注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
前置评价:
- 论文是字节 Seed 团队的大作,是这个领域的惊喜,非常值得一读
UI-TARS 的关键创新总结:
- (1)增强感知:利用大规模的 ** GUI 屏幕截图**数据集,实现对 UI 元素的上下文感知理解和精确描述;
- (2)统一动作建模,将动作标准化到跨平台的统一空间,并通过大规模动作轨迹实现精确的定位和交互;
- (3)System 2 推理,将审慎推理(deliberate reasoning)融入多步决策过程,涉及任务分解、反思性思考、里程碑识别等多种推理模式;
- (4)基于反思性在线轨迹的迭代训练,通过在数百台虚拟机上自动收集、筛选和反思性优化新的交互轨迹,解决数据瓶颈问题
论文介绍了 UI-TARS,这是一种原生图形用户界面(Graphical User Interface, GUI )智能体模型,它仅将屏幕截图作为输入,并执行类似人类的交互操作(例如键盘和鼠标操作)
与目前流行的依赖大量封装的商业模型(如 GPT-4o)以及专家精心设计的提示和工作流程的智能体框架不同,UI-TARS 是一个端到端的模型 ,性能优于这些复杂的框架
实验证明了 UI-TARS 的卓越性能:
- UI-TARS 在十多个评估感知、定位和 GUI 任务执行的 GUI 智能体基准测试中取得了最优成绩(见下文)
- 在 OSWorld 基准测试中,UI-TARS 在 50 步内得分为 24.6,15 步内得分为 22.7,分别超过 Claude 的 22.0 和 14.9
- 在 AndroidWorld 基准测试中,UI-TARS 得分为 46.6,超过 GPT-4o 的 34.5
通过迭代训练和反思调整,UI-TARS 不断从错误中学习,并在极少的人工干预下适应意外情况
论文还分析了 GUI 智能体的发展路径,为该领域的进一步发展提供指导

Introduction and Discussion
- 自主智能体 (2024b; 2023; 2024) 被期望能够在极少的人工监督下运行,感知环境、做出决策并执行动作以实现特定目标
- 在该领域的众多挑战中,让智能体与图形用户界面(GUI)实现无缝交互已成为一个关键的前沿课题 (2024; 2024a; 2024; 2024e; 2024)
- GUI 智能体旨在数字环境中执行任务,这些环境严重依赖按钮、文本框和图像等图形元素
- 通过利用先进的感知和推理能力,这些智能体有潜力彻底改变任务自动化方式、提高可访问性,并简化各种应用程序的工作流程
- GUI 智能体的发展历来依赖于结合文本表示(例如 HTML 结构和可访问性树)的混合方法 (2018; 2023; 2023)
- 虽然这些方法推动了显著的进展,但它们存在一些局限性,如特定平台的不一致性、冗长性和有限的可扩展性 (2024)
- 基于文本的方法通常需要系统级权限来访问底层系统信息,如 HTML 代码,这进一步限制了它们在不同环境中的适用性和通用性
- 另一个关键问题是:许多现有的 GUI 系统遵循智能体框架范式 (2023; 2024a; 2024a; 2024b; 2024; 2024),其中关键功能被模块化到多个组件中
- 这些组件通常依赖于专门的视觉语言模型(Vision-Language Model, VLM),如GPT-4o (2024) 进行理解和推理 (2024b) ,而定位 (2024b) 或记忆 (2023) 模块则通过额外的工具或脚本来实现
- 尽管这种模块化架构有助于特定领域任务的快速开发,但它依赖于手工制作的方法,这些方法依赖于专家知识、模块化组件和特定任务的优化,与端到端模型相比,可扩展性和适应性较差
- 这使得该框架在面对不熟悉的任务或动态变化的环境时容易失败 (2024)
- 这些挑战促使向原生 GUI 智能体模型(native GUI agent model)发生了两个关键转变:
- (1)从依赖文本(textual-dependent)的 GUI 智能体转变为基于纯视觉(pure-vision-based)的 GUI 智能体 (2023; 2024)
- “纯视觉(Pure-vision)” 意味着模型仅依赖界面的屏幕截图作为输入,而不是文本描述(例如 HTML)
- 这绕过了文本表示的复杂性和特定平台的限制,更符合人类的认知过程
- (2)从模块化智能体框架演变为端到端的智能体模型 (2024b; 2024; 2024b; 2024a; Anthropic, 2024b)
- 端到端设计将传统的模块化组件统一到单个架构中,实现了模块之间的信息流畅传递
- 从理念上讲:
- 智能体框架是设计驱动的,需要大量的手动工程和预定义的工作流程来维持稳定性并防止意外情况;
- 智能体模型本质上是数据驱动的,能够通过大规模数据和迭代反馈进行学习和适应 (2024)
- (1)从依赖文本(textual-dependent)的 GUI 智能体转变为基于纯视觉(pure-vision-based)的 GUI 智能体 (2023; 2024)
- 尽管原生 GUI 智能体模型在概念上具有优势,但在实际应用中往往存在不足,导致其在现实世界中的影响力落后于预期。这些限制主要源于两个方面:
- (1) GUI 领域本身带来了独特的挑战,增加了开发强大智能体的难度
- (1.a)在感知方面,智能体不仅要识别,还要有效地解释不断演变的用户界面中高信息密度的内容
- (1.b)推理和规划机制同样重要,以便有效地浏览、操作这些界面并做出响应
- (1.c)这些机制还必须利用记忆,考虑过去的交互和经验来做出明智的决策
- (1.d)除了高层次的决策,智能体还必须执行精确的低层次动作,例如输出点击或拖动的精确屏幕坐标,并在适当的字段中输入文本
- (2)从智能体框架向智能体模型的转变引入了一个根本性的数据瓶颈
- 模块化框架传统上依赖为单个组件定制的单独数据集:这些数据集相对容易整理,因为它们处理的是孤立的功能
- 训练一个端到端的智能体模型需要在统一的工作流程中整合所有组件的数据,捕捉感知、推理、记忆和动作之间的无缝交互
- 这类数据包含了人类专家丰富的工作流程知识,但在历史上很少被记录下来
- 这种全面、高质量数据的缺乏限制了原生智能体在各种现实场景中的泛化能力,阻碍了它们的可扩展性和稳健性
- (1) GUI 领域本身带来了独特的挑战,增加了开发强大智能体的难度
- 为了解决这些挑战,论文致力于推进原生 GUI 智能体模型的发展
- 论文首先回顾 GUI 智能体的发展路径(章节2)
- 通过根据人工干预程度和泛化能力将 GUI 智能体的发展划分为关键阶段,论文进行了全面的文献综述
- 从传统的基于规则的智能体开始,论文重点介绍了从僵化的、基于框架的系统到能够无缝集成感知、推理、记忆和动作的自适应原生模型的演变
- 论文还展望了具有主动和终身学习能力的 GUI 智能体的未来潜力,这种智能体能够在最大限度减少人工干预的同时最大化泛化能力
- 为了加深理解,论文详细分析了原生智能体模型的核心能力,包括:
- (1)感知,实现对环境的实时理解以提高态势感知能力;
- (2)动作,要求原生智能体模型在预定义空间中准确预测和定位动作;
- (3)推理,模仿人类思维过程,包括 System 1 和 System 2 思维;
- (4)记忆,存储特定任务信息、先前经验和背景知识
- 论文还总结了 GUI 智能体的主要评估指标和基准测试
- 论文首先回顾 GUI 智能体的发展路径(章节2)
- 基于这些分析,论文提出了一种原生 GUI 智能体模型 UI-TARS,图1展示了一个示例案例
- UI-TARS 有以下核心贡献:
- 增强 GUI 屏幕截图感知(Enhanced Perception for GUI Screenshots,章节4.2) :
- GUI 环境信息密度高、布局复杂且风格多样,需要强大的感知能力
- 论文使用专门的解析工具收集屏幕截图,构建了一个大规模数据集,以提取网站、应用程序和操作系统中的元素类型、边界框和文本内容等元数据
- 以上数据集针对以下任务:
- (1)元素描述,提供对 GUI 组件的细粒度、结构化描述;
- (2)密集标题,旨在通过描述整个 GUI 布局(包括空间关系、层次结构和元素之间的交互)来实现对界面的整体理解;
- (3)状态转换标题,捕捉屏幕上的细微视觉变化;
- (4)问答,旨在增强智能体的视觉推理能力;
- (5)标记集提示,使用视觉标记将 GUI 元素与特定的空间和功能上下文相关联
- 这些精心设计的任务共同使 UI-TARS 能够以极高的精度识别和理解 GUI 元素,为进一步的推理和动作提供了坚实的基础
- 多步执行的统一动作建模(Unified Action Modeling for Multi-step Execution,章节4.3) :
- 论文设计了一个统一的动作空间,以标准化跨平台语义等效的动作
- 为了改进多步执行,论文创建了一个大规模的动作轨迹数据集,结合了论文标注的(annotated)轨迹和标准化的开源数据
- 通过整理将元素描述与其空间坐标配对的大量数据集,提高了定位能力,即准确找到特定 GUI 元素并与之交互的能力
- 这些数据使 UI-TARS 能够实现精确可靠的交互
- 审慎决策的 System 2 推理(System 2 Reasoning for Deliberate Decision-making,章节4.4) :
- 在动态环境中实现稳健的性能需要先进的推理能力
- 为了丰富推理能力,论文爬取了 6M 个 GUI 教程 ,并进行了精心筛选和优化,为逻辑决策提供 GUI 知识
- 在此基础上,论文通过将任务分解、长期一致性、里程碑识别、试错和反思等多种推理模式注入模型,增强了对所有收集到的动作轨迹的推理能力
- UI-TARS 通过在每次动作前生成明确的 “思考”,将感知和动作与审慎决策联系起来,整合了这些能力
- 从先前经验中学习的迭代优化(Iterative Refinement by Learning from Prior Experience,章节4.5) :
- GUI 智能体开发中的一个重大挑战在于缺乏用于训练的大规模、高质量动作轨迹
- 为了克服这个数据瓶颈,UI-TARS 采用了一种迭代改进框架,动态收集和优化新的交互轨迹
- 利用数百台虚拟机,UI-TARS 根据构建的指令探索各种现实世界任务,并生成大量轨迹
- 通过基于规则的启发式方法、VLM 评分和人工审核等严格的多阶段筛选,确保轨迹质量
- 然后将这些优化后的轨迹反馈到模型中,使智能体在连续的训练周期中不断迭代提升性能
- 这个在线自训练过程的另一个核心组件是反思调整,即智能体通过分析自己的次优动作来识别和纠正错误。论文为这个过程标注(annotate)了两种类型的数据:
- (1)错误纠正,标注者指出智能体生成的轨迹中的错误并标记纠正动作;
- (2)反思后处理,标注者模拟恢复步骤,展示智能体在出错后应如何重新调整任务进度
- 这两种类型的数据创建了配对样本,用于使用直接偏好优化(Direct Preference Optimization, DPO) (2023) 训练模型
- 这种策略确保智能体不仅学会避免错误,还能在错误发生时动态适应
- 这些策略共同使 UI-TARS 能够在极少的人工监督下实现稳健、可扩展的学习
- 增强 GUI 屏幕截图感知(Enhanced Perception for GUI Screenshots,章节4.2) :
- 论文在大约 50B 个标记上持续训练 Qwen-2-VL 7B 和 72B (2024c) ,以开发 UI-TARS-7B 和 UI-TARS-72B
- 通过广泛的实验,论文得出以下结论:
- Overall Performance :
- UI-TARS 在十多个 GUI 智能体基准测试中展示了最优性能,涵盖了对感知、定位和智能体任务执行的评估
- 这些结果验证了论文方法的有效性,在推理密集型和动态场景中显著优于 GPT-4o 和 Claude Computer Use (Anthropic, 2024b) 等竞争基线
- 感知(Perception) :
- UI-TARS在 GUI 感知方面表现出色,能够有效处理高信息密度和复杂布局。实验证实了它提取精确元数据、描述 GUI 元素以及生成详细的、具有上下文感知的标题的能力
- 例如,UI-TARS-72B 在 VisualWebBench (2024c) 中得分 82.8,高于 GPT-4o 的 78.5
- 定位(Grounding) :
- UI-TARS 通过准确地将 GUI 元素与其空间坐标相关联,在移动、桌面和网络环境中实现了高精度定位
- 例如,它在最近发布的具有挑战性的基准测试 ScreenSpot Pro (2025) 中获得了 38.1 分(最优成绩)
- 智能体能力(Agent Capabilities) :
- 广泛的评估突出了 UI-TARS 卓越的智能体能力
- 实验表明,它在推理密集型基准测试中表现出色,72B 版本在多步和动态任务中表现尤为突出
- 值得注意的是,UI-TARS 在 OSWorld (2024) 和 AndroidWorld (2024a) 等具有挑战性的基准测试中取得了优异成绩
- 在 OSWorld 中,UI-TARS-72B 在 50步 内得分为 24.6,15步 内得分为 22.7,分别超过 Claude 的 22.0 和 14.9
- 在 AndroidWorld 中,它的得分达到 46.6,超过 GPT-4o 的 34.5,进一步强调了它处理高复杂性现实场景的能力
