teacher 策略不更新,梯度不流入 Teacher )
$$
\mathcal{L}_{\mathrm{OPSD} }(\theta) = \mathbb{E}_{(x,y^*)\sim \mathcal{S} } \mathbb{E}_{\hat{y} \sim p_S(\cdot | x)} \left[ \frac{1}{|\hat{y}|} \sum_{n=1}^{|\hat{y}|} D\big(p_T | p_S\big) \right]
$$ - Step 4:重复直到收敛
- SDPO vs OPSD(本文) 方法:
- 除了 OPSD 强调信号来自已有数据集 \(\mathcal{D}\) 的参考答案外,OPSD 几乎和 SDPO 思路一致,都是 On-policy 蒸馏的
- SDPO 强调外部评估环境信号
- 实际上,在 SDPO 原始论文的表 2 中可以看到:如果存在正确 Rollout 的话,Teacher 的 Prompt 中可能会包含之前生成的正确 Rollout 作为 Hint
- OPSD 强调参考答案 \(y^*\),类似 SFT 的样本(注意:OPSD 要求包含的参考答案 \(y^*\) 是原始数据集中必须存在的,不是 Student 也不是 Teacher 生成的)
- 两者算法上几乎没有差异(两篇文章几乎同时发出 20260126 vs 20260128,算是并发的工作,OPSD 引用了 SDPO )
- 总结来说:两者核心区别在于 hint 信号不同:
- OPSD 更强调仅使用自身(能生成至少一次正确答案的自身)模型,数据集必须包含参考答案 \(y^*\)(类似 SFT 的样本)
- SDPO 则强调外部评估信号的引入(数据集中只需要 Query,不需要参考答案 \(y^*\),但需要外部评估的反馈信号)
Introduction and Discussion
- 已有各种方法的缺点:
- RLVR(如 GRPO/PPO 等): 存在效率低下的问题,包括:
- (1) 为每个 Prompt 采样一组 Response 在计算上代价高昂,并且可能在估计真实价值函数时引入高方差
- 当所有样本都是正确或错误时,梯度信号会消失
- (2) 奖励信号是稀疏的,并且统一应用于生成输出的所有 token,忽略了细粒度的 Token-level 反馈
- (1) 为每个 Prompt 采样一组 Response 在计算上代价高昂,并且可能在估计真实价值函数时引入高方差
- 监督微调:
- 存在曝光偏差 (训练的前缀往往是当前策略不会生成的)
- 泛化能力较弱 (跟曝光偏差也有关系,数据本身受限于固定的数据)
- 传统的知识蒸馏: 提供了来自 Teacher 模型的密集 Token-level 监督
- 但依赖于 Off-policy 数据 (2015)
- On-policy 蒸馏: 让 Student 模型采样自己的轨迹,Teacher 策略提供密集的 Token-level 监督
- 通过结合 On-policy 训练的现实分布特性和密集反馈,展示了卓越的样本效率 (2024; 2025)
- RLVR(如 GRPO/PPO 等): 存在效率低下的问题,包括:
- On-policy 蒸馏很好,但需要有一个一个独立与于 Student 的,比 Student 更好的 Teacher 模型来监督 Student
- 理解:On-policy 蒸馏对 Teacher 模型的要求很高,必须要求 Teacher 模型比 On-policy 好许多才行
- 研究问题提出:一个模型能否通过自蒸馏有效地充当自己的 Teacher ?
- 受到人类学习的启发:在错误地解决一个问题后,Student 可以检查正确的解决方案,解释其步骤,并找出自己推理失败的地方
- 先前研究表明,对于 LLM 来说,评估通常比生成更容易 (2024; 1996)
- 本文作者假设,解释(对一个给定正确答案进行说明)同样比生成更容易
- 吐槽:这么随意的吗?
- 本文将 Teacher 和 Student 策略从一个单一的 LLM 中实例化
- Teacher 策略被提供了 Privileged 信息 \(y^*\)
- 例如 ground-truth 答案或参考思维链
- Teacher 策略 \(p_T(\cdot |x,y^*)\) 同时基于问题和 Privileged 答案进行条件设定
- Student 策略仅基于问题 \(x\) 进行条件设定
- Student 策略 \(p_S(\cdot |x)\) 仅观察问题
- Teacher 策略被提供了 Privileged 信息 \(y^*\)
- 通过仅从 Student 策略采样轨迹 \(\hat{y}\) 来保留 On-policy 训练范式
- 然后 Student 策略从 Privileged Teacher 策略那里接收密集的 Token-level 监督
- 本文提出 On-policy Self-Distillation (OPSD) 框架
- 其中单个模型同时扮演 Teacher 和 Student 的角色
- Student 采样其自己的轨迹 \(\hat{y} \sim p_S(\cdot |x)\)
- 计算 Student 和 Teacher 分布之间的每个 token 的散度,并将其最小化于 Student 自己的 Rollout 之上
- 这个公式:
- (i) 使用了 On-policy 监督( Student 自己的轨迹)
- (ii) 提供了密集的每个 token 反馈
- (iii) 利用了 ground-truth 解决方案 \(y^*\)
- (iv) 不需要单独的 Teacher 模型
- 学习过程由损失函数描述
$$\mathcal{L}_{\text{OPSD} }(\theta) = \mathbb{E}_{(x,y^*)\sim \mathcal{S} }\mathbb{E}_{\hat{y}\sim p_S(\cdot |x)}\sum_{n = 1}^{|\hat{y}|}\ D\Big(p_T(\cdot |x,y^*,\hat{y}_{< n})\Big|\Big| p_S(\cdot |x,\hat{y}_{< n})\Big) \tag {1}$$
Background
Knowledge Distillation for Autoregressive Large Language Models
- 知识蒸馏通过训练 Student 模型模仿 Teacher 模型的行为,将知识从较大的 Teacher 模型转移到较小的 Student 模型 (2015;2016;2019)
- Teacher 模型在类别上的软概率分布包含了比硬标签更丰富的信息,因为 软概率分布 揭示了 Teacher 模型学习到的类别之间的相似性
- 对于自回归语言模型,给定一个数据集
$$ \mathcal{S} = \{(x,y^*)\}$$- \(x\) 表示输入
