本文将介绍一般RNN,RNN的变种GRU(门控循环单元)和LSTM(长短期记忆网络)等神经网络结构
- LSTM原始论文: NIPS 2014, Sequence to Sequence Learning with Neural Networks
- GRU原始论文: EMNLP 2014, Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
一般的RNN
循环神经网络(Recurrent Neural Network,RNN)
- 将神经单元展开后的示意图如下:
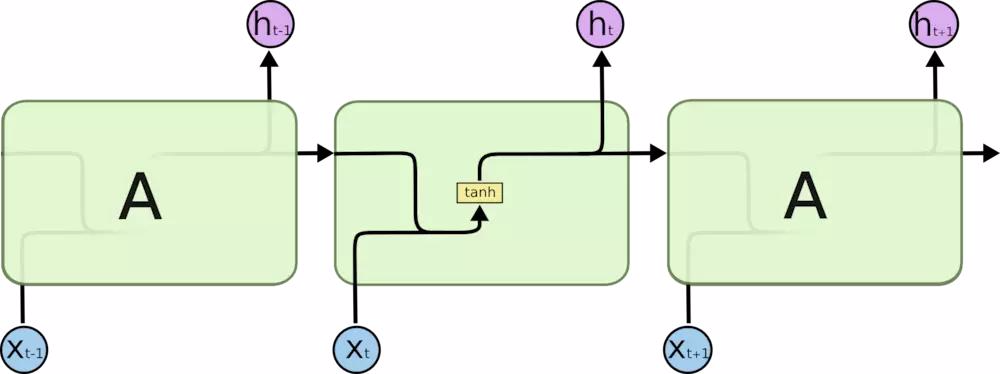
RNN与CNN优缺点比较
此处我们之比较 CNN 和 RNN 在序列预测问题中的优劣
- 关于前馈神经网络:
- 是一种最简单的神经网络
- 各神经元分层排列,每个神经元只接受前一层的输入,输出到下一层,已知到输出层
- 整个网络中没有反馈(后面的 backward 求梯度不能算反馈,这里指一次输入到输出计算各层间没有反馈,数据流只能从上一层到下一层单向流动)
- 可以用一个有向无环图表示
- CNN:
- 是一种前馈神经网络(多层感知机),是多层感知机的变体
- 采用固定大小的输入并生成固定大小的输出
- CNN是图像和视频处理的理想选择
- RNN:
- 不是前馈神经网络,有环
- 可以处理任意长度的输入输出
- 使用时间序列信息,能用之前的状态影响下一个状态
- RNN是文本和语音分析的理想选择
- RNN在处理序列信息的缺点:
- 对短期输入非常敏感,但是对长期输入不敏感
- 难以处理长文本中长距离的单词间的关系
LSTM
长短期记忆网络(Long Short-Term Memory, LSTM)
- 整体示意图如下:
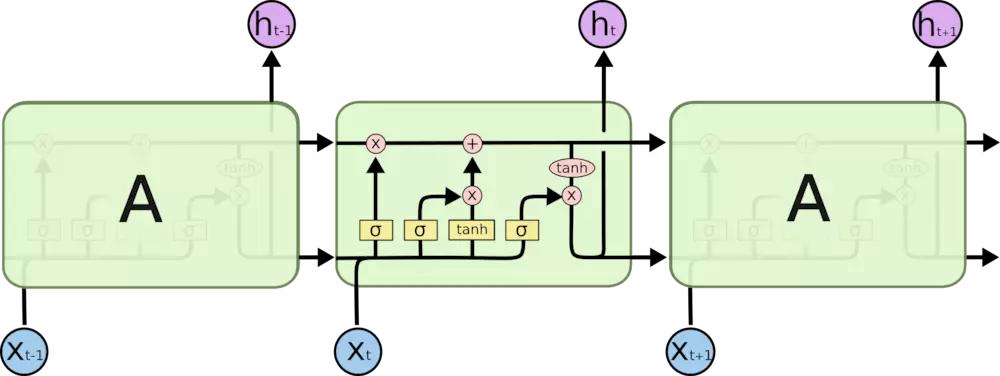
- 核心是”(Gate)门”结构
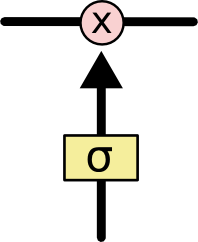
- 其中Sigmoid是输出0到1的数值,描述每个部分有多少量可以通过当前门
- 0表示拒绝所有,1表示接受所有
- 多个门和状态共同作用,使LSTM能够有效捕捉长期依赖关系并避免梯度消失问题:
- 细胞状态 \( C_t \)部分 :长期记忆,传递历史信息
- 隐藏状态 \( h_t \)部分 :短期记忆,当前时间步的输出
- 输入门 \( i_t \)部分 :控制新信息的加入
- 遗忘门 \( f_t \)部分 :控制历史信息的保留
- 输出门 \( o_t \)部分 :控制细胞状态对隐藏状态的影响
- 候选细胞状态 \( \tilde{C}_t \)部分 :当前时间步的候选更新值
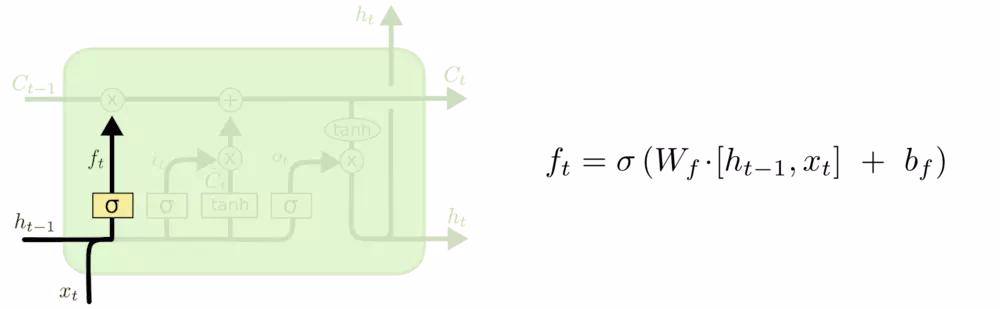
遗忘门(Forget Gate,\( f_t \) )
- 作用 :控制前一个细胞状态 \( C_{t-1} \) 的遗忘程度:\(f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)\),输出在0到1之间,决定保留或丢弃多少历史信息
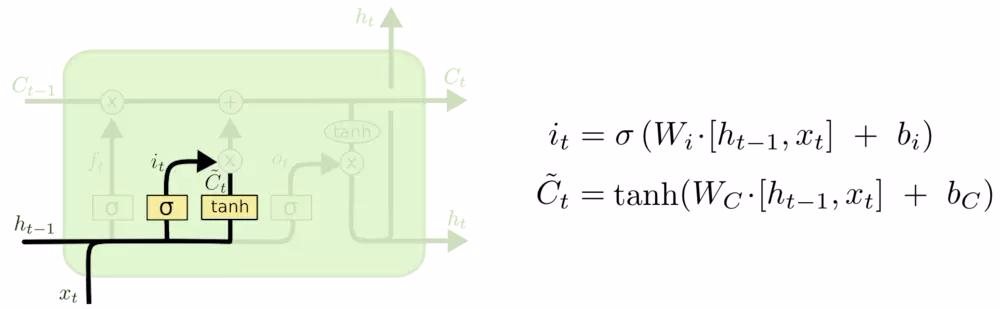
输入门(Input Gate,\( i_t \))和 候选细胞状态(Candidate Cell State,\( \tilde{C}_t \))
- 输入门作用 :控制当前输入信息对细胞状态的更新程度, \(i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)\),输入门的输出在0到1之间,决定哪些新信息需要加入细胞状态
- 候选细胞状态作用 :表示当前时间步的候选更新值, \(\tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C)\),用于更新细胞状态,候选细胞状态是当前输入和前一隐藏状态的非线性组合
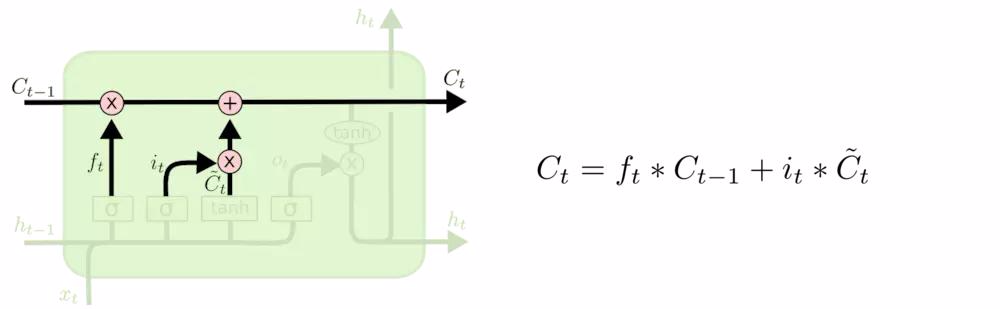
细胞状态(Cell State, \( C_t \) )
- 细胞状态 \( C_t \) 作用 :细胞状态是LSTM的核心,负责长期记忆的传递。\(C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t\),它像一个“传送带”,能够在时间步之间传递信息,并通过门控机制(遗忘门控制历史信息的保留,输入门控制新信息的加入)决定保留或丢弃哪些信息,细胞状态的变化相对平缓,能够捕捉长期依赖关系,通过遗忘门和输入门更新:
输出门(Output Gate,\( o_t \))和 隐藏状态(Hidden State,\( h_t \))
- 输出门 \( o_t \) 作用 :控制细胞状态对当前隐藏状态的影响程度,\(o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)\),输出门的输出在0到1之间,决定细胞状态如何影响当前隐藏状态
