本文分析UserID(User ID)和ItemID(Item ID)特征的及其常见处理方法
- 参考链接:
UserID和ItemID类特征有什么特点?
- UserID和ItemID可训练的交互数据一般服从长尾分布。从UserID视角看,头部UserID占据了样本的大多数;从ItemID视角看,头部ItemID占据了样本的大多数
- 头部的ID对应的Embedding可以得到充分学习,但是尾部的ID由于数据不够,他们的Embedding往往得不到充足的学习(一轮数据训练完成,Embedding几乎没有被更新过,那就与随机初始化参数无异了)
- 通常UserID和ItemID是高维稀疏特征,如果表示成One-Hot特征的话,会出现几千万甚至上亿维度的向量中,只有一个维度为1的情况
- 这部分特征样本区分度很高,常常称为“记忆性”特征,他们没有什么泛化能力,但是可以记住某些交互行为(比如用户A购买过物品B)
是否应该加入模型?
- 基本理念 :适合加入的情况应该是大部分ID训练样本充足的情况,且线上serving时遇到的新ID不能太多
- 数据量要求:
- 基本思路:每个ID取值下,平均样本量越少的场景越不建议加入ID特征,如果数据过于集中于极少数头部ID,还需要看看长尾情况,长尾商家(样本不足的商家)越多,越不建议加入ID特征
- 理解:ID是否能用还是要看是否有充足的数据量训练ID对应的Embedding
- 冷起要求:
- 基本思路:ItemID更新越频繁(即物品池频繁汰换)的场景越不建议加入ItemID特征;新用户占比越高的场景越不建议加入UserID特征
- 理解:新ID过多时,新的ID都是模型没有见过的,模型效果会衰减的非常快,现实生活中,可以通过使用 T+N 的数据集作为测试集验证是否有衰减问题
加入模型的哪个位置?
- 数据充足时 :每个ID数据充足的场景,可以将这些ID特征当做普通特征对待,直接Embedding后加入模型
- 数据不足时 :
- 可以考虑使用特征粒度Dropout(直接按照Embedding维度Dropout)的方式来增强泛化性【TOOD:如何理解?】
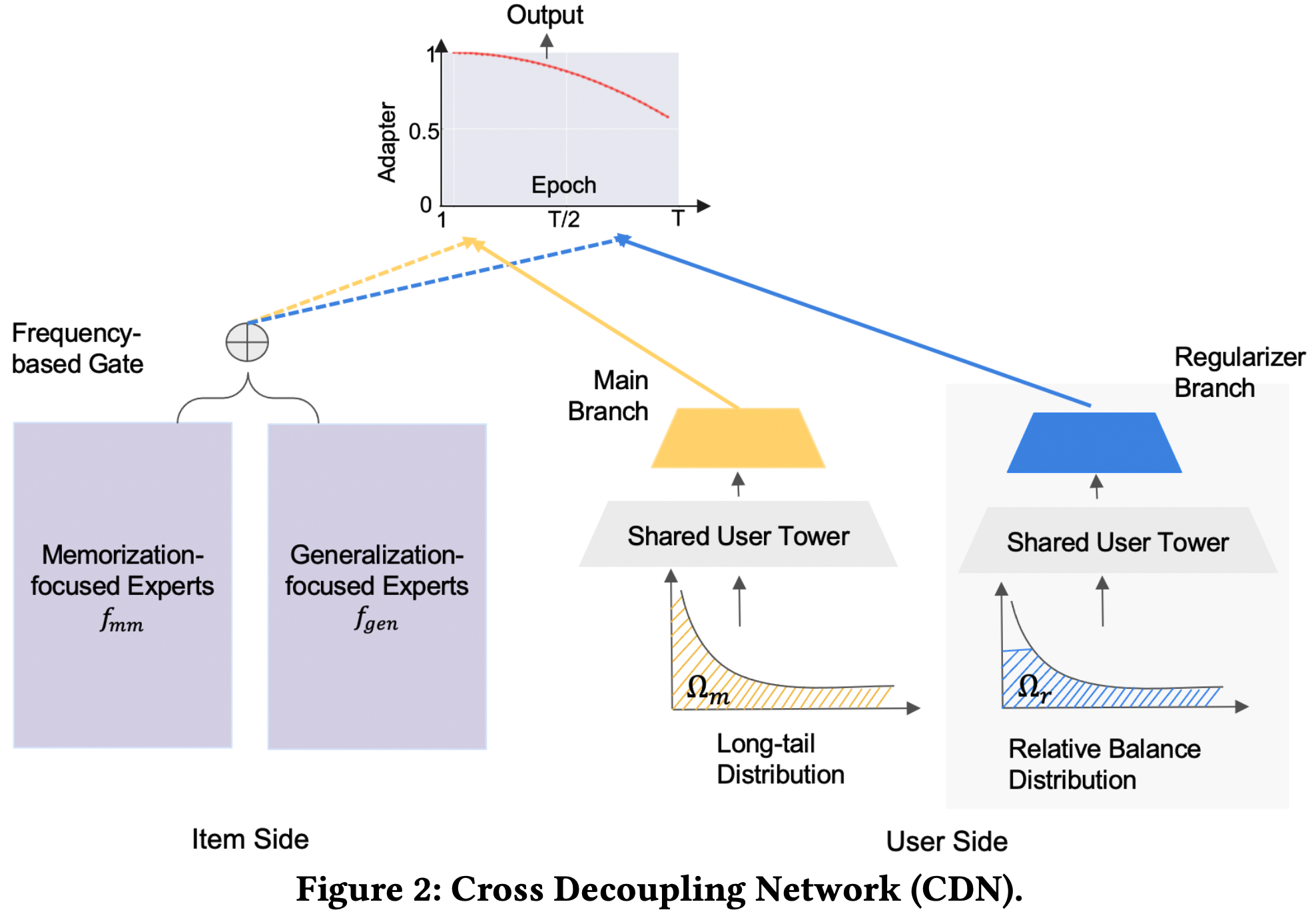
- 可以考虑将这部分特征放到一个独立的塔,然后其他特征在另一个塔,引入一个门控网络来控制两个塔对最终预估结果的影响。可参考谷歌的Empowering Long-tail Item Recommendation through Cross Decoupling Network (CDN),其网络结构图如下: