注:本文包含 AI 辅助创作
Paper Summary
- 整体总结和说明:
- 作者定义并提出了 长度膨胀(length inflation) 现象:模型倾向于产生不必要的冗长或过度思考
- 长度膨胀(length inflation) 是 LLM RL 训练中一个根本性的效率问题
- 为解决 长度膨胀问题,作者提出了一个无损长度控制的通用框架 组相对奖励重缩放(Group Relative Reward Rescaling, \(\mathbf{GR}^3\))
- \(\text{GR}^{3}\) 通过一个乘法的、组相对的形式,并结合优势感知校准来调控推理长度
- 在 RLVR 和 RLHF 两种 Setting 下,\(\text{GR}^{3}\) 均能将 性能-成本帕累托前沿 向外推移
- 观测效果:保持与标准 GRPO 相当的训练动态和下游性能,同时显著缓解了长度膨胀问题
- 在保持(甚至提升)模型能力的同时减少 Token 使用
- 理解:本文的核心思路创新是将加性的长度惩罚方式转变成 乘性的长度惩罚方式
- 当前 LLM RL 面临问题:模型采用冗长或低效的推理来最大化奖励(长度膨胀)
- 先前的方法:难以以一种通用且无损的方式解决这一挑战,主要是因为:
- 加性惩罚 :引入了一种补偿效应 ,从而创造了优化捷径
- 启发式门控策略 :在二元反馈之外缺乏通用性
- 本文方法:组相对奖励重缩放(Group Relative Reward Rescaling, \(\mathbf{GR}^3\))
- 将长度控制重新构建为一种乘法重缩放范式
- 建立了一个通用的、连续的、且依赖于奖励的门控机制
- 其他创新:在 \(\mathbf{GR}^3\) 的基础上,结合了 组相对正则化(group-relative regularization) 和 优势感知校准(advantage-aware calibration)
- 能根据实例难度动态调整长度预算,并保留高质量轨迹的优势信号

- 能根据实例难度动态调整长度预算,并保留高质量轨迹的优势信号
Introduction and Discussion
- LLM 上的 RL 表现出一个持续的缺陷,本文称之为长度膨胀(length inflation):
- 长度膨胀的定义:经过 RL 训练的模型倾向于产生不必要的冗长轨迹,导致推理成本增加,而质量却没有成比例地提升
- 长度膨胀现象在主要的 RL 范式中都有出现
- 在 RLHF(2022)中,模型利用奖励模型对冗长的偏好,导致 Reward Hacking(2023)
- 在 RLVR(2024)中,长度膨胀则源于推理效率低下(2025),模型生成不必要的长思维链以略微提高正确解的可能性
- 之前的工作:
- 路线一:训练对 Response 长度不变的奖励模型(2024a;2024)
- RLHF 中有效,无法扩展到 RLVR,因为 RLVR 的奖励来自真实值验证器,而非可以被去偏的学习代理
- 路线二(更通用):在奖励中引入显式的长度惩罚(2025a;2025c;2025)
- 大多数现有方法依赖于粗略的正则化,导致了次优的优化动态
- 一种常见的设计:采用加性塑形(additive shaping)(2025;2025)
- 用一个显式的长度项(例如,\(R’ = R - \lambda \ell\))修改目标函数
- 这引入了解耦的激励,创造了一个与任务成功无关的、使极端简洁成为有吸引力的捷径的、由长度驱动的组成部分
- For 更好地使惩罚与结果对齐,一些工作提出了启发式门控(heuristic gating)(2025;2025),仅在 \(R = 1\) 时应用惩罚
- 这种设计本质上局限于二元反馈,不能自然地扩展到像 RLHF 这样的连续奖励 Setting
- 许多方法依赖粗略的控制机制,如静态截断阈值或未校准的惩罚强度(2025b;2025),导致固有的效率-性能权衡,如图 1 所示
- 一种常见的设计:采用加性塑形(additive shaping)(2025;2025)
- 大多数现有方法依赖于粗略的正则化,导致了次优的优化动态
- 路线一:训练对 Response 长度不变的奖励模型(2024a;2024)
- 核心问题提出:能否在不损害 RL 能力增益的情况下,以一种通用的方式解决长度膨胀?
- 本工作提出了一个用于无损效率优化的 Principled 框架 GR\(^3\))
- 特点:GR\(^3\) 不使用加性惩罚 ,而是通过乘法重缩放 来正则化长度
- 作为一个广义的门控机制,消除了加性方案固有的补偿捷径
- 为了进一步确保无损优化,作者引入了两个细粒度机制
- 采用 Group-relative Regularization
- 根据 On-policy 统计量而非刚性阈值来归一化长度,从而动态地将长度预算调整到每个 Prompt 固有的难度
- 补充引入 Advantage-aware Calibration,显式控制惩罚强度
- 这确保了长度正则化不会推翻代表性高质量轨迹的优势信号,从而保障了向能力提升的稳定优化
- 采用 Group-relative Regularization
- 特点:GR\(^3\) 不使用加性惩罚 ,而是通过乘法重缩放 来正则化长度
- 实验显示:GR\(^3\) 解决了先前方法中固有的效率-性能权衡
- 如图 1 所示,GR\(^3\) 显著减少了 Token 使用量(在 AIME-25 上超过 \(40%\)),同时提高了准确性(\(+8\) points)
- 这证明冗长并非智能的先决条件
- 在 RLHF 设置中,GR\(^3\) 表现出自适应的长度动态:
- 当计算有益时,它允许适度增长,但随着策略成熟,它会自动抑制生成长度(图 2)
- 这种机制有效地通过冗长来缓解 Reward Hacking ,而不牺牲性能
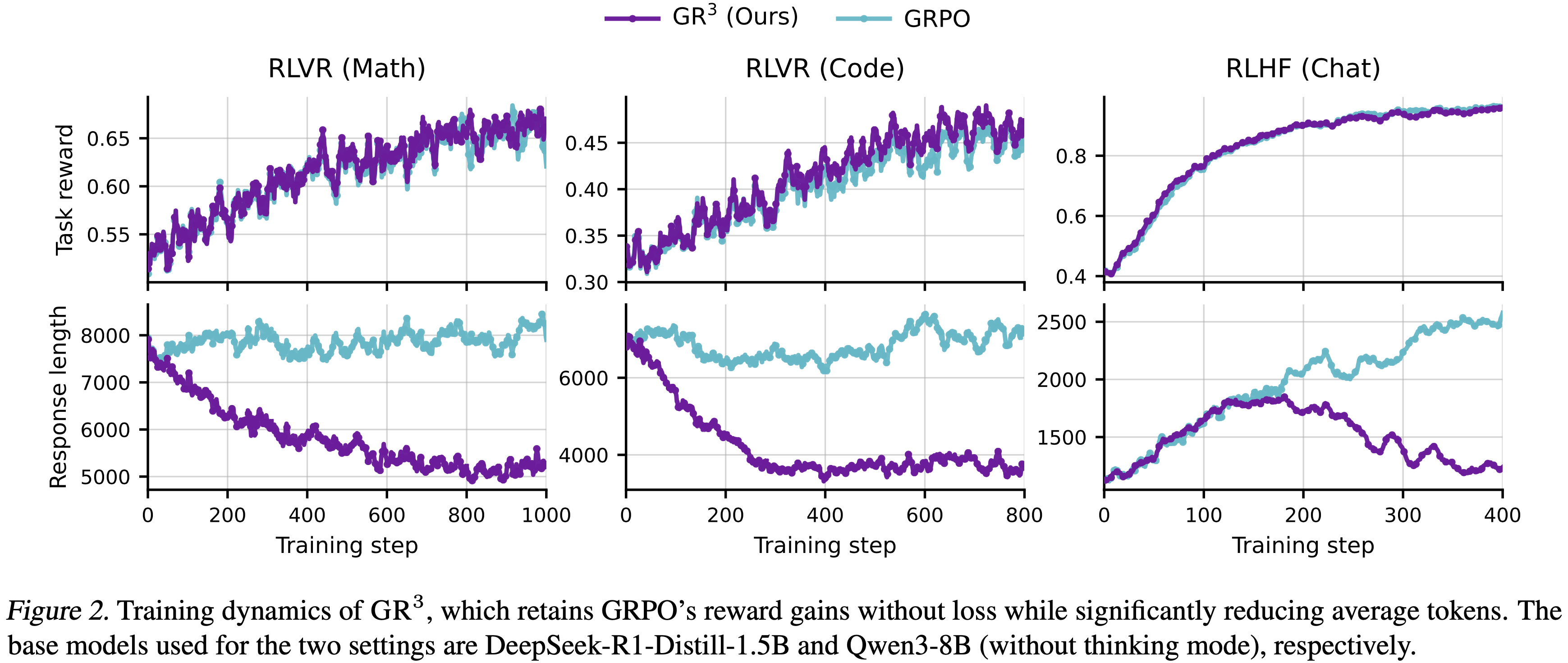
- 如图 1 所示,GR\(^3\) 显著减少了 Token 使用量(在 AIME-25 上超过 \(40%\)),同时提高了准确性(\(+8\) points)
- 本文贡献总结:
- 提出无损长度控制框架 \(\text{GR}^3\),用乘法奖励重缩放替代了加性惩罚
- 这种设计消除了补偿性优化捷径,并为二元奖励和连续奖励提供了统一的机制
- 开发了一种优化保持策略,将组相对正则化与优势感知校准相结合,使约束适应于 On-policy 统计量,同时保留学习信号
- 在数学推理、代码生成和 RLHF 对齐任务中,GR\(^3\) 在匹配标准 GRPO 性能的同时产生了简洁的生成,推动了效率-性能帕累托前沿的迁移
- 提出无损长度控制框架 \(\text{GR}^3\),用乘法奖励重缩放替代了加性惩罚
Preliminary
Group Relative Policy Optimization(GRPO)
- LLM 生成可以被形式化为一个 Token 级别的 MDP