- \(y^*\) 是对应的参考输出
- 注意:这里 \( \mathcal{S}\) 跟后续的脚标 \(S\) 容易引起混淆,注意数据集是花体
- Teacher \(p_T\) 和 Student \(p_S\) 都定义了词表 \(\mathcal{V}\) 上的 Token-level 分布
- 传统的监督蒸馏最小化 Teacher 和 Student 分布之间的散度 \(D\),并在固定数据集上取平均:
$$\mathcal{L}_{\text{Supervised Distillation} }(\theta) = \mathbb{E}_{(x,y)\sim \mathcal{S} }[D(p_T| p_S)(y|x)] \tag {2}$$- 其中 \(D(p_T| p_S)(y|x)\) 衡量每个 token 的差异:
$$ D(p_T| p_S)(y|x) = \frac{1}{|y|}\sum_{n = 1}^{|y|}D(p_T(\cdot |y_{< n},x) || p_S(\cdot |y_{< n},x)) $$ - 但这种 Off-policy 方法存在分布不匹配的问题:
- Student 在自回归生成过程中遇到的部分序列 \(y_{< n}\) 与在固定数据集上训练时看到的序列不同,导致错误累积
- 其中 \(D(p_T| p_S)(y|x)\) 衡量每个 token 的差异:
- On-policy 蒸馏(OPD) (2024;2025;) 使用 Student 采样序列 \(\hat{y} \sim p_S(\cdot |x)\)
- 并从 Teacher 那里获得密集的 Token-level 反馈:
$$\mathcal{L}_{\text{On-Policy Distillation} }(\theta) = \mathbb{E}_{x\sim \mathcal{S} }[\mathbb{E}_{\hat{y}\sim p_S(\cdot |x)}[D(p_T| p_S)(\hat{y} |x)]] \tag {3}$$- OPD 将蒸馏与模仿学习联系起来
- OPD 中,Student 在 Student 自身的输出上学习 Teacher 的信号来迭代改进
- 这结合了 RL 的 On-policy 相关性和监督学习的密集奖励信号
- OPD 减轻了曝光偏差,同时保持了计算效率
- 并从 Teacher 那里获得密集的 Token-level 反馈:
RLVR:Reinforcement Learning with Verifiable Rewards
- RLVR 是 LLM 后训练的一种流行方法,特别是在数学和编程等结果易于验证的任务上
- RLVR 一般使用 PPO 和 GRPO 等算法
- GRPO 通过为每个问题 \(x\) 从当前策略 \(\pi_{\theta}\) 采样一组 \(G\) 个 Response \(\{o_1,o_2,\ldots ,o_G\}\) 来进行训练
- 每个 Response \(o_i\) 收到一个表示正确性的二进制奖励 \(r_i\in \{0,1\}\)
- 该方法使用一个组归一化的奖励为 Response \(o_i\) 内的所有 token \(k = 1,\ldots ,|o_i|\) 分配优势:
$$A_{i} = \frac{r_{i} - \text{mean}(\{r_{j}\}_{j = 1}^{G})}{\text{std}(\{r_{j}\}_{j = 1}^{G})} \tag {4}$$- 这个公式可以通过价值函数的角度来理解:
- \(\text{mean}(\{r_j\}_{j = 1}^G)\) 作为价值函数 \(V(x)\) 的 \(G\) 样本蒙特卡洛估计
- 稀疏的二进制奖励 \(r_i\) 代表(未折扣的)状态-动作价值 \(Q(x,o_i)\)
- 由于奖励信号仅在 Sequence-level 提供,一个 Response 内的所有 token 共享相同的优势
- 这个公式可以通过价值函数的角度来理解:
- GRPO 目标函数包含一个裁剪的替代损失以缓和策略更新,以及一个反向 KL 惩罚项以防止过度偏离参考策略:
$$\begin{align}
\mathcal{L}_{\text{GRPO} }(\theta) = \mathbb{E}_{x \sim \mathcal{S}, \{o_i\}_{i=1}^G \sim \pi_{\theta}(\cdot|x)} \left[\frac{1}{G}\sum_{i = 1}^{G}\frac{1}{|o_i|}\sum_{n = 1}^{|o_i|} \min (\rho_i^n A_i,\text{clip}(\rho_i^n,1 - \epsilon ,1 + \epsilon)A_i) -\beta D_{\text{KL} }[\pi_{\theta}(\cdot |x)||\pi_{\text{ref} }(\cdot |x)]\right] \end{align} \tag {5}$$- \(\rho_i^n = \frac{\pi_{\theta}(o_i^n|x,o_i^{< n})}{\pi_{\theta_{\text{old} } }(o_i^n|x,o_i^{< n})}\) 是重要性比率
- 其中的 \(\pi_{\theta_{\text{old} } }\) 是本轮更新前的策略
- \(\epsilon\) 控制裁剪范围
- \(\rho_i^n = \frac{\pi_{\theta}(o_i^n|x,o_i^{< n})}{\pi_{\theta_{\text{old} } }(o_i^n|x,o_i^{< n})}\) 是重要性比率
- RLVR 方法面临两个关键限制:
- (1) 奖励信号稀疏,仅提供 Sequence-level 反馈,而不是关于错误发生在哪里的 Token-level 指导
- (2) 当所有采样的 Response 收到相同的奖励(全部正确或全部错误)时,优势变为零
- 有采样成本,但无法进行任何策略更新
- 问题:作者这里将 GRPO/PPO 等与 RLVR 强绑定描述非常奇怪,RLVR 更像是描述一类具有 Variable Reward 的 RL 信号建模方法,并不太适合描述为一个具体的 RL 训练方法
Methods
Learning from Verifiable Reasoning Dataset
- 考虑一个问题-解决方案对的数据集
$$ \mathcal{S} = \{(x_i,y_i^*)\}_{i = 1}^N$$- \(x_i\) 表示一个问题
- \(y_i^*\) 是对应的参考解决方案(可能包含思维链推理)
- 为简洁起见,后续本文省略样本索引 \(i\),并使用 \((x,y^*)\) 表示数据集中的一个通用样本
