注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 论文核心:介绍了一个用于大规模 RL 训练搜索智能体的开源项目 ASearcher
- 论文的贡献包括一个完全异步的智能体 RL 训练系统和一个用于大规模高质量问答对构建的数据合成智能体
- 实验验证 ASearcher 在不同的模型规模和评估设置下均优于 SOTA 开源智能体
- 包括 Qwen2.5-7B、Qwen2.5-14B 的基础模型
- QWQ-32B(基于提示)的 LLM 智能体
- 背景信息:LLM-based LLM 集成了外部工具,在处理复杂的、知识密集型任务方面展现出了卓越的能力
- 在众多工具选择中,搜索工具 (search tools) 在访问海量外部知识方面扮演着关键角色
- 问题提出:
- 但开源智能体在实现专家级的(expert-level)搜索智能 (Search Intelligence)方面仍然存在不足
- 搜索智能 即解决模糊 Query 、生成精确搜索、分析结果并进行彻底探索的能力
- 现有方法在可扩展性、效率和数据质量方面存在缺陷
- 例如,现有 Online RL 方法中的小步数限制(例如 \(\leq 10\))限制了复杂策略的学习
- 但开源智能体在实现专家级的(expert-level)搜索智能 (Search Intelligence)方面仍然存在不足
- 论文的主要贡献包括:
- (1) 可扩展的完全异步 RL 训练 (Scalable fully asynchronous RL training) ,能够在保持高训练效率的同时实现长视野搜索 (long-horizon search)
- (2) 一个基于提示的 LLM 智能体 (prompt-based LLM agent) ,能够自主合成高质量且具有挑战性的问答对 (QA),创建大规模 QA 数据集
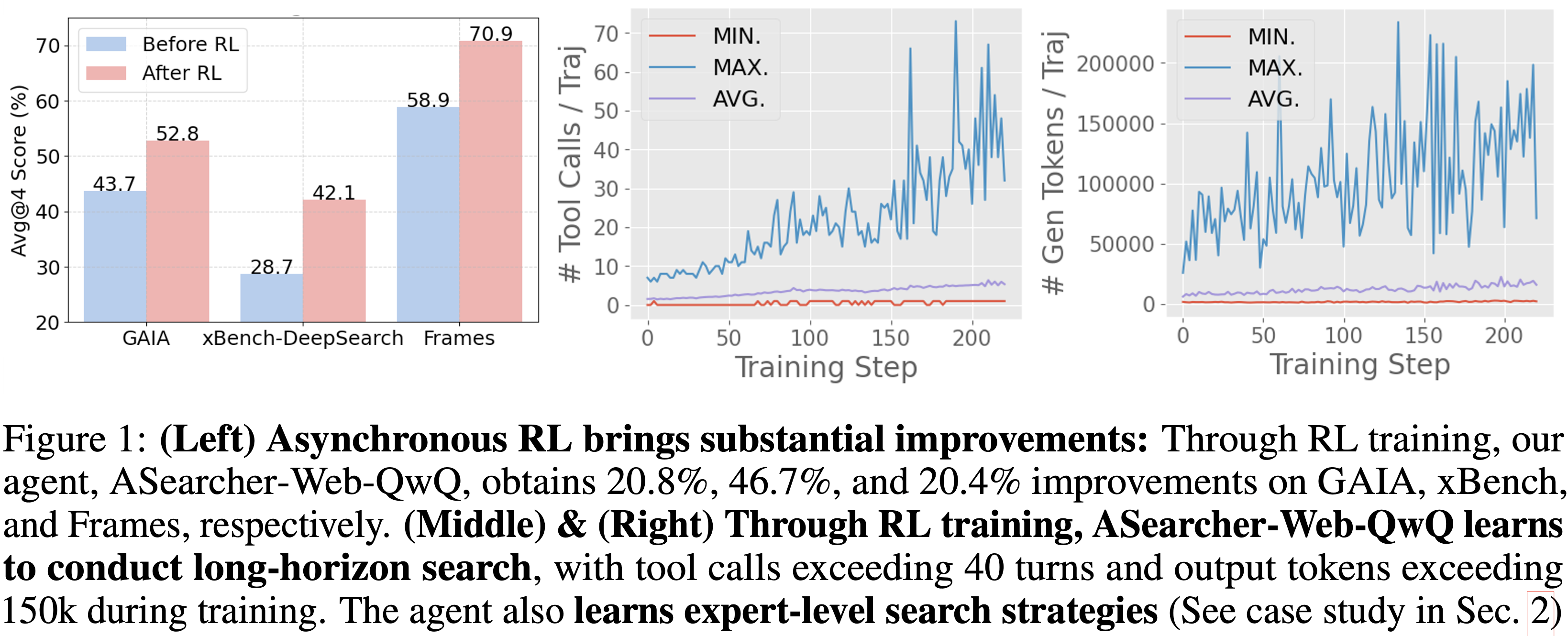
- 通过 RL 训练,论文基于提示的 QwQ-32B 智能体取得了显著改进,在 xBench 和 GAIA 上的 Avg@4 指标分别提升了 46.7% 和 20.8%
- 论文的智能体表现出极长的视野搜索能力,在训练期间工具调用次数超过 40 步,输出 Token 数超过 150k
- 通过简单的智能体设计且无需外部 LLM,ASearcher-Web-QwQ 在 xBench 和 GAIA 上分别取得了 42.1 和 52.8 的 Avg@4 分数,超越了现有的开源 32B 智能体
- 论文已在 github.com/inclusionAI/ASearcher 开源论文的模型、训练数据和代码
Introduction and Discussion
- LLM-based LLM 的最新进展表明
- 通过利用单个或多个外部工具 (2024; 2025;),Agent 在解决复杂的、知识密集型问题方面具有卓越能力
- 其中,搜索工具 (search tools) 尤为关键,它使智能体能够访问海量外部知识以增强问题解决能力 (2023; 2024; 2025)。然而,专家级地使用搜索需要高级智能
- 例如,考虑这个问题:“截至 2024 年 12 月 31 日,中国在 2012 年伦敦奥运会上获得的金牌、银牌和铜牌数量分别是多少?”
- 这个问题看似简单,但实际上具有挑战性,因为网络上存在相互矛盾的答案(例如,“38 金、27 银、22 铜” vs “39 金、31 银、22 铜”)
- 一个搜索智能体必须从不同来源中筛选噪声和矛盾的答案,识别冲突的根本原因(例如官方报告中因兴奋剂检测不合格而被取消资格),并最终确定正确答案
- 例如,考虑这个问题:“截至 2024 年 12 月 31 日,中国在 2012 年伦敦奥运会上获得的金牌、银牌和铜牌数量分别是多少?”
- 具有挑战性的现实世界任务要求智能体能够解决输入 Query 中的高度不确定性、生成精确的搜索 Query 、从海量数据中分析和提取关键见解、解决不一致性并进行深入探索
- 论文将这种高级能力称为 “搜索智能 (Search Intelligence)”
- 专有智能体和模型已经通过大规模 RL 训练 (2025;) 展现出复杂的搜索行为迹象
- 但用于开发搜索智能体的开源方法仍然面临显著限制
- 一系列工作采用强化学习 或监督微调 方法来激励工具使用能力 (2025;)
- 基于提示的 LLM 智能体 (prompt-based LLM agents) 可以在无需训练的情况下执行大量工具调用 (2025;)
- 但在实践中,论文发现现有的 Online RL 方法未能激励复杂且有效的搜索策略
- 论文还发现基于提示的 LLM 智能体可能会因为 LLM 能力不足而失败
- 例如无法从噪声网页中精确提取关键信息,以及无法验证错误结论
- 最近一些工作进一步在基于提示的 LLM 智能体基础上,利用 Offline RL 方法来改进这些智能体 (2025;)
- 但这种 Offline RL 范式在更广泛的领域中被证明表现不如 Online RL (2024; 2021; 2024)
- 在数学和代码等推理任务中,Online RL 使得模型能够基于正确性反馈迭代优化推理过程,从而演化出复杂行为 (2025;)
- 这引出了一个关键问题:Online RL 方法如何有效地在开源智能体中解锁搜索智能?