- 给定一个 Prompt \(x \sim \mathcal{D}\) ,一个自回归策略 \(\pi_{\theta}\) 通过从 \(\pi_{\theta}(y_t\mid x,y_{< t})\) 中采样 Token 来生成长度为 \(\ell := |y|\) 的 Response \(y = (y_1, \ldots , y_\ell)\)
- 一个标量奖励 \(R(x,y)\) 定义在完整 Response 上,强化学习旨在最大化期望奖励:
$$\max_{\pi_{\theta} }\mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\big[R(x,y)\big]. \tag {1}$$
- 随着像 DeepSeek-R1 这样的推理模型的出现,组式 RL 在 LLM 后训练中变得普遍
- 其中的 GRPO(2024)因其可扩展性和无需单独的价值模型而被广泛采用
- 对于每个 Prompt \(x\) ,GRPO 从一个旧策略 \(\pi_{\theta_{\text{old} } }(\cdot |x)\) 中采样一组 \(G\) 个 Response \(\{y^{(i)}\}_{i = 1}^{G}\),并通过 \(R(x,y^{(i)})\) 评估每个 Response
- 通过组内归一化构建一个组相对优势(group-relative advantage):
$$\begin{array}{c}{\hat{A}^{(i)} = \frac{R(x,y^{(i)}) - \mu_R}{\sigma_R} }\\ {\mu_R:= \frac{1}{G}\sum_{j = 1}^{G}R(x,y^{(j)}), \quad \sigma_R:= \text{std}\Big(\{R(x,y^{(j)})\}_{j = 1}^{G}\Big)} \end{array} \tag {2}$$
- 通过组内归一化构建一个组相对优势(group-relative advantage):
- 策略优化时,使用一个 PPO 风格的、在组归一化优势上的裁剪目标进行优化:
$$\begin{array}{rl} & {\mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{x\sim \mathcal{D},\{y^{(i)}\}_{i = 1}^{G} }\left[\frac{1}{G}\sum_{i = 1}^{G}\sum_{t = 1}^{|y^{(i)}|}\right.} {\left.\left(\min \left(r_{i,t}(\theta)\hat{A}^{(i)},\text{clip}(r_{i,t}(\theta),1 - \epsilon ,1 + \epsilon)\hat{A}^{(i)}\right)\right.\right.} {\left.\left. - \beta D_{\text{KL} }(\pi_{\theta}| \pi_{\text{ref} })\right)\right],} \end{array} \tag {3}$$- 重要性采样比率定义为
$$r_{i,t}(\theta) = \frac{\pi_{\theta}(y_t^{(i)}\mid x,y_{< t}^{(i)})}{\pi_{\theta_{\text{old} } }(y_t^{(i)}\mid x,y_{< t}^{(i)})}. \tag {4}$$
- 重要性采样比率定义为
- GRPO 基于组内统计量估计优势
- 后面,本文作者会利用这一结构特性来构建一个更符合 On-policy 的长度正则化方案,并制定优势感知校准,以更好地尊重底层的优化信号,详见第 3 节
Length-Regularized Reinforcement Learning
- RL 带来了实质性的性能提升,但 RL 的一个关键的失败模式变得越来越明显(本文称为长度膨胀)
- 长思维链(Long-CoT)模型特别容易受到过度思考的影响(2024b;2025a)
- RLHF 中的 Reward Hacking(2023;2023)也可能导致 Response 长度的爆炸性增长

- 缓解 RL 中长度膨胀的一个常见策略是通过 Reward Shaping 显式地正则化 Response 长度
- 从一个统一的视角来看(2025c),大多数现有方法可以被实例化为加性塑形 :
$$\text{Additive:}\hat{R}^{(+)} = R + \lambda \cdot S,\lambda >0 \tag {5}$$- \(R\) 是任务奖励
- \(S\) 是一个依赖于长度的塑形信号
- \(\lambda\) 控制长度正则化的强度
- \(\hat{R}^{(+)}\) 表示用于策略优化的塑形后奖励
- 表 1 中展示了一些代表性的 加性塑形 的例子
- 在这个公式下,现有方法主要在长度正则器 \(S\) 的实例化方式上有所不同
- 最基本的策略通常依赖于一个固定的阈值(例如, \(\ell_{T} = 4K\) ):
- 一旦 Response 长度超过这个限制,模型就会招致一个恒定的惩罚(2025b)或一个逐渐增加的惩罚(2025)
- 一个更 Principled 范式则利用组级统计量(2025)来确定惩罚的强度
- 一些方法引入了门控机制(例如, \(\mathbb{I}(R = 1)\) )(2025), 仅对成功的轨迹激活长度正则化,以防止模型过度优化简洁性
- 最基本的策略通常依赖于一个固定的阈值(例如, \(\ell_{T} = 4K\) ):
- 这些方法在具体实例上有所不同,但共享一个共同的目标:
- 在 RL 训练期间压缩 Response 长度
- 但实践发现,这种正则化常常导致性能下降,这促使本文作者更仔细地审视 Reward Shaping 设计
- 从一个统一的视角来看(2025c),大多数现有方法可以被实例化为加性塑形 :
Group Relative Reward Rescaling(GR3, GR\(^3\))
- \(\mathbf{GR}^3\) 是一个旨在无损能力的情况下缓解长度膨胀的 Principled 框架
- 对于一个在一组 \(G\) 个样本中的、长度为 \(\ell^{(i)} = |y^{(i)}|\) 的 Response \(y^{(i)}\), \(\mathbf{GR}^3\) 将重缩放后的奖励定义为:
$$\hat{R} (x,y^{(i)}) = R(x,y^{(i)}) \cdot \underbrace{\frac{1}{1 + \alpha \cdot \frac{\ell^{(i)} }{\bar{\ell} } } }_{S^{(i)} } \tag {6}$$- \(S^{(i)}\) 表示长度缩放因子
- \(\bar{\ell}\) 表示组内的平均 Response 长度
- 这个公式反映了三个维度的统一设计
- 采用乘法奖励重缩放(第 3.1 节)作为一种依赖于奖励的门控,减轻了补偿效应,同时仍适用于一般的连续奖励分布
- 通过组相对正则化(第 3.2 节)实例化缩放因子,利用 On-policy 平均值 \(\bar{\ell}\) 来动态地将长度预算调整到 Prompt 的固有难度