- 可以通过不同方式利用这个数据集的学习信号:
- SFT: 在该数据集 \(\mathcal{S}\) 上进行标准的 SFT 可以看作是一种使用专家轨迹的 Off-policy 蒸馏/模仿学习
- 但 SFT 存在训练和推理之间的分布不匹配问题
- RLVR: 基于 RLVR 也可以
- 比如 GRPO 通过在 On-policy 样本上进行优化并通过将生成答案与 \(y^*\) 比较来分配二进制奖励来解决此问题
- 但 RLVR 计算代价高昂,并且奖励信号稀疏,无论错误发生在哪里,都为所有 token 提供相同的反馈
- 理解:这里的表述可以是对的,也可以是错的
- “对的” 理解方式:RLVR 中的 Reward 反馈确实是 Sequence-level 的
- 虽然 PPO 的 Advantage 是 Token-level 的,但是反馈也只是 Sequence-level 的,只是加了 KL 散度建模
- “错的” 理解方式:若将 PPO 每一步的 KL 散度理解为反馈,那么这里的所谓 RLVR 方法就是错的
- “对的” 理解方式:RLVR 中的 Reward 反馈确实是 Sequence-level 的
- 理解:这里的表述可以是对的,也可以是错的
- PRM 添加 Token-level 信号: 可以训练一个 PRM 在 RL 期间提供密集的 Token-level 反馈
- 但获取用于 PRM 训练的标签非常昂贵且难以扩展 (2023;2025)
- On-policy Distillation 方法 (2024;2025) 通过训练 Student 自身的样本来解决分布偏移问题
- 但需要一个单独的、通常更大的 Teacher 模型来提供监督
- SFT: 在该数据集 \(\mathcal{S}\) 上进行标准的 SFT 可以看作是一种使用专家轨迹的 Off-policy 蒸馏/模仿学习
- 本文作者寻求一种密集的、on-policy 的、不需要外部 Teacher 或奖励模型的训练信号
- 这引出了本文的 On-policy Self-Distillation 方法
- 表 1 中总结了这些方法的差异

On-Policy Self-Distillation
Motivation: Learning by understanding solutions,通过理解解决方案来学习
- 本文提出了一个受 Student 学习方式启发的不同视角:
- 当遇到难题时,与其进行长时间的试错,不如让 Student 可以检查解决方案,理解推理过程,并内化该方法
- 如果一个模型能够访问正确答案或推理过程 \(y^{*}\) 并且足够强大,它可以合理解释推理步骤并自我教导
- 这类似于 Student 复习一个解决方案并回溯其有效的原因
- 利用 ground-truth 解决方案 \(y^{*}\) 作为训练期间的 Privileged 信息,使模型能够在不需要外部奖励模型或更大 Teacher 模型的情况下充当自己的 Teacher
Teacher and student policies
- 通过改变条件上下文,从同一个语言模型 \(p_{\theta}\) 实例化两个条件分布
- Teacher 策略基于 Privileged 信息,即问题 \(x\) 和参考解决方案 \(y^{*}\) 进行条件设定:
$$p_{T}(\cdot |x,y^{\star})\triangleq p_{\theta}(\cdot |x,y^{\star}) $$ - Student 策略只观察问题陈述,与推理时的条件相匹配:
$$p_{S}(\cdot |x)\triangleq p_{\theta}(\cdot |x) $$ - Teacher 和 Student 策略共享相同的参数 \(\theta\),仅在条件上下文上有所不同
- 为了鼓励 Teacher 自然地评估 Student 的生成结果,添加了一个 Prompt
- 要求 Teacher 在看到参考解决方案后生成一个新的解决方案,如图 2 所示
- 注:Teacher 不会生成 token,它只是通过前向传播隐式地进行合理化

- 为了鼓励 Teacher 自然地评估 Student 的生成结果,添加了一个 Prompt
On-policy sampling from the student
- 给定一个问题 \(x\)
- Student 生成一个 On-policy Response
$$\hat{y} = (\hat{y}_1,\ldots ,\hat{y}_{|\hat{y}|})\sim p_S(\cdot |x) $$ - 让 Teacher 和 Student 都评估这个 Student 生成的轨迹
- 在每个位置 \(n\),基于相同的 Student 前缀诱导出下一个 token 的分布:
$$p_{S}(y_{n}\mid x,\hat{y}_{< n}),\qquad p_{T}(y_{n}\mid x,y^{\star},\hat{y}_{< n}) $$- 其中 \(\hat{y}_{< n} \triangleq (\hat{y}_{1}, \ldots , \hat{y}_{n - 1})\)
- Student 生成一个 On-policy Response
Training objective: Full-vocabulary logit distillation
- 本文实例化了一个全词表散度目标,该目标在每个位置上匹配 Teacher 和 Student 的下一个 token 分布
- 给定一个 Student 生成的序列 \(\hat{y}\),定义轨迹平均的、按 token 计算的散度为
$$D(p_{T}| p_{S})(\hat{y}\mid x)\triangleq \frac{1}{|\hat{y}|}\sum_{n = 1}^{|\hat{y}|}D\bigg (p_{T}(\cdot \mid x,y^{\star},\hat{y}_{< n})| p_{S}(\cdot \mid x,\hat{y}_{< n})\bigg) \tag {6}$$- \(p_S(\cdot \mid x,\hat{y}_{< n})\) 和 \(p_T(\cdot \mid x,y^*,\hat{y}_{< n})\) 表示下一个 token \(y_{n}\in \mathcal{V}\) 上的分布
- 这里,\(D\) 可以是任何分布散度度量(Forward/Reverse KL 或者 Jensen-Shannon Divergence (JSD) 等),例如广义 Jensen-Shannon 散度 \(\text{JSD}_{\beta}\),对于权重 \(\beta \in [0,1]\) 定义为:
$$\text{JSD}_{\beta}(p_{T}| p_{S}) = \beta D_{KL}(p_{T}| m) + (1 - \beta)D_{KL}(p_{S}| m) \tag {7}$$- 其中 \(m = \beta p_{T} + (1 - \beta)p_{S}\) 是插值混合分布
- 这种全词表公式提供了密集的、按 token 计算的反馈:
- 由 \(y^*\) 提供信息的 Teacher 将 Student 暴露在合理下一个 token 的整个分布中,并引导它走向能得出正确答案的推理路径
- 本人最小化 On-policy Student 样本上的 Teacher 和 Student 之间的期望散度:
$$\mathcal{L}(\theta) = \mathbb{E}_{(x,y^{\star})\sim \mathcal{S} }\left[\mathbb{E}_{\hat{y}\sim p_S(\cdot |x)}\left[D(p_T| p_S)(\hat{y}\mid x)\right]\right] \tag {8}$$ - 梯度仅通过 Student 策略 \(p_S\) 反向传播,而 Teacher \(p_T\) 作为一个固定的、基于 Privileged 信息 \((x,y^*)\) 的全分布目标
Per-Token Pointwise Divergence Clipping
- 本文实验观察到 Token-level 散度在词表条目上高度倾斜:
- 一小部分风格化 Token 的散度远高于具有数学意义的 Token(见表 5)
- 这种不平衡导致训练信号被风格化模式所主导
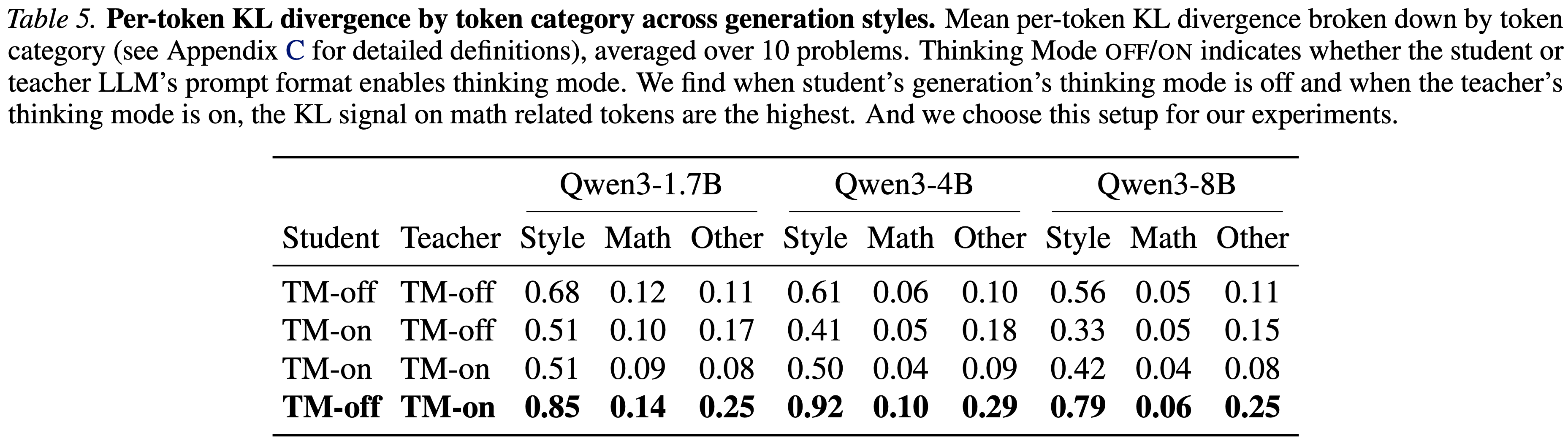
- 为了解决这个问题,本文对词表级别的散度贡献应用逐点裁剪
- 令 \(D_f(p_T | p_S)\) 表示一个 \(f\)-散度
- 在每个 Token 位置 \(n\) 和词表条目 \(v\) 上,定义:
$$
\ell^{(f)}_{n,v} = p_T(v \mid \cdot) f\left(\frac{p_S(v \mid \cdot)}{p_T(v \mid \cdot)}\right)
$$
- 计算裁剪后的散度:
$$
D^{(f)}_{\text{clip} }(p_T | p_S) = \frac{1}{|\hat{y}|} \sum_{n=1}^{|\hat{y}|} \sum_{v \in \mathcal{V} } \min(\ell^{(f)}_{n,v}, \tau)
$$
Alternative objective: Sampled-token distillation through policy gradient
- 本文 Follow 最近的 On-policy 蒸馏方法 (2025),构建了一个 Sample-token 奖励信号(关于采样动作的反向 KL 信号),并使用策略梯度进行优化
- 对于一个采样序列 \(\hat{y}\) 中的每个位置 \(n\),定义优势项
$$ A_{n}(x,\hat{y}) = \log p_{T}(\hat{y}_{n}\mid x,y^{\star},\hat{y}_{< n}) - \log p_{S}(\hat{y}_{n}\mid x,\hat{y}_{< n})$$ - 并优化策略梯度风格的目标函数
$$
\begin{align}
\mathcal{L}(\theta) = -\mathbb{E}_{(x,y^{\star})\sim \mathcal{S} }\left[\mathbb{E}_{\hat{y}\sim p_S(\cdot |x)}\left[\frac{1}{|\hat{y}|}\sum_{n = 1}^{|\hat{y}|}A_n(x,\hat{y}) \cdot \log p_S(\hat{y}_n\mid x,\hat{y}_{< n})\right]\right]
\end{align}
\tag {9}
$$- \(A_{n}(x,\hat{y})\) 被视为关于 \(\theta\) 的常数(即,梯度不会通过优势项流动),因此梯度采用通常的策略梯度形式 \(A_{n}\nabla_{\theta}\log p_{S}\)
- 与全词表散度目标相比,这个 On-policy 塑形目标仅对采样的 token 进行操作,利用 Teacher 的 log-probabilities 提供密集的、轨迹级的塑形信号,而无需在每一步显式匹配完整分布
OPSD as dense-reward policy gradient and comparison to STaR,OPSD 作为密集奖励策略梯度以及与 STaR 的比较
- 等式 (9) 中的目标可以看作是具有密集、 Token-level 奖励的策略梯度
- 在附录 C 部分,本文对此进行了形式化,并与 STaR (2022) 进行了对比
- STaR:
- 使用相同的模型生成推理轨迹,然后进行拒绝采样,随后对正确的轨迹进行 SFT
- 这个过程可以看作是具有 Sequence-level 二进制奖励的策略梯度,该奖励为所有 token 分配相同的信用,并在样本不正确时消失
- OPSD:
- 无论最终答案正确与否,OPSD 在每个 token 位置都提供反馈
- STaR:
Experiments
- 本文开展了全面的实验,旨在解答以下研究问题:
- (1) OPSD在推理性能和样本效率方面与SFT、GRPO相比表现如何?(§4.2)
- (2) OPSD中的逐 Token 点态KL裁剪(per-Token pointwise KL clipping)如何帮助稳定训练?(§4.3.3)
- (3) 生成风格、生成长度对模型性能有何影响?(§4.3.4)
- (4) 全词表logit蒸馏(full-vocabulary logit distillation)相比采样 Token 策略梯度(sampled-Token policy gradient)是否具备优势?(§4.3.5)
Experimental Setup
Models and datasets
- 本文基于 Qwen3 模型系列的三个参数量规模开展实验:Qwen3-1.7B、Qwen3-4B 和 Qwen3-8B
- 注:文中强调这里使用的是 instruct 微调版本,但实际上 Qwen3-8B 是没有 Thinking Mode 和 Non-Thinking Mode 在一起的
- 2507 出的 Qwen-4B 是有 Thinking 版本和 Instruct 版本的
- 训练数据:
- 本文会采用 OpenThoughts 数据集 (2025) 中的数学推理子集,抽取 30K 个包含思维链推理的问题-解决方案对
- Benchmarks
- 在 AIME 2024、AIME 2025 和 HMMT 2025
Baselines
- 在相同数据集上与两种方法进行对比:
- (1) SFT,即基于专家轨迹的标准有监督微调,可视为由生成推理轨迹的更强大LLM执行的离策略蒸馏