- Overall Performance :
Evolution Path of GUI Agents
- 在工作流自动化方面, GUI 智能体的意义尤为重大,它们有助于简化重复性任务、减少人力投入并提高生产力
- GUI 智能体的核心设计目标是促进人机交互,简化任务执行过程
- 其发展历程体现了从僵化的、人为定义的启发式方法到日益自主的系统的演进,这些系统能够适应环境、自主学习,甚至独立识别任务
- 在此背景下,GUI 智能体的角色已从简单的自动化工具转变为成熟的、自我改进的智能体,它们与人类工作流的融合程度不断加深,不仅是工具,更成为任务执行过程中的协作伙伴
- 多年来,智能体已从基本的基于规则的自动化系统发展为先进、高度自动化且灵活的系统,其行为越来越接近人类,执行任务时只需极少的人工干预
- 如图2所示,GUI 智能体的发展可分为几个关键阶段,每个阶段都代表着在自主性、灵活性和泛化能力方面的飞跃
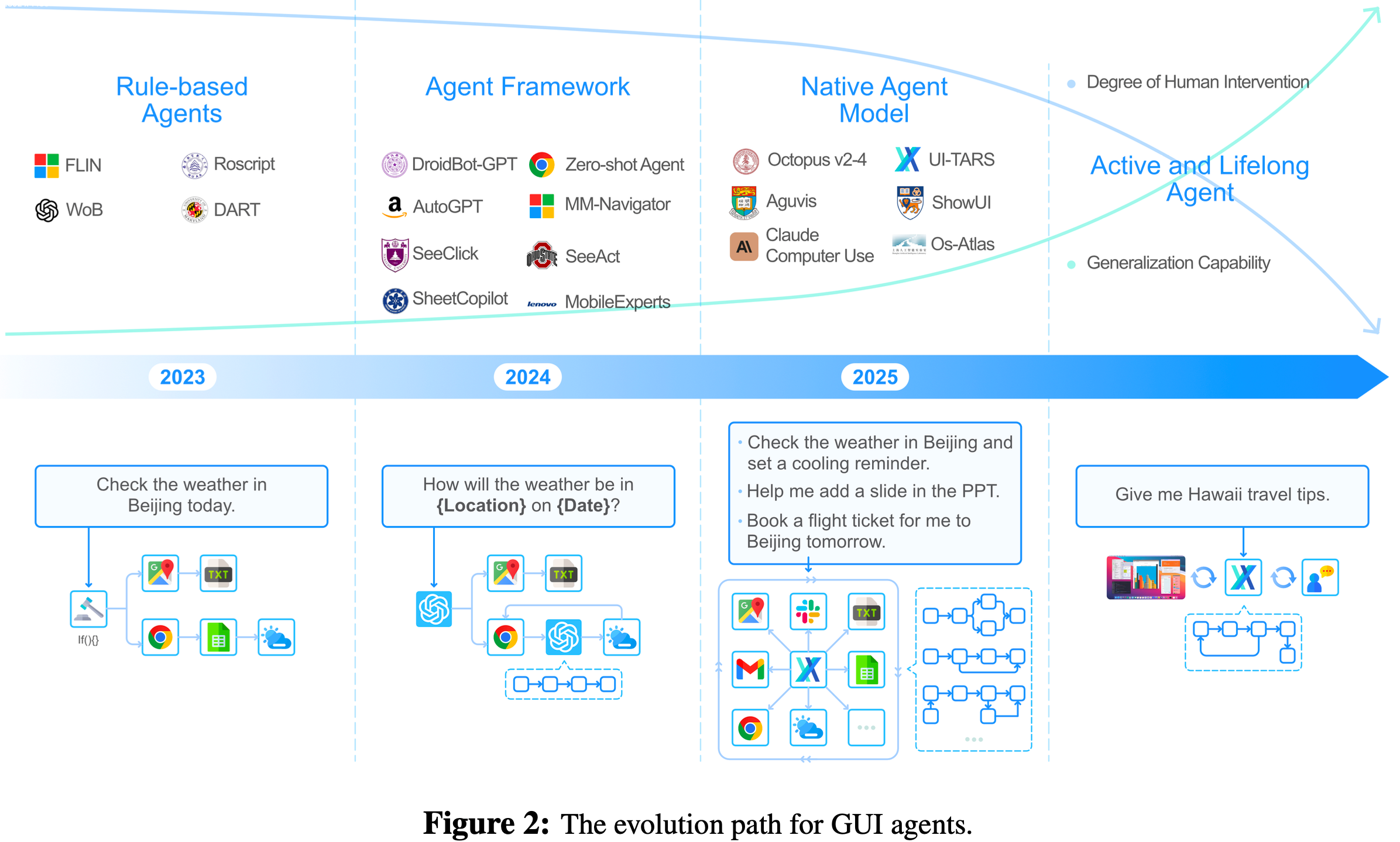
- 每个阶段的特点体现在工作流设计和学习过程中所需的人工干预程度上
Rule-based Agents
Stage 1: Rule-based Agents
- 在初始阶段,像机器人流程自动化(Robotic Process Automation, RPA)系统这样的智能体 (2022; 2020) 旨在高度结构化的环境中复制人类动作,通常与 GUI 和企业软件系统进行交互
- 这些智能体通常通过将用户指令与预定义规则匹配并调用相应的 AP I来处理指令
- 尽管这类系统在处理定义明确的重复性任务时很有效,但它们受限于对人为定义的启发式方法和明确指令的依赖,难以处理新颖和复杂的场景
- 在这个阶段,智能体无法从环境或以往经验中学习,工作流的任何变更都需要人工干预
- 此外,这些智能体需要直接访问 API 或底层系统权限,如 DART (2003)、WoB (2017)、Roscript (2020) 和 FLIN (2021) 等系统所展示的那样
- 这使得它们不适用于那些限制或不提供此类访问权限的场景
- 这种固有的僵化限制了它们在不同环境中的扩展应用
- 基于规则的智能体的局限性凸显了向基于 GUI 的智能体转变的重要性,这种智能体依赖视觉信息并直接对 GUI 进行操作,而无需获取系统的低级访问权限
- 通过与界面进行视觉交互,GUI 智能体获得了更大的灵活性和适应性,显著扩展了它们能够完成的任务范围,不再受预定义规则或明确系统访问权限的限制
- 这种范式转变为智能体自主与陌生或新开发的界面进行交互开辟了道路
From Modular Agent Framework to Native Agent Model
- 近年来,利用大型模型(Large Language Model, LLM)能力的智能体框架迅速流行起来
- 这种流行源于基础模型能够深度理解多种数据类型,并通过多步推理生成相关输出
- 与基于规则的智能体需要为每个特定任务手工设计规则不同,基础模型可以在不同环境中进行泛化,并通过与环境的多次交互有效处理任务
- 这消除了人类为每个新场景费力定义规则的需求,显著简化了智能体的开发和部署
Stage 2: Agent Framework
- 具体而言,这些智能体系统主要利用先进基础模型(如 GPT-4 (OpenAI, 2023b) 和 GPT-4o (2024))的理解和推理能力来增强任务执行的灵活性,从而成为更灵活的、基于框架的智能体
- 早期研究主要集中在文本界面内调用特定 API 或执行代码片段等任务上 (2023; 2023a, 2023; 2021)
- 这些智能体标志着从纯基于规则的系统向更自动化、更灵活的交互方式的重大进步
- AutoGPT (2023a) 和 LangChain 等自主框架允许智能体集成多个外部工具、API 和服务,实现更动态、更具适应性的工作流
- 增强基于基础模型的智能体框架的性能通常涉及设计特定任务的工作流并优化每个组件的提示词
- 例如,一些方法通过为这些框架增加专门的模块(如短期或长期记忆)来提供特定任务的知识或存储操作经验以实现自我改进
- Cradle (2024) 通过存储和利用任务执行经验来增强基础智能体的多任务处理能力
- Song等人 (2024) 提出了一个基于API的网络智能体框架,该框架利用特定任务的背景知识来执行复杂的网络操作
- 智能体工作流记忆(Agent Workflow Memory, AWM)模块 (2024g) 通过选择性地提供相关工作流来指导智能体的后续动作,进一步优化了记忆管理
- 另一种提高任务成功率的常见策略是融入基于反思的多步推理,以改进动作规划和执行
- 广为人知的 ReAct 框架 (2023) 将推理与动作结果相结合,实现更动态、更具适应性的规划
- 对于多模态任务:
- MMNavigator (2023) 利用总结的上下文动作和标记来生成准确的、可执行的动作
- SeeAct (2024b) 则采用不同的方法,明确指示 GPT-4V 模仿人类浏览行为,同时考虑任务、网页内容和先前动作
- 此外,多智能体协作已成为提高任务完成率的有效技术。例如:
- MobileExperts (2024c) 通过整合工具构建和促进多个智能体之间的协作,解决了移动环境的独特挑战
- 总之,当前智能体框架的进步在很大程度上依赖于通过提示词工程优化计划和动作生成,其核心是底层基础模型的能力,最终实现任务完成度的提升
- 例如,一些方法通过为这些框架增加专门的模块(如短期或长期记忆)来提供特定任务的知识或存储操作经验以实现自我改进
- 智能体框架的主要局限性(Key Limitations of Agent Frameworks) :尽管与基于规则的系统相比,智能体框架具有更强的适应性,但它们仍然依赖人为定义的工作流来规划动作;“智能体工作流知识(agentic workflow knowledge)” (2024g) 通过自定义提示词、外部脚本或工具使用启发式方法进行手动编码;这种知识的外部化带来了几个缺点:
- 脆弱性和维护开销(Fragility and Maintenance Overhead) :每当任务、界面或使用场景发生变化时,开发人员必须重新设计或扩展工作流的手动规则或提示词——这是一个容易出错且耗时费力的过程
- 脱节的学习范式(Disjoint Learning Paradigms) :基于框架的方法很少整合新的经验数据来更新底层 LLM/VLM 参数
- 相反,它们依赖离线提示词工程或工作流设计
- 当任务偏离原始领域时,这些框架往往会失效 ,限制了适应性
- 模块不兼容性(Module Incompatibility) :复杂任务需要多个模块(如视觉解析、记忆存储、长期规划),这些模块必须通过提示词或桥接代码进行协调
- 任何模块中的不一致或错误都可能破坏整个流程,而诊断这些问题通常需要领域专家进行流程调试
- 因此,尽管智能体框架能快速演示,并且在狭窄范围内具有灵活性,但在任务和界面不断演变的现实场景中部署时,它们最终仍然很脆弱
- 这种对预编程工作流的依赖(由人类专业知识驱动)使得框架本质上不具备可扩展性。它们依赖开发人员的远见来预测所有未来的变化,这限制了它们处理不可预见的变化或自主学习的能力。框架是设计驱动的,这意味着如果没有持续的人类参与,它们无法跨任务进行学习和泛化
第三阶段:原生智能体模型
- 相比之下,自主智能体开发的未来在于创建原生智能体模型 ,其中工作流知识通过定向学习直接嵌入智能体的模型中
- 在这种范式中,任务以端到端的方式进行学习和执行,将感知、推理、记忆和动作统一在一个不断进化的单一模型中
- 这种方法本质上是数据驱动的,使智能体能够适应新任务、新界面或新用户需求,而无需依赖手工设计的提示词或预定义规则
- 原生智能体具有几个显著优势,有助于提高其可扩展性和适应性:
- 整体学习和适应(Holistic Learning and Adaptation) :由于智能体的策略是端到端学习的,它可以在内部参数中统一来自感知、推理、记忆和动作的知识
- 当新数据或用户演示可用时,整个系统(而不仅仅是单个模块或提示词)会更新其知识
- 这使模型能够更无缝地适应不断变化的任务、界面或用户需求
- 减少人工工程 :原生模型从大规模演示或在线经验中学习与任务相关的工作流,而不是仔细编写如何在每个节点调用 LLM/VLM 的脚本
- “硬编码工作流”的负担被数据驱动的学习所取代
- 这显著减少了环境演变时领域专家手工设计启发式方法的需求
- 通过统一参数实现强泛化 :尽管手动提示词工程可以使模型适应用户定义的新工具,但模型本身无法进化
- 在一个参数化策略和统一的数据构建与训练流程下 ,不同环境中的知识(如某些应用程序功能、导航策略或 UI 模式)可以在任务之间转移,使其具备强大的泛化能力
- 持续自我改进 :原生智能体模型自然适用于在线或终身学习范式
- 通过在现实世界的 GUI 环境中部署智能体并收集新的交互数据,可以对模型进行微调或进一步训练以应对新挑战
- 整体学习和适应(Holistic Learning and Adaptation) :由于智能体的策略是端到端学习的,它可以在内部参数中统一来自感知、推理、记忆和动作的知识
- 这种数据驱动的、以学习为导向的方法与设计驱动的、静态的智能体框架形成对比
- 目前, GUI 智能体的发展逐渐达到了这个阶段,代表性作品包括 Claude Computer-Use (Anthropic, 2024b)、Aguvis (2024)、ShowUI (2024b)、OS-Atlas (2024b)、Octopus v2-4 (2024) 等
- 这些模型主要利用现有的世界数据,专门为 GUI 交互领域定制大型 VLM
Active and Lifelong Agent (Prospect)
Stage 4:Active and Lifelong Agent
- 尽管在适应性方面有所改进,原生智能体仍然严重依赖人类专家进行数据标注和训练指导
- 这种依赖性本质上限制了它们的能力,使它们的性能取决于人类提供的数据和知识的质量与广度
- 向主动和终身学习 (2022; 2024) 的转变代表了 GUI 智能体发展的关键下一步
- 在这种范式中,智能体主动与环境交互,提出任务、执行任务并评估结果
- 这些智能体可以根据动作的成功与否自主分配自我奖励,强化积极行为,并通过持续的反馈循环逐步完善自身能力
- 这种自主探索和学习过程使智能体能够发现新知识、改进任务执行,并增强问题解决策略,而无需大量依赖手动标注或明确的外部指导
- 这些智能体像机器人领域的持续学习 (2024; 2024) 一样,迭代地发展和修改自己的技能,它们可以从成功和失败中学习,逐步提高在越来越广泛的任务和场景中的泛化能力
- 原生智能体模型与主动终身学习智能体之间的关键区别在于学习过程的自主性:
- 原生智能体仍然依赖人类,而主动智能体通过识别自身知识差距并通过自主发起的探索来填补这些差距,从而驱动自己的学习
- 在这项工作中,论文专注于构建一个可扩展的数据驱动原生智能体模型,为这个主动和终身学习智能体阶段奠定基础
- 论文首先探索这种框架所需的核心能力(章节3),然后介绍 UI-TARS,论文对这种方法的具体实现(章节4)
Core Capabilities of Native Agent Model
- 原生智能体模型将先前智能体框架中的模块化组件内化为几项核心能力,从而向端到端结构转变
- 为了更深入地理解原生智能体模型,本节将详细分析其核心能力,并回顾当前的评估指标和基准测试
Core Capabilities
- 如图3所示,论文的分析围绕四个主要方面展开:感知(Perception)、动作(Action)、推理(Reasoning,System 1 和 System 2 thinking)以及记忆(Memory)
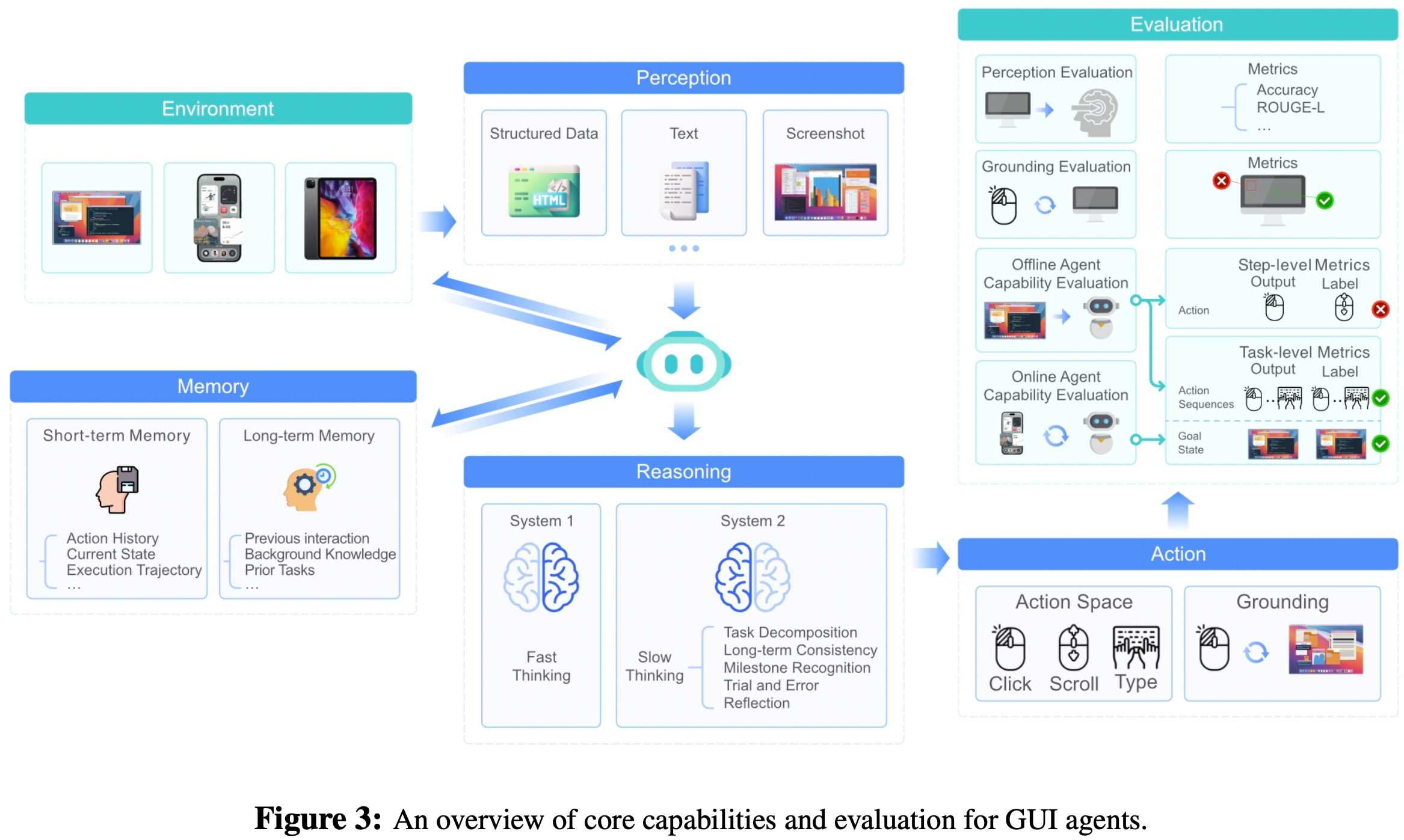
Perception
- 高效的 GUI 智能体的一个基本方面在于其实时精确感知和解释图形用户界面的能力
- 这不仅包括理解静态截图,还包括随着界面演变动态适应变化
- 论文根据现有研究使用的输入特征对其进行回顾:
- 结构化文本(Structured Text) :
- 早期由 LLM 驱动的 GUI 智能体版本 (2023a; 2023; 2024a) 受限于 LLM 只能处理文本输入的局限性
- 因此,这些智能体依赖于将 GUI 页面转换为结构化文本表示,如 HTML、可访问性树或文档对象模型(Document Object Model, DOM)
- 对于网页,一些智能体使用 HTML 数据作为输入,或者利用 DOM 来分析页面布局(DOM 提供了一种层次化组织元素的树状结构)
- 为了减少输入噪声,Agent-E (2024) 采用了 DOM 蒸馏技术,以实现更有效的截图表示
- Tao等人 (2023) 引入了 WebWISE,它基于从过滤后的 DOM 元素中观察到的信息迭代生成小程序,并按顺序执行任务
- 视觉截图(Visual Screenshot) :
- 随着计算机视觉和视觉语言模型(Vision-Language Model, VLM)的发展,智能体现在能够利用屏幕上的视觉数据来解释其屏幕环境
- 很大一部分研究依赖于标记集(Set-of-Mark, SoM)提示技术 (2023b) 来提高视觉定位能力