- 论文识别了两个阻碍搜索智能体有效进行 Online RL 训练的关键障碍:
- 搜索步数不足限制了复杂策略的学习
- 现有工作,例如 Search-R1 (2025),人为限制了搜索步数,例如每条轨迹 \(\leq 10\) 步,这阻止了智能体探索更深的搜索路径
- 但复杂的 Query 通常需要多轮工具调用和多步推理,这在严格的步数限制下无法学习
- 缺乏大规模、高质量的问答对 (question-answer, QA pairs):
- 推理任务的 RL 训练需要丰富、具有挑战性且正确的 QA 对 (2025;)
- 但大多数现有的用于搜索智能体的开源数据集往往过时(例如 HotpotQA)、过于简化或规模太小,无法通过 RL 激发复杂的搜索行为 (2018; 2020; 2025;)
- 搜索步数不足限制了复杂策略的学习
- 为了应对这些挑战,论文提出了 ASearcher,一个旨在为搜索智能体实现大规模智能体 RL 训练 (large-scale agentic RL training) 的开源项目。论文的贡献包括:
- 通过完全异步智能体 RL 训练实现长视野搜索
- 在批生成 RL 训练系统 (2025;) 中设置较大的步数限制时,批次内的长轨迹很容易导致显著的闲置时间,从而减慢整个训练过程
- 基于 AREaL (2025),论文的完全异步系统通过将轨迹执行与模型更新解耦,避免了长轨迹阻塞训练
- 这允许放宽步数限制(例如,128 步/轨迹),使得智能体能够在不牺牲训练效率的情况下探索更深的搜索路径
- 论文的智能体 ASearcher-Web-QwQ 实现了极长的视野搜索,在 RL 训练期间工具调用次数超过 40 步,生成的 Token 数超过 150k
- 一个可扩展的 QA 合成智能体
- 论文设计了一个 LLM-based 智能体,能够自主生成需要多轮工具使用的具有挑战性、不确定性和事实依据的 (challenging, uncertain, and grounded) QA 对
- 从种子问题开始,该智能体通过模糊关键信息或注入外部事实来迭代地模糊查询 (fuzzes queries) 以增加复杂性
- 每个构建的问题都经过多阶段验证 (multistage validation) 以确保质量和难度
- 论文从 14k 个种子 QA 中生成了 134k 个高质量样本,其中 25.6k 个需要借助外部工具来解决
- 通过完全异步智能体 RL 训练实现长视野搜索
- 使用 ASearcher,论文在两种设置下训练配备搜索引擎和浏览器的智能体:
- 从基础模型开始进行 RL 训练 (Qwen2.5-7B/14B),以证明论文的训练流程能够激励强大且可泛化的搜索策略;
- 微调由强大 LRM (QwQ-32B) 驱动的基于提示的智能体 ,以验证论文的训练流程在微调大规模基于提示的 LLM 智能体时的可扩展性
- 论文在多跳 QA 基准测试和具有挑战性的基准测试上评估论文的智能体
- 包括 GAIA (2023)、xbench-DeepSearch (2025) 和 Frames (2024)
- 仅使用本地知识库训练的 ASearcher-Local-7B/14B,在现实的网络搜索中展现出惊人的泛化能力,并在多跳和单跳 QA 任务上达到了 SOTA 性能
- 基于 QwQ-32B 构建的 ASearcher-Web-QwQ 在 xBench-DeepSearch 和 GAIA 上分别取得了 42.1 和 52.8 的 Avg@4 分数,超越了一系列开源智能体
- 在评估 Pass@4 时,ASearcher-Web-QwQ 在 GAIA 和 xBench-DeepSearch 上分别达到了 70.1 和 68.0
- 通过 RL 训练,ASearcher-Web-QwQ 在 xBench-DeepSearch 和 GAIA 上分别获得了 46.7% 和 20.8% 的提升
- ASearcher 提出了一个面向基于 LRM 和 LLM 的搜索智能体的大规模开源在线智能体 RL 流程,通过可扩展的训练和高质量的数据解锁了搜索智能
- 希望论文的发现不仅能推动搜索智能体的发展,也能为面向复杂现实世界任务的 LLM 智能体带来更广泛的创新启发
Limitations of Existing Open-source Approaches
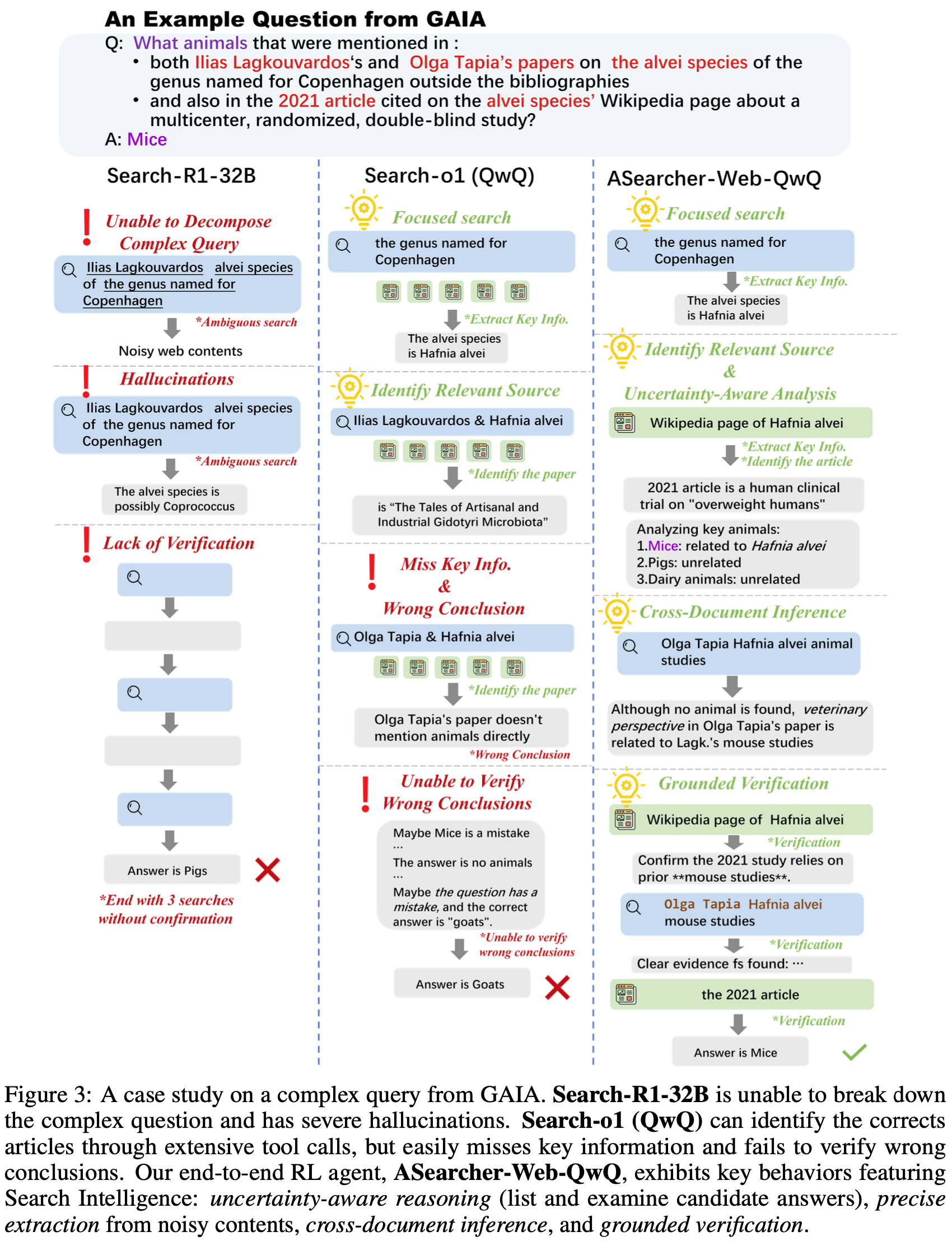
- 在本节中,论文针对一个来自 GAIA (2023) 的极具挑战性的问题进行了详细的案例研究
- 具体来说,论文在图 3 中分析了 Search-R1-32B (2025) 和 Search-o1 (QwQ) (2025)
- 详细的轨迹在附录 A 中提供
- 详细的轨迹在附录 A 中提供
Solution Path of the Sample Question
- 在图 3 中,论文的案例研究针对一个需要找到具有 4 个未知变量 的特定动物的问题
- 为了识别正确答案,搜索智能体应首先根据条件“以哥本哈根命名的属 (genus named for Copenhagen)”找出所提及的物种
- 根据该物种维基百科页面上的引文识别正确的 2021 年文章,然后找出两位提及人物的论文
- 最终,正确答案应通过交叉引用 2021 年的文章和论文来确定;总而言之,这个例子具有挑战性的原因有几个:
- 高不确定性 (High Uncertainty): 问题涉及多个未知变量,这些变量可能指向许多不同的实体
- 例如,“2021 年的文章”可能指向 2021 年发表的任何文章,并且只能通过检查 肺泡物种 (alvei species) 维基百科页面中的“多中心、随机、双盲研究 (multicenter, randomized, double-blind study)”来确定
- 需要精确的信息提取 (Requirement for Exact Information Extraction): 为了找到答案,智能体应列出网页上提到的所有动物并进行跨文档比较
- 这要求智能体从海量、充满噪声的网页内容中精确提取关键信息,而不是简单地总结网页
- 误导性答案 (Misleading Answers): 在解决此任务的过程中,可能会出现多个误导性答案(例如“猪 (pigs)”)
- 智能体应通过检查所有相关网页和文档中的预期答案来严格验证其结论
- 高不确定性 (High Uncertainty): 问题涉及多个未知变量,这些变量可能指向许多不同的实体
- 现有 Online RL 方法未能学习复杂搜索策略 (Existing Online RL Approaches Fail to Learn Complex Search Strategies)
- 在图 3 中,Search-R1-32B 无法将复杂 Query 分解为单个组成部分,因此只能进行涉及太多未知信息的模糊 Query
- 该智能体还存在严重的幻觉 (hallucinations),产生了搜索结果不支持结论
- 最后,它未能解析所有未知信息
- 这个案例研究表明,现有的 Online RL 方法仅能激励初级的搜索策略
- 同样值得注意的是,由于在训练期间步数限制被设置为一个较小的值(例如 4 步)该模型仅表现出较短的工具使用视野
- 在图 3 中,Search-R1-32B 无法将复杂 Query 分解为单个组成部分,因此只能进行涉及太多未知信息的模糊 Query
- 基于提示的 LLM 智能体可能因 LLM 能力不足而失败 (Prompt-based LLM Agents Could Fail Due to Insufficient Capability of the LLM)
- 在图 3 中,Search-o1 (QwQ) 可以通过大量工具调用找到物种名称,以及 2021 年的文章和相关论文
- 但在试图寻找答案时,Search-o1 (QwQ) 很容易遗漏关键信息,从而得出错误的结论
- 即使智能体找到了直接指向正确答案的信息,它仍然会被先前错误的结论所误导
- 最后,该智能体无法验证先前结论的正确性
- 这个案例研究揭示,尽管一个未在智能体任务上明确训练的开源模型可以执行大量的工具调用 ,但它无法基于检索到的内容和历史上下文进行专家级的推理
- ASearcher-Web-QwQ (论文端到端 RL 智能体 ASearcher-Web-QwQ 的搜索策略)
- 如图 3 所示,ASearcher-Web-QwQ 将复杂 Query 分解为精确的 Query
- 与 Search-o1 (QwQ) 在每次搜索 Query 后访问大量网站不同,ASearcher-Web-QwQ 专注于一次访问一个网站
- 问题:这样会不会太慢
- ASearcher-Web-QwQ 总结了网站的所有相关信息
- 所有候选答案都被列出并由智能体仔细分析
- 当搜索结果没有直接指向期望目标时,例如,当使用“Olga Tapia Hafnia alvei animal studies”进行搜索以查找与 Olga Tapia 论文相关的动物时,智能体没有获得明确的信息,但能够通过与其他论文建立联系来推断出正确答案
- 在找到正确答案“小鼠 (Mice)”后,智能体在报告最终答案之前花费了额外的步数来验证先前的结论
- 总之,ASearcher 成功训练出了一个展现出专家级搜索行为的搜索智能体 :
- 不确定性感知推理 (Uncertainty-aware reasoning): 智能体详尽地列出并检查所有不确定实体的可能性
- 精确的关键信息提取 (Precise Key Information Extraction): 智能体能够从海量、充满噪声的网页内容中识别关键信息
- 跨文档推理 (Cross-document Inference): 智能体能够通过建立多个文档之间的联系来推断关键结论
- 基于事实的验证 (Grounded Verification): 智能体通过访问或搜索相关材料来验证先前结论的正确性
- 如图 3 所示,ASearcher-Web-QwQ 将复杂 Query 分解为精确的 Query
ASearcher
- 论文提出了 ASearcher,一个通过大规模 RL 训练来解锁搜索智能(Search Intelligence)的开源项目
- 如图 3 所示,ASearcher 训练了一个能够通过彻底解决所有不确定性并执行多轮工具调用来解决复杂问题的搜索智能体
- 在后续的小节中,论文将介绍 ASearcher 中的智能体设计、训练数据及数据合成智能体,以及完全异步的强化学习训练
Agent Design
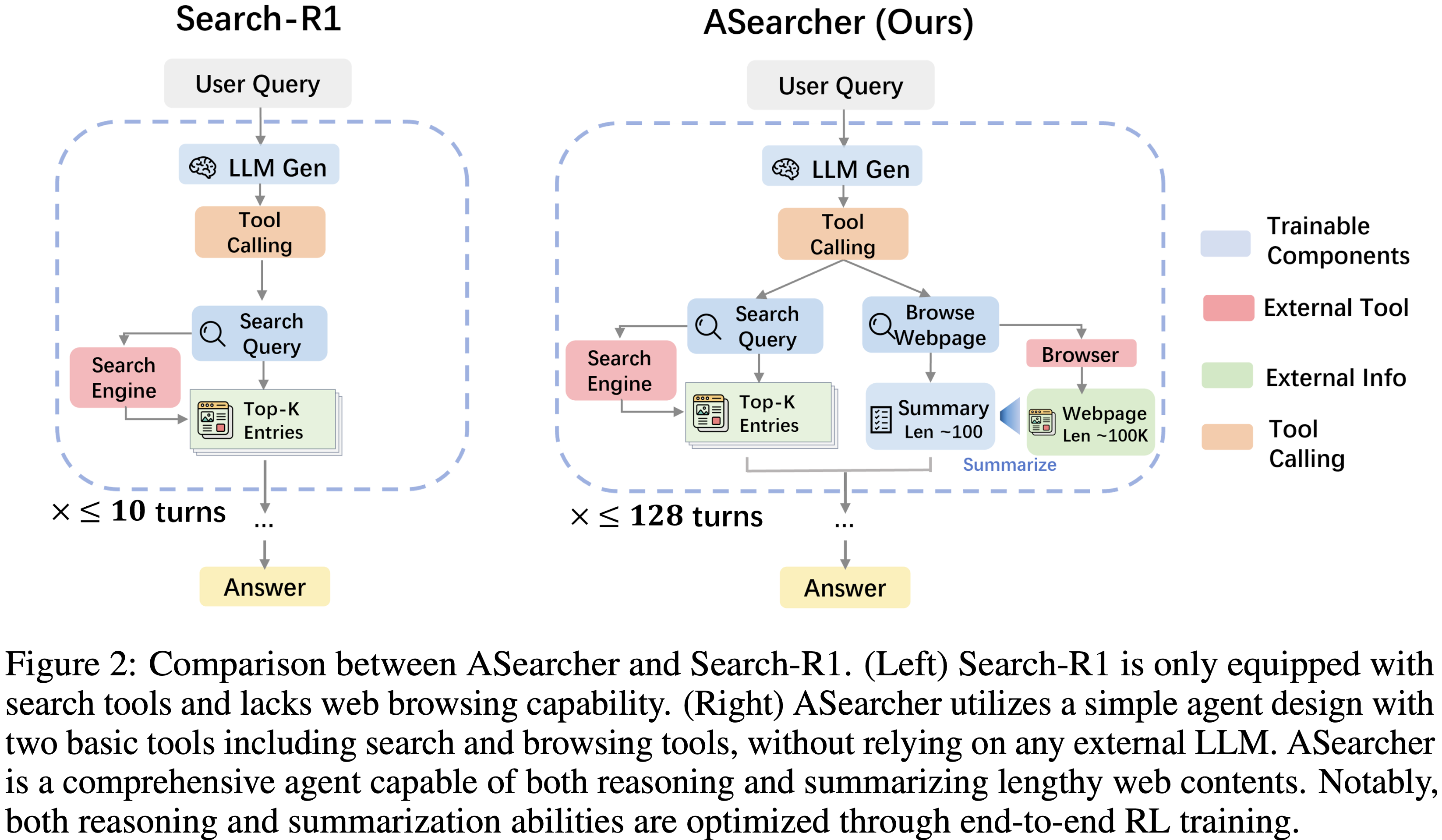
- 论文在 ASearcher 中采用了一种简单的智能体设计,如图 2 所示
- 工具 (Tools).