- 为了维持稳定的优化,优势感知校准(第 3.3 节)进一步控制惩罚强度,防止对高优势轨迹的不当抑制
Multiplicative Reward Rescaling
Motivation and Formulation
- 最朴素的长度控制方法依赖于如公式 5 所示的加性 Reward Shaping ,其中 \(\lambda\) 控制长度惩罚的强度
- 但加性塑形引入了一个固有的补偿效应:塑形项 \(S\) 形成了一个可以独立于任务性能被利用的辅助优化目标
- 一些工作通过门控机制缓解了这个问题,例如,将 \(I(R = 1)\) 纳入 \(S\)
- 但这种设计仅限于二元奖励,不能扩展到连续奖励设置
- 区别于这些加性公式,作者提出了一个更通用的乘法塑形范式:
$$\mathbf{Multiplicative:}\quad \hat{R}^{(\times)} = R\cdot S, \tag {7}$$- 这可以解释为启发式门控的连续扩展,消除了权衡系数 \(\lambda\),并自然地推广到任意奖励尺度 1
- 重点:乘法公式消除了加性塑形的补偿特性,要求策略联合优化任务性能和长度控制
- 如图 3 所示,加性塑形表现出一个系统性的失败模式:
- 对于任何 \(\lambda\) 的选择,优化都被快速的长度缩减所主导,导致严重的性能下降
- 乘法塑形不允许这样的捷径,因此避免了这种崩溃
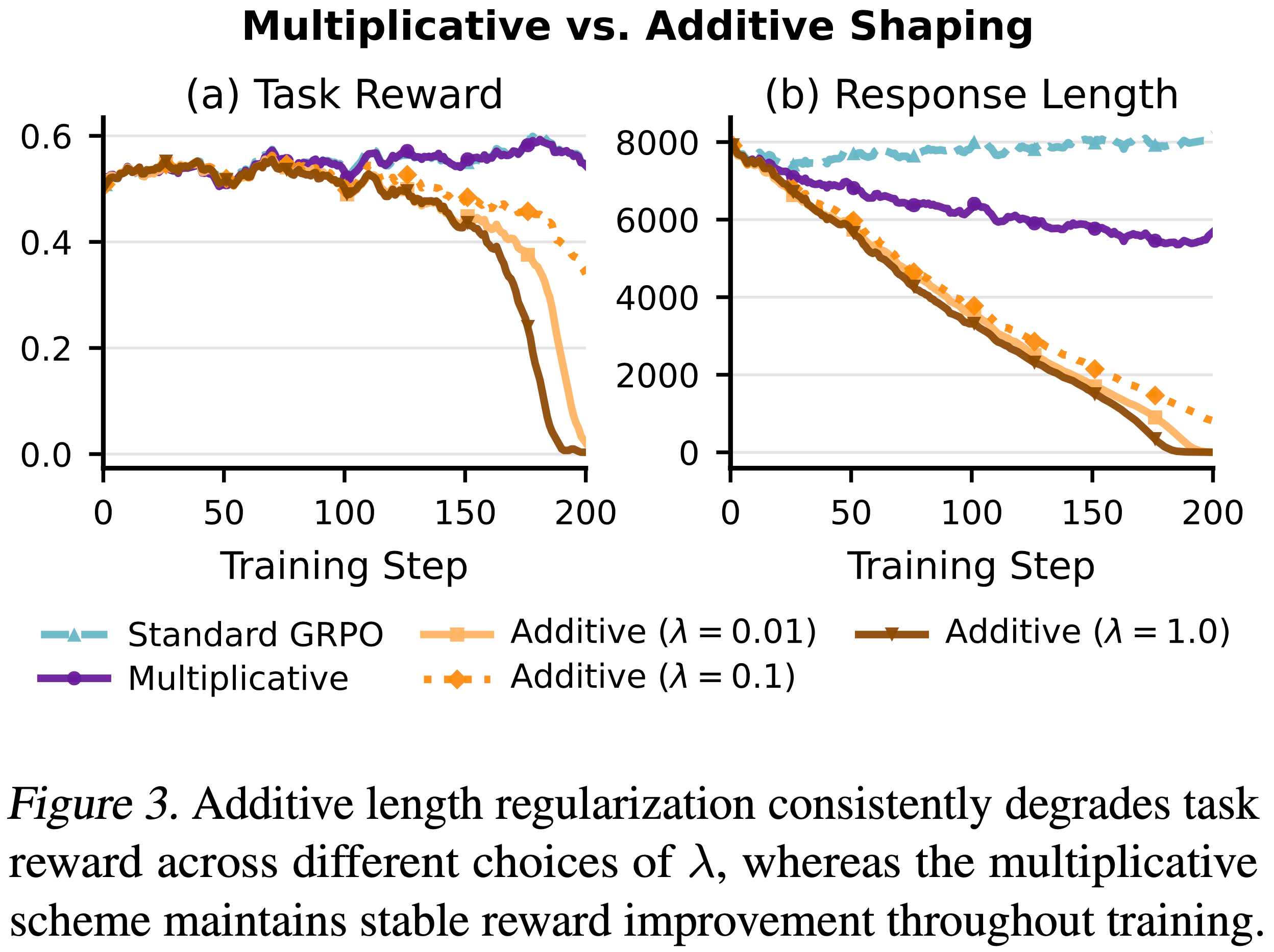
- 直观地说,乘法塑形通过下式将长度控制的影响与任务奖励耦合起来:
$$\frac{\partial\hat{R}^{(\times)} }{\partial S} = R. \tag {8}$$- 因此,长度正则化随着任务成功而自动增强,使塑形内在地具有奖励感知性
Analysis Under Group-Normalized Advantage
- 在 GRPO 采用的组归一化优势下进一步提炼上述直觉
- 固定一个 Prompt \(x\),并考虑由采样 Response \(y \sim \pi_{\theta_{\text{old} } }(\cdot |x)\) 引起的 \((R,S)\) 的组内分布
- 其中 \(R \in [0,1]\) 表示任务奖励, \(S \in [0,1]\) 表示一个与长度相关的分数(例如,公式 6)
- 固定一个 Prompt \(x\),并考虑由采样 Response \(y \sim \pi_{\theta_{\text{old} } }(\cdot |x)\) 引起的 \((R,S)\) 的组内分布
- 比较加性塑形 \(\hat{R}^{(+)}\)(公式 5)和乘性塑形 \(\hat{R}^{(\times)}\)(公式 7)
- 令 \(\mu\) 和 \(\sigma\) 表示组内均值和标准差
- 结果使用 Population Moments 陈述,经验版本通过 Substituting 样本均值得到
Proposition 3.1 (Additive shaping: linear injection of the length signal)
- 命题 3.1 (加性塑形:长度信号的线性注入)
- 令 \((R,S)\) 具有有限二阶矩,并定义
- \(\mu_{R} = \mathbb{E}[R]\)
- \(\mu_{S} = \mathbb{E}[S]\)
- \(\sigma_{R}^{2} = \text{Var}(R)\)
- \(\sigma_{S}^{2} = \text{Var}(S)\)
- \(\sigma_{RS} = \text{Cov}(R,S)\)
- 对于
$$\hat{R}^{(+)} = R + \lambda S, \quad where \lambda >0 $$- 有:
$$ \begin{align}
\hat{R}^{(+)} - \mathbb{E}[\hat{R}^{(+)}] &= (R - \mu_R) + \lambda (S - \mu_S), \tag {9} \\ \text{Var}(\hat{R}^{(+)}) &:= \sigma_{R}^{2} + \lambda^{2}\sigma_{S}^{2} + 2\lambda \sigma_{RS}, \tag {10}
\end{align}$$
- 有:
- 因此
$$A\left(\hat{R}^{(+)}\right) = \frac{(R - \mu_R) + \lambda(S - \mu_S)}{\sqrt{\sigma_R^2 + \lambda^2\sigma_S^2 + 2\lambda\sigma_{RS} } }. \tag {11}$$ - 因此,与长度相关的信号 \((S - \mu_S)\) 以固定权重 \(\lambda\) 线性地注入到优势中,并且即使在组内 \(R\) 提供很少的判别信号时也能起作用
- Proof :
- 公式 (9) 由下式给出:
$$\mathbb{E}[\hat{R}^{(+)}] = \mu_R + \lambda \mu_S$$ - 公式 (10) 由下式导出:
$$\text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y) + 2\text{Cov}(X,Y)$$- 其中 \(X = R\) 和 \(Y = \lambda S\)
- 公式 (11) 通过将公式 (2) 中的 \(R\) 替换为 \(\hat{R}^{(+)}\) 得到
- 公式 (9) 由下式给出:
Proposition 3.2 (Multiplicative shaping: reward-weighted length signal)
- 命题 3.2 (乘性塑形:奖励加权的长度信号)
- 令 \((R,S)\) 具有有限二阶矩,并定义
- \(\mu_R = \mathbb{E}[R]\)
- \(\mu_S = \mathbb{E}[S]\),
- \(\sigma_R^2 = \text{Var}(R)\),
- \(\sigma_S^2 = \text{Var}(S)\),
- \(\sigma_{RS} = \text{Cov}(R,S)\)
- 对于乘性塑形 \(\hat{R}^{(\times)} = RS\),有:
$$\mathbb{E}[\hat{R}^{(\times)}] = \mathbb{E}[RS] = \mu_R\mu_S + \sigma_{RS}. \tag {12}$$ - 此外,中心化后的塑形奖励允许分解为:
$$RS - \mathbb{E}[RS] = R(S - \mu_S) + \mu_S(R - \mu_R) - \sigma_{RS}. \tag {13}$$ - 因此,组归一化后的优势可以写为:
$$A\left(\hat{R}^{(\times)}\right) = \frac{R(S - \mu_S) + \mu_S(R - \mu_R) - \sigma_{RS} }{\sqrt{\text{Var}(RS)} }. \tag {14}$$ - Proof :