- 为了增强视觉理解,这些方法经常将光学字符识别(Optical Character Recognition, OCR)与 GUI 元素检测模型(包括ICONNet (2022) 和DINO (2025))结合使用
- 这些算法用于通过边界框识别和勾勒交互元素,随后将这些边界框映射到特定的图像区域,丰富智能体的上下文理解
- 一些研究还通过添加截图中这些交互元素的描述来提高元素的语义定位能力和理解能力
- 例如,SeeAct (2024a) 通过将视觉元素与其在HTML网页中所代表的内容相关联,增强了对截图内容的细粒度理解
- 全面界面建模(Comprehensive Interface Modeling) :
- 最近,一些研究采用结构化文本、视觉快照和元素的语义轮廓来实现对外部感知的全面理解
- Gou 等人 (2024a) 合成了大规模的 GUI 元素数据,并训练了一个视觉定位模型 UGround,以获取不同平台上 GUI 页面中元素的相关引用
- OSCAR (Wang和Liu, 2024) 利用 Windows API 生成的 A11y 树来表示 GUI 组件,并融入描述性标签以促进语义定位
- DUALVCR (2024) 捕捉截图的视觉特征和相关 HTML 元素的描述,以获得对视觉截图的稳健表示
- 结构化文本(Structured Text) :
- 另一个重要点是实时交互能力
- GUI 本质上是动态的,元素经常会响应用户操作或系统进程而发生变化
- GUI 智能体必须持续监控这些变化,以保持对界面状态的最新理解
- 这种实时感知对于确保智能体能够及时、准确地响应不断变化的情况至关重要
- 例如,如果出现 loading spinner,智能体应该将其识别为一个待处理进程的指示,并相应地调整其动作
- 这里的 loading spinner 指的是加载旋转图标,表示正在加载
- 同样,智能体必须检测并处理界面无响应或行为异常的情况
- 通过有效结合上述方面,强大的感知系统确保 GUI 智能体能够保持态势感知,并对用户界面的不断变化的状态做出适当响应,使其动作与用户目标和应用程序要求保持一致
- 然而,隐私问题以及 DOM 引入的额外感知噪声,使得将纯文本描述和混合文本-视觉感知扩展到任何 GUI 环境都面临挑战
- 因此,与人类与周围环境的交互类似,原生智能体模型应该通过视觉感知直接理解外部环境 ,并将其动作准确地定位到原始截图上
- 通过这种方式,原生智能体模型可以泛化各种任务,并提高每一步动作的准确性
Action
- 有效的动作机制必须具有通用性、精确性,并能适应各种 GUI 环境。关键方面包括:
- 统一多样的动作空间(Unified and Diverse Action Space) :
- GUI 智能体 (2023; 2024) 在多个平台上运行,包括移动设备、桌面应用程序和网页界面,每个平台都有其独特的交互范式
- 建立统一的动作空间将特定平台的动作抽象为一组通用操作,如点击、输入、滚动和拖动(click, type, scroll, and drag)
- 此外,整合来自语言智能体的动作(如 API 调用 (2024b; 2023a)、代码解释 (2024a) 和命令行界面(Command-Line Interface, CLI)操作 (2024))增强了智能体的多功能性
- 动作可以分为原子动作(执行单个操作)和组合动作(将多个原子动作排序以简化任务执行)
- 平衡原子动作和组合动作可优化效率并减少认知负荷,使智能体能够无缝处理简单交互和多个步骤的协调执行
- 坐标定位挑战(Challenges in Grounding Coordinates) :
- 准确确定点击、拖动和滑动等动作的坐标具有挑战性,这是由于 GUI 布局的可变性 (2024; 2020)、不同设备的宽高比差异以及内容的动态变化
- 不同设备的宽高比可能会改变界面元素的空间排列,使精确定位变得复杂
- 坐标定位需要先进的技术来准确解释来自截图或实时界面流的视觉线索
- 统一多样的动作空间(Unified and Diverse Action Space) :
- 由于不同操作空间中的动作具有相似性,智能体模型可以将来自各种 GUI 环境的动作标准化为统一的动作空间
- 将动作分解为原子操作降低了学习复杂性,促进原子动作在不同平台之间的更快适应和转移
Reasoning with System 1&2 Thinking
- 推理是一种复杂的能力,整合了多种认知功能,人类与 GUI 的交互依赖于两种不同类型的认知过程 (1970):System 1 和 System 2 思维
- System 1 指的是快速、自动和直觉性的思维 ,通常用于简单和常规任务,例如点击熟悉的按钮或无需有意识思考就将文件拖到文件夹中
- System 2 包括缓慢、审慎和分析性的思维 ,这对于解决复杂任务(如规划整体工作流或通过反思排查错误)至关重要
- 同样,自主 GUI 智能体必须具备模仿 System 1 和 System 2 思维的能力,才能在各种任务中有效发挥作用
- 通过学习识别何时应用快速的、基于启发式的响应,何时进行详细的、逐步的推理,这些智能体可以在动态环境中实现更高的效率、适应性和可靠性
- System 1 推理(System 1 Reasoning) :
- 代表智能体通过识别界面中的模式并将预先学到的知识应用于观察到的情况来执行快速、直觉性响应的能力
- 这种推理形式类似于人类与 GUI 的熟悉元素的交互
- 例如认识到在文本字段中按“Enter”键会提交表单,或者理解点击某个按钮会进入工作流的下一步
- 这些基于启发式的动作使智能体能够快速响应并在常规场景中保持操作效率,但对预定 mapping 的依赖限制了其决策范围(只能在即时的、反应性的行为上)
- 例如,大型动作模型等模型 (2024b; 2024a) 擅长通过利用环境观察生成快速响应,但它们通常缺乏更复杂的推理能力
- 在需要规划和执行多步骤操作的任务中,这种问题尤为明显,这些任务超出了 System 1 的反应性、单步推理范围
- 虽然 System 1 为快速高效的操作提供了基础,但它凸显了智能体需要向 System 2 推理中所见的更审慎和反思性的能力发展的必要性
- System 2 推理(System 2 Reasoning) :
- 代表审慎、结构化和分析性的思维,使智能体能够处理超出 System 1 反应性行为的复杂、多步骤任务
- 与基于启发式的推理不同, System 2 涉及明确生成中间思维过程,通常使用 CoT (2022) 或 ReAct (2023) 等技术,这些技术弥合了简单动作与复杂工作流之间的差距
- 这种推理范式由几个基本组件组成:
- 第一,任务分解(task decomposition) :
- 任务分解(task decomposition)侧重于通过将任务分解为更小的、可管理的子任务来制定实现总体目标的计划 (2023; 2023; 2024)
- 例如,填写多字段表单涉及一系列步骤,如输入姓名、地址和其他详细信息,所有这些都在结构良好的计划指导下进行
- 第二,长期一致性(long-term consistency) :
- 在整个任务完成过程中,长期一致性至关重要
- 通过始终参考初始目标,智能体模型可以有效避免在复杂的多阶段任务中可能出现的任何潜在偏差,从而确保从开始到结束的连贯性和连续性
- 第三,里程碑识别(milestone recognition) :
- 里程碑识别(milestone recognition)使智能体模型能够估计当前的进展状态、分析观察结果并确定后续目标
- 这确保多步骤工作流能够有效执行而不会迷失方向
- 第四,试错(trial and error) :
- 试错(trial and error)赋予智能体模型更多机会来假设、测试和评估潜在动作,从而提高决策的精确性,特别是在模糊和复杂的场景中(如无需直接交互即可验证搜索结果)
- 第五,反思(reflection) :
- 反思(reflection)使智能体模型能够评估过去的动作、识别错误并进行调整以改进未来的性能 (2023; Renze和Guven, 2024)
- 这个迭代过程提高了可靠性,并有助于防止重复出现错误
- 第一,任务分解(task decomposition) :
- UI-TARS 的开发着重于为模型配备强大的 System 2 推理能力,使其能够更精确、更灵活地处理复杂任务
- 通过整合高级规划机制,UI-TARS 擅长将总体目标分解为更小的、可管理的子任务
- 这种结构化方法使模型能够系统地处理需要跨多个步骤协调的复杂工作流
- UI-TARS 融入了长文本 CoT 推理过程,这有助于在执行特定动作之前进行详细的中间思考
- UI-TARS 采用了基于反思的训练过程
- 通过融入反思性思维,模型不断评估其过去的动作,识别潜在错误,并调整其行为以随着时间的推移提高性能
- 模型的迭代学习方法带来了显著的好处,提高了其可靠性,并使其能够应对动态环境和意外障碍
Memory
- 记忆主要用于存储智能体在制定决策时参考的支持性显性知识和历史经验
- 对于智能体框架,通常会引入额外的记忆模块来存储先前的交互和任务级知识,然后,智能体在决策过程中检索和更新这些记忆模块
- 记忆模块可以分为两类:
- 短期记忆(Short-term Memory) :
- 短期记忆(Short-term Memory)作为特定任务信息的临时存储库 ,捕捉智能体的即时上下文
- 这包括智能体的动作历史、当前状态详情以及任务的正在进行的执行轨迹,实现实时态势感知和适应性
- 通过对上下文截图进行语义处理,CoAT (2024d) 提取关键界面细节,从而增强对任务环境的理解
- CoCo-Agent (2024) 通过综合环境感知(Comprehensive Environment Perception, CEP)记录布局和动态状态
- 长期记忆(Long-term Memory) :
- 长期记忆(Long-term Memory)作为长期数据储备,捕捉并保护先前交互、任务和背景知识的记录
- 它保留诸如先前任务的执行路径等细节,提供支持未来任务推理和决策的综合知识库
- 通过整合包含用户偏好和任务操作经验的累积知识
- OS-copilot (2024a) 随着时间的推移改进其任务执行,以更好地符合用户需求并提高整体效率
- Cradle (2024) 专注于通过为基础智能体配备存储和利用任务执行经验的能力来增强其多任务处理能力
- Song等人 (2024) 引入了一个基于API的网络智能体框架,该框架利用特定任务的背景知识来执行复杂的网络操作
- 短期记忆(Short-term Memory) :
- 记忆反映了利用背景知识和输入上下文的能力。短期和长期记忆存储之间的协同作用显著提高了智能体决策过程的效率
- 与智能体框架不同,原生智能体模型将任务的长期操作经验编码在其内部参数中,将可观察的交互过程转换为隐式的、参数化的存储
- 可以采用上下文学习(In-Context Learning, ICL)或 CoT 推理等技术来激活这种内部记忆
Capability Evaluation
- 为了评估 GUI 智能体的有效性,人们精心设计了众多基准测试,重点关注感知、定位和智能体能力(perception, grounding, and agent capabilities)等各个方面的能力
- 具体而言:
- 感知评估反映对 GUI 知识的理解程度
- 定位评估验证智能体是否能够在不同的 GUI 布局中准确定位坐标
- 智能体能力主要可分为两类:
- 离线智能体能力评估 ,在预定义的静态环境中进行,主要关注评估 GUI 智能体执行的各个步骤;
- 在线智能体能力评估 ,在交互式动态环境中进行,评估智能体成功完成任务的整体能力
- 感知评估(Perception Evaluation) :感知评估评估智能体对用户界面(User Interface, UI)知识的理解及其对环境的感知能力
- VisualWebBench (2024c) 专注于智能体的网页理解能力
- WebSRC (2021) 和ScreenQA (2022) 通过问答(Question-Answering, QA)任务评估网页结构理解和移动屏幕内容理解
- GUI-World (2024a) 提供多种选择题、自由形式和对话形式的查询,以评估 GUI 理解能力,根据不同的问题形式,采用了一系列指标
- 例如,准确性用于选择题(Multiple-Choice Question, MCQ)任务作为关键指标
- 在标题生成或光学字符识别(OCR)任务中,采用 ROUGE-L 指标来评估性能
- 定位评估(Grounding Evaluation) :给定指令,定位评估侧重于精确找到 GUI 元素的能力
- ScreenSpot (2024) 评估多个平台上的单步 GUI 定位性能
- ScreenSpot v2 (2024b) 是重新标注的版本,解决了原始ScreenSpot中存在的标注错误
- ScreenSpot Pro (2025) 通过整合来自各种高分辨率专业桌面环境的现实世界任务,促进定位评估
- 定位评估的指标通常根据模型的预测位置是否准确位于目标元素的边界框内来确定
- 离线智能体能力评估(Offline Agent Capability Evaluation) :离线评估衡量 GUI 智能体在静态、预定义环境中的性能
- 每个环境通常包括输入指令和环境的当前状态(例如截图或先前动作的历史记录),要求智能体产生正确的输出或动作,这些环境在整个评估过程中保持一致