- 给定一个用户 Query ,智能体可以使用两个基本工具:一个搜索引擎和一个网络浏览器
- 搜索引擎:接收文本 Query 作为输入,并返回相关的摘要片段及其对应的 URL
- 网络浏览器:接收一个 URL 并返回网页的内容
- 为了有效解决复杂问题,模型应策略性地结合这些工具,并从海量数据中提取关键信息
- 给定一个用户 Query ,智能体可以使用两个基本工具:一个搜索引擎和一个网络浏览器
- 网页摘要 (Webpage Summarization).
- 网页可能包含过长的内容,因此论文利用智能体将网页总结成一个简洁的摘要
- 在训练时,这个摘要过程也会被优化,允许智能体通过强化学习训练来提高摘要能力
- 使用基础 LLM 和高级 LRM 实例化 ASearcher (Instantiating ASearcher with Base LLMs and Advanced LRMs).
- 在 ASearcher 框架内,论文研究了两种搜索智能体的具体实例化方式:
- 一种是使用基础大语言模型(Base LLMs) ,例如 Qwen2.5-7B/14B;
- 另一种是使用高级大推理模型(Large Reasoning Models, LRMs) ,例如 QwQ-32B
- 这两种不同类型的实例化在历史管理和提示(Prompting)方面需要不同的设计选择
- 对于基础 LLM ,论文遵循先前的工作 (2025;),采用仅追加(append-only)风格的提示方式
- 从一个系统提示(System Prompt)开始,所有由 LLM 生成的响应、搜索结果和网页摘要都被追加到历史记录中
- 智能体按时间顺序接收完整的历史记录作为输入,并输出一些推理文本和动作。
- 这种方法确保了推理时的效率
- 对于LRM ,LRM 本身已经具备了指令跟随能力
- 论文使用不同的提示来指导 LRM 进行工具选择、摘要和回答
- 论文还注意到 LRM 通常会生成长响应,有时历史记录会很长
- 问题:需要确保输入的紧凑性,以保证 LRM 有足够的预算来生成 Token
- 解法:在历史记录中,丢弃思维过程,而是保留总结后的想法和工具调用
- 在提示 LRM 时,只将最近 25k 个字符的历史记录作为附加上下文提供给 LRM
- 这些简单的设计确保了 LRM 的输入最多为 10k 个 Token
- 问题:25k 不是已经比 10k 大了吗?
- 对于基础 LLM ,论文遵循先前的工作 (2025;),采用仅追加(append-only)风格的提示方式
- 在 ASearcher 框架内,论文研究了两种搜索智能体的具体实例化方式:
- 端到端强化学习 (End-to-End Reinforcement Learning).
- 智能体所有由 LLM 生成的响应,包括思维过程、工具调用和摘要,都是以端到端的方式使用强化学习进行训练的
Training Data
- 论文的训练数据主要有两个来源
- 开源数据集:仔细筛选,以确保其难度和质量
- 合成数据:高质量的问答对(Question-Answer pairs, QA pairs),专门设计用于指导智能体学习可泛化的搜索策略
开源数据 (Open-source Data).
- 论文从 HotpotQA (2018) 和 2WikiMultiHopQA (2020) 的训练集开始,这两个都是多跳问答数据集
- 论文采用了基于模型的过滤流程
- 使用 RL 在完整的开源数据集上训练一个模型,再使用训练好的模型为每个问题生成 16 个响应
- 最后,论文过滤掉满足以下任一标准的问题:
- 模型在 16 个响应中未能找到一个正确答案
- 模型达到了 \(\ge\) 50% 的准确率,意味着问题挑战性不足
- 模型仅用少量搜索轮次(即 \(\le\) 1 轮)就找到了正确答案
- 这种过滤方法确保论文只保留最具挑战性但又可解决、且需要使用工具的问题
- 最终,从总共 304k 个问答对中 ,论文保留了 16k 个具有挑战性的样本用于 RL 训练
- 此外,论文还纳入了一组专为访问特定网页而设计的问答对
- 特别是,论文加入了 WebWalkerQA (2025) 的一小部分子集,以帮助模型学习如何在嘈杂的真实网络搜索环境中定位答案
Data Synthesis Agent
- 论文进一步开发了一个数据合成智能体来创建高质量的问答对
- 如图 4 所示,数据合成智能体从一个种子问题开始,迭代地修改问题以增加复杂性
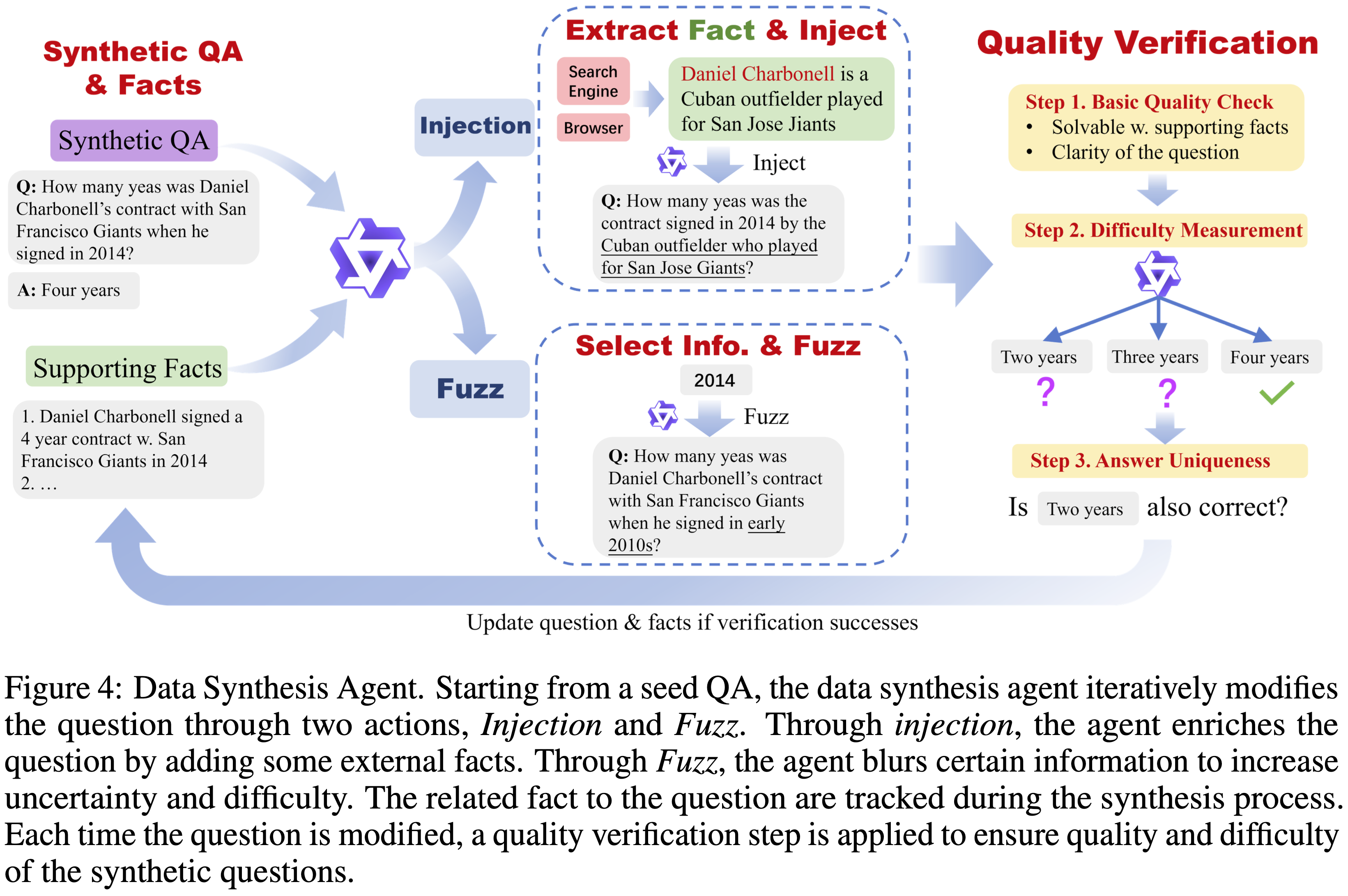
- 为了确保合成的问题与可靠来源严格对齐,在问题合成过程中获得的一系列支持事实(supporting facts)被保留下来,并持续更新以进行质量验证
- 在每一步,给定当前的问题和一个支持事实列表,智能体自动在以下两个关键动作之间进行选择:
- 动作 1:注入(Injection) 旨在通过插入与问题相关的事实来丰富问题的上下文
