模型压缩
- 模型压缩(Model Compression)技术包含模型量化、蒸馏、剪枝等
- 有时候模型量化和蒸馏会同时使用
- 剪枝不常见
模型量化
- 模型量化(Model Quantization),是一种将模型中的权重和激活从浮点数(高位宽)转换为低精度(低位宽)的表示的方法,如8位整数(INT8)
- 数值上来看,量化是将连续值离散化的过程
- 参考链接:
线性量化与非线性量化
- 线性量化(linear quantization),也叫仿射量化(affine quantization)或者均匀量化
- 我们很容易给出量化公式:
其中,r(real value)值得是量化前的值,q(quantized value)是量化后的值,s(scale)是放缩比例,z(zero point)相当于是一个偏移量
- 我们很容易给出量化公式:
- 非线性量化(nonlinear quantization),也叫作非均匀量化
对称量化与非对称量化
- 对称量化(symmetric quantization):映射前后0点相同
- 非对称量化(asymmetric quantization):映射前后0点不相同
量化粒度
- Per-Tensor Quantization(逐张量量化):
- 这是最简单的量化方式,对整个张量(即模型中的一个参数矩阵或输入数据)使用相同的量化参数(比如最小值和最大值,或者量化因子)
- 由于所有值共享相同的量化参数,因此这种方法的精度较低,但计算简单,存储和传输效率高
- Per-Channel Quantization(逐通道量化):
- 在这种量化方式中,每个通道(对于卷积神经网络中的滤波器来说,通道通常指的是滤波器输出的不同颜色或特征)使用不同的量化参数
- 这种方法比逐张量量化更精细,因为不同的通道可能具有不同的值范围,因此可以独立地进行量化,以保持每个通道的精度
- 因为有研究发现不同Channel的参数量级差距较大
- Per-Layer Quantization(逐层量化):
- 逐层量化意味着网络中的每一层都有自己的量化参数集
- 这种方法允许每一层根据其激活值的范围独立地进行量化,这可能比逐张量量化提供更好的精度,但比逐通道量化的计算成本要低
- Per-Axis Quantization(逐轴量化):
- 这种量化方式通常用于多维张量,比如二维的权重矩阵。在这种情况下,”axis”可以指特定的维度,比如行或列
- 逐轴量化意味着沿着张量的一个或多个维度,量化参数是不同的。例如,在二维张量中,可以对每一行或每一列使用不同的量化参数
量化方式(PTQ vs QAT)
- PTQ(Post training quantization),后训练量化,训完的模型直接量化,然后进行推理
- QAT(Quantization aware training),量化感知训练,训练完的模型加载到内存,进行微调后再用于推理
- LLM常用的思路就是float16训练base模型并存储,SFT时使用INT8量化并使用LoRA微调模型,然后存储LoRA参数,推理时加载base模型(INT8量化加载)和LoRA参数一起推理
量化位宽
- 统一位宽
- 混合精度
量化模型训练梯度
- 梯度回传时量化是离散的,梯度为0,实际上可以设置为1,因为量化一般是阶梯函数,类似于线性的
最新的量化模型
QLoRA
- QLoRA是一种高效的微调方法,它允许在保持完整的16位微调任务性能的同时,将内存使用量降低到足以在单个48GB GPU上微调650亿参数模型。QLoRA通过冻结的4位量化预训练语言模型向低秩适配器(Low Rank Adapters,简称LoRA)反向传播梯度。这种方法的主要贡献包括:
- 4-bit NormalFloat (NF4):一种新的数据类型,理论上对正态分布的权重是最优的
- Double Quantization:通过量化量化常数来减少平均内存占用
- Paged Optimizers:使用NVIDIA统一内存特性,自动在CPU和GPU之间进行页面转换,以避免梯度检查点操作时内存不足
- QLoRA主要用于微调训练阶段,使得在单个GPU上进行大型模型的微调成为可能,这对于资源有限的研究者和开发者来说是一个重大突破
GPTQ
- GPTQ(Generative Pre-trained Transformer Quantization)是一种针对生成预训练Transformer模型的量化技术。GPTQ旨在解决大型GPT模型的高计算和存储成本问题。这些模型由于其庞大的规模,即使在高性能GPU上进行推理也需要大量的计算资源。GPTQ通过以下方式来提高效率:
- 一次性权重量化:基于近似二阶信息的方法,可以在不需要重新训练的情况下压缩模型
- 高压缩率:能够将模型量化到每个权重3或4位,同时几乎不降低准确度
- 高效执行:允许在单个GPU上执行大型参数模型的生成推理,显著减少了所需的硬件资源
- GPTQ通过用于部署推理阶段,用于减少模型的大小和内存占用,使得这些大型模型更易于部署和使用
模型蒸馏
- 模型蒸馏通常也叫作知识蒸馏(Knowledge Distillation),模型蒸馏泛指整个蒸馏技术框架,两者通常可以视作同一概念,但在一些特定的场景上会有微小差别
- 模型蒸馏更倾向于表达模型压缩的思想,强调从大模型(教师模型)迁移知识到小模型(学生模型)的过程
- 知识蒸馏更专注于将教师模型的知识(如输出分布、中间特征)传递给学生模型,不强调模型压缩,目标是提升学生模型的泛化能力
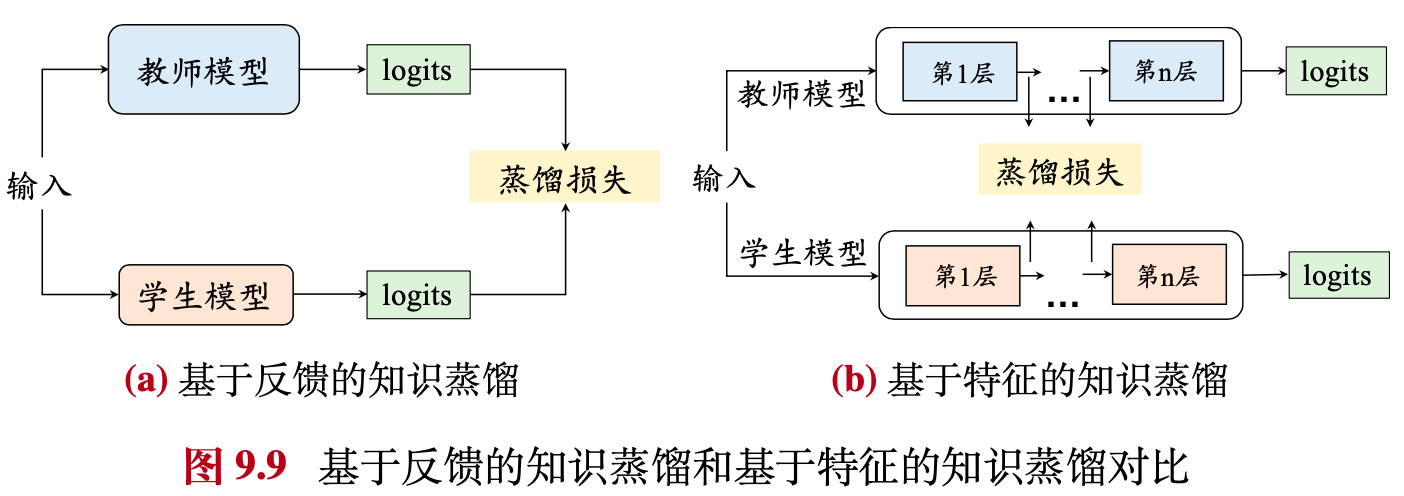
- 模型蒸馏(Model Distillation),主要包含Logits蒸馏和特征蒸馏两大类
- 参考链接:知识蒸馏算法汇总
知识蒸馏有两大类:一类是logits蒸馏,另一类是特征蒸馏。logits蒸馏指的是在softmax时使用较高的温度系数,提升负标签的信息,然后使用Student和Teacher在高温softmax下logits的KL散度作为loss。中间特征蒸馏就是强迫Student去学习Teacher某些中间层的特征,直接匹配中间的特征或学习特征之间的转换关系。例如,在特征No.1和No.2中间,知识可以表示为如何模做两者中间的转化,可以用一个矩阵让学习者产生这个矩阵,学习者和转化之间的学习关系。 这篇文章汇总了常用的知识蒸馏的论文和代码,方便后续的学习和研究
Logits蒸馏
- 关注输出层
- 也叫作基于反馈的知识蒸馏
- 学生模型被训练以模仿教师模型的输出概率分布。通过最小化两个模型输出概率分布之间的KL散度(或其他相似性度量),学生模型学习教师模型的“软目标”,即对每个类别的概率预测,而不是单一的预测标签
- 损失函数 :一般实现时,除了损失函数一般还会考虑真实的预测标签,以多分类模型为例,输出是一个概率分布(例如,经过 softmax 后的 \( K \) 维向量),教师模型和学生模型的输出概率分布可以表示为:
- 教师模型的输出:\( P_T = [p_T^1, p_T^2, \dots, p_T^K] \)
- 学生模型的输出:\( P_S = [p_S^1, p_S^2, \dots, p_S^K] \)
- 损失函数包括:
- KL散度损失 :
$$
L_{KD} = T^2 \cdot D_{KL}(P_T || P_S) = T^2 \cdot \sum_{i=1}^K p_T^i \log \frac{p_T^i}{p_S^i}
$$- 其中 \(T\) 为维度系数
- 交叉熵损失 :
$$
L_{CE} = - \sum_{i=1}^K y_i \log p_S^i
$$- 其中,\( y_i \) 是真实标签的 one-hot 编码
- 总损失 :
$$
L = \alpha \cdot L_{KD} + (1 - \alpha) \cdot L_{CE}
$$
- KL散度损失 :
特征蒸馏
- 关注中间层
- 也叫作基于特征的知识蒸馏
- 学生模型被训练以模仿教师模型在中间层的激活或特征图。这通常通过最小化两个模型对应层的特征表示之间的距离(如L2距离或cosine相似度)来实现
- 损失函数 :特征蒸馏的总损失函数通常结合特征蒸馏损失和任务损失(如分类损失):
$$
L = \alpha \cdot L_{Feature} + (1 - \alpha) \cdot L_{Task}
$$- 其中:
- \( L_{Feature} \) 是特征蒸馏损失(如 MSE、余弦相似度等)
- \( L_{Task} \) 是任务损失(如交叉熵损失)
- \( \alpha \) 是权重系数,用于平衡两部分损失
- 其中:
LLM的蒸馏
- 在A Survey on Model Compression for Large Language Models中,将知识蒸馏分为黑盒知识蒸馏和白盒知识蒸馏两类
- 黑盒知识蒸馏 :通常表示对ChatGPT,GPT4等黑盒LLM模型教师模型进行蒸馏,黑盒蒸馏使用教师模型的输出token作为监督来优化学生模型,蒸馏手段包含了基于CoT(Chain-of-Thought)的知识蒸馏、基于语境学习(In-Context Learning)的蒸馏和基于指令跟随(Insruction Following)的知识蒸馏
- 白盒知识蒸馏 :通常表示对白盒LLM教师模型内部的结构和知识进行蒸馏
- Deepseek-R1技术报告中的蒸馏是直接采用Deepseek-R1训练过程中收集到的80W数据对开源的模型(如qwen,llama等)做SFT
模型剪枝
- Model Pruning
- 通过删减网络结构然后调整分布实现模型压缩,剪枝方法不常用