- (2) GRPO(2024),即结合基于真实答案验证的二值结果奖励的分组相对策略优化
- 最大生成长度设置为16k
Implementation details
- 将教师策略固定为初始策略,而非当前更新的学习策略
- 因为实验发现这一设置有助于稳定训练 ,且能隐式起到正则化作用,防止模型过度偏离初始策略 (这个理解不错)
- 实验中采用全词表 logit 蒸馏的方式
- 所有实验均在 A100 或 H100 GPU 上完成,并使用 LoRA 技术
- 注意:这里使用的是 LoRA
- 更多实验细节见附录B
Main Results
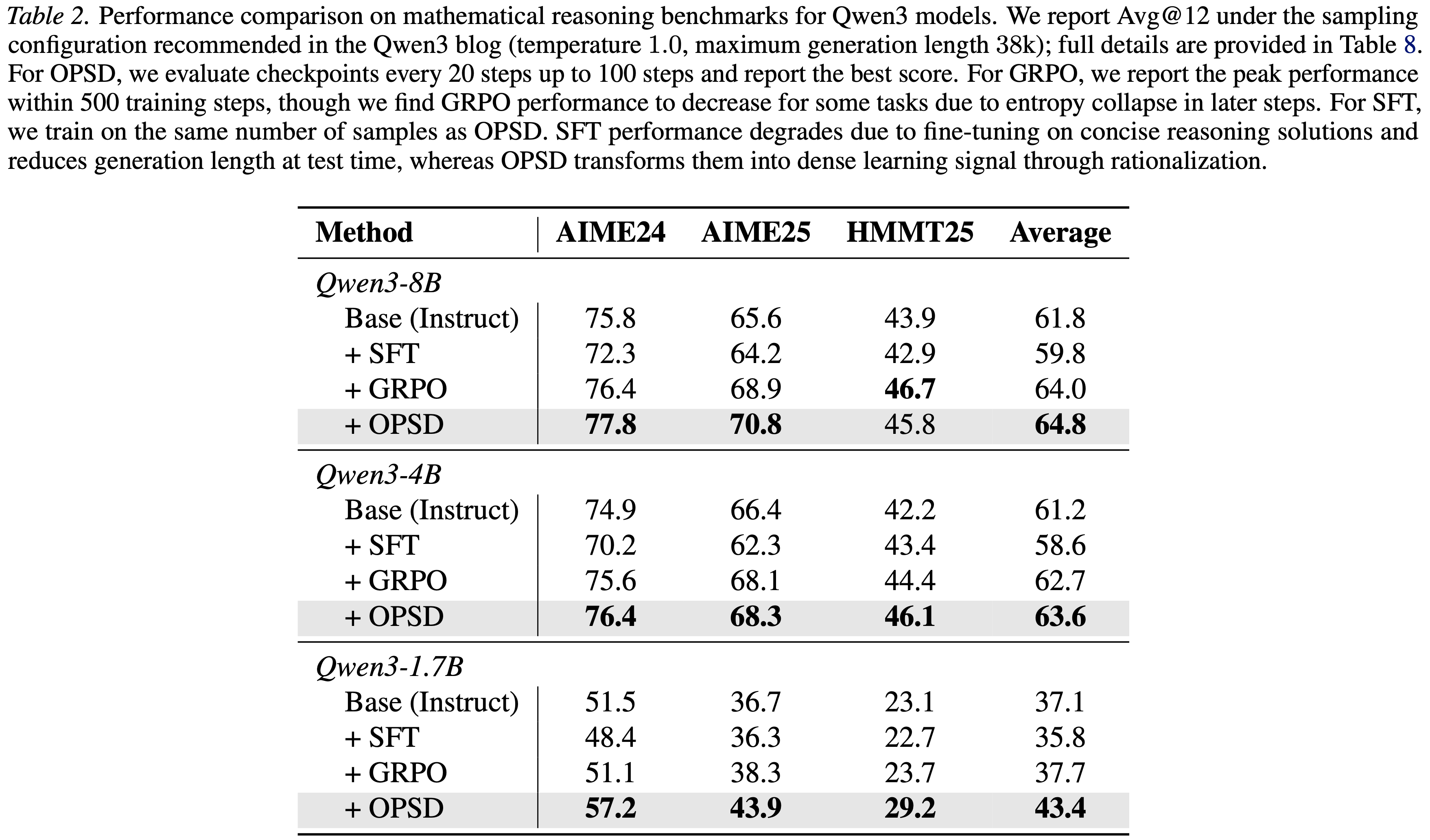
- 表 2:Qwen3 模型在数学推理基准数据集上的性能对比
- 按照 Qwen3 技术博客推荐的采样配置(温度值 1.0,最大生成长度 38k)报告
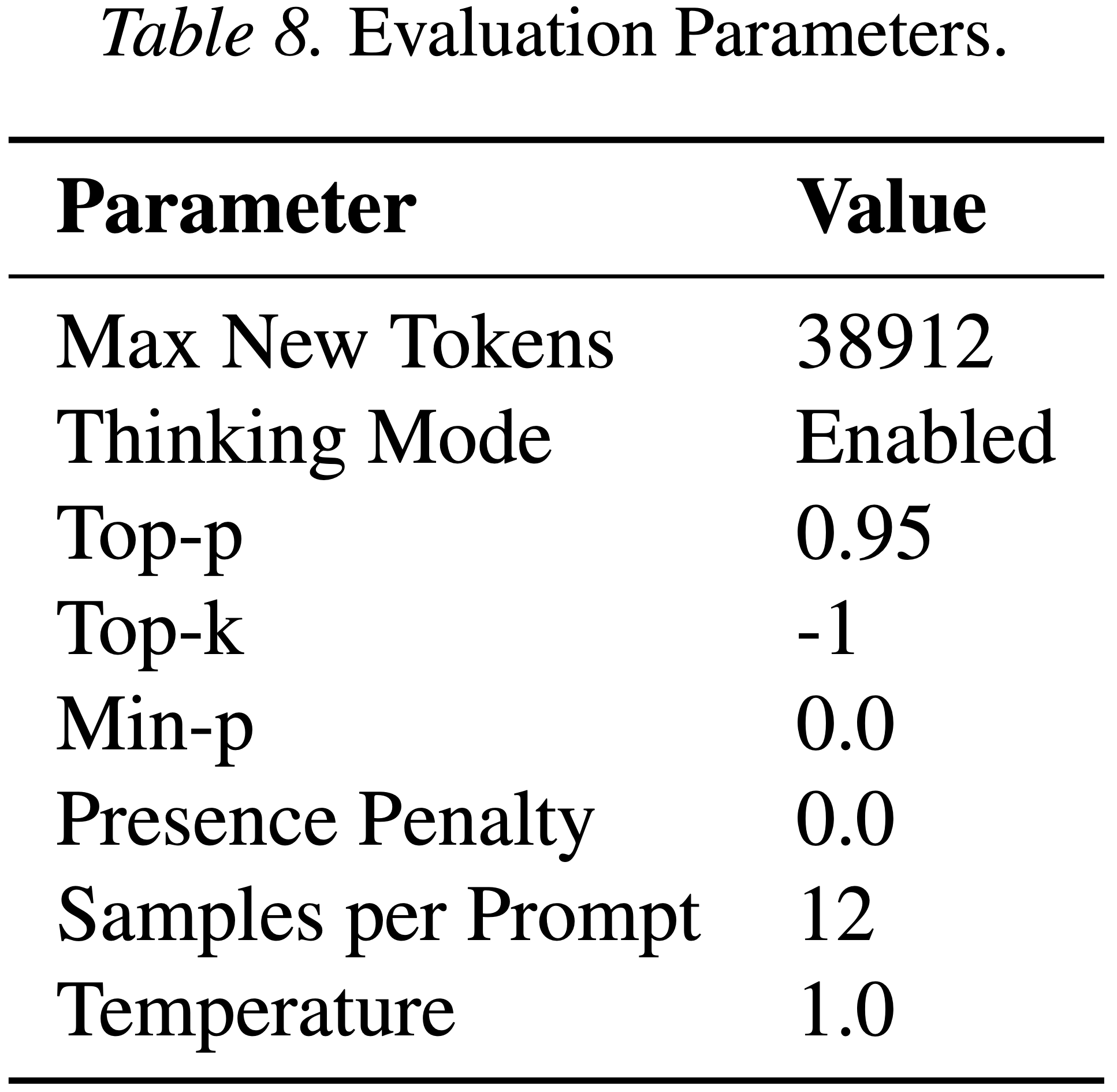
Avg@12指标;完整细节见 表 8 - 对于 OPSD,每 20 步评估一次模型检查点,直至 100 步,并报告最优分数
- 对于 GRPO,报告 500 步训练内的峰值性能(实验发现部分任务中 GRPO 的性能会因后期的熵坍缩出现下降)
- 对于 SFT,其训练样本量与 OPSD 保持一致
- SFT 的性能退化源于在简洁的推理解决方案上进行微调,导致模型测试阶段的生成长度缩短
- OPSD 则通过合理化(Rationalization)将这些解决方案转化为稠密的学习信号
- 按照 Qwen3 技术博客推荐的采样配置(温度值 1.0,最大生成长度 38k)报告
- 表 2 报告了在数学推理基准数据集上的实验结果
- 在所有模型规模下,OPSD 始终优于 SFT,且相比基础模型均有性能提升
- 在所有实验设置中 OPSD 均达到或超越 GRPO 的表现
- 效率方面:
- OPSD 仅对每个问题进行一次 rollout 即可实现上述性能提升
- 在 100 步内收敛
- 每个问题仅需采样 1024 个 Token
- 理解:传统的 RL 中不能这样做(这是 OPD 专有的优点)
- 在 OPD 场景中,不需要 Rollout 结束就可以有奖励(来源于 Teacher)
- 在传统 RL 场景,一般是需要 Rollout 结束才能得到 Reward 反馈的
- GRPO 对每个问题需要进行 8 次 Rollout
- 每次生成 16k 个 Token
- 后期还可能因熵坍缩出现性能退化
- 在该 OpenThoughts 数据集上,采样组内的奖励标准差大多为 0,导致模型无法获得学习信号,造成采样预算的浪费
- OPSD 仅对每个问题进行一次 rollout 即可实现上述性能提升
- 其他观察,在相同数据集上训练时
- SFT 在所有任务和模型规模下均出现一致的性能退化
- 这一现象可归因于真实标签解决方案的推理风格简洁,导致模型在测试阶段的生成长度缩短
- 一些推测:
- OPSD 的 Token 效率得益于教师分布提供的稠密 Token-level 监督
- 同时作者推测 :前序 Token 可能对有效蒸馏的贡献更大(因为这些 Token 可能代表了推理过程中更关键的分支节点)
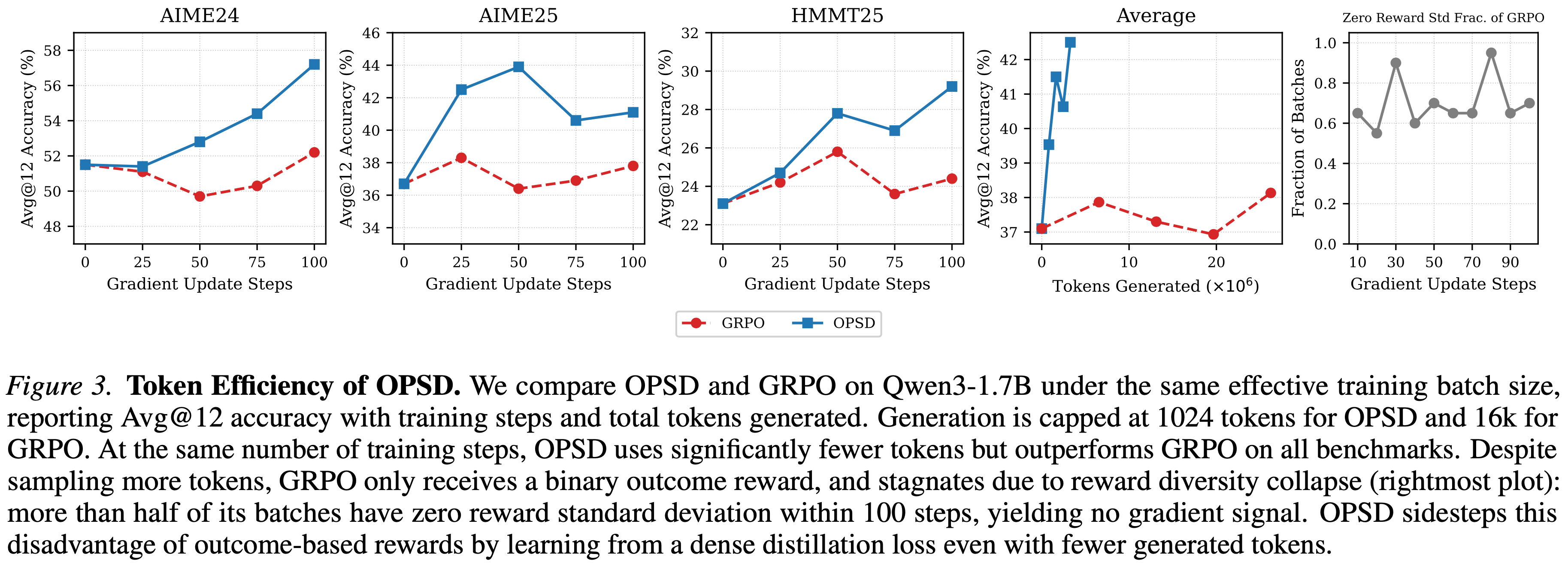
- 如图 3 所示
- 在 100 步的训练范围内,OPSD 相比 GRPO 实现了更高的 Token 学习效率
- 在 100 步训练内,当采样组内的结果奖励保持一致时,GRPO 的性能陷入停滞,学习信号减少,最终导致梯度为 0
- 这些结果表明,OPSD 能比 GRPO 和 SFT 更高效地从相同的推理数据集中提取学习信号,同时大幅缩短训练时间
- 图 3. OPSD 的 Token 效率
- 在相同的有效训练批次大小下比较了 Qwen3-4B 上的 OPSD 和 GRPO,报告了平均 \(@16\) 性能随梯度更新步数和总生成 Token 数的变化
- 两种方法在每次更新的采样生成数量方面具有相同的有效批次大小,但在生成长度上有所不同:
- OPSD 的每个生成上限为 1024 个 Token,而 GRPO 为 16384 个 Token
- OPSD 以明显更少的生成 Token 数量达到了与 GRPO 相当的性能,从而降低了采样成本和训练时间
- 在此实验中,OPSD 的 Token 效率比 GRPO 高 \(8 - 12 \times\)
- 实验细节见第 B 节
Ablation Studies & Discussions
- 本节开展了大量消融实验,研究 OPSD 中关键的设计选择,包括:
- (1) 散度目标函数
- (2) 学生和教师的生成风格(如思维模式开启/关闭)
- (3) 逐 Token KL 裁剪的效果;
- (4) 学生生成长度的影响
- (5) 全词表 logit 蒸馏与采样 Token 蒸馏的对比
Effect of Divergence Objective
- OPSD 中一个关键的设计选择是散度函数的选择
- 即用于实现教师与学生之间 Per-Token 分布匹配的散度函数
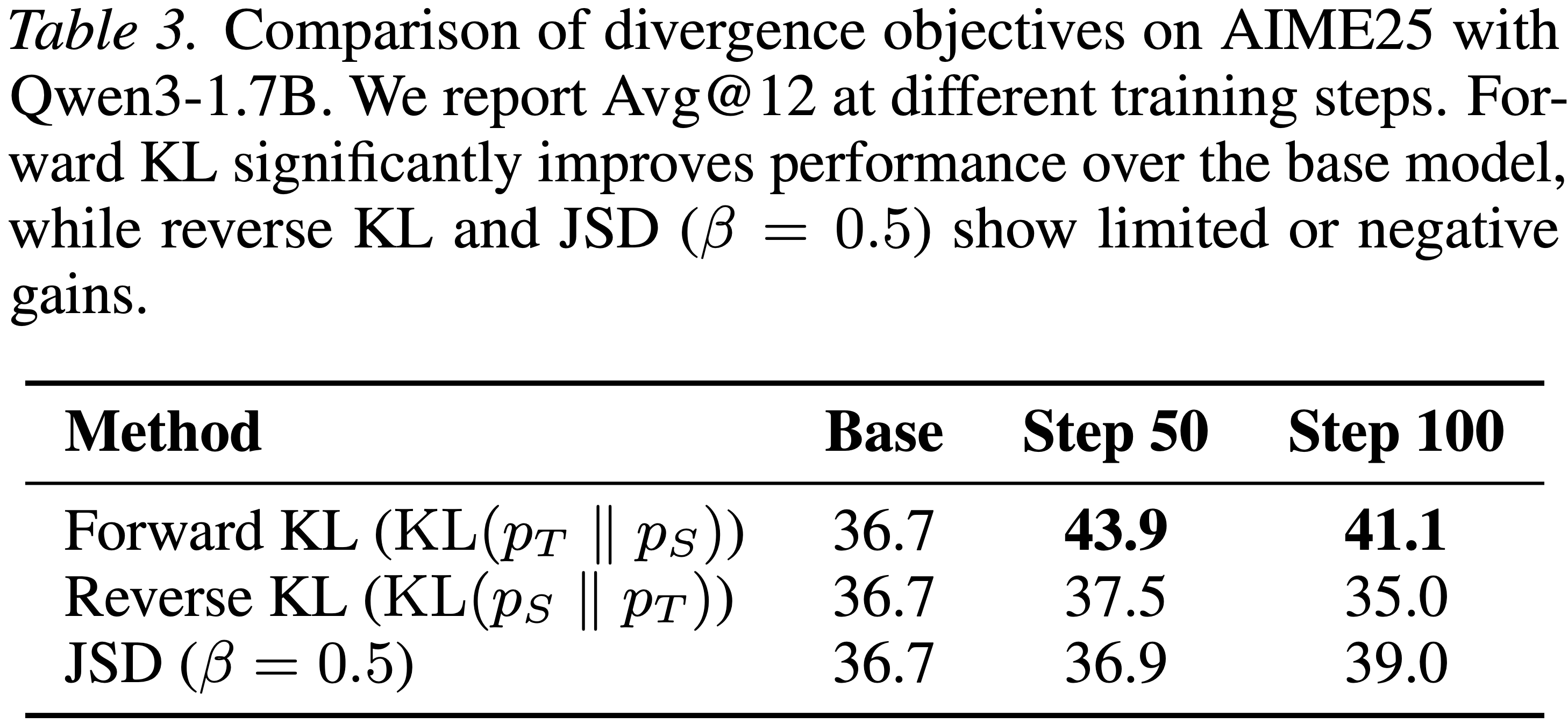
- 本文在 AIME25 数据集上基于 Qwen3-1.7B 模型,对比了前向 KL 散度、反向 KL 散度和 JSD 散度的表现,结果见表 3
- 所有目标函数均在相同的点态裁剪方案下评估以保证训练稳定性
- 前向 KL 散度始终能带来最显著的性能提升,将模型在第 50 步的性能从 36.7 提升至 43.9,且在第 100 步仍高于基线模型
- 反向 KL 散度和 JSD 散度仅带来有限的提升,甚至产生负面效果
- 注:在后续所有实验中,作者均采用前向 KL 散度
Effect of Generation Styles And Per-Token KL Clipping,生成风格与逐 Token KL 裁剪的影响
- OPSD 中另一项关键设计选择是学生和教师模型的生成风格,这一选择决定了学生的学习对象,以及教师提供的监督风格
- Qwen3模型支持两种生成模式:
- 思维模式开启(TM-on),模型会生成自反思的思维链 Token
- 思维模式关闭(TM-off),模型会直接生成响应结果
- 为确定哪种组合能产生最有效的学习信号,本文分析了四种学生/教师模式组合下的前向 KL 散度 \(KL(p_T | p_S)\),并将 Token 分为三类:
- 数学类(数字、运算符和数学关键词)
- 风格类(推理连接词)
- 其他类
- 表 5 报告了每个类别内的平均逐 Token KL 散度
- 在所有模型规模下,思维模式关闭的学生与思维模式开启的教师组合,在数学类 Token 上的 KL 散度值最大,这表明该组合能对数学相关 Token 提供更强的监督
- 报告的 KL 散度值对应每个位置上词表的期望散度