- 智能体首先选择问题中的一个实体,然后从外部来源(如维基百科)获取关于该选定实体的一条相关事实
- 接着,通过将该事实注入到问题中,提出一个新的问题
- 这个注入动作增加了问题的复杂性
- 动作 2:模糊化(Fuzzing) 模糊问题中的某些细节,以增加问题的不确定性水平
- 例如,“Catskill Mountain Railroad”(Catskill 山铁路)可能被替换为 “a historic mountain railway”(一条有历史意义的铁路)
- 通过多次对问题进行模糊化处理,问题的不确定性水平和难度都会逐渐增加
- 动作 1:注入(Injection) 旨在通过插入与问题相关的事实来丰富问题的上下文
- 为了确保合成问题的高质量并精确评估其难度,论文为评估合成问题加入了一个严格的质量验证(quality verification)阶段:
- 步骤 1. 基本质量(Basic Quality). 论文使用一个 LLM 来评估每个问题的基本质量
- 此验证包括检查问题的清晰度,并根据支持事实验证问答对的准确性
- 此质量控制步骤确保每个问答对都正确地基于可靠来源
- 步骤 2. 难度测量(Difficulty Measurement). 论文使用一个前沿的 LRM(例如 QwQ-32B)直接为合成问题生成多个答案,而不使用任何外部工具
- 此验证过程也作为问题难度的衡量标准
- 步骤 3. 答案唯一性(Answer Uniqueness). 模糊化动作可能会过度放松约束,损害答案的唯一性
- 为了防止因多个正确答案而产生的歧义,论文评估在难度测量步骤中生成的任何 mismatched answers 是否可以作为替代的有效答案
- 步骤 1. 基本质量(Basic Quality). 论文使用一个 LLM 来评估每个问题的基本质量
- 论文在表 1 中提供了两个说明性示例。从一个简单的问题开始,注入动作用相关的事实细节替换特定的实体
- 例如,“Michael P. Hein” 被扩展为 “who served as the first County Executive of Ulster County, New York…”
- 模糊化动作通过泛化精确信息来引入模糊性,例如将确切的年份 “1934” 替换为 “the early 1930s”,或者将 “Catskill Mountain Railroad” 替换为 “a historic mountain railway”
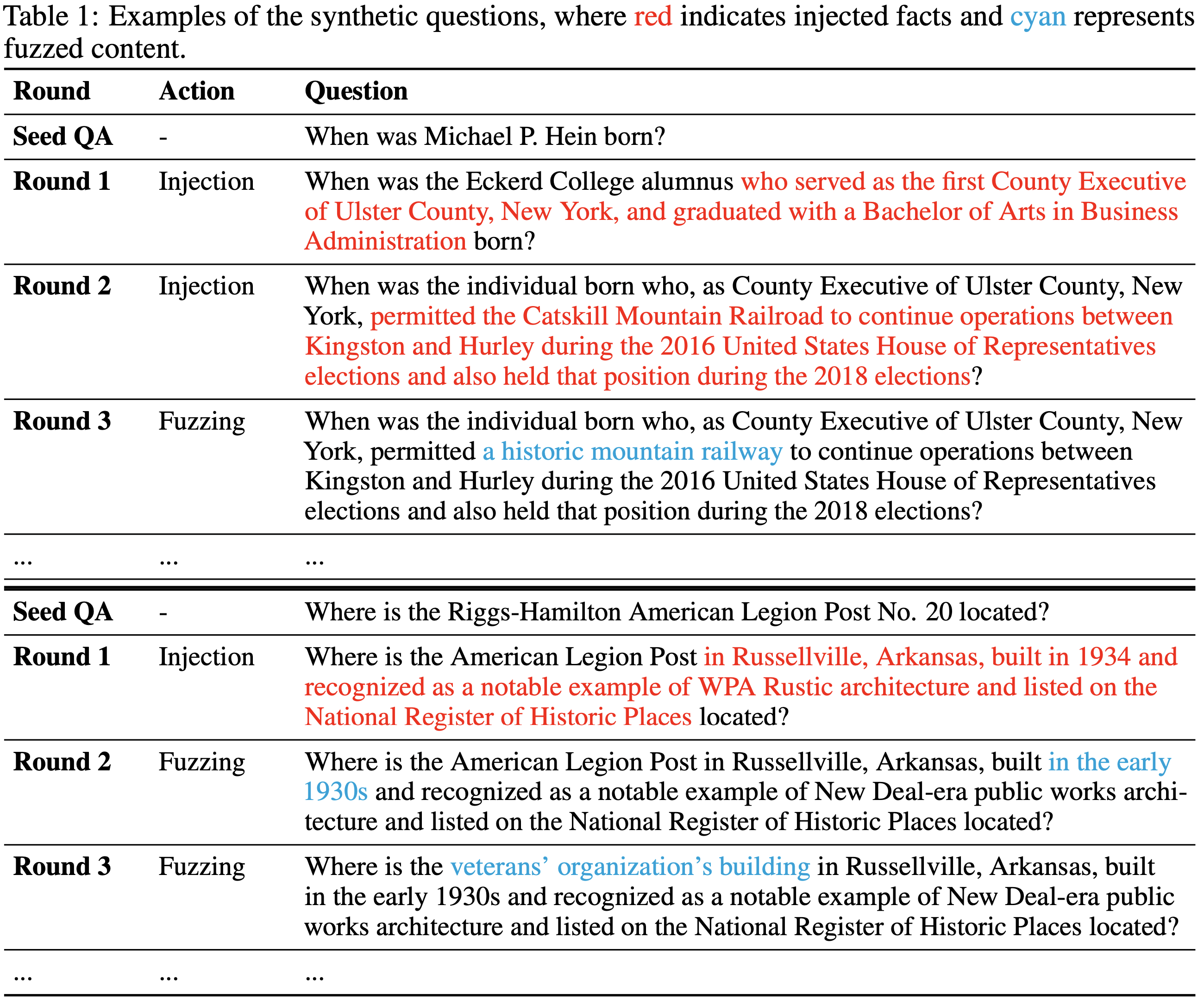
- 通过迭代的注入和模糊化,数据合成智能体产生出涉及复杂信息和高不确定性的问题,需要大量的搜索和推理才能找到正确答案
- 在完成问题合成过程后,论文过滤掉那些 LRM 可以不依赖搜索工具直接生成正确答案的问题
- 由于这些问题仅基于模型的内在知识就能回答,它们对于增强搜索能力几乎没有价值
- 从 14,107 个种子问题开始,论文对每个问题平均执行了 6.3 次注入和 3.2 次模糊化
- 从合成池中,论文为每个种子问题最多选择三个高质量的变体
- 这个筛选过程产生了包含 25,624 个条目的最终数据集,所选问题平均每个包含 4.27 次注入和 2.10 次模糊化
Asynchronous Agentic RL Training
Challenges of Scaling Up Trajectory Length in RL
- 实验表明复杂任务需要大量的工具调用,因此具有较大轮次限制的 RL 训练对于训练高级搜索智能体是必要的
- 训练期间轨迹执行时间的方差很大,这可能导致批量生成 RL 系统出现显著的闲置时间
- 复杂任务需要长轨迹 (Complex Tasks Require Long Trajectories).
- 智能体任务通常需要大量的 LLM 生成和多次工具调用来解决复杂问题,导致轨迹执行时间延长
- 如图 6(左)所示,论文在 GAIA (2023)、xBench-Deepsearch (2025) 和 Frames (2024) 上评估了论文经过 RL 训练的 QwQ-32B 智能体,强制智能体使用不同最小轮次数量的工具
- 结果表明,准确率随着轮次的增加而提高,证实了复杂任务需要更长的轨迹来进行有效的问题解决
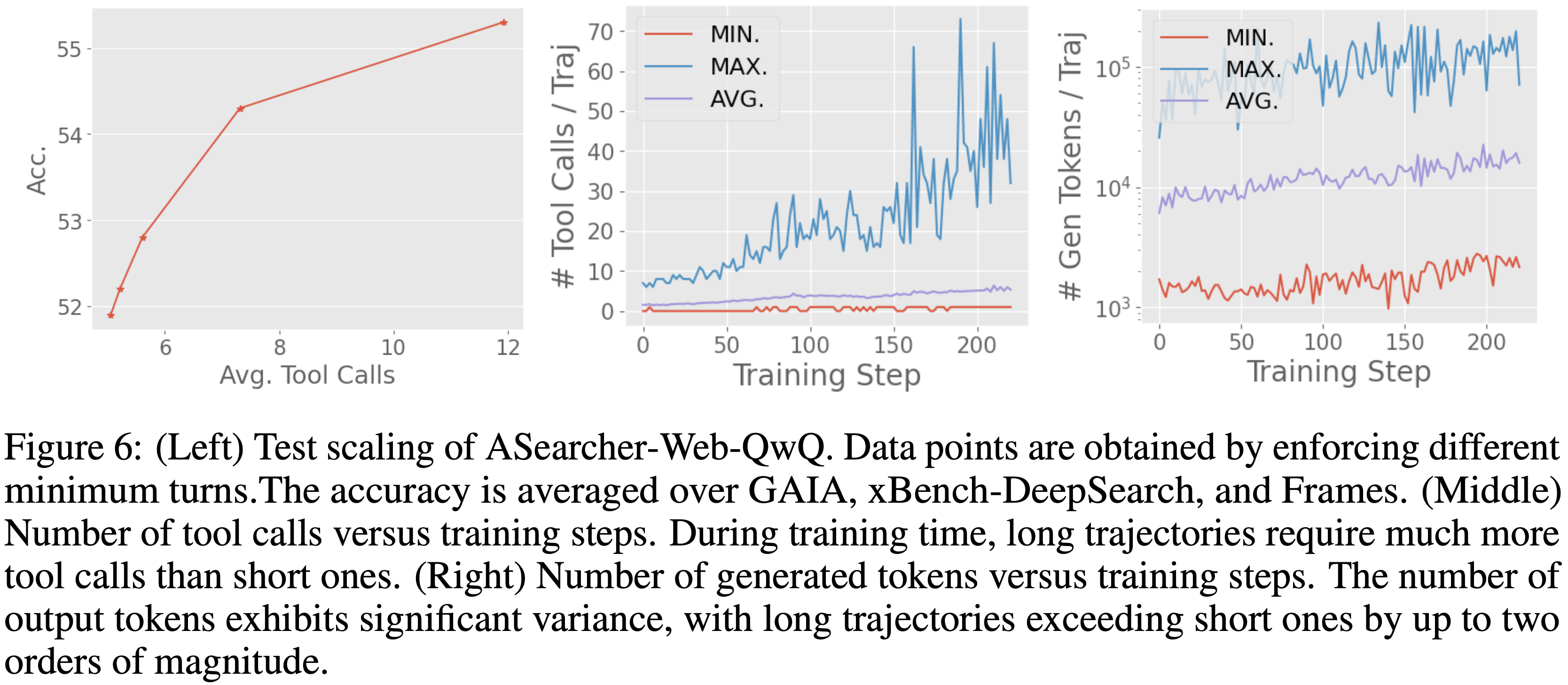
- 轨迹执行时间的高方差 (High Variance in Trajectory Execution Time).
- 长轨迹也带来了执行时间的显著方差
- 论文分析了 QwQ 智能体 RL 训练期间的工具调用次数和 Token 生成数量(图 6),观察到最长的轨迹可能比短轨迹多出数十次工具调用和两个数量级以上的 Token
- 这种差异导致每个轨迹的运行时间高度不可预测,进一步降低了训练效率
- 智能体 RL 训练的效率问题 (Efficiency Issues of Agentic RL Training).