- 许多离线评估基准测试,包括 AITW (2023)、Mind2Web (2023)、MT-Mind2Web (2024)、AITZ (2024e)、AndroidControl (2024c) 和 GUI-Odyssey (2024a),为智能体提供任务描述、当前截图和先前动作历史,旨在使智能体能够准确预测下一步动作
- 这些基准测试通常采用步骤级指标,提供对其特定行为的细粒度监督。例如:
- 动作匹配分数(Action-Matching Score) (2023; 2024e; 2024c; 2024a) 仅在动作类型及其具体细节(如输入内容或滚动方向等参数)与真实情况一致时,才认为动作是正确的
- 一些基准测试 (2020a; 2022) 要求智能体根据提供的指令和截图生成一系列可自动执行的动作
- 这些基准测试主要使用任务级指标来评估性能,通过输出结果是否与预定义标签精确匹配(如完整和部分动作序列匹配准确性)来确定任务是否成功 (2020a; 2022; 2023)
- 在线智能体能力评估(Online Agent Capability Evaluation) :在线评估提供动态环境,每个环境都设计为模拟现实世界场景的交互式模拟
- 在这些环境中,GUI 智能体可以通过实时执行动作来修改环境状态
- 这些动态环境跨越多个平台:
- (1)网页:WebArena (2023) 和 MMInA (2024g) 提供逼真的网页环境
- (2)桌面:OSWorld (2024)、OfficeBench (2024f)、ASSIST GUI (2023) 和WindowsAgentArena (2024) 在真实的计算机桌面环境中运行
- (3)移动设备:AndroidWorld (2024a)、LlamaTouch (2024f) 和B-MOCA (2024) 建立在Android等移动操作系统上
- 为了评估在线评估中的性能,采用了任务级指标,提供对智能体有效性的全面衡量
- 具体而言,在在线智能体能力评估领域,这些任务级指标主要根据智能体是否成功达到目标状态来确定任务成功与否
- 这个验证过程检查预期结果是否实现,或者生成的输出是否与标签精确匹配 (2023; 2024; 2024f; 2023)
UI-TARS
- 在本节中,论文介绍 UI-TARS,这是一种原生图形用户界面(Graphical User Interface, GUI)智能体模型,其设计不依赖繁琐的手动规则或传统智能体框架中典型的级联模块
- UI-TARS 直接感知截图、应用推理过程并自主生成有效动作
- UI-TARS 可以从先前经验中学习,通过利用环境反馈迭代优化自身性能
Architecture Overview
- 下面,论文首先描述 UI-TARS 的整体架构(章节4.1),然后介绍如何增强其感知(章节4.2)和动作(章节4.3)能力
- 接着,论文重点阐述如何为 UI-TARS 注入 System 2 推理能力(章节4.4),以及如何通过经验学习实现迭代改进(章节4.5)
- 如图4所示,给定初始任务指令,UI-TARS迭代接收来自设备的观察结果并执行相应动作以完成任务
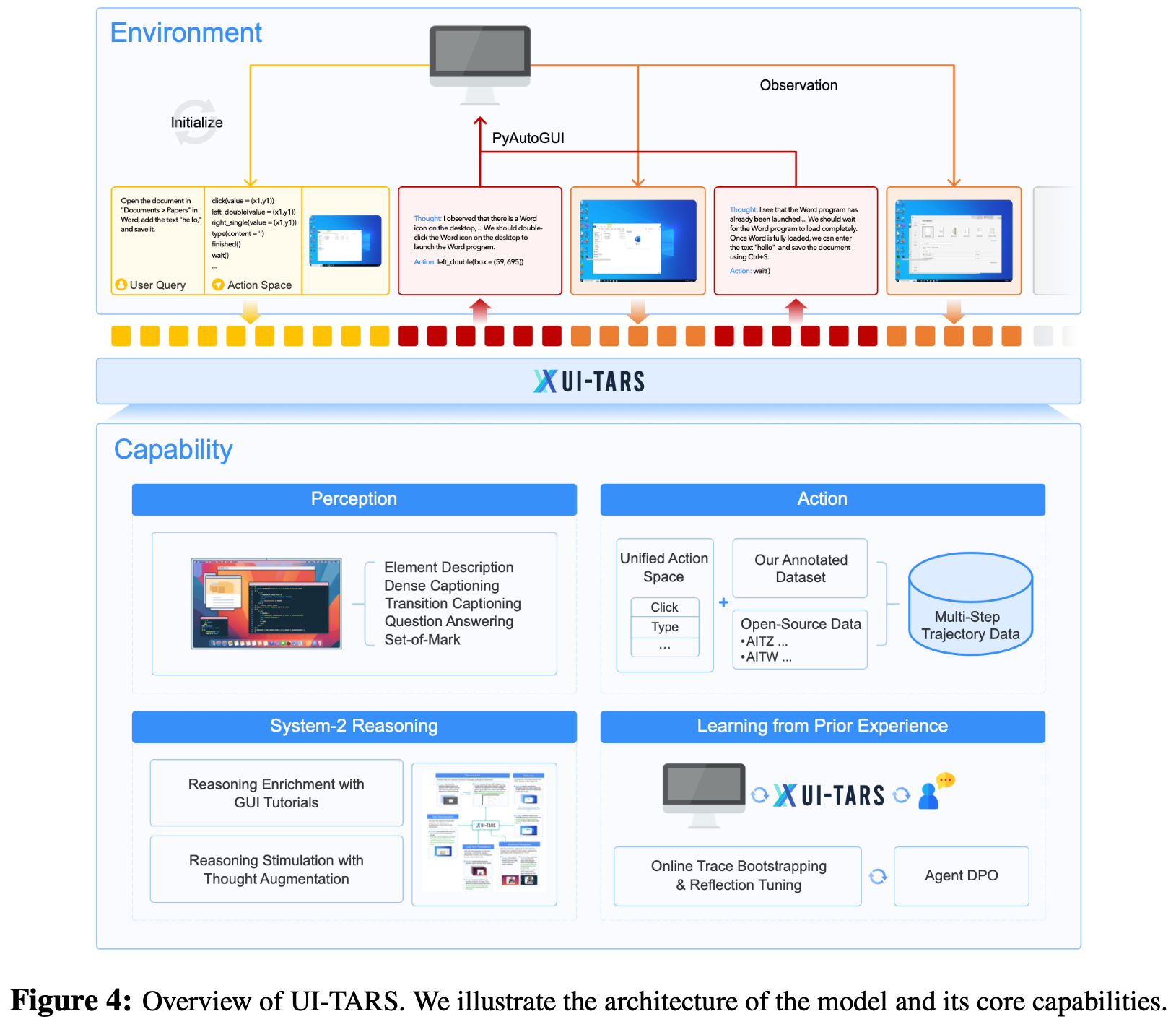
- 这一序列过程可以形式化表示为:
$$(instruction, (o_{1}, a_{1}), (o_{2}, a_{2}), \cdots, (o_{n}, a_{n}))$$- \(o_{i}\) 表示在时间步 \(i\) 的观察结果(设备截图)
- \(a_{i}\) 表示智能体执行的动作
- 在每个时间步
- UI-TARS 将任务指令、先前交互历史 \((o_{1}, a_{1}, \cdots, o_{i-1}, a_{i-1})\) 以及当前观察结果 \(o_{i}\) 作为输入
- 基于这些输入,模型从预定义的动作空间中输出动作 \(a_{i}\)
- 执行动作后,设备提供下一个观察结果,这些过程迭代进行
- 为了进一步增强智能体的推理能力并促进更审慎的决策,论文以“思考”\(t_{i}\) 的形式整合了一个推理组件,该组件在每个动作 \(a_{i}\) 之前生成
- 这些思考反映了“ System 2 ”思维的反思特性
- 它们作为关键的中间步骤,指导智能体在前进之前重新考虑先前的动作和观察结果,从而确保每个决策都经过深思熟虑
- 这种方法受到 ReAct 框架(2023)的启发,该框架引入了类似的反思机制,但形式更简单
- 相比之下,论文对“思考”的整合涉及更结构化、面向目标的思考过程
- 这些思考是更明确的推理过程,指导智能体做出更好的决策,尤其是在复杂或模糊的情况下
- 该过程现在可以形式化表示为:
$$(instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), \cdots, (o_{n}, t_{n}, a_{n}))$$ - 这些中间思考指导模型的决策,并实现与环境更细致、更具反思性的交互
- 为了优化内存使用并在通常受限的 Token 预算(例如 32k 序列长度)内保持效率,论文将输入限制为最后的 \(N\) 个观察结果
- 这一约束确保模型能够处理必要的上下文,而不会使其内存容量不堪重负
- 先前动作和思考的完整历史被保留为短期记忆
- UI-TARS 迭代预测思考 \(t_{n}\) 和动作 \(a_{n}\) 的输出,其条件是任务指令和先前的交互:
$$P(t_{n}, a_{n} | instruction, t_{1}, a_{1}, \cdots, (o_{n-i}, t_{n-i}, a_{n-i})_{i=1}^{N}, o_{n})$$
Enhancing GUI Perception
- 改进 GUI 感知面临几个独特挑战:
- (1)截图稀缺性 :虽然大规模的通用场景图像广泛可用,但特定于 GUI 的截图相对稀少
- (2)信息密度和精度要求 :GUI 图像本质上比通用场景图像具有更高的信息密度和结构性,通常包含数百个元素,这些元素以复杂的布局排列
- 模型不仅要识别单个元素,还要理解它们的空间关系和功能交互
- 此外,GUI 图像中的许多元素很小(例如,1920×1080 图像中的 10×10 像素图标),这使得准确感知和定位这些元素变得困难
- 与依赖单独的、模块化感知模型的传统框架不同,原生智能体通过直接处理来自 GUI 截图的原始输入来克服这些挑战
- 这种方法使它们能够通过利用大规模、统一的数据集更好地进行扩展,从而更有效地应对 GUI 感知的独特挑战
Screenshot Collection
- 为了解决数据稀缺问题并确保多样化覆盖,论文构建了一个大规模数据集,其中包含来自网站、应用程序和操作系统的截图和元数据
- 论文使用专门的解析工具,在渲染截图时自动提取丰富的元数据——例如每个元素的元素类型、深度、边界框和文本内容
- 论文的方法结合了自动爬取和人工辅助探索,以捕获广泛的内容
- 论文包括了主要界面以及通过重复交互访问的更深层次的嵌套页面
- 所有数据都以结构化格式(截图、元素框、元素元数据)记录,以全面覆盖各种界面设计
- 论文采用自下而上的数据构建方法,从单个元素开始,逐步发展到整体界面理解
- 通过在将 GUI 的小局部部分整合到更广泛的上下文中之前专注于它们,这种方法最大限度地减少了错误,同时平衡了识别组件的精度和解释复杂布局的能力
- 基于收集的截图数据,论文精心设计了五种核心任务数据(图5):
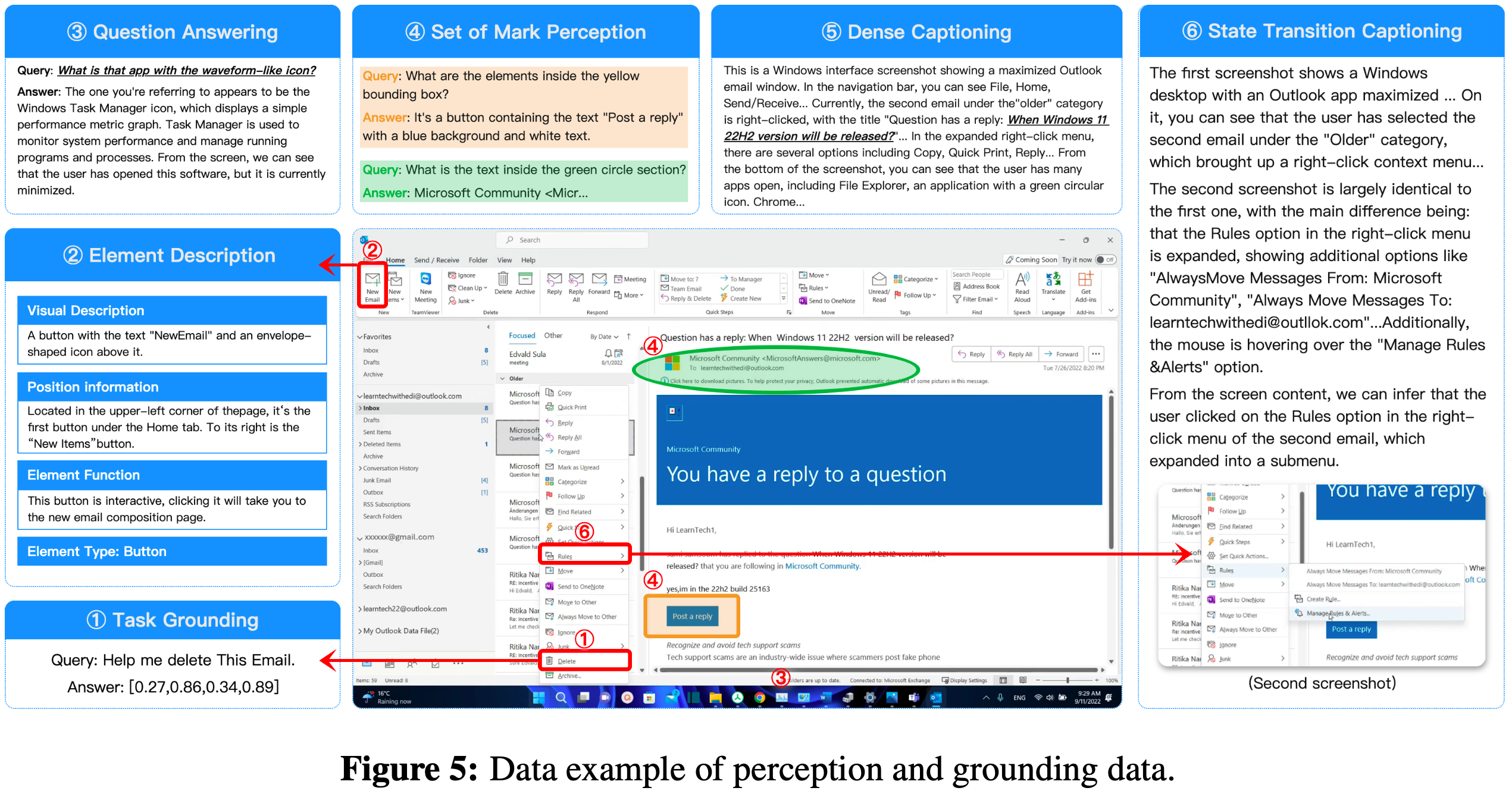
- 元素描述(Element Description)
- 为了增强对 GUI 中特定元素(特别是微小元素)的识别和理解,论文专注于为每个元素创建详细的结构化描述
- 这些描述基于使用解析工具提取的元数据,并由视觉语言模型(Vision-Language Model, VLM)进一步合成,涵盖四个方面:
- (1)元素类型(例如,窗口控制类型):论文根据视觉线索和系统信息对元素(例如按钮、文本字段、滚动条)进行分类
- (2)视觉描述,描述元素的外观,包括其形状、颜色、文本内容和样式,直接从图像中提取;
- (3)位置信息:论文描述每个元素相对于其他元素的空间位置;
- (4)元素功能,描述元素的预期功能和可能的交互方式
- 论文训练 UI-TARS 枚举截图中的所有可见元素,并生成它们的元素描述,条件是截图
- 密集标题(Dense Captioning)
- 论文训练 UI-TARS 理解整个界面,同时保持准确性并最大限度地减少幻觉
- 密集标题的目标是提供 GUI 截图的全面、详细描述,不仅捕获元素本身,还包括它们的空间关系和界面的整体布局
- 对于截图中记录的每个元素,论文首先获取它们的元素描述
- 对于通常缺乏详细元数据的嵌入图像,论文也生成它们的描述性标题
- 之后,论文使用VLM将所有图像和元素描述整合到一个连贯、高度详细的标题中,该标题保留了 GUI 布局的结构
- 在训练期间,只给 UI-TARS 提供图像,并要求其输出相应的密集标题
- 状态转换标题(State Transition Captioning)
- 虽然密集标题提供了 GUI 界面的全面描述,但它没有捕获状态转换 ,特别是动作(例如,微小按钮被按下)对界面的细微影响
- 为了解决这一限制,论文训练模型识别和描述两个连续截图之间的差异,并确定是否发生了诸如鼠标点击或键盘输入之类的动作
- 论文还纳入了对应于非交互式 UI 变化(例如动画、屏幕刷新或背景更新)的截图对
- 在训练期间,向 UI-TARS 展示一对图像,并要求其预测这两个图像的特定视觉变化(以及可能的原因)
- 通过这种方式,UI-TARS 学习细微的 UI 变化,包括用户发起的动作和非交互式转换
- 这种能力对于需要细粒度交互理解和动态状态感知的任务至关重要
- 问答(Question Answering, QA)
- 虽然密集标题和元素描述主要关注对 GUI 的布局和元素的理解,但问答提供了一种更动态、更灵活的方法,将这些任务与推理能力相结合
- 论文合成了多样化的问答数据集,涵盖广泛的任务,包括界面理解、图像解释、元素识别和关系推理
- 这增强了 UI-TARS 处理涉及更高程度抽象或推理的查询的能力
- 标记集(Set-of-Mark, SoM)
- 论文还增强了 UI-TARS 的标记集提示能力(2023b)
- 论文根据 GUI 截图中解析元素的空间坐标,为这些元素绘制视觉上不同的标记
- 这些标记在形式、颜色和大小等属性上有所不同,为模型提供清晰、直观的视觉线索,以定位和识别特定元素
- 通过这种方式,UI-TARS 更好地将视觉标记与其对应的元素相关联
- 论文将标记集标注与密集标题和问答等任务相结合
- 例如,可以训练模型描述由标记突出显示的元素
Unified Action Modeling and Grounding
- 改进动作能力的实际方法包括训练模型模仿人类在任务执行中的行为,即行为克隆(Bain和Sammut, 1995)
- 虽然单个动作是离散和孤立的,但现实世界的智能体任务本质上涉及执行一系列动作,因此必须在多步轨迹上训练模型
- 这种方法使模型不仅能够学习如何执行单个动作,还能学习如何有效地对它们进行排序( System 1 思维)
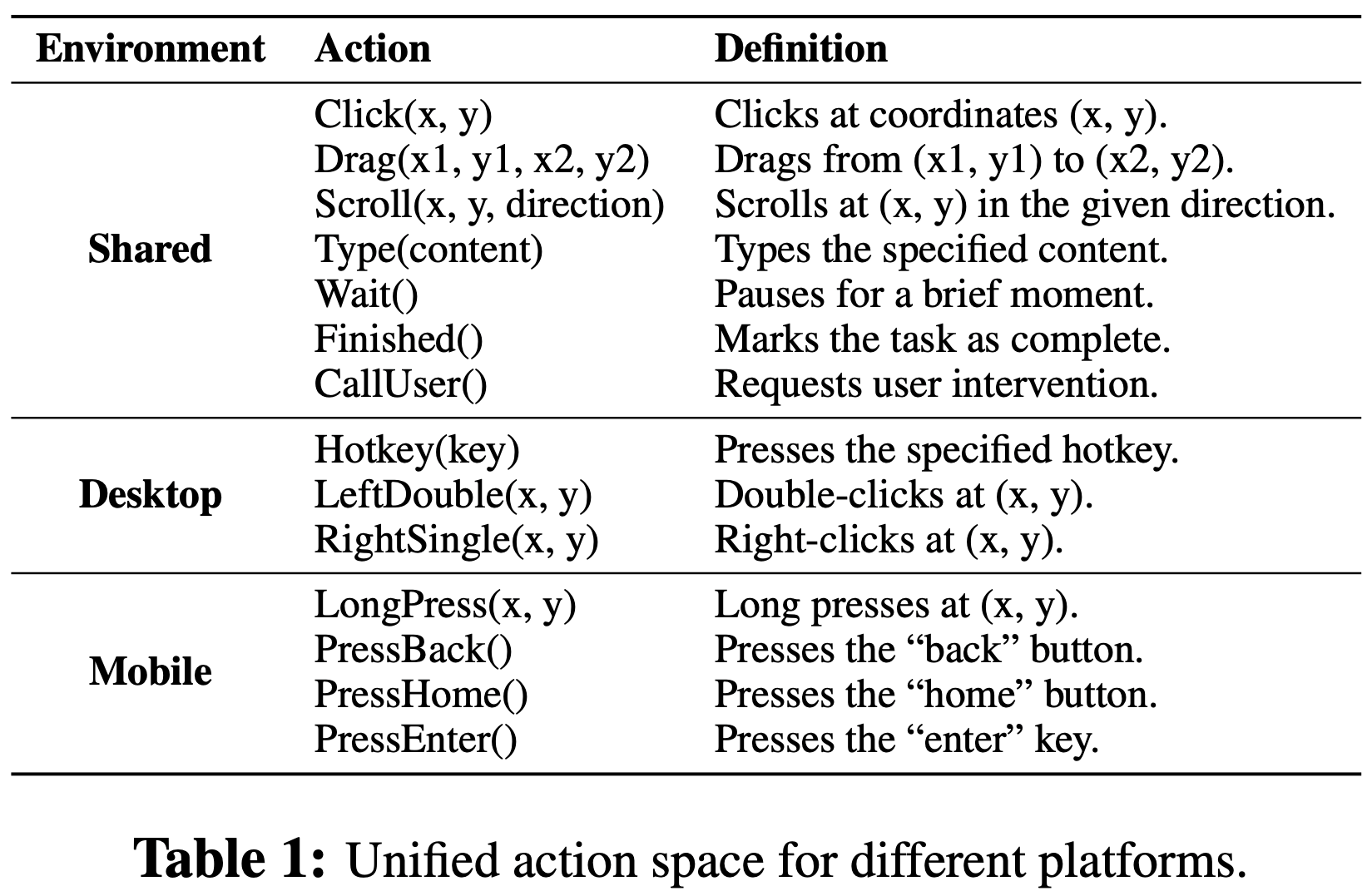
- 统一动作空间(Unified Action Space)
- 与先前的工作类似,论文设计了一个通用动作空间,标准化跨设备的语义等效动作(表1),例如 Windows 上的“点击”与移动设备上的“轻触”,实现跨平台的知识转移
- 由于设备特定的差异,论文还引入了为每个平台量身定制的可选动作
- 这确保模型能够处理每个设备的独特要求,同时在各种场景中保持一致性
- 论文还定义了两个终端动作:Finished(),表示任务完成;以及 CallUser(),在需要用户干预的情况下调用,例如登录或身份验证
- 动作轨迹收集(Action Trace Collection)
- 训练模型执行任务的一个重大挑战在于多步轨迹数据的可用性有限,这些数据在历史上记录不足且稀少
- 为了解决这个问题,论文依赖两个主要数据源:
- (1)论文的标注数据集:
- 论文开发了专门的标注工具,以捕获PC环境中各种软件和网站上的用户动作
- 标注过程始于创建初始任务指令,标注者对其进行审查和完善,以确保清晰度并与预期目标保持一致
- 然后,标注者执行任务,确保他们的动作满足指定的要求
- 每个任务都经过严格的质量筛选;
- (2)开源数据:
- 论文还整合了多个现有数据集( MM-Mind2Web(2024b)、 GUI Act(2024c)、AITW(2023)、AITZ(2024d)、AndroidControl(2024c)、 GUI-Odyssey(2024a)、AMEX(2024)),并将它们标准化为统一的动作空间格式
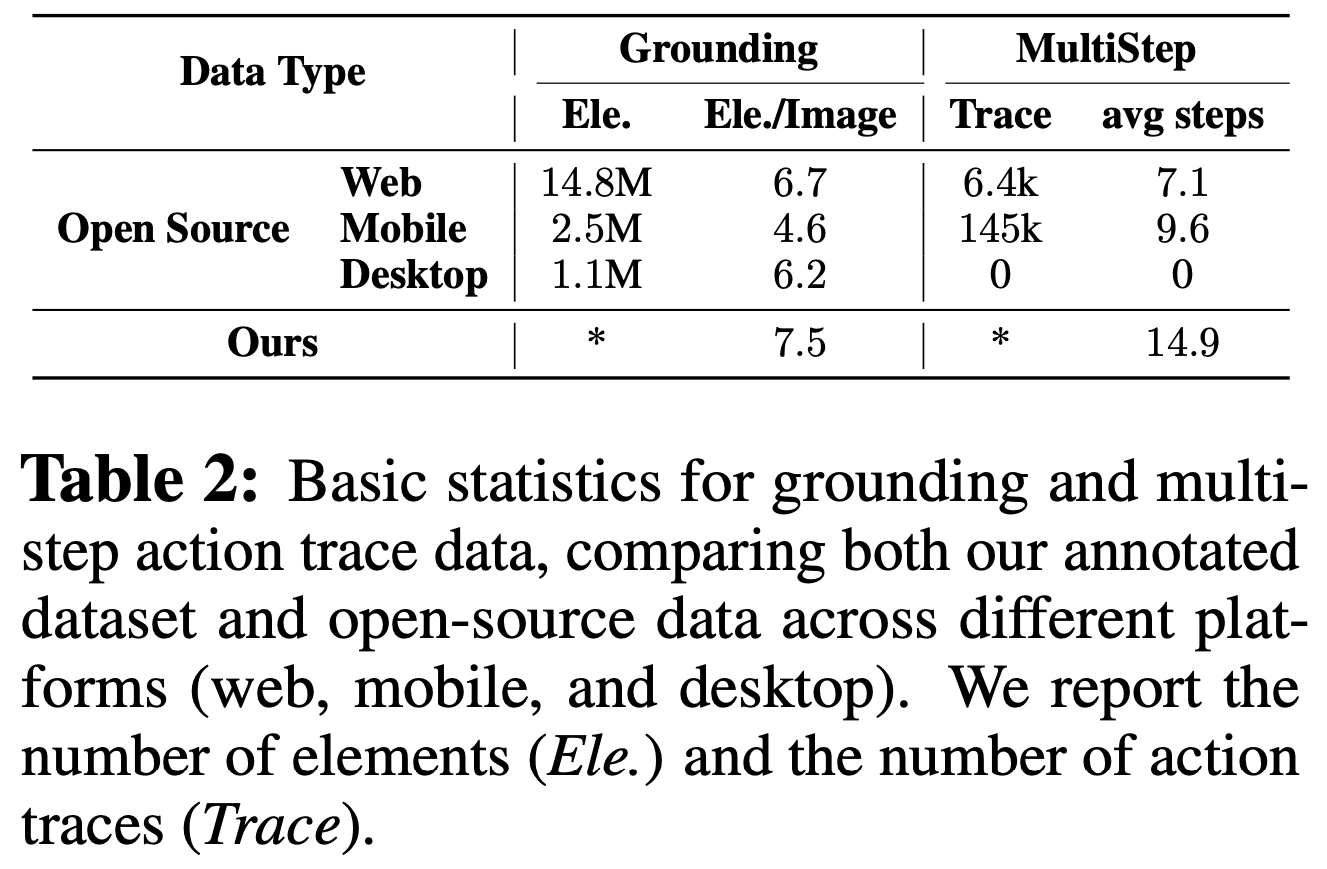
- 这涉及将不同的动作表示协调为一致的模板,以便与标注数据无缝集成。在表2中,论文列出了动作轨迹数据的基本统计信息
- (1)论文的标注数据集:
- 提高定位能力(Improving Grounding Ability)
- 定位(Grounding) ,即准确找到特定 GUI 元素并与之交互的能力,对于诸如点击或拖动之类的动作至关重要