- 如表 5 所示,这一期望分布存在严重的偏斜,风格类 Token 贡献的散度值占比过高
- 这一现象促使作者采用点态裁剪的方式,控制此类厚尾分布的贡献
- 从实验结果来看,该配置能实现最优的下游任务性能
- 本文最终采用 思维模式关闭的学生/思维模式开启的教师 配置(注:其实这种实现严格来说已经不是 Self Distillation 了)
关于 Prompt 格式的实现说明
- 在本预印本初次发布后,发现 Student 模型的采样 Prompt 与 Teacher 模型的 Prompt 之间存在意外的格式不匹配:
- 具体情况: Student Prompt 缺少 Qwen3 的聊天模板,而 Teacher Prompt 则遵循 Qwen3 的思维风格聊天模板
- 因此 Student 模型的推理是在无模板风格下生成的,而 Teacher 模型的分布则是在包含思考标签的 Prompt 条件下生成的
- 尽管本文的方法不要求 Student 和 Teacher 模型的 Prompt 模板必须匹配,但本文在此记录这一实现细节以确保透明度和可复现性
- 理解:这个问题会导致 Teacher 的性能远超 Student 的效果
- 本预印本中报告的实验结果对应于这种配置
- Prompt 模板/指令可以被视为本文方法的一个设计选择:
- Teacher 和 Student Prompt 格式都可以作为框架中可优化的组件
- 可以通过诸如 GEPA 等 Prompt 优化技术来优化 Teacher Prompt 以塑造监督信号,同时可以改变 Student Prompt 来研究哪种生成模式能产生最有效的学习
- Prompt 模板/指令可以被视为本文方法的一个设计选择:
Effect of Per-Token Pointwise Clipping
- 如表 5 所示,风格类 Token 的 KL 散度可能高于数学相关 Token ,导致其主导训练信号
- 本文通过逐 Token 点态裁剪的方式缓解这一问题
- 本文通过逐 Token 点态裁剪的方式缓解这一问题
- 图 4 展示了 Qwen3-1.7B 模型的实验结果,裁剪操作能稳定训练过程,防止性能退化
- 这一点对于在百步内快速收敛的 OPSD 而言尤为重要
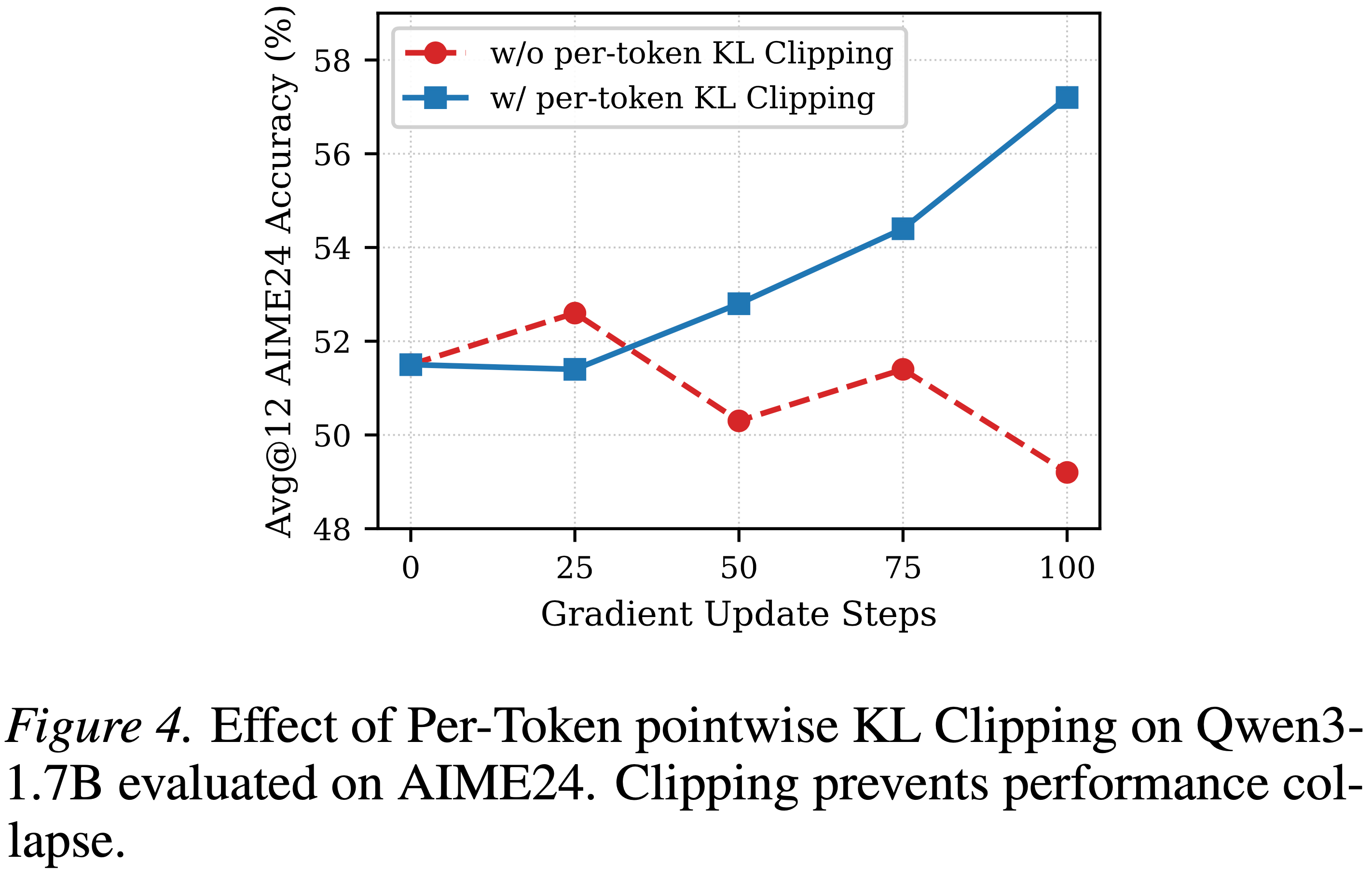
- 这一点对于在百步内快速收敛的 OPSD 而言尤为重要
Effect of Generation Length
- 由于 OPSD 的目标函数在 Token-level 运作(公式 6)
- 每个样本的生成 Token 数量直接决定了学生可获得的监督信号量
- 更长的序列能让学生获得更多的教师反馈,但同时也会增加计算成本,且可能引入噪声或无信息的后续内容
- 为研究这一权衡关系,本文在 Qwen3-1.7B 模型上开展消融实验
- 将基于策略采样的学生响应生成长度设置为 1024 和 4096 个 Token 两种情况,并采用全词表 logit 蒸馏
- 如图 5 所示,增加生成长度并未在两个任务上带来一致的性能提升
- 本文作者将这一现象归因于前序 Token 对学习的关键性:
- 当学生的生成序列变长时,在足够长的学生前缀条件下,教师对后续 Token 的预测会变得越来越确定,因此对后续 Token 施加的惩罚也会减少
- 注:(2025)的研究中也发现了这一现象
- 当学生的生成序列变长时,在足够长的学生前缀条件下,教师对后续 Token 的预测会变得越来越确定,因此对后续 Token 施加的惩罚也会减少
- 本文作者将这一现象归因于前序 Token 对学习的关键性:
Learning Objective Comparison: Full Vocabulary Logits Distillation vs Sampled-Token Distillation
- 公式 6 中的目标函数定义为教师与学生分布之间的 Per-Token 差异
- 回顾 公式 6:
$$D(p_{T}| p_{S})(\hat{y}\mid x)\triangleq \frac{1}{|\hat{y}|}\sum_{n = 1}^{|\hat{y}|}D\bigg (p_{T}(\cdot \mid x,y^{\star},\hat{y}_{< n})| p_{S}(\cdot \mid x,\hat{y}_{< n})\bigg) \tag {6}$$
- 回顾 公式 6:
- 在实际实验中,OPSD 可通过两种方式实例化该目标函数:
- (1) 全词表 logit 蒸馏(Fullvocabulary logit distillation) (2024):
- 在每个 Token 位置,通过全 softmax 操作计算整个词表上的 \(D(p_T | p_S)\),得到两个策略之间合理的逐 Token f-散度
- 这种变体直接匹配完整的 Token 分布
- (2) 采样 Token 优势策略梯度目标(Sampled-token advantage policy-gradient objective) (2025):
- 仅在学生实际采样的 Token \(\hat{y}_n\) 位置评估教师和学生的对数概率,并将反向 KL 项作为标量优势,融入策略梯度风格的损失函数中
- 这种变体优化由教师对数概率塑造的 On-policy RL 目标,而非完整分布的散度
- 理解:这里的 Sampled Token 就是指 Rollout 得到的 Token
- (1) 全词表 logit 蒸馏(Fullvocabulary logit distillation) (2024):
- 本文在 Qwen3-4B 模型上对比了这两种变体,蒸馏过程中的生成预算设置为 2048 个 Token ,结果如表 4 所示
- 全词表散度目标相比采样 Token 目标能带来稳定的性能提升
- 这表明让学生学习完整的教师分布,相比仅依赖逐 Token 的在线策略塑造,能获得更丰富的监督信息
- 但全词表计算需要在每个位置存储词表规模的 logit,会导致峰值内存占用更高,这也体现了性能与效率之间的权衡
- 全词表散度目标相比采样 Token 目标能带来稳定的性能提升
- 表 4:
- OPSD 中散度计算策略的消融实验(基于 Qwen3-4B 模型,蒸馏生成长度 2048)
- 报告在 AIME25 和 HMMT25 数据集上的
pass@8指标 - 全分布目标(logit 蒸馏)优于采样 Token 目标

Related Work
LLM Self-Training
- 本文的与一系列研究表明 LLM 可以通过生成和利用自身的监督信号来改进的研究相关联 (2020;2024b;2024;2023;2023;2024;2024)
- 在理念上最接近的是上下文蒸馏 (2022),它使用相同的底层模型作为 Teacher 和 Student ,通过为 Teacher 提供 Privileged 上下文,然后对 Student 在无上下文情况下生成的输出进行 SFT