- 长时间的执行和高运行时间方差都会降低 RL 训练效率
- 论文以 one-step-off RL 训练系统 (one-step-off RL training system,也称为 One-Off,来自 DeepCoder,2025) 作为批量生成 RL 系统的代表性例子
- 在 one-step-off RL 训练中,第 N 步的训练和第 N+1 步的轨迹生成是并发执行的
- 如图 7 所示,尽管该系统将轨迹 rollout 与模型训练重叠,但批量生成仍然受限于最慢的轨迹(例如轨迹 7),导致 GPU 闲置时间和利用率不足
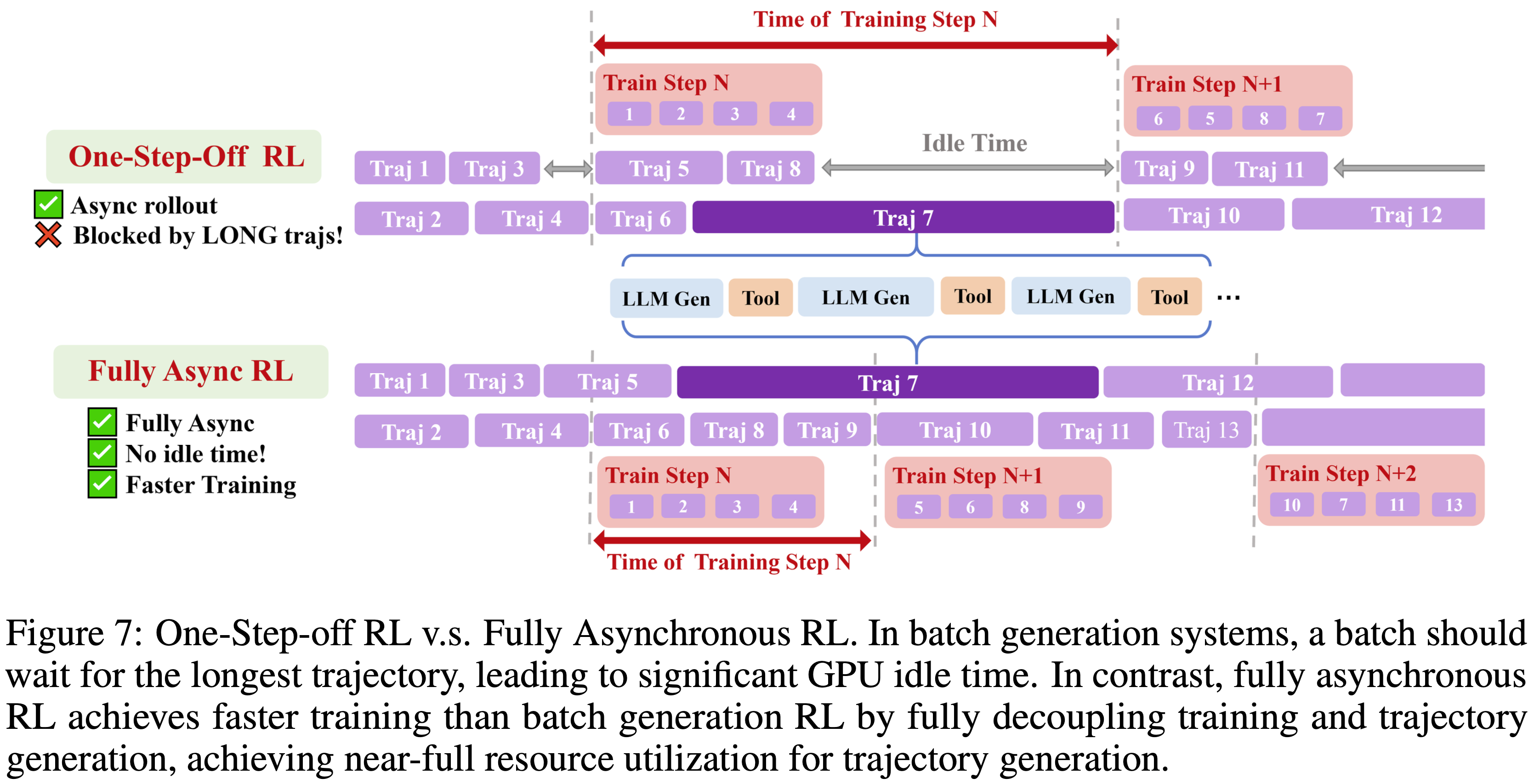
完全异步 RL 训练 (Fully Asynchronous RL Training).
- 为了确保高效的智能体 RL 训练,论文采用了完全异步的训练范式
- 论文的方法在两个不同方面引入了异步
- 异步轨迹 Rollout (Asynchronous Trajectory Rollouts).
- 轨迹 rollout 是并行收集的,并且不直接相互干扰
- 每个轨迹独立地向相应服务器发送工具调用请求,并向 LLM 推理引擎发送 LLM 生成请求
- 来自不同轨迹的并发请求由服务器自动处理
- 完全独立的轨迹执行确保了一个轨迹在生成 LLM 响应和等待工具调用响应时不需要等待其他轨迹,从而提高了训练效率
- 解耦的 Rollout 和训练 (Decoupled Rollout and Training).
- 除了异步 rollout 之外,轨迹 rollout 和模型更新也是完全解耦的
- 在图 7 中,论文将论文的完全异步 RL 训练与 one-step-off RL 训练进行了比较,后者在批次内利用异步 rollout
- 在完全异步 RL 训练中,长轨迹不会阻塞生成,并且可以跨越多个版本,显著减少了 GPU 闲置时间,并在生成过程中实现了近乎完全的 GPU 利用率
- 在训练侧,一旦收集到足够的轨迹形成一个批次,就会立即启动一个训练步骤
- 如图 7 所示,训练过程不会等待极长的轨迹 7,而是继续处理轨迹 9
Training Details
- MDP 公式化 (MDP Formulation). 论文遵循马尔可夫决策过程(Markov Decision Process, MDP)的公式化
- 形式上,一个 MDP 由元组 \((S,A,T,R)\) 定义
- \(S\) 代表状态空间,通常包含历史记录、搜索结果和检索到的网页
- \(A\) 表示动作空间,一个动作包括智能体生成的 Token
- 一些工具调用可以通过特定的标签从动作中提取,例如
<search> search query </search>
- 一些工具调用可以通过特定的标签从动作中提取,例如
- \(T(s^{\prime}|s,a)\) 是转移概率:其中 \(s^{\prime}\) 是在状态 \(s\) 应用动作 \(a\) 中的工具调用后的更新状态
- 在每个时间步,智能体接收一个状态 \(s_{t}\),并根据策略 \(\pi:S\to A\) 生成一个动作 \(a_{t}\)
- 智能体的目标是最大化回报
$$ J(\pi)=\mathbb{E}\left[\sum_{t=0}^{\infty}R(s_{t},a_{t})\bigg{|}a_{t}\sim\pi(s_{t})\right]$$
- 形式上,一个 MDP 由元组 \((S,A,T,R)\) 定义
- GRPO 训练 (GRPO Training). 论文采用 GRPO (2024) 算法来训练搜索智能体
- 对于每个输入问题 \(x\),生成 \(G\) 个轨迹 \(\tau_{1},\tau_{2},\cdots,\tau_{G}\)
$$ \tau_{i}=(s^{i}_{0},a^{i}_{0},s^{i}_{1},\cdots,s^{i}_{T_{i} }) $$ - 为了优化智能体,论文采用以下损失函数:
$$
\begin{align}
\mathcal{J}_{GRPO}(\theta)=\mathbb{E}_{x\sim\mathcal{D}_{\epsilon}\{\tau_{i}\}_{i=1}^{G}\sim\pi_{\theta_{old} }(:\left|x\right\rangle}\left[\frac{ 1}{G}\sum_{i=1}^{G}\frac{1}{\sum_{t=0}^{T_{i}-1}|a^{i}_{t}|}\sum_{t=0}^{T_{i}-1}\sum_{j=1}^{|a^{i}_{t}|}\min\left(\frac{\pi_{\theta}(a^{i}_{t,j}|s_{t},a^{i}_{t,< j})}{\pi_{\theta_{old} }(a^{i}_{t,j}|s_{t},a^{i}_{t,< j})}\hat{A}_{i},\right.\right. \left.\left.\text{clip}\Bigg{(}\frac{\pi_{\theta}(a^{i}_{t,j}|s_{ t},a^{i}_{t,< j})}{\pi_{\theta_{old} }(a^{i}_{t,j}|s_{ t},a^{i}_{t,< j})},1-\epsilon ,1+\epsilon \Bigg{)}\hat{A}_{i}\Bigg{)}\right]\right.
\end{align} \tag{1}
$$- 其中 \(\epsilon\) 是一个超参数,\(\hat{A}_{i}\) 是第 \(i\) 个轨迹的优势函数(Advantage),基于每个组内所有轨迹的相对奖励计算得出
- 对于每个输入问题 \(x\),生成 \(G\) 个轨迹 \(\tau_{1},\tau_{2},\cdots,\tau_{G}\)
- 动态过滤 (Dynamic Filtering). 为了提高训练效率,论文实施了动态过滤,以排除缺乏有意义的训练信号的 Query
- 具体来说,论文移除所有响应产生相同奖励(导致优势为零)的 Query ,包括智能体已经达到高准确率的 Query 和答案标记错误的 Query
- 奖励函数 (Reward Function). 对于奖励函数,论文采用稀疏奖励(Sparse-reward)设置,在轨迹完成时计算奖励
- 若从基础 LLM 开始训练 ,奖励函数通过乘法结合了格式奖励(Format Reward)和 F1 分数
- 问题:这里的 F1 分数是什么?是工具调用相关 精确率 和 召回率 的衡量吗?