- 与多步动作数据不同,定位数据更容易扩展,因为它主要依赖于元素的视觉和位置属性,这些属性可以有效地合成或提取(2024; 2024a; 2024b)
- 论文训练 UI-TARS 直接预测它需要交互的元素的坐标
- 这涉及将 GUI 中的每个元素与其空间坐标和元数据相关联
- 如章节4.2所述,论文收集了截图,并使用专门的解析工具提取了元数据,包括元素类型、深度、边界框和文本内容
- 对于记录有边界框的元素,论文计算角的平均值以得出单个点坐标,表示边界框的中心
- 为了构建训练样本,每个截图都与从元数据派生的单个元素描述配对
- 模型的任务是输出归一化到屏幕尺寸的相对坐标,确保在具有不同分辨率的设备上保持一致性
- 例如,给定描述“右上角标有‘提交’的红色按钮”,模型预测该按钮的归一化坐标
- 这种描述和坐标之间的直接映射增强了模型理解和准确定位视觉元素的能力
- 为了进一步扩充论文的数据集,论文整合了开源数据(Seeclick(2024)、 GUI Act(2024c)、MultiUI(2024b)、Rico-SCA(2020a)、WidgetCaption(2020b)、MUG(2024b)、Rico Icon(2022)、CLAY(2022)、UIBERT(2021)、OmniACT(2024)、Auto GUI (Anonymous, 2024)、OS-ATLAS(2024b)),并将它们标准化为论文的统一动作空间格式
- 论文在表2中提供了用于训练的定位数据的基本统计信息
- 这个组合的数据集使 UI-TARS 能够实现高精度定位,显著提高其在点击和拖动等动作中的有效性
Infusing System 2 Reasoning
- 仅依靠 System 1 的直觉决策不足以处理复杂场景和不断变化的环境
- 因此,论文旨在让UI-TARS结合 System 2 级别的推理,通过理解任务的全局结构灵活规划动作步骤
Reasoning Enrichment with GUI Tutorials
- 第一步侧重于推理丰富(reasoning enrichment),论文利用公开可用的教程,这些教程交织了文本和图像,演示了在各种软件和网络环境中的详细用户交互
- 这些教程为建立基础 GUI 知识提供了理想的来源,同时引入了任务执行中固有的逻辑推理模式
- 论文选择 MINT(2024)和 OmniCorpus(2024a)这两个广受认可的图像-文本交错预训练数据集作为论文的初始数据源
- 然而,这些数据集包含大量噪声,只有一小部分符合 GUI 教程标准
- 为了提取高质量的教程数据,论文实施了多阶段数据收集和筛选流程:
- (1)粗粒度筛选:
- 为了分离类似教程的内容,论文使用手动精心挑选的高质量教程正集和来自 MINT 和 OmniCorpus 的随机样本作为负集,训练了一个fastText分类器(2016)
- 然后应用训练好的分类器进行初步筛选,过滤掉不相关的样本并生成候选数据集
- (2)细粒度筛选:
- 为了进一步细化候选数据集,论文使用大型语言模型(Large Language Model, LLM)识别并移除假阳性样本
- 这一步确保剩余样本符合 GUI 教程的特征。粗筛选和细筛选过程经过多轮迭代,以最大限度地提高高质量 GUI 教程的召回率
- (3)去重和数据优化:
- 对筛选后的数据集进行进一步优化,以处理重复项、广告和残留噪声
- 使用基于 URL 的方法和局部敏感哈希(Locality-Sensitive Hashing, LSH)方法进行去重
- 最后,论文提示大型语言模型重新表述教程中的所有文本内容,在优化内容的同时消除不相关或低质量的内容
- (1)粗粒度筛选:
- 通过这个多阶段过程,论文精心挑选了大约 6M 个高质量的 GUI 教程
- 平均而言,每个教程包含 510 个文本 Token 和 3.3 个图像。这些数据不仅增强了模型对 GUI 操作的理解,还为注入推理能力奠定了坚实的基础
Reasoning Stimulation with Thought Augmentation
- 论文在章节4.3中收集的动作轨迹数据本质上是以动作为中心的,包含观察和动作序列 \((o_{i-1}, a_{i-1}, o_{i}, a_{i}, …)\),但缺乏明确的推理思考
- 为了刺激 UI-TARS 的推理能力,论文通过标注“思考”来扩充数据集,以弥合感知和动作之间的差距
- 这将数据格式转换为 \((o_{i-1}, t_{i-1}, a_{i-1}, o_{i}, t_{i}, a_{i}, …)\),其中 \(t\) 表示推理思考
- 这些思考使模型能够明确表达其决策过程,促进与任务目标的更好对齐
- 为了构建这些思考,论文采用两个标注阶段:
- 阶段(1)ActRe(2024b):如(4)所示,对于在章节4.3中收集的每个轨迹,论文将它们分成多个步骤
- 对于每个步骤 \(n\),其思考 \(t_{n}\) 通过用先前的上下文和当前的目标动作 \(a_{n}\) 提示视觉语言模型来迭代生成
- 这种方法试图使生成的思考在逻辑上基于先前的上下文,并与当前动作对齐
$$
\left\{
\begin{array}{l}
t_{n} = VLM(instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, o_{n}, a_{n}) \\
t_{n+1} = VLM(instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, (o_{n}, t_{n}, a_{n}), o_{n+1}, a_{n+1}) \\
\vdots
\end{array}
\right. \tag{4}
$$ - 在ActRe标注期间,论文提示视觉语言模型表现出更高阶的 System 2 推理,这涉及审慎的、逐步的决策和反思
- 通过促进这些推理模式,论文鼓励模型进行深思熟虑的长期规划和反思,以解决复杂任务
- 如图6所示,论文提示视觉语言模型遵循的推理模式包括:
- 任务分解:指导模型将复杂任务分解为更小的、可管理的子任务,使其能够逐步处理复杂的工作流
- 长期一致性:确保模型在整个任务过程中保持一致的目标,参考整体目标和操作历史,以避免在复杂的多步骤任务中出现偏差
- 里程碑识别:使模型能够识别中间目标的完成情况,促进向后续目标的平稳过渡
- 试错:使模型能够假设、测试和评估潜在动作,特别是在模糊情况下(如无需直接交互即可验证搜索结果)
- 反思:使模型能够在操作失败时识别并纠正错误,通过反思性推理鼓励适应性和错误恢复

- 阶段(2)思考自举(Thought Bootstrapping) :
- 基于真实动作反向标注思考(即ActRe)可能导致假阳性,因为生成的思考可能在表面上与相应动作匹配,但没有建立真正的因果关系
- 具体而言,动作背后的推理过程可能被忽略,导致思考仅通过巧合与动作对齐,而不是通过逻辑推理
- 出现这个问题是因为标注过程依赖于预先知道动作,这可能会使思考偏向于符合动作,而不是反映导致动作的实际决策过程
- 为了解决这个问题,论文采用了一种自举方法,在不预先知道真实动作的情况下生成思考
- 通过采样多个思考-动作对,如(5)所示,论文识别出导致正确动作的思考,确保推理与所选动作存在因果对齐
- 这种方法产生更高质量的标注,因为它迫使模型模拟真正的决策过程,而不仅仅是为预先确定的动作辩护(\(UI-TARS_{early}\) 表示早期模型检查点)
$$
\left\{
\begin{array}{l}
(\hat{t}_{n_{i} }, \hat{a}_{n_{i} })_{i=1}^{max-try} = UI-TARS_{early}(instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, o_{n}) \\
Select(\hat{t}_{n_{i} }, \hat{a}_{n_{i} }), where \hat{a}_{n_{i} } = a_{n}
\end{array}
\right. \tag{5}
$$
- 论文用中文和英文两种语言标注思考,以扩大语言多样性
- 尽管论文为所有轨迹增强了思考,但在训练期间论文也会涉及 vanilla 动作轨迹(没有思考)
- 基于真实动作反向标注思考(即ActRe)可能导致假阳性,因为生成的思考可能在表面上与相应动作匹配,但没有建立真正的因果关系
Learning from Prior Experience in Long-term Memory
- GUI 智能体在扩展到 LLM 级别方面面临重大挑战,主要原因是缺乏用于 GUI 操作的大规模、标准化、真实世界流程数据
- 虽然大型语言模型可以利用丰富的文本数据,这些数据捕获了各种知识和推理模式,但详细记录 GUI 环境中用户交互和决策序列的流程数据很少被记录或系统地组织
- 这种数据的缺乏阻碍了 GUI 智能体有效扩展和在广泛任务中泛化的能力
- 一个有前景的解决方案在于从存储在长期记忆中的先前经验中学习
- 通过捕获和保留来自先前任务的知识,智能体可以利用这些过去的经验为未来的决策提供信息,使其动作更具适应性和效率
- 为了促进这一过程,论文让 UI-TARS 能够从与真实世界设备的交互中动态学习
- 通过半自动化的数据收集、筛选和优化,该模型不断改进,同时最大限度地减少对人工干预的需求
- 通过利用长期记忆,UI-TARS 建立在其积累的知识基础上,随着时间的推移优化其性能,并更有效地适应新任务
- 这个过程的每次迭代都会产生一个更强大的模型
Online Trace Bootstrapping
- 如图7所示,论文首先获得多样化的任务目标集,结合人工标注的指令和模型生成的指令
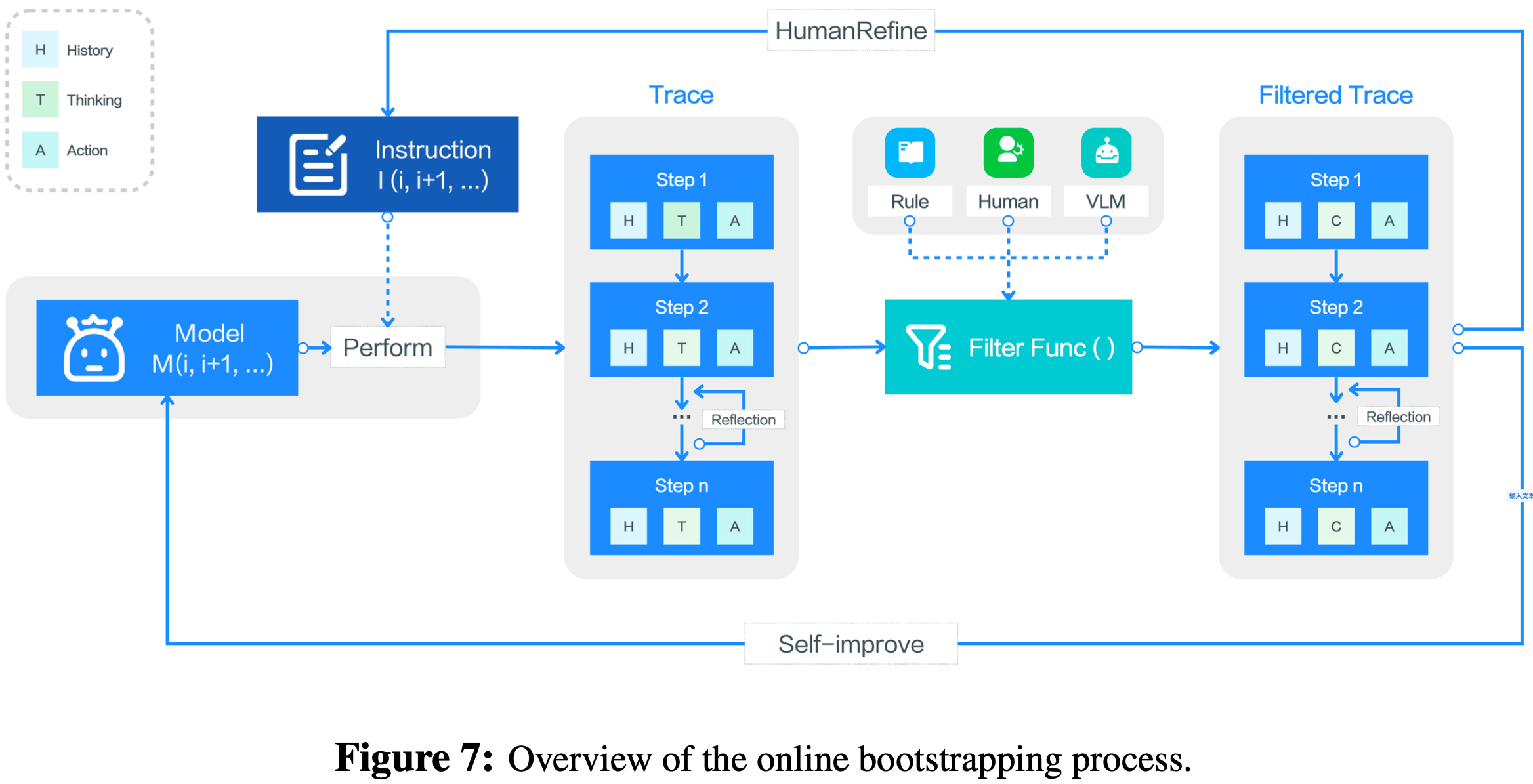
- 在迭代 \(n\) 时,智能体 \(\psi_{n}\) 在目标 GUI 环境(例如虚拟PC)中执行这些指令,生成原始轨迹集:
$$\mathcal{T}_{raw, n} = \{(o_{1}, t_{1}, a_{1}, o_{2}, t_{2}, a_{2}, …, o_{n}, t_{n}, a_{n}), \cdots\}$$ - 为了确保高质量的数据,论文应用多级筛选函数:
$$Filter(\mathcal{T}_{raw, n}, \mathcal{I}_{n}) = \mathcal{T}_{filtered, n}$$ - 通过以下步骤丢弃有噪声或无效的轨迹:
- (1)基于规则的奖励:启发式规则移除具有明显异常的轨迹(例如,不改变环境的冗余动作);
- (2)视觉语言模型评分:视觉语言模型为剩余轨迹分配质量分数,移除得分低于预定义阈值的轨迹;
- (3)人工审核:部分轨迹由标注者(annotators)进一步检查,他们识别出发生错误的步骤,丢弃后续动作,并只保留有效的前缀
- UI-TARS利用得到的筛选轨迹集 \(\mathcal{T}_{filtered, n}\) 进行自我改进:
$$M_{n+1} = FineTune(M_{n}, \mathcal{T}\_{filtered, n})$$ - 对于每一轮,论文让标注者优化或扩展指令集:
$$\mathcal{I}_{n+1} = HumanRefine(\mathcal{I}_{n}, \mathcal{T}_{filtered, n})$$ - 论文在数百台虚拟 PC 上多轮迭代上述过程,不断利用最新模型 \(M_{n}\) 生成新轨迹,从而扩展和优化数据
Reflection Tuning
- 在现实的在线部署中,智能体经常会遇到因缺乏自我反思和错误纠正能力而陷入困境的情况
- 例如,智能体可能会反复点击无响应的按钮,或者由于对界面的误解而尝试无效操作
- 如果没有识别这些错误或调整策略的能力,智能体将陷入无效动作的循环,无法向任务目标推进
- 然而,大多数离线数据集包含理想化的、无错误的轨迹,因为标注者在数据标注过程中确保每个动作都符合预期
- 虽然此类数据有助于减少模型训练期间的噪声,但也阻止了智能体学习如何从错误中恢复
- 为了解决这一限制,论文提出了一种反思调整协议,使模型接触到自身犯下的真实世界错误及其纠正方法,使 UI-TARS 能够学习如何从次优决策中恢复
- 对于 UI-TARS 生成的在线轨迹:
$$ \mathcal{T} = (instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, (o_{t}, t_{t}, a_{t})$)$$- 假设在步骤 \(\tau\) 发生错误,其中动作 \(a_{\tau}\) 被认为是无效的或次优的
- 论文要求标注者识别此错误,并标记纠正后的思考和动作 \(t_{\tau}^{*}\)、\(a_{\tau}^{*}\)
- 这产生了一个错误纠正轨迹对:
$$
\left\{
\begin{array}{l}
\mathcal{T}_{-} = (instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, (o_{\tau}, t_{\tau}, a_{\tau})) \\
\mathcal{T}_{+} = (instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, (o_{\tau}, t_{\tau}^{*}, a_{\tau}^{*}))
\end{array}
\right.
