本文介绍求解无约束最优化问题的优化方法:梯度下降法(Gradient Descent)、牛顿法(Newton’s Method)和拟牛顿法(Quasi-Newton Methods)
- 共轭梯度法也是一种无约束的参数优化方法,详情见ML——共轭梯度法和最速下降法
无约束参数优化方法概览
目标
$$
\begin{align}
\theta^{\star} = \mathop{\arg\max}_{\theta}L(\theta)
\end{align}
$$
直接法
使用直接法需要满足两个条件
- \(L(\theta)\) 为关于 \(\theta\) 的凸函数
- \(\nabla L(\theta)=0\) 有解析解(又名闭式解,指的是有限个常见运算的组合给出的形式)
求解
- 目标函数直接对参数求导后令目标函数导数为0: $$\nabla L(\theta)=0$$
迭代法
- 包括梯度下降法和牛顿法,牛顿法又可以拓展为拟牛顿法
梯度下降法
更详细的说明参考ML——最小二乘与梯度下降中的介绍
- 梯度下降法通过每次迭代沿着梯度下降最快的方向(梯度的负方向)前进一个 \(\Delta \theta\) 长度
- \(\Delta \theta\) 为步长 \(\alpha\) (参数)乘以梯度的模(变化率)的方法,实现对极大(小)值的一步步逼近
牛顿法
数学中的牛顿法
- 牛顿法的本质是求函数值 \(f(x)\) 为零(\(f(x)=0\))时参数(自变量 \(x\))的值
- 本质上说,牛顿法是用逼近的方法来解方程的一种方法
算法流程
- 对于确定的方程 \(f(x)=0\),我们的目标是求解自变量 \(x\) 的值
- 1.初始值定义为 \(x=x_{0}\)
- 2.牛顿法通过迭代每次从当前点 \((x=x_k,y=f(x_k))\) 沿着斜率 \(f’(x) = \frac{\partial f(x)}{\partial x}\) 出发做一条直线,并求出其表达式 \(y-f(x_k) = (x-x_k)\cdot f’(x)\)
- 3.求出该直线与x轴的交点 \(x_{k+1}=x_{k}-\frac{f(x_{k})}{f’(x_{k})}\)
- 4.设置下一次迭代的点为 \(x=x_{k+1}\)
- 5.重复2到4,直到斜率小于某个阈值 \(\epsilon\) 时停止迭代
- 6.迭代停止时 \(x=x_{k+1}\) 就是方程的近似解
- 迭代过程图示化如下:

迭代公式推导
- 上述迭代流程中迭代公式 \(x_{k+1}=x_{k}-\frac{f(x_{k})}{f{}’(x_{k})}\) 的推导如下:
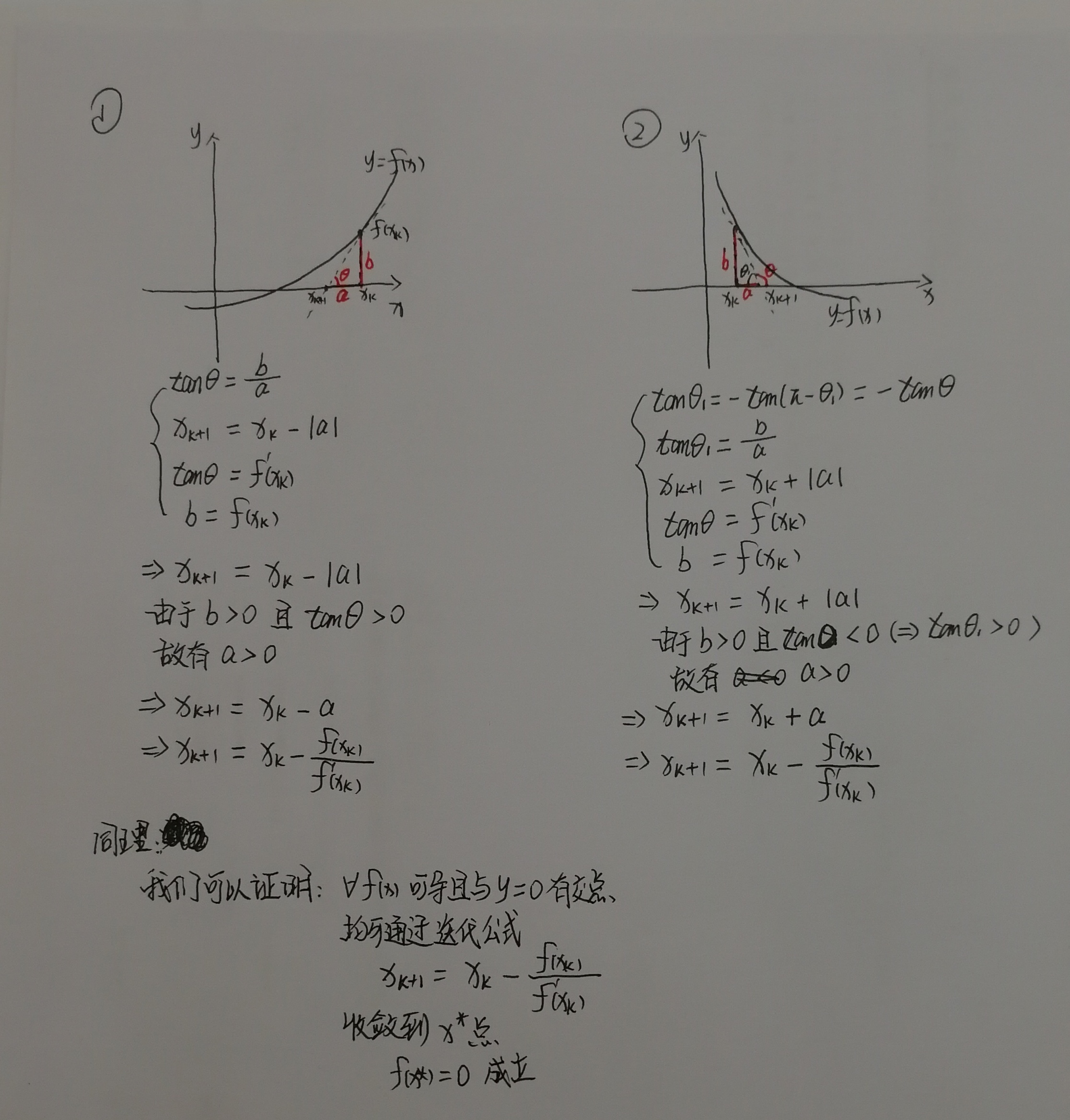
最优化方法中的牛顿法
- 最优化方法的目标是学习函数 \(f(\theta)\) 的极小/大值(若 \(f(\theta)\) 是凸函数,则为最小/大值)
- 可以证明,目标函数(凸函数)取最优点(最大/小值)时,目标函数的导数 \(\frac{\partial f(\theta)}{\partial \theta}=0, 其中\theta=\theta^{\star}\)
- 基于这个事实,在知道目标函数的导数 \(f{}’(\theta)=\frac{\partial f(\theta)}{\partial \theta}\) 的表达式后,我们可以列出方程 \(f{}’(\theta)=0\)
- 此时方程的解 \(\theta^{\star}\) 就是原始目标函数的最优解
- 解上述方程 \(\frac{\partial f(\theta)}{\partial \theta}=0\) 时我们即可使用数学中的牛顿法
算法流程
- 具体算法步骤与数学中的算法流程小节一致,不同的地方在于此时迭代公式变为 \(\theta_{k+1}=\theta_{k}-\frac{f{}’(\theta_{k})}{f{}’{}’(\theta_{k})}\)
- 在具体的实现中,我们一般会直接推导出每一步的迭代公式,按照公式迭代即可得到最优解
迭代公式推导
- 根据上述事实,此时我们的目标函数为 \(f(\theta)\),目标方程方程为 \(f{}’(\theta)=0\)
- 此时迭代公式为$$\theta_{k+1}=\theta_{k}-\frac{f{}’(\theta_{k})}{f{}’{}’(\theta_{k})}$$
- 当参数数量不止一个时, \(\theta\) 表示一个向量,此时迭代公式为$$\theta_{k+1}=\theta_{k}-H_{k}^{-1}\nabla_{\theta}f(\theta_{k})$$
- 其中 \(H_{k}^{-1}\) 为海森矩阵 \(H_{k}\) 的逆, \(H_{k}=H(\theta_{k})\)
- \(H_{k}^{-1}\) 和 \(\frac{1}{f{}’{}’(\theta_{k})}\) 分别是多维和一维参数时目标函数的二阶导
- 海森矩阵是目标函数对参数的二阶导数, \(H(\theta)=\left [ \frac{\partial^{2}f}{\partial \theta^{i}\partial \theta^{j}} \right ]_{n\times n}\)
- 推导步骤和上面的数学中的迭代公式推导一致
牛顿法与梯度下降法的一种简单推导方法
- 用泰勒展开来推导,详情待更新(参考<<百面>>P149)
迭代法的思想
- 最小化目标函数
$$
\begin{align}
\delta_{t} &= \mathop{\arg\min}_{\delta}L(\theta_{t} + \delta) \\
\theta_{t+1} &= \theta_{t} + \delta_{t} \\
\end{align}
$$ - 注意,如果这里是max最大化目标函数的话,对应的是梯度上升法,此时后面推导的步骤中加入L2正则项时为了使得 \(\left | \delta \right |_{2}^{2}\) 的值最小,正则项的权重应该为负数,这样整体目标函数最大时正则项才能取得最小值,最终推导得到的结果也将变成梯度上升的表达式,(\(\alpha > 0\) 时对应的参数迭代公式变成加好而不是减号)
- 但是实际上最大化目标函数可以价格负号转变为最小化目标函数,所以其实掌握最小化目标函数的优化方法即可
一阶法——梯度下降法
- 对目标函数在 \(L(\theta_{t} + \delta)\) 处做一阶泰勒展开
$$
\begin{align}
L(\theta_{t} + \delta) = L(\theta_{t}) + \nabla L(\theta_{t})^{T}\delta \\
\end{align}