- 隐藏状态 \( h_t \) 作用 :隐藏状态是LSTM的短期记忆,表示当前时间步的输出,\(h_t = o_t \cdot \tanh(C_t)\),它基于细胞状态和当前输入生成(输出门控制细胞状态对当前隐藏状态的影响,生成当前时间步的输出),并传递到下一个时间步,隐藏状态是LSTM对外的输出(即
output_t),它既用于当前时间步的输出,也用于下一个时间步的计算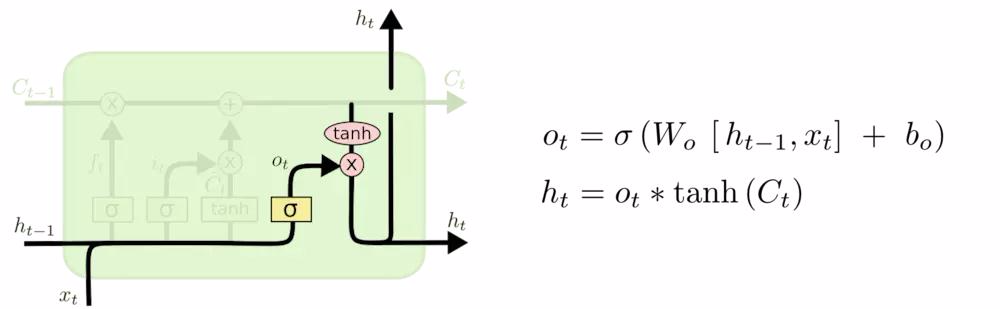
- 特别说明 :LSTM中的第 \(t\) 步的输出不是 \(o_t\)(\(o_t\)是输出门,而不是输出), LSTM的通用输出就是 \(h_t\) 本身,但具体将LSTM应用到不同场景中时,可以接入不同的层来将 \(h_t\) 解码/转换为真实的输出 \(output_t = TransLayer(h_t)\)
- 补充问题 :在文本翻译中,解码阶段,是否LSTM的 \(h_{t-1}\) 和 \(x_t\) 相等?一般不相等,因为解码时有:
$$x_t = Embedding(output_{t-1}) = Embedding(TransLayer(h_{t-1}))$$- 比如在文本翻译中 \(h_{t-1}\) 是一个向量,而 \(output_{t-1}\) 是一个具体的 token,而上述公式中的 \(x_t \) 则一般是输入 \(input_t\)(\(= output_{t-1}\)) 经过 Embedding 后的向量
LSTM简单代码实现
- LSTM的PyTorch实现Demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 定义 LSTM 单元
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 定义门参数
self.W_i = nn.Linear(input_size + hidden_size, hidden_size) # 输入门参数
self.W_f = nn.Linear(input_size + hidden_size, hidden_size) # 遗忘门参数
self.W_c = nn.Linear(input_size + hidden_size, hidden_size) # 候选记忆单元参数
self.W_o = nn.Linear(input_size + hidden_size, hidden_size) # 输出门参数
def forward(self, x, h_prev, c_prev):
combined = torch.cat((x, h_prev), dim=1)
i = torch.sigmoid(self.W_i(combined))
f = torch.sigmoid(self.W_f(combined))
c_tilde = torch.tanh(self.W_c(combined))
o = torch.sigmoid(self.W_o(combined))
c_next = f * c_prev + i * c_tilde
h_next = o * torch.tanh(c_next)
return h_next, c_next
GRU
门控循环单元(Gated Recurrent Unit, GRU)
整体示意图及推导如下:

特别说明 :上述公式中,没有明确包含输出 \(output_t\),GRU中的第 \(t\) 步的通用输出和LSTM一致,就是 \(h_t\) 本身,但具体将GRU应用到不同场景中时,可以接入不同的层来将 \(h_t\) 解码/转换为真实的输出 \(output_t = TransLayer(h_t)\)
GRU简单代码实现
- GRU的PyTorch实现Demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 定义 GRU 单元
class GRUCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(GRUCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 定义门参数
self.W_z = nn.Linear(input_size + hidden_size, hidden_size)
self.W_r = nn.Linear(input_size + hidden_size, hidden_size)
self.W_h = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, x, h_prev):
combined = torch.cat((x, h_prev), dim=1)
z = torch.sigmoid(self.W_z(combined))
r = torch.sigmoid(self.W_r(combined))
h_tilde = torch.tanh(self.W_h(torch.cat((x, r * h_prev), dim=1)))
h_next = (1 - z) * h_prev + z * h_tilde
return h_next
GRU与LSTM对比
- 二者提出的时间基本相同
- 都是用来解决RNN不能处理长期依赖的问题
- LSTM有三个”门”结构, GRU只有两个”门结构”
- GRU较简单,参数比较少,不容易过拟合,LSTM 比较复杂一点,但是常用
附录:一个基于nn.LSTM的Decoder-Encoder翻译模型实现
- 一个基于
nn.LSTM的Decoder-Encoder翻译实现示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129import torch
import torch.nn as nn
import torch.optim as optim
# 编码器
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.lstm(output, hidden)
return output, hidden
def initHidden(self):
return (torch.zeros(1, 1, self.hidden_size),
torch.zeros(1, 1, self.hidden_size))
# 解码器
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = torch.relu(output)
output, hidden = self.lstm(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return (torch.zeros(1, 1, self.hidden_size),
torch.zeros(1, 1, self.hidden_size))
# 数据集
source_vocab = {'hello': 0, 'world': 1, '!': 2}
target_vocab = {'你好': 0, '世界': 1, '!': 2, '<EOS>': 3}
input_size = len(source_vocab)
output_size = len(target_vocab)
hidden_size = 256
encoder = Encoder(input_size, hidden_size)
decoder = Decoder(hidden_size, output_size)
# 合并编码器和解码器的参数
params = list(encoder.parameters()) + list(decoder.parameters())
# 创建一个优化器来更新所有参数
optimizer = optim.SGD(params, lr=0.01)
criterion = nn.NLLLoss()
# 训练数据
train_data = [
(["hello", "world", "!"], ["你好", "世界", "!", "<EOS>"])
]
# 训练
for epoch in range(100):
total_loss = 0
for src, tgt in train_data:
input_tensor = torch.tensor([source_vocab[word] for word in src])
target_tensor = torch.tensor([target_vocab[word] for word in tgt])
optimizer.zero_grad()
encoder_hidden = encoder.initHidden()
for ei in range(len(input_tensor)):
encoder_output, encoder_hidden = encoder(input_tensor[ei].unsqueeze(0), encoder_hidden)
decoder_input = torch.tensor([[0]])
decoder_hidden = encoder_hidden
loss = 0
for di in range(len(target_tensor)):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
loss += criterion(decoder_output, target_tensor[di].unsqueeze(0))
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f'Epoch {epoch + 1}, Loss: {total_loss / len(train_data)}')
# 评估
reverse_target_vocab = {idx: word for word, idx in target_vocab.items()}
for src, _ in train_data:
input_tensor = torch.tensor([source_vocab[word] for word in src])
encoder_hidden = encoder.initHidden()
for ei in range(len(input_tensor)):
encoder_output, encoder_hidden = encoder(input_tensor[ei].unsqueeze(0), encoder_hidden)
decoder_input = torch.tensor([[0]])
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(10):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
topv, topi = decoder_output.topk(1) # topk(1)函数在默认维度(最后一维)上抽取最大的1个数字,并返回其在这个维度上的index
decoded_word = reverse_target_vocab[topi.item()]
decoded_words.append(decoded_word)
if decoded_word == '<EOS>':
break
decoder_input = topi.squeeze().detach()
print(f'Input: {" ".join(src)}, Translation: {" ".join(decoded_words)}')
# Epoch 10, Loss: 4.957141399383545
# Epoch 20, Loss: 4.250643253326416
# Epoch 30, Loss: 3.5705487728118896
# Epoch 40, Loss: 2.95521879196167
# Epoch 50, Loss: 2.438739538192749
# Epoch 60, Loss: 2.025095224380493
# Epoch 70, Loss: 1.698549509048462
# Epoch 80, Loss: 1.438602328300476
# Epoch 90, Loss: 1.2278329133987427
# Epoch 100, Loss: 1.0538270473480225
# Input: hello world !, Translation: 你好 世界 ! <EOS>
附录:一个基于 nn.GRU 的 Decoder-Encoder 翻译模型实现
一个基于
nn.GRU的 Decoder-Encoder 翻译实现示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127import torch
import torch.nn as nn
import torch.optim as optim
# 编码器
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size)
# 解码器
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = torch.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size) # 这里LSTM是2个隐向量
# 数据集
source_vocab = {'hello': 0, 'world': 1, '!': 2}
target_vocab = {'你好': 0, '世界': 1, '!': 2, '<EOS>': 3}
input_size = len(source_vocab)
output_size = len(target_vocab)
hidden_size = 256
encoder = Encoder(input_size, hidden_size)
decoder = Decoder(hidden_size, output_size)
# 合并编码器和解码器的参数
params = list(encoder.parameters()) + list(decoder.parameters())
# 创建一个优化器来更新所有参数
optimizer = optim.SGD(params, lr=0.01)
criterion = nn.NLLLoss()
# 训练数据
train_data = [