$$
- 论文的创新是,进一步要求标注者基于错误动作 \(a_{\tau}\) 继续标记后续步骤,模拟错误已经发生的场景
- 在确定下一步的思考 \(t_{\tau+1}^{*}\) 时,标注者必须承认先前错误的影响,弥补其影响,并提供正确的动作 \(a_{\tau+1}^{*}\) 以重新调整任务进度
- 例如,如果前一步旨在将网页添加到书签,但错误地点击了关闭按钮,那么下一步应该包括重新打开最近关闭的网页,以重新尝试点击书签按钮
- 形式上,论文有一个反思后轨迹对:
$$
\left\{
\begin{array}{l}
\mathcal{T}_{-} = (instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, (o_{\tau}, t_{\tau}, a_{\tau}), (o_{\tau+1}, t_{\tau+1}, a_{\tau+1})) \\
\mathcal{T}_{+} = (instruction, (o_{1}, t_{1}, a_{1}), (o_{2}, t_{2}, a_{2}), …, (o_{\tau}, t_{\tau}, a_{\tau}), (o_{\tau+1}, t_{\tau+1}^{*}, a_{\tau+1}^{*}))
\end{array}
\right.
$$
- 论文利用正样本 \(T_{+}\) 进行有 SFT 训练,并且只对纠正后的步骤(即 \((t_{\tau}^{*}, a_{\tau}^{*})\) 和 \((t_{\tau+1}^{*}, a_{\tau+1}^{*})\))计算损失,而错误步骤(即 \((t_{\tau}, a_{\tau})\))不用于训练
- 通过这个过程,UI-TARS逐渐提高其识别和从错误中恢复的能力,使其能够在面对不完善或不确定的条件时做出有效调整
- 培养这种反思能力增强了智能体对动态环境和任务的适应性
Agent DPO
- 在在线自举期间,自然会产生大量错误步骤(负例) ,但 SFT 仅利用纠正后的步骤(即“正”例),而忽略负样本
- 这限制了其明确引导智能体远离次优动作的能力
- 为了解决这一限制,论文转向直接偏好优化(2023),它通过引入基于参考的目标函数来利用纠正后的动作和错误动作
- 这种方法通过直接编码对纠正动作(正例)而非错误动作(负例)的偏好来优化 UI-TARS,从而更好地利用可用数据
- 考虑智能体最初执行了错误动作 \(a_{\tau}\) 后来被纠正为优选动作 \(a_{\tau}’\) 的状态 \(s_{\tau}\)
- 这里,状态 \(s_{\tau}\) 由指令及其到当前步骤的交互历史 \((o_{1}, t_{1}, a_{1}, …, o_{\tau-1}, t_{\tau-1}, a_{\tau-1})\) 组成
- 这种全面的表示为智能体做出明智决策提供了必要的上下文
- 关键思想是定义一个偏好可能性,量化模型对纠正动作 \(a_{\tau}’\) 相对于原始动作 \(a_{\tau}\) 的偏好程度
- 形式上,论文定义一个学习到的奖励函数 \(r_{\theta}(s, a)\),估计在状态 \(s\) 中采取动作 \(a\) 的可取性
- 基于 Bradley-Terry Model(1952),我们可以将成对偏好可能性表示为:
$$P_{\theta}(a_{\tau}’ \succ a_{\tau} | s_{\tau}) = \frac{exp(r_{\theta}(s_{\tau}, a_{\tau}’))}{exp(r_{\theta}(s_{\tau}, a_{\tau})) + exp(r_{\theta}(s_{\tau}, a_{\tau}’))}$$- 其中,\(a_{\tau}’ \succ a_{\tau}\) 表示 \(a_{\tau}’\) 比 \(a_{\tau}\) 更受偏好
- 分子表示分配给纠正动作的奖励的指数,而分母是两个动作的奖励的指数之和,确保可能性得到适当归一化
- 直接偏好优化从具有KL散度约束的强化学习目标中导出解析最优策略。论文遵循直接偏好优化,用最优策略替换奖励函数 \(r_{\theta}\),并直接在偏好数据集上优化直接偏好优化目标:
$$\mathcal{L}_{DPO}(\theta) = -\underset{\tau}{\mathbb{E} }\left[log \sigma\left(\beta log \frac{\pi_{\theta}(a_{\tau}’ | s_{\tau})}{\pi_{SFT}(a_{\tau}’ | s_{\tau})} - \beta log \frac{\pi_{\theta}(a_{\tau} | s_{\tau})}{\pi_{SFT}(a_{\tau} | s_{\tau})}\right)\right]$$- \(\tau\) 遍历所有有错误纠正对的时间步
- \(\pi_{\theta}\) 表示最优智能体
- \(\pi_{SFT}\) 表示有监督微调智能体
- \(\beta\) 作为超参数控制最优智能体和有监督微调智能体之间的差异
- 通过最小化直接偏好优化损失,论文使智能体增加纠正动作的可能性,同时减少错误动作的可能性,并使用隐式奖励函数
Training
- 为了确保与现有工作(如 Aguvis(2024)和 OS-Atlas(2024b))进行公平比较,论文使用相同的视觉语言模型骨干 Qwen-2-VL(2024c),并采用三阶段训练过程
- 该过程在各种 GUI 任务中优化模型的能力,使用的总数据量约为 50B 个 Token
- 每个阶段逐步纳入更高质量的数据,以提高模型在复杂推理任务上的性能
- 持续预训练阶段(Continual Pre-training Phase) :
- 论文使用章节4中描述的全套数据(不包括反思调整数据)进行持续预训练,采用恒定的学习率
- 这个基础阶段使模型能够学习自动 GUI 交互所需的所有知识,包括感知、定位和动作轨迹,确保对各种 GUI 元素和交互的稳健覆盖
- 退火阶段(Annealing Phase) :
- 然后,论文选择感知、定位、动作轨迹、反思调整数据的高质量子集进行退火
- 退火过程逐渐调整模型的学习动态,促进更有针对性的学习,并更好地优化其在真实世界 GUI 交互场景中的决策策略
- 论文将此阶段后训练的模型表示为 UI-TARS-SFT
- 直接偏好优化阶段 :
- 最后,论文使用来自在线自举数据的标注反思对进行直接偏好优化训练
- 在此过程中,模型优化其决策,强化最优动作,同时惩罚次优动作
- 这个过程提高了模型在真实世界 GUI 交互中做出精确、上下文感知决策的能力
- 最终模型表示为 UI-TARS-DPO
Experiment
- 在本节中,论文评估 UI-TARS 的性能
- 该模型在第4节所述的包含约 50B 词元的数据集上进行训练
- 论文选择 Qwen-2-VL (2024c) 作为训练的基础模型,并开发了三个模型变体:UI-TARS-2B、UI-TARS-7B 和 UI-TARS-72B
- 论文进行了大量实验来验证所提出模型的优势
- 这些实验旨在评估模型在感知、定位和智能体能力这三个关键维度上的能力
- 最后,论文进行了对比分析,以进一步研究 System 1 和 System 2 推理对下游任务的影响
- 在本节中,论文将公式(3)中的 \(N\) 设置为5
- 在5.4节中,论文同时评估了 UI-TARS-SFT 和 UI-TARS-DPO 在 OSWorld 基准测试中的表现,因为该基准测试从 DPO 阶段的迭代改进中获益最大
- 然而,对于其他基准测试,论文报告的是经过退火阶段训练后的模型(即 UI-TARS-SFT)的结果
- Baseline :
- 论文将 UI-TARS 与各种基线模型进行比较,包括:
- 商业模型,如 GPT-4o (2024)、Claude-3.5-Sonnet (2024a)、Gemini-1.5-Pro (2024) 和 Gemini-2.0 (Project Mariner) (2024)
- 学术模型,如 CogAgent (2024)、OminiParser (2024b)、InternVL (2024d)、Aria-UI (2024a)、Aguvis (2024)、OS-Atlas (2024b)、UGround (2024b)、ShowUI (2024a)、SeeClick (2024)、Qwen系列模型QwenVL-7B (2023b)、Qwen2-VL (7B和72B) (2024c)、UIX-Qwen2-7B (2024a) 和 Qwen-VL-Max (2023a)
- 论文将 UI-TARS 与各种基线模型进行比较,包括:
Perception Capability Evaluation
- 论文使用三个关键基准测试来评估 UI-TARS 模型的感知能力:VisualWebBench (2024c)、WebSRC (2021) 和ScreenQA-short (2022)
- VisualWebBench 衡量模型理解和定位网页元素的能力,涵盖网页问答、网页光学字符识别(OCR)和动作预测等任务
- UI-TARS 模型取得了出色的成绩,其 72B 变体得分达到 82.8,显著超过了 GPT-4o(78.5)和 Claude 3.5(78.2)等闭源模型,如表3所示
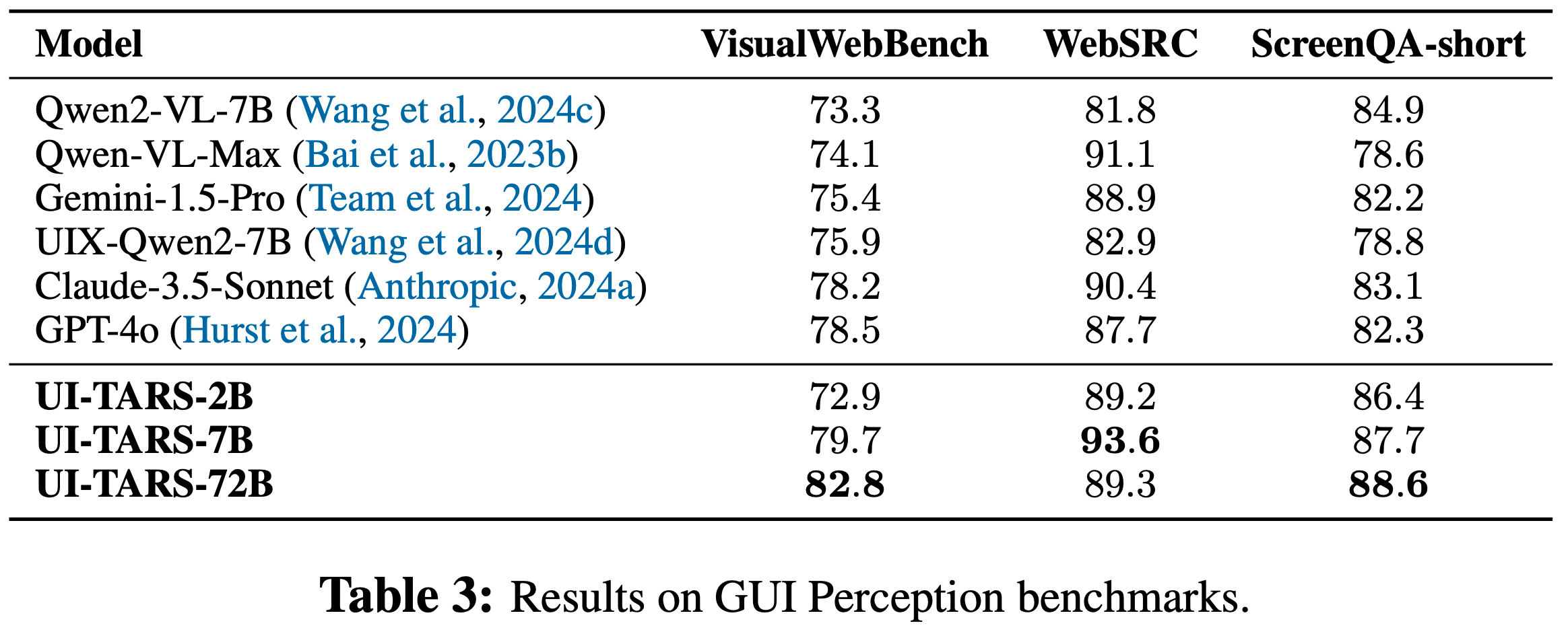
- 对于 WebSRC 和 ScreenQA-short,这两个基准测试通过问答任务评估网页结构理解和移动屏幕内容理解能力,UI-TARS模型展现出明显的优势
- WebSRC 专注于理解网页上下文中网页的语义内容和布局
- ScreenQA-short 评估对复杂移动屏幕布局和界面相关问题的解读能力
- UI-TARS-7B 在 WebSRC 上获得了领先的 93.6 分,而 UI-TARS-72B 在 ScreenQA-short 中以 88.6 分的成绩表现出色
- 这些结果证明了 UI-TARS 在网页和移动环境中卓越的感知和理解能力
- 这种感知能力为智能体任务奠定了基础,因为准确的环境理解对于任务执行和决策至关重要
Grounding Capability Evaluation
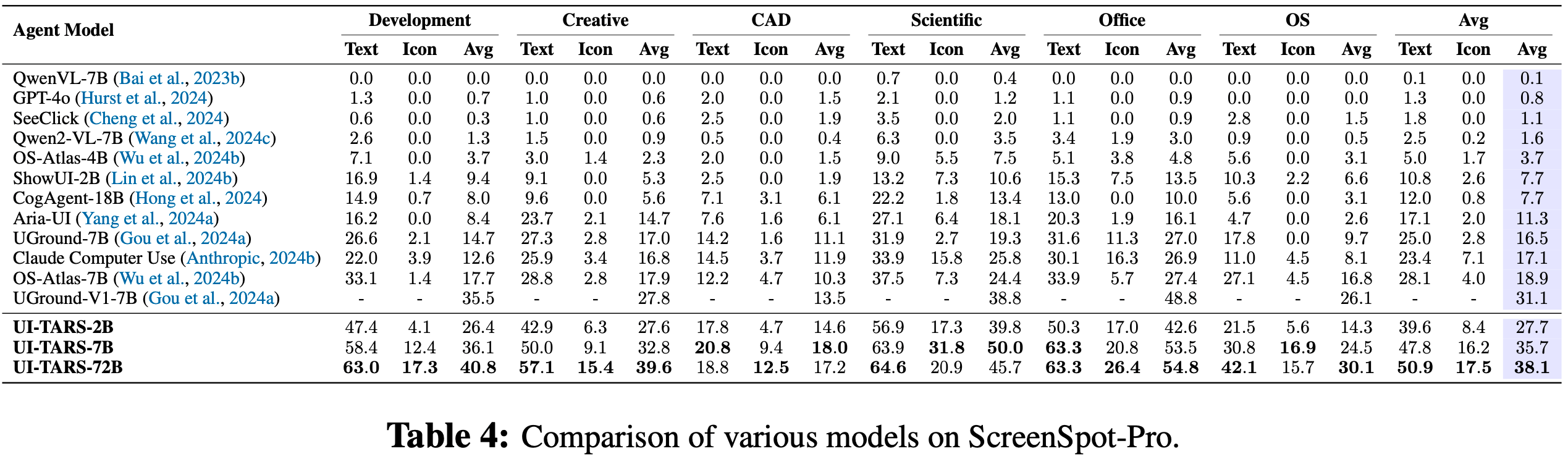
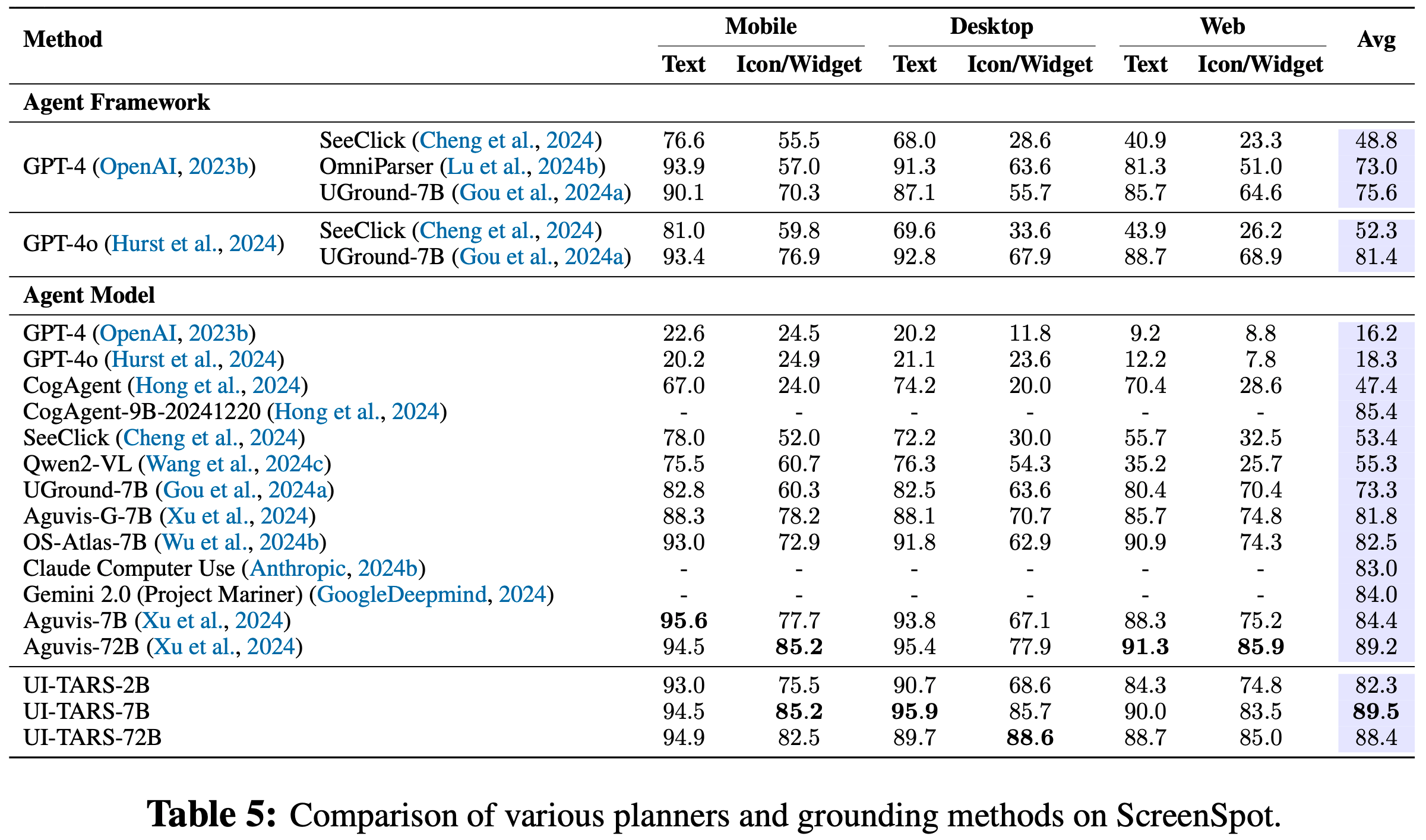
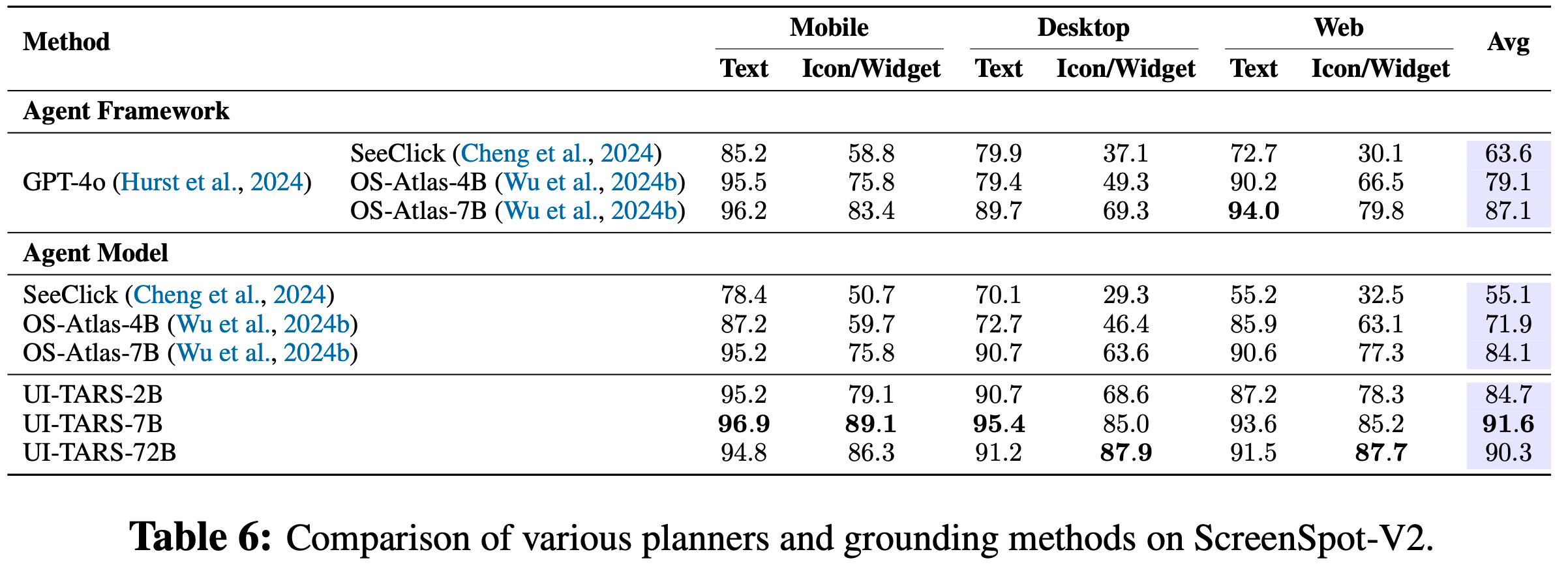
- 为了评估 UI-TARS 的定位能力,论文重点关注三个基准测试:ScreenSpot Pro (2025)、ScreenSpot (2024) 和ScreenSpot v2 (2024b)
- 这些基准测试评估在图形用户界面(GUI)中理解和定位元素的能力
- ScreenSpot Pro 是为高分辨率专业环境设计的,该基准测试包括来自五个行业和三个操作系统的23个应用程序的专家标注任务
- 它为在专业、高复杂度场景中评估模型的定位性能提供了严格的标准
- ScreenSpot 和 ScreenSpot v2 在移动、桌面和网页平台上测试 GUI 定位能力
- ScreenSpot 使用直接指令和自生成计划来评估模型
- ScreenSpot v2通过纠正标注错误提高了评估的准确性
- UI-TARS 在多个基准测试中始终优于基线模型
- 具体来说,在表4中,UI-TARS-72B 在 ScreenSpot Pro 上获得了 38.1 分,显著超过 UGround-V1-7B(31.1)和OS-Atlas-7B(18.9)的性能
- 值得注意的是,论文观察到在 ScreenSpot Pro 上提高输入图像分辨率会导致性能显著提升
- 此外,UI-TARS-7B 在 ScreenSpot 上获得了领先的 89.5 分,如表5所示
- 在ScreenSpot v2上,如表6所示,UI-TARS-7B(91.6)和UI-TARS-72B(90.3)均超过了现有基线模型,如OS-Atlas-7B(87.1),进一步凸显了论文方法的稳健性
- 此外,结果显示,从UI-TARS-2B 到 UI-TARS-7B,在所有三个定位数据集上,定位性能都有显著提升
- 比较 UI-TARS-7B 和 UI-TARS-72B,虽然 ScreenSpot v1 和 v2 没有显示出显著的性能变化,但 ScreenSpot Pro 显示出模型在规模扩大时的显著改进
- 这表明 ScreenSpot v1 和 v2 可能不够稳健,无法充分捕捉更高规模下模型的定位能力
Offline Agent Capability Evaluation
- 为了评估 UI-TARS 在静态、预定义环境中的 GUI 智能体能力,论文在三个基准测试上进行评估:
- Multimodal Mind2Web (2024a)旨在创建和评估执行语言指令的通用网页智能体,主要评估模型在基于网页的环境中的性能,指标包括元素准确率(Ele.Acc)、操作F1分数(Op.F1)和步骤成功率(Step SR),如表7所示;
- Android Control (2024c)评估移动环境中的规划和动作执行能力,该数据集包括两种类型的任务,高级任务要求模型自主规划和执行多步动作,低级任务指示模型为每个步骤执行预定义的、人工标注的动作(表8);
- GUI Odyssey (2024a)专注于移动环境中的跨应用导航任务,每个任务平均有15个以上的步骤,任务涵盖各种导航场景,指令由预定义模板生成,该数据集包括在安卓模拟器上记录的人工演示,为每个任务情节提供详细且经过验证的元数据
- 对于Multimodal Mind2Web,论文遵循原始框架中指定的设置和指标
- 对于Android Control和 GUI Odyssey(表8),论文遵循OS-Atlas (2024b)中概述的设置和指标
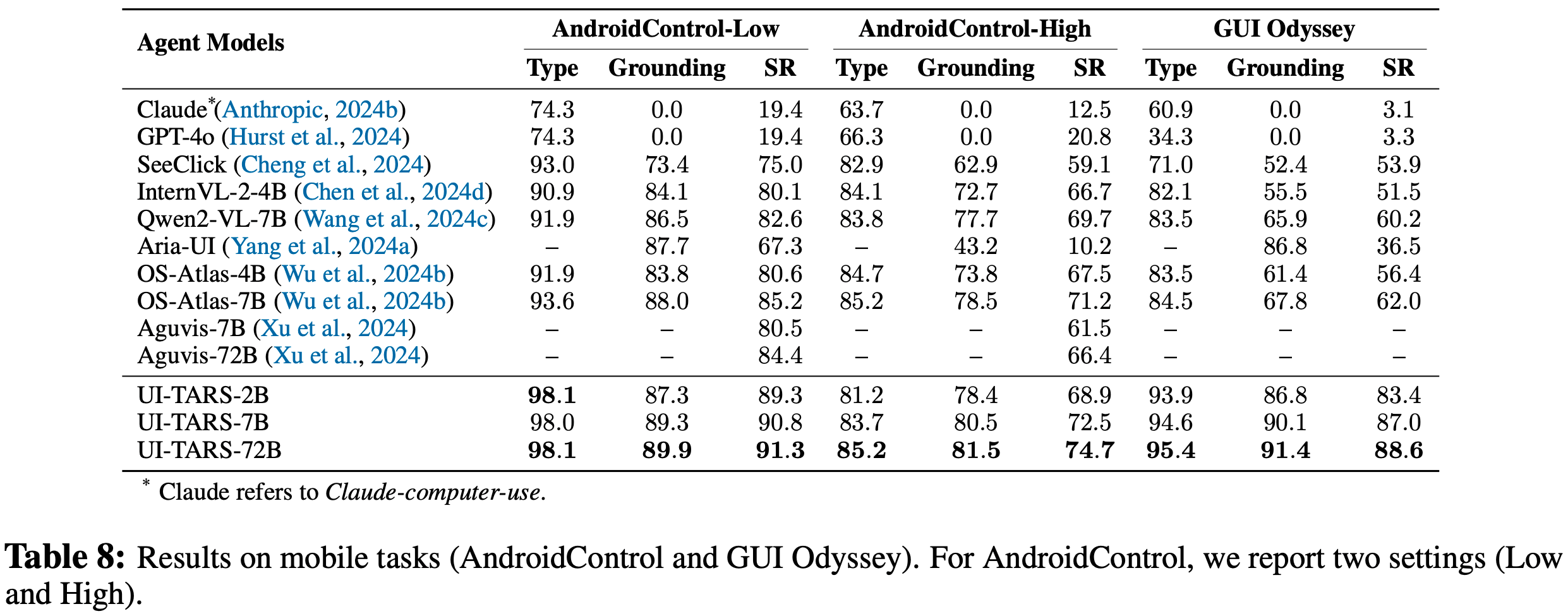
- 在这三个评估数据集中,UI-TARS 在推理和执行能力方面展现出明显的进步
- 在 Multimodal Mind2Web(表7)中,大多数智能体模型显著优于基于框架的方法(使用 GPT-4o 或 GPT-4V 作为核心规划器)
- 比较不同的智能体模型,UI-TARS-72B 在关键指标上实现了最优性能
- UI-TARS-7B 尽管参数较少,但超过了 Aguvis-72B 模型和 Claude 等强大的基线模型
- 在 AndroidControl 和 GUI Odyssey(表7)上,UI-TARS-7B 和 UI-TARS-72B 超过了之前的最优方法(OS-Atlas-7B),绝对性能提升了25,在多步离线任务中表现出显著的优势
- 论文还发现,Claude Computer-Use 在基于网页的任务中表现强劲,但在移动场景中明显吃力,这表明 Claude 的 GUI 操作能力没有很好地转移到移动领域
- 相比之下,UI-TARS 在网站和移动领域均表现出色,突出了其适应性和泛化能力
- 在 Multimodal Mind2Web(表7)中,大多数智能体模型显著优于基于框架的方法(使用 GPT-4o 或 GPT-4V 作为核心规划器)
Online Agent Capability Evaluation
- 在线评估模拟动态环境,每个环境都设计为一个交互式模拟,反映现实世界的场景
- 在这些环境中,GUI 智能体可以通过实时执行动作来改变环境状态
- 论文使用两个基准测试在在线环境中评估不同的模型:
- OSWorld (2024) 提供了一个可扩展且多样化的环境,用于评估多模态智能体在 Ubuntu、Windows 和 macOS 平台上的复杂任务
- 它由 369 个涉及现实世界网页和桌面应用程序的任务组成,具有详细的设置和评估脚本