- 回答:从下文来看,是的
- 若基于 LRM 的智能体(例如 QwQ)进行微调,论文使用 LLM-as-Judge (2023; 2024) 作为奖励函数,并省略格式奖励,因为这些模型本身就保持了适当的输出格式
- 若从基础 LLM 开始训练 ,奖励函数通过乘法结合了格式奖励(Format Reward)和 F1 分数
Experiments
Experiment Setup
- 基准测试 (Benchmarks)
- 论文首先在单跳和多跳问答任务上评估智能体
- 对于单跳问题,论文使用 Natural Questions (2019)、TriviaQA (2017) 和 PopQA (2022)
- 对于多跳问题,论文使用 HotpotQA (2018)、2WikiMultiHopQA (2020)、MuSiQue (2022) 和 Bamboogle (2022)
- 论文进一步在更具挑战性的基准测试上进行了评估,包括 Frames (2024)、GAIA (2023) 和 xBench-DeepSearch (2025) 作为额外的测试集
- 从 HotpotQA、2WikiMultiHopQA 和 MuSiQue 的验证集中随机抽取 1000 个实例进行评估
- 对于 Bamboogle、Frames、GAIA 和 xBench-DeepSearch,论文使用其完整的测试集
- 对于 GAIA,论文使用来自纯文本验证子集 (2025) 的 103 个示例
- 论文首先在单跳和多跳问答任务上评估智能体
- 搜索工具 (Search Tools)
- 论文在两种设置下评估搜索智能体,每种设置使用不同类型的搜索工具
- 带有 RAG 的本地知识库 (local knowledge base with RAG)的交互:智能体与本地部署的 RAG 系统交互,从一个 Wikipedia 2018 语料库 (2020) 中检索相关信息
- 基于网络的搜索和浏览 (web-based search and browsing) 的交互:智能体在交互式网络环境中运行,可以访问搜索引擎和浏览器工具
- 对于更具挑战性的基准测试 GAIA、xBench-DeepSearch 和 Frames,论文仅在此基于网络的设置下进行评估
- 论文在两种设置下评估搜索智能体,每种设置使用不同类型的搜索工具
- 基线 (Baselines)
- 论文考虑与两类基准测试相对应的两组基线
- 对于多跳和单跳问答基准测试,包括 Search-R1(7B/14B/32B) (2025)、R1-Searcher(7B) (2025)、Search-o1(QwQ-32B) (2025)、DeepResearcher (2025) 和 SimpleDeepSearcher (2025)
- 还直接提示 Qwen-2.5-7B/32B 在不使用任何工具的情况下生成答案
- 在更具挑战性的基准测试上,论文与强大的 32B 规模模型进行比较,包括直接使用 QwQ-32B 生成、Search-o1(QwQ-32B) (2025)、Search-R1-32B (2025)、WebThinker-QwQ (2025)、SimpleDeepSearcher-QwQ (2025) 和 WebDancer-32B (2025)
- 所有基线都使用与论文智能体相同的工具进行评估,以确保公平比较
- 对于多跳和单跳问答基准测试,包括 Search-R1(7B/14B/32B) (2025)、R1-Searcher(7B) (2025)、Search-o1(QwQ-32B) (2025)、DeepResearcher (2025) 和 SimpleDeepSearcher (2025)
- 论文考虑与两类基准测试相对应的两组基线
- Evaluation metrics
- 论文采用两个互补的评估指标:F1 分数和 LLM-as-Judge (LasJ)
- F1 分数在词级别(Word Level)计算,衡量预测答案和参考答案之间的精确率和召回率的调和平均数
- 对于 LLM-as-Judge,论文提示一个强大的 LLM (Qwen2.5-72B-Instruct) 根据特定任务的指令评估模型输出的正确性
- 在 GAIA、xBench-DeepSearch 和 Frames 上,论文仅使用 LLM-as-Judge 并报告所有模型的 Avg@4 和 Pass@4 分数
- ASearcher 的训练细节 (Training Details of ASearcher)
- 轮次限制:7B 和 14B 模型为 32,ASearcher-Web-QwQ 为 128
- 批次大小:7B 和 14B 模型为 128,ASearcher-Web-QwQ 为 64
- 论文整理了两组训练数据,一组用于 7B/14B 训练,另一组用于 QwQ-32B 训练
- 这两个数据集大小均为 35k 并已开源
- ASearcher-Web-QwQ 的训练大约需要 7.6k H800 GPU 小时
Main Results
- 论文在三种评估设置下展示了主要的实验结果:
- (1) 在标准问答基准测试上使用带有检索增强生成 (RAG) 的本地知识库
- (2) 在相同基准测试上使用基于网络的搜索和浏览
- (3) 在更具挑战性的基准测试上使用基于网络的搜索和浏览
- ASearcher ,实例化为 Qwen2.5-7B、Qwen2.5-14B 和 QwQ-32B,在 F1 和 LasJ 指标上始终优于相同模型规模的现有开源智能体
- ASearcher-14B 在一系列多跳和单跳问答基准测试上取得了 7B、14B 和 32B 模型中的最佳性能,并且 ASearcher-QwQ 在这些具有挑战性的基准测试上显著优于几个规模相当的有力基线
- 这些结果突显了 ASearcher 在不同任务和模型规模上的通用性和可扩展性
- 在标准问答基准测试上使用带有 RAG 的本地知识库 (Local Knowledge Base with RAG on Standard QA Benchmarks)
- 如表 2 所示,通过强化学习在本地知识库上训练的 ASearcher-Local,在一系列多跳和单跳问答基准测试上,在 7B 和 14B 规模上均取得了最佳性能
- 在 7B 设置下,ASearcher 的平均 F1 达到 58.0 ,优于 Search-R1-7B (54.3) 和 R1-Searcher-7B (52.2) 等强基线
- 其 LasJ 分数也达到 61.0 ,显著优于 Search-R1-7B (55.4) 和 R1-Searcher-7B (54.7)