(["hello", "world", "!"], ["你好", "世界", "!", "<EOS>"])
]
# 训练
for epoch in range(100):
total_loss = 0
for src, tgt in train_data:
input_tensor = torch.tensor([source_vocab[word] for word in src])
target_tensor = torch.tensor([target_vocab[word] for word in tgt])
optimizer.zero_grad()
encoder_hidden = encoder.initHidden()
for ei in range(len(input_tensor)):
encoder_output, encoder_hidden = encoder(input_tensor[ei].unsqueeze(0), encoder_hidden)
decoder_input = torch.tensor([[0]])
decoder_hidden = encoder_hidden
loss = 0
for di in range(len(target_tensor)):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
loss += criterion(decoder_output, target_tensor[di].unsqueeze(0))
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f'Epoch {epoch + 1}, Loss: {total_loss / len(train_data)}')
# 评估
reverse_target_vocab = {idx: word for word, idx in target_vocab.items()}
for src, _ in train_data:
input_tensor = torch.tensor([source_vocab[word] for word in src])
encoder_hidden = encoder.initHidden()
for ei in range(len(input_tensor)):
encoder_output, encoder_hidden = encoder(input_tensor[ei].unsqueeze(0), encoder_hidden)
decoder_input = torch.tensor([[0]])
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(10):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
topv, topi = decoder_output.topk(1) # topk(1)函数在默认维度(最后一维)上抽取最大的1个数字,并返回其在这个维度上的index
decoded_word = reverse_target_vocab[topi.item()]
decoded_words.append(decoded_word)
if decoded_word == '<EOS>':
break
decoder_input = topi.squeeze().detach()
print(f'Input: {" ".join(src)}, Translation: {" ".join(decoded_words)}')
# Epoch 10, Loss: 4.1139960289001465
# Epoch 20, Loss: 2.4189529418945312
# Epoch 30, Loss: 1.5635995864868164
# Epoch 40, Loss: 1.0992240905761719
# Epoch 50, Loss: 0.8163852691650391
# Epoch 60, Loss: 0.6290442943572998
# Epoch 70, Loss: 0.49852463603019714
# Epoch 80, Loss: 0.4044916033744812
# Epoch 90, Loss: 0.3349364101886749
# Epoch 100, Loss: 0.2822900116443634
# Input: hello world !, Translation: 你好 世界 ! <EOS>与LSTM实现的主要区别是,
output, hidden = self.gru(output, hidden)中输入和输出的 hiden 的数量不同,LSTM 包含两个向量(\(C_t\) 和 \(h_t\)),而 GRU 只包含一个 \(h_t\)