$$ - 由于上式在 \(\delta\) 非常小时才成立,所以我们一般加上加入L2正则项(L2正则项可以保证 \(\delta\) 的值不会太大),为了保证 \(\left | \delta \right |_{2}^{2}\) 的值最小,要求 \(\alpha > 0\),才能保证目标函数最小时正则项也对应最小 (梯度上升法中要求 \(\alpha < 0\) 或者需要在正则项前面的系数加上负号,才能保证目标函数最大时正则项最小)
$$
\begin{align}
L(\theta_{t} + \delta) = L(\theta_{t}) + \nabla L(\theta_{t})^{T}\delta + \frac{1}{2\alpha}\left | \delta \right |_{2}^{2} \\
\end{align}
$$ - 直接对上式求导=0得
$$
\begin{align}
\delta_{t} &= \mathop{\arg\min}_{\delta}L(\theta_{t} + \delta) \\
&= \mathop{\arg\min}_{\delta}(L(\theta_{t}) + \nabla L(\theta_{t})^{T}\delta + \frac{1}{2\alpha}\left | \delta \right |_{2}^{2}) \\
&= -\alpha \nabla L(\theta_{t})
\end{align}
$$ - 于是梯度下降法的更新表达式为
$$
\begin{align}
\theta_{t+1} &= \theta_{t} + \delta_{t} \\
&= \theta_{t} - \alpha \nabla L(\theta_{t})
\end{align}
$$
二阶法——牛顿迭代法
- 对目标函数在 \(L(\theta_{t} + \delta)\) 处做二阶泰勒展开
$$
\begin{align}
L(\theta_{t} + \delta) = L(\theta_{t}) + \nabla L(\theta_{t})^{T}\delta + \frac{1}{2}\delta^{T}\nabla^{2}L(\theta_{t})\delta \\
\end{align}
$$ - 直接对上式求导=0得
$$
\begin{align}
\delta_{t} &= \mathop{\arg\min}_{\delta}L(\theta_{t} + \delta) \\
&= \mathop{\arg\min}_{\delta}(L(\theta_{t}) + \nabla L(\theta_{t})^{T}\delta + \frac{1}{2}\delta^{T}\nabla^{2}L(\theta_{t})\delta) \\
&= -\nabla^{2} L(\theta_{t})^{-1} \nabla L(\theta_{t}) \\
&= -H(\theta_{t})^{-1}\nabla L(\theta_{t}) \\
\end{align}
$$ - 于是梯度下降法的更新表达式为
$$
\begin{align}
\theta_{t+1} &= \theta_{t} + \delta_{t} \\
&= \theta_{t} - \nabla^{2} L(\theta_{t})^{-1} \nabla L(\theta_{t})
\end{align}