- 这可以视为 Off-policy,其学习信号是一个离散的 Token 序列
- 在推理领域,ReST (2023) 和 STaR (2022) 同样依赖于迭代的自训练循环
- 基于 Prompt 或答案生成推理过程,通过奖励或真实答案进行筛选,然后在成功的轨迹上进行微调
- 注:这也是硬蒸馏
- Mitra & Ulukus (2025) 将其扩展到软蒸馏
- 上下文编辑 (2025) 从 Student 模型进行 On-policy 采样,并展示了通过最小化散度可以将上下文诱导的知识内化,并在知识编辑场景中展示了这一点
- OPSD 与这些方法的不同之处在于,本文在推理任务上对 Student 自己的 Rollout 执行 On-policy 软蒸馏:
- Teacher 的监督是每个 Token 的分布匹配,而不是生成用于 SFT 的推理过程
- OPSD 将推理改进视为学习一个由数据集的真实解答和模型自身推理能力共同诱导的条件分布
- 其他:
- SDPO (Hü2026) 探索了类似的算法,利用环境反馈作为 Privileged 信息,详情见 (SDPO)Reinforcement Learning via Self-Distillation, 20260128
- SDPO 方法除了信号以外来自环境反馈外,几乎和本文思路一致,都是 On-policy 蒸馏的
- 特别说明:SDPO 中的损失函数也是在整个词表上计算的
- SDFT (2026) 探索了持续学习任务中的 On-policy 自蒸馏
- SDPO (Hü2026) 探索了类似的算法,利用环境反馈作为 Privileged 信息,详情见 (SDPO)Reinforcement Learning via Self-Distillation, 20260128
On-Policy Distillation methods
- On-Policy Distillation 方法直接在从其自身策略采样的轨迹上训练 Student 模型,而 Teacher 模型则通过 KL 散度 (2024;2024a;2024;2025;2026;2025) 提供每个 Token 的指导
- 这些方法通过直接优化 Student 的访问分布来缓解分布偏移,但它们通常依赖于一个独立的、通常更大的 Teacher 模型
- 本文探索 LLM 是否可以通过利用更 Privileged 答案信息并依靠其自身的推理能力来引导其较弱版本改进推理,从而实现自我教学
- On-policy 训练范式也广泛用于机器人和深度强化学习中,例如 DAgger (2011),其中人类 Teacher 为 Student 策略访问的状态提供纠正性监督
Improving LLM Reasoning through SFT and RL
- SFT 和 RL 是提升 LLM 推理能力的两种主要方法
- 在高品质推理轨迹上进行 SFT 已展示出强大的性能 (2023;2024;2023;2025a;2025;2025;2023)
- 但先前的工作表明 SFT 可能依赖于记忆而非稳健的泛化能力 (2025)
- 直接优化基于结果的目标的 RL 可以表现出更好的泛化能力 (2025)
- 较新的算法如 GRPO 通过从组级别奖励估计优势来实现可扩展的 RL,而不需要像 PPO 那样需要一个显式的 Critic
- 在这一系列工作的基础上,越来越多的研究强调了 RLVR 在推理任务中的有效性 (2025;2025;2025;2025a;2025)
附录 A:Limitations and Future Directions
- 由于计算限制,本文实验仅限于 8B 参数以下的模型
- 虽然更大的模型从 OPSD 中受益更多(这与本文的假设(即自我合理化需要足够的模型容量)一致)
- 但这一趋势是否会在 8B 参数以上的规模(例如 70B 或更大的前沿模型)中持续,仍然是一个悬而未决的问题
- 有几个有前景的方向值得进一步研究
- 第一,本文当前的框架没有明确利用生成答案的正确性验证
- 整合这些信号可以提供超越分布匹配的额外学习目标
- 第二,问题难度在自我蒸馏中起着至关重要的作用:
- 如果推理问题超出了模型的理解阈值,那么即使可以访问真实解决方案, Teacher 策略也无法提供有意义的监督
- 这表明,课程学习策略(随着模型改进而逐渐增加问题难度)可以提高训练效果
- 探索能够将问题保持在模型能力前沿的自适应课程,是将 OPSD 扩展到更具挑战性的推理任务的一个重要方向
- 第一,本文当前的框架没有明确利用生成答案的正确性验证
附录 B:Experimental Details
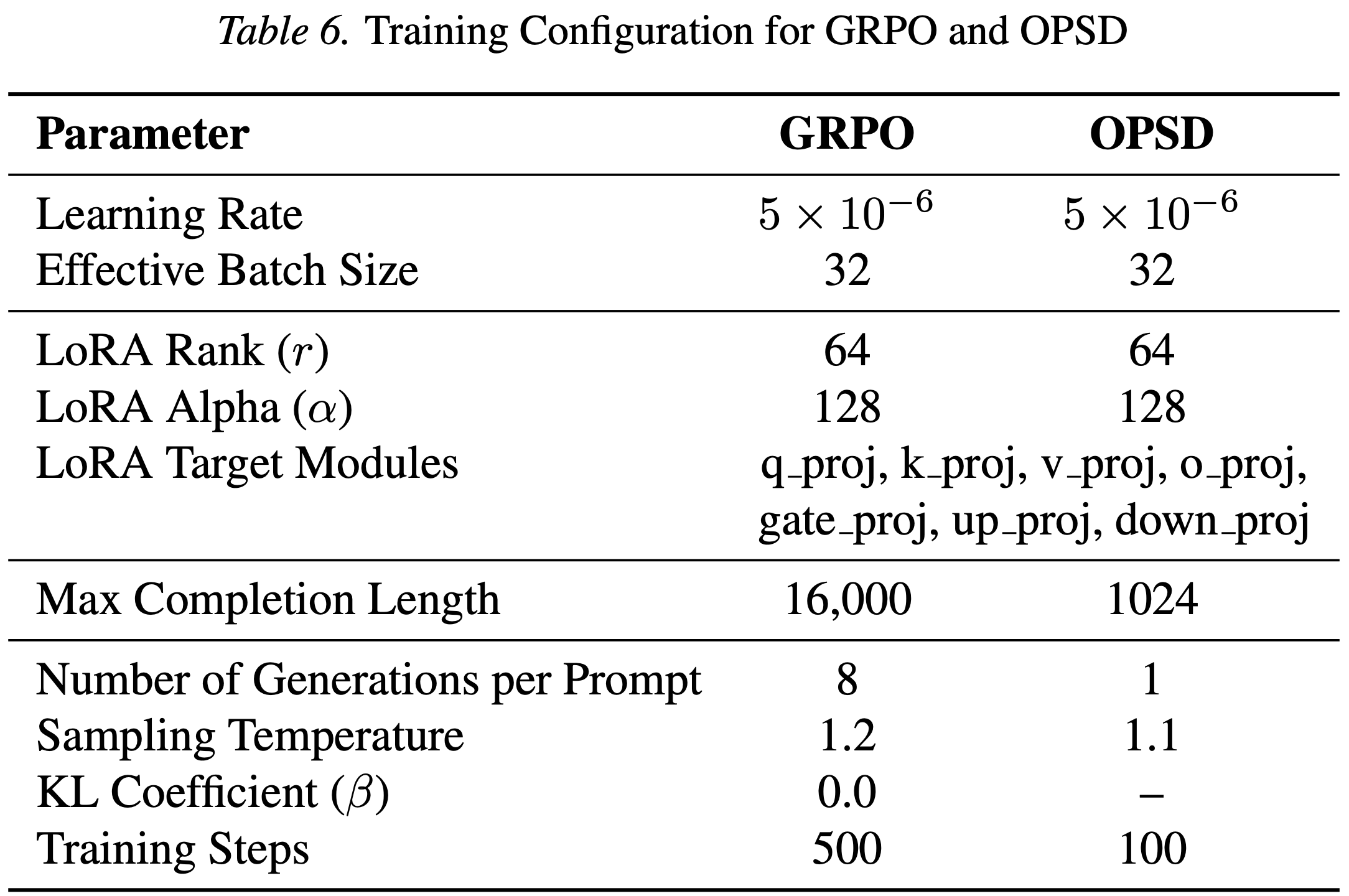
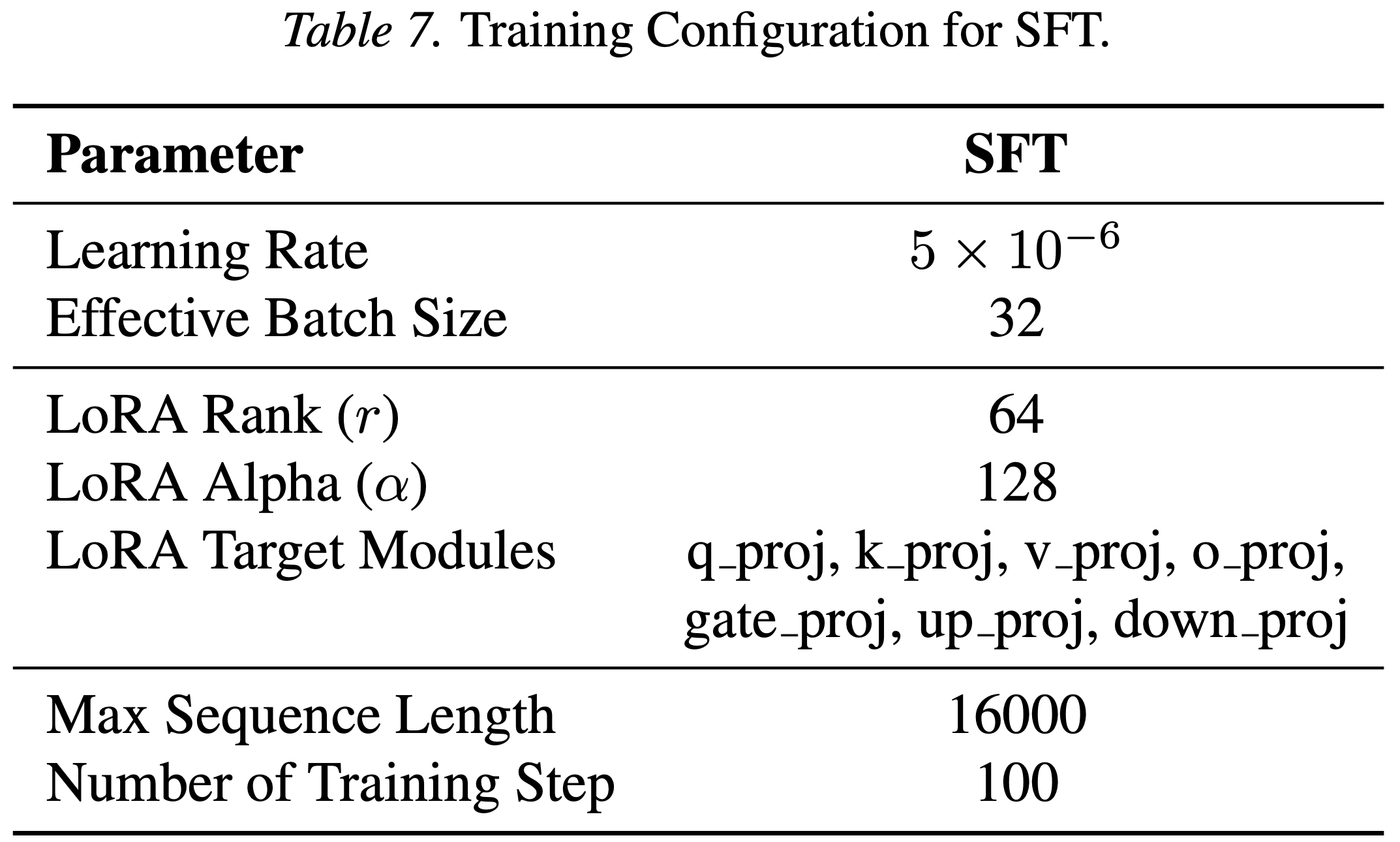
- 表 5、4 和 6 中提供了 SFT、GRPO 和 OPSD 实验的训练和评估配置
- 表 2 中的评估设置:
- 对于每种方法(GRPO、OPSD 和 SFT),报告在训练过程中,每 100 步评估一次,直到 1500 步,在每个任务上获得的最高得分
- 由于本文对所有基线一致地应用了相同的协议,考虑到任何固定评估点存在的内在方差,这仍然是不同算法之间的公平比较
- 本文作者在图 3 中报告了所有三个基线的检查点平均准确率
- 在图 3 中
- OPSD 的运行生成长度为 1024,学习率为 \(2 \times 10^{-4}\)
- 对于 OPSD,对于较短的生成长度(如 1024),使用 \(2 \times 10^{-4}\) 比使用 \(2 \times 10^{-5}\) 能获得更好的结果
- Remind:传统的 RL 中不能这样做(这是 OPD 专有的优点)
- 在 OPD 场景中,不需要 Rollout 结束就可以有奖励(来源于 Teacher),但是在传统 RL 场景,一般是需要 Rollout 结束才能得到 Reward 反馈的
- 所有实验均使用 8 张 A100 或 8 张 H100 GPU 进行,并启用了梯度检查点和 Flash Attention 2 以提高内存效率
- 本文为所有训练运行使用了 AdamW (2017) 优化器和 bfloat16 精度
- 对于 OPSD,除非另有说明,作者使用了全词表 Logit 蒸馏
- 表 6. GRPO 和 OPSD 的训练配置
- 表 7. SFT 的训练配置
- 表 6. 评估参数
附录 C:Token Category Definitions
- 本文将 Token 分类为 Style Token 和 Match Token(提前预定义的关键词)
- 这些关键词常用语分析 Per-token KL 散度(分别针对风格 Token 和数学知识 Token)
- Style Tokens.
maybe, perhaps, probably, possibly, let, okay, ok, alright, hmm, wait, because, since, so, thus, hence, therefore, but, however, although, though, yet, or, alternatively, instead, otherwise, actually, really, just, simply, basically, very, quite, pretty, rather, fairly, now, then, next, first, second, finally, try, see, check, note, recall, think, idea, strategy, approach, method, way, would, could, should, might, can, huge, large, big, small, tiny, interesting, tricky, complex, simple.
- Math Tokens.
exponential, exponent, power, powers, base, logarithm, logarithms, log, ln, compare, comparing, comparison, less, equal, larger, smaller, greater, factor, factors, prime, divisible, equation, expression, formula, inequality, rational, irrational, real, integer, coefficient, variable, constant, sum, product, difference, quotient, fraction, denominator, numerator, root, square, cube, nth, maximum, minimum, optimize, bound.
附录 D:Policy-Gradient Interpretation of OPSD and Comparison to STaR,OPSD 的策略梯度解释以及与 STaR 的比较
- 方程 (9) 中的 OPSD 目标可以解释为一种带有密集、 Token-level 奖励信号的策略梯度更新
- 回顾方程(9)策略梯度风格的目标函数
$$
\begin{align}
\mathcal{L}(\theta) = -\mathbb{E}_{(x,y^{\star})\sim \mathcal{S} }\left[\mathbb{E}_{\hat{y}\sim p_S(\cdot |x)}\left[\frac{1}{|\hat{y}|}\sum_{n = 1}^{|\hat{y}|}A_n(x,\hat{y}) \cdot \log p_S(\hat{y}_n\mid x,\hat{y}_{< n})\right]\right]
\end{align}
\tag {9}
$$
- 回顾方程(9)策略梯度风格的目标函数
- 本节将展示:
- (1) OPSD 可以被视为一种密集奖励的策略梯度
- (2) 本文将 OPSD 与 STaR 进行对比,证明 STaR 的学习信号是 Sequence-level ,而 OPSD 是 Token-level
D.1. STaR as Sequence-Level Policy-Gradient
- STaR (2022) 可以被视为 RL 风格策略梯度目标的一种近似
- 语言模型 \(p_{\theta}\) 在 rationale(基本原理/根本原因) \(r\) 和答案 \(y\) 上诱导出一个联合分布:
$$
p_{\theta}(r,y\mid x) = p_{\theta}(r\mid x)p_{\theta}(y\mid x,r),
$$- 这里表示:模型在预测最终答案 \(y\) 之前,先采样一个潜在的 rationale \(r\)
- 给定一个指示器奖励 \(R(y) = \mathbf{1}(y = y^{*})\),在整个数据集 \(\mathcal{S} = \{(x_i,y_i^*)\}_{i = 1}^N\) 上的期望回报为:
$$
J_{\text{STaR} }(\theta) = \sum_{i = 1}^{N}\mathbb{E}_{(r,y)\sim p_{\theta}(\cdot |x_i)}\big[\mathbf{1}(y = y_i^*)\big] \tag {10}
$$ - 应用对数导数技巧,得到策略梯度:
$$
\nabla_{\theta}J_{\text{STaR} }(\theta) = \sum_{i = 1}^{N}\mathbb{E}_{(r,y)\sim p_{\theta}(\cdot |x_i)}\Big[\mathbf{1}(y = y_i^*)\nabla_{\theta}\log p_{\theta}(r,y\mid x_i)\Big] \tag {11}
$$- 注意,指示函数丢弃了所有未导致正确答案 \(y_i^*\) 的 sampled rationale 的梯度:
- 这对应于 STaR 中的筛选步骤
- 注意,指示函数丢弃了所有未导致正确答案 \(y_i^*\) 的 sampled rationale 的梯度:
- 语言模型 \(p_{\theta}\) 在 rationale(基本原理/根本原因) \(r\) 和答案 \(y\) 上诱导出一个联合分布:
- 一个局限性是 STaR 的奖励是 Sequence-level :
- 二元指示器 \(\mathbf{1}(y = y^*)\) 为轨迹中的所有 Token 提供相同的信号,不提供中间的 Credit Assignment
- 当所有采样的轨迹都不正确时,学习信号就会消失
C.2. OPSD as Dense-Reward Policy Gradient
- 方程 (9) 中的采样 Token 目标也可以被视为一种策略梯度方法,但具有 Token-level 奖励
- 固定一个训练对 \((x,y^{\star})\),并让 Student 生成一个轨迹 \(\hat{y}\sim p_S(\cdot |x)\)
- 在每个位置 \(n\),定义每个 Token 的奖励:
$$
r_{n}(x,\hat{y})\triangleq \log p_{T}(\hat{y}_{n}\mid x,y^{\star},\hat{y}_{< n}) - \log p_{S}(\hat{y}_{n}\mid x,\hat{y}_{< n}).
$$
- 这个奖励衡量了拥有 Privileged 信息的 Teacher 相对于 Student ,偏好采样 Token \(\hat{y}_n\) 的程度
- 如正文所述,在计算梯度时,本文将 \(r_n\) (等同于 advantage \(A_{n}\))视为关于 \(\theta\) 的常数
- 即,在奖励计算中阻止了通过 \(p_T\) 和 \(p_S\) 的梯度传播
- 在这种处理下,方程 (9) 的梯度呈现标准的策略梯度形式:
$$
\nabla_{\theta}\mathcal{L}(\theta) = -\mathbb{E}_{(x,y^{\star})\sim \mathcal{S} }\left[\mathbb{E}_{\hat{y}\sim p_S(\cdot |x)}\left[\frac{1}{|\hat{y}|}\sum_{n = 1}^{|\hat{y}|}r_n(x,\hat{y})\nabla_{\theta}\log p_S(\hat{y}_n\mid x,\hat{y}_{< n})\right]\right],
$$
- 这对应于最大化 Student 在线 Rollout 上的期望 Per-Token 奖励:
$$
J_{OPSD}(\theta) = \mathbb{E}_{(x,y^{\star})\sim \mathcal{S} }\left[\mathbb{E}_{\hat{y}\sim p_S(\cdot |x)}\left[\frac{1}{|\hat{y}|}\sum_{n = 1}^{|\hat{y}|}r_n(x,\hat{y})\right]\right].
$$ - 这个奖励是密集的:
- 它在每个 Token 位置都提供学习信号,无论最终答案是否正确
Comparison
- STaR 和 OPSD 都可以被理解为策略梯度方法,但它们的奖励结构有根本的不同
- STaR 使用一个 Sequence-level 指示器 \(\mathbf{1}(y = y^{\star})\),为所有 Token 分配相同的信号
- 当所有采样的轨迹都不正确时,学习信号完全消失
- OPSD 在每个位置都提供一个 Token-level 奖励 \(r_n\),即使在最终答案错误的情况下也能实现细粒度的 Credit Assignment
- STaR 使用一个 Sequence-level 指示器 \(\mathbf{1}(y = y^{\star})\),为所有 Token 分配相同的信号
附录:关于 JSD 的补充说明
- 假定使用 \(\mathrm{JSD}_{\beta=0.5}\),其原始定义为
$$ JS(P|Q) = \frac{1}{2}KL(P|M) + \frac{1}{2}KL(Q|M) \quad \text{ where } M = \frac{P+Q}{2}$$- JSD 是对称的:\(JS(P||Q) = JS(Q||P)\)
- JSD 是有界的:值域在 \([0, \ln2]\) 之间
- 注意:相对而言,KL 散度的阈值是 \([0, +\infty]\),因为某个节点 Q 很小的时候,KL 可能会非常大,而 JSD 则不存在这个情况