- 公式 (12) 由下面的公式得到:
$$\mathbb{E}[RS] = \mathbb{E}[R]\mathbb{E}[S] + \text{Cov}(R,S)$$ - 对于公式 (13)
- 重写为
$$RS = R\mu_S + R(S - \mu_S) = \mu_R\mu_S + \mu_S(R - \mu_R) + R(S - \mu_S)$$ - 并减去
$$\mathbb{E}[RS] = \mu_R\mu_S + \sigma_{RS}$$
- 重写为
- 公式 (14) 是将公式 (2) 应用于 \(\hat{R}^{(\times)}\) 的结果
- 公式 (12) 由下面的公式得到:
Remark 3.3 (为什么乘性塑形在组归一化下具有奖励感知性)
- 在加性塑形下,命题 3.1 表明长度偏差 \((S - \mu_S)\) 以固定系数 \(\lambda\) 注入中心化后的塑形奖励
- 这创造了一个补偿性的自由度:即使当 \(R\) 提供很少的学习信号时,策略也可以通过操纵 \(S\) 来改善塑形奖励
- 相比之下,命题 3.2 给出了分解式
$$RS - \mathbb{E}[RS] = R(S - \mu_S) + \mu_S(R - \mu_R) - \sigma_{RS}$$- 其中长度偏差的影响被 \(R\) 本身缩放
- 因此,当奖励低时长度控制较弱,并随着任务性能提高而增强,使得乘性塑形内在地具有奖励感知性
- 问题:为什么奖励低时应该用耿荣的长度控制?奖励高时应该用更强的长度控制?
Group Relative Length Regularization
- 之前工作的问题:
- 许多先前的工作通过施加绝对长度阈值(2025;2025c)来解决长度膨胀问题,惩罚超过固定预算的轨迹
- 这种设计可能会抑制困难实例上的必要推理,使策略对任务难度不敏感,从而降低性能
- 更重要的是,固定的阈值不可避免地会导致 Off-policy 偏差:
- 最优推理长度随任务变化,并在训练过程中发生改变,这是单一的全局常数无法捕捉的
- 许多先前的工作通过施加绝对长度阈值(2025;2025c)来解决长度膨胀问题,惩罚超过固定预算的轨迹
- 解法:组相对长度正则化策略,它能够适应 On-policy 行为
- 根据公式 6,使用组内统计量定义一个界于 \((0,1)\) 的有界长度塑形项 \(S^{(i)}\):
$$S^{(i)} = \frac{1}{1 + \alpha \cdot \frac{\ell^{(i)} }{\bar{\ell} } }, \quad \alpha >0. \tag {15}$$- \(\ell^{(i)}\) 是 Response 长度
- \(\bar{\ell}\) 是组均值
- 这个惩罚随着长度增加而平滑下降,同时通过 \(\bar{\ell}\) 归一化避免了任意的全局阈值,并使惩罚适应模型当前的生成行为
- 根据公式 6,使用组内统计量定义一个界于 \((0,1)\) 的有界长度塑形项 \(S^{(i)}\):
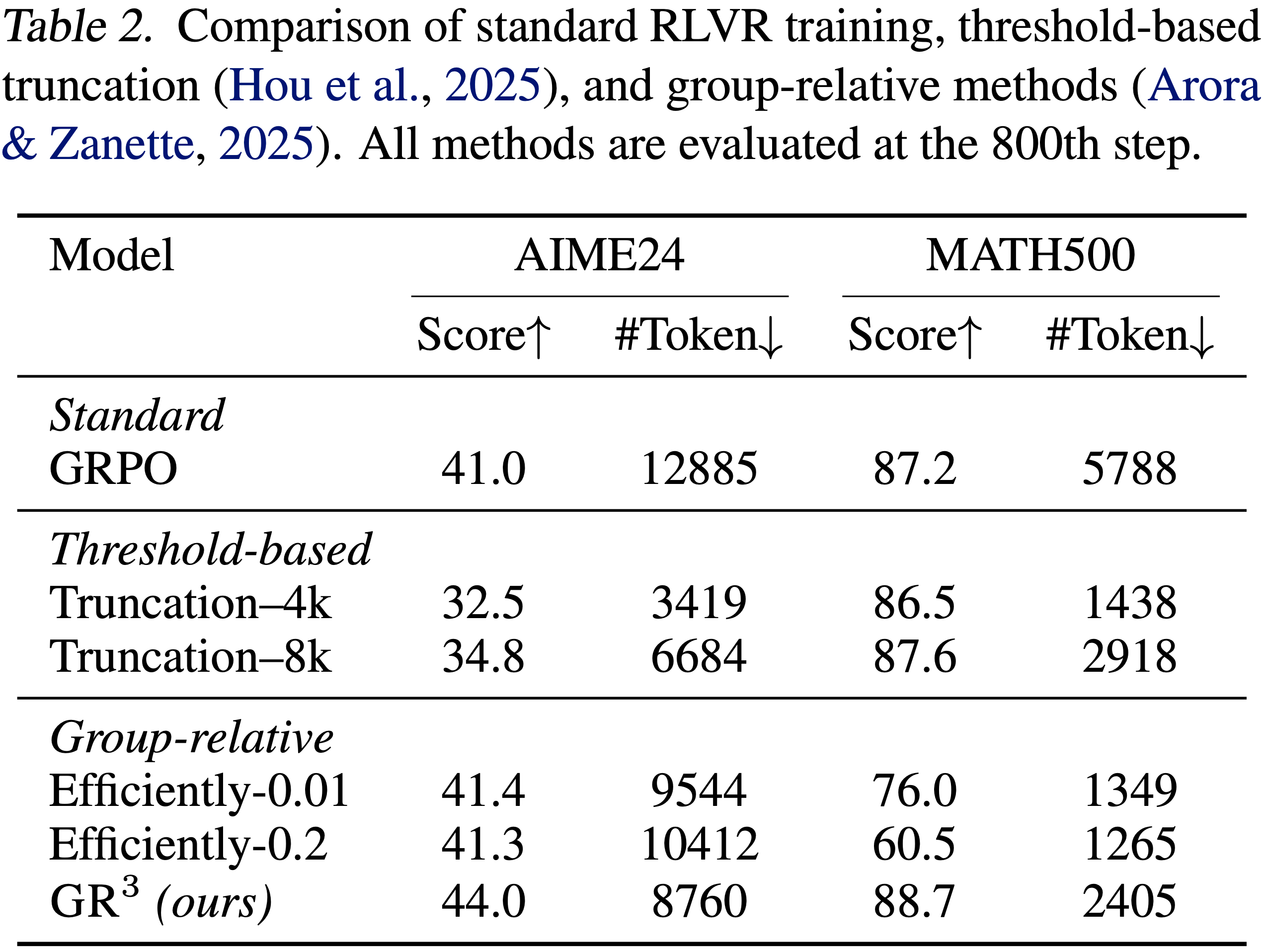
- 如表 2 所示,将固定阈值截断方法(2025)作为一个极简基线
- 可以发现,基于阈值的截断即使在困难的基准测试上也强加了统一的最大 Response 长度,这会损害在挑战性问题上的推理性能
- 与其他组相对方法进行比较,发现某些塑形策略(2025)引入了偏向于在简单基准上进行浅层推理的偏差(分析见附录 B)
- 作者还评估了另一种组相对方法 Kimi-1.5(2025),但它表现出训练崩溃;
- 因此,作者省略了其结果
- 作者将此失败归因于没有门控的加性塑形范式,如第 3.1 节所述
Advantage-Aware Calibration
- 在组相对策略优化的框架内,长度惩罚项 \(S\) 充当了优势格局的强大塑造者
- 惩罚强度与组归一化之间的相互作用 is non-trivial:\(S\) 的微小变化都可能显著改变优化轨迹
- 在实践中,无约束或过强的惩罚可能会严重惩罚高质量 Response ,以至于产生一个矛盾的信号,阻止模型生成其最佳 Response
- 一个自然但过于严格的目标是要求所有高质量轨迹都保持正优势
- 在高奖励密度下,当组内大多数 Response 都达到最大奖励 \(R_{\text{max} }\) 时(例如,16 个中有 15 个是正确的),这会变得难以实现
- 由于组归一化的零和结构,正确但长度高于平均水平的 Response 可能不可避免地获得负优势
- 作者在附录 C.1 中对此限制提供了正式分析
- 理解:GRPO 中,优势为负的 Response 会被打压(降低生成概率),优势为正的 Response 会被提升(提升生成概率)
- 所以这里主要想强调高质量的 Response 不应该 优势为负
- 问题:实际上,从 PG 方法来看,即使所有的梯度系数(比如可以为累计收益)都为正,或者都为负,也总会收敛到最优策略(至少从数学上来看是这样的,所有动作的概率都在被提升的时候,因为总的概率和为 1,所以提升最大的动作肯定是概率提升的,提升最小的动作概率肯定是下降的),所以推测,GRPO 这里理论上也不一定需要这个优质样本优势为正的强假设
Average-Case Advantage Preservation,平均情况优势保持
- 我们不是要保护最长的异常轨迹,而是旨在保持一个有代表性的高质量 Response 的优势
- 考虑一个 Response ,它达到了组内最大奖励 \(R_{\text{max} }\),并具有组平均长度 \(\bar{\ell}\),并要求其优势保持非负
- 令 \(\mu_{\bar{R} }\) 表示组内正则化后奖励的均值,这产生了条件:
$$\frac{R_{\text{max} } }{1 + \alpha\cdot\frac{\bar{\ell} }{\bar{\ell} } }\geq \mu_{\bar{R} }\Rightarrow \frac{R_{\text{max} } }{1 + \alpha}\geq \mu_{\bar{R} } \tag {16}$$- 这确保了惩罚 \(\alpha\) 不会推翻一个典型高质量 Response 的优势
- 在组内所有轨迹都达到 \(R_{\text{max} }\) 的极限情况下,平均情况约束仍然可能无法满足
- 因此,本文过滤掉此类组 (见附录 C.2)
- 在实践中,由于 On-policy 采样的随机性,公式 (16) 并非作为每次更新的硬约束来执行
- 可将其视为选择惩罚系数 \(\alpha\) 的校准标准
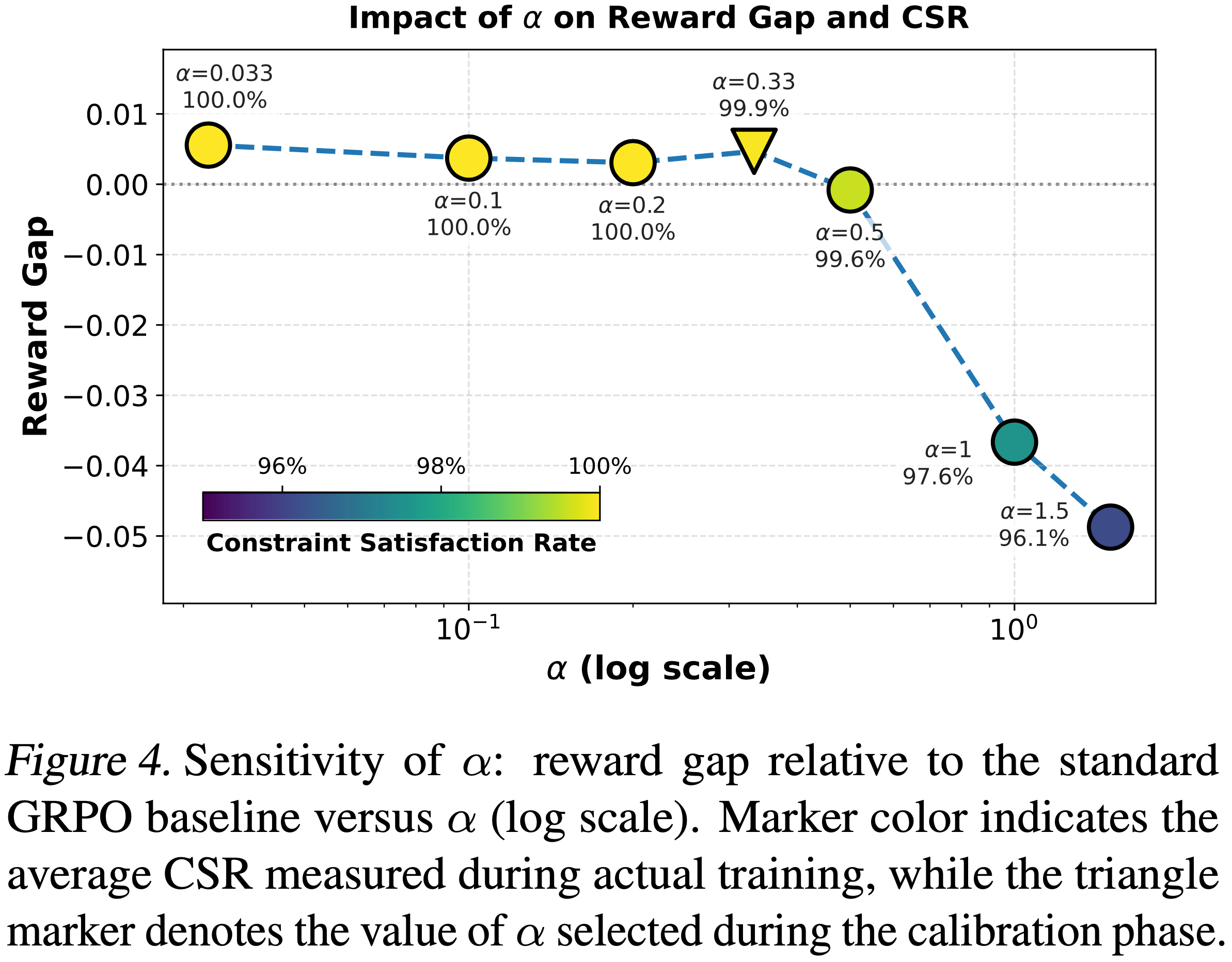
- 在 GRPO 训练开始时运行一个短暂的校准阶段,并测量候选 \(\alpha\) 值上的约束满足率(Constraint Satisfaction Rate, CSR)
- 然后选择 CSR 保持持续高值(例如,\(\geq 99.9%\))的最大 \(\alpha\),以确保高概率的约束满足,同时保持强大的长度正则化
- 经验上,通过此协议选择的 \(\alpha\) 在整个训练过程中保持了近乎完美的 CSR(见图 4)
- 这一点有效地标志了一个实际边界:相对于 GRPO 基线的奖励差距已经是正的,表明任务能力得到保留
- 进一步降低惩罚强度(即减小 \(\alpha\))不会带来一致的性能提升,反而会导致与训练方差一致的波动
Experiments
Setup
Efficient Reasoning for RLVR
- 遵循先前的工作,采用 DeepSeek-R1-Distill-1.5B 和 DeepSeek-R1-Distill-7B (2025) 作为基础模型
- 对于数学推理,使用 DeepScaleR-Preview-Dataset (2025b) 作为训练数据
- 将现有高效推理方法的开源检查点作为基线,如 LC-R1 (2025)、Laser (2025c)、AdaptThink (2025) 和 DLER (2025b)
- For 通用性,进一步将其扩展到代码生成任务,使用来自 DeepDistill (2025) 的 Prompt
Mitigating Length Bias in RLHF
- 对于 RLHF 设置,使用非推理版本的 Qwen3-4B 和 Qwen3-8B (2025) 作为基础模型
- 从 arena-human-preference-140k 构建 RL Prompt,并采用 Skywork-Reward-V2-Llama-3.1-8B (2025a) 作为奖励模型
- 为了提高训练稳定性,应用了基于参考的 Sigmoid 塑形 (2025) 方案(原始论文见:(PAR)Reward Shaping to Mitigate Reward Hacking in RLHF, 20250226-20260121, Fudan & UC Berkeley & StepFun):
$$R(x,y^{(i)}) = s\Big(R_{\text{origin} }(x,y^{(i)}) - R_{\text{origin} }(x,y^{\text{ref} })\Big). \tag {17}$$- \(R_{\text{origin} }(\cdot)\) 表示原始奖励模型分数
- \(s(\cdot)\) 是 sigmoid 函数
- 注:原始论文中,可能会有多个 参考回复 \(y^{\text{ref}}\)
- 详细的实验设置在附录 D 中提供
Main Results
Efficient Reasoning for RLVR
- 7B 模型的实验结果如表 3 所示,1.5B 模型的结果见附录 E.1
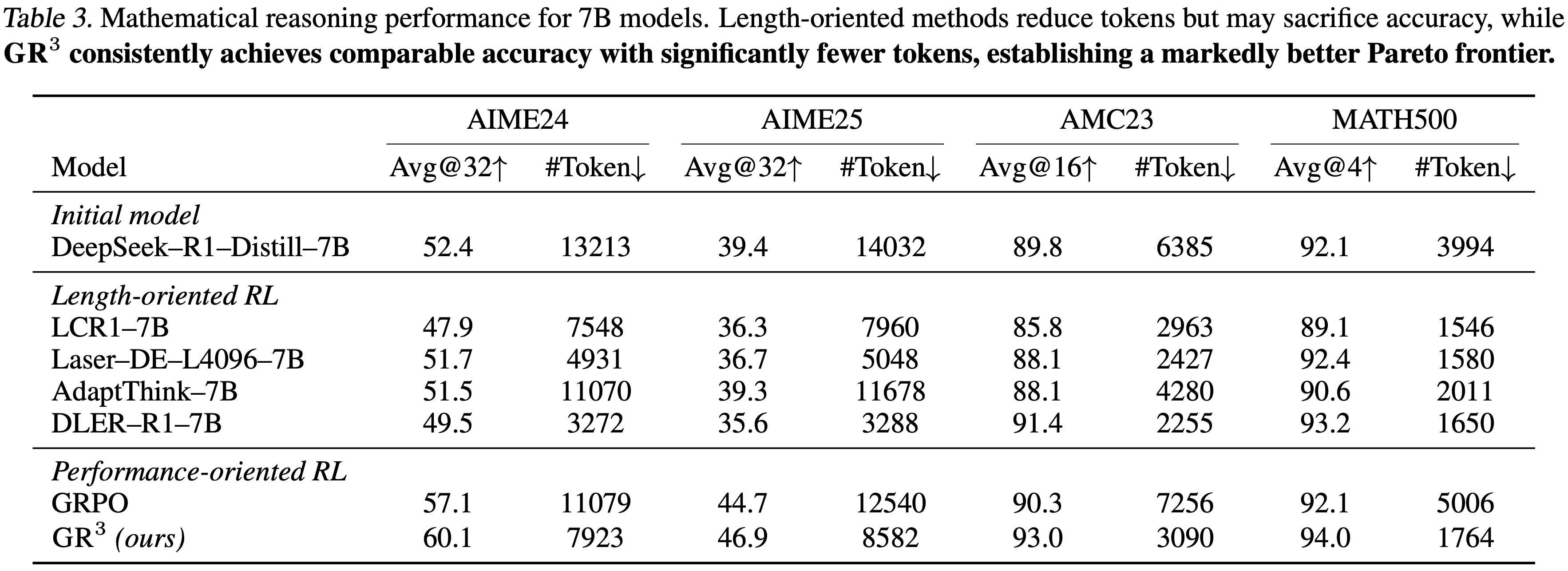
- \(\mathbf{GR}^3\) 在减少生成长度的同时提高了推理性能,这表明其实现了真正的效率提升,而非一种权衡
- 在数学推理中,与标准 GRPO 相比,\(\mathbf{GR}^3\) 在保持甚至提升性能的同时,生成了更短的文本
- 在 7B 规模的 AIME24 上
- \(\mathbf{GR}^3\) 平均长度:13,213 Token -> 7,923 Token(GRPO 为 11079)
Avg@32:52.4 -> 60.1(GRPO 为 57.1)
- 在 7B 规模的 AIME24 上
- 在数学推理中,与现有的面向长度的基线相比,\(\mathbf{GR}^3\) 没有以牺牲准确性为代价过度压缩推理长度
- GR3 能优先在保持性能的同时去除冗余推理
- 在 AIME25(7B)上,没有一个面向长度的基线能够超越初始检查点的性能(39.4),而 \(\mathbf{GR}^3\) 则用更少的 Token(14,032 -> 8,582)将其性能提升至 46.9
- 这表明 \(\mathbf{GR}^3\) 鼓励更高效的推理轨迹,而不仅仅是截断推理,从而在不同规模上都能带来持续的增益
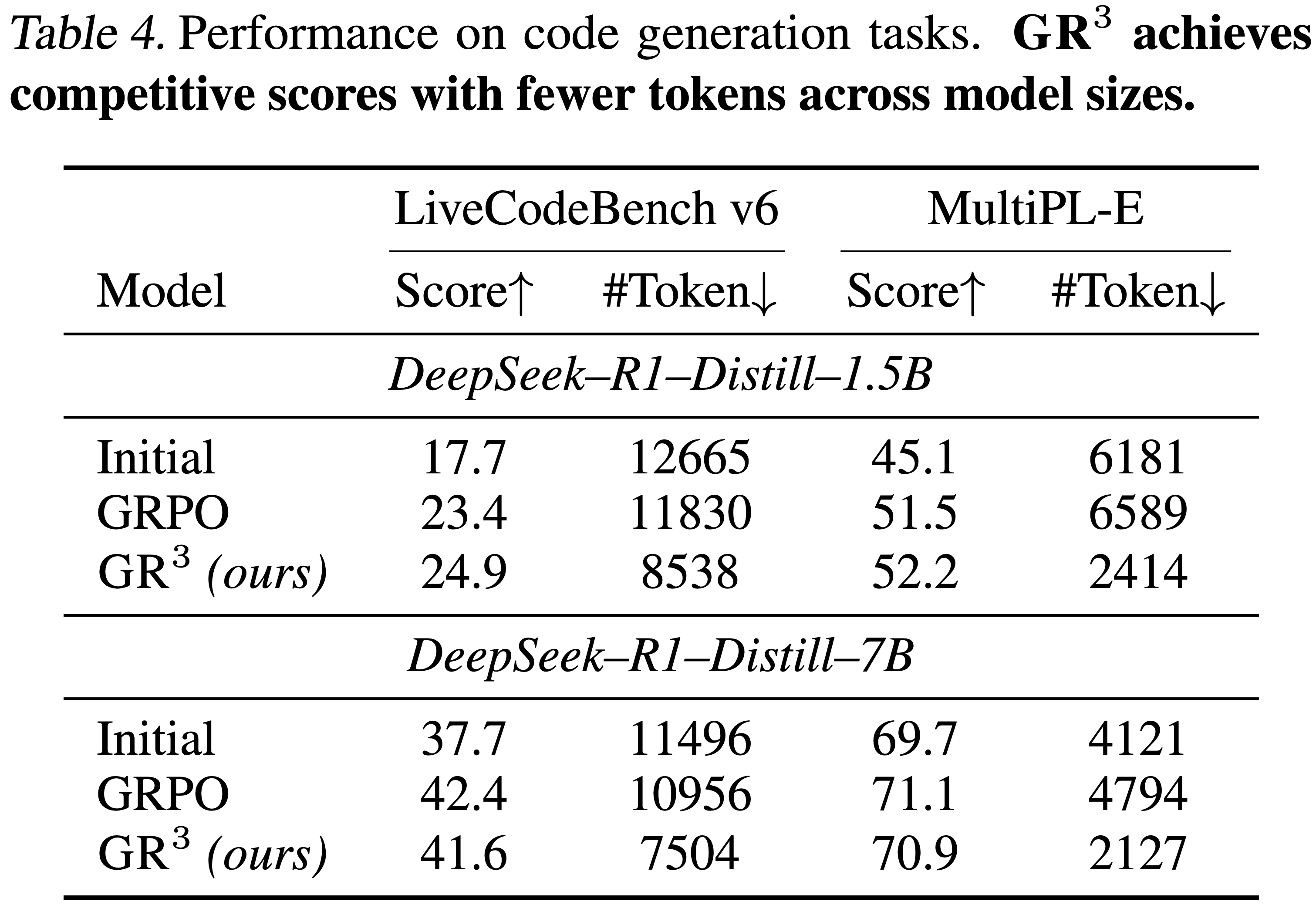
- 表 4 展示了在代码 Setting 下的结果,与数学推理结论一致,\(\mathbf{GR}^3\) 在保持任务性能的同时实现了显著的效率提升
Mitigating Length Bias in RLHF
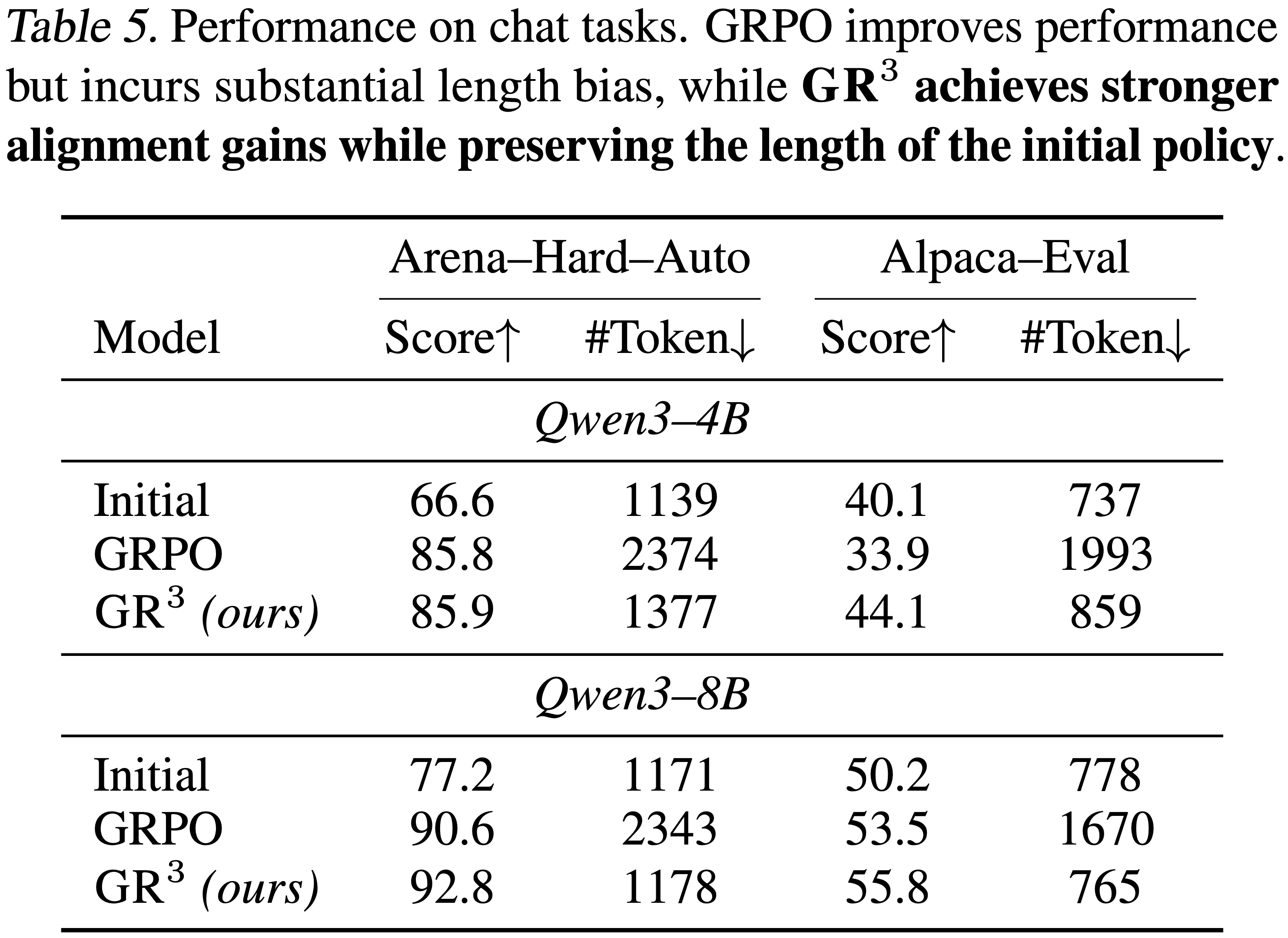
- 对齐基准上的结果如表 5 所示
- 与初始模型相比,RLHF 训练在聊天质量上带来了显著的改进
- 标准 GRPO:
- 在长度偏置下遭受严重的 Reward Hacking,即模型可以通过生成不必要地长 Response 来人为地增加奖励,导致爆炸性的长度膨胀
- 例如,在 Qwen3-8B 上,Arena-Hard-Auto 的平均 Response 长度从 1,171 个 Token 增加到 2,343 个 Token
- \(\mathbf{GR}^3\)
- 在保持 Response 长度几乎不变的同时,取得了相当甚至更强的对齐增益,有效地将性能提升与冗长性解耦
- 例如,在 Qwen3-8B 上,\(\text{GR}^{3}\) 将 Arena-Hard-Auto 分数从 77.2 提高到 92.8,而 Token 成本仅略微增加 (1,171 -> 1,178)
- 图 2 中进一步可视化了 RLHF 设置下的训练动态
- 在 GRPO 下,Response 长度在整个训练过程中单调且不可控地增长
- 相比之下,\(\text{GR}^{3}\) 呈现出清晰的“先增后减”模式 :模型最初扩展其推理以确保对齐改进,然后在性能稳定后压缩冗余生成
- 这种动态行为符合作者的设计直觉:\(\text{GR}^{3}\) 优先实现可靠的对齐增益,然后通过抑制基于长度的利用来逐步提高 Response 效率
Analysis and Discussion
Ablation on Penalty Strength \(\alpha\)
- 通过在其值范围内进行扫描来研究惩罚系数 \(\alpha\) 的影响,同时保持所有其他设置不变
- 注:详细的结果和分析见附录 E.2,这里作者仅总结关键发现
- 当 \(\alpha\) 过大时(例如,1.0):\(\text{GR}^{3}\) 退化为一种朴素的长度正则化方法:Response 变得更短,但相较于基础模型的性能增益有限,因为优化过程主要由压缩主导,而非能力提升
- 随着 \(\alpha\) 减小:Response 长度平滑增长,而任务性能先提高后趋于平稳
- 这一趋势与第 3.3 节的分析一致:
- 当具有代表性的高质量轨迹的优势得以保留后,进一步减小惩罚主要会放宽长度控制,而不会产生更强的学习信号
- 问题:如何理解这里的 不会产生更强的学习信号?
- 所选值 \(\alpha = 0.33\) 接近这个过渡区域,在保留大部分性能增益的同时实现了显著的长度缩减
- 这一趋势与第 3.3 节的分析一致:
Why Does \(\text{GR}^{3}\) Outperform GRPO?
- 作者观察到一个反直觉的现象:在许多 Setting 中,\(\text{GR}^{3}\) 不仅缩短了 Response,而且取得了比标准 GRPO 更强的下游性能,同时相对于 GRPO 基线保持正向的奖励差距
- 作者将此归因于优化信号结构方式的不同
- 在无约束的 RL(如 GRPO)下,策略往往会漂移到过度扩展的推理轨迹上
- 尽管这些轨迹最终可能达到正确答案,但它们往往包含许多贡献较低的 Token
- 从优化的角度来看,这会使得学习信号在长 Response 中被稀释,降低了奖励对最重要推理步骤的有效影响
- 通过抑制不必要的冗长,\(\text{GR}^{3}\) 在保留关键步骤的同时压缩了推理痕迹
- 这增加了奖励相对于 Token 的信号密度,使得优化能够更强烈地聚焦于因果上重要的推理模式 ,而不是将梯度分散在冗长但相关性弱的 Token 上
- 附录 F 中提供了定性的生成示例
Related Work
- RL (1996; 2022; 2025) 存在推理成本高和生成长度不断增长的问题,作者将这一瓶颈称为 长度膨胀 (length inflation)
- 一系列工作研究高效推理 (2025; 2025),旨在改进长思维链模型的准确率-成本权衡
- 早期方法依赖于 Prompt 工程或有监督微调来鼓励更短的推理痕迹 (2025a; 2025; 2025b)
- 最近更多的方法应用 RL,通过长度感知的目标直接优化效率 (2025; 2025c; 2025)
- 虽然这些方法在减少 Token 使用方面很有效,但由于惩罚校准不佳或存在捷径解 (2025),它们可能会降低性能或引入不稳定的优化动态
- 另一系列工作将 RLHF 中的长度膨胀归因于 Reward Hacking 和长度偏置 (2022; 2023; 2023)
- 由于奖励模型可能隐式地偏爱较长的 Response,冗长可能源于利用奖励的假象而非真正的能力提升 (2023)
- 先前的工作通过改进奖励建模和校准 (2024a; 2025) 或应用事后奖励修正 (2024) 来缓解这一问题,尽管许多这些解决方案是针对特定训练环境定制的
- \(\text{GR}^{3}\) 与基于 RL 的高效推理最为相关,并且在由长度偏置驱动的 Reward Hacking 情况下仍然有效
- \(\text{GR}^{3}\) 是一个通用的长度正则化框架,在保持性能的同时改善了性能-成本帕累托前沿
附录 A:Connection to Heuristic Gating Mechanisms,分析 GR3 与启发式门控机制的联系
- 第 3.1 节中主要从消除加法塑形固有的补偿性优化捷径的角度来激励乘法塑形
- 本节通过分析 \(\text{GR}^{3}\) 与启发式门控机制 (2025; 2025) 之间的关系,提供另一种视角
- 作者证明,乘法塑形可以被视为启发式门控的一个 Principled 泛化:
- 在二元奖励设置中数学上简化为门控,同时在硬指示器失效的连续奖励场景中提供了一个鲁棒的、”软性”的门控机制
Equivalence in Binary Reward Settings,二元奖励中两者是等价的
- 启发式门控是对高效推理 (RLVR) 中加法塑形的一种常见改进,可防止模型以牺牲准确性为代价来优化长度
- 启发式门控通常采用一个指示函数 \(\mathbb{I}(R = 1)\),仅在 Response 正确时应用长度惩罚
- 设 \(P\) 表示一个通用的基于长度的惩罚项(例如,一个长度的负函数)
- 标准的门控加法塑形将等式 5 中的塑形项 \(S\) 修改为依赖于任务成功与否的条件形式:
$$\text{Gated Additive: }\hat{R}^{(+g)} = R + \lambda \cdot S_{\text{gate} }$$ $$\text{where }S_{\text{gate} } = \mathbb{I}(R = 1)\cdot P.$$- \(\mathbb{I}(R = 1)\) 是一个硬门控
- \(R\in \{0,1\}\) 是二元任务结果
- 标准的门控加法塑形将等式 5 中的塑形项 \(S\) 修改为依赖于任务成功与否的条件形式:
- 考虑在等式 7 中定义的乘法塑形:
$$\text{Multiplicative: }\hat{R}^{(\times)} = R\cdot S_{\text{mult} }.$$ - 为了便于比较,将缩放因子 \(S_{\text{mult} }\) 分解为一个基线和偏差项
- 将 \(S_{\text{mult} } = 1 + (S_{\text{mult} } - 1)\) 重写,其中偏差对应于缩放机制应用的隐式惩罚:
$$\lambda P:= S_{\text{mult} } - 1\quad \Longrightarrow \quad S_{\text{mult} } = 1 + \lambda P.$$
- 将 \(S_{\text{mult} } = 1 + (S_{\text{mult} } - 1)\) 重写,其中偏差对应于缩放机制应用的隐式惩罚:
- 分析两种二元状态下的行为:
- 情况 \(R = 0\) (失败):
$$\hat{R}^{(+g)} = 0 + \lambda \cdot (0\cdot P) = 0$$ $$\hat{R}^{(\times)} = 0\cdot (1 + \lambda P) = 0$$- 两种方法都会停用惩罚,防止在困难实例上过早终止
- 情况 \(R = 1\) (成功):
$$\hat{R}^{(+g)} = 1 + \lambda \cdot (1\cdot P) = 1 + \lambda P$$ $$\hat{R}^{(\times)} = 1\cdot (1 + \lambda P) = 1 + \lambda P$$- 两种方法都应用完整的惩罚,以激励正确解决方案中的效率
- 情况 \(R = 0\) (失败):
- 结论:在典型的 RLVR 的严格二元奖励设置中,乘法塑形在数学上等价于启发式门控
- 继承了在不正确的推理路径上保护策略免受惩罚的理想特性
Generalization to Continuous Rewards,泛化到连续奖励
- 当过渡到连续奖励设置时,启发式门控的局限性变得明显,例如 RLHF(其中奖励通常由奖励模型给出)或具有部分分数的推理任务
- 在这些场景中,硬指示器 \(\mathbb{I}(R = 1)\) 是难以定义的
- 简单地将它替换为一个阈值 \(\mathbb{I}(R > \tau)\) 会引入超参数和优化不连续性
- 相反,完全移除门控(回到纯粹的加法塑形)会重新引入命题 3.1 中讨论的权衡问题,即模型可以通过缩短长度来改进 \(\hat{R}^{(+)}\),即使 \(R\) 略有下降
- 乘法塑形通过充当软门控机制解决了这个问题
- 正如命题 3.2 推导的那样,在乘法塑形下,组归一化优势包含以下控制长度信号的项:
$$A(\hat{R}^{(\times)})\propto R\cdot (S - \mu_S) + \ldots$$ - 这个分解表明,长度变化 \((S - \mu_S)\) 对优势的影响明确地由任务奖励 \(R\) 缩放
- 这创建了学习信号的动态重加权:
- 低质量 \((R \approx 0)\): 长度信号被抑制 \((R \cdot (S - \mu_S) \approx 0)\)
- 优势主要由改进任务正确性的需求决定,策略几乎收不到关于长度的信号。这模仿了非激活的门控,防止模型坍缩到短但不正确的 Response
- 高质量 \((R \approx 1)\): 长度信号完全激活 \((R \cdot (S - \mu_S) \approx S - \mu_S)\)
- 优势显著地倾向于成功组内较短的轨迹
- 这模仿了激活的门控,能力得到保证后,就有效地优先考虑效率
- 低质量 \((R \approx 0)\): 长度信号被抑制 \((R \cdot (S - \mu_S) \approx 0)\)
- 正如命题 3.2 推导的那样,在乘法塑形下,组归一化优势包含以下控制长度信号的项:
- 这个特性有效地根据 Response 质量在”无惩罚”和”完全惩罚”之间进行插值
- 因此,\(\mathbf{GR}^3\) 允许作者在 RLHF 中应用强长度正则化,而不会有模型坍缩到短、低质量 Response 的风险,如图 2 中的动态所示
Empirical Observation
- 作者进一步进行了一项分析实验,如图 5 所示
- 通过定义 \(\lambda P := S_{\text{mult} } - 1\),将乘法塑形项转换为门控加法塑形中使用的惩罚形式
- 然后引入不同的阈值 \(\mathbb{I}(R > \tau)\) 来将门控加法塑形扩展到连续奖励的 RLHF 设置
- 可观察到
- 由于优化不连续性,所有 \(\tau\) 的选择都导致性能低于标准 GRPO
- 同时,生成长度被更激进地减少,降至基础策略模型的典型水平以下
")
附录 B:Analysis of the Difficulty Over-Adaptation Phenomenon,难度过适应现象分析
- 第 3.2 节中讨论了组相对长度正则化如何使长度预算适应于 on-policy 统计量
- 虽然这消除了全局阈值的刚性,但在某些塑形策略中观察到了一个意想不到的副作用(例如,Efficiently (2025)):
- 策略可能变得对感知到的任务难度过度适应(over-adaptive) ,作者将此现象称为难度过适应(Difficulty Over-Adaptation)
- 具体解释:模型倾向于在简单 Prompt 上激进地压缩推理,而在困难 Prompt 上未能有效约束过长的长度
- 理解:可能是因为
- 简单的 Prompt 上,大家的奖励都收敛为 1 左右了,从而学习的重点是长度(缩短)
- 困难的 Prompt 上,偶尔有一个正确的 Response,此时的长度惩罚可能不占主体,主要以优化 Response 为主
- 因为乘法情况下,想要获得高的 Final Reward,高质量(Reward Score 为正)的回复是必须的前提
- 理解:可能是因为
- 如表 2 所示,并通过表 6 中的示例加以说明
- 换句话说,正则化器扭曲了推理 effort 在不同难度级别上的分配

- 为了理解这种偏差背后的机制,作者分析奖励函数对长度变化的敏感性
- 考虑 Efficiently (2025) 的公式:
$$\hat{R} (x,y^{(i)}) = R(x,y^{(i)}) - \lambda \cdot \mathbb{I}(R(x,y^{(i)}) = 1)\cdot s\left(\frac{\ell^{(i)} - \bar{\ell} }{\sigma_{\ell} }\right).$$- 在这个公式中,sigmoid 函数 \(s(\cdot)\) 的输入被因子 \(1 / \sigma_{\ell}\) 放大
- 这意味着增加 Response 长度的边际惩罚与该组的统计离散度 \((\sigma_{\ell})\) 成反比
- 这种依赖性在不同难度区间内造成了不稳定性
- 在较简单的 Prompt 上,策略通常很自信,并收敛到一致的 Response ,导致长度标准差坍缩(即,\(\sigma_{\ell} \rightarrow 0\))
- 因此,缩放因子 \(1 / \sigma_{\ell}\) 变得极大
- 在这个低方差区间内,即使是一个 token 的偏差也会被视为巨大的统计异常值,触发奖励的严重下降
- 这种 hypersensitivity 迫使模型过度压缩简单 Response 以避免严厉的惩罚
- 在困难的 Prompt 上,策略通常会探索多样化的推理路径,导致更大的 \(\sigma_{\ell}\)
- 这会减弱惩罚信号,使得较长的生成能够以相对较小的代价持续存在
- 在较简单的 Prompt 上,策略通常很自信,并收敛到一致的 Response ,导致长度标准差坍缩(即,\(\sigma_{\ell} \rightarrow 0\))
- 考虑 Efficiently (2025) 的公式:
- 相比之下,\(\text{GR}^{3}\) 基于特征尺度(平均长度 \(\bar{\ell}\))而非离散度来归一化惩罚:
$$\hat{R} (x,y^{(i)}) = R(x,y^{(i)})\cdot \frac{1}{1 + \alpha\cdot\frac{\ell^{(i)} }{\ell} }.$$- 惩罚的敏感性取决于相对于 \(\bar{\ell}\) 的比率
- 平均长度 \(\bar{\ell}\) 对于较简单的任务自然更小(适当地使预算更紧张)
- 但它代表了 Response 的物理尺度,并且不会随着模型变得自信而坍缩到接近零的值
- \(\text{GR}^{3}\) 使用基于尺度而非方差进行归一化,提供了一个稳定的正则化信号
- 该信号对模型的收敛状态保持鲁棒,有效地缓解了不同难度级别间压缩压力的不平衡
附录 C:The Dilemma of High Reward Density,高奖励密度的困境
- 本节分析了将长度正则化与组归一化优势相结合时出现的一个基本结构张力
- 作者证明,在高奖励密度下,一个看似理想化的严格条件(确保所有最高奖励轨迹都保持正优势)通常在数学上是不可行的
- 然后作者证明,即使是一个宽松的平均情况标准,在所有采样轨迹都达到 \(R_{\text{max} }\) 的极限情况下也会退化,这是由于乘法长度重缩放的凸性所致
- 这些观察结果证明了第 3.3 节中采用的基于松弛的校准策略和在线过滤策略的合理性
C.1 Impossibility of the Strict Advantage-Preservation Objective,严格优势保持目标是不可行的
A Strict but Natural Objective
- 长度感知强化学习的一个自然目标是保留最佳解决方案的优化信号
- 具体来说,考虑以下严格条件:在一个采样组内,所有达到最大任务奖励 \(R_{\text{max} }\) 的轨迹,在长度正则化后应获得正的优势
- 直观上,这些轨迹代表了最高质量的 Response ,给它们分配负的优势可能会阻碍正确的推理行为
- 在 GRPO 风格的归一化下,严格的目标因此等价于要求
$$\hat{R} (x,y^{(j)}) > \mu_{\hat{R} },\quad \forall j\in \mathcal{H}$$- \(\mathcal{H}:= \{j:R(x,y^{(j)}) = R_{\text{max} }\}\) 表示最高奖励轨迹的集合
- \(\hat{R} (x,y^{(j)})\) 是正则化后的奖励,而 \(\mu_{\hat{R} }\) 是组内正则化奖励的平均值
Impracticality Under High Reward Density,在高奖励密度下,上述目标不切实际
- 在高奖励密度下,为所有最高奖励轨迹保留正优势的严格目标在数学上是不可行的,无论长度惩罚系数 \(\alpha\) 有多小
- 在 \(\mathbf{GR}^3\) 下,正则化奖励为
$$\hat{R} (x,y^{(j)}) = \frac{R(x,y^{(j)})}{1 + \alpha \cdot \frac{\ell^{(j)} }{\ell} }.$$ - 对于所有 \(j\in \mathcal{H}\),有 \(R(x,y^{(j)}) = R_{\text{max} }\),因此 \(\hat{R}\) 的变化仅取决于长度
- 由于正则化项在 \(\ell^{(j)}\) 上是单调递减的,\(\mathcal{H}\) 中最长的轨迹
$$\ell_{\text{max} } = \max_{j\in \mathcal{H} }\ell^{(j)}$$ - 获得最小的正则化奖励
$$\hat{R}_{\text{min} } = \frac{R_{\text{max} } }{1 + \alpha \cdot \frac{\ell_{\text{max} } }{\ell} }.$$ - 当奖励密度高时,组均值 \(\mu_{\hat{R} }\) 主要由 \(\mathcal{H}\) 中的轨迹决定,因此近似于它们的平均值
- 由于一个集合的最小值不能超过其均值,作者必须有 \(\hat{R}_{\text{min} }\leq \mu_{\hat{R} }\)
- 因此,至少有一个最高奖励轨迹在组归一化后获得非正的优势
- 这表明,在高奖励密度下,所有最高奖励轨迹在组归一化后都保持正优势是不可能的
- 这种冲突是结构性的,而非超参数选择的结果
- 即使在极限 \(\alpha \rightarrow 0\) 下,这种不可能性仍然存在
- 使用一阶展开,
$$\hat{R} (x,y^{(j)})\approx R_{\text{max} }\cdot \left(1 - \alpha \cdot \frac{\ell^{(j)} }{\ell}\right)$$ - 并记
$$\bar{\ell}_{\mathcal{H} } = \frac{1}{k}\sum_{j\in \mathcal{H} }\ell^{(j)}$$ - 为最高奖励轨迹中的平均长度,得到
$$\hat{R} (x,y^{(j)}) - \mu_{\hat{R} }\approx -R_{\text{max} }\cdot \alpha \cdot \frac{\ell^{(j)} - \bar{\ell}_{\mathcal{H} } }{\bar{\ell} }.$$ - 因此
$$\hat{A}^{(j)}\propto -(\ell^{(j)} - \bar{\ell}_{\mathcal{H} }).$$ - 所以任何长度超过 \(\mathcal{H}\) 平均长度的最高奖励轨迹都必须获得负优势,无论 \(\alpha\) 有多小
- 组归一化强制实行零均值约束,这不可避免地导致在具有不同长度的同等正确的轨迹中产生符号翻转
- 使用一阶展开,
Empirical Observation
- 图 6 凭经验说明了这一现象
- 横轴显示组中达到 \(R_{\text{max} }\) 的轨迹比例(奖励密度),纵轴显示满足严格条件 \(A_{i} > 0\) 的最高奖励轨迹的比例
- 即使使用非常小的惩罚强度(图 6(a), \(\alpha = 0.05\)),满足率也随着奖励密度的增加而下降
- 使用较大的 \(\alpha\)(图 6(b), \(\alpha = 5.0\)),下降变得更加明显
- 这些结果证实,严格条件的违反源于固有的结构冲突,而不是糟糕的超参数调整

- 这个不可能性结果直接激发了第 3.3 节中宽松校准策略的提出(在组内所有轨迹都达到 \(R_{\text{max}}\) 的极限情况下, 过滤掉此类组)
- 作者不是试图保护最长的高奖励轨迹(这通常是不可行的),而是采用一个平均情况标准,确保一个典型的、长度接近组均值的高质量轨迹保持在组平均正则化奖励之上
- 这自然导致了等式 16 中的实际约束
C.2. Degeneracy of the Average-Case Criterion in the All-\(R_{\text{max} }\) Limit,全 \(R_{\text{max} }\) 极限下平均情况标准的退化
- 回顾平均情况校准标准(等式 16),它要求一个代表性的高质量轨迹(奖励 \(R_{\text{max} }\) 和平均长度 \(\bar{\ell}\))保持非负优势:
$$\frac{R_{\text{max} } }{1 + \alpha}\geq \mu_{\hat{R} }$$- \(\mu_{\hat{R} }\) 表示正则化奖励的组内均值
- 如第 3.3 节所述,在组中所有轨迹都达到 \(R_{\text{max} }\) 的极限情况下,这个约束可能会失败,这激发了在线过滤的动机