$$
比较梯度下降法与牛顿法
- 一般来说,牛顿法收敛速度快
- 一种解释是梯度下降法用一次平面去拟合局部区域牛顿法是用二次曲面去拟合局部区域 ,所以后者能得到更好的拟合效果,迭代的方向也就越精确
- 另一种解释是梯度下降只能看到当前目标函数的下降方向,牛顿法可以看到当前当前目标函数的下降方向,同时还能看到一阶导数的变化趋势,所以拟合更快
- 梯度下降法中有个超参数 \(\alpha\)
- 牛顿法中海森矩阵的逆在迭代过程中不断减小,可以起到逐步减小步长的效果(这里的步长与梯度下降中的 \(\alpha\) 步长不一样,梯度下降中的 \(\alpha\) 是超参数,表示每次向着负梯度移动的长度,而牛顿法中没有超参数)
- 为了防止震荡,这个步长 \(\alpha\) 也可以随着迭代次数不断减小
- 梯度下降法可能造成震荡
- 越接近最优值时,步长 \(\alpha\) 应该不断减小,否则会在最优值附近来回震荡
- <<统计学习方法>>第一版附录A中, \(\alpha\) 是不断变化的,能保证不会造成震荡
- 牛顿法在多变量时需要求海森矩阵H的逆,比较复杂,时间和空间上有要求,不如梯度下降法来的容易
拟牛顿法
- 解决牛顿法求取海森矩阵 \(H\) 的逆 \(H^{-1}\) 时比较耗时间的难题
- 用一个近似矩阵 \(B\) 代替海森矩阵 \(H\) 的逆 \(H^{-1}\)
- 不同算法近似矩阵 \(B\) 的计算有差异
- 常见的拟牛顿法:BFGS,L-BFGS和OWL-QN等
- <<统计学习方法>>中讲解了三个拟牛顿算法: DFP,BFGS和Broyden类算法
总结
归纳自<<统计学习方法>>
相同迭代公式
- 目标函数为 \(f(\theta)\),最优化方法的终极目标是求 \(f(\theta)\) 的最大值点(或极大值点)
- 目标函数的一阶导数
- 参数一维时为: \(f{}’(\theta)=\frac{\partial f(\theta)}{\partial \theta}\)
- 参数多维时为: \(\nabla f(\theta)\)
- 目标函数的二阶导数
- 参数一维时为: \(f{}’{}’(\theta)\)
- 参数多维时为:(海森矩阵) \(H(\theta)=\left [ \frac{\partial^{2}f}{\partial \theta^{i}\partial \theta^{j}} \right ]_{n\times n}\)
- 梯度下降法,牛顿法和拟牛顿法的迭代参数均可表示为下面的迭代形式:
$$\theta_{k+1}=\theta_{k}+\lambda_{k}p_{k}$$ - 均通过一阶导数 \(\left | \nabla f(\theta) \right |<\epsilon\) 为收敛判断条件
- 在<<统计学习方法>>中,梯度下降法还可以通过 \(\left | \theta_{k+1}-\theta_{k+} \right |<\epsilon\) 或 \(\left | f(\theta_{k+1})-f(\theta_{k+}) \right |<\epsilon\) 来判断收敛
梯度下降法
- \(p_{k}=\nabla f(x)\)
- \(\lambda_{k}\) 是步长,满足
$$f(\theta_{k}+\lambda_{k}p_{k})=\min_{\lambda \geq 0}f(\theta_{k}+\lambda p_{k})$$