- 在 14B 规模上,增益更为显著,ASearcher-Local-14B 的 F1 达到 60.0 ,LasJ 达到 65.6 ,甚至超过了更大的 32B 基于检索的基线 Search-R1-32B
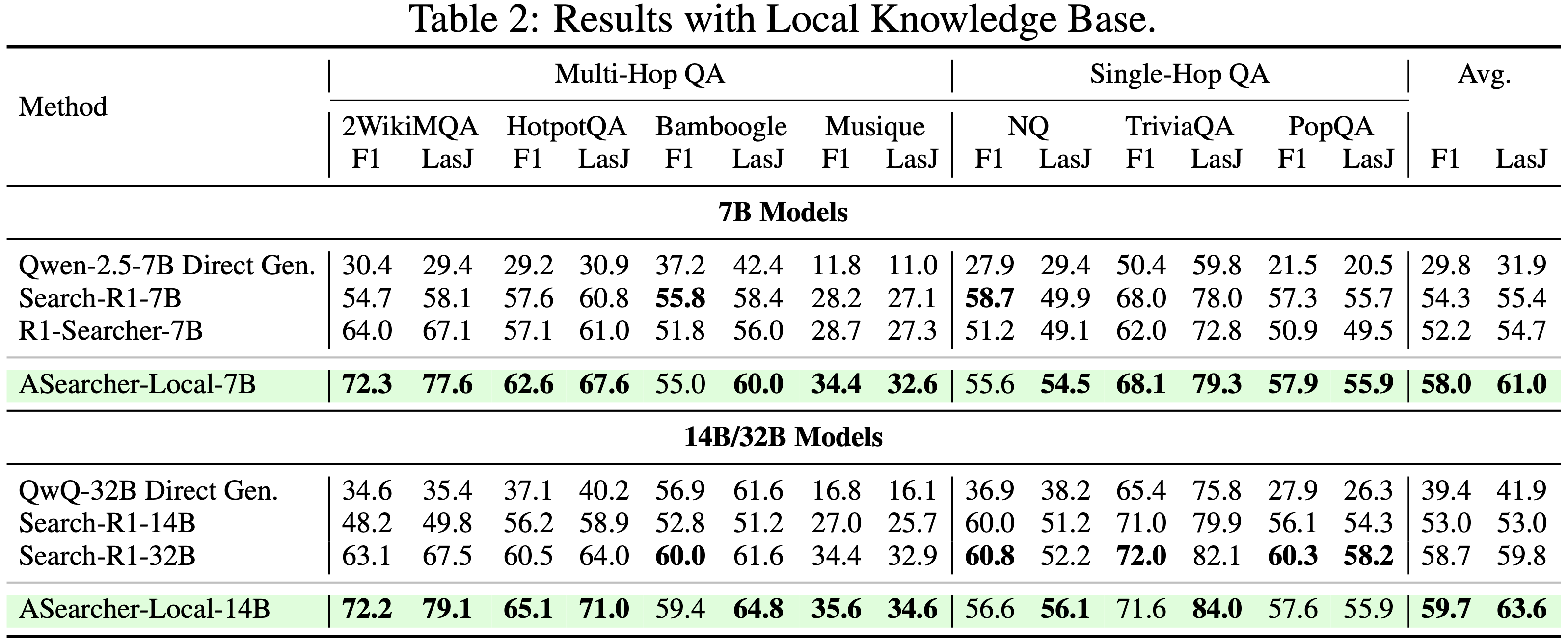
- 在 7B 设置下,ASearcher 的平均 F1 达到 58.0 ,优于 Search-R1-7B (54.3) 和 R1-Searcher-7B (52.2) 等强基线
- 如表 2 所示,通过强化学习在本地知识库上训练的 ASearcher-Local,在一系列多跳和单跳问答基准测试上,在 7B 和 14B 规模上均取得了最佳性能
- 在标准问答基准测试上使用基于网络的搜索和浏览 (Web-based Search and Browsing on Standard QA Benchmarks)。
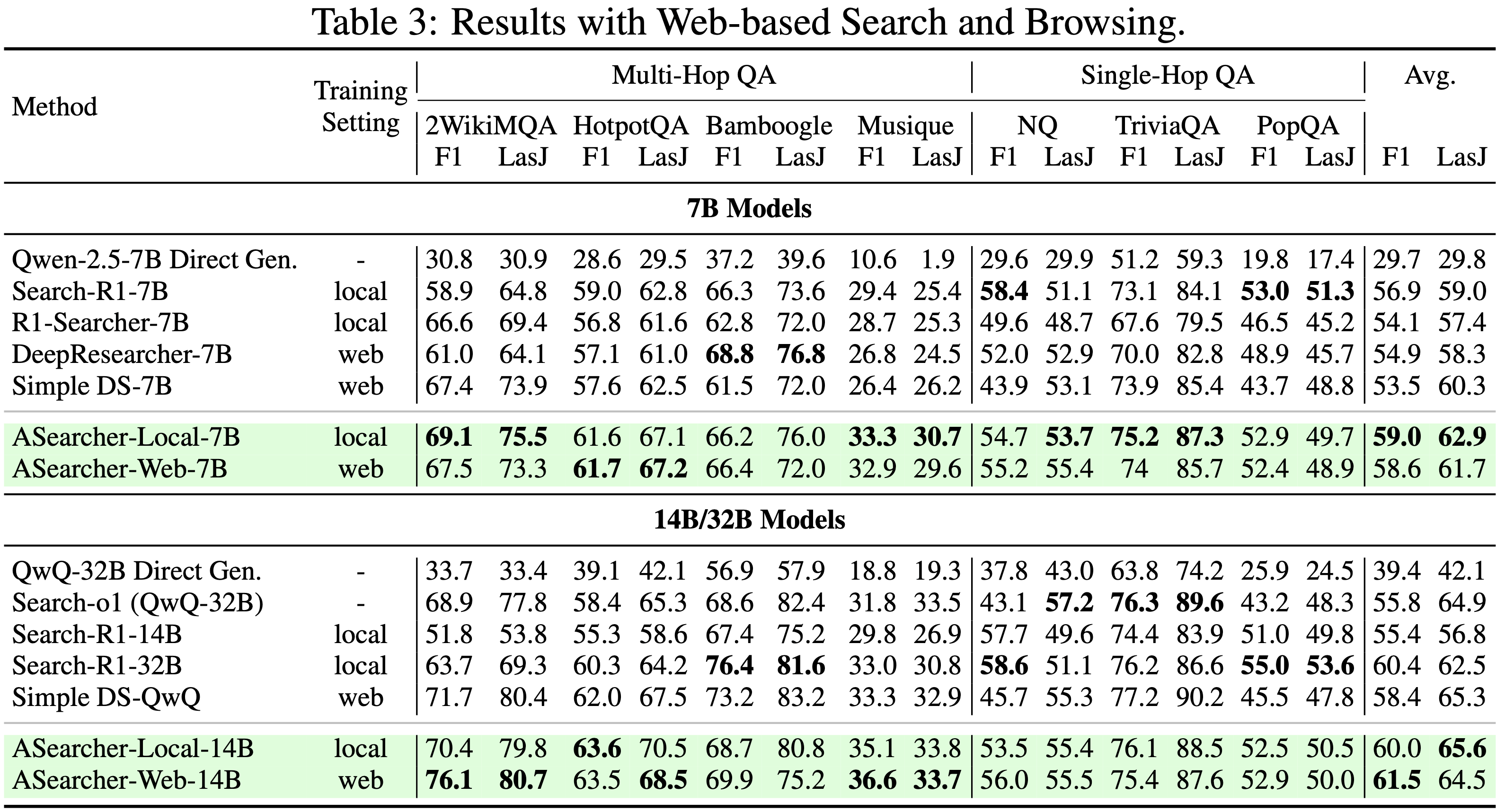
- 在表 3 中,论文在现实的基于网络的环境中评估智能体
- 论文以 zero-shot 方式评估完全使用本地知识库训练的模型在网络设置中的表现,以直接检验通过 RL 学习的搜索策略的泛化能力
- 在所有模型规模上,ASearcher 始终优于强基线
- ASearcher-Web-14B 取得了最佳性能,平均 F1 为 61.5 ,超过了在此设置下最强的 32B 基线 SimpleDeepSearcher
- ASearcher-Local-14B 模型在网络设置下测试时表现出强大的泛化能力,在 LasJ 指标上相对于相似或更大规模的所有基线模型均取得了显著增益
- 这证实了 ASearcher 学习了可迁移到不同信息源的通用搜索策略
- 在具有挑战性的基准测试上使用基于网络的搜索和浏览 (Web-based Search and Browsing on Challenging Benchmarks)
- 表 4 显示了在需要高级问题解决能力和搜索策略的具有挑战性的问答任务上的实验结果
- 这些基准测试专门设计用于评估智能体与真实网络交互并检索超出 LLM 内部知识的最新信息的能力
- 因此,直接从模型(例如 QwQ-32B)生成答案在所有数据集上表现都很差
- 论文的智能体 ASearcher-Web-QwQ 在 GAIA (52.8) 和 xBench-DeepSearch (42.1) 上取得了最佳的 Avg@4 分数
- 优于之前的开源智能体最优水平
- 这些结果进一步凸显了其在处理长视野规划、现实世界工具使用和开放领域探索方面的优越性
- 除了 Avg@4,论文还报告了 Pass@4 分数,该分数计算智能体在 4 次试验中找到正确答案的问题比例
ASearcher-Web-QwQ 在通过率方面也优于 SOTA 开源智能体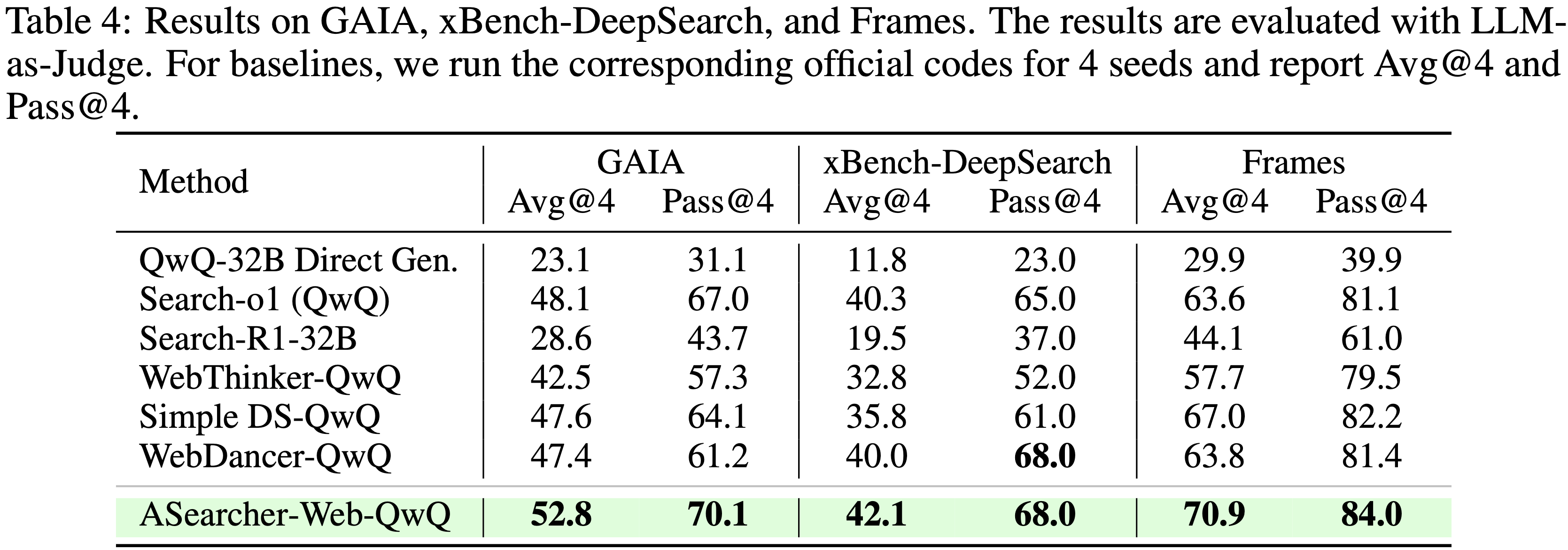
- 表 4 显示了在需要高级问题解决能力和搜索策略的具有挑战性的问答任务上的实验结果
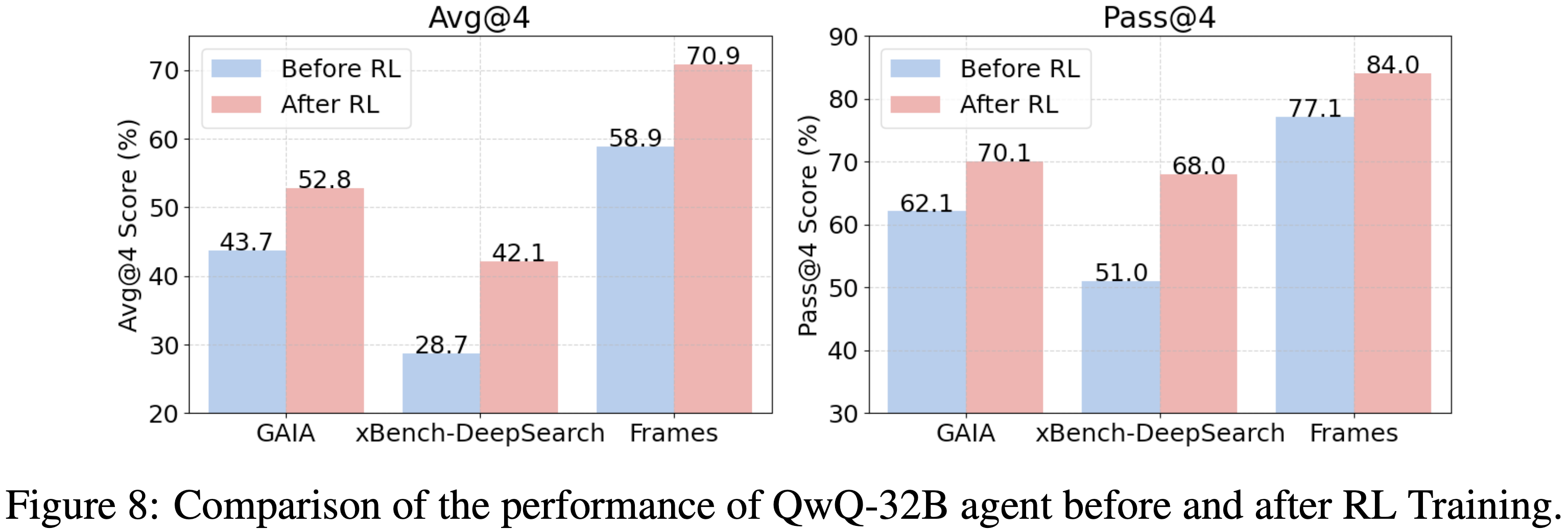
- RL 训练的效果 (Effect of RL Training)
- 如图 8 所示,ASearcher-Web-QwQ 在 GAIA、xBench-DeepSearch 和 Frames 上分别获得了 +9.1、+13.4 和 +12.0 的提升
- 当考虑通过率(即 Pass@4)时,ASearcher-Web-QwQ 也获得了显著增益,尤其是在 xBench-DeepSearch 上提升了 17.0
- 通过率的显著提升表明论文的训练流程训练智能体学习复杂的搜索策略,以执行精确搜索、提取关键信息并解决冲突信息
Training Dynamics
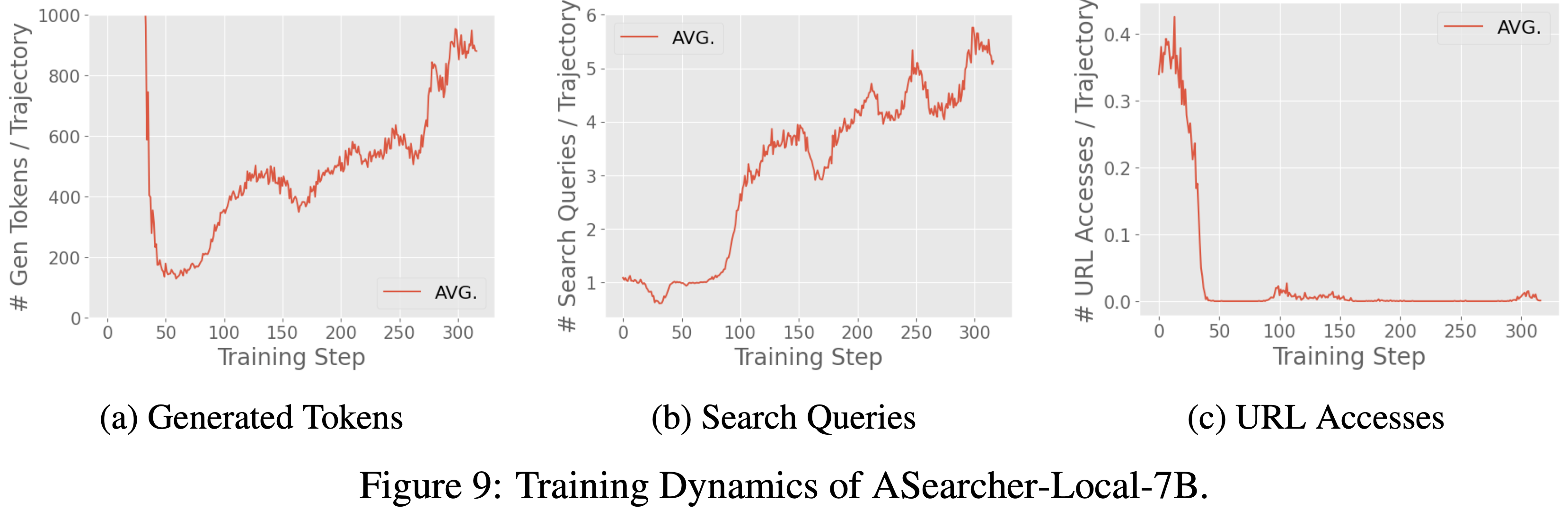
- ASearcher-Local-7B/14B 的训练动态 (Training Dynamics of ASearcher-Local-7B/14B)
- 在图 9 和图 10 中,论文分别绘制了 ASearcher-Local-7B 和 ASearcher-Local-14B 训练过程中生成的 Token 数量、搜索 Query 和网页浏览情况
- 使用论文的训练方法,在 7B 和 14B 规模上都观察到了生成长度和工具调用次数的增加
- 搜索 Query 次数扩展到 6 次,高于先前工作 (2025;) 报告的数字
- 有趣的是,论文发现 7B 模型未能学习有效的网页浏览 ,而 14B 模型可以在训练后期学习访问网页来解决具有挑战性的问题
- 论文假设 7B 模型在学习网页浏览方面的失败是因为模型容量太小 ,无法在零 RL 训练设置中稳定地学习总结冗长的网页
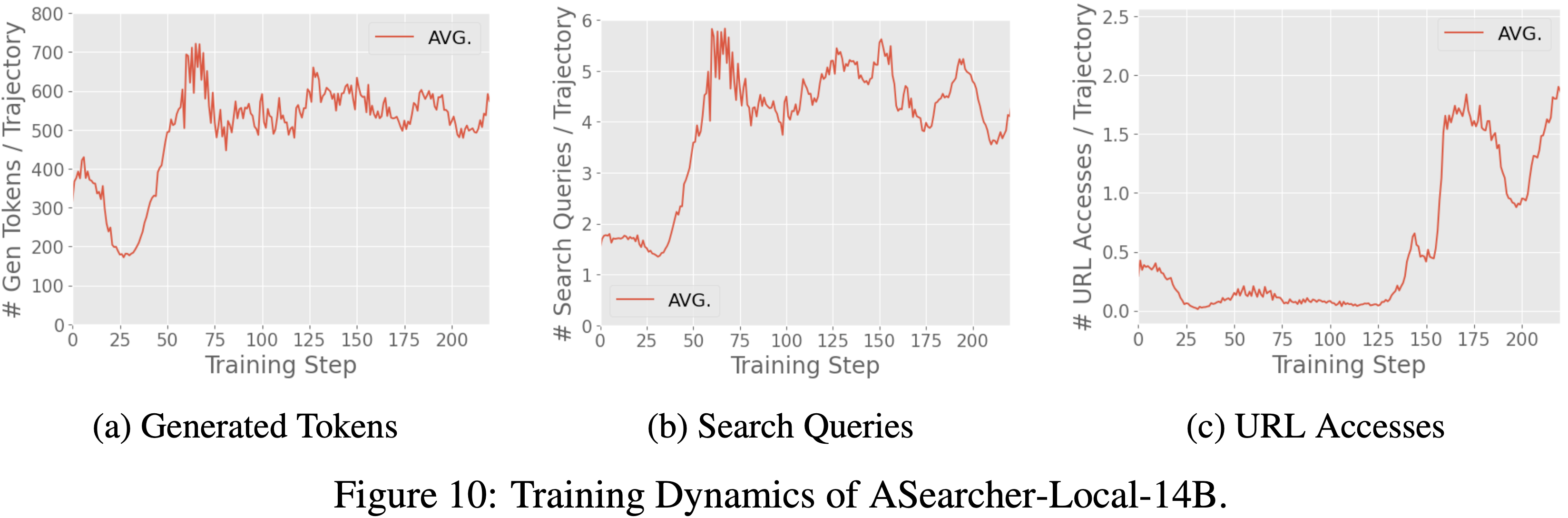
- 论文假设 7B 模型在学习网页浏览方面的失败是因为模型容量太小 ,无法在零 RL 训练设置中稳定地学习总结冗长的网页
- ASearcher-Web-QwQ 的训练动态 (Training Dynamics of ASearcher-Web-QwQ)
- ASearcher-Web-QwQ 的训练动态如图 6 所示
- 随着训练的进行,智能体学会执行更多的工具调用,在第 200 步左右达到约 40 次调用,峰值实例甚至达到 70 次调用
- QwQ-32B 智能体通过训练生成了更多的 Token ,最多超过 150k 个 Token
- 工具利用率和输出长度的这种扩展趋势突显了完全异步 RL 训练对于复杂现实世界智能体应用的潜力
- 问题:这跟完全异步 RL 有什么关系?
Related Works
Search Agents
- 一些工作已经构建了智能体工作流,使 LLM 能够利用外部工具来解决复杂任务
- 著名的例子包括 Search-o1 (2025) 和 ReAgent (2025)
- 基于提示的方法虽然对于快速开发有效,但根本上受到底层 LLM 能力的限制,并且无法通过环境反馈可靠地改进
- 一些工作尝试为 LLM 构建 SFT 轨迹
- 例如,(2023; 2024) 利用大 LLM 合成检索和推理轨迹来微调较小的模型
- 最近,一些工作研究强化学习 (RL) 方法来增强 LLM-based 智能体,主要关注多跳问答基准测试,如 HotpotQA 和 2Wiki-Multihop
- (2025;) 使用多跳问答数据进行 RL 训练,并观察到工具使用次数的增加
- RAG-R1 (2025) 进一步结合了 SFT 和 RL 来增强搜索策略
- 最近,研究人员开始关注更具挑战性的任务,通过 Offline RL (2025) 微调由大型推理模型 (LRM) 驱动的复杂基于提示的智能体,在具有真实网络数据的模拟轨迹上进行 SFT (2025;),以及为 RL 训练构建具有挑战性的问答对 (2025)