All-\(R_{\text{max} }\) case reduces the condition to a Jensen inequality,全为 \(R_{\text{max} }\) 将条件简化为 Jensen 不等式
- 假设一个采样组满足所有 \(i \in \{1, \ldots , G\}\) 有 \(R(x,y^{(i)}) = R_{\text{max} }\)
- 在 \(\text{GR}^{3}\) 下,正则化奖励为
$$\hat{R}^{(i)} = R_{\text{max} }\cdot \frac{1}{1 + \alpha\cdot\frac{\ell^{(i)} }{\bar{\ell} } }.$$ - 定义归一化长度比率 \(z_{i} := \ell^{(i)} / \bar{\ell}\),它满足 \(\frac{1}{G} \sum_{i = 1}^{G} z_{i} = 1\)
- 设
$$f(z):= \frac{1}{1 + \alpha z},\qquad z\geq 0.$$ - 那么 \(\mu_{\hat{R} } = R_{\text{max} } \cdot \frac{1}{G} \sum_{i = 1}^{G} f(z_{i})\),并且等式 16 变为
$$f(1)\geq \frac{1}{G}\sum_{i = 1}^{G}f(z_{i}).$$
Convexity flips the inequality,凸性翻转了不等式
- 直接计算给出
$$f^{\prime \prime}(z) = \frac{2\alpha^{2} }{(1 + \alpha z)^{3} } >0$$ - 所以 \(f\) 在 \([0,\infty)\) 上是凸函数
- 根据 Jensen 不等式,
$$f\left(\frac{1}{G}\sum_{i = 1}^{G}z_{i}\right)\leq \frac{1}{G}\sum_{i = 1}^{G}f(z_{i}).$$ - 利用 \(\frac{1}{G}\sum_{i}z_{i} = 1\),可以得到
$$f(1)\leq \frac{1}{G}\sum_{i = 1}^{G}f(z_{i})$$- 这与期望的条件相反
- 而且,只要长度不全相同(即,当 \(z_{i}\) 不是常数时),这个不等式就是严格的
- 因此,在一个全 \(R_{\text{max} }\) 组中,等式 16 中的平均情况约束只有在退化情况 \(\ell^{(1)} = \dots = \ell^{(G)}\) 下才能成立;否则它必然失败
- 这解释了为什么作者在实践中通过在线过滤排除这样的组
- 理解:
- 这里这种组下,都是正确的回复,我们希望模型选择更短的 Response,似乎也不是什么问题吧?为什么在作者的眼里是一个问题呢?
附录 D:Detailed Experimental Settings
- 在跨越 RLVR 和 RLHF 的代表性后训练场景中评估 \(\text{GR}^{3}\)
- 在 RLVR 设置中,研究模型是否能在保持任务性能提升的同时,减少不必要的长 CoT 推理
- 在 RLHF 设置中,检验 GR3 是否减轻了 Reward Hacking (2016) 并产生具有自然 Response 长度的良好对齐的 Response
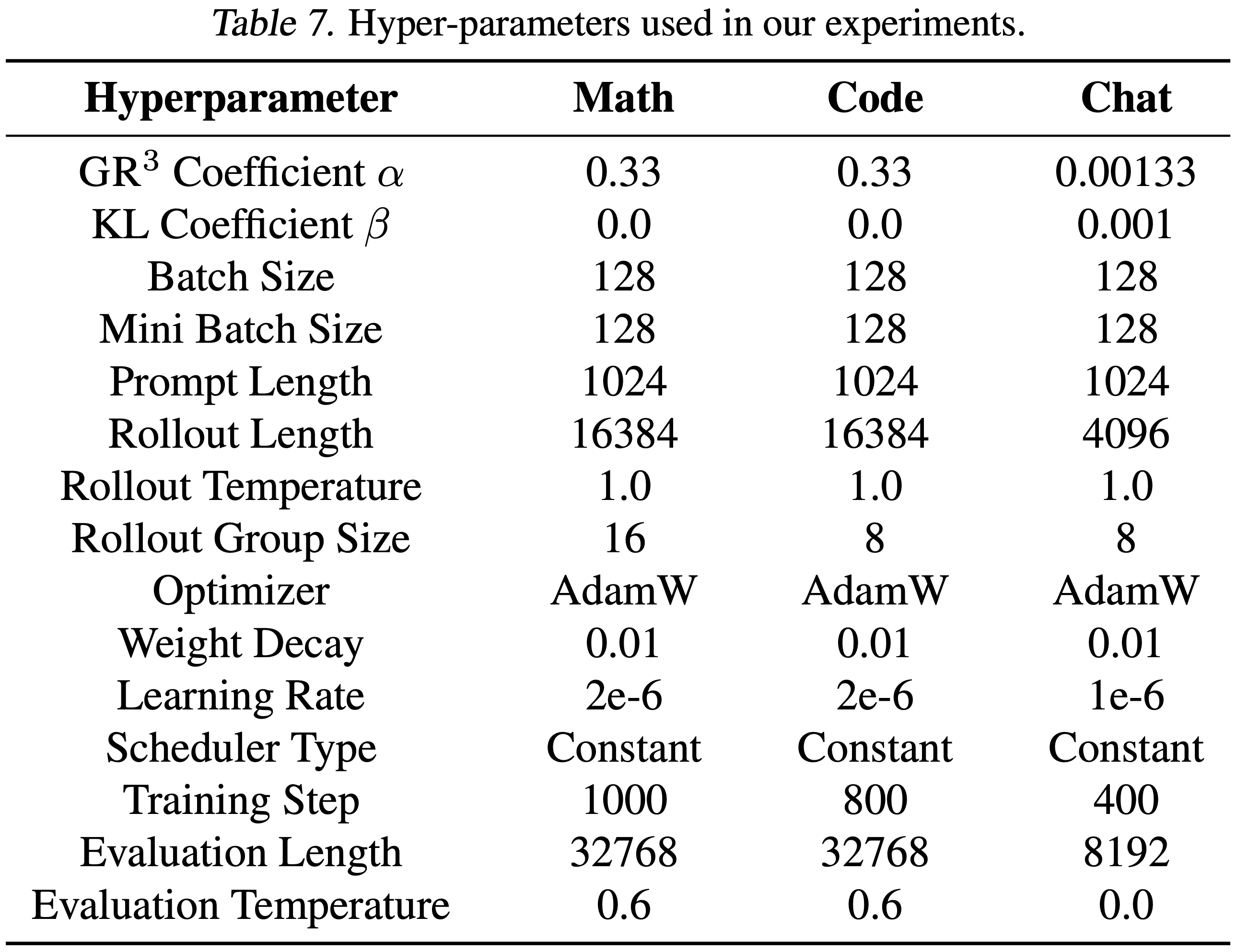
- 本节提供实验中使用的详细超参数和配置
- 所有实验均使用 veRL (2024) 作为训练框架进行,基于标准的 GRPO 优势估计器
- 实验的详细实现设置如表 7 所示
- 作者还做了如下验证:
- 在 AIME-24 (MAA, 2024)、AIME-25 (MAA, 2025)、AMC-23 (MAA, 2023) 和 MATH500 (2023) 上评估数学推理能力
- 在 LiveCodeBench v6 (2024) 和 MultiPL-E (2022) 上评估代码生成能力
- 在 Arena-Hard-Auto (2024) 和 AlpacaEval (2024) 上评估对话能力
- 遵循标准做法,报告 AlpacaEval 的长度控制 (LC) 胜率
- 对于 Arena-Hard-Auto,不应用长度控制,而是使用直接从原始成对评判器得出的分数
附录 E:Additional Experimental Results
E.1. Mathematical Reasoning Results on 1.5B Models
- 本节展示使用 DeepSeek-R1-Distill-1.5B 作为基础模型的数学推理任务实验结果
- 如表 8 所示,结果与 DeepSeek-R1-Distill-7B 的实验结果一致:
- \(\text{GR}^3\) 不仅显著增强了模型的推理能力,而且在 token 数量方面大幅减少了生成输出的长度,展示了在不同规模上的良好性能
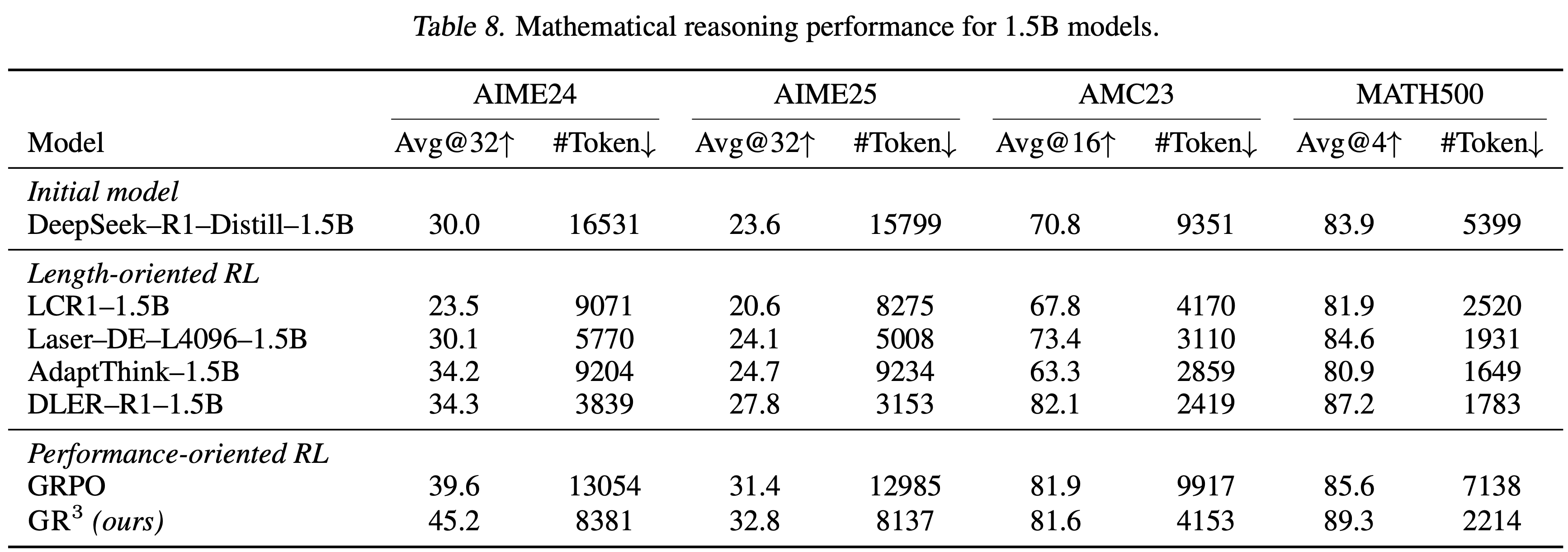
- \(\text{GR}^3\) 不仅显著增强了模型的推理能力,而且在 token 数量方面大幅减少了生成输出的长度,展示了在不同规模上的良好性能
E.2. Ablation Results on Penalty Strength \(\alpha\),关于 \(\alpha\) 的消融结果
- 本节通过在相同训练设置下改变其值,分析 \(\text{GR}^3\) 对长度惩罚系数 \(\alpha\) 的敏感性
- 1.5B 模型的详细结果如表 9 所示
- 当 \(\alpha\) 较大时(例如, \(\alpha = 1.0\)),乘法重缩放项会严重惩罚长轨迹,很大程度上独立于它们的奖励水平
- 在这种 regime 下,\(\text{GR}^3\) 的行为类似于传统的长度惩罚 RL,其中优化主要由缩短 Response 而非提高解决方案质量驱动
- 尽管 token 使用量显著减少,但相对于初始模型的性能增益变得明显较小,表明过于激进的正则化抑制了有用的长形式推理
- 随着 \(\alpha\) 减小, Response 长度以逐渐且良好的方式增加,而任务性能首先提高,然后趋于饱和
- 特别是,从 \(\alpha = 0.33\) 移动到更小的值(例如,0.2 和 0.1)会产生更长的生成,但准确率提升微乎其微或不一致
- 这一经验趋势与第 3.3 节中的分析紧密吻合
- 一旦惩罚足够弱,以至于代表性的高质量轨迹的优势得以保留,进一步降低 \(\alpha\) 主要会放宽长度约束,而不会引入更强的优化信号
- 换句话说,训练已经越过了优势保持边界,在此之后,额外的推理长度不再转化为有意义的性能增益
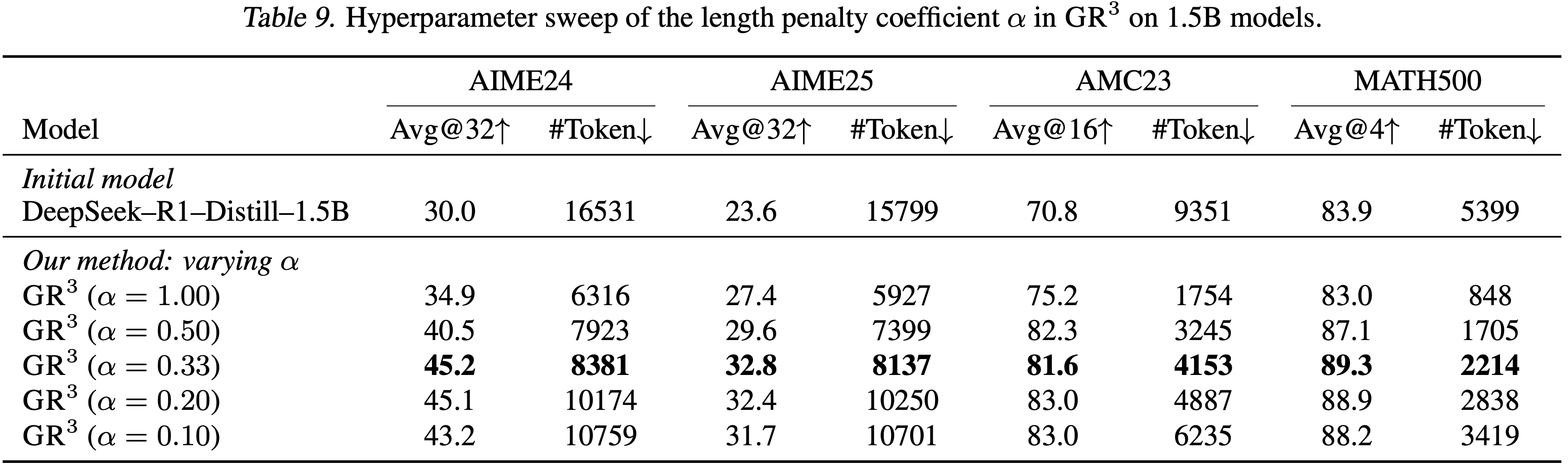
- 换句话说,训练已经越过了优势保持边界,在此之后,额外的推理长度不再转化为有意义的性能增益
- 特别是,从 \(\alpha = 0.33\) 移动到更小的值(例如,0.2 和 0.1)会产生更长的生成,但准确率提升微乎其微或不一致
- 当 \(\alpha\) 较大时(例如, \(\alpha = 1.0\)),乘法重缩放项会严重惩罚长轨迹,很大程度上独立于它们的奖励水平
- 总体而言,\(\alpha\) 控制着不同的行为区间,而 \(\text{GR}^3\) 提供了一种 Principled 方法,使其在长度控制和能力增益之间的优势保持过渡点附近进行选择
附录 F:Qualitative Analysis of Rollout Trajectories,Rollout 轨迹的定性分析
- 为了更好地理解两种训练目标所导致的行为差异,本节在相同的推理 Prompt 上,展示了 \(\text{GR}^3\) 训练模型和 GRPO 训练基线的代表性 rollout 示例
- 表 10 和 11 显示了生成轨迹
\(\text{GR}^3\): concise reasoning with preserved structure,简洁的推理与保留的结构
- 如表 10 所示,\(\text{GR}^3\) 训练的模型产生了一个既结构化又经济的推理轨迹
- 解决方案遵循清晰的进展:
- (i) 重述任务
- (ii) 识别完整旋转下方向的周期性
- (iii) 将角度约简为 \(360^{\circ}\) 的余数
- (iv) 将剩余旋转映射到罗盘方向
- 每一步都直接有助于推进解决方案,中间检查用于确认而非重新推导早期的结果

- 重要的是,轨迹以正确格式化的 boxed 答案果断终止
- 推理链既没有人为缩短,也没有过于冗长
- 冗余的重新计算和自我怀疑循环基本不存在
- 这反映了一个策略,它已经学会主要将 token 分配给因果相关的步骤
GRPO: verbose loops and diluted signal,冗长的循环和稀释的信号
- GRPO 训练的 baseline(表 11)表现出显著不同的行为
- 尽管它反复识别出正确的中间事实(例如 \(360^{\circ}\) 周期性和 \(2250 \mod 360 = 90^{\circ}\) 的约简)
- 但它经常重新推导这些事实,质疑先前已建立的结论,并在等效的公式之间振荡(例如,完整旋转与分数旋转)
- 轨迹包含多次自我修正,但这些修正并未引入新信息

- 这种模式导致冗长的推理痕迹,其中许多 token 仅与进展 weakly 相关
- 从优化的角度来看,这样的轨迹将奖励信号分散到大量低影响的 token 上,减少了对决定性推理步骤的有效学习压力
- 此外,尽管最终绕回正确的方向,但模型未能以所需的 boxed 格式呈现清晰的最终答案,使解决方案没有结论
Implications for optimization dynamics
- 这些定性差异与第 4.3.2 节讨论的机制一致
- 通过降低不必要长轨迹的优势,\(\text{GR}^3\) 隐式地偏好具有更高 Per Token 信息密度的推理路径
- 这鼓励策略保留基本的逻辑结构,同时避免非鲁棒的推理模式,例如重复或自我怀疑的循环
- 结论:奖励信号更加集中在对应于有意义的推理转换的 token 上,而不是被稀释到冗长但贡献低的片段中