牛顿法
- \(p_{k}=-H_{k}^{-1}\nabla f(\theta)\)
- \(\lambda_{k}=1\) 是固定长度的,详情见数学中的牛顿法的推导,每次迭代到斜率与横轴的交点
$$\lambda_{k}=1$$
拟牛顿法
- 核心思想是找一个容易计算的近似矩阵(可以迭代计算,而不是每次重新计算逆矩阵的矩阵)替代原始牛顿法中的海森矩阵 \(H\) (\(B\))或者海森矩阵的逆矩阵 \(H^{-1}\) (\(G\))
DFP算法
- 使用 \(G_{k}\) 逼近海森矩阵的逆矩阵 \(H^{-1}\)
- \(p_{k}=-G_{k}\nabla f(\theta)\)
- 关于 \(G_{k}\) 的计算:
- 初始化 \(G(0)\) 为正定对称矩阵
- \(G_{k+1}=G_{k}+\frac{\delta_{k}\delta_{k}^{T}}{\delta_{k}^{T}y_{k}}-\frac{G_{k}y_{k}y_{k}^{T}G_{k}}{y_{k}^{T}G_{k}y_{k}}\)
- \(\delta_{k}=\theta_{k+1}-\theta_{k}\)
- \(y_{k}=\nabla f(\theta_{k+1})-\nabla f(\theta_{k})\)
- 关于 \(G_{k}\) 的计算:
- \(\lambda_{k}\) 是步长,满足
$$f(\theta_{k}+\lambda_{k}p_{k})=\min_{\lambda \geq 0}f(\theta_{k}+\lambda p_{k})$$
BFGS算法
- 使用 \(B_{k}\) 逼近海森矩阵 \(H_{k}\)
- \(p_{k}=-B_{k}^{-1}\nabla f(\theta)\)
- 关于 \(B_{k}\) 的计算:
- 初始化 \(B(0)\) 为正定对称矩阵
- \(B_{k+1}=B_{k}+\frac{y_{k}y_{k}^{T}}{y_{k}^{T}\delta_{k}}-\frac{B_{k}\delta_{k}\delta_{k}^{T}B_{k}}{\delta_{k}^{T}B_{k}\delta_{k}}\)
- \(\delta_{k}=\theta_{k+1}-\theta_{k}\)
- \(y_{k}=\nabla f(\theta_{k+1})-\nabla f(\theta_{k})\)
- 关于 \(B_{k}\) 的计算:
- \(\lambda_{k}\) 是步长,满足
$$f(\theta_{k}+\lambda_{k}p_{k})=\min_{\lambda \geq 0}f(\theta_{k}+\lambda p_{k})$$
Broyden类算法(Broyden’s algorithm)
- 使用 \(G_{k}\) 逼近海森矩阵的逆矩阵 \(H^{-1}\)
- 在BFGS中取 \(G^{BFGS}=B^{-1}\)
- 利用DFP和BFGS二者的线性组合选择合适的海森矩阵的逆矩阵 \(H^{-1}\) 的替代矩阵
$$G_{k+1}=\alpha G^{DFP}+(1-\alpha)G^{BFGS}$$ - 可以证明 \(G\) 此时是正定的
- \(0\leq \alpha \leq 1\)
- 这样得到的一类拟牛顿法都称为Broyden类算法