Synthetic Data for Search Agents
- 除了依赖大规模人工标注,数据合成也已成为一种可扩展的方法来为搜索智能体准备训练数据
- 一些方法通过与真实网页交互并使用 LRM 整理数据来生成合成但真实的问答轨迹 (2025;)
- WebSailor (2025) 通过采样和模糊测试构建结构上具有挑战性的任务
- WebShaper (2025) 利用集合论技术构建高质量的复杂问答对
- ASearcher 开发了一个自主的 LLM 智能体来合成具有高不确定性的挑战性问答对,而不依赖复杂的知识图谱
- ASearcher 中的数据合成智能体和合成训练数据都是完全开源的
附录 A:Full Case Study
- 在本节中,论文对来自 GAIA (2023) 的一个极具挑战性的问题进行了详细的案例研究
- 论文在图 11 中分析了 Search-R1-32B (2025) 和 Search-o1 (QwQ) (2025)
中均有提及,且同时出现在维基百科 “alvei 物种” 词条所引用的、一篇关于多中心、随机、双盲研究的 2021 年文章中的动物有哪些?")
- 论文在图 11 中分析了 Search-R1-32B (2025) 和 Search-o1 (QwQ) (2025)
- 示例问题的解决路径 (Solution Path of the Sample Question)
- 在图 11 中,论文的案例研究针对一个在给定 2 个条件和 4 个未知变量的情况下寻找特定动物的问题进行
- 为了识别正确答案,搜索智能体应首先根据条件 C1 找出提到的物种 U1 ,识别满足条件 C2 的正确文章 U2 ,然后找出 U3.1 和 U3.2 中列出的论文
- 最后,正确答案应通过交叉引用文章 U2 和论文 U3.1&U3.2 来确定
- 总结来说,这个示例具有挑战性主要有以下几个原因:
- 高不确定性 (High Uncertainty): 问题涉及多个未知变量,这些变量可能指向许多不同的实体
- 例如,2021 年的文章 U2 可能指向 2021 年发表的任何文章,并且只能在给定条件 C2 和肺泡物种 U1 的情况下确定
- 对精确信息提取的要求 (Requirement for Exact Information Extraction): 为了找到答案,智能体应列出网页上提到的所有动物并进行跨文档比较
- 这将要求智能体从海量、嘈杂的网络内容中精确提取关键信息,而不是简单地总结网页
- 误导性答案 (Misleading Answers): 在解决此任务的过程中,可能会出现多个误导性答案,例如“猪”
- 智能体应通过检查所有相关网页和文档中的预期答案来严格确认其结论
- 高不确定性 (High Uncertainty): 问题涉及多个未知变量,这些变量可能指向许多不同的实体
- 现有的 Online RL 方法未能学习复杂的搜索策略 (Existing Online RL Approaches Fail to Learn Complex Search Strategies)
- 在图 11 中,Search-R1-32B 无法将复杂 Query 分解为单独的组成部分,因此只进行了涉及过多未知信息的冗余 Query
- 该智能体还存在严重的幻觉,产生了搜索结果不支持结论
- 它未能解析所有未知变量
- 此案例研究表明,现有的 Online RL 方法仅激励了初级的搜索策略
- 同样值得注意的是,由于在训练期间轮次限制设置为较小的值(例如 4),模型仅表现出较短的工具使用视野
- 在图 11 中,Search-R1-32B 无法将复杂 Query 分解为单独的组成部分,因此只进行了涉及过多未知信息的冗余 Query
- 基于提示的 LLM 智能体可能因 LLM 能力不足而失败 (Prompt-based LLM Agents Could Fail Due to Insufficient Capability of the LLM)
- 在图 11 中,Search-o1 (QwQ) 可以通过大量的工具调用找到物种名称 U1 ,以及 2021 年的文章 U2 和论文 U3.1&U3.2
- 但在尝试寻找答案时,Search-o1 (QwQ) 很容易遗漏关键信息
- 因此,智能体得出了错误的结论
- 而且,即使智能体找到了直接指向正确答案的信息,它仍然被先前错误的结论所误导
- 最后,智能体无法验证先前结论的正确性
- 这个案例研究表明,尽管一个未在智能体任务上明确训练的开源模型可以执行大量的工具调用 ,但它无法基于检索到的内容和历史上下文进行专家级的推理
- 在图 11 中,Search-o1 (QwQ) 可以通过大量的工具调用找到物种名称 U1 ,以及 2021 年的文章 U2 和论文 U3.1&U3.2
- ASearcher-Web-QwQ
- 论文还分析了论文端到端 RL 智能体 ASearcher-Web-QwQ 的搜索策略
- 如图 11 所示,ASearcher-Web-QwQ 将复杂 Query 分解为精确且聚焦的 Query
- 与 Search-o1 (QwQ) 在每次搜索 Query 后访问大量网站不同,ASearcher-Web-QwQ 专注于访问最相关的网站
- ASearcher-Web-QwQ 总结了网站的所有相关信息
- 所有候选答案都被智能体列出并仔细分析
- 当尝试在论文 U3.1&U3.2 中搜索相关事实时,智能体明确引用了关键信息
- 当搜索结果没有直接指向期望的目标时,例如,当使用“Olga Tapia (U3.2) Hafnia alvei (U1) animal studies”进行搜索以查找与 Olga Tapia 论文相关的动物时,智能体没有得到明确的信息,但能够通过与其他论文 U3.1 建立联系来推断出正确答案
- 在找到正确答案“Mice”之后,智能体在报告最终答案之前花费了额外的轮次来确认先前的结论
- 总之,ASearcher 成功训练了一个展现出复杂行为的搜索智能体,这些行为体现了搜索智能:
- 不确定性感知推理 (Uncertainty-aware reasoning): 智能体详尽地列出并检查所有不确定实体的可能性
- 精确的关键信息提取 (Precise Key Information Extraction): 智能体能够从海量、嘈杂的网络内容中识别关键信息
- 跨文档推理 (Cross-document Inference): 智能体能够通过建立多个文档之间的联系来推断关键结论
- 严格确认 (Rigorous Confirmation): 智能体通过额外的工具调用来验证先前结论的正确性