- 评估在仅使用截图的模式下进行
- 为了减少网络不稳定和环境因素的潜在干扰,最终得分是3次运行的平均值
- 论文也将模型决定 “CallUser” 的轨迹或模型最终未能输出 “Finish” 的轨迹视为不可行任务进行评估
- AndroidWorld (2024b) 是一个用于在实时安卓模拟器上开发和基准测试自主智能体的环境。它包括来自20个移动应用程序的116个任务,通过随机参数生成动态任务变体。这个数据集非常适合评估智能体在移动环境中的适应性和规划能力。结果列于表9
- 在OSWorld上,当给定15步的预算时,UI-TARS-7B-DPO(18.7)和UI-TARS-72B-DPO(22.7)显著超过Claude(14.9),展示了其强大的推理能力。此外,UI-TARS-72B-DPO在15步预算下(22.7)的表现与Claude在50步预算下(22.0)的表现相当,显示出很高的执行效率。值得注意的是,UI-TARS-72B-DPO在OSWorld上以50步预算获得了24.6的新最优结果,超过了所有现有的智能体框架(如搭配Aria-UI的GPT-4o),突出了智能体模型在以更高效率和效果处理复杂桌面任务方面的巨大潜力
- AndroidWorld上的结果得出了类似的结论,UI-TARS-72B-SFT达到了46.6的性能,超过了之前最好的智能体框架(搭配Aria-UI的GPT-4o,44.8)和智能体模型(Aguvis-72B,26.1)
- 比较SFT模型和DPO模型的结果,论文发现DPO显著提高了在OSWorld上的性能,这表明在训练过程中引入 “负样本” 能使模型更好地区分最优和次优动作
- 此外,比较UI-TARS-72B和UI-TARS-7B,论文发现72B模型在在线任务中的表现比7B模型好得多,并且与离线任务相比差距更大(表7和表8)
- 这表明扩大模型规模显著提高了 System 2 推理能力,使决策更加深思熟虑和符合逻辑
- 而且,这种差异表明仅基于离线基准测试的评估可能无法准确反映模型在实时、动态环境中的能力
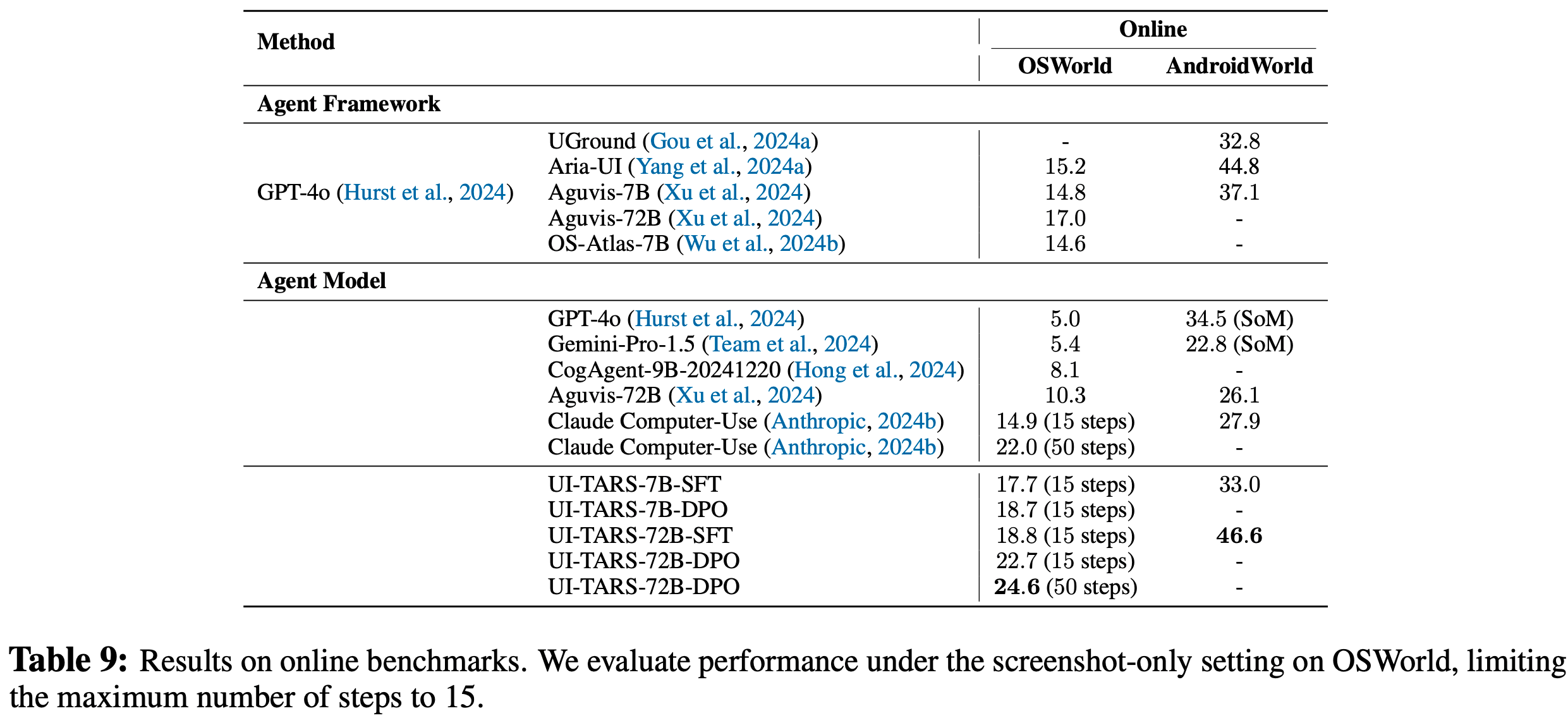
- OSWorld (2024) 提供了一个可扩展且多样化的环境,用于评估多模态智能体在 Ubuntu、Windows 和 macOS 平台上的复杂任务
- 总的来说,这些结果验证了智能体模型在推理密集型任务中的潜力,并强调了利用更大规模模型应对在线环境挑战的优势
Comparing System 1 and System 2 Reasoning
- 论文比较 System 1 和 System 2 推理对模型性能的影响
- System 1 推理是指模型直接生成动作而不进行思维链推理
- System 2 推理则涉及更审慎的思维过程,模型在选择动作之前会生成推理步骤
- 论文训练 UI-TARS-7B 以获得这两种能力,但在推理过程中通过提示工程修改模型的推理行为
In-domain Evaluation
- 论文首先在三个域内智能体基准测试中评估性能:Multimodal Mind2Web、Android Control 和 GUI Odyssey,这些基准测试在 UI-TARS 中都有相应的训练数据
- 为了提高评估效率,论文在 Android Control 和 GUI Odyssey 基准测试中随机抽取 1000 个示例
- 论文使用最佳 \(N\) 选 1(Best-of-N,BoN)采样方法,即 UI-TARS 为每个输入采样 \(N\) 个候选输出, \(N\) 设置为 1、16 和 64
- 评估指标采用步骤成功率
- 如图8所示:
- 当 \(N = 1\) 时,System 2 推理在所有三个域内基准测试中的表现略逊于 System 1 推理
- 虽然通常期望 System 2 推理通过引入反思性的多步过程来提高任务执行能力,但这个结果表明,在单样本条件下, System 2 推理的复杂性可能导致次优的推理步骤
- 具体来说,模型可能会引入无关或错误的推理步骤,例如引用不存在的对象或做出错误的推断,这增加了产生幻觉或无法生成正确动作的风险
- 在没有多样化候选输出的情况下,模型可能会陷入有缺陷的推理路径,导致选择正确动作的可能性降低
- 当 \(N = 1\) 时,System 2 推理在所有三个域内基准测试中的表现略逊于 System 1 推理
- 然而,当 \(N\) 增加到 16 和 64 时,System 2 模型开始显示出相对于 System 1 推理的明显优势。候选输出数量的增加在决策空间中提供了更大的多样性,使模型能够克服次优的推理路径。特别是, System 2 模型受益于探索多个推理链的机会,这弥补了N = 1时出现的问题。候选的多样性增加了正确动作出现在采样输出中的可能性,即使一些中间推理步骤并不理想。这种性能变化尤为显著,因为它表明当有足够的候选输出时, System 2 的审慎多步推理可以有效地弥补其最初的劣势
- 一个关键的发现是,虽然 System 2 推理在多样性充足的情况下表现出色,但要在单一样本输出(如Bo1)中实现最佳性能仍然是一个重大挑战。未来的理想方向是利用 System 2 推理在多样化现实场景中的优势,同时尽量减少对多个样本的需求。这可以通过强化微调(2024)等技术来实现,该技术将引导模型在单次传递中高置信度地生成正确动作
域外评估
- 接下来,论文在 AndroidWorld 上评估这两种推理方法,AndroidWorld 是一个域外(OOD)基准测试,在 UI-TARS 中没有相应的训练数据
- 论文在 Bo1 设置下评估 UI-TARS-7B 和 UI-TARS-72B
- 有趣的是,AndroidWorld 的结果与域内基准测试相比有显著差异
- 虽然 System 1 推理在域内场景(Mind2Web、Android Control和 GUI Odyssey)中表现良好,但 System 2 推理在 OOD 设置(AndroidWorld)中显著优于 System 1
- 这表明,尽管 System 2 在域内场景中可能面临挑战,特别是在单样本条件下,但其更深层次的推理能力在 OOD 情况下具有明显优势
- 在这些情况下,增加的推理深度有助于模型泛化到以前未见过的任务 ,突出了 System 2 推理在现实世界多样化场景中的更广泛适用性和潜力
Conclusion
- 论文介绍了 UI-TARS(一种原生 GUI 智能体模型),它将感知、动作、推理和记忆集成到一个可扩展且具有适应性的框架中
- UI-TARS 在 OSWorld 等具有挑战性的基准测试中取得了 SOTA 性能,优于 Claude 和 GPT-4o 等现有系统
- 论文提出了几项新颖的创新,包括增强的感知能力、统一的动作建模、System 2 推理以及利用在线轨迹进行迭代优化,所有这些创新都使该智能体能够在最少的人工干预下有效处理复杂的 GUI 任务
- 论文还回顾了 GUI 智能体的发展路径,从基于规则的系统到具有适应性的原生模型
- 论文根据人工干预程度和泛化能力,将发展过程划分为几个关键阶段,强调了从基于文本的方法到纯视觉、端到端智能体模型的转变
- 论文还探讨了原生智能体模型的核心能力,包括感知、动作、推理和记忆,这些能力构成了 GUI 智能体未来发展的基础
- 展望未来,虽然原生智能体代表了一大步进步,但未来的发展方向在于整合主动学习和终身学习,使智能体能够通过持续的现实世界交互自主驱动自身的学习
附录 A:Case Study
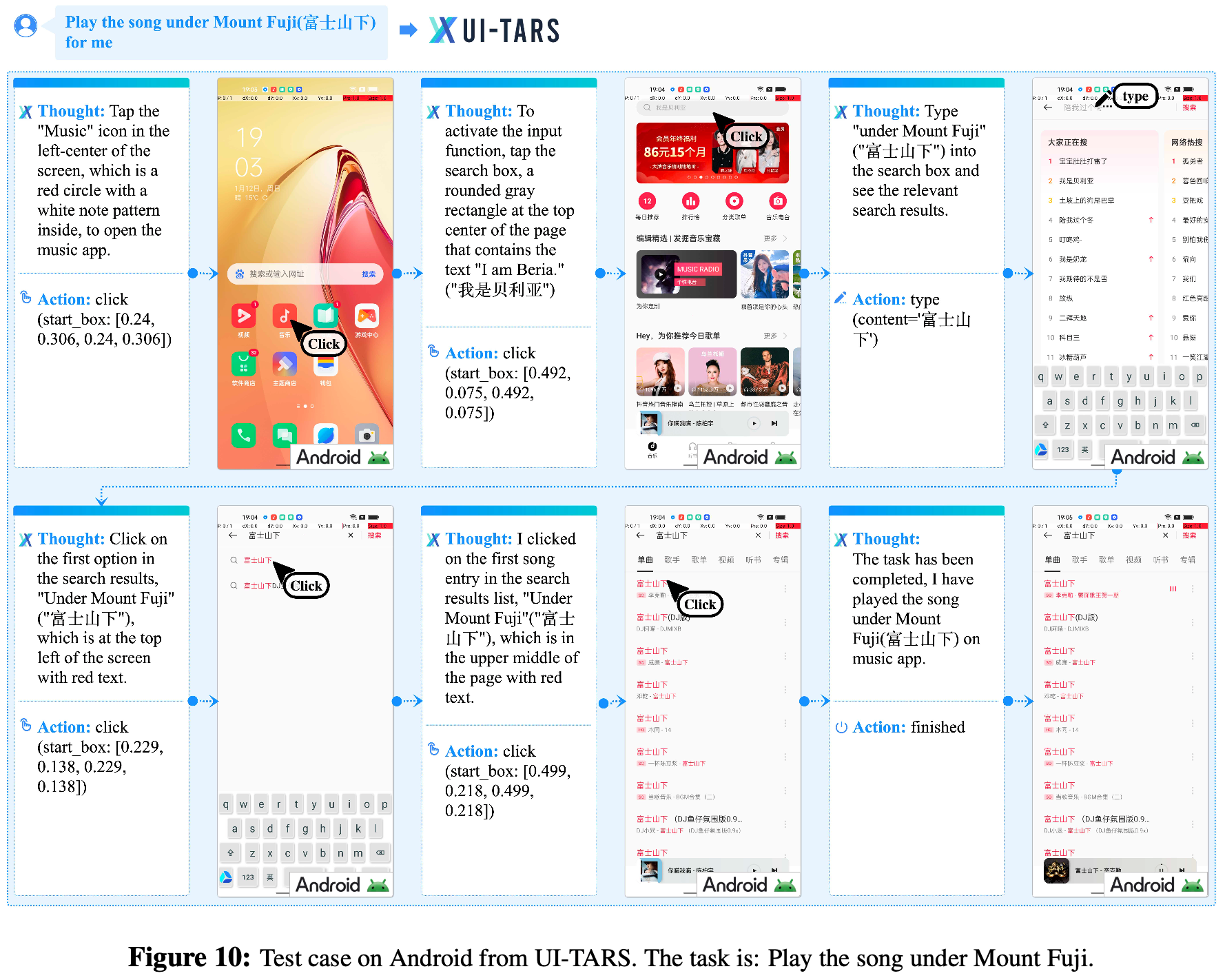
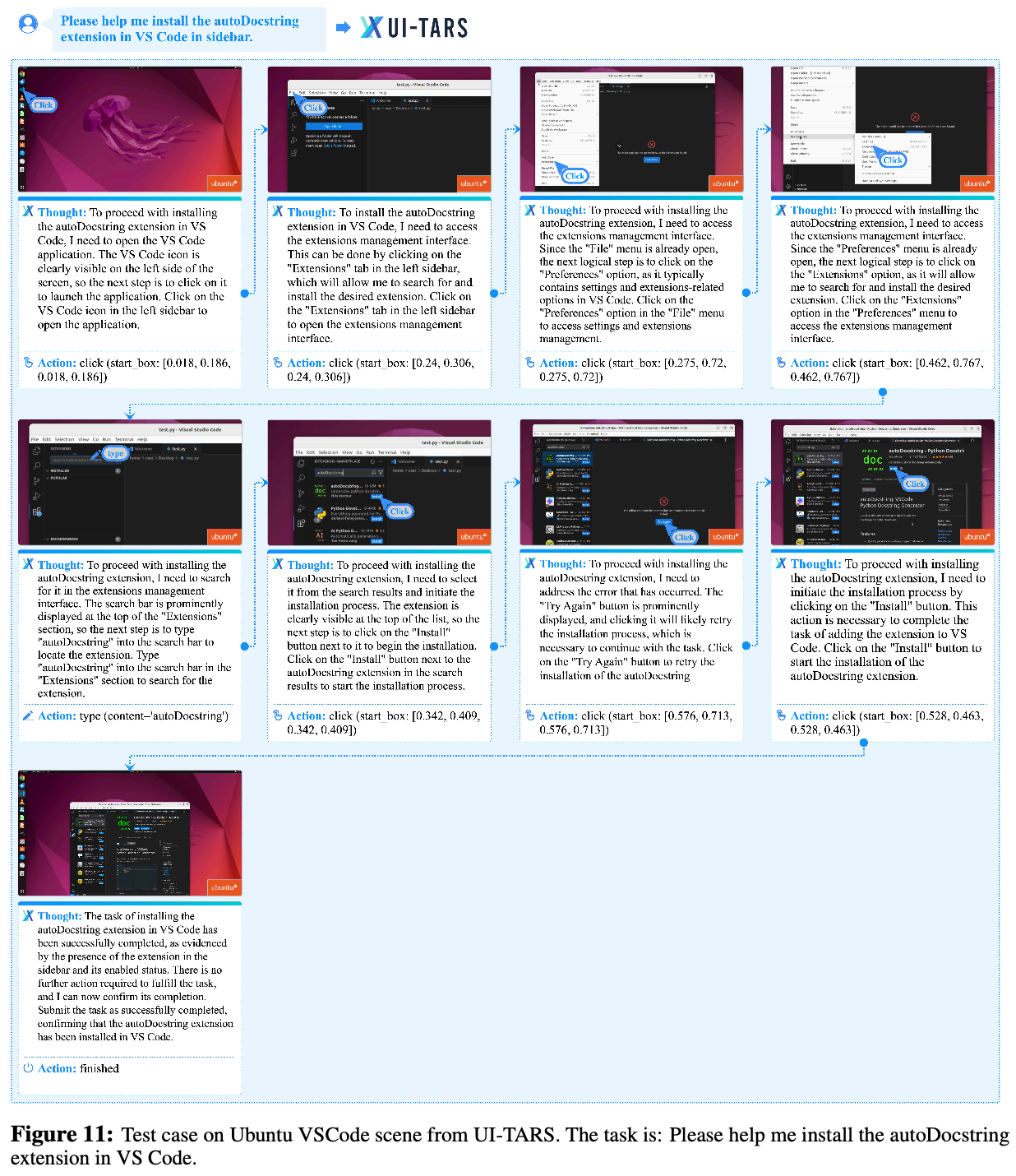
- 论文列出了一些基于 UI-TARS 执行的 Case,详情见下面的图片
- 图9:捕捉颜色并修改 PPT 背景颜色

- 图10:打开 APP 播放歌曲
- 图11:VSCode 安装插件
- 图12:
