One-hot encoding与Dummy-encoding易混淆点区分
Label Encoding标签编码
独热码(One-Hot code)
- 又称独热编码、一位有效编码,直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制
- 其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效
哑变量编码(Dummy encoding)
- 哑变量编码直观的解释就是在One-Hot编码的基础上任意的将一个状态位去除
- 比热独码少一维即可编码
- 可以理解为多个状态位之间是相关的,已知n-1个那么可以推出剩下的那个
- 比如已知前n-1个状态位为0,那么最后一位一定为1
- 一种做法是: 全0算是一维(理解: 由于全0可以默认最后一位为1, 其他非全0的可以默认最后一维为0,所以能够区分不同样本)
哑变量(Dummy variable)
亦称指示变量(Indicator variable)
- 以上两种编码得到的变量都称为指示变量或者哑变量
为什么需要One-Hot编码?
- 大部分算法是基于向量空间中的度量来进行计算的,为了使非偏序关系的变量取值不具有偏序性,并且到圆点是等距的, 使用one-hot编码, 将离散特征的取值扩展到了欧式空间, 离散特征的某个取值就对应欧式空间的某个点, 将离散型特征使用one-hot编码,会让特征之间的距离计算更加合理
- 将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间
独热编码优缺点
优点
- 独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用
- 它的值只有0和1,不同的类型存储在垂直的空间
- 数据天然归一化了, 非常优秀
缺点
- 当类别的数量很多时,特征空间会变得非常大
- 一般可以用PCA来减少维度
- One-Hot encoding + PCA 这种组合在实际中也非常有用
什么时候不用独热编码
- 有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码, 典型的代表如XGBoost, LightGBM等
- 存在偏序关系的特征,不能用独热编码, 独热编码会使得特征失去原来的偏序关系
标签编码
Label Encoding
- 将类别编码为连续的数值类型(0,1,2,3…)
- 举例
1
2
3
4
5
6
7from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit([1,8,9,67,5,8,6])
print(le.transform([1,1,8,9,67,5,5]))
# Output:
[0 0 3 4 5 1 1]
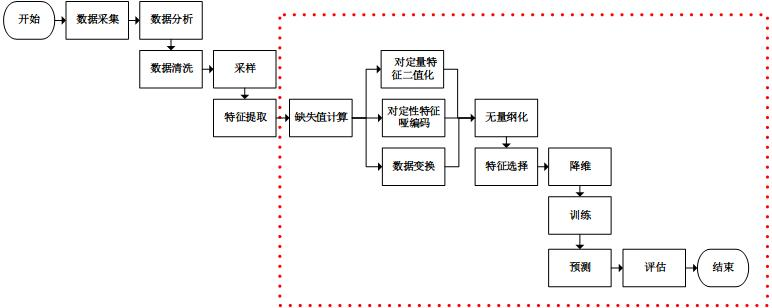
附录: 